Как эффективно работать с json в R?
Является продолжением предыдущих публикаций.
Постановка проблемы
Как правило, основным источником данных в формате json оказыватся REST API. Применение json помимо платформонезависимости и удобства восприятия данных человеком позволяет обмениваться системам неструктурированными данными со сложной древовидной структурой.
В задачах построения API это очень удобно. Легко обеспечить версионность коммуникационных протоколов, легко обеспечить гибкость информационного обмена. При этом сложность структуры данных (уровней вложенности может быть 5, 6, 10 или даже больше) не пугает, поскольку написать для единичной записи гибкий парсер, учитывающий все и вся, не так уж сложно.
Задачи обработки данных включают в себя также получение данных из внешних источников, в т.ч. в формате json. В R есть хороший набор пакетов, в частности, jsonlite, предназначенных для преобразования json в объекты R (list или, data.frame, если структура данных позволяет).
Однако, на практике часто возникает два класса задач, когда использование jsonlite и ему подобных становится крайне неэффективным. Задачи выглядят примерно так:
- обработка большого объема данных (единица измерения — гигабайты), полученных в ходе работы различных информационных систем;
- объединение большого количества ответов с переменной структурой, полученных в ходе пакета параметризированных запросов REST API, в единообразное прямоугольное представление (
data.frame).
Пример подобной структуры на иллюстрациях:
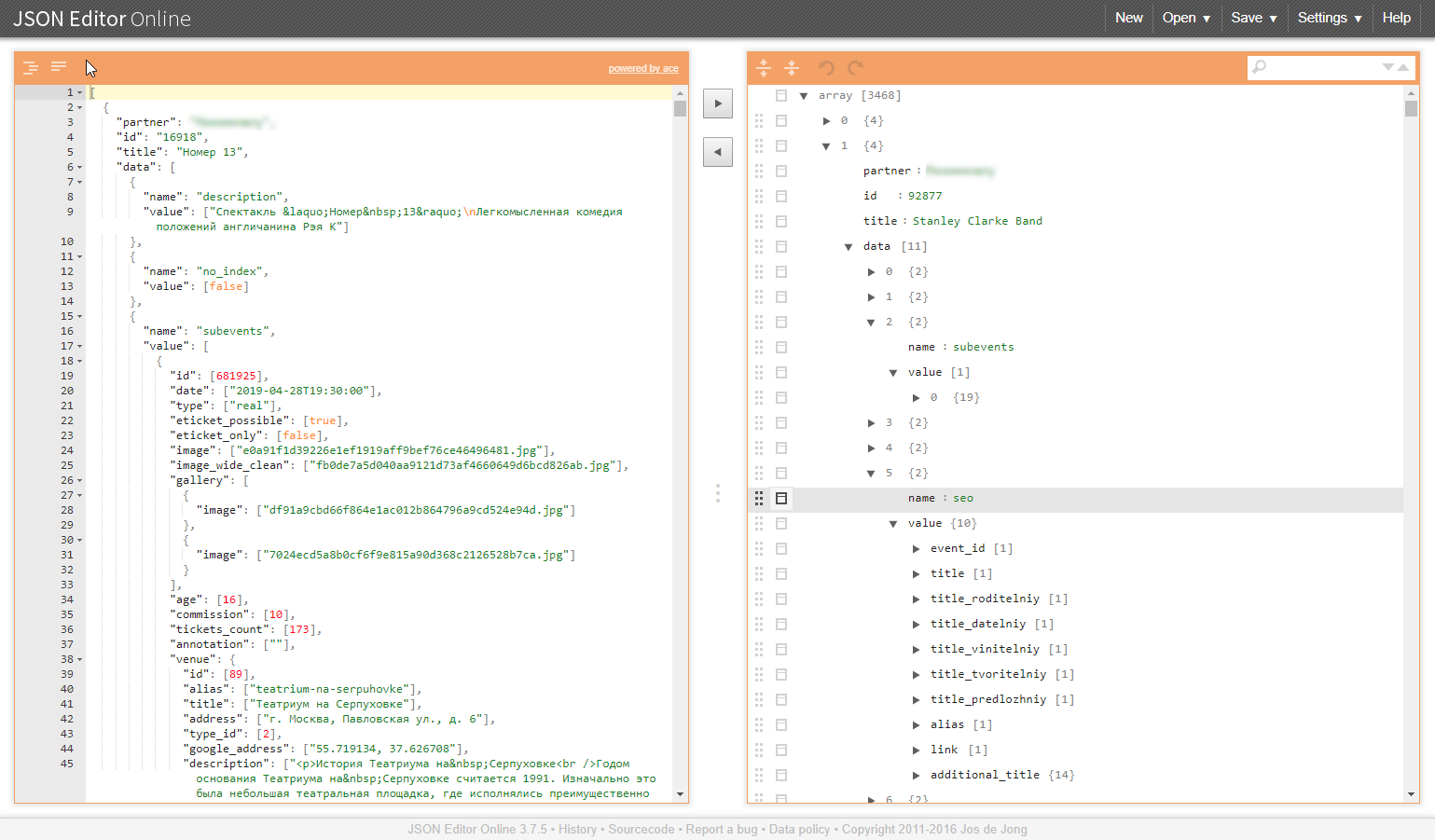
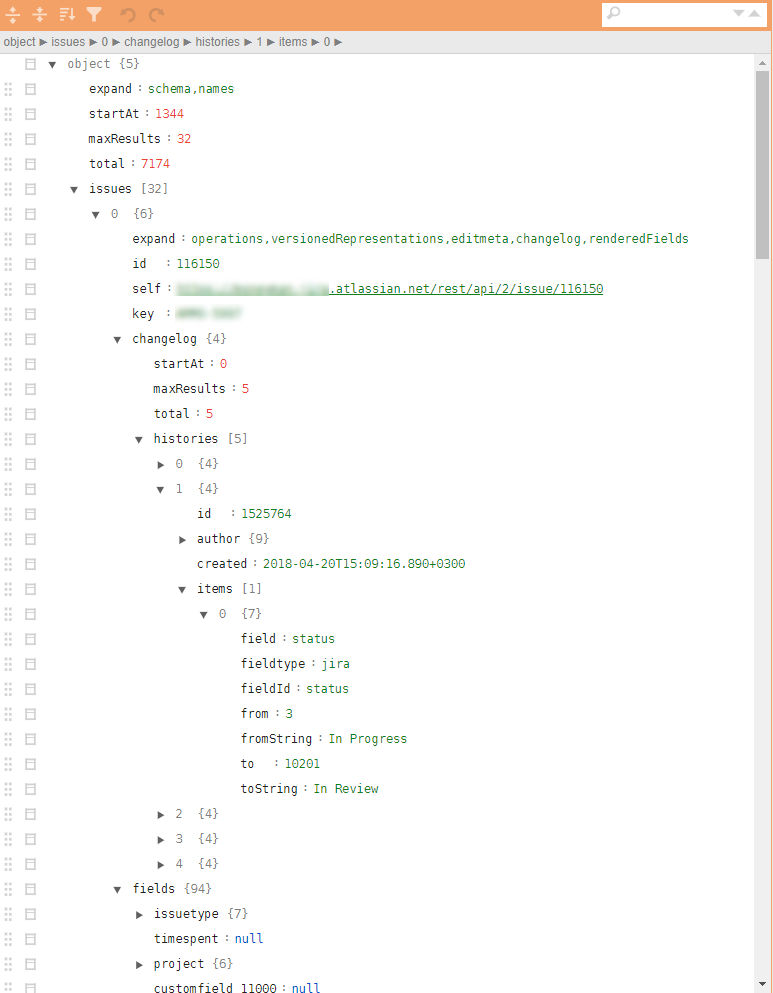
Почему же эти классы задач проблематичны?
Большой объем данных
Как правило, выгрузки из информационных систем в формате json представляют собой неделимый блок данных. Чтобы его распарсить корректно необходимо весь его прочитать и пробежаться по всему его объему.
Индуцированные проблемы:
- необходимо сообразное количество оперативки и вычислительных ресурсов;
- скорость парсинга сильно зависит от качества используемых библиотек и даже при наличии достаточности ресурсов время преобразования может составить десятки или даже сотни минут;
- в случае сбоя парсинга на выходе никакого результата не получается, а надеяться, что все и всегда пройдет гладко, нет никаких оснований, скорее наоборот;
- будет весьма удачно, если разобранные данные можно будет преобразовать в
data.frame.
Слияние древовидных структур
Подобные задачи возникают, например, когда необходимо по пачке запросов через API собрать справочники, требуемые по бизнес-процессу для работы. Дополнительно справочники подразумевают унификацию и готовность к встраиванию в аналитический пайплайн и потенциальной выгрузке в БД. А это опять же приводит к необходимости превращения таких сводных данных в data.frame.
Индуцированные проблемы:
- древовидные структуры сами не превратятся в плоскую. json парсеры превратят входные данные в набор вложенных списков, которые потом вручную необходимо долго и мучительно развертывать;
- свобода в атрибутах выдаваемых данных (отсутствующие могут и не выдаваться) приводит к появлению
NULLобъектов, которые уместны в списках, но не могут "уместиться" вdata.frame, что еще больше усложняет постпроцессинг и усложняет даже базовый процесс слияния отдельных строк-листов вdata.frame(неважно,rbindlist,bind_rows,map_dfrилиrbind).
JQ — выход из ситуации
В особо сложных ситуациях применение весьма удобных подходов пакета jsonlite "конвертируем все в R объекты" по указанным выше причинам дает серьезный сбой. Хорошо, если до конца обработки удаётся добраться. Хуже, если посередине придется развести руки и сдаться.
Альтернативой такому подходу является использование json препроцессора, оперирующего непосредственно данными в формате json. Библиотека jq и обертка jqr. Практика показывает, что ее не только мало используют, но и мало кто о ней вообще слышал.
И очень зря!
Преимущества библиотеки jq.
- библиотекой можно пользоваться в R, в Python и в командной строке;
- все преобразования производятся на уровне json, без трансформации в представления R/Python объектов;
- процессинг можно разбить на атомарные операции и использовать принцип цепочек (pipe);
- циклы по обработке векторов объектов скрыты внутри парсера, синтаксис итерирования максимальной упрощен;
- возможность провести все процедуры по унификации структуры json, развертыванию и выборке необходимых элементов с целью формирования json формата, преобразуемого пакетным образом в
data.frameсредствамиjsonlite; - многократное сокращение R кода, отвечающего за процессинг json данных;
- огромная скорость обработки, в зависимости от объема и сложности структуры данных выигрыш может составлять 1-3 порядка;
- гораздо меньшие требования к оперативной памяти.
Код по обработке сжимается до размеров экрана и может выглядеть примерно таким образом:
cont <- httr::content(r3, as = "text", encoding = "UTF-8")
m <- cont %>%
# исключим ненужные атрибутивные списки
jqr::jq('del(.[].movie.rating, .[].movie.genres, .[].movie.trailers)') %>%
jqr::jq('del(.[].movie.countries, .[].movie.images)') %>%
# исключим ненужные атрибутивные списки
jqr::jq('del(.[].schedules[].hall, .[].schedules[].language, .[].schedules[].subtitle)') %>%
# исключим ненужные атрибутивные списки
jqr::jq('del(.[].cinema.location, .[].cinema.photo, .[].cinema.phones)') %>%
jqr::jq('del(.[].cinema.goodies, .[].cinema.subway_stations)')
# расщепляем
m2 <- m %>%
jqr::jq('[.[] | {date, movie, schedule: .schedules[], cinema}]')
df <- fromJSON(m2) %>%
as_tibble()jq весьма элегантен и быстр! Тем, кому это актуально: качаем, ставим, разбираемся. Ускоряем процессинг, упрощаем жизнь себе и коллегам.
Предыдущая публикация — «Как начать применять R в Enterprise. Пример практического подхода».
