Иногда для того, чтобы решить какую-то проблему, надо просто взглянуть на нее под другим углом. Даже если последние лет 10 подобные проблемы решали одним и тем же способом с разным эффектом, не факт, что этот способ единственный.
Есть такая тема, как отток клиентов. Штука неизбежная, потому что клиенты любой компании могут по множеству причин взять и перестать пользоваться ее продуктами или сервисами. Само собой, для компании отток — хоть и естественное, но не самое желаемое действие, поэтому все стараются этот отток минимизировать. А еще лучше — предсказывать вероятность оттока той или иной категории пользователей, или конкретного пользователя, и предлагать какие-то шаги по удержанию.
Анализировать и пытаться удержать клиента, если это возможно, нужно, как минимум, по следующим причинам:
Существуют стандартные подходы к прогнозированию оттока. Но на одном из чемпионатов по ИИ мы решили взять и попробовать для этого распределение Вейбулла. Чаще всего его используют для анализа выживаемости, прогнозирования погоды, анализа стихийных бедствий, в промышленной инженерии и подобном. Распределение Вейбулла — специальная функция распределения, параметризуемая двумя параметрами и
и  .
.
Википедия
В общем, вещь занятная, но для прогнозирования оттока, да и вообще в финтехе, использующаяся не так, чтобы часто. Под катом расскажем, как мы (Лаборатория интеллектуального анализа данных) это сделали, попутно завоевав золото на Чемпионате по искусственному интеллекту в номинации «AI в банках».
Давайте немного разберемся, что такое отток клиента и почему он так важен. Для бизнеса важна клиентская база. В эту базу приходят новые клиенты, например, узнав о продукте или услуге из рекламы, какое-то время живут (активно пользуются продуктами ) и через какое-то время перестают пользоваться. Такой период называют «Жизненный цикл клиента» (англ. Customer Lifecycle) — это термин, описывающий этапы, которые проходит клиент, когда узнает о продукте, принимает решение о покупке, платит, использует и становится лояльным потребителем, и в конечном счете перестает пользоваться по тем или иным причинам продуктами. Соответственно отток — это завершающая стадия жизненного цикла клиента, когда клиент перестает пользоваться услугами, а для бизнеса это означает, что клиент перестал приносить прибыль и вообще какую-либо пользу.
Каждый клиент банка — это конкретный человек, который выбирает ту или иную банковскую карту специально под свои нужды. Часто путешествует — пригодится карта с милями. Много покупает — привет, карта с кэшбеком. Много покупает в конкретных магазинах — и для этого уже есть специальный партнерский пластик. Конечно, иногда карта выбирается и по критерию «Самое дешевое обслуживание». В общем, переменных тут хватает.
А еще человек выбирает сам банк — смысл выбирать карту банка, отделения которого есть только в Москве и области, когда ты из Хабаровска? Будь карта такого банка хоть в 2 раза выгоднее, наличие отделений банка поблизости все еще является важным критерием. Да, 2019 уже здесь и digital — наше все, но ряд вопросов у некоторых банков можно решить только в отделении. Плюс, опять же, какая-то часть населения куда больше доверяет физическому банку, а не приложению в смартфоне, это тоже надо учитывать.
Как следствие, причин для отказа от продуктов банка (или от самого банка) у человека может быть множество. Сменил работу, и тариф карты сменился с зарплатного на «Для простых смертных», который менее выгоден. Переехал в другой город, где нет отделений банка. Не понравилось общение с неквалифицированным операционистом в отделении. То есть причин для закрытия счета может быть даже сильно побольше, чем для использования продукта.
А еще клиент может не просто явно выразить свое намерение — прийти в банк и написать заявление, а просто перестать пользоваться продуктами, не разрывая договор. Вот для понимания подобных задач и решено было использовать машинное обучение и ИИ.
Более того, отток клиентов может происходить в любой отрасли (телеком, интернет-провайдеры, страховые компании, в общем, везде, где есть клиентская база и периодические транзакции).
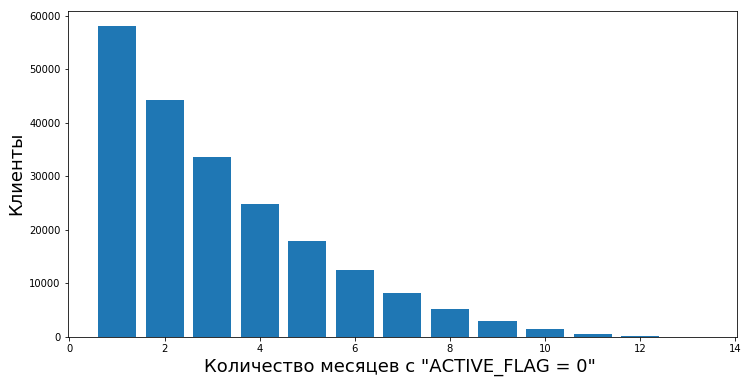
Прежде всего, надо было описать четкую границу — с какого времени мы начинаем считать клиента ушедшим. С точки зрения банка, предоставившего нам данные для работы, состояние активности клиента было бинарным — он или активен, или нет. Был флаг ACTIVE_FLAG в таблице «Активность», значением которого могло быть либо «0», либо «1» (соответственно, «Неактивен» и «Активен»). И все бы хорошо, но человек таков, что может какое-то время активно пользоваться, а потом на месяц выпасть из числа активных — заболел, уехал в другую страну отдыхать, или вообще пошел тестировать карту другого банка. А может после долгого периода неактивности снова начать пользоваться услугами банка
Поэтому мы решили называть периодом неактивности определенный непрерывный промежуток времени, в течение которого флаг для него устанавливался как «0».
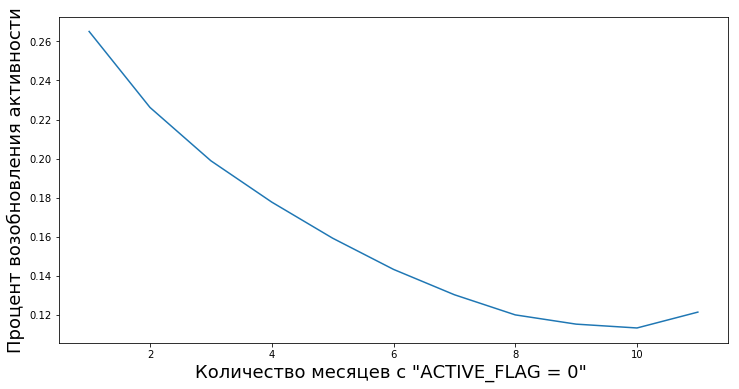
Клиенты переходят из неактивных в активные после периодов неактивности различной длины. У нас появляется возможность рассчитать степень эмпирической величины «надежность периодов неактивности» — то есть вероятность того, что человек снова начнет пользоваться продуктами банка после временной неактивности.
К примеру, вот на этом графике отображено возобновление активности (ACTIVE_FLAG=1) клиентов спустя несколько месяцев неактивности (ACTIVE_FLAG=0).
Здесь мы немного уточним тот набор данных, с которыми мы начали работать. Итак, банк предоставил агрегированную информацию за 19 месяцев в следующих таблицах:
Для работы нам потребовались все таблицы, кроме «Карты».
Сложность тут была вот еще в чем — в этих данных банк не указывал, какая именно активность проходила по картам. То есть понять, были транзакции или нет, мы могли, а вот определить их тип — уже нет. Поэтому было неясно, снимал ли клиент наличные, поступала ли ему зарплата, или он тратил деньги на покупки. А еще у нас не было данных по остаткам на счетах, что было бы полезно.
Сама выборка была несмещенной — на этом срезе за 19 месяцев банк не предпринимал никаких попыток по удержанию клиентов и минимизации оттока.
Так вот, про периоды неактивности.
Для формулирования определения оттока надо выбрать период неактивности. Чтобы создать прогноз оттока в момент времени , надо иметь историю клиентов минимум в 3 месяца на интервале
, надо иметь историю клиентов минимум в 3 месяца на интервале ![$[t − 3; t − 1]$](https://habrastorage.org/getpro/habr/formulas/879/299/270/879299270c1a642e16f0fd242662b36f.svg) . История у нас была ограничена 19 месяцами, поэтому решили брать период неактивности в 6 месяцев, если он есть. А за минимальный период для качественного прогноза взяли 3 месяца. Цифры в 3 и 6 месяцев мы взяли эмпирически на основании анализа поведения данных клиентов.
. История у нас была ограничена 19 месяцами, поэтому решили брать период неактивности в 6 месяцев, если он есть. А за минимальный период для качественного прогноза взяли 3 месяца. Цифры в 3 и 6 месяцев мы взяли эмпирически на основании анализа поведения данных клиентов.
Определение оттока мы сформулировали так: месяц оттока клиента это первый месяц с ACTIVE_FLAG=0, где с этого месяца идут не менее шести нулей подряд в поле ACTIVE_FLAG, другими словами, месяц, начиная с которого клиент 6 месяцев был неактивен.
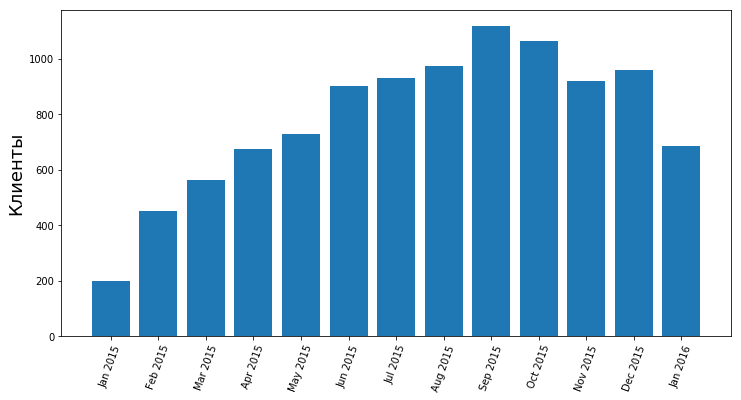
Количество ушедших клиентов
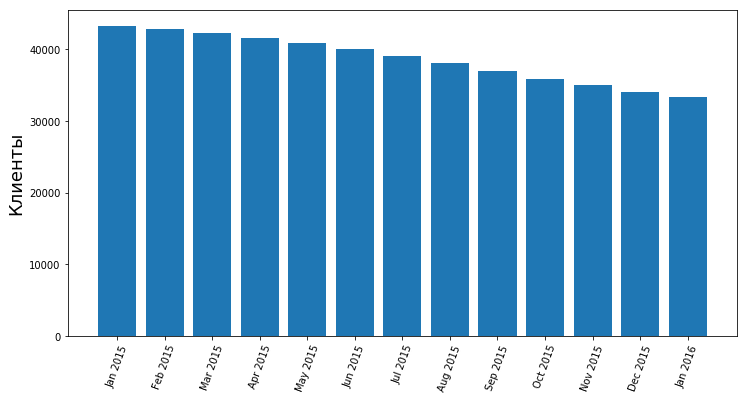
Количество оставшихся клиентов
В подобных соревнованиях, да и вообще на практике, отток довольно часто прогнозируют вот таким способом. Клиент использует продукты и сервисы в разные промежутки времени, данные о взаимодействии с ним представляют в виде вектора признаков фиксированной длины n. Чаще всего в эту информацию включают:
И уже после этого выводят определение оттока, свое для каждой задачи. Потом используют алгоритм машинного обучения, который и предсказывает вероятность ухода клиента на основании вектора факторов  . Для обучения алгоритма используют один из известных фреймворков построения ансамблей решающих деревьев, XGBoost, LightGBM, CatBoost или их модификации.
. Для обучения алгоритма используют один из известных фреймворков построения ансамблей решающих деревьев, XGBoost, LightGBM, CatBoost или их модификации.
Сам по себе алгоритм неплох, но именно в части прогнозирования оттока у него есть несколько серьезных минусов.
Мы решили сразу, что использовать стандартные подходы не будем. В чемпионате кроме нас зарегистрировалось еще 497 человек, у каждого из которых за плечами был неслабый опыт. Так что пытаться делать что-то по стандартной схеме в таких условиях — не самая хорошая идея.
И мы стали решать проблемы, стоящие перед моделью бинарной классификации, с помощью прогнозирования вероятностного распределения времени оттока клиентов. Подобный подход можно посмотреть здесь, он позволяет более гибко прогнозировать отток и проверять более сложные гипотезы, чем в классическом подходе. В качестве семейства распределений моделирующих время оттока мы выбрали распределение Вейбулла за его широкое применение в анализе выживаемости. Поведение клиента можно рассматривать как своего рода выживаемость.
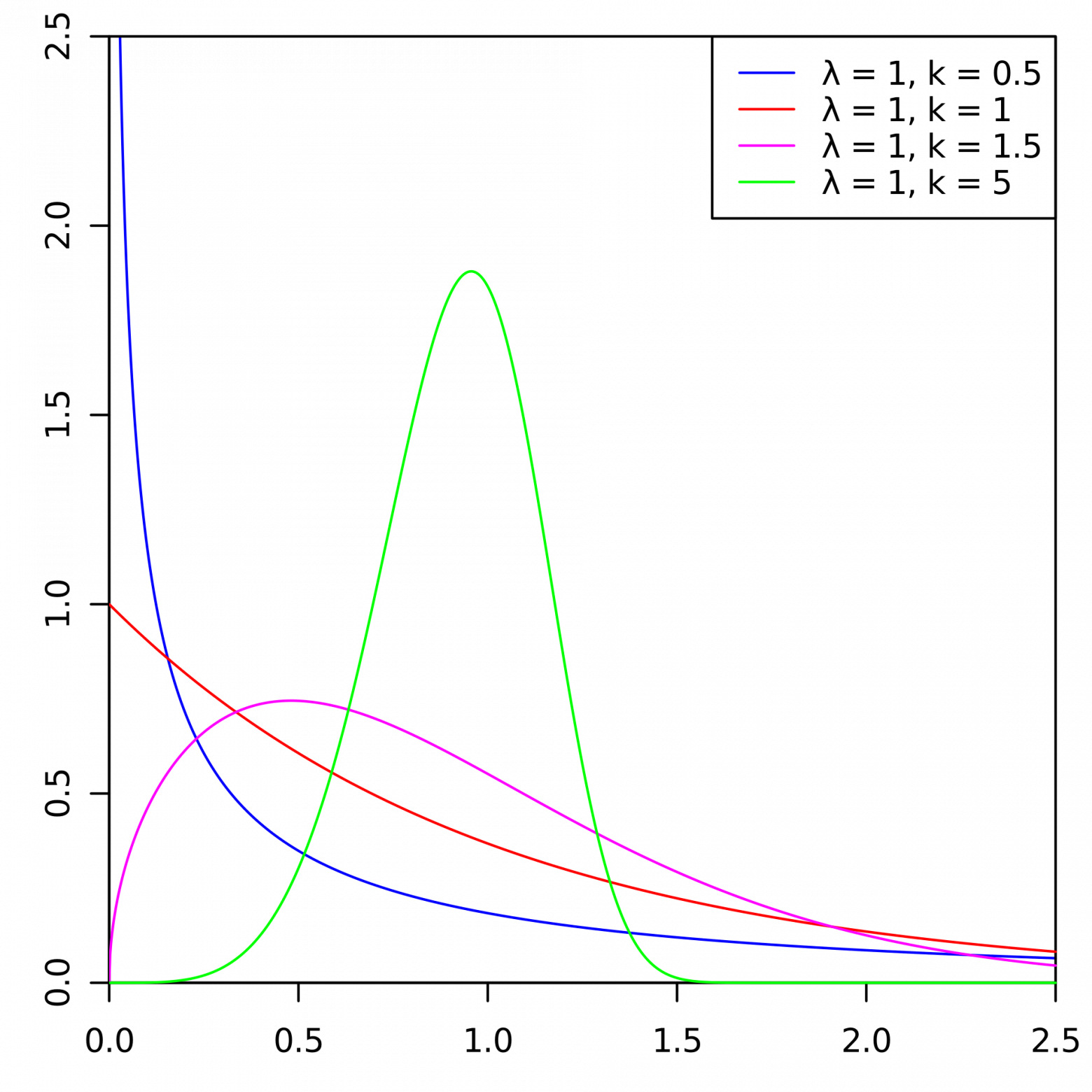
Вот примеры распределения плотностей вероятностей Вейбулла в зависимости от параметров и :
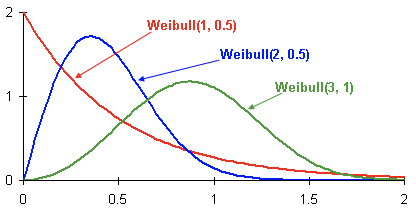
Это плотность распределения вероятности оттока клиента трех разных клиентов с течением времени. Время представлено в месяцах. Иными словами, данный график показывает, когда вероятнее всего произойдет отток клиента в следующие два месяца Как видно, клиент с распределением, обладает большим потенциалом уйти раньше, чем клиенты с распределениями Weibull(2, 0.5) и Weibull(3,1).
В итоге получается модель, которая для каждого клиента для любого
месяца предсказывает параметры распределения Вейбулла, наилучшим образом отражающая наступление вероятности оттока с течением времени. Если подробнее:
Вот в чем плюсы такого метода:
Но мало создать хорошую модель, нужно еще и нормально оценить ее качество.
В качестве метрики мы выбрали Lift Curve. Ее используют в бизнесе для подобных случаев из-за понятной интерпретации, она хорошо описана тут и здесь. Если описать смысл этой метрики одним предложением, получится «Во сколько раз алгоритм делает лучшее предсказание на первых%, чем случайным образом».
Условиями соревнования не устанавливалась конкретная метрика качества, по которой можно сравнивать различные модели и подходы. Более того, определение понятия оттока может быть разное и может зависеть от постановки задачи, которая, в свою очередь, определяется бизнес-целями. Поэтому для того, чтобы понять, какой метод лучше, мы обучили две модели:
Тестовая выборка состояла из 500 заранее отобранных клиентов, которых не было в обучающей выборке. Для модели производился подбор гипер-параметров с использованием кросс-валидации с разбивкой по клиентам. Для обучения каждой модели использовались одинаковые наборы признаков.
В связи с тем, что модель не обладает памятью, для нее брались специальные признаки, показывающие отношение изменения параметров одного месяца к среднему значению по параметрам за последние три месяца. Что собой характеризовало скорость изменения значений за последний период в три месяца. Без этого модель на базе Random Forest была бы в заранее проигрышном положении относительно Weibull-LSTM.
Тут все наглядно буквально парой картинок.
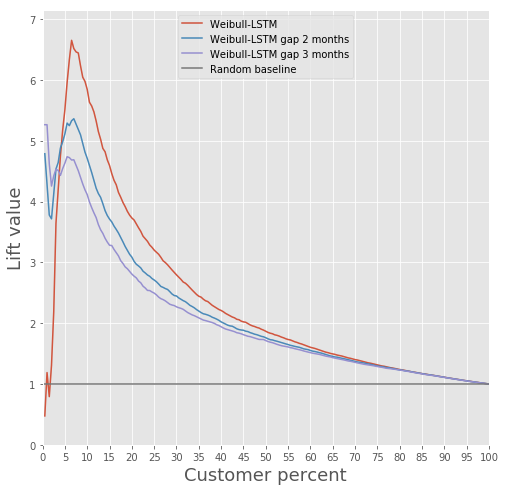
Сравнение Lift Curve для классического алгоритма и Weibull-LSTM
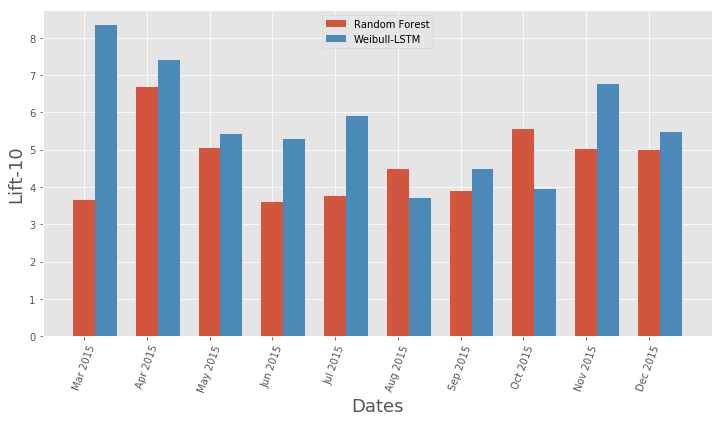
Сравнение метрики Lift Curve по месяцам для классического алгоритма и Weibull-LSTM
В общем, LSTM уделывает классический алгоритм почти во всех случаях.
Модель на основе рекуррентной нейронной нейронной сети с LSTM-ячейками с распределением Вейбулла может предсказывать отток заранее, например, предсказать уход клиента в течение следующих n месяцев. Рассмотрим случай для n = 3. В этом случае для каждого месяца нейронная сеть должна правильно определить: уйдет ли клиент, начиная со следующего месяца и до n-го месяца. Другими словами, она должна правильно определить, останется ли клиент по истечении n месяцев. Это можно считать прогнозом заранее: предсказание момента, когда клиент только начал думать о том, чтобы уйти.
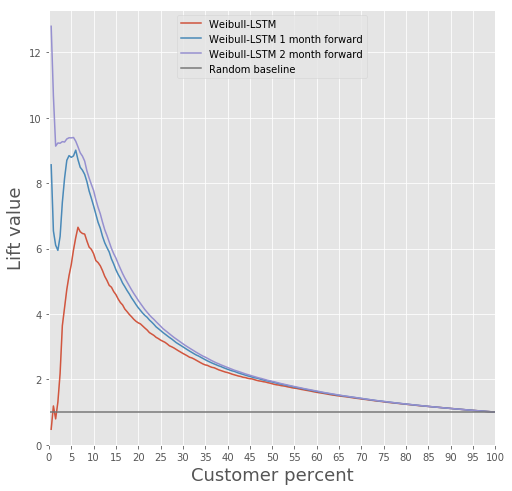
Сравним Lift Curve для Weibull-LSTM на 1, 2 и 3 месяца раньше оттока:
Мы уже писали выше, что важны еще и те прогнозы, которые сделаны для клиентов, выпадающих из активных на какое-то время. Поэтому тут мы добавим в выборку такие случаи, когда ушедший клиент уже был неактивен один или два месяца, и проверим, чтобы Weibull-LSTM правильно классифицировала такие случаи как отток. Так как такие случаи присутствовали в выборке, мы ожидаем, что сеть хорошо с ними справится:
Собственно, это главное, что можно сделать, имея на руках информацию о том, что вот такие-то клиенты готовятся перестать использовать продукт. Говоря о построении модели, которая могла бы предлагать что-то полезное клиентам, дабы их удержать — этого не получится сделать, если у вас нет истории подобных попыток, которые бы закончились хорошо.
У нас такой истории не было, поэтому мы это решили вот так.
Проверкой качества такого удержания может выступать обычное A/B-тестирование — разбиваем клиентов, которые потенциально уходят, на две группы. Одной предлагаем продукты на основе нашей модели удержания, вторым не предлагаем ничего. Мы решили обучить модель, которая могла бы принести пользу уже на пункте 1 нашего примера.
Мы хотели сделать сегментацию максимально интерпретируемой. Для этого выбрали несколько признаков, которые могли быть легко интерпретируемы: общее количество транзакций, заработная плата, суммарный оборот по счёту, возраст, пол. Признаки из таблицы «Карты» не брались в расчёт как малоинформативные, а признаки из таблицы 3 «Договоры» — по причине сложности обработки во избежание утечки данных между валидационным множеством и обучающим множеством.
Кластеризация производилась при помощи Gaussian mixture models. Информационный критерий Акаике позволил определить 2 оптимума. Первый оптимум соответствует 1 кластеру. Второй оптимум, менее выраженный, соответствует 80 кластерам. По данному результату можно сделать следующий вывод: данные крайне сложно разделить на кластеры без априорно заданной информации. Для более качественной кластеризации нужны данные, которые детально описывают каждого клиента.
Поэтому была рассмотрена задача обучения с учителем, дабы предложить каждому отдельно взятому клиенту свой продукт. Рассматривались следующие продукты: «Срочный депозит», «Кредитная карта», «Овердрафт», «Потребительский кредит», «Автокредит», «Ипотека».
В данных присутствовал ещё один вид продукта: «Текущий счёт». Но мы его не рассматривали из-за малой информативности. По пользователям, которые являются клиентами банка, т.е. не прекратили пользоваться его продуктами, была построена модель, предсказывающая, какой продукт может быть им интересен. В качестве модели выбрана логистическая регрессия, а в качестве метрики оценки качества использовалась значение Lift для первых 10 перцентилей.
Качество модели можно оценить на рисунке.
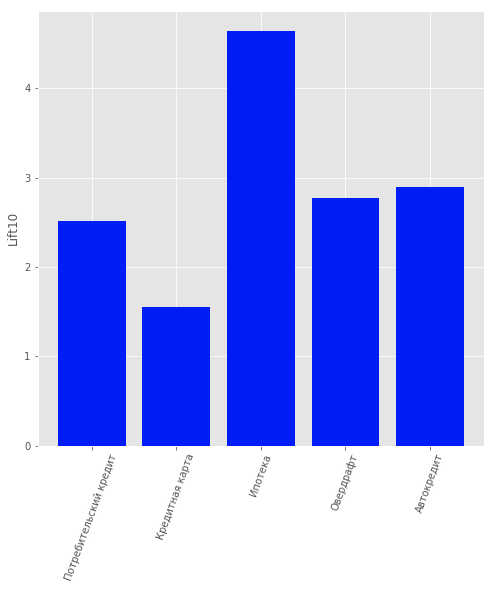
Результаты модели рекомендации продуктов для клиентов
Этот подход и принес нам первое место в номинации «AI в банках» на Чемпионате по ИИ RAIF-Challenge 2017.

Видимо, главным было все же подойти к проблеме с не самой привычной стороны, и использовать метод, который принято использовать для других ситуаций.
Хотя массовый отток пользователей вполне может быть для сервисов стихийным бедствием.
Этот метод можно взять на заметку и для любой другой сферы, где важно учитывать отток, не банками едиными. Например, мы использовали его и для того, чтобы просчитать собственный отток — в Сибирском и Санкт-Петербургском филиалах Ростелекома.
«Лаборатория интеллектуального анализа данных» компания «Поисковый портал «Спутник»
Есть такая тема, как отток клиентов. Штука неизбежная, потому что клиенты любой компании могут по множеству причин взять и перестать пользоваться ее продуктами или сервисами. Само собой, для компании отток — хоть и естественное, но не самое желаемое действие, поэтому все стараются этот отток минимизировать. А еще лучше — предсказывать вероятность оттока той или иной категории пользователей, или конкретного пользователя, и предлагать какие-то шаги по удержанию.
Анализировать и пытаться удержать клиента, если это возможно, нужно, как минимум, по следующим причинам:
- привлечение новых клиентов дороже процедур удержания. На привлечение новых клиентов, как правило, нужно потратить определенные деньги (реклама), в то время как существующих клиентов можно активизировать специальным предложением с особыми условиями;
- понимание причин ухода клиентов — ключ к улучшению продуктов и услуг.
Существуют стандартные подходы к прогнозированию оттока. Но на одном из чемпионатов по ИИ мы решили взять и попробовать для этого распределение Вейбулла. Чаще всего его используют для анализа выживаемости, прогнозирования погоды, анализа стихийных бедствий, в промышленной инженерии и подобном. Распределение Вейбулла — специальная функция распределения, параметризуемая двумя параметрами
и . 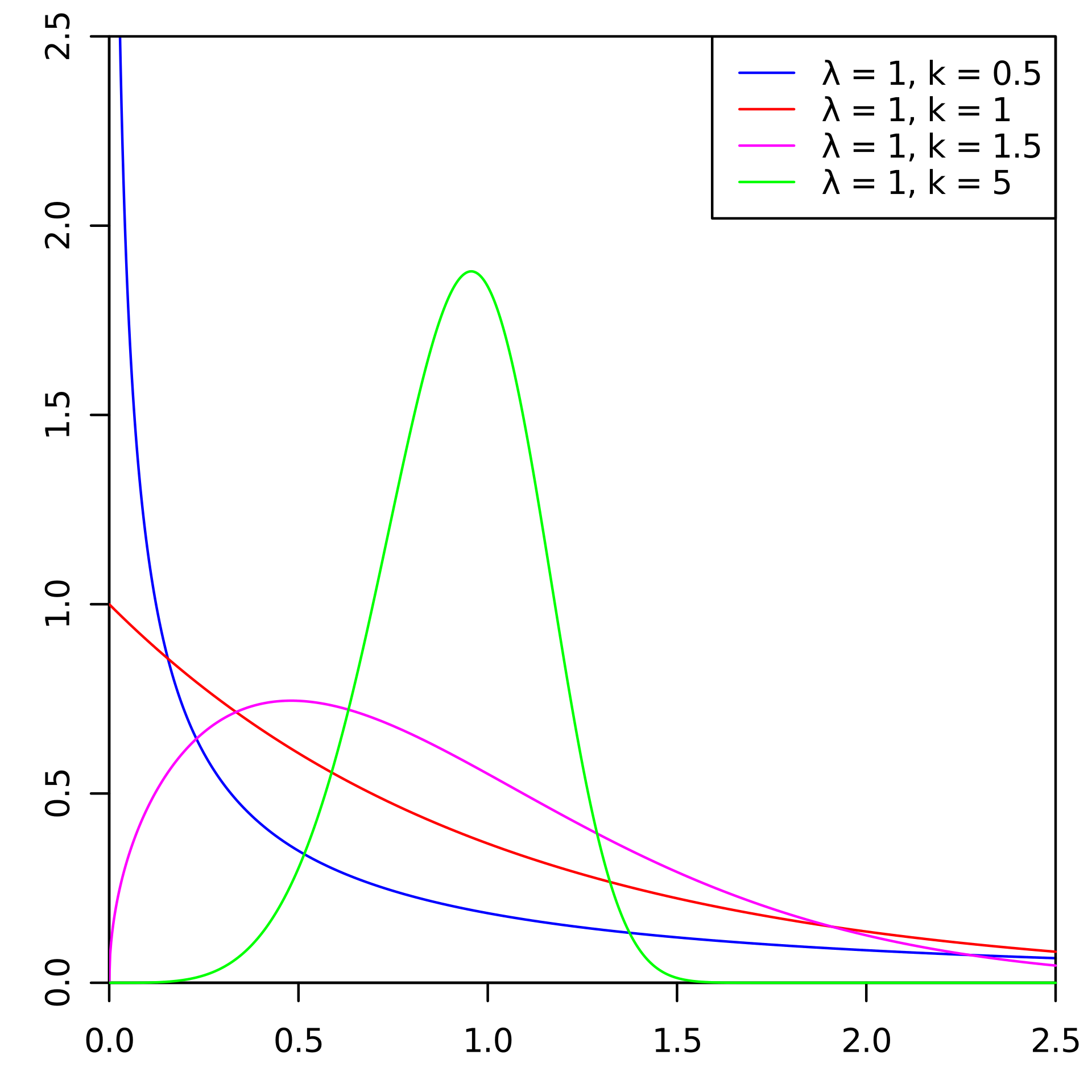
Википедия
В общем, вещь занятная, но для прогнозирования оттока, да и вообще в финтехе, использующаяся не так, чтобы часто. Под катом расскажем, как мы (Лаборатория интеллектуального анализа данных) это сделали, попутно завоевав золото на Чемпионате по искусственному интеллекту в номинации «AI в банках».
Про отток в целом
Давайте немного разберемся, что такое отток клиента и почему он так важен. Для бизнеса важна клиентская база. В эту базу приходят новые клиенты, например, узнав о продукте или услуге из рекламы, какое-то время живут (активно пользуются продуктами ) и через какое-то время перестают пользоваться. Такой период называют «Жизненный цикл клиента» (англ. Customer Lifecycle) — это термин, описывающий этапы, которые проходит клиент, когда узнает о продукте, принимает решение о покупке, платит, использует и становится лояльным потребителем, и в конечном счете перестает пользоваться по тем или иным причинам продуктами. Соответственно отток — это завершающая стадия жизненного цикла клиента, когда клиент перестает пользоваться услугами, а для бизнеса это означает, что клиент перестал приносить прибыль и вообще какую-либо пользу.
Каждый клиент банка — это конкретный человек, который выбирает ту или иную банковскую карту специально под свои нужды. Часто путешествует — пригодится карта с милями. Много покупает — привет, карта с кэшбеком. Много покупает в конкретных магазинах — и для этого уже есть специальный партнерский пластик. Конечно, иногда карта выбирается и по критерию «Самое дешевое обслуживание». В общем, переменных тут хватает.
А еще человек выбирает сам банк — смысл выбирать карту банка, отделения которого есть только в Москве и области, когда ты из Хабаровска? Будь карта такого банка хоть в 2 раза выгоднее, наличие отделений банка поблизости все еще является важным критерием. Да, 2019 уже здесь и digital — наше все, но ряд вопросов у некоторых банков можно решить только в отделении. Плюс, опять же, какая-то часть населения куда больше доверяет физическому банку, а не приложению в смартфоне, это тоже надо учитывать.
Как следствие, причин для отказа от продуктов банка (или от самого банка) у человека может быть множество. Сменил работу, и тариф карты сменился с зарплатного на «Для простых смертных», который менее выгоден. Переехал в другой город, где нет отделений банка. Не понравилось общение с неквалифицированным операционистом в отделении. То есть причин для закрытия счета может быть даже сильно побольше, чем для использования продукта.
А еще клиент может не просто явно выразить свое намерение — прийти в банк и написать заявление, а просто перестать пользоваться продуктами, не разрывая договор. Вот для понимания подобных задач и решено было использовать машинное обучение и ИИ.
Более того, отток клиентов может происходить в любой отрасли (телеком, интернет-провайдеры, страховые компании, в общем, везде, где есть клиентская база и периодические транзакции).
Что мы сделали
Прежде всего, надо было описать четкую границу — с какого времени мы начинаем считать клиента ушедшим. С точки зрения банка, предоставившего нам данные для работы, состояние активности клиента было бинарным — он или активен, или нет. Был флаг ACTIVE_FLAG в таблице «Активность», значением которого могло быть либо «0», либо «1» (соответственно, «Неактивен» и «Активен»). И все бы хорошо, но человек таков, что может какое-то время активно пользоваться, а потом на месяц выпасть из числа активных — заболел, уехал в другую страну отдыхать, или вообще пошел тестировать карту другого банка. А может после долгого периода неактивности снова начать пользоваться услугами банка
Поэтому мы решили называть периодом неактивности определенный непрерывный промежуток времени, в течение которого флаг для него устанавливался как «0».
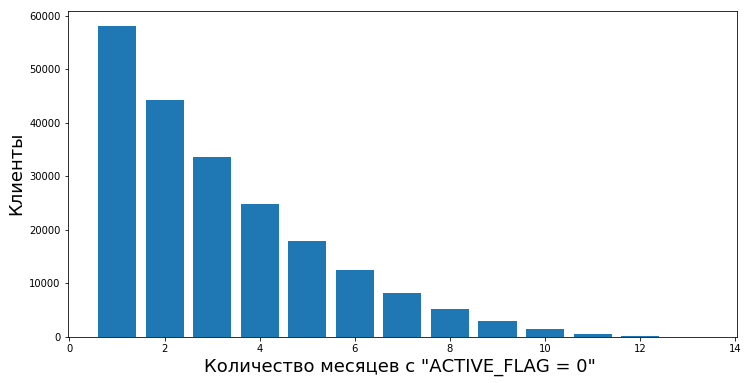
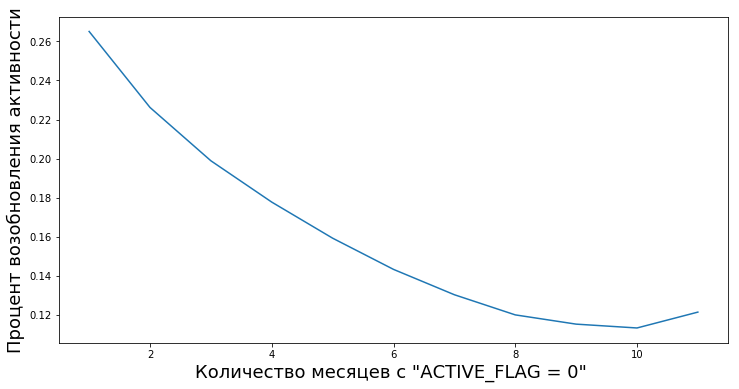
Клиенты переходят из неактивных в активные после периодов неактивности различной длины. У нас появляется возможность рассчитать степень эмпирической величины «надежность периодов неактивности» — то есть вероятность того, что человек снова начнет пользоваться продуктами банка после временной неактивности.
К примеру, вот на этом графике отображено возобновление активности (ACTIVE_FLAG=1) клиентов спустя несколько месяцев неактивности (ACTIVE_FLAG=0).
Здесь мы немного уточним тот набор данных, с которыми мы начали работать. Итак, банк предоставил агрегированную информацию за 19 месяцев в следующих таблицах:
- «Активность» — ежемесячные транзакции клиентов (по картам, в интернет-банке и мобильном банке), включая начисления зарплаты и информацию об оборотах.
- «Карты» — данные о всех картах, что есть у клиента, с подробной тарифной сеткой.
- «Договоры» — информация о договорах клиента (как открытых, так и закрытых): кредиты, депозиты и прочее, с указанием параметров каждого.
- «Клиенты» — набор демографических данных (пол и возраст) и наличие контактных данных.
Для работы нам потребовались все таблицы, кроме «Карты».
Сложность тут была вот еще в чем — в этих данных банк не указывал, какая именно активность проходила по картам. То есть понять, были транзакции или нет, мы могли, а вот определить их тип — уже нет. Поэтому было неясно, снимал ли клиент наличные, поступала ли ему зарплата, или он тратил деньги на покупки. А еще у нас не было данных по остаткам на счетах, что было бы полезно.
Сама выборка была несмещенной — на этом срезе за 19 месяцев банк не предпринимал никаких попыток по удержанию клиентов и минимизации оттока.
Так вот, про периоды неактивности.
Для формулирования определения оттока надо выбрать период неактивности. Чтобы создать прогноз оттока в момент времени
, надо иметь историю клиентов минимум в 3 месяца на интервале . История у нас была ограничена 19 месяцами, поэтому решили брать период неактивности в 6 месяцев, если он есть. А за минимальный период для качественного прогноза взяли 3 месяца. Цифры в 3 и 6 месяцев мы взяли эмпирически на основании анализа поведения данных клиентов.Определение оттока мы сформулировали так: месяц оттока клиента
это первый месяц с ACTIVE_FLAG=0, где с этого месяца идут не менее шести нулей подряд в поле ACTIVE_FLAG, другими словами, месяц, начиная с которого клиент 6 месяцев был неактивен. 
Количество ушедших клиентов

Количество оставшихся клиентов
Как принято считать отток
В подобных соревнованиях, да и вообще на практике, отток довольно часто прогнозируют вот таким способом. Клиент использует продукты и сервисы в разные промежутки времени, данные о взаимодействии с ним представляют в виде вектора признаков фиксированной длины n. Чаще всего в эту информацию включают:
- Характеризующие пользователя данные (демографические данные, маркетинговый сегмент).
- Историю использования банковских продуктов и услуг (это действия клиентов, которые всегда привязаны к конкретному времени или периоду нужного нам интервала).
- Внешние данные, если их удалось получить — к примеру, отзывы из социальных сетей.
И уже после этого выводят определение оттока, свое для каждой задачи. Потом используют алгоритм машинного обучения, который и предсказывает вероятность ухода клиента
на основании вектора факторов . Для обучения алгоритма используют один из известных фреймворков построения ансамблей решающих деревьев, XGBoost, LightGBM, CatBoost или их модификации. Сам по себе алгоритм неплох, но именно в части прогнозирования оттока у него есть несколько серьезных минусов.
- Он не обладает так называемой «памятью». На вход модели поступает заданное количество признаков, которые соответствуют текущему моменту времени. Для того чтобы закладывать информацию об истории изменения параметров, необходимо вычислять специальные признаки, которые характеризуют изменения параметров во времени, например количество или сумму банковских транзакций за последние 1,2,3 месяцев. Такой подход может лишь частично отражать характер временных изменений.
- Фиксированный горизонт прогнозирования. Модель способна предсказывать отток клиентов только на предварительно заданный промежуток времени, например, прогноз на один месяц вперед. Если требуется прогноз на другой промежуток времени, например, на три месяца, то нужно перестраивать обучающую выборку и переобучать новую модель.
Наш подход
Мы решили сразу, что использовать стандартные подходы не будем. В чемпионате кроме нас зарегистрировалось еще 497 человек, у каждого из которых за плечами был неслабый опыт. Так что пытаться делать что-то по стандартной схеме в таких условиях — не самая хорошая идея.
И мы стали решать проблемы, стоящие перед моделью бинарной классификации, с помощью прогнозирования вероятностного распределения времени оттока клиентов. Подобный подход можно посмотреть здесь, он позволяет более гибко прогнозировать отток и проверять более сложные гипотезы, чем в классическом подходе. В качестве семейства распределений моделирующих время оттока мы выбрали распределение Вейбулла за его широкое применение в анализе выживаемости. Поведение клиента можно рассматривать как своего рода выживаемость.
Вот примеры распределения плотностей вероятностей Вейбулла в зависимости от параметров
и :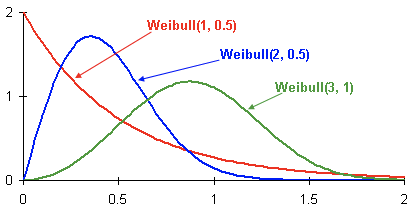
Это плотность распределения вероятности оттока клиента трех разных клиентов с течением времени. Время представлено в месяцах. Иными словами, данный график показывает, когда вероятнее всего произойдет отток клиента в следующие два месяца Как видно, клиент с распределением, обладает большим потенциалом уйти раньше, чем клиенты с распределениями Weibull(2, 0.5) и Weibull(3,1).
В итоге получается модель, которая для каждого клиента для любого
месяца предсказывает параметры распределения Вейбулла, наилучшим образом отражающая наступление вероятности оттока с течением времени. Если подробнее:
- Целевые признаки на обучающей выборке — время, оставшееся до оттока в конкретном месяца для конкретного клиента.
- Если показателя оттока для клиента нет, предполагаем, что время оттока больше, чем количество месяцев, начиная с текущего и до конца имеющейся у нас истории.
- Используемая модель: рекуррентная нейронная сеть с LSTM-слоем.
- В качестве функции потерь используем отрицательную логарифмическую функцию правдоподобия для распределения Вейбулла.
Вот в чем плюсы такого метода:
- Вероятностное распределение, помимо очевидной возможности бинарной классификации, позволяет гибко предсказывать разные события, например, перестанет ли клиент пользоваться услугами банка в течение 3 месяцев. Также, при необходимости, по этому распределению можно усреднять различные метрики.
- Рекуррентная нейронная сеть LSTM имеет память и эффективно использует всю имеющуюся историю. С расширением или уточнением истории точность вырастает.
- Подход можно без проблем масштабировать при разбиении временных промежутков на более мелкие (например, при разбиении месяцев на недели).
Но мало создать хорошую модель, нужно еще и нормально оценить ее качество.
Как оценивали качество
В качестве метрики мы выбрали Lift Curve. Ее используют в бизнесе для подобных случаев из-за понятной интерпретации, она хорошо описана тут и здесь. Если описать смысл этой метрики одним предложением, получится «Во сколько раз алгоритм делает лучшее предсказание на первых
%, чем случайным образом». Обучаем модели
Условиями соревнования не устанавливалась конкретная метрика качества, по которой можно сравнивать различные модели и подходы. Более того, определение понятия оттока может быть разное и может зависеть от постановки задачи, которая, в свою очередь, определяется бизнес-целями. Поэтому для того, чтобы понять, какой метод лучше, мы обучили две модели:
- Часто используемый подход бинарной классификации с использованием алгоритма машинного обучения ансамбля решающих деревьев (LightGBM);
- Модель Weibull-LSTM
Тестовая выборка состояла из 500 заранее отобранных клиентов, которых не было в обучающей выборке. Для модели производился подбор гипер-параметров с использованием кросс-валидации с разбивкой по клиентам. Для обучения каждой модели использовались одинаковые наборы признаков.
В связи с тем, что модель не обладает памятью, для нее брались специальные признаки, показывающие отношение изменения параметров одного месяца к среднему значению по параметрам за последние три месяца. Что собой характеризовало скорость изменения значений за последний период в три месяца. Без этого модель на базе Random Forest была бы в заранее проигрышном положении относительно Weibull-LSTM.
Чем LSTM с распределением Вейбулла лучше, чем подход, основанный на ансамбле решающих деревьев
Тут все наглядно буквально парой картинок.
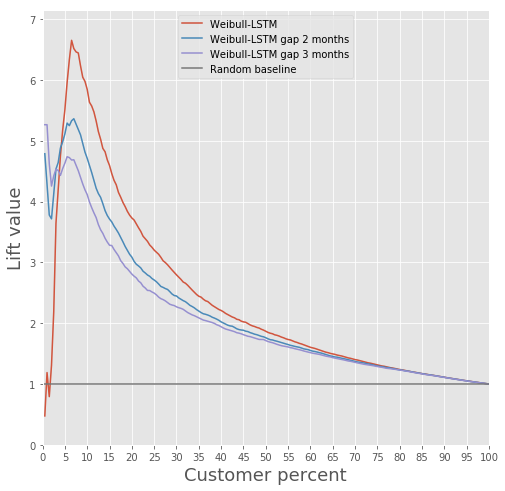
Сравнение Lift Curve для классического алгоритма и Weibull-LSTM
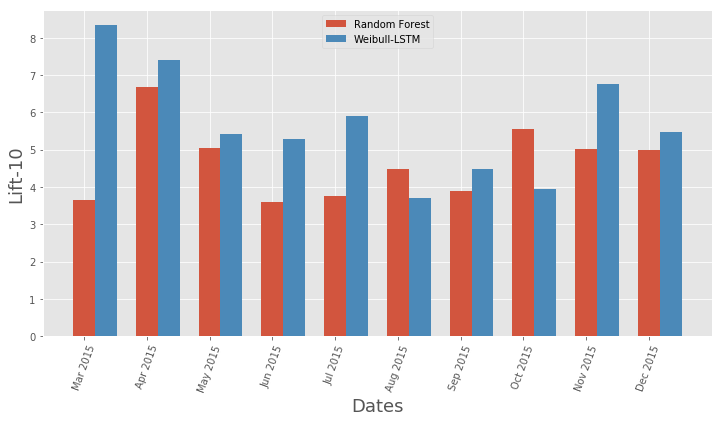
Сравнение метрики Lift Curve по месяцам для классического алгоритма и Weibull-LSTM
В общем, LSTM уделывает классический алгоритм почти во всех случаях.
Предсказание оттока
Модель на основе рекуррентной нейронной нейронной сети с LSTM-ячейками с распределением Вейбулла может предсказывать отток заранее, например, предсказать уход клиента в течение следующих n месяцев. Рассмотрим случай для n = 3. В этом случае для каждого месяца нейронная сеть должна правильно определить: уйдет ли клиент, начиная со следующего месяца и до n-го месяца. Другими словами, она должна правильно определить, останется ли клиент по истечении n месяцев. Это можно считать прогнозом заранее: предсказание момента, когда клиент только начал думать о том, чтобы уйти.
Сравним Lift Curve для Weibull-LSTM на 1, 2 и 3 месяца раньше оттока:
Мы уже писали выше, что важны еще и те прогнозы, которые сделаны для клиентов, выпадающих из активных на какое-то время. Поэтому тут мы добавим в выборку такие случаи, когда ушедший клиент уже был неактивен один или два месяца, и проверим, чтобы Weibull-LSTM правильно классифицировала такие случаи как отток. Так как такие случаи присутствовали в выборке, мы ожидаем, что сеть хорошо с ними справится:
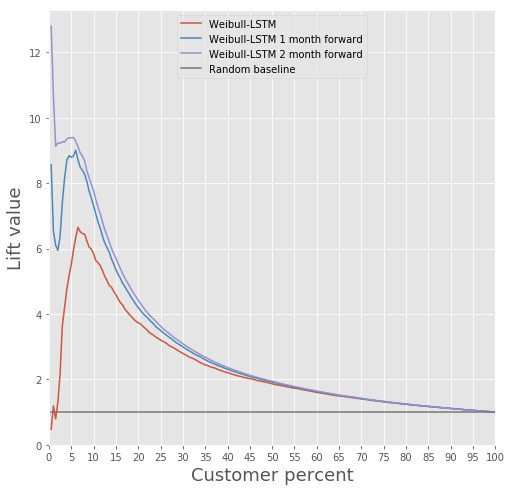
Удержание клиентов
Собственно, это главное, что можно сделать, имея на руках информацию о том, что вот такие-то клиенты готовятся перестать использовать продукт. Говоря о построении модели, которая могла бы предлагать что-то полезное клиентам, дабы их удержать — этого не получится сделать, если у вас нет истории подобных попыток, которые бы закончились хорошо.
У нас такой истории не было, поэтому мы это решили вот так.
- Строим модель, определяющую интересные продукты для каждого клиента.
- В каждом месяце прогоняем классификатор и определяем потенциально уходящих клиентов.
- Части клиентов предлагаем продукт, согласно модели из пункта 1, запоминаем свои действия.
- Спустя несколько месяцев смотрим, кто из этих потенциально уходящих клиентов ушел, а кто остался. Таким образом формируем обучающую выборку.
- Обучаем модель на истории, полученной в пункте 4.
- Опционально, повторяем процедуру, заменяя модель из пункта 1 на модель, полученную в пункте 5.
Проверкой качества такого удержания может выступать обычное A/B-тестирование — разбиваем клиентов, которые потенциально уходят, на две группы. Одной предлагаем продукты на основе нашей модели удержания, вторым не предлагаем ничего. Мы решили обучить модель, которая могла бы принести пользу уже на пункте 1 нашего примера.
Мы хотели сделать сегментацию максимально интерпретируемой. Для этого выбрали несколько признаков, которые могли быть легко интерпретируемы: общее количество транзакций, заработная плата, суммарный оборот по счёту, возраст, пол. Признаки из таблицы «Карты» не брались в расчёт как малоинформативные, а признаки из таблицы 3 «Договоры» — по причине сложности обработки во избежание утечки данных между валидационным множеством и обучающим множеством.
Кластеризация производилась при помощи Gaussian mixture models. Информационный критерий Акаике позволил определить 2 оптимума. Первый оптимум соответствует 1 кластеру. Второй оптимум, менее выраженный, соответствует 80 кластерам. По данному результату можно сделать следующий вывод: данные крайне сложно разделить на кластеры без априорно заданной информации. Для более качественной кластеризации нужны данные, которые детально описывают каждого клиента.
Поэтому была рассмотрена задача обучения с учителем, дабы предложить каждому отдельно взятому клиенту свой продукт. Рассматривались следующие продукты: «Срочный депозит», «Кредитная карта», «Овердрафт», «Потребительский кредит», «Автокредит», «Ипотека».
В данных присутствовал ещё один вид продукта: «Текущий счёт». Но мы его не рассматривали из-за малой информативности. По пользователям, которые являются клиентами банка, т.е. не прекратили пользоваться его продуктами, была построена модель, предсказывающая, какой продукт может быть им интересен. В качестве модели выбрана логистическая регрессия, а в качестве метрики оценки качества использовалась значение Lift для первых 10 перцентилей.
Качество модели можно оценить на рисунке.
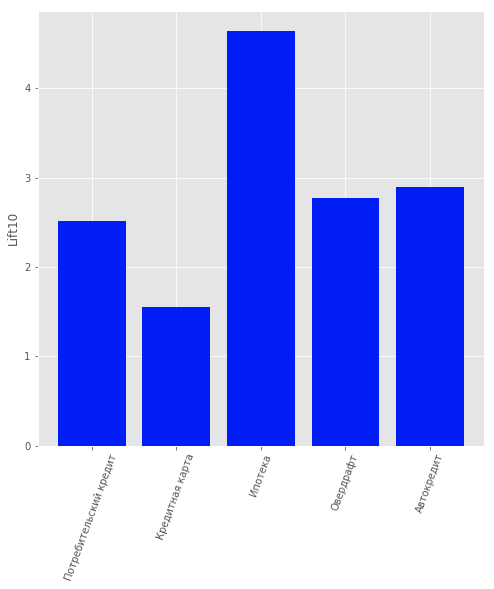
Результаты модели рекомендации продуктов для клиентов
Итог
Этот подход и принес нам первое место в номинации «AI в банках» на Чемпионате по ИИ RAIF-Challenge 2017.

Видимо, главным было все же подойти к проблеме с не самой привычной стороны, и использовать метод, который принято использовать для других ситуаций.
Хотя массовый отток пользователей вполне может быть для сервисов стихийным бедствием.
Этот метод можно взять на заметку и для любой другой сферы, где важно учитывать отток, не банками едиными. Например, мы использовали его и для того, чтобы просчитать собственный отток — в Сибирском и Санкт-Петербургском филиалах Ростелекома.
«Лаборатория интеллектуального анализа данных» компания «Поисковый портал «Спутник»
