Привет, Хабр! В этом посте мы напишем приложение на Spring Boot 2 с использованием Apache Kafka под Linux, от установки JRE до работающего микросервисного приложения.
Коллеги из отдела фронтэнд-разработки, увидевшие статью, сетуют на то, что я не объясняю, что такое Apache Kafka и Spring Boot. Я полагаю, что всякий, кому понадобится собрать готовый проект с использованием вышеперечисленных технологий, знают, что это и зачем они им нужны. Если для читателя вопрос не праздный, вот отличные статьи на Хабре, что такое Apache Kafka и Spring Boot.
Мы же обойдёмся без пространных объяснений, что такое Kafka, Spring Boot и Linux, а вместо этого запустим Kafka-сервер с нуля на Linux-машине, напишем два микросервиса и сделаем так, чтобы одно из них посылало сообщения на другое — в общем, настроим полноценную микросервисную архитектуру.

Пост будет состоять из двух разделов. В первом мы настроим и запустим Apache Kafka на Linux-машине, во втором — напишем два микросервиса на Java.
В стартапе, в котором я начинал свой профессиональный путь программиста, были микросервисы на Kafka, и один из моих микросервисов тоже работал с другими через Kafka, но я не знал, как работает сам сервер, был ли он написан как приложение или это уже полностью коробочный продукт. Каково же было моё удивление и разочарование, когда выяснилось, что Kafka — всё-таки коробочный продукт, и моей задачей будет не только написание клиента на Java (что я обожаю делать), а также деплой и настройка готового приложения в качестве devOps (что я ненавижу делать). Впрочем, если даже я смог поднять на виртуальном сервере Kafka меньше чем за день, значит, сделать это действительно довольно просто. Итак.
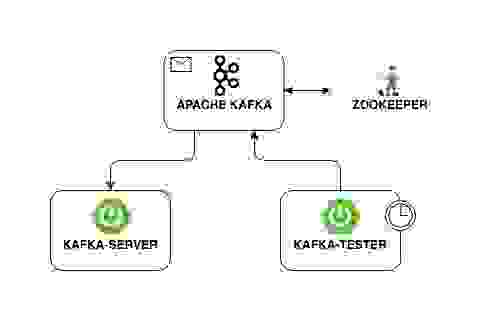
Наше приложение будет иметь следующую структуру взаимодействия:
В конце поста, как обычно, будут ссылки на git с рабочим кодом.
Я пытался поднять Kafka на локальном линуксе, на маке и на удалённом линуксе. В двух случаях (линукс) у меня получилось довольно быстро. С маком пока ничего не вышло. Поэтому поднимать Kafka будем на Linux. Я выбрал Ubuntu 18.04.
Для того, чтобы Kafka заработала, ей нужен Zookeeper. Для этого, Вы должны скачать и запустить его раньше, чем запустите Kafka.
Итак.
Это делается следующими командами:
Если всё прошло ок, то Вы можете ввести команду
и убедиться, что Java установилась.
Я не люблю магических команд на линуксе, особенно когда просто дают несколько команд и непонятно, что они делают. Поэтому я буду описывать каждое действие — что конкретно оно делает. Итак, нам надо скачать Zookeeper и распаковать его в удобную папку. Желательно, если все приложения будут храниться в папке /opt, то есть, в нашем случае, это будет /opt/zookeeper.
Я воспользовался командой ниже. Если Вы знаете другие команды на Linux, которые, на Ваш взгляд, позволят это сделать более расово правильно, воспользуйтесь ими. Я же разработчик, а не девопс, и с серверами общаюсь на уровне «сам козёл». Итак, качаем приложение:
Приложение скачается в ту папку, которую Вы укажете, я создал папку /home/xpendence/downloads для скачивания туда всех нужных мне приложений.
Я воспользовался командой:
Эта команда распаковывает архив в ту папку, в которой Вы находитесь. Возможно, Вам потом придётся перенести приложение в /opt/zookeeper. А можно сразу перейти в неё и оттуда уже распаковать архив.
В папке /zookeeper/conf/ есть файл zoo-sample.cfg, предлагаю переименовать его в zoo.conf, именно этот файл будет искать JVM при запуске. В этот файл нужно в конце дописать следующее:
Также, создайте директорию /var/zookeeper.
Переходим в папку /opt/zookeeper и запускаем сервер командой:
Должна появиться надпись «STARTED».
После чего, предлагаю проверить, что сервер заработал. Пишем:
Должно появиться сообщение, что коннект удался. Если у Вас слабый сервер и сообщение не появилось, повторите попытку — даже когда появилась надпись STARTED, приложение начинает слушать порт намного позже. Когда я испытывал всё это на слабом сервере, у меня случалось это каждый раз. Если всё подключилось, вводим команду
Что означает: «Ты ок?» Сервер должен ответить:
и отключиться. Значит, всё по плану. Переходим к запуску Apache Kafka.
Для работы с Kafka нам потребуется отдельный юзер.
Существует два дистрибутива — бинарный и sources. Нам нужен бинарный. С виду архив с бинарником отличается размером. Бинарник весит 59 МБ, сорцы весят 6,5 МБ.
Качаем бинарник в нужную там директорию по ссылке ниже:
Процедура распаковки ничем не отличается от такой же для Zookeeper. Мы также распаковываем архив в директорию /opt и переименовываем в kafka, чтобы путь к папке /bin был /opt/kafka/bin
Настройки находятся в /opt/kafka/config/server.properties. Добавляем одну строчку:
Эта настройка вроде не является обязательной, работает и без неё. Эта настройка позволяет удалять топики. Иначе, Вы просто не сможете удалять топики через командную строку.
Вводим команду, после которой Kafka должен запуститься:
Если в лог не посыпались привычные эксепшены (Kafka написана на Java и Scala), значит, всё заработало и можно протестировать наш сервис.
Я взял для опытов над Apache Kafka слабый сервер с одним ядром и 512 Мб оперативки (зато всего за 99 рублей), что обернулось для меня несколькими проблемами.
Нехватка памяти. Конечно, с 512 Мб не разгонишься, и сервер не смог развернуть Kafka из-за нехватки памяти. Дело в том, что по умолчанию Kafka потребляет 1 Гб памяти. Неудивительно, что ему не хватило :)
Заходим в kafka-server-start.sh, zookeeper-server-start.sh. Там уже есть строчка, регулирующая память:
Меняем её на:
Это сократит аппетиты Kafka и позволит запустить сервер.
Вторая проблема слабого компьютера — нехватка времени на подключение к Zookeeper. По умолчанию на это даётся 6 секунд. Если железо слабое, этого, конечно, не хватит. В server.properties увеличиваем время подключения к зукиперу:
Я поставил полминуты.
Для этого мы откроем два терминала, на одном запустим продюсер, на другом — консьюмер.
В первой консоли вводим по одной строчке:
Должен появиться вот такой значок, означающий, что продюсер готов спамить сообщения:
Во второй консоли вводим команду:
Теперь, набирая текст в консоли-продюсере, при нажатии на Enter, он будет появляться в консоли-консьюмере.
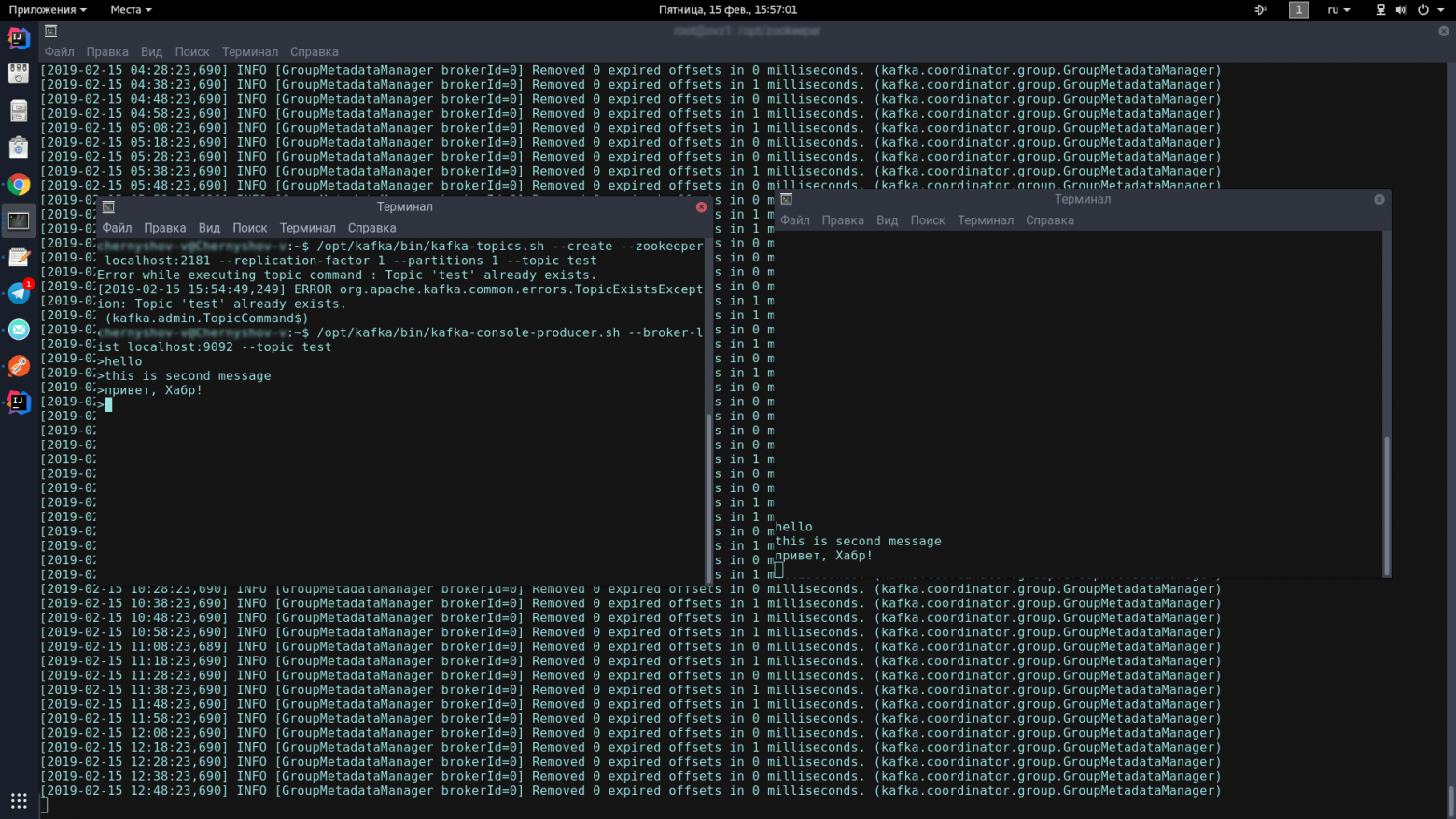
Если Вы видите на экране приблизительно то же, что и я — поздравляю, самое страшное позади!

Теперь нам осталось написать пару клиентов на Spring Boot, которые будут общаться друг с другом через Apache Kafka.
Мы напишем два приложения, которые будут обмениваться сообщениями через Apache Kafka. Первое сообщение будет называться kafka-server и будет содержать в себе и продюсер, и консьюмер. Второе будет называться kafka-tester, оно предназначено, чтобы у нас была микросервисная архитектура.
Для наших проектов, созданных через Spring Initializr, нам потребуется модуль Kafka. Я дополнительно добавил Lombok и Web, но это уже дело вкуса.
Kafka-клиент состоит из двух компонентов — продюсера (он отправляет сообщения на Kafka-сервер) и консьюмера (слушает Kafka-сервер и берёт оттуда новые сообщения по тем темам, на которые он подписан). Наша задача — написать оба компонента и заставить их работать.
Consumer:
Нам потребуется 2 поля, инициализированных статическими данными из kafka.properties.
kafka.server — это адрес, на котором висит наш сервер, в данном случае, локальный. По умолчанию Kafka слушает порт 9092.
kafka.group.id — это группа консьюмеров, в рамках которой доставляется один экземпляр сообщения. Например, у Вас есть три консьюмера в одной группе, и все они слушают одну тему. Как только на сервере появляется новое сообщение с данной темой, оно доставляется кому-то одному из группы. Остальные два консьюмера сообщение не получают.
Далее, мы создаём фабрику консьюмеров — ConsumerFactory.
Проинициализированная нужными нам свойствами, она будет служить стандартной фабрикой консьюмеров в дальнейшем.
consumerConfigs — это просто Map конфигов. Мы указываем адрес сервера, группу и десериализаторы.
Далее, один из самых важных моментов для консьюмера. Консьюмер может получать как единичные объекты, так и коллекции — например, как StarshipDto, так и List. И если StarshipDto мы получаем как JSON, то List мы получаем как, грубо говоря, как JSON-массив. Поэтому у нас как минимум две фабрики сообщений — для одиночных сообщений и для массивов.
Мы создаём экземпляр ConcurrentKafkaListenerContainerFactory, типизированный Long (ключ сообщения) и AbstractDto (абстрактное значение сообщения) и инициализируем его поля свойствами. Фабрику мы, понятно, инициализируем нашей стандартной фабрикой (которая уже содержит Map конфигов), далее помечаем, что не слушаем пакеты (те самые массивы) и указываем в качестве конвертера простой конвертер из JSON.
Когда же мы создаём фабрику для пакетов/массивов (batch), то главное отличие (не считая того, что мы помечаем, что слушаем именно пакеты) заключается в том, что мы указываем в качестве конвертера специальный конвертер пакетов, который будет конвертировать пакеты, состоящие из JSON-строк.
И ещё один момент. При инициализации бинов Spring может не досчитаться бина под именем kafkaListenerContainerFactory и запороть запуск приложения. Наверняка есть более изящные варианты решения проблемы, пишите о них в комментариях, я же пока просто создал не обременённый функционалом бин с таким названием:
Консьюмер настроен. Переходим к продюсеру.
Из статических переменных нам потребуются адрес kafka-сервера и ID продюсера. Он может быть любым.
В конфигах, как мы видим, ничего особенного нет. Почти то же самое. Но в отношении фабрик есть существенное различие. Мы должны прописать шаблон для каждого класса, объекты которого мы будем отправлять на сервер, а также, фабрику для него. У нас такая пара одна, но их могут быть десятки.
В шаблоне мы помечаем, что будем сериализовать объекты в JSON, и этого, пожалуй, достаточно.
У нас есть консьюмер и продюсер, осталось написать сервис, который будет отправлять сообщения и получать их.
В нашем сервисе всего два метода, их нам хватит для объяснения работы клиента. Мы автовайрим нужные нам шаблоны:
Метод-продюсер:
Всё, что требуется для того, чтобы отправить сообщение на сервер — это вызвать метод send у шаблона и передать туда топик (тему) и наш объект. Объект будет сериализован в JSON и под указанным топиком улетит на сервер.
Слушающий метод выглядит так:
Мы помечаем такой метод аннотацией @KafkaListener, где указываем любой ID, который нам нравится, слушаемые топики и фабрику, которая будет конвертировать полученное сообщение в то, что нам нужно. В данном случае, поскольку мы принимаем один объект, нам нужен singleFactory. Для List<?> указываем batchFactory. В итоге, мы отправляем объект на kafka-сервер при помощи метода send и получаем его при помощи метода consume.
Можно за 5 минут написать тест, который позволит продемонстрировать всю силу Kafka, но мы пойдём дальше — потратим 10 минут и напишем ещё одно приложение, которое будет отправлять на сервер сообщения, которые будет слушать наше первое приложение.
Имея опыт написания первого приложения, мы легко можем написать второе, особенно если скопипастить проперти и пакет dto, прописать только продюсер (мы будем только отправлять сообщения) и добавить в сервис единственный метод send. По ссылке ниже Вы легко сможете скачать код проекта и убедиться, что ничего сложного там нет.
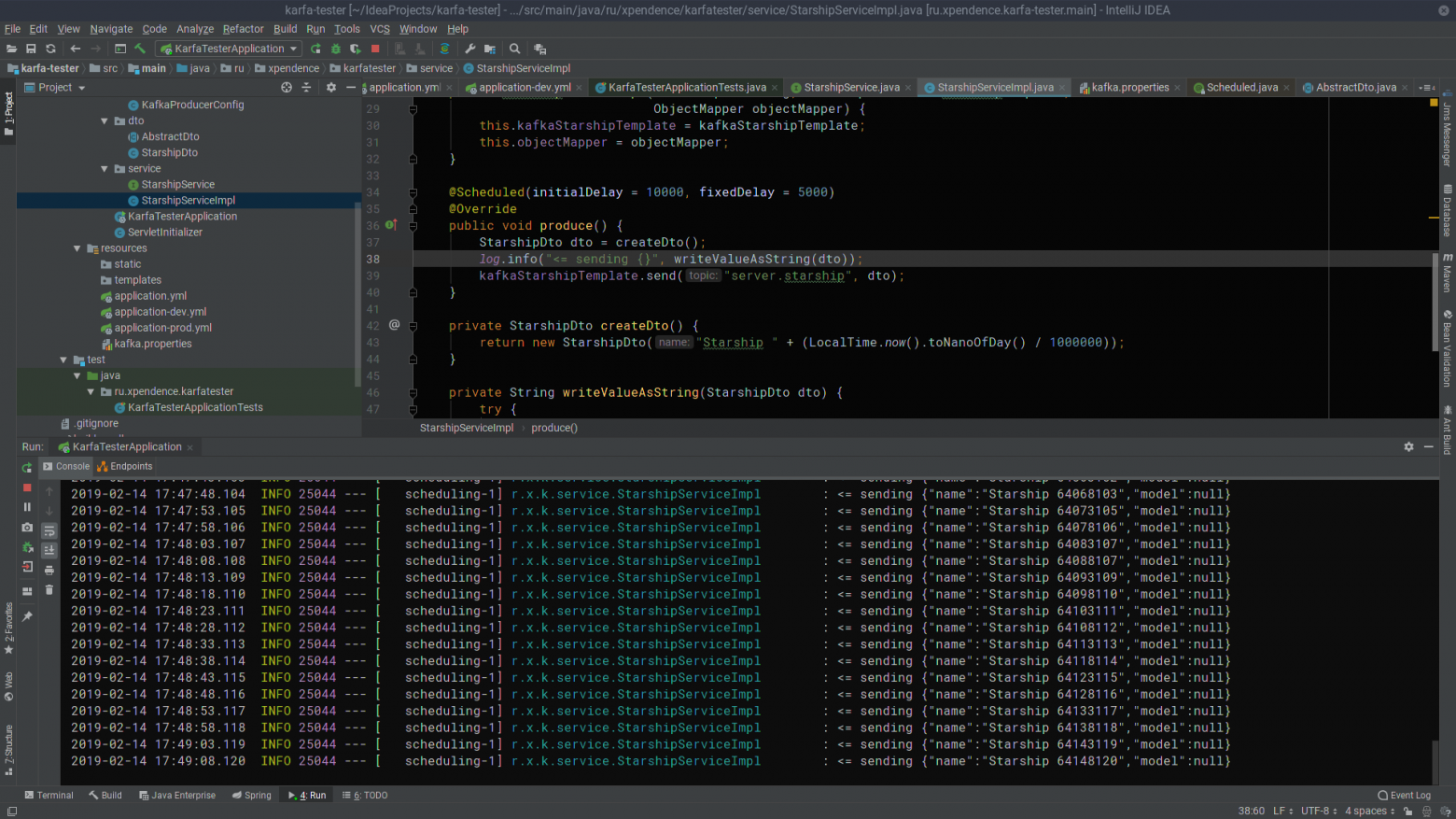
По истечении первых 10 секунд kafka-tester начинает каждые 5 секунд слать сообщения с названиями звездолётов на сервер Kafka (картинка кликабельна).
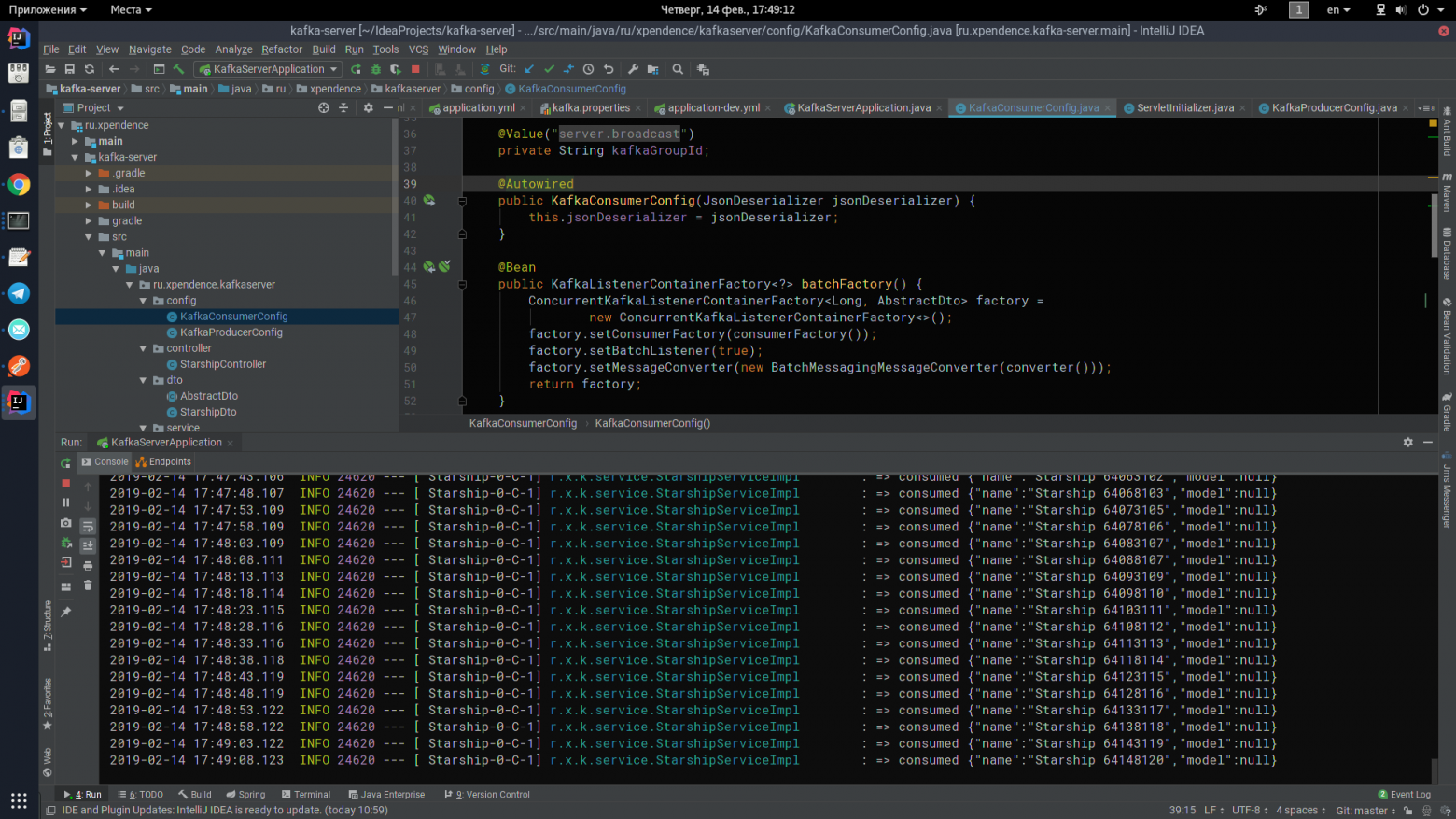
Там их слушает и получаает kafka-server (картинка так же кликабельна).
Надеюсь, у мечтающих начать писать микросервисы на Кафке получится так же легко, как это получилось у меня. А вот ссылки на проекты:
→ kafka-server
→ kafka-tester
Коллеги из отдела фронтэнд-разработки, увидевшие статью, сетуют на то, что я не объясняю, что такое Apache Kafka и Spring Boot. Я полагаю, что всякий, кому понадобится собрать готовый проект с использованием вышеперечисленных технологий, знают, что это и зачем они им нужны. Если для читателя вопрос не праздный, вот отличные статьи на Хабре, что такое Apache Kafka и Spring Boot.
Мы же обойдёмся без пространных объяснений, что такое Kafka, Spring Boot и Linux, а вместо этого запустим Kafka-сервер с нуля на Linux-машине, напишем два микросервиса и сделаем так, чтобы одно из них посылало сообщения на другое — в общем, настроим полноценную микросервисную архитектуру.

Пост будет состоять из двух разделов. В первом мы настроим и запустим Apache Kafka на Linux-машине, во втором — напишем два микросервиса на Java.
В стартапе, в котором я начинал свой профессиональный путь программиста, были микросервисы на Kafka, и один из моих микросервисов тоже работал с другими через Kafka, но я не знал, как работает сам сервер, был ли он написан как приложение или это уже полностью коробочный продукт. Каково же было моё удивление и разочарование, когда выяснилось, что Kafka — всё-таки коробочный продукт, и моей задачей будет не только написание клиента на Java (что я обожаю делать), а также деплой и настройка готового приложения в качестве devOps (что я ненавижу делать). Впрочем, если даже я смог поднять на виртуальном сервере Kafka меньше чем за день, значит, сделать это действительно довольно просто. Итак.
Наше приложение будет иметь следующую структуру взаимодействия:

В конце поста, как обычно, будут ссылки на git с рабочим кодом.
Деплой Apache Kafka + Zookeeper на виртуальной машине
Я пытался поднять Kafka на локальном линуксе, на маке и на удалённом линуксе. В двух случаях (линукс) у меня получилось довольно быстро. С маком пока ничего не вышло. Поэтому поднимать Kafka будем на Linux. Я выбрал Ubuntu 18.04.
Для того, чтобы Kafka заработала, ей нужен Zookeeper. Для этого, Вы должны скачать и запустить его раньше, чем запустите Kafka.
Итак.
0. Устанавливаем JRE
Это делается следующими командами:
sudo apt-get update
sudo apt-get install default-jreЕсли всё прошло ок, то Вы можете ввести команду
java -versionи убедиться, что Java установилась.
1. Качаем Zookeeper
Я не люблю магических команд на линуксе, особенно когда просто дают несколько команд и непонятно, что они делают. Поэтому я буду описывать каждое действие — что конкретно оно делает. Итак, нам надо скачать Zookeeper и распаковать его в удобную папку. Желательно, если все приложения будут храниться в папке /opt, то есть, в нашем случае, это будет /opt/zookeeper.
Я воспользовался командой ниже. Если Вы знаете другие команды на Linux, которые, на Ваш взгляд, позволят это сделать более расово правильно, воспользуйтесь ими. Я же разработчик, а не девопс, и с серверами общаюсь на уровне «сам козёл». Итак, качаем приложение:
wget -P /home/xpendence/downloads/ "http://apache-mirror.rbc.ru/pub/apache/zookeeper/zookeeper-3.4.12/zookeeper-3.4.12.tar.gz"Приложение скачается в ту папку, которую Вы укажете, я создал папку /home/xpendence/downloads для скачивания туда всех нужных мне приложений.
2. Распаковываем Zookeeper
Я воспользовался командой:
tar -xvzf /home/xpendence/downloads/zookeeper-3.4.12.tar.gzЭта команда распаковывает архив в ту папку, в которой Вы находитесь. Возможно, Вам потом придётся перенести приложение в /opt/zookeeper. А можно сразу перейти в неё и оттуда уже распаковать архив.
3. Правим настройки
В папке /zookeeper/conf/ есть файл zoo-sample.cfg, предлагаю переименовать его в zoo.conf, именно этот файл будет искать JVM при запуске. В этот файл нужно в конце дописать следующее:
tickTime=2000
dataDir=/var/zookeeper
clientPort=2181Также, создайте директорию /var/zookeeper.
4. Запускаем Zookeeper
Переходим в папку /opt/zookeeper и запускаем сервер командой:
bin/zkServer.sh startДолжна появиться надпись «STARTED».
После чего, предлагаю проверить, что сервер заработал. Пишем:
telnet localhost 2181Должно появиться сообщение, что коннект удался. Если у Вас слабый сервер и сообщение не появилось, повторите попытку — даже когда появилась надпись STARTED, приложение начинает слушать порт намного позже. Когда я испытывал всё это на слабом сервере, у меня случалось это каждый раз. Если всё подключилось, вводим команду
ruokЧто означает: «Ты ок?» Сервер должен ответить:
imok (Я ок!)и отключиться. Значит, всё по плану. Переходим к запуску Apache Kafka.
5. Создаём юзера под Kafka
Для работы с Kafka нам потребуется отдельный юзер.
sudo adduser --system --no-create-home --disabled-password --disabled-login kafka6. Загружаем Apache Kafka
Существует два дистрибутива — бинарный и sources. Нам нужен бинарный. С виду архив с бинарником отличается размером. Бинарник весит 59 МБ, сорцы весят 6,5 МБ.
Качаем бинарник в нужную там директорию по ссылке ниже:
wget -P /home/xpendence/downloads/ "http://mirror.linux-ia64.org/apache/kafka/2.1.0/kafka_2.11-2.1.0.tgz"7. Распаковываем Apache Kafka
Процедура распаковки ничем не отличается от такой же для Zookeeper. Мы также распаковываем архив в директорию /opt и переименовываем в kafka, чтобы путь к папке /bin был /opt/kafka/bin
tar -xvzf /home/xpendence/downloads/kafka_2.11-2.1.0.tgz8. Правка настроек
Настройки находятся в /opt/kafka/config/server.properties. Добавляем одну строчку:
delete.topic.enable = trueЭта настройка вроде не является обязательной, работает и без неё. Эта настройка позволяет удалять топики. Иначе, Вы просто не сможете удалять топики через командную строку.
9. Даём доступ юзеру kafka к директориям Kafka
chown -R kafka:nogroup /opt/kafka
chown -R kafka:nogroup /var/lib/kafka10. Долгожданный запуск Apache Kafka
Вводим команду, после которой Kafka должен запуститься:
/opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.propertiesЕсли в лог не посыпались привычные эксепшены (Kafka написана на Java и Scala), значит, всё заработало и можно протестировать наш сервис.
10.1. Проблемы слабого сервера
Я взял для опытов над Apache Kafka слабый сервер с одним ядром и 512 Мб оперативки (зато всего за 99 рублей), что обернулось для меня несколькими проблемами.
Нехватка памяти. Конечно, с 512 Мб не разгонишься, и сервер не смог развернуть Kafka из-за нехватки памяти. Дело в том, что по умолчанию Kafka потребляет 1 Гб памяти. Неудивительно, что ему не хватило :)
Заходим в kafka-server-start.sh, zookeeper-server-start.sh. Там уже есть строчка, регулирующая память:
export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"Меняем её на:
export KAFKA_HEAP_OPTS="-Xmx256M -Xms128M"Это сократит аппетиты Kafka и позволит запустить сервер.
Вторая проблема слабого компьютера — нехватка времени на подключение к Zookeeper. По умолчанию на это даётся 6 секунд. Если железо слабое, этого, конечно, не хватит. В server.properties увеличиваем время подключения к зукиперу:
zookeeper.connection.timeout.ms=30000Я поставил полминуты.
11. Тест работы Kafka-сервера
Для этого мы откроем два терминала, на одном запустим продюсер, на другом — консьюмер.
В первой консоли вводим по одной строчке:
/opt/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
/opt/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic testДолжен появиться вот такой значок, означающий, что продюсер готов спамить сообщения:
>Во второй консоли вводим команду:
/opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginningТеперь, набирая текст в консоли-продюсере, при нажатии на Enter, он будет появляться в консоли-консьюмере.
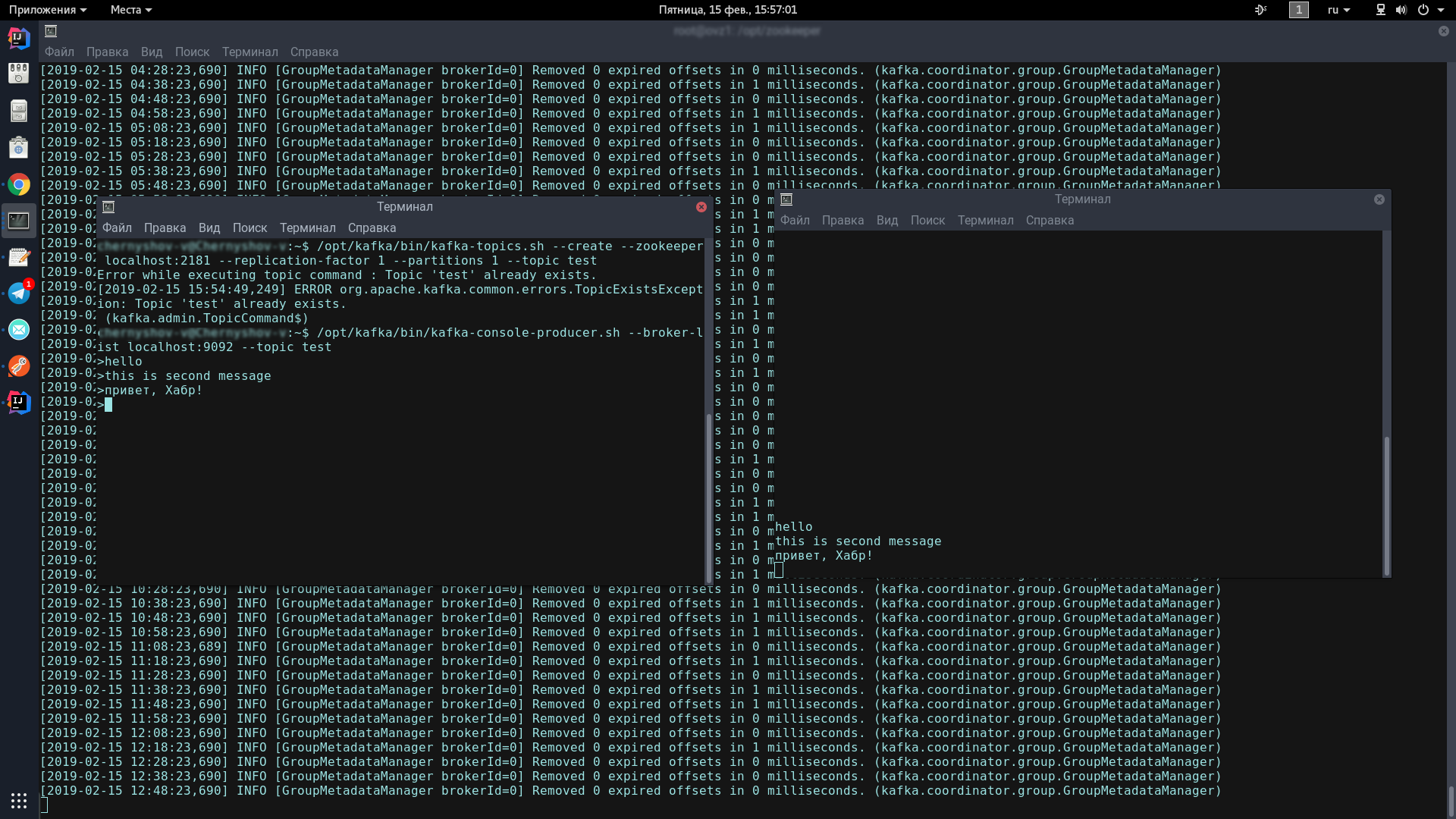
Если Вы видите на экране приблизительно то же, что и я — поздравляю, самое страшное позади!

Теперь нам осталось написать пару клиентов на Spring Boot, которые будут общаться друг с другом через Apache Kafka.
Пишем приложение на Spring Boot
Мы напишем два приложения, которые будут обмениваться сообщениями через Apache Kafka. Первое сообщение будет называться kafka-server и будет содержать в себе и продюсер, и консьюмер. Второе будет называться kafka-tester, оно предназначено, чтобы у нас была микросервисная архитектура.
kafka-server
Для наших проектов, созданных через Spring Initializr, нам потребуется модуль Kafka. Я дополнительно добавил Lombok и Web, но это уже дело вкуса.
Kafka-клиент состоит из двух компонентов — продюсера (он отправляет сообщения на Kafka-сервер) и консьюмера (слушает Kafka-сервер и берёт оттуда новые сообщения по тем темам, на которые он подписан). Наша задача — написать оба компонента и заставить их работать.
Consumer:
@Configuration
public class KafkaConsumerConfig {
@Value("${kafka.server}")
private String kafkaServer;
@Value("${kafka.group.id}")
private String kafkaGroupId;
@Bean
public KafkaListenerContainerFactory<?> batchFactory() {
ConcurrentKafkaListenerContainerFactory<Long, AbstractDto> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.setBatchListener(true);
factory.setMessageConverter(new BatchMessagingMessageConverter(converter()));
return factory;
}
@Bean
public KafkaListenerContainerFactory<?> singleFactory() {
ConcurrentKafkaListenerContainerFactory<Long, AbstractDto> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.setBatchListener(false);
factory.setMessageConverter(new StringJsonMessageConverter());
return factory;
}
@Bean
public ConsumerFactory<Long, AbstractDto> consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
}
@Bean
public KafkaListenerContainerFactory<?> kafkaListenerContainerFactory() {
return new ConcurrentKafkaListenerContainerFactory<>();
}
@Bean
public Map<String, Object> consumerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaServer);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, LongDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.GROUP_ID_CONFIG, kafkaGroupId);
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
return props;
}
@Bean
public StringJsonMessageConverter converter() {
return new StringJsonMessageConverter();
}
}Нам потребуется 2 поля, инициализированных статическими данными из kafka.properties.
kafka.server=localhost:9092
kafka.group.id=server.broadcastkafka.server — это адрес, на котором висит наш сервер, в данном случае, локальный. По умолчанию Kafka слушает порт 9092.
kafka.group.id — это группа консьюмеров, в рамках которой доставляется один экземпляр сообщения. Например, у Вас есть три консьюмера в одной группе, и все они слушают одну тему. Как только на сервере появляется новое сообщение с данной темой, оно доставляется кому-то одному из группы. Остальные два консьюмера сообщение не получают.
Далее, мы создаём фабрику консьюмеров — ConsumerFactory.
@Bean
public ConsumerFactory<Long, AbstractDto> consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
}Проинициализированная нужными нам свойствами, она будет служить стандартной фабрикой консьюмеров в дальнейшем.
@Bean
public Map<String, Object> consumerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaServer);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, LongDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.GROUP_ID_CONFIG, kafkaGroupId);
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
return props;
}consumerConfigs — это просто Map конфигов. Мы указываем адрес сервера, группу и десериализаторы.
Далее, один из самых важных моментов для консьюмера. Консьюмер может получать как единичные объекты, так и коллекции — например, как StarshipDto, так и List. И если StarshipDto мы получаем как JSON, то List мы получаем как, грубо говоря, как JSON-массив. Поэтому у нас как минимум две фабрики сообщений — для одиночных сообщений и для массивов.
@Bean
public KafkaListenerContainerFactory<?> singleFactory() {
ConcurrentKafkaListenerContainerFactory<Long, AbstractDto> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.setBatchListener(false);
factory.setMessageConverter(new StringJsonMessageConverter());
return factory;
}Мы создаём экземпляр ConcurrentKafkaListenerContainerFactory, типизированный Long (ключ сообщения) и AbstractDto (абстрактное значение сообщения) и инициализируем его поля свойствами. Фабрику мы, понятно, инициализируем нашей стандартной фабрикой (которая уже содержит Map конфигов), далее помечаем, что не слушаем пакеты (те самые массивы) и указываем в качестве конвертера простой конвертер из JSON.
Когда же мы создаём фабрику для пакетов/массивов (batch), то главное отличие (не считая того, что мы помечаем, что слушаем именно пакеты) заключается в том, что мы указываем в качестве конвертера специальный конвертер пакетов, который будет конвертировать пакеты, состоящие из JSON-строк.
@Bean
public KafkaListenerContainerFactory<?> batchFactory() {
ConcurrentKafkaListenerContainerFactory<Long, AbstractDto> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.setBatchListener(true);
factory.setMessageConverter(new BatchMessagingMessageConverter(converter()));
return factory;
}
@Bean
public StringJsonMessageConverter converter() {
return new StringJsonMessageConverter();
}И ещё один момент. При инициализации бинов Spring может не досчитаться бина под именем kafkaListenerContainerFactory и запороть запуск приложения. Наверняка есть более изящные варианты решения проблемы, пишите о них в комментариях, я же пока просто создал не обременённый функционалом бин с таким названием:
@Bean
public KafkaListenerContainerFactory<?> kafkaListenerContainerFactory() {
return new ConcurrentKafkaListenerContainerFactory<>();
}Консьюмер настроен. Переходим к продюсеру.
@Configuration
public class KafkaProducerConfig {
@Value("${kafka.server}")
private String kafkaServer;
@Value("${kafka.producer.id}")
private String kafkaProducerId;
@Bean
public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaServer);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, LongSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class);
props.put(ProducerConfig.CLIENT_ID_CONFIG, kafkaProducerId);
return props;
}
@Bean
public ProducerFactory<Long, StarshipDto> producerStarshipFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
@Bean
public KafkaTemplate<Long, StarshipDto> kafkaTemplate() {
KafkaTemplate<Long, StarshipDto> template = new KafkaTemplate<>(producerStarshipFactory());
template.setMessageConverter(new StringJsonMessageConverter());
return template;
}
}Из статических переменных нам потребуются адрес kafka-сервера и ID продюсера. Он может быть любым.
В конфигах, как мы видим, ничего особенного нет. Почти то же самое. Но в отношении фабрик есть существенное различие. Мы должны прописать шаблон для каждого класса, объекты которого мы будем отправлять на сервер, а также, фабрику для него. У нас такая пара одна, но их могут быть десятки.
В шаблоне мы помечаем, что будем сериализовать объекты в JSON, и этого, пожалуй, достаточно.
У нас есть консьюмер и продюсер, осталось написать сервис, который будет отправлять сообщения и получать их.
@Service
@Slf4j
public class StarshipServiceImpl implements StarshipService {
private final KafkaTemplate<Long, StarshipDto> kafkaStarshipTemplate;
private final ObjectMapper objectMapper;
@Autowired
public StarshipServiceImpl(KafkaTemplate<Long, StarshipDto> kafkaStarshipTemplate,
ObjectMapper objectMapper) {
this.kafkaStarshipTemplate = kafkaStarshipTemplate;
this.objectMapper = objectMapper;
}
@Override
public void send(StarshipDto dto) {
kafkaStarshipTemplate.send("server.starship", dto);
}
@Override
@KafkaListener(id = "Starship", topics = {"server.starship"}, containerFactory = "singleFactory")
public void consume(StarshipDto dto) {
log.info("=> consumed {}", writeValueAsString(dto));
}
private String writeValueAsString(StarshipDto dto) {
try {
return objectMapper.writeValueAsString(dto);
} catch (JsonProcessingException e) {
e.printStackTrace();
throw new RuntimeException("Writing value to JSON failed: " + dto.toString());
}
}
}В нашем сервисе всего два метода, их нам хватит для объяснения работы клиента. Мы автовайрим нужные нам шаблоны:
private final KafkaTemplate<Long, StarshipDto> kafkaStarshipTemplate;Метод-продюсер:
@Override
public void send(StarshipDto dto) {
kafkaStarshipTemplate.send("server.starship", dto);
}Всё, что требуется для того, чтобы отправить сообщение на сервер — это вызвать метод send у шаблона и передать туда топик (тему) и наш объект. Объект будет сериализован в JSON и под указанным топиком улетит на сервер.
Слушающий метод выглядит так:
@Override
@KafkaListener(id = "Starship", topics = {"server.starship"}, containerFactory = "singleFactory")
public void consume(StarshipDto dto) {
log.info("=> consumed {}", writeValueAsString(dto));
}Мы помечаем такой метод аннотацией @KafkaListener, где указываем любой ID, который нам нравится, слушаемые топики и фабрику, которая будет конвертировать полученное сообщение в то, что нам нужно. В данном случае, поскольку мы принимаем один объект, нам нужен singleFactory. Для List<?> указываем batchFactory. В итоге, мы отправляем объект на kafka-сервер при помощи метода send и получаем его при помощи метода consume.
Можно за 5 минут написать тест, который позволит продемонстрировать всю силу Kafka, но мы пойдём дальше — потратим 10 минут и напишем ещё одно приложение, которое будет отправлять на сервер сообщения, которые будет слушать наше первое приложение.
kafka-tester
Имея опыт написания первого приложения, мы легко можем написать второе, особенно если скопипастить проперти и пакет dto, прописать только продюсер (мы будем только отправлять сообщения) и добавить в сервис единственный метод send. По ссылке ниже Вы легко сможете скачать код проекта и убедиться, что ничего сложного там нет.
@Scheduled(initialDelay = 10000, fixedDelay = 5000)
@Override
public void produce() {
StarshipDto dto = createDto();
log.info("<= sending {}", writeValueAsString(dto));
kafkaStarshipTemplate.send("server.starship", dto);
}
private StarshipDto createDto() {
return new StarshipDto("Starship " + (LocalTime.now().toNanoOfDay() / 1000000));
}По истечении первых 10 секунд kafka-tester начинает каждые 5 секунд слать сообщения с названиями звездолётов на сервер Kafka (картинка кликабельна).
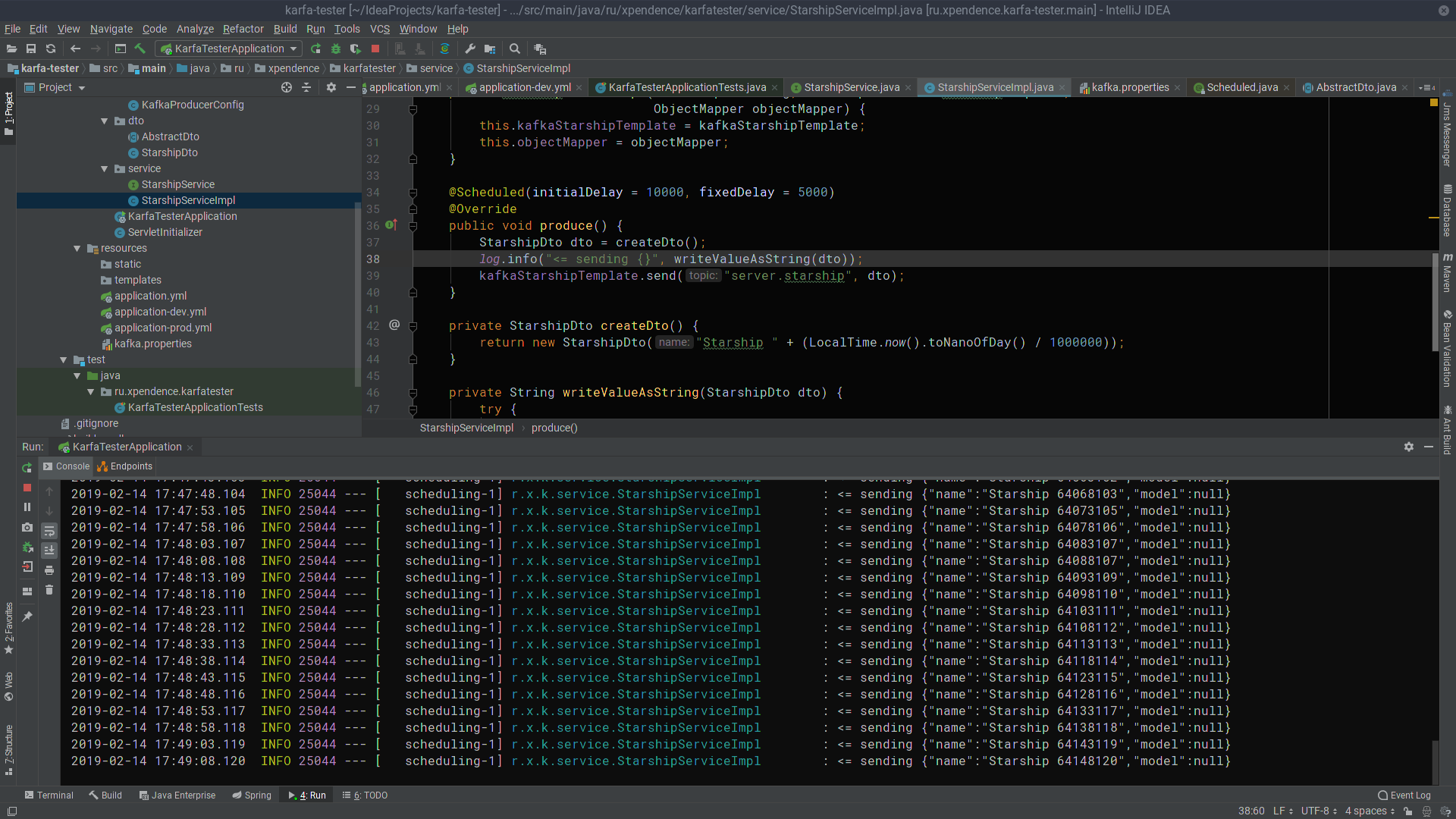
Там их слушает и получаает kafka-server (картинка так же кликабельна).

Надеюсь, у мечтающих начать писать микросервисы на Кафке получится так же легко, как это получилось у меня. А вот ссылки на проекты:
→ kafka-server
→ kafka-tester
