Веб-краулер (или веб-паук) — это важная составная часть поисковых систем для обхода веб-страниц с целью занесения информации о них в базы данных, в основном, для их дальнейшей индексации. Такая штука есть у поисковиков (Google, Yandex, Bing), а также у SEO-продуктов (SEMrush, MOZ, ahrefs) и не только. И штука эта — довольно интересная: как в плане потенциала и вариантов использования, так и для технической реализации.

Этой статьей мы начнем итеративно создавать свойвелосипед краулер, разбирая многие особенности и встречая подводные камни. От простой рекурсивной функции до масштабируемого и расширяемого сервиса. Должно быть интересно!
Итеративно — значит в конце каждого выпуска ожидается готовая к использованию версия «продукта» с условленными ограничениями, характеристиками и интерфейсом.
В качестве платформы и языка выбраны node.js и JavaScript, потому что это просто и асинхронно. Конечно, для промышленной разработки выбор технологической базы должен опираться на бизнес-требования, ожидания и ресурсы. В качестве же демонстрации и прототипа эта платформа — вполне ничего (имхо).
Реализация краулера — довольно популярная задача и встречается даже на технических собеседованиях. Готовых (Apache Nutch) и самописных решений для разных условий и на множестве языков — действительно много. Поэтому, любые комментарии из личного опыта разработки или использования приветствуются и будут интересны.
Задание для первой (начальной) реализации нашеготяп-ляп краулера будет следующим:
Внимание! Игнорировать правила robots.txt — плохая идея по понятным причинам. Мы наверстаем это упущение в дальнейшем. А пока, добавим ограничивающий количество обходимых страниц параметр limit, чтобы останавливаться и не DoS'ить подопытный сайт (лучше и вовсе для экспериментов использовать какой-нибудь свой персональный «сайт-хомячок»).
Для нетерпеливых вот исходники этого решения.
Первое, что нам нужно уметь делать — это, собственно, отправлять запросы и получать ответы по HTTP и HTTPS. В node.js для этого есть два соответствующих клиента. Конечно, можно взять готовый клиент request, но для нашей задачи он крайне избыточен: нам всего лишь надо отправить GET-запрос и получить response с телом и заголовками.
Необходимый нам API обоих клиентов идентичен, заведем мапу:
Объявим простую функцию fetch, единственным параметром которой будет абсолютный URL нужного веб-ресурса строкой. С помощью утильного модуля url будем парсить полученную строку в объект URL. В этом объекте имеется поле с протоколом (с двоеточием), по которому мы выберем подходящий клиент:
Далее используем выбранный клиент и обернем результат функции fetch в промис:
Теперь мы умеем асинхронно получать response, но пока ничего с ним не делаем.
Для обхода сайта достаточно обрабатывать 3 варианта ответа:
Функция fetch будет резолвить обработанный response с указанием его типа:
Реализация стратегии формирования результата в лучших традициях if-else:
Функция fetch готова к использованию: код функции целиком.
Теперь в зависимости от варианта полученного ответа нужно уметь экстрагировать из данных результата fetch ссылки для дальнейшего обхода. Для этого определим функцию extract, принимающую на вход объект результата и возвращающую массив новых ссылок.
Если тип результата — REDIRECT, то функция вернет массив с одной единственной ссылкой из поля location. Если NO_DATA, то пустой массив. Если же OK, то нам необходимо подключить парсер для представленного текстового content для поиска.
Для задачи поиска <a href /> можно написать и регулярное выражение. Но это решение совершенно не масштабируется, так как в дальнейшем мы как минимум будем обращать внимание на прочие атрибуты (rel) ссылки, как максимум — подумаем про img, link, script, audio/video (source) и прочие ресурсы. Гораздо перспективнее и удобнее парсить текст документа и строить дерево его узлов для обхода привычными селекторами.
Воспользуемся популярной библиотекой JSDOM для работы с DOM в node.js:
Достаем из документа все A элементы, а затем все отфильтрованные значения атрибута href, как не пустые строки.
В результате работы экстрактора мы имеем набор ссылок (URL) и две проблемы: 1) URL может быть относительным и 2) URL может вести на внешний ресурс (нам нужны сейчас только внутренние).
С первой проблемой нам поможет справиться функция url.resolve, которая резолвит URL целевой страницы относительно URL страницы-источника.
Чтобы решить вторую проблему, напишем простую утильную функцию inScope, которая проверяет хост целевой страницы относительно хоста базового URL текущего краула:
Функция осуществляет поиск подстроки (baseHost) с проверкой предыдущего символа, если подстрока была найдена: так как wwwexample.com и example.com — разные домены. В результаты мы не покидаем заданный домен, но обходим его поддомены.
Доработаем функцию extract, добавив «абсолютизацию» и фильтрацию полученных ссылок:
Здесь fetched — полученный результат от функции fetch, src — URL страницы-источника, base — базовый URL краула. На выходе мы получаем список уже абсолютных внутренних ссылок (URL) для дальнейшей обработки. Код функции целиком можно увидеть здесь.
Повторно встретив какой-либо URL, не нужно отправлять еще запрос за ресурсом, так как данные уже были получены (или другое соединение еще открыто и ожидает ответа). Но не всегда достаточно сравнить строки двух URL, чтобы это понять. Нормализация — это процедура, необходимая для определения эквивалентности синтаксически различных URL-адресов.
Процесс нормализации — это целый набор преобразований, применяемых к исходному URL и его компонентам. Вот только некоторые из них:
Всегда можно взять что-то готовое (например normalize-url) или написать свою простую функцию, покрывающую наиболее важные и частые случаи:
Да, здесь нет сортировки query-параметров, игнорирования utm-меток, обработки _escaped_fragment_ и прочего, чего нам (пока) совершенно не нужно.
Далее заведем локальный кэш запрошенных в рамках краула нормализованных URL. Перед отправкой очередного запроса нормализуем полученный URL, и, если тот отсутствует в кэше, добавим и только тогда отправим новый запрос.
Ключевые компоненты (примитивы) решения уже готовы, пришло время начать собирать все вместе. Для начала определимся с сигнатурой функции crawl: на входе — стартовый URL и ограничение по страницам. Функция возвращает промис, резолв которого предоставляет аккумулированный результат; запишем его в файл output:
Простейшая схема рекурсивной работы функции краула может быть описана шагами:
Да, этот алгоритм будет претерпевать серьезные изменения в дальнейшем. Сейчас же умышленно используется рекурсивное решение в лоб, чтобы позже лучше «прочувствовать» разницу в реализациях. Заготовка для имплементации функции выглядит так:
Достижение лимита страниц проверяется простым счетчиком запросов. Второй счетчик — количество активных запросов в момент времени — послужит проверкой готовности отдать результат (когда значение оборачивается в ноль). Если функции fetch не удалось получить очередную страницу, то для нее Status Code выставим как null.
С кодом имплементации можно (не обязательно) ознакомиться здесь, но перед этим стоит рассмотреть формат возвращаемого результата.
Введем уникальный идентификатор id с простым инкрементом для опрошенных страниц:
Для результата заведем массив pages, в который будем складывать объекты с данными по странице: id {number}, url {string} и code {number|null} (этого сейчас достаточно). Также заведем массив links для ссылок между страницами в виде объекта: from (id страницы-источника), to (id целевой страницы).
Для информативности перед резолвом результата отсортируем список страниц по возрастанию id (ведь ответы будут приходить в каком-угодно порядке), дополним результат числом просканированных страниц count и флагом о достижении заданного лимита fin:
Готовый краулер-скрипт имеет следующий синопсис:
Дополнив логированием ключевых точек процесса, увидим такую картину при запуске:
А вот результат в формате JSON:
Что с этим уже можно делать? Как минимум, по списку страниц можно найти все битые страницы сайта. А имея информацию о внутренней перелинковке, можно обнаружить длинные цепочки (и замкнутые циклы) редиректов или найти наиболее важные страницы по ссылочной массе.
У нас получился вариант простейшего консольного краулера, который обходит страницы одного сайта. Исходный код лежит здесь. Там же есть еще пример и юнит-тесты для некоторых функций.
Сейчас это бесцеремонный отправитель запросов и следующим разумным шагом будет — научить его хорошим манерам. Речь пойдет о заголовке User-agent, правилах robots.txt, директиве Crawl-delay и прочем. С точки зрения реализации, это первым делом организация очереди сообщений и далее обслуживание большей нагрузки. Если, конечно, этот материал будет интересным!

Этой статьей мы начнем итеративно создавать свой
Интро
Итеративно — значит в конце каждого выпуска ожидается готовая к использованию версия «продукта» с условленными ограничениями, характеристиками и интерфейсом.
В качестве платформы и языка выбраны node.js и JavaScript, потому что это просто и асинхронно. Конечно, для промышленной разработки выбор технологической базы должен опираться на бизнес-требования, ожидания и ресурсы. В качестве же демонстрации и прототипа эта платформа — вполне ничего (имхо).
Это мой краулер. Таких краулеров много, но этот — мой.
Мой краулер — мой лучший друг.
Реализация краулера — довольно популярная задача и встречается даже на технических собеседованиях. Готовых (Apache Nutch) и самописных решений для разных условий и на множестве языков — действительно много. Поэтому, любые комментарии из личного опыта разработки или использования приветствуются и будут интересны.
Постановка задачи
Задание для первой (начальной) реализации нашего
Краулер на раз-два 1.0
Написать краулер-скрипт, который обходит внутренние <a href /> ссылки некоторого небольшого (до 100 страниц) сайта. В качестве результата предоставить список URL'ов страниц с полученными кодами и карту их перелинковки. Правила robots.txt и атрибут ссылки rel=nofollow игнорировать.
Внимание! Игнорировать правила robots.txt — плохая идея по понятным причинам. Мы наверстаем это упущение в дальнейшем. А пока, добавим ограничивающий количество обходимых страниц параметр limit, чтобы останавливаться и не DoS'ить подопытный сайт (лучше и вовсе для экспериментов использовать какой-нибудь свой персональный «сайт-хомячок»).
Реализация
Для нетерпеливых вот исходники этого решения.
- HTTP(S)-клиент
- Варианты ответа
- Экстрагирование ссылок
- Подготовка и фильтрация ссылок
- Нормализация URL
- Алгоритм работы main-функции
- Возвращаемый результат
1. HTTP(S)-клиент
Первое, что нам нужно уметь делать — это, собственно, отправлять запросы и получать ответы по HTTP и HTTPS. В node.js для этого есть два соответствующих клиента. Конечно, можно взять готовый клиент request, но для нашей задачи он крайне избыточен: нам всего лишь надо отправить GET-запрос и получить response с телом и заголовками.
Необходимый нам API обоих клиентов идентичен, заведем мапу:
const clients = {
'http:': require('http'),
'https:': require('https')
};
Объявим простую функцию fetch, единственным параметром которой будет абсолютный URL нужного веб-ресурса строкой. С помощью утильного модуля url будем парсить полученную строку в объект URL. В этом объекте имеется поле с протоколом (с двоеточием), по которому мы выберем подходящий клиент:
const url = require('url');
function fetch(dst) {
let dstURL = new URL(dst);
let client = clients[dstURL.protocol];
if (!client) {
throw new Error('Could not select a client for ' + dstURL.protocol);
}
// ...
}
Далее используем выбранный клиент и обернем результат функции fetch в промис:
function fetch(dst) {
return new Promise((resolve, reject) => {
// ...
let req = client.get(dstURL.href, res => {
// do something with the response
});
req.on('error', err => reject('Failed on the request: ' + err.message));
req.end();
});
}
Теперь мы умеем асинхронно получать response, но пока ничего с ним не делаем.
2. Варианты ответа
Для обхода сайта достаточно обрабатывать 3 варианта ответа:
- OK — Был получен 2xx Status Code. Необходимо сохранить в результат тело ответа для дальнейшей обработки — экстрагирования новых ссылок.
- REDIRECT — Был получен 3xx Status Code. Это редирект на другую страницу. В этом случае нам понадобится заголовок ответа Location, откуда мы в дальнейшем возьмем одну единственную «исходящую» ссылку.
- NO_DATA — Все прочие случаи: 4xx/5xx и 3xx без заголовка Location. Здесь некуда дальше идти нашему краулеру.
Функция fetch будет резолвить обработанный response с указанием его типа:
const ft = {
'OK': 1, // code (2xx), content
'REDIRECT': 2, // code (3xx), location
'NO_DATA': 3 // code
};
Реализация стратегии формирования результата в лучших традициях if-else:
let code = res.statusCode;
let codeGroup = Math.floor(code / 100);
// OK
if (codeGroup === 2) {
let body = [];
res.setEncoding('utf8');
res.on('data', chunk => body.push(chunk));
res.on('end', () => resolve({ code, content: body.join(''), type: ft.OK }));
}
// REDIRECT
else if (codeGroup === 3 && res.headers.location) {
resolve({ code, location: res.headers.location, type: ft.REDIRECT });
}
// NO_DATA (others)
else {
resolve({ code, type: ft.NO_DATA });
}
Функция fetch готова к использованию: код функции целиком.
3. Экстрагирование ссылок
Теперь в зависимости от варианта полученного ответа нужно уметь экстрагировать из данных результата fetch ссылки для дальнейшего обхода. Для этого определим функцию extract, принимающую на вход объект результата и возвращающую массив новых ссылок.
Если тип результата — REDIRECT, то функция вернет массив с одной единственной ссылкой из поля location. Если NO_DATA, то пустой массив. Если же OK, то нам необходимо подключить парсер для представленного текстового content для поиска.
Для задачи поиска <a href /> можно написать и регулярное выражение. Но это решение совершенно не масштабируется, так как в дальнейшем мы как минимум будем обращать внимание на прочие атрибуты (rel) ссылки, как максимум — подумаем про img, link, script, audio/video (source) и прочие ресурсы. Гораздо перспективнее и удобнее парсить текст документа и строить дерево его узлов для обхода привычными селекторами.
Воспользуемся популярной библиотекой JSDOM для работы с DOM в node.js:
const { JSDOM } = require('jsdom');
let document = new JSDOM(fetched.content).window.document;
let elements = document.getElementsByTagName('A');
return Array.from(elements)
.map(el => el.getAttribute('href'))
.filter(href => typeof href === 'string')
.map(href => href.trim())
.filter(Boolean);
Достаем из документа все A элементы, а затем все отфильтрованные значения атрибута href, как не пустые строки.
4. Подготовка и фильтрация ссылок
В результате работы экстрактора мы имеем набор ссылок (URL) и две проблемы: 1) URL может быть относительным и 2) URL может вести на внешний ресурс (нам нужны сейчас только внутренние).
С первой проблемой нам поможет справиться функция url.resolve, которая резолвит URL целевой страницы относительно URL страницы-источника.
Чтобы решить вторую проблему, напишем простую утильную функцию inScope, которая проверяет хост целевой страницы относительно хоста базового URL текущего краула:
function getLowerHost(dst) {
return (new URL(dst)).hostname.toLowerCase();
}
function inScope(dst, base) {
let dstHost = getLowerHost(dst);
let baseHost = getLowerHost(base);
let i = dstHost.indexOf(baseHost);
// the same domain or has subdomains
return i === 0 || dstHost[i - 1] === '.';
}
Функция осуществляет поиск подстроки (baseHost) с проверкой предыдущего символа, если подстрока была найдена: так как wwwexample.com и example.com — разные домены. В результаты мы не покидаем заданный домен, но обходим его поддомены.
Доработаем функцию extract, добавив «абсолютизацию» и фильтрацию полученных ссылок:
function extract(fetched, src, base) {
return extractRaw(fetched)
.map(href => url.resolve(src, href))
.filter(dst => /^https?\:\/\//i.test(dst))
.filter(dst => inScope(dst, base));
}
Здесь fetched — полученный результат от функции fetch, src — URL страницы-источника, base — базовый URL краула. На выходе мы получаем список уже абсолютных внутренних ссылок (URL) для дальнейшей обработки. Код функции целиком можно увидеть здесь.
5. Нормализация URL
Повторно встретив какой-либо URL, не нужно отправлять еще запрос за ресурсом, так как данные уже были получены (или другое соединение еще открыто и ожидает ответа). Но не всегда достаточно сравнить строки двух URL, чтобы это понять. Нормализация — это процедура, необходимая для определения эквивалентности синтаксически различных URL-адресов.
Процесс нормализации — это целый набор преобразований, применяемых к исходному URL и его компонентам. Вот только некоторые из них:
- Схема и хост не чувствительны к регистру, поэтому их стоит конвертировать в нижний.
- Все символы с процентным указателем (например "%3A") должны быть приведены в верхний регистр.
- Порт по умолчанию (80 для HTTP) может быть удален.
- Фрагмент (#) никогда не виден серверу и тоже может быть удален.
Всегда можно взять что-то готовое (например normalize-url) или написать свою простую функцию, покрывающую наиболее важные и частые случаи:
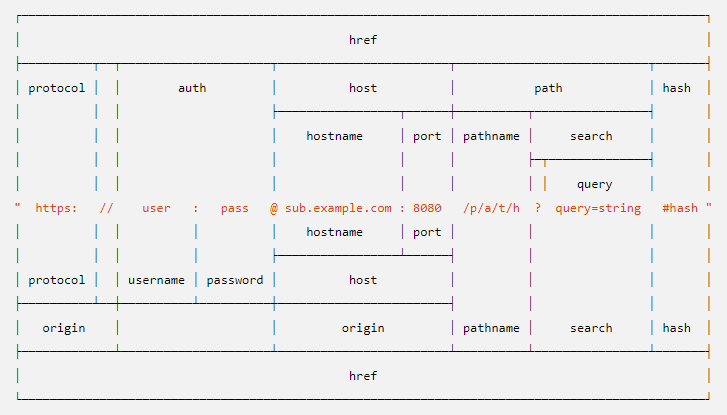
function normalize(dst) {
let dstUrl = new URL(dst);
// ignore userinfo (auth property)
let origin = dstUrl.protocol + '//' + dstUrl.hostname;
// ignore http(s) standart ports
if (dstUrl.port && (!/^https?\:/i.test(dstUrl.protocol) || ![80, 8080, 443].includes(+dstUrl.port))) {
origin += ':' + dstUrl.port;
}
// ignore fragment (hash property)
let path = dstUrl.pathname + dstUrl.search;
// convert origin to lower case
return origin.toLowerCase()
// and capitalize letters in escape sequences
+ path.replace(/%([0-9a-f]{2})/ig, (_, es) => '%' + es.toUpperCase());
}
На всякий случай, формат объекта URL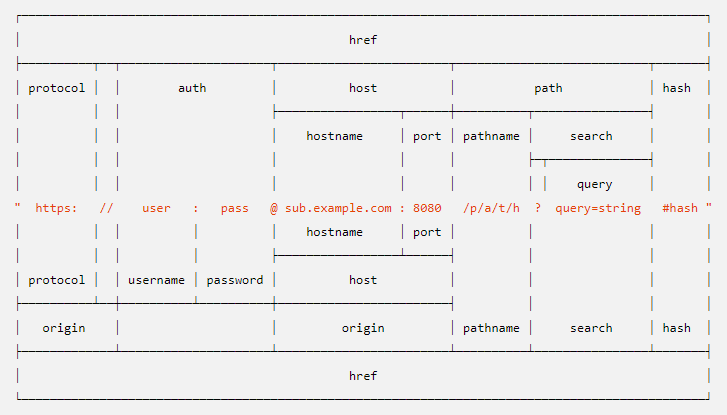
Да, здесь нет сортировки query-параметров, игнорирования utm-меток, обработки _escaped_fragment_ и прочего, чего нам (пока) совершенно не нужно.
Далее заведем локальный кэш запрошенных в рамках краула нормализованных URL. Перед отправкой очередного запроса нормализуем полученный URL, и, если тот отсутствует в кэше, добавим и только тогда отправим новый запрос.
6. Алгоритм работы main-функции
Ключевые компоненты (примитивы) решения уже готовы, пришло время начать собирать все вместе. Для начала определимся с сигнатурой функции crawl: на входе — стартовый URL и ограничение по страницам. Функция возвращает промис, резолв которого предоставляет аккумулированный результат; запишем его в файл output:
crawl(start, limit).then(result => {
fs.writeFile(output, JSON.stringify(result), 'utf8', err => {
if (err) throw err;
});
});
Простейшая схема рекурсивной работы функции краула может быть описана шагами:
1. Инициализация кэша и объекта результата
2. ЕСЛИ URL целевой страницы (через normalize) отсутствует в кэше, ТО
— 2.1. ЕСЛИ достигнут limit, ТО КОНЕЦ (ждать результат)
— 2.2. Добавить URL в кэш
— 2.3. Сохранить ссылку между источником и целевой страницей в результат
— 2.4. Отправить асинхронный запрос за страницей (fetch)
— 2.5. ЕСЛИ запрос выполнился успешно, ТО
— — 2.5.1. Экстрагировать новые ссылки из результата (extract)
— — 2.5.2. Для каждой новой ссылки выполнить алгоритм 2-3
— 2.6. ИНАЧЕ пометить страницу состоянием ошибки
— 2.7. Сохранить данные о странице в результат
— 2.8. ЕСЛИ это была последняя страница, ТО ВЕРНУТЬ результат
3. ИНАЧЕ сохранить ссылку между источником и целевой страницей в результат
Да, этот алгоритм будет претерпевать серьезные изменения в дальнейшем. Сейчас же умышленно используется рекурсивное решение в лоб, чтобы позже лучше «прочувствовать» разницу в реализациях. Заготовка для имплементации функции выглядит так:
function crawl(start, limit = 100) {
// initialize cache & result
return new Promise((resolve, reject) => {
function curl(src, dst) {
// check dst in the cache & pages limit
// save the link (src -> dst) to the result
fetch(dst).then(fetched => {
extract(fetched, dst, start).forEach(ln => curl(dst, ln));
}).finally(() => {
// save the page's data to the result
// check completion and resolve the result
});
}
curl(null, start);
});
}
Достижение лимита страниц проверяется простым счетчиком запросов. Второй счетчик — количество активных запросов в момент времени — послужит проверкой готовности отдать результат (когда значение оборачивается в ноль). Если функции fetch не удалось получить очередную страницу, то для нее Status Code выставим как null.
С кодом имплементации можно (не обязательно) ознакомиться здесь, но перед этим стоит рассмотреть формат возвращаемого результата.
7. Возвращаемый результат
Введем уникальный идентификатор id с простым инкрементом для опрошенных страниц:
let id = 0;
let cache = {};
// ...
let dstNorm = normalize(dst);
if (dstNorm in cache === false) {
cache[dstNorm] = ++id;
// ...
}
Для результата заведем массив pages, в который будем складывать объекты с данными по странице: id {number}, url {string} и code {number|null} (этого сейчас достаточно). Также заведем массив links для ссылок между страницами в виде объекта: from (id страницы-источника), to (id целевой страницы).
Для информативности перед резолвом результата отсортируем список страниц по возрастанию id (ведь ответы будут приходить в каком-угодно порядке), дополним результат числом просканированных страниц count и флагом о достижении заданного лимита fin:
resolve({
pages: pages.sort((p1, p2) => p1.id - p2.id),
links: links.sort((l1, l2) => l1.from - l2.from || l1.to - l2.to),
count,
fin: count < limit
});
Пример использования
Готовый краулер-скрипт имеет следующий синопсис:
node crawl-cli.js --start="<URL>" [--output="<filename>"] [--limit=<int>]
Дополнив логированием ключевых точек процесса, увидим такую картину при запуске:
$ node crawl-cli.js --start="https://google.com" --limit=20
[2019-02-26T19:32:10.087Z] Start crawl "https://google.com" with limit 20
[2019-02-26T19:32:10.089Z] Request (#1) "https://google.com/"
[2019-02-26T19:32:10.721Z] Fetched (#1) "https://google.com/" with code 301
[2019-02-26T19:32:10.727Z] Request (#2) "https://www.google.com/"
[2019-02-26T19:32:11.583Z] Fetched (#2) "https://www.google.com/" with code 200
[2019-02-26T19:32:11.720Z] Request (#3) "https://play.google.com/?hl=ru&tab=w8"
[2019-02-26T19:32:11.721Z] Request (#4) "https://mail.google.com/mail/?tab=wm"
[2019-02-26T19:32:11.721Z] Request (#5) "https://drive.google.com/?tab=wo"
...
[2019-02-26T19:32:12.929Z] Fetched (#11) "https://www.google.com/advanced_search?hl=ru&authuser=0" with code 200
[2019-02-26T19:32:13.382Z] Fetched (#19) "https://translate.google.com/" with code 200
[2019-02-26T19:32:13.782Z] Fetched (#14) "https://plus.google.com/108954345031389568444" with code 200
[2019-02-26T19:32:14.087Z] Finish crawl "https://google.com" on count 20
[2019-02-26T19:32:14.087Z] Save the result in "result.json"
А вот результат в формате JSON:
{
"pages": [
{ "id": 1, "url": "https://google.com/", "code": 301 },
{ "id": 2, "url": "https://www.google.com/", "code": 200 },
{ "id": 3, "url": "https://play.google.com/?hl=ru&tab=w8", "code": 302 },
{ "id": 4, "url": "https://mail.google.com/mail/?tab=wm", "code": 302 },
{ "id": 5, "url": "https://drive.google.com/?tab=wo", "code": 302 },
// ...
{ "id": 19, "url": "https://translate.google.com/", "code": 200 },
{ "id": 20, "url": "https://calendar.google.com/calendar?tab=wc", "code": 302 }
],
"links": [
{ "from": 1, "to": 2 },
{ "from": 2, "to": 3 },
{ "from": 2, "to": 4 },
{ "from": 2, "to": 5 },
// ...
{ "from": 12, "to": 19 },
{ "from": 19, "to": 8 }
],
"count": 20,
"fin": false
}
Что с этим уже можно делать? Как минимум, по списку страниц можно найти все битые страницы сайта. А имея информацию о внутренней перелинковке, можно обнаружить длинные цепочки (и замкнутые циклы) редиректов или найти наиболее важные страницы по ссылочной массе.
Анонс 2.0
У нас получился вариант простейшего консольного краулера, который обходит страницы одного сайта. Исходный код лежит здесь. Там же есть еще пример и юнит-тесты для некоторых функций.
Сейчас это бесцеремонный отправитель запросов и следующим разумным шагом будет — научить его хорошим манерам. Речь пойдет о заголовке User-agent, правилах robots.txt, директиве Crawl-delay и прочем. С точки зрения реализации, это первым делом организация очереди сообщений и далее обслуживание большей нагрузки. Если, конечно, этот материал будет интересным!
