
В прошлом месяце на NVIDIA GTC 2019 компания NVIDIA представила новое приложение, которое превращает нарисованные пользователем простые цветные шарики в великолепные фотореалистичные изображения.
Приложение построено на технологии генеративно-состязательных сетей (GAN), в основе которой лежит глубинное обучение. Сама NVIDIA называет его GauGAN — это каламбур-отсылка к художнику Полу Гогену. В основе функциональности GauGAN лежит новый алгоритм SPADE.
В этой статье я объясню, как работает этот инженерный шедевр. И чтобы привлечь как можно больше заинтересованных читателей, я постараюсь дать детализированное описание того, как работают свёрточные нейронные сети. Поскольку SPADE — это генеративно-состязательная сеть, я расскажу подробнее и о них. Но если вы уже знакомы с эти термином, вы можете сразу перейти к разделу «Image-to-image трансляция».
Давайте начнем разбираться: в большинстве современных приложений глубинного обучения используется нейронный дискриминантный тип (дискриминатор), а SPADE — это генеративная нейронная сеть (генератор).
Дискриминатор занимается классификацией вводимых данных. Например, классификатор изображения — это дискриминатор, который берет изображение и выбирает одну подходящую метку класса, например, определяет изображение как «собаку», «автомобиль» или «светофор», то есть выбирает метку, которая целиком описывает изображение. Полученный классификатором вывод обычно представлен в виде вектора чисел , где
, где  — это число от 0 до 1, выражающее уверенность сети в принадлежности изображения к выбранному
— это число от 0 до 1, выражающее уверенность сети в принадлежности изображения к выбранному  -классу.
-классу.
Дискриминатор также может составить целый список классификаций. Он может классифицировать каждый пиксель изображения как принадлежащий классу «людей» или «машин» (так называемая «семантическая сегментация»).

Классификатор берет изображение с 3 каналами (красный, зеленый и синий) и сопоставляет его с вектором уверенности в каждом возможном классе, который может представлять изображение.
Поскольку связь между изображением и его классом очень сложна, нейронные сети пропускают его через стек из множества слоев, каждый из которых «немного» обрабатывает его и передает свой вывод на следующий уровень интерпретации.
Генеративная сеть наподобие SPADE получает набор данных и стремится создавать новые оригинальные данные, которые выглядят так, как будто они принадлежат этому классу данных. При этом данные могут быть любыми: звуками, языком или чем-то еще, но мы сосредоточимся на изображениях. В общем случае ввод данных в такую сеть представляет собой просто вектор случайных чисел, причем каждый из возможных наборов вводимых данных создает свое изображение.
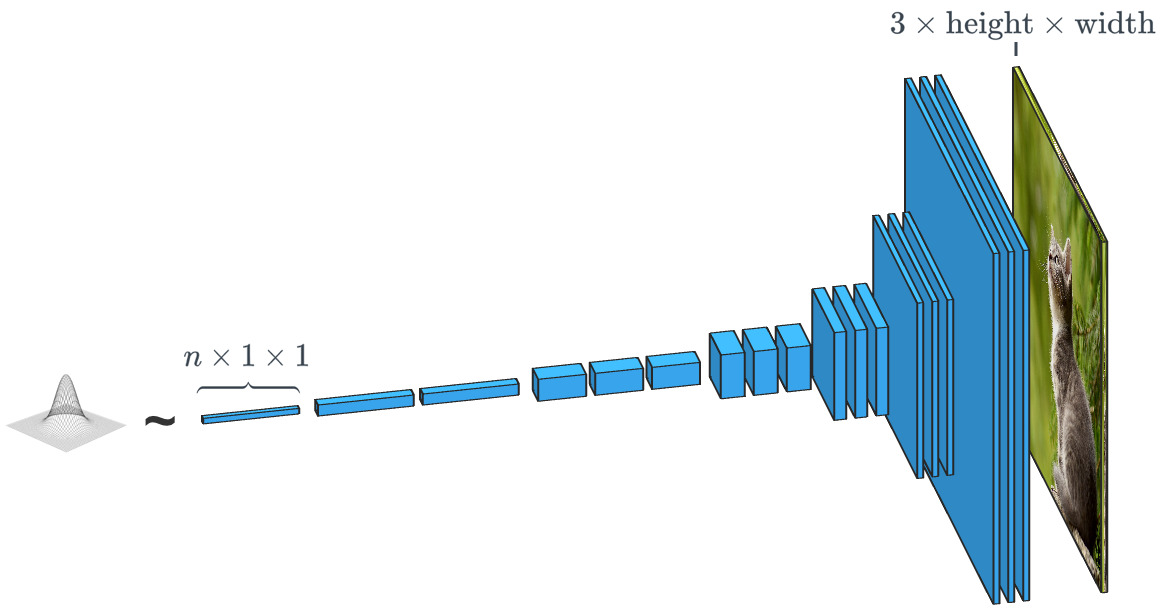
Генератор на основе случайного входного вектора работает фактически противоположно классификатору изображения. В генераторах «условных классов» входной вектор — это, фактически, вектор целого класса данных.
Как мы уже видели, SPADE использует намного больше, чем просто «случайный вектор». Система руководствуется своеобразным чертежом, который называется «картой сегментации». Последняя указывает, что и где размещать. SPADE проводит процесс, обратный семантической сегментации, упомянутой нами выше. В целом, дискриминационная задача, переводящая один тип данных в другой, имеет аналогичную задачу, но идет другим, непривычным путем.
Современные генераторы и дискриминаторы обычно используют сверточные сети для обработки своих данных. Для более полного ознакомления со сверточным нейронным сетям (CNNs), см. пост Ужвал Карна или работу Андрея Карпати.
Между классификатором и генератором изображения есть одно важное различие, и заключается оно в том, как именно они изменяют размер изображения в ходе его обработки. Классификатор изображения должен уменьшать его до тех пор, пока изображение не потеряет всю пространственную информацию и не останутся только классы. Это может быть достигнуто объединением слоев, либо через использование сверточных сетей, через которые пропускают отдельные пиксели. Генератор же создает изображение с помощью процесса, обратного «свертке», который называется сверточным транспонированием. Его еще часто путают с «деконволюцией» или «обратной сверткой».
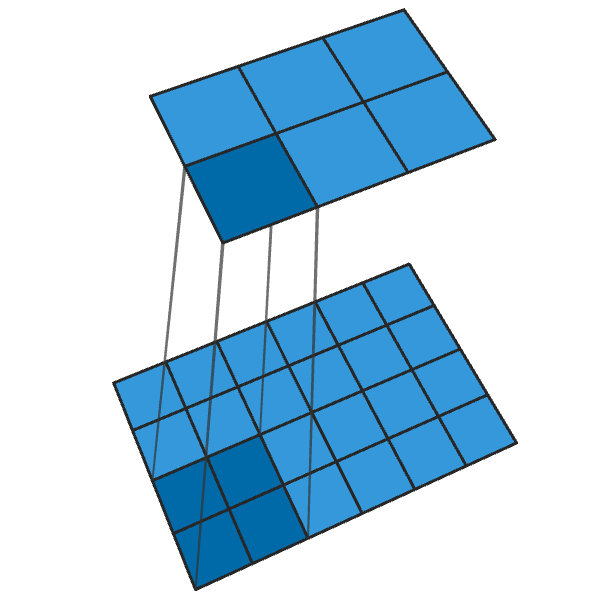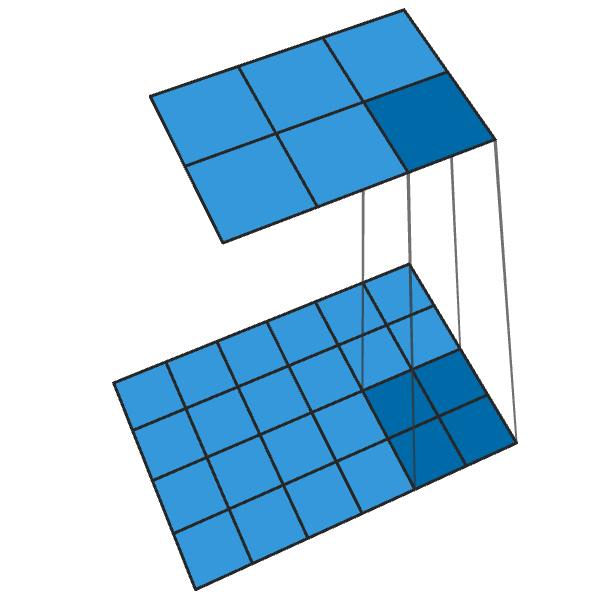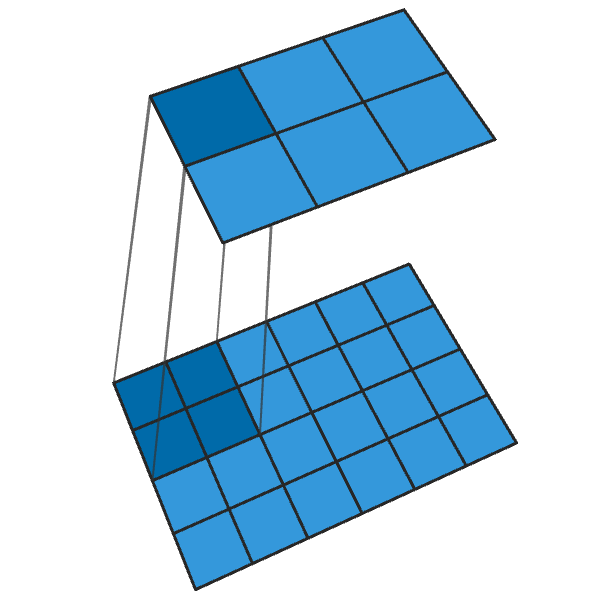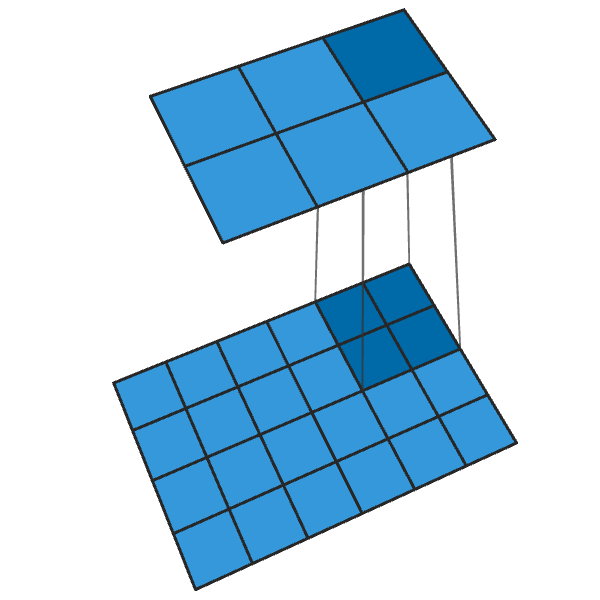
Обычная свертка 2x2 с шагом «2» превращает каждый блок 2x2 в одну точку, уменьшая выходные размеры на 1/2.

Транспонированная свертка 2x2 с шагом «2» генерирует блок 2x2 из каждой точки, увеличивая выходные размеры в 2 раза.
Теоретически, сверточная нейронная сеть cможет генерировать изображения описанным выше образом. Но как мы мы ее натренируем? То есть, если учитывать набор входных данных-изображений, как мы можем настроить параметры генератора (в нашем случае SPADE), чтобы он создавал новые изображения, которые выглядят так, как будто они соответствуют предложенному набору данных?
Для этого нужно проводить сравнение с классификаторами изображений, где каждое из них имеет правильную метку класса. Зная вектор предсказания сети и правильный класс, мы можем использовать алгоритм обратного распространения (backpropagation algorithm), чтобы определить параметры обновления сети. Это нужно, чтобы повысить ее точность в определении нужного класса и уменьшить влияние остальных классов.

Точность классификатора изображения можно оценить, поэлементно сравнив его вывод с правильным вектором класса. Но для генераторов не существует «правильного» выходного изображения.
Проблема в том, что когда генератор создает изображение, для каждого пикселя нет «правильных» значений (мы не можем сравнить результат, как в случае классификатора по заранее подготовленной базе, — прим. пер.). Теоретически, любое изображение, которое выглядит правдоподобно и похоже на целевые данные, является действительным, даже если его значения пикселей сильно отличаются от реальных изображений.
Итак, как мы можем сообщить генератору, в каких пикселях он должен изменять свой вывод и каким образом он может создавать более реалистичные изображения (т.е. как подавать «сигнал об ошибке»)? Исследователи много размышляли над этим вопросом, и на самом деле это довольно сложно. Большинство идей, таких как вычисление некоторого среднего «расстояния» до реальных изображений, дают размытые картинки низкого качества.
В идеале мы могли бы «измерить», насколько реалистично выглядят сгенерированные изображения через использование концепции «высокого уровня», такой как «Насколько сложно это изображение отличить от реального?»…
Именно это реализовали в рамках работы Goodfellow et al., 2014. Идея состоит в том, чтобы генерировать изображения, используя две нейронные сети вместо одной: одна сеть —
генератор, вторая — классификатор изображений (дискриминатор). Задача дискриминатора состоит в том, чтобы отличать выходные изображения генератора от реальных изображений из первичного набора данных (классы этих изображений обозначены как «поддельные» и «реальные»). Работа же генератора заключается в том, чтобы обмануть дискриминатор, создавая изображения, максимально похожие на изображения в наборе данных. Можно сказать, что генератор и дискриминатор являются противниками в этом процессе. Отсюда и название: генеративно-состязательная сеть.
Генеративно-состязательная сеть, работающая на базе случайного векторного ввода. В этом примере один из выходов генератора пытается обмануть дискриминатор при выборе «реального» изображения.
Как это нам помогает? Теперь мы можем использовать сообщение об ошибке, основанное исключительно на предсказании дискриминатора: значение от 0 («фальшивый») до 1 («реальный»). Поскольку дискриминатор является нейронной сетью, мы можем делиться его выводами об ошибках и с генератором изображений. То есть, дискриминатор может сообщать генератору, где и как тот должен корректировать свои изображения, чтобы лучше «обмануть» дискриминатор (т.е. — как повысить реалистичность своих изображений).
В процессе обучения по нахождению поддельных изображений дискриминатор дает генератору все лучшую и лучшую обратную связь о том, как последний может улучшить свою работу. Таким образом, дискриминатор выполняет «learn a loss»-функцию для генератора.
Рассматриваемый нами GAN в своей работе следует описанной выше логике. Его дискриминатор анализирует изображение
анализирует изображение  и получает значение
и получает значение  от 0 до 1, которое отражает его степень уверенности в том, реальное это изображение, или же подделанное генератором. Его генератор
от 0 до 1, которое отражает его степень уверенности в том, реальное это изображение, или же подделанное генератором. Его генератор  получает случайный вектор нормально распределенных чисел
получает случайный вектор нормально распределенных чисел  и выводит изображение
и выводит изображение  , которое может обмануть дискриминатор (по факту, это изображение
, которое может обмануть дискриминатор (по факту, это изображение  )
)
Один из вопросов, который мы не обсуждали, — это как обучают GAN и какую функцию потерь используют разработчики для измерения производительности сети. В общем случае функция потерь должна возрастать по мере обучения дискриминатора и понижаться по мере обучения генератора. Функция потерь исходного GAN использовала два следующих параметра. Первый —
представляет степень того, как часто дискриминатор правильно классифицирует реальные изображения как реальные. Второй — насколько хорошо дискриминатор обнаруживает поддельные изображения:
![$\begin{equation*} \mathcal{L}_\text{GAN}(D, G) = \underbrace{E_{\vec{x} \sim p_\text{data}}[\log D(\vec{x})]}_{\text{accuracy on real images}} + \underbrace{E_{\vec{z} \sim \mathcal{N}}[\log (1 - D(G(\vec{z}))]}_{\text{accuracy on fakes}} \end{equation*}$](https://habrastorage.org/getpro/habr/formulas/dc8/27b/167/dc827b167828a36c09058285534cdf8f.svg)
Дискриминатор выводит свое утверждение о том, что изображение реально. Это имеет смысл, так как  возрастает, когда дискриминатор считает x реальным. Когда же дискриминатор лучше выявляет поддельные изображения, увеличивается и значение выражения
возрастает, когда дискриминатор считает x реальным. Когда же дискриминатор лучше выявляет поддельные изображения, увеличивается и значение выражения  (начинает стремиться к 1), так как будет стремиться к 0.
(начинает стремиться к 1), так как будет стремиться к 0.
На практике мы оцениваем точность, используя целые партии изображений. Мы берем много (но далеко не все) реальных изображений и много случайных векторов , чтобы получить усредненные числа по формуле выше. Затем мы выбираем распространенные ошибки и набор данных.
Со временем это приводит к интересным результатам:

Goodfellow GAN, имитирующий наборы данных MNIST, TFD и CIFAR-10. Контурные изображения являются самыми близкими в наборе данных к смежным подделкам.
Все это было фантастикой всего 4,5 года назад. К счастью, как показывает SPADE и другие сети, машинное обучение продолжает быстро прогрессировать.
Генеративно-соревновательные сети печально известны своей сложностью в подготовке и нестабильностью работы. Одна из проблем заключается в том, что если генератор слишком сильно опережает дискриминатор в темпах обучения, то его выборка изображений сужается до конкретно тех, которые помогают ему обмануть дискриминатор. Фактически, в итоге обучение генератора сводится к созданию одного-единственного универсального изображения для обмана дискриминатора. Эта проблема называется «режимом коллапса».

Режим коллапса GAN похож на Goodfellow's. Обратите внимание, многие из этих изображений спальни выглядят очень похожими друг на друга. Источник
Другая проблема заключается в том, что, когда генератор эффективно обманывает дискриминатор , он оперирует очень маленьким градиентом, поэтому
, он оперирует очень маленьким градиентом, поэтому  не может получить достаточно данных для нахождения истинного ответа, при которых это изображение выглядело бы более реалистичным.
не может получить достаточно данных для нахождения истинного ответа, при которых это изображение выглядело бы более реалистичным.
Усилия исследователей по решению этих проблем в основном были направлены на изменение структуры функции потерь. Одним из простых изменений, предложенных Xudong Mao et al., 2016, является замена функции потерь на пару простых функций
на пару простых функций  , в основе которых лежат квадраты меньшей площади. Это приводит к стабилизации процесса тренировки, получению более качественных изображений и меньшему шансу коллапса с использованием незатухающих градиентов.
, в основе которых лежат квадраты меньшей площади. Это приводит к стабилизации процесса тренировки, получению более качественных изображений и меньшему шансу коллапса с использованием незатухающих градиентов.
Другая проблема, с которой столкнулись исследователи, — это сложность получения изображений с высоким разрешением, отчасти из-за того, что более детальное изображение дает дискриминатору больше информации для обнаружения поддельных изображений. Современные GAN начинают обучать сеть с картинок в низком разрешении и постепенно добавляют все больше и больше слоев, пока не будет достигнут желаемый размер изображения.

Постепенное добавление слоев с более высоким разрешением во время обучения GAN существенно повышает стабильность всего процесса, а также скорость и качество получаемого изображения.
До сих пор мы говорили о том, как генерировать изображения из случайных наборов вводных данных. Но SPADE не просто использует случайные данные. Эта сеть использует изображение, которое называется картой сегментации: она назначает каждому пикселю класс материала (например, трава, дерево, вода, камень, небо). Из этого изображения-карты SPADE и генерирует то, что выглядит как фотография. Это и называется «Image-to-image трансляция».
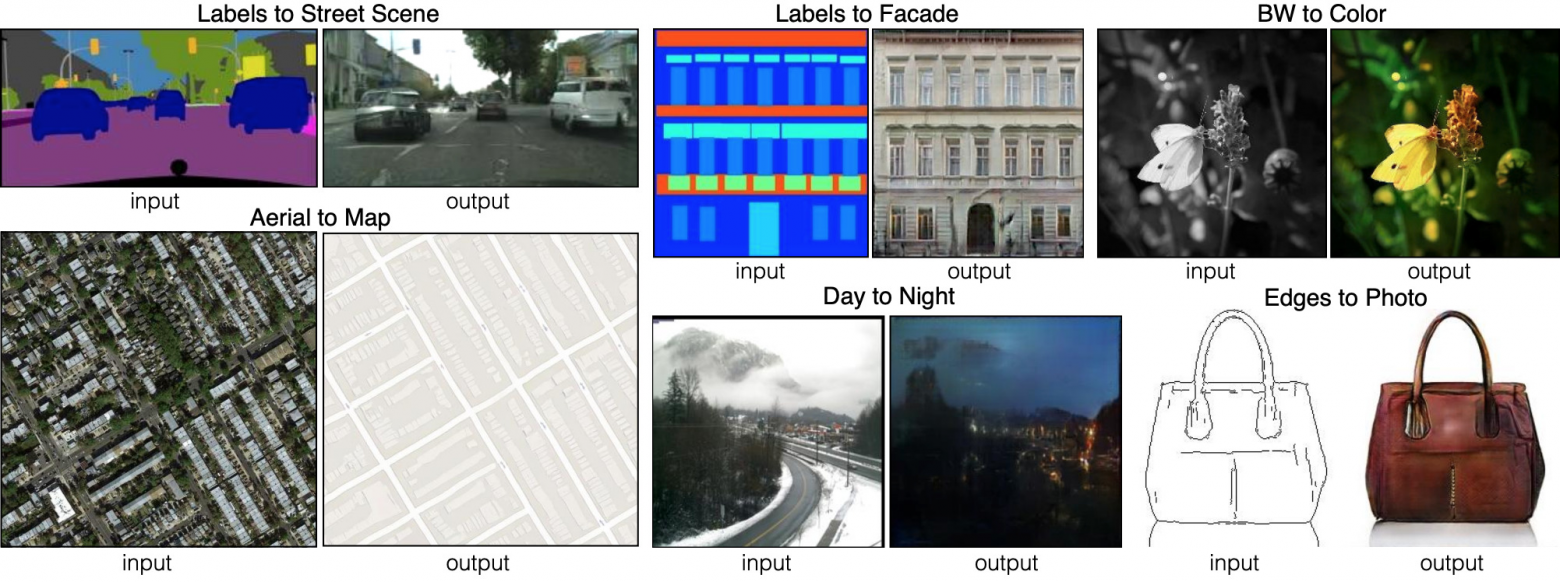
Шесть различных видов Image-to-image трансляции, продемонстрированные сетью pix2pix. Pix2pix является предшественником двух сетей, которые мы рассмотрим далее: pix2pixHD и SPADE.
Для того чтобы генератор выучил этот подход, ему нужен набор карт сегментации и соответствующие фотографии. Мы модифицируем архитектуру GAN, чтобы и генератор, и дискриминатор получили карту сегментации. Генератору, конечно, нужна карта, чтобы знать, «в какую сторону рисовать». Дискриминатору она также необходима, чтобы убедиться, что генератор размещает правильные вещи в правильных местах.
В ходе обучения генератор учится не ставить траву там, где на карте сегментации указано «небо», поскольку в противном случае дискриминатор легко определит поддельное изображение, и так далее.
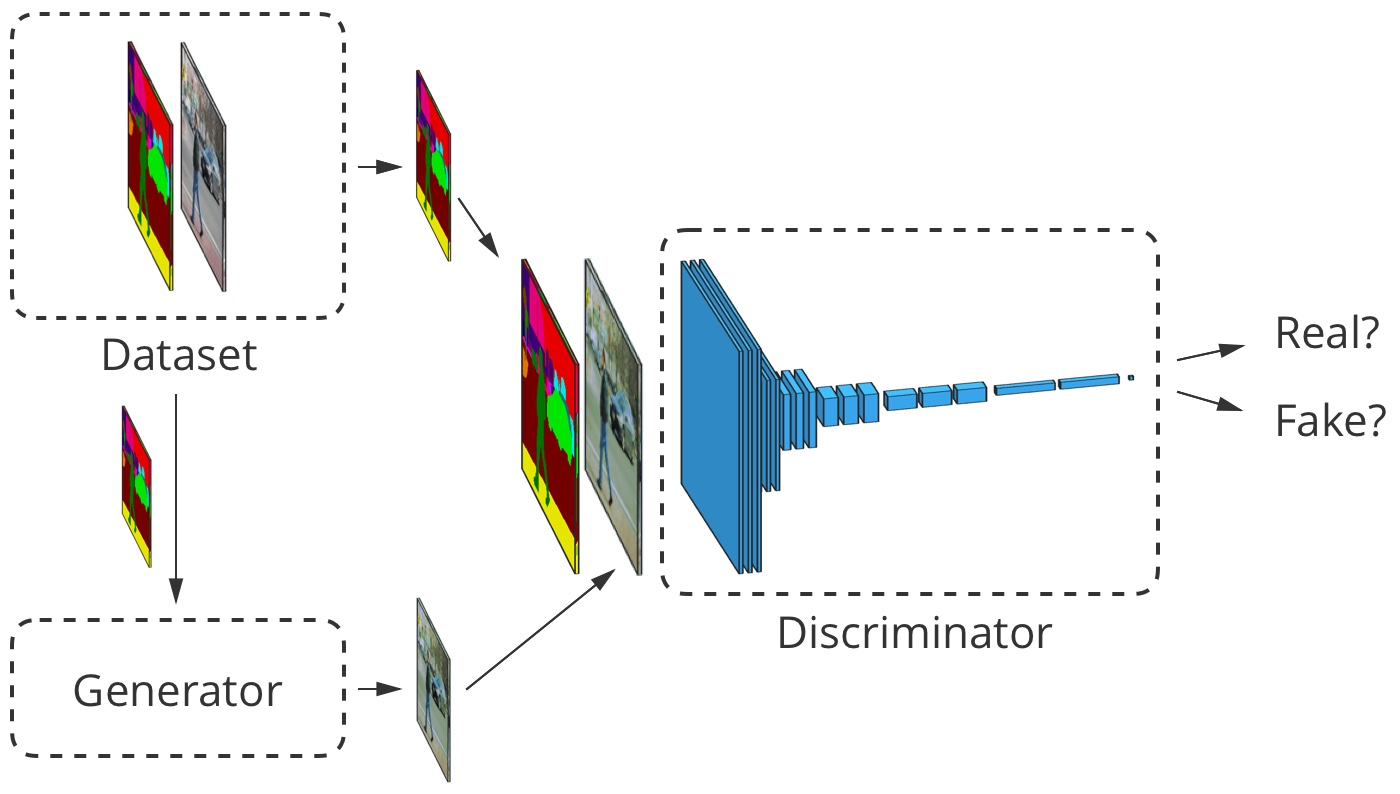
Для image-to-image трансляции входное изображение принимается как генератором, так и дискриминатором. Дискриминатор дополнительно получает либо выходные данные генератора, либо истинный вывод из набора обучающих данных. Пример
Давайте посмотрим на реальный image-to-image транслятор: pix2pixHD. Кстати, SPADE спроектирован большей частью по образу и подобию pix2pixHD.
Для image-to-image транслятора наш генератор создает изображение и принимает его в качестве входного. Мы могли бы просто использовать карту сверточных слоев, но поскольку сверточные слои объединяют значения только в небольших участках, нам нужно слишком много слоев для передачи информации об изображении в высоком разрешении.
pix2pixHD решает эту проблему более эффективно при помощи «Кодировщика», который уменьшает масштаб входного изображения, за которым следует «Декодер», увеличивающий масштаб для получения выходного изображения. Как мы скоро увидим, у SPADE более элегантное решение, не требующее кодировщика.

Схема сети pix2pixHD на «высоком» уровне. «Остаточные» блоки и «+операция» относятся к технологии «skip connections» из Residual neural network. В сети есть скипаемые блоки, которые соотносятся между собой в кодировщике и декодере.
Почти все современные свёрточные нейронные сети используют пакетную нормализацию или один из ее аналогов, чтобы ускорить и стабилизировать процесс тренировки. Активация каждого канала сдвигает среднее к 0 и стандартное отклонение к 1 до того, как пара параметров каналов и
и  позволяют им снова денормализоваться.
позволяют им снова денормализоваться.
![$y = \frac{x - \mathrm{E}[x]}{\sqrt{\mathrm{Var}[x] + \epsilon}} * \gamma + \beta$](https://habrastorage.org/getpro/habr/formulas/f7c/7a7/bf6/f7c7a7bf613467f3379fdd1ba8badbc5.svg)
К сожалению, пакетная нормализация вредит генераторам, затрудняя для сети реализацию некоторых типов обработки изображений. Вместо того чтобы нормализовать партию изображений, pix2pixHD использует эталон нормализации, который нормализует каждое изображение по отдельности.
Современные GAN, такие как pix2pixHD и SPADE, измеряют реалистичность своих выходных изображений немного иначе, чем это было описано для оригинального дизайна генеративно-состязательных сетей.
Для решения проблемы генерации изображений в высоком разрешении pix2pixHD использует три дискриминатора одинаковой структуры, каждый из которых получает выходное изображение в разном масштабе (обычный размер, уменьшенный в 2 раза и уменьшенный в 4 раза).
Для определения своей функции потерь pix2pixHD использует, а также включает в себя другой элемент, предназначенный для того чтобы сделать выводы генератора более реалистичными (независимо от того, помогает ли это обмануть дискриминатор). Этот элемент  называется «сопоставление признаков» — он побуждает генератор сделать распределение слоев при симуляции дискриминации одинаковым между реальными данными и выходами генератора, сводя к минимуму
называется «сопоставление признаков» — он побуждает генератор сделать распределение слоев при симуляции дискриминации одинаковым между реальными данными и выходами генератора, сводя к минимуму  между ними.
между ними.
Так, оптимизация сводится к следующему:
где потери суммируются по трем дискриминационным факторам и коэффициенту , который контролирует приоритет обоих элементов.
, который контролирует приоритет обоих элементов.

pix2pixHD использует карту сегментации, составленную из реальной спальни (слева в каждом примере), чтобы создать поддельную спальню (справа).
Хотя дискриминаторы уменьшают масштаб изображения до тех пор, пока не разберут изображение целиком, они останавливаются на «пятнах» размером 70×70 (в соответствующих масштабах). Затем они просто суммируют все значения этих «пятен» для всего изображения.
И такой подход отлично работает, поскольку функция заботится о том, чтобы изображение реалистично смотрелось в большом разрешении, и требуется только для проверки мелких деталей. Такой подход также имеет дополнительные преимущества в виде ускорения работы сети, уменьшения количества используемых параметров и в возможности ее использования для генерации изображений любого размера.

pix2pixHD генерирует из простых набросков лиц фотореалистичные изображения с соответствующими гримасами. Каждый пример показывает реальное изображение из набора данных CelebA слева, эскиз выражения лица этой знаменитости в виде скетча и созданное из этих данных изображение справа.
Эти результаты невероятны, но мы можем добиться большего. Оказывается, pix2pixHD очень сильно проигрывает в одном важном аспекте.
Рассмотрим, что делает pix2pixHD с одноклассным вводом, скажем, с картой, на которой повсюду трава. Поскольку вход является пространственно однородным, выходы первого сверточного слоя также являются одинаковыми. Затем нормализация экземпляров «нормализует» все (идентичные) значения для каждого канала в изображении и возвращает как вывод для всех них. β-параметр может сдвинуть это значение от нуля, но факт остается фактом: выход больше не будет зависеть от того, была на входе «трава», «небо», «вода» или что-то еще.
как вывод для всех них. β-параметр может сдвинуть это значение от нуля, но факт остается фактом: выход больше не будет зависеть от того, была на входе «трава», «небо», «вода» или что-то еще.

В pix2pixHD нормализация экземпляров имеет тенденцию игнорировать информацию из карты сегментации. Для изображений, состоящих из одного класса, сеть генерирует одно и то же изображение независимо от этого самого класса.
И решение этой проблемы — главная особенность дизайна SPADE.
Наконец-то мы достигли принципиально нового уровня в создании изображений из карт сегментации: пространственно-адаптивная (де)нормализация (SPADE).
Идея SPADE состоит в том, чтобы предотвратить потерю семантической информации в сети, позволяя карте сегментации управлять параметрами нормализации γ, а также β, локально, на уровне каждого отдельного слоя. Вместо того чтобы использовать только одну пару параметров для каждого канала, они вычисляются для каждой пространственной точки путем подачи карты сегментации с пониженной дискретизацией через 2 сверточных слоя.
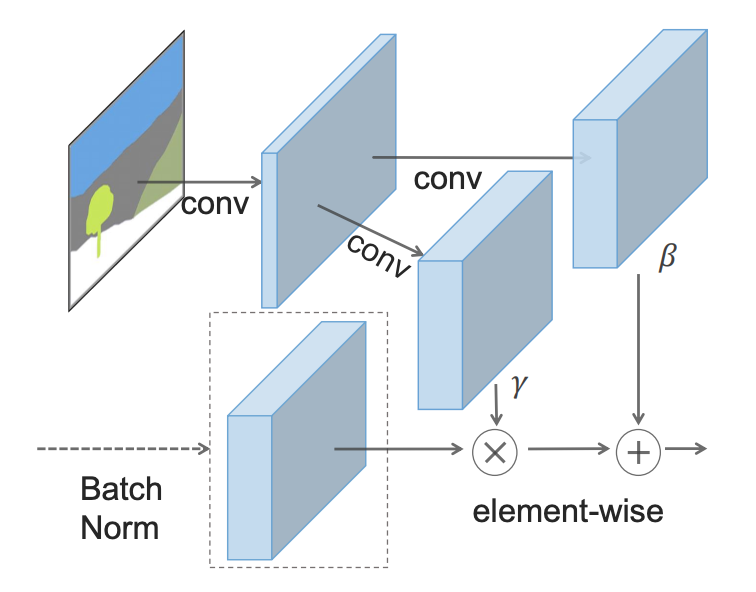
Вместо того чтобы раскатывать карту сегментации на первый слой, SPADE использует ее версии с пониженной дискретизацией для модуляции нормализованных выходных данных для каждого слоя.
Генератор SPADE объединяет всю эту конструкцию в небольшие «остаточные блоки», которые помещаются между слоями повышающей дискретизации (транспонированная свертка):
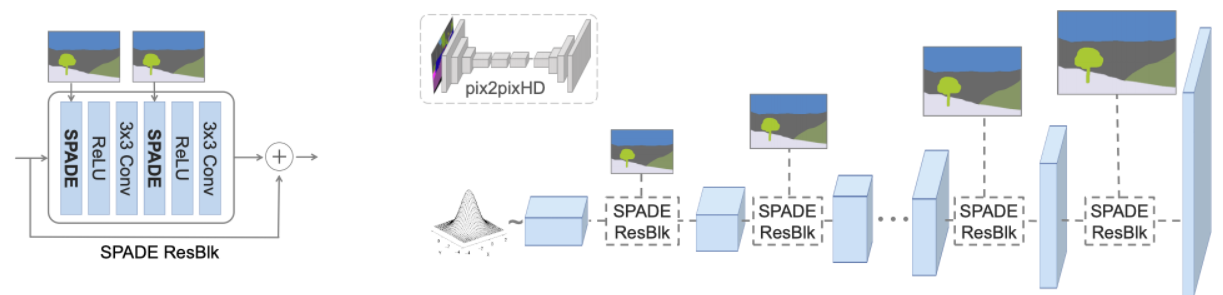
Высокоуровневая схема генератора SPADE в сравнении с генератором pix2pixHD
Теперь, когда карта сегментации подается «изнутри» сети, нет необходимости использовать ее в качестве входных данных для первого слоя. Вместо этого мы можем вернуться к исходной схеме GAN, в которой в качестве входных данных использовался случайный вектор. Это дает нам дополнительную возможность генерировать различные изображения из одной карты сегментации («мультимодальный синтез»). Это также делает ненужным весь «кодировщик» pix2pixHD, а это серьезное упрощение.
SPADE использует ту же функцию потерь, что и pix2pixHD, но с одним изменением: вместо возведения в квадрат значений в ней используется hinge loss.
С этими изменениями мы получаем прекрасные результаты:

Здесь результаты SPADE сравниваются с результатами pix2pixHD
Давайте подумаем о том, как SPADE может показывать такие результаты. В приведенном ниже примере у нас есть дерево. GauGAN использует один «древовидный» класс для представления как ствола, так и листьев дерева. Тем не менее, каким-то образом SPADE узнает, что узкая часть в нижней части «дерева» является стволом и должна быть коричневой, в то время как большая капля сверху должна быть листвой.
Сегментация с пониженной дискретизацией, которую использует SPADE для модуляции каждого слоя, и обеспечивает подобное «интуитивное» распознавание.
Вы можете заметить, что ствол дерева продолжается и в части кроны, которая относится к «листве». Так как же SPADE понимает, где разместить там часть ствола, а где листву? Ведь судя по карте 5х5, там должно быть просто «дерево».
Ответ заключается в том, что показанный участок может получать информацию от слоев с более низким разрешением, где блок 5x5 содержит все дерево целиком. Каждый последующий сверточный слой также обеспечивает некоторое перемещение информации по изображению, что дает более полную картину.
SPADE позволяет карте сегментации напрямую модулировать каждый слой, но это не препятствует процессу связного распространения информации между слоями, как это происходит, например, в pix2pixHD. Это предотвращает потерю семантической информации, поскольку она обновляется в каждом последующем слое за счет предыдущего.
В SPADE есть еще одно волшебное решение — способность генерировать изображение в заданном стиле (например, освещение, погодные условия, время года).

SPADE может генерировать несколько разных изображений на базе одной карты сегментации, мимикрируя под заданный стиль.
Это работает следующим образом: мы пропускаем изображения через кодировщик и обучаем его, чтобы задать векторы генератора, который в свою очередь сгенерирует похожие изображения. После того как кодировщик обучен, мы заменяем соответствующие карты сегментации на произвольные, и генератор SPADE создает изображения, соответствующие новым картам, но в стиле предоставленных изображений на базе ранее полученного обучения.
Поскольку генератор обычно ожидает получить выборку на базе многомерного нормального распределения, то для получения реалистичных изображений мы должны обучить кодировщик выводить значения с аналогичным распределением. Фактически, это идея вариационных автокодировщиков, которую объясняет Йоэль Зельдес.
Вот так функционирует SPADE / GaiGAN. Я надеюсь, эта статья удовлетворила ваше любопытство на тему того, как работает новая система NVIDIA. Связаться со мной вы можете через Twitter @AdamDanielKin или по электронной почте adam@AdamDKing.com.
Приложение построено на технологии генеративно-состязательных сетей (GAN), в основе которой лежит глубинное обучение. Сама NVIDIA называет его GauGAN — это каламбур-отсылка к художнику Полу Гогену. В основе функциональности GauGAN лежит новый алгоритм SPADE.
В этой статье я объясню, как работает этот инженерный шедевр. И чтобы привлечь как можно больше заинтересованных читателей, я постараюсь дать детализированное описание того, как работают свёрточные нейронные сети. Поскольку SPADE — это генеративно-состязательная сеть, я расскажу подробнее и о них. Но если вы уже знакомы с эти термином, вы можете сразу перейти к разделу «Image-to-image трансляция».
Генерация изображений
Давайте начнем разбираться: в большинстве современных приложений глубинного обучения используется нейронный дискриминантный тип (дискриминатор), а SPADE — это генеративная нейронная сеть (генератор).
Дискриминаторы
Дискриминатор занимается классификацией вводимых данных. Например, классификатор изображения — это дискриминатор, который берет изображение и выбирает одну подходящую метку класса, например, определяет изображение как «собаку», «автомобиль» или «светофор», то есть выбирает метку, которая целиком описывает изображение. Полученный классификатором вывод обычно представлен в виде вектора чисел
, где — это число от 0 до 1, выражающее уверенность сети в принадлежности изображения к выбранному -классу.Дискриминатор также может составить целый список классификаций. Он может классифицировать каждый пиксель изображения как принадлежащий классу «людей» или «машин» (так называемая «семантическая сегментация»).

Классификатор берет изображение с 3 каналами (красный, зеленый и синий) и сопоставляет его с вектором уверенности в каждом возможном классе, который может представлять изображение.
Поскольку связь между изображением и его классом очень сложна, нейронные сети пропускают его через стек из множества слоев, каждый из которых «немного» обрабатывает его и передает свой вывод на следующий уровень интерпретации.
Генераторы
Генеративная сеть наподобие SPADE получает набор данных и стремится создавать новые оригинальные данные, которые выглядят так, как будто они принадлежат этому классу данных. При этом данные могут быть любыми: звуками, языком или чем-то еще, но мы сосредоточимся на изображениях. В общем случае ввод данных в такую сеть представляет собой просто вектор случайных чисел, причем каждый из возможных наборов вводимых данных создает свое изображение.
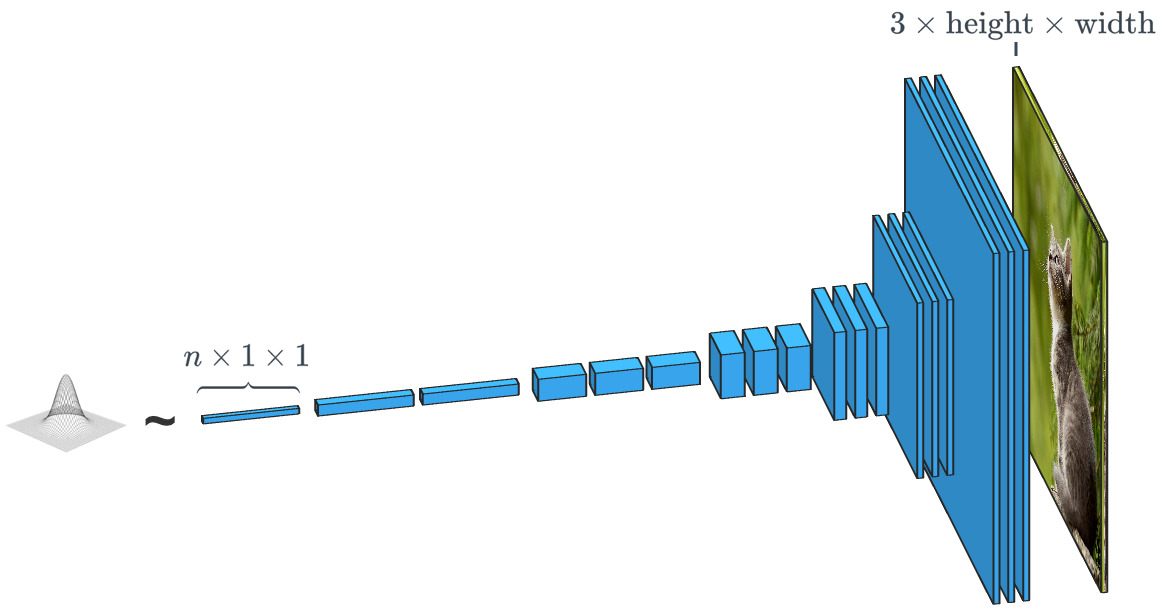
Генератор на основе случайного входного вектора работает фактически противоположно классификатору изображения. В генераторах «условных классов» входной вектор — это, фактически, вектор целого класса данных.
Как мы уже видели, SPADE использует намного больше, чем просто «случайный вектор». Система руководствуется своеобразным чертежом, который называется «картой сегментации». Последняя указывает, что и где размещать. SPADE проводит процесс, обратный семантической сегментации, упомянутой нами выше. В целом, дискриминационная задача, переводящая один тип данных в другой, имеет аналогичную задачу, но идет другим, непривычным путем.
Современные генераторы и дискриминаторы обычно используют сверточные сети для обработки своих данных. Для более полного ознакомления со сверточным нейронным сетям (CNNs), см. пост Ужвал Карна или работу Андрея Карпати.
Между классификатором и генератором изображения есть одно важное различие, и заключается оно в том, как именно они изменяют размер изображения в ходе его обработки. Классификатор изображения должен уменьшать его до тех пор, пока изображение не потеряет всю пространственную информацию и не останутся только классы. Это может быть достигнуто объединением слоев, либо через использование сверточных сетей, через которые пропускают отдельные пиксели. Генератор же создает изображение с помощью процесса, обратного «свертке», который называется сверточным транспонированием. Его еще часто путают с «деконволюцией» или «обратной сверткой».
Обычная свертка 2x2 с шагом «2» превращает каждый блок 2x2 в одну точку, уменьшая выходные размеры на 1/2.
Транспонированная свертка 2x2 с шагом «2» генерирует блок 2x2 из каждой точки, увеличивая выходные размеры в 2 раза.
Тренировка генератора
Теоретически, сверточная нейронная сеть cможет генерировать изображения описанным выше образом. Но как мы мы ее натренируем? То есть, если учитывать набор входных данных-изображений, как мы можем настроить параметры генератора (в нашем случае SPADE), чтобы он создавал новые изображения, которые выглядят так, как будто они соответствуют предложенному набору данных?
Для этого нужно проводить сравнение с классификаторами изображений, где каждое из них имеет правильную метку класса. Зная вектор предсказания сети и правильный класс, мы можем использовать алгоритм обратного распространения (backpropagation algorithm), чтобы определить параметры обновления сети. Это нужно, чтобы повысить ее точность в определении нужного класса и уменьшить влияние остальных классов.
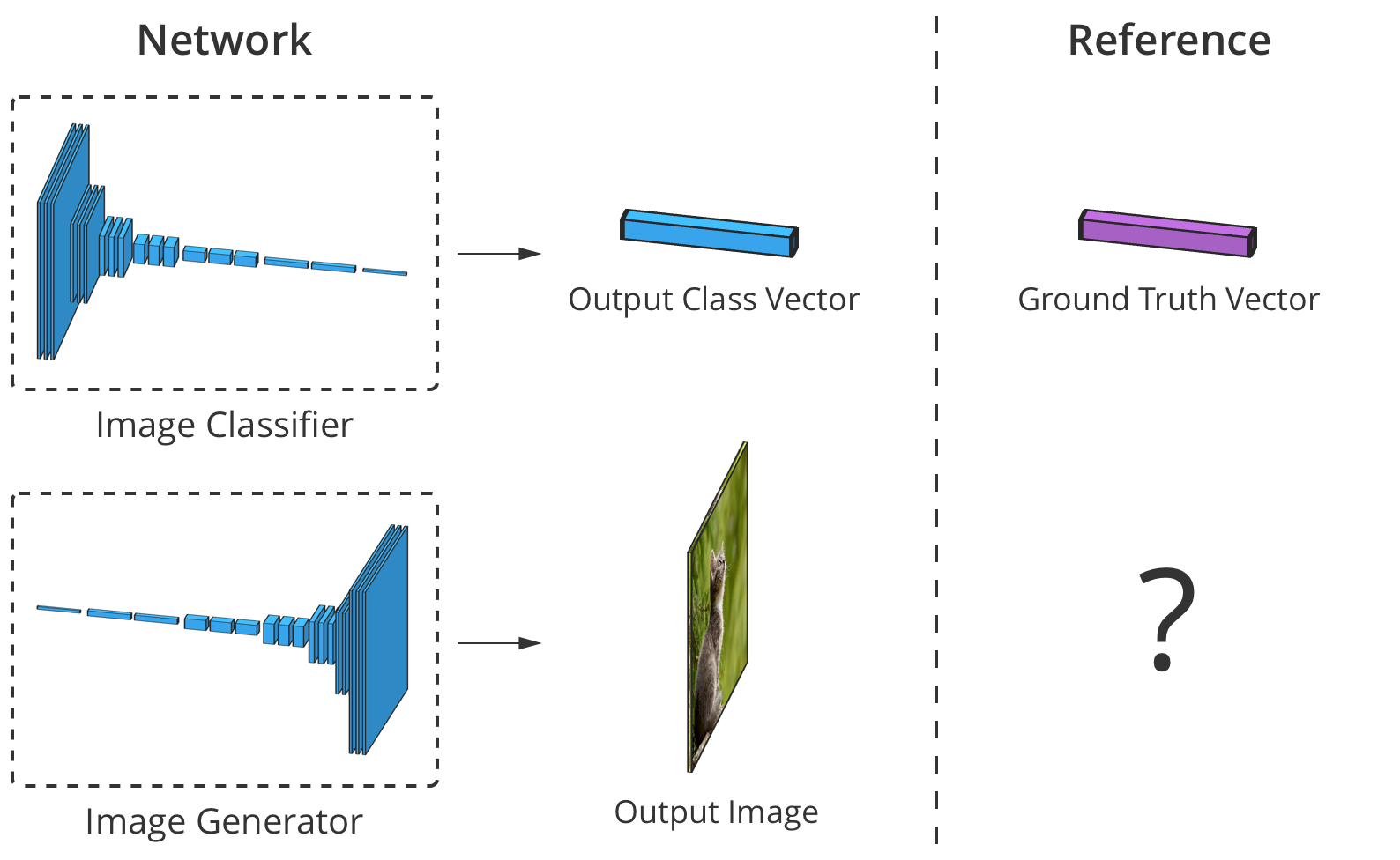
Точность классификатора изображения можно оценить, поэлементно сравнив его вывод с правильным вектором класса. Но для генераторов не существует «правильного» выходного изображения.
Проблема в том, что когда генератор создает изображение, для каждого пикселя нет «правильных» значений (мы не можем сравнить результат, как в случае классификатора по заранее подготовленной базе, — прим. пер.). Теоретически, любое изображение, которое выглядит правдоподобно и похоже на целевые данные, является действительным, даже если его значения пикселей сильно отличаются от реальных изображений.
Итак, как мы можем сообщить генератору, в каких пикселях он должен изменять свой вывод и каким образом он может создавать более реалистичные изображения (т.е. как подавать «сигнал об ошибке»)? Исследователи много размышляли над этим вопросом, и на самом деле это довольно сложно. Большинство идей, таких как вычисление некоторого среднего «расстояния» до реальных изображений, дают размытые картинки низкого качества.
В идеале мы могли бы «измерить», насколько реалистично выглядят сгенерированные изображения через использование концепции «высокого уровня», такой как «Насколько сложно это изображение отличить от реального?»…
Генеративные состязательные сети
Именно это реализовали в рамках работы Goodfellow et al., 2014. Идея состоит в том, чтобы генерировать изображения, используя две нейронные сети вместо одной: одна сеть —
генератор, вторая — классификатор изображений (дискриминатор). Задача дискриминатора состоит в том, чтобы отличать выходные изображения генератора от реальных изображений из первичного набора данных (классы этих изображений обозначены как «поддельные» и «реальные»). Работа же генератора заключается в том, чтобы обмануть дискриминатор, создавая изображения, максимально похожие на изображения в наборе данных. Можно сказать, что генератор и дискриминатор являются противниками в этом процессе. Отсюда и название: генеративно-состязательная сеть.
Генеративно-состязательная сеть, работающая на базе случайного векторного ввода. В этом примере один из выходов генератора пытается обмануть дискриминатор при выборе «реального» изображения.
Как это нам помогает? Теперь мы можем использовать сообщение об ошибке, основанное исключительно на предсказании дискриминатора: значение от 0 («фальшивый») до 1 («реальный»). Поскольку дискриминатор является нейронной сетью, мы можем делиться его выводами об ошибках и с генератором изображений. То есть, дискриминатор может сообщать генератору, где и как тот должен корректировать свои изображения, чтобы лучше «обмануть» дискриминатор (т.е. — как повысить реалистичность своих изображений).
В процессе обучения по нахождению поддельных изображений дискриминатор дает генератору все лучшую и лучшую обратную связь о том, как последний может улучшить свою работу. Таким образом, дискриминатор выполняет «learn a loss»-функцию для генератора.
«Славный малый» GAN
Рассматриваемый нами GAN в своей работе следует описанной выше логике. Его дискриминатор
анализирует изображение и получает значение от 0 до 1, которое отражает его степень уверенности в том, реальное это изображение, или же подделанное генератором. Его генератор получает случайный вектор нормально распределенных чисел и выводит изображение , которое может обмануть дискриминатор (по факту, это изображение )Один из вопросов, который мы не обсуждали, — это как обучают GAN и какую функцию потерь используют разработчики для измерения производительности сети. В общем случае функция потерь должна возрастать по мере обучения дискриминатора и понижаться по мере обучения генератора. Функция потерь исходного GAN использовала два следующих параметра. Первый —
представляет степень того, как часто дискриминатор правильно классифицирует реальные изображения как реальные. Второй — насколько хорошо дискриминатор обнаруживает поддельные изображения:
Дискриминатор
выводит свое утверждение о том, что изображение реально. Это имеет смысл, так как возрастает, когда дискриминатор считает x реальным. Когда же дискриминатор лучше выявляет поддельные изображения, увеличивается и значение выражения (начинает стремиться к 1), так как будет стремиться к 0. На практике мы оцениваем точность, используя целые партии изображений. Мы берем много (но далеко не все) реальных изображений
и много случайных векторов , чтобы получить усредненные числа по формуле выше. Затем мы выбираем распространенные ошибки и набор данных. Со временем это приводит к интересным результатам:

Goodfellow GAN, имитирующий наборы данных MNIST, TFD и CIFAR-10. Контурные изображения являются самыми близкими в наборе данных к смежным подделкам.
Все это было фантастикой всего 4,5 года назад. К счастью, как показывает SPADE и другие сети, машинное обучение продолжает быстро прогрессировать.
Проблемы тренировки
Генеративно-соревновательные сети печально известны своей сложностью в подготовке и нестабильностью работы. Одна из проблем заключается в том, что если генератор слишком сильно опережает дискриминатор в темпах обучения, то его выборка изображений сужается до конкретно тех, которые помогают ему обмануть дискриминатор. Фактически, в итоге обучение генератора сводится к созданию одного-единственного универсального изображения для обмана дискриминатора. Эта проблема называется «режимом коллапса».

Режим коллапса GAN похож на Goodfellow's. Обратите внимание, многие из этих изображений спальни выглядят очень похожими друг на друга. Источник
Другая проблема заключается в том, что, когда генератор эффективно обманывает дискриминатор
, он оперирует очень маленьким градиентом, поэтому не может получить достаточно данных для нахождения истинного ответа, при которых это изображение выглядело бы более реалистичным.Усилия исследователей по решению этих проблем в основном были направлены на изменение структуры функции потерь. Одним из простых изменений, предложенных Xudong Mao et al., 2016, является замена функции потерь
на пару простых функций , в основе которых лежат квадраты меньшей площади. Это приводит к стабилизации процесса тренировки, получению более качественных изображений и меньшему шансу коллапса с использованием незатухающих градиентов.Другая проблема, с которой столкнулись исследователи, — это сложность получения изображений с высоким разрешением, отчасти из-за того, что более детальное изображение дает дискриминатору больше информации для обнаружения поддельных изображений. Современные GAN начинают обучать сеть с картинок в низком разрешении и постепенно добавляют все больше и больше слоев, пока не будет достигнут желаемый размер изображения.
Постепенное добавление слоев с более высоким разрешением во время обучения GAN существенно повышает стабильность всего процесса, а также скорость и качество получаемого изображения.
Image-to-image трансляция
До сих пор мы говорили о том, как генерировать изображения из случайных наборов вводных данных. Но SPADE не просто использует случайные данные. Эта сеть использует изображение, которое называется картой сегментации: она назначает каждому пикселю класс материала (например, трава, дерево, вода, камень, небо). Из этого изображения-карты SPADE и генерирует то, что выглядит как фотография. Это и называется «Image-to-image трансляция».
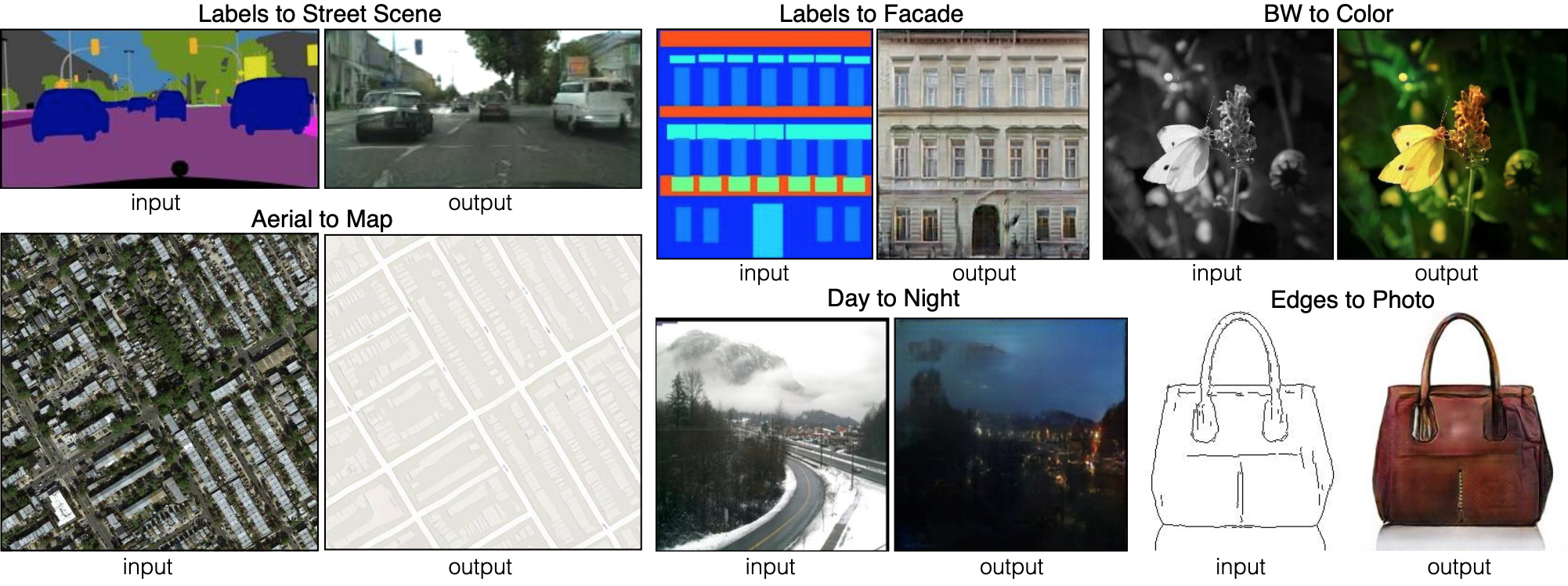
Шесть различных видов Image-to-image трансляции, продемонстрированные сетью pix2pix. Pix2pix является предшественником двух сетей, которые мы рассмотрим далее: pix2pixHD и SPADE.
Для того чтобы генератор выучил этот подход, ему нужен набор карт сегментации и соответствующие фотографии. Мы модифицируем архитектуру GAN, чтобы и генератор, и дискриминатор получили карту сегментации. Генератору, конечно, нужна карта, чтобы знать, «в какую сторону рисовать». Дискриминатору она также необходима, чтобы убедиться, что генератор размещает правильные вещи в правильных местах.
В ходе обучения генератор учится не ставить траву там, где на карте сегментации указано «небо», поскольку в противном случае дискриминатор легко определит поддельное изображение, и так далее.
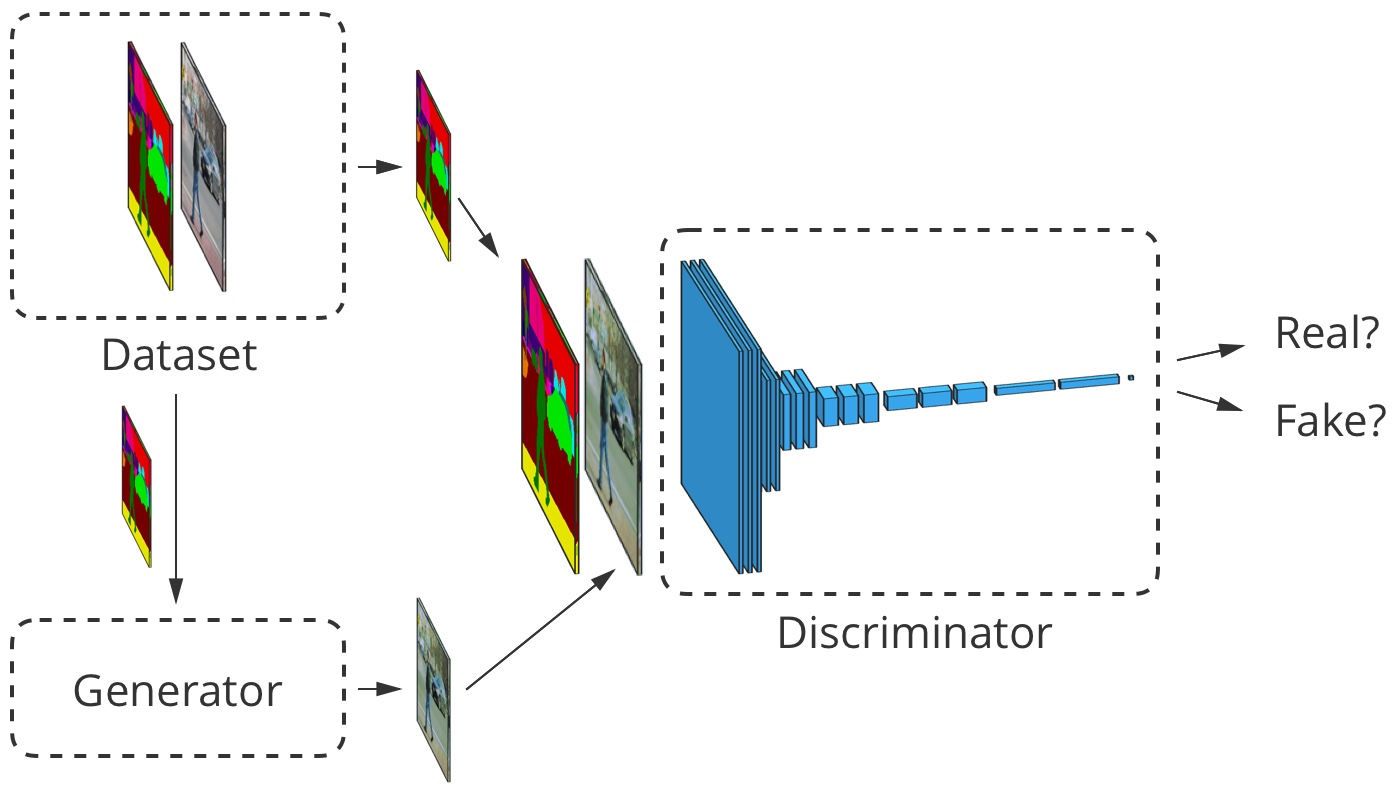
Для image-to-image трансляции входное изображение принимается как генератором, так и дискриминатором. Дискриминатор дополнительно получает либо выходные данные генератора, либо истинный вывод из набора обучающих данных. Пример
Разработка image-to-image транслятора
Давайте посмотрим на реальный image-to-image транслятор: pix2pixHD. Кстати, SPADE спроектирован большей частью по образу и подобию pix2pixHD.
Для image-to-image транслятора наш генератор создает изображение и принимает его в качестве входного. Мы могли бы просто использовать карту сверточных слоев, но поскольку сверточные слои объединяют значения только в небольших участках, нам нужно слишком много слоев для передачи информации об изображении в высоком разрешении.
pix2pixHD решает эту проблему более эффективно при помощи «Кодировщика», который уменьшает масштаб входного изображения, за которым следует «Декодер», увеличивающий масштаб для получения выходного изображения. Как мы скоро увидим, у SPADE более элегантное решение, не требующее кодировщика.

Схема сети pix2pixHD на «высоком» уровне. «Остаточные» блоки и «+операция» относятся к технологии «skip connections» из Residual neural network. В сети есть скипаемые блоки, которые соотносятся между собой в кодировщике и декодере.
Пакетная нормализация — это проблема
Почти все современные свёрточные нейронные сети используют пакетную нормализацию или один из ее аналогов, чтобы ускорить и стабилизировать процесс тренировки. Активация каждого канала сдвигает среднее к 0 и стандартное отклонение к 1 до того, как пара параметров каналов
и позволяют им снова денормализоваться.К сожалению, пакетная нормализация вредит генераторам, затрудняя для сети реализацию некоторых типов обработки изображений. Вместо того чтобы нормализовать партию изображений, pix2pixHD использует эталон нормализации, который нормализует каждое изображение по отдельности.
Обучение pix2pixHD
Современные GAN, такие как pix2pixHD и SPADE, измеряют реалистичность своих выходных изображений немного иначе, чем это было описано для оригинального дизайна генеративно-состязательных сетей.
Для решения проблемы генерации изображений в высоком разрешении pix2pixHD использует три дискриминатора одинаковой структуры, каждый из которых получает выходное изображение в разном масштабе (обычный размер, уменьшенный в 2 раза и уменьшенный в 4 раза).
Для определения своей функции потерь pix2pixHD использует
, а также включает в себя другой элемент, предназначенный для того чтобы сделать выводы генератора более реалистичными (независимо от того, помогает ли это обмануть дискриминатор). Этот элемент называется «сопоставление признаков» — он побуждает генератор сделать распределение слоев при симуляции дискриминации одинаковым между реальными данными и выходами генератора, сводя к минимуму между ними.Так, оптимизация сводится к следующему:

где потери суммируются по трем дискриминационным факторам и коэффициенту
, который контролирует приоритет обоих элементов. 
pix2pixHD использует карту сегментации, составленную из реальной спальни (слева в каждом примере), чтобы создать поддельную спальню (справа).
Хотя дискриминаторы уменьшают масштаб изображения до тех пор, пока не разберут изображение целиком, они останавливаются на «пятнах» размером 70×70 (в соответствующих масштабах). Затем они просто суммируют все значения этих «пятен» для всего изображения.
И такой подход отлично работает, поскольку функция
заботится о том, чтобы изображение реалистично смотрелось в большом разрешении, и требуется только для проверки мелких деталей. Такой подход также имеет дополнительные преимущества в виде ускорения работы сети, уменьшения количества используемых параметров и в возможности ее использования для генерации изображений любого размера.
pix2pixHD генерирует из простых набросков лиц фотореалистичные изображения с соответствующими гримасами. Каждый пример показывает реальное изображение из набора данных CelebA слева, эскиз выражения лица этой знаменитости в виде скетча и созданное из этих данных изображение справа.
Что не так с pix2pixHD?
Эти результаты невероятны, но мы можем добиться большего. Оказывается, pix2pixHD очень сильно проигрывает в одном важном аспекте.
Рассмотрим, что делает pix2pixHD с одноклассным вводом, скажем, с картой, на которой повсюду трава. Поскольку вход является пространственно однородным, выходы первого сверточного слоя также являются одинаковыми. Затем нормализация экземпляров «нормализует» все (идентичные) значения для каждого канала в изображении и возвращает
как вывод для всех них. β-параметр может сдвинуть это значение от нуля, но факт остается фактом: выход больше не будет зависеть от того, была на входе «трава», «небо», «вода» или что-то еще.
В pix2pixHD нормализация экземпляров имеет тенденцию игнорировать информацию из карты сегментации. Для изображений, состоящих из одного класса, сеть генерирует одно и то же изображение независимо от этого самого класса.
И решение этой проблемы — главная особенность дизайна SPADE.
Решение: SPADE
Наконец-то мы достигли принципиально нового уровня в создании изображений из карт сегментации: пространственно-адаптивная (де)нормализация (SPADE).
Идея SPADE состоит в том, чтобы предотвратить потерю семантической информации в сети, позволяя карте сегментации управлять параметрами нормализации γ, а также β, локально, на уровне каждого отдельного слоя. Вместо того чтобы использовать только одну пару параметров для каждого канала, они вычисляются для каждой пространственной точки путем подачи карты сегментации с пониженной дискретизацией через 2 сверточных слоя.
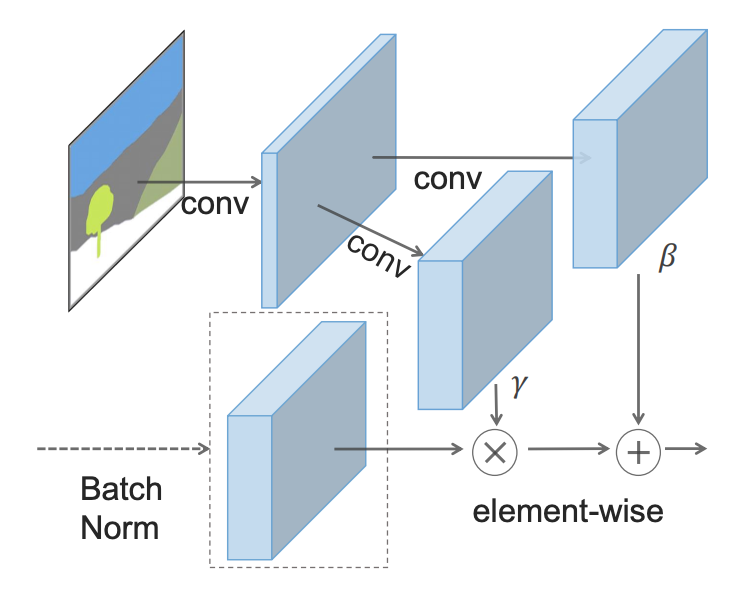
Вместо того чтобы раскатывать карту сегментации на первый слой, SPADE использует ее версии с пониженной дискретизацией для модуляции нормализованных выходных данных для каждого слоя.
Генератор SPADE объединяет всю эту конструкцию в небольшие «остаточные блоки», которые помещаются между слоями повышающей дискретизации (транспонированная свертка):

Высокоуровневая схема генератора SPADE в сравнении с генератором pix2pixHD
Теперь, когда карта сегментации подается «изнутри» сети, нет необходимости использовать ее в качестве входных данных для первого слоя. Вместо этого мы можем вернуться к исходной схеме GAN, в которой в качестве входных данных использовался случайный вектор. Это дает нам дополнительную возможность генерировать различные изображения из одной карты сегментации («мультимодальный синтез»). Это также делает ненужным весь «кодировщик» pix2pixHD, а это серьезное упрощение.
SPADE использует ту же функцию потерь, что и pix2pixHD, но с одним изменением: вместо возведения в квадрат значений
в ней используется hinge loss.С этими изменениями мы получаем прекрасные результаты:

Здесь результаты SPADE сравниваются с результатами pix2pixHD
Интуиция
Давайте подумаем о том, как SPADE может показывать такие результаты. В приведенном ниже примере у нас есть дерево. GauGAN использует один «древовидный» класс для представления как ствола, так и листьев дерева. Тем не менее, каким-то образом SPADE узнает, что узкая часть в нижней части «дерева» является стволом и должна быть коричневой, в то время как большая капля сверху должна быть листвой.
Сегментация с пониженной дискретизацией, которую использует SPADE для модуляции каждого слоя, и обеспечивает подобное «интуитивное» распознавание.
Вы можете заметить, что ствол дерева продолжается и в части кроны, которая относится к «листве». Так как же SPADE понимает, где разместить там часть ствола, а где листву? Ведь судя по карте 5х5, там должно быть просто «дерево».
Ответ заключается в том, что показанный участок может получать информацию от слоев с более низким разрешением, где блок 5x5 содержит все дерево целиком. Каждый последующий сверточный слой также обеспечивает некоторое перемещение информации по изображению, что дает более полную картину.
SPADE позволяет карте сегментации напрямую модулировать каждый слой, но это не препятствует процессу связного распространения информации между слоями, как это происходит, например, в pix2pixHD. Это предотвращает потерю семантической информации, поскольку она обновляется в каждом последующем слое за счет предыдущего.
Стиль передачи
В SPADE есть еще одно волшебное решение — способность генерировать изображение в заданном стиле (например, освещение, погодные условия, время года).

SPADE может генерировать несколько разных изображений на базе одной карты сегментации, мимикрируя под заданный стиль.
Это работает следующим образом: мы пропускаем изображения через кодировщик и обучаем его, чтобы задать векторы генератора
, который в свою очередь сгенерирует похожие изображения. После того как кодировщик обучен, мы заменяем соответствующие карты сегментации на произвольные, и генератор SPADE создает изображения, соответствующие новым картам, но в стиле предоставленных изображений на базе ранее полученного обучения. Поскольку генератор обычно ожидает получить выборку на базе многомерного нормального распределения, то для получения реалистичных изображений мы должны обучить кодировщик выводить значения с аналогичным распределением. Фактически, это идея вариационных автокодировщиков, которую объясняет Йоэль Зельдес.
Вот так функционирует SPADE / GaiGAN. Я надеюсь, эта статья удовлетворила ваше любопытство на тему того, как работает новая система NVIDIA. Связаться со мной вы можете через Twitter @AdamDanielKin или по электронной почте adam@AdamDKing.com.
