
Слоеная архитектура – это спасение в мире корпоративной разработки. С ее помощью можно разгрузить железо, распараллелить процессы и навести порядок в коде. Мы попробовали использовать паттерн CQRS при разработке корпоративного проекта. Всё стало логичнее и … сложнее. Недавно я рассказал о том, с чем пришлось столкнуться, на митапе Panda-Meetup C# .Net, и вот теперь делюсь с вами.

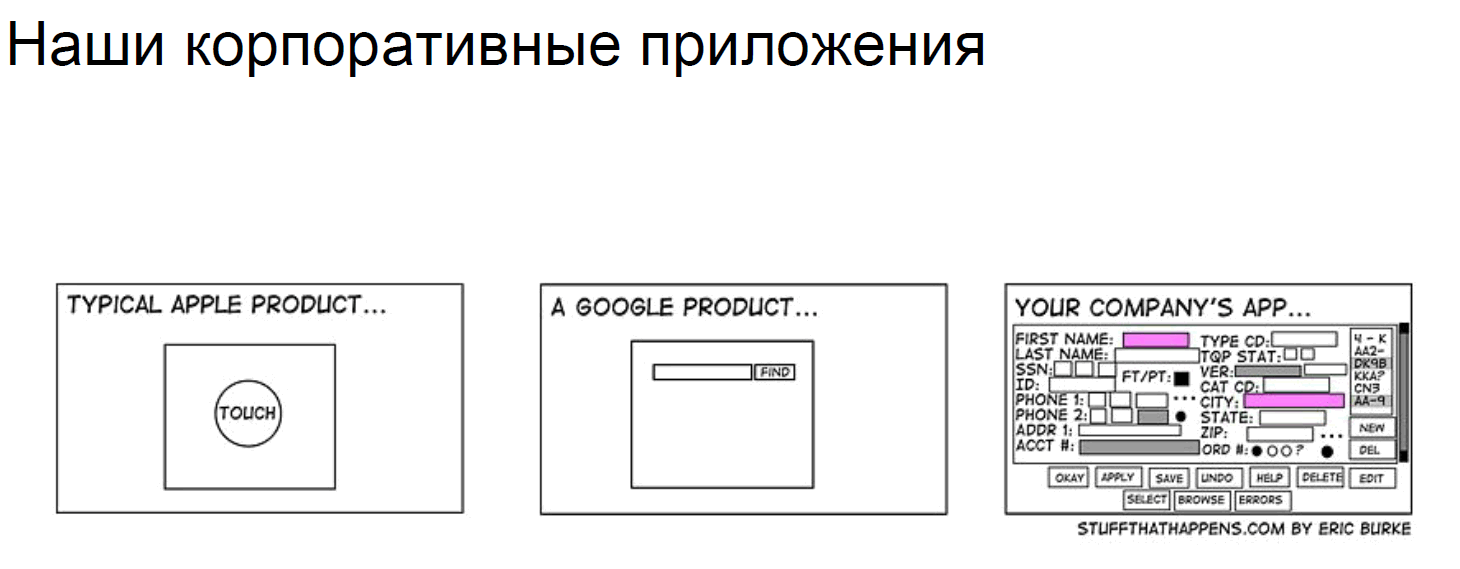
Вы когда-нибудь обращали внимание, как выглядит ваше корпоративное приложение? Почему оно не может быть таким, как у Apple и Google? Да потому что у нас постоянная нехватка времени. Требования меняются часто, срок их изменений обычно «вчера». И что самое неприятное, бизнес очень не любит ошибок.
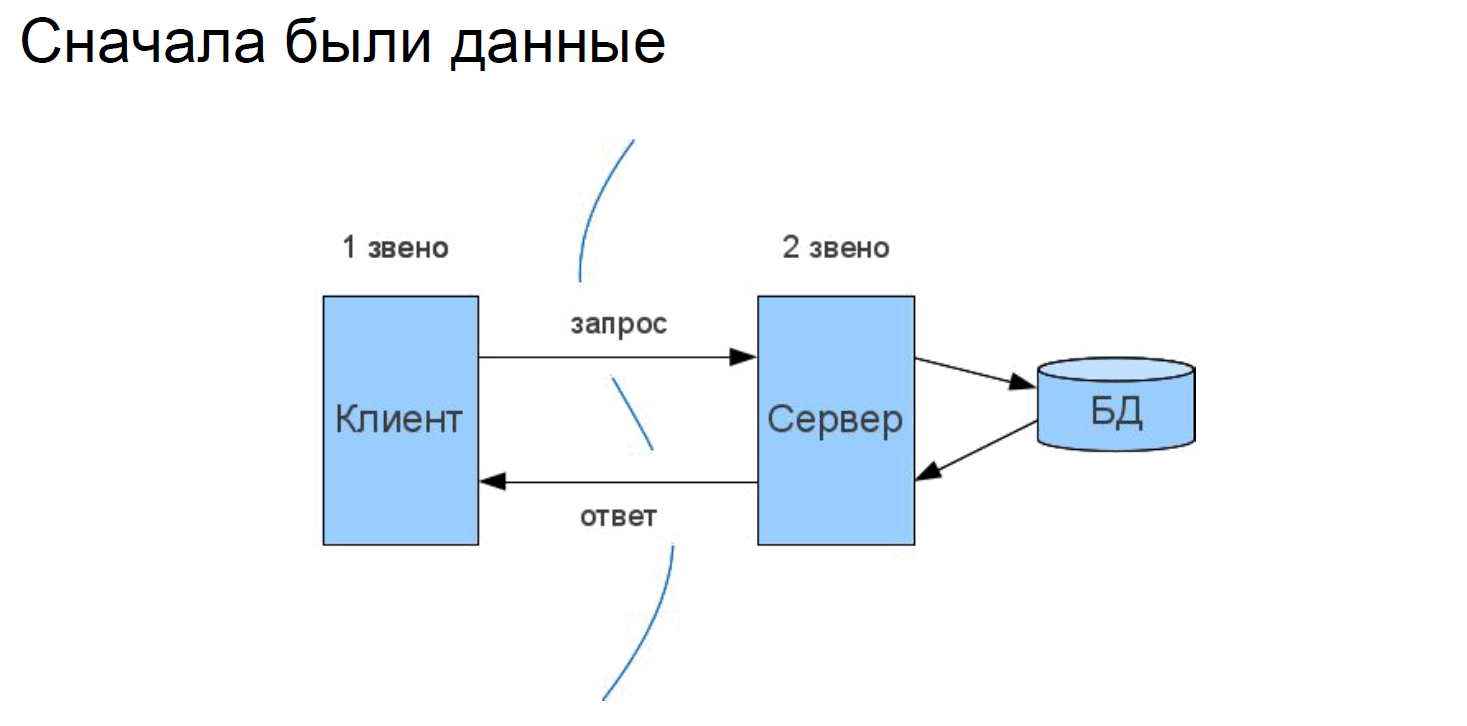
Чтобы как-то с этим жить, разработчики начали делить свои приложения на части. Начиналось все просто – с данных. Многим знакома схема, когда данные отдельно, клиент отдельно, при этом логика хранится там же, где данные.
Хорошая схема. У крупнейших СУБД есть вполне работоспособные процедурные расширения SQL. Про Oracle вообще ходит пословица «Где есть Oracle, там есть логика». Трудно поспорить об удобстве и скорости такой конфигурации.
Но у нас корпоративное приложение, и есть проблема: логику сложно масштабировать. Да и неразумно загружать мощности СУБД, которой и так хватает проблем с извлечением и обновлением данных, еще и тривиальными бизнес-задачами.
Ну и инструменты программирования бизнес-логики, встроенные в СУБД, если честно, слабоваты для создания нормальных корпоративных приложений. Поддерживать бизнес-логику на T-SQL/PL-SQL – это боль. Неспроста ООП-языки так распространились среди корпоративных приложений: C#, Java, за примером далеко ходить не надо.
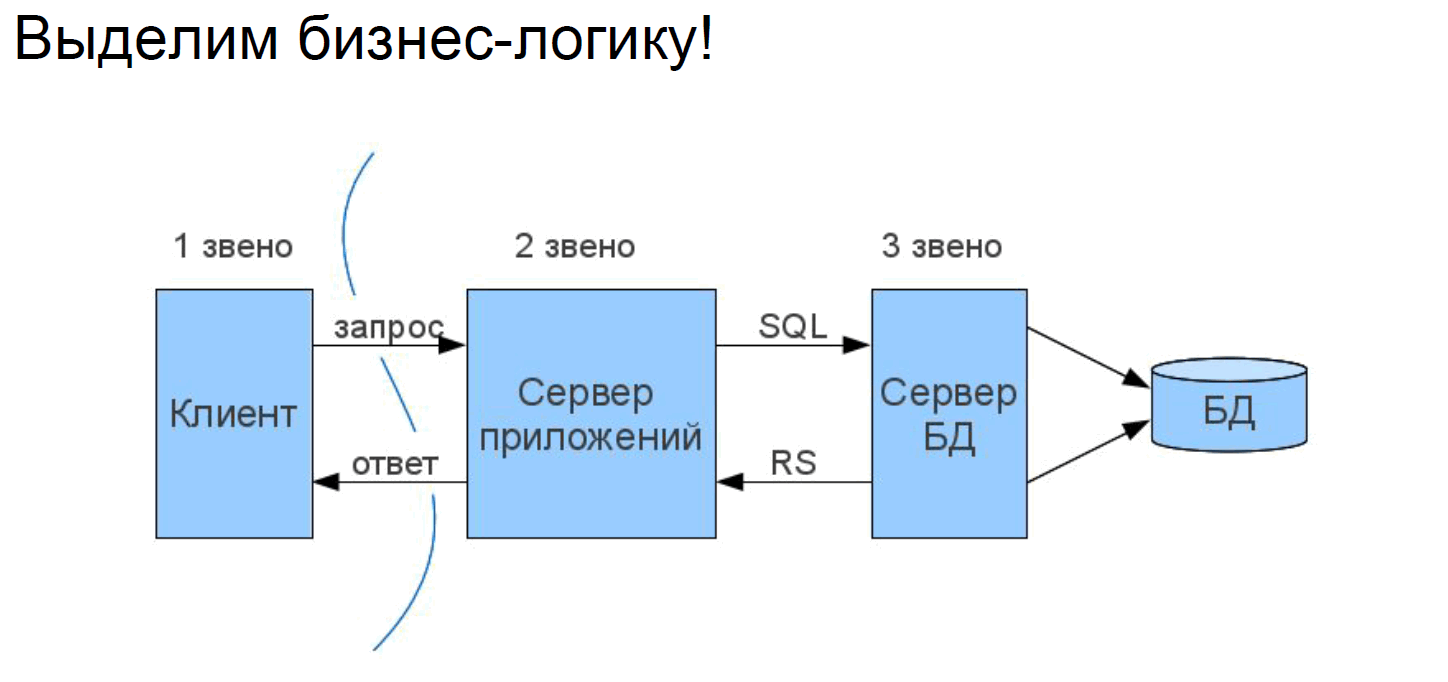
Казалось бы, логичное решение: выделим бизнес-логику. Она будет жить на своем сервере, база – на своем, клиент – отдельно.
Что можно улучшить в этой трехзвенной архитектуре? В слое бизнес-логики замешана архитектура, этого хотелось бы избежать. Бизнес-логика вообще ничего не хочет знать и о хранении данных. UI – это тоже отдельный мир, в котором есть свои сущности, не характерные для бизнес-логики.
Поможет увеличение слоев. Это решение выглядит почти идеально, в нем есть какая-то внутренняя красота.
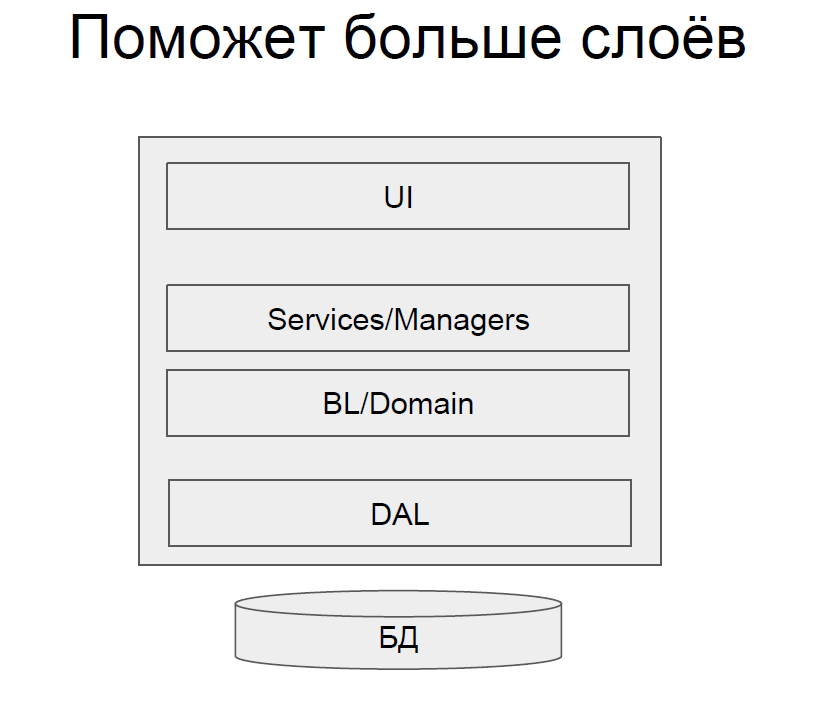
У нас есть DAL (Data Access Layer) – данные отделены от логики, обычно это CRUD репозиторий с применением ORM, плюс хранимые процедуры для сложных запросов. Такой вариант позволяет и разрабатывать достаточно быстро, и иметь приемлемое быстродействие.
Бизнес-логика может идти в составе сервисов или быть отдельным слоем. Взаимодействие между слоями может осуществляться через транспортные объекты (DTO).
Запрос от UI у нас идет на сервис, тот общается с бизнес-логикой, лезет в DAL для доступа к данным. Такой подход называется N-tier, и у него есть явные преимущества.
У каждого слоя свои очевидные цели и задачи, что нам, как программистам, так нравится. Каждый конкретный слой занимается только своим делом. Сервисы можно масштабировать горизонтально. Подход понятен даже начинающему разработчику, человек быстро понимает, как работает система. Очень легко проследить все взаимодействия, как идет запрос от начала до конца.
Еще консистентность: все подсистемы проекта работают с одними данными, вам не нужно беспокоиться, что мы в одном месте записали данные, а в другой части пользователь их не видит.
Ниже пример типичного фрагмента приложения, построенного по этим принципам. У нас есть денежное требование, здесь я рассмотрел Anemic-модель. И есть классический репозиторий, работа с которым идет через ORM.
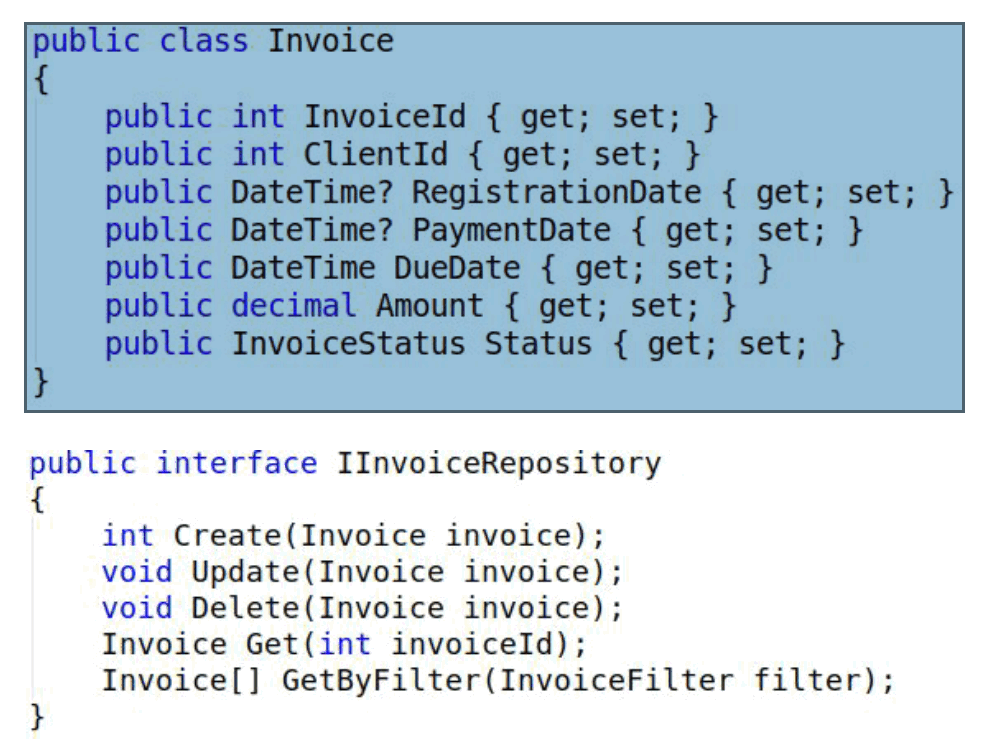
Это типичный сервис, их еще называют менеджерами. Он работает с репозиторием, получает запросы и отдает ответы клиентами. В этом сервисе мы видим некоторую мешанину: у нас есть процесс по обработке, процесс по работе с UI и процесс для каких-то внутренних контролирующих подразделений, они слабо связаны между собой.
Вот как выглядит типичный метод этого сервиса. Например, регистрация денежного требования.
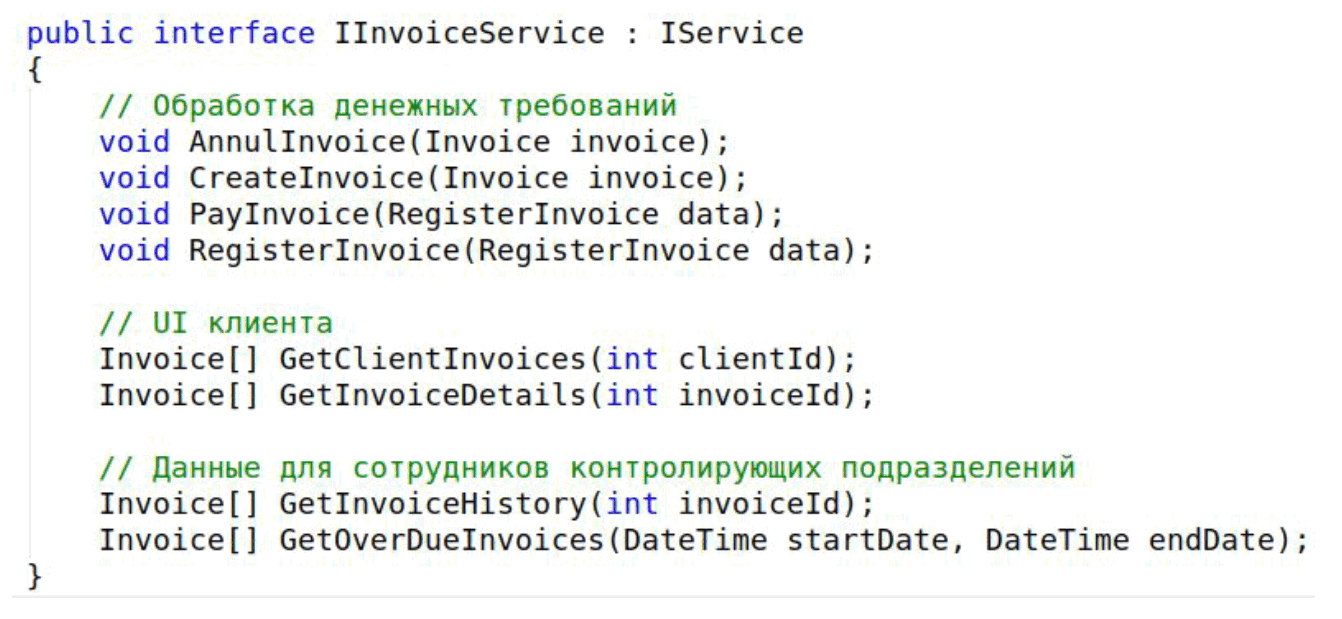
Мы получаем данные, выполняем какие-то бизнес-проверки. Затем идет обновление, а после него — какие-то пост-действия, например, отправка нотификации или запись в юзер лог.
В таком подходе, несмотря на всю его красоту, есть свои проблемы. Очень часто в корпоративных приложениях нагрузка несимметрична: операций чтения на порядок-два больше, чем записи. С масштабированием самой базы данных здесь уже возникает проблема. Конечно, это делается, причем даже средствами СУБД в масштабах базы, называется партиционирование. Но это сложно. Если это сделать не с той квалификацией или сделать раньше, чем это нужно, партиционирования уже не получится.
Например, в одной из наших систем объем данных достиг 25 ТБ, появились проблемы. Мы сами пробовали масштабироваться, пригласили крутых парней из известной компании. Они посмотрели и сказали: нам потребуется 14 часов полного простоя базы. Мы подумали и сказали: ребята, не пойдет, бизнес это не примет.
Помимо объема базы растет и количество методов в сервисах и репозиториях. Например, в сервисе по денежным требованиям более сотни методов. Это сложно поддерживать, возникают постоянные конфликты при merge request, code review проводить тяжелее. А если учесть, что процессы разные, над ними работают разные группы разработчиков, то задача отследить все изменения, связанные с какой-то проблемой, становится настоящей головной болью.
Так что же делать? Есть решение, которое придумали еще в древнем Риме: разделять и властвовать.

Как говорится, все новое — хорошо забытое старое. Еще в 1988 году Бертран Мейер сформулировал принцип императивного программирования CQS – Command-query separation – для работы с объектами. Все методы четко делятся на два типа. Первый – Query – запросы, которые возвращают результат, не изменяя состояние объекта. То есть когда вы смотрите денежные требования клиента, никто в базу не должен писать, что клиент такой-то посмотрел то-то, никаких side-эффектов в запросе не должно быть.
Второй – Commands – команды, которые изменяют состояние объекта, не возвращая данные. То есть вы приказали что-то изменить, и в ответ не ждете отчет на 10 тысяч строк.
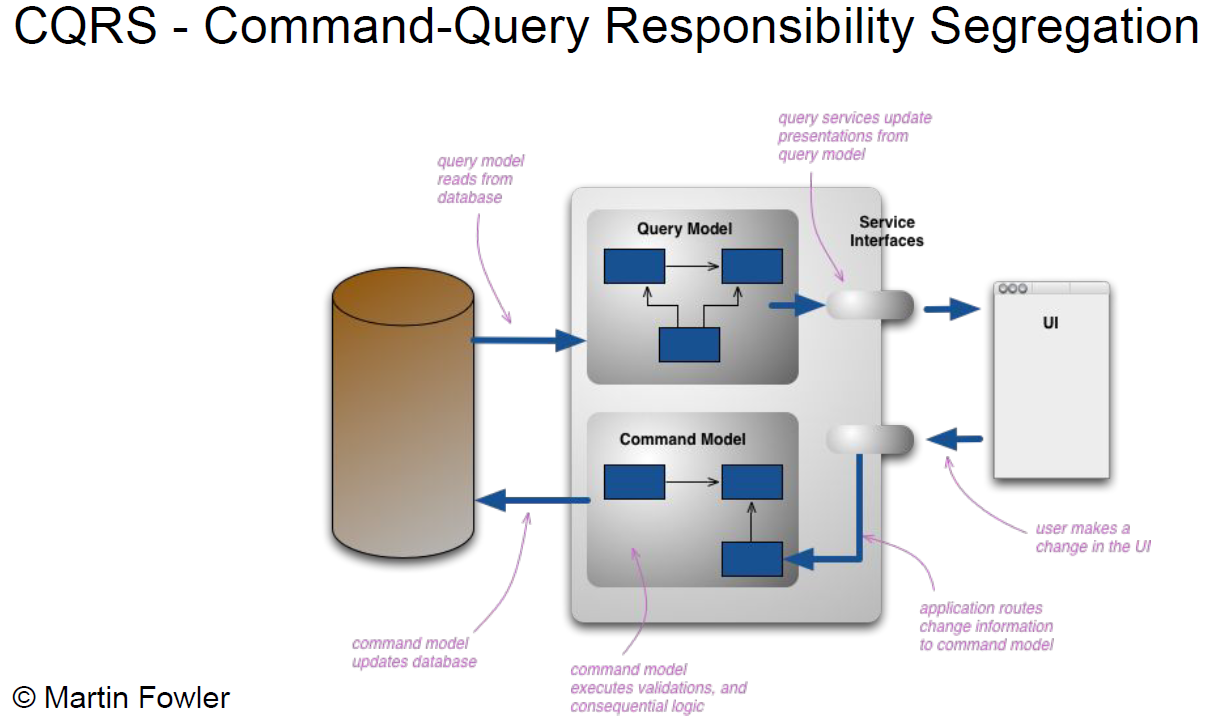
Здесь четко отделена модель данных для чтения от модели для записи. Большая часть бизнес-логики отрабатывает на операциях записи. Чтение же может работать по материализованным представлениям или вообще по другой базе. Их можно разделить и синхронизировать через события или какие-то внутренние службы. Тут много вариантов.
CQRS не сложен. Мы должны четко выделить команды, которые изменяют состояние системы, но при этом ничего не возвращают. Тут подход может быть и более взвешенный. Не особо страшно, если команда вернет результат выполнения: ошибку или, например, идентификатор созданной сущности, то в этом никакого криминала нет. Важно, чтобы команда не занималась работой с запросом, она не должна искать данные и возвращать бизнес-сущности.
Запросы — там все просто. Не изменяет состояние, чтобы не было побочных эффектов. Это означает, что если мы два раза подряд вызвали запрос, и не было других команд, состояние объекта в обоих случаях должно остаться идентичным. Это позволяет параллелить запросы. Интересно, что отдельная модель для запросов не нужна для работы, т.к. нет смысла привлекать для этого бизнес-логику из доменной модели.
Вот что мы хотели сделать в своем проекте:
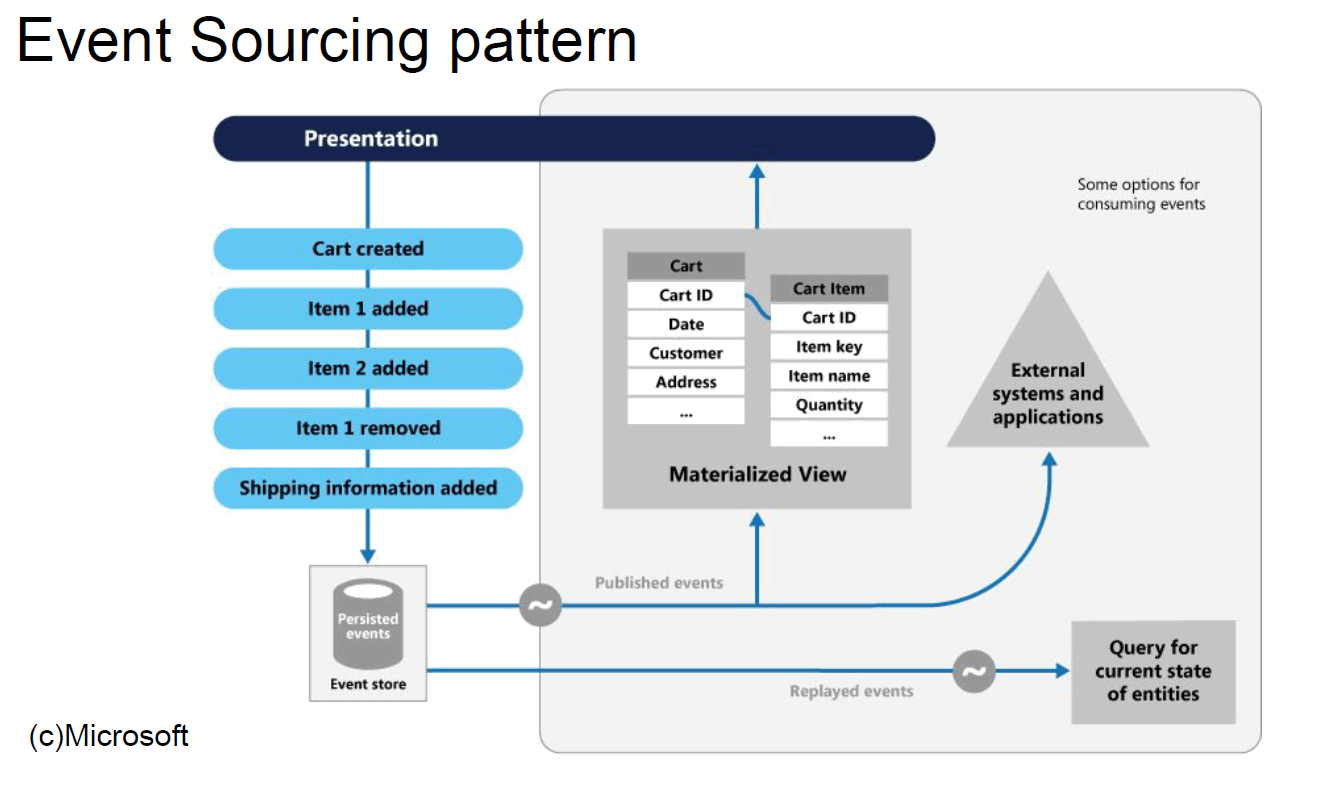
У нас существующее приложение функционирует с 2006 года, у него классическая слоеная архитектура. Старомодная, но до сих пор работающая. Никто ее не хочет менять и даже не знает, на что заменить. Настал момент, когда нужно было разрабатывать что-то новое, с нуля практически. В 2011-2012 году Event Sourcing и CQRS были очень модной темой. Мы подумали, что это классно, что таким образом сможем хранить оригинальное состояние объекта и события, которые к нему привели.
То есть мы как бы не обновляем объект. Есть оригинальное состояние и рядом – то, что к нему применили. В этом случае есть громаднейший плюс — мы можем восстановить состояние объекта на любой момент истории. Фактически, журнал становится не нужен. Поскольку мы храним события, нам понятно, что конкретно случилось. То есть не просто у клиента обновилось значение в ячейке «адрес», у нас будет зафиксировано именно событие, например, переезд клиента.
Понятно, что такая схема работает медленно при получении данных, поэтому у нас есть отдельная база с материальными представлениями для выбора. Ну и синхронизация по событиям: при каждом поступлении событий на изменение состояния происходит публикация. В теории вроде все хорошо, но… Я так и не встретил людей, которые это в полной мере реализовали на продакшене, на высоких нагрузках с приемлемой для бизнеса консистентностью.

Схему можно развить дальше, если разделить обработчики и команды/запросы. Вот, в качестве примера, у нас команда — зарегистрированное денежное требование: имеется дата, сумма, клиент и другие поля.
На обработчик регистрации денежного требования мы ставим ограничение, что он может принимать только нашу команду (where TCommand: ICommand). Мы можем писать обработчики, не меняя старых, просто по методу добавления сложных требований. Например, сначала обнови дату, потом запиши значение, а здесь пошли клиенту уведомление — все это пишется в разных обработчиках на одну команду.
Как же нам все это вызвать? Есть диспетчер, который знает, где у него все эти обработчики хранятся.

Диспетчер передаётся (например, через DI контейнер) в API. И когда приходит команда, он делает только execute. Он знает, где находится контейнер, где команды, и их выполняет. С запросами — аналогично.
В чем проблема такой схемы: все взаимодействия становятся менее очевидными. Мы строим иерархию на типах, которые регистрируются в контейнерах, а потом реагируют на свои команды/запросы. Требуется очень четко спроектировать архитектуру. Любое действие одним методом с одним параметром уже не ограничивается. Вы пишете команду, пишете обработчик, регистрируете в контейнере. Возрастает количество оверхеда. В большом проекте возникают проблемы с элементарной навигацией. Мы решили пойти более классическим путем.
Для асинхронного взаимодействия была использована сервисная шина Rebus.

Для простых задач ее более чем хватает.
CQRS заставляет немного по-другому подойти к коду, сконцентрироваться на процессе, ведь все действия рождаются в рамках процесса. Мы выделили репозиторий для запросов, отдельно сделали команды, относящиеся к обработке, и отдельно запросы, относящиеся к обработке. Для чтения мы не стали использовать отдельный репозиторий, просто в командах работаем с ORM.
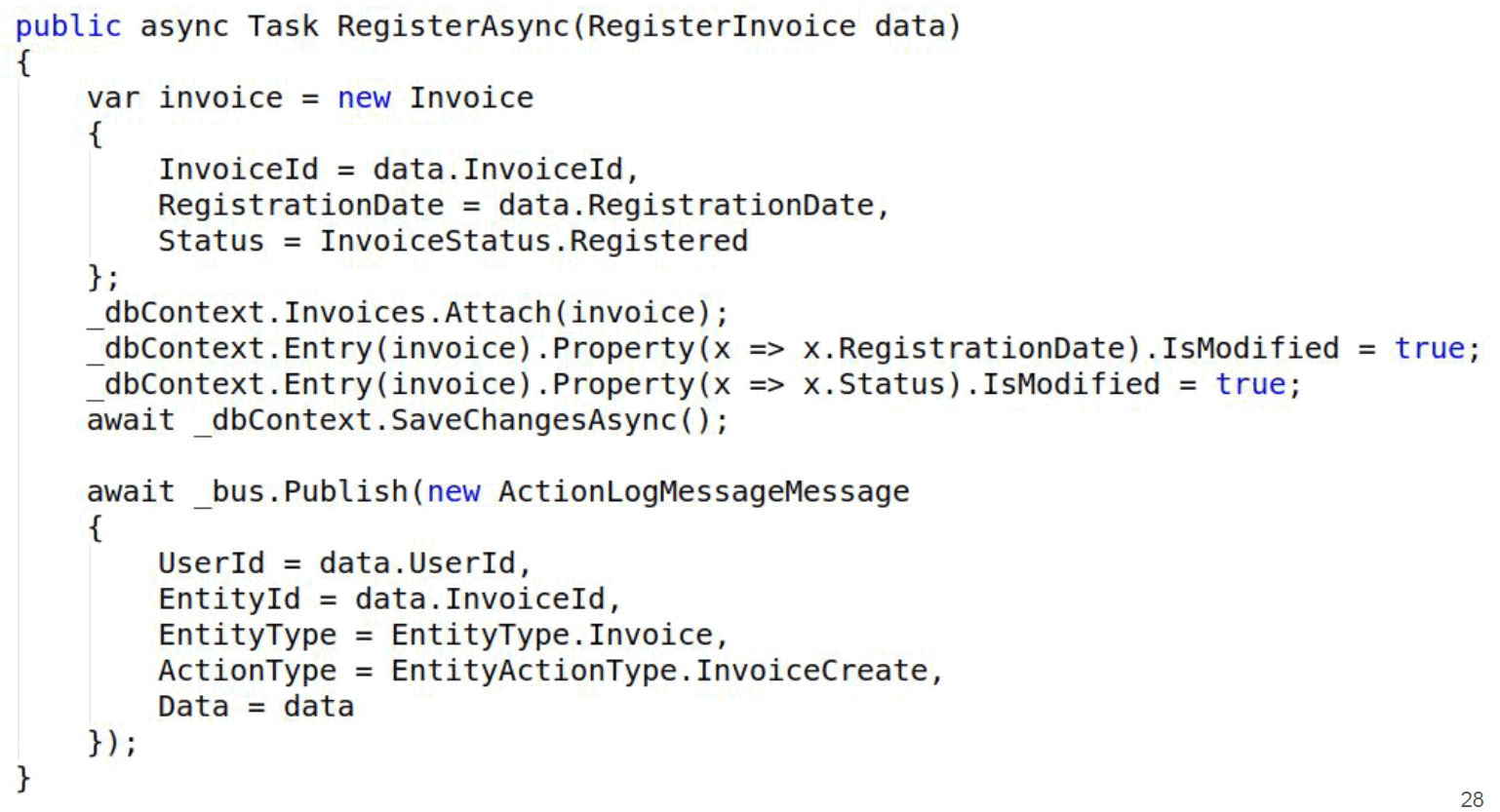
Вот, например, метод, из которого выкинуто все лишнее. В команде регистрации денежного требования мы регистрируем требование и публикуем событие в шину, что зарегистрировано денежное требование.
Кто в этом заинтересован, тот отреагирует на него. Например, там сработает идентификация пользователя и журналирование.
Вот пример запроса. Тоже стало все просто: мы читаем и в репозиторий отдаем.
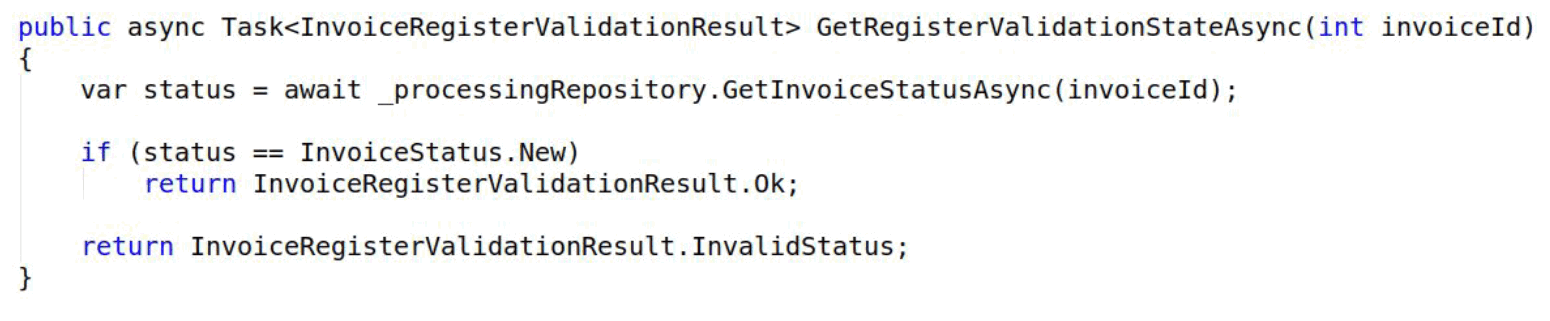
Хочу отдельно остановиться на Rebus.Saga. Это паттерн, который позволяет разбить бизнес-транзакцию на атомарные действия. Это позволяет блокировать не все сразу, а понемногу и по очереди.
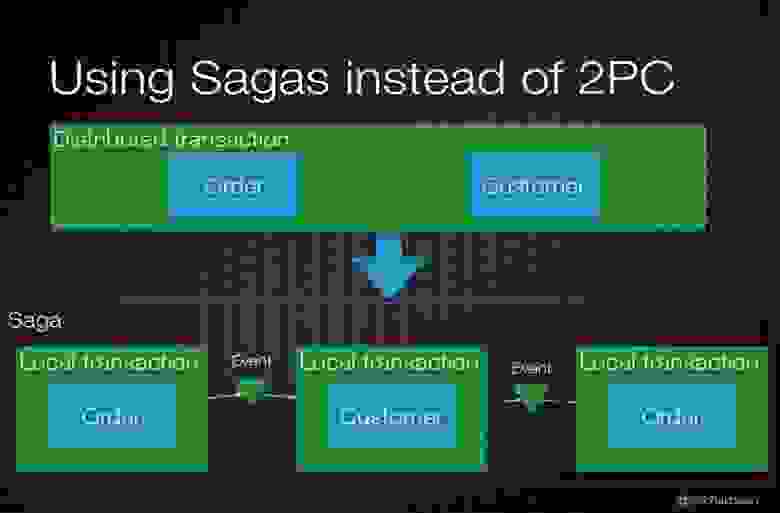
Первый элемент совершает действия и шлет сообщение, второй подписчик на него реагирует, отрабатывает, шлет свое сообщение, на которое реагирует уже третья часть системы. Если все закончилось хорошо, Saga генерирует собственное сообщение заданного типа, на которое будут реагировать уже другие подписчики.
Посмотрим, как в этом случае выглядит класс по обработке денежного требования. Все четко: есть команды, есть запросы, которые относятся к процессу регистрации, ну шина с логами.
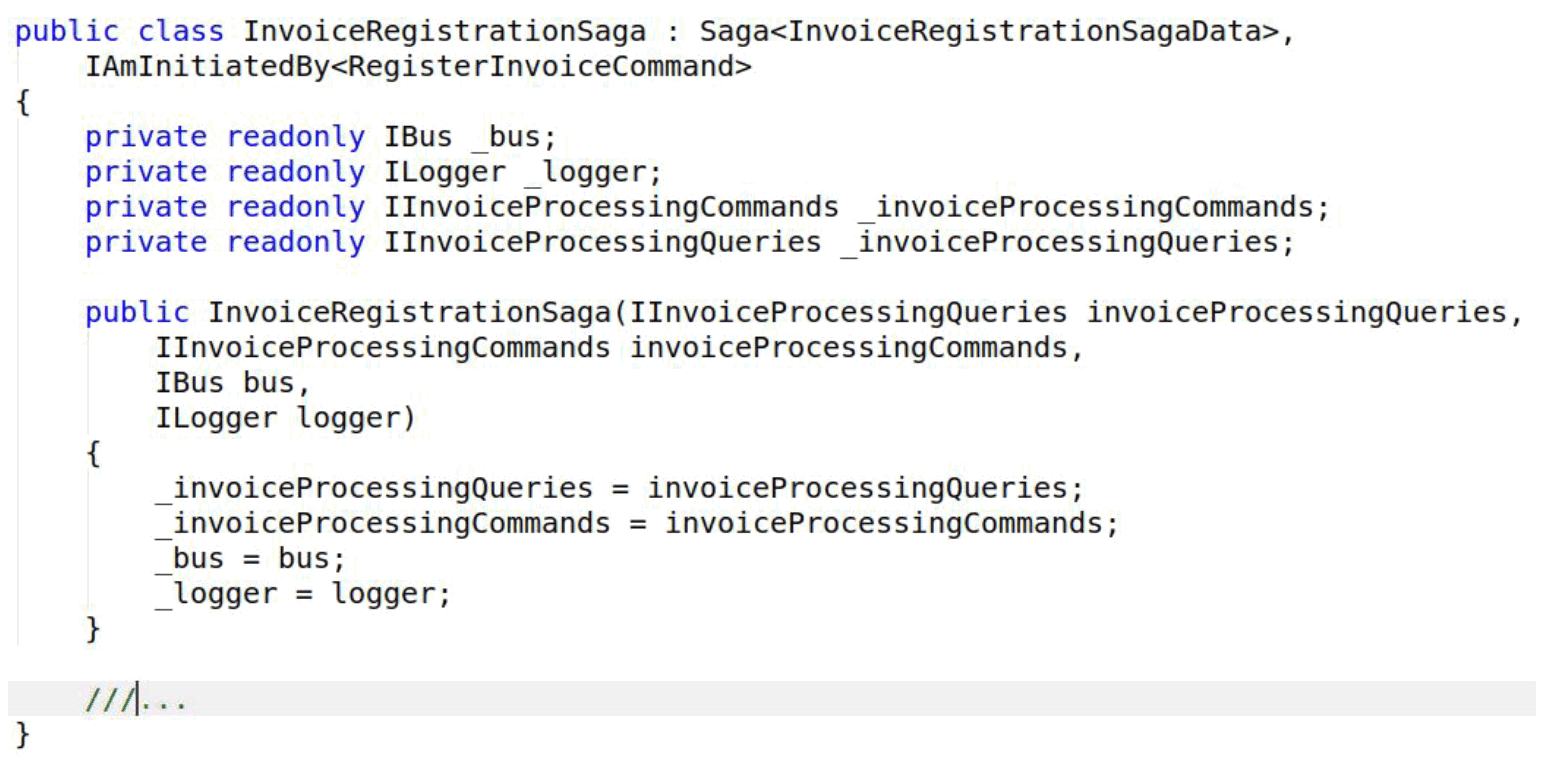
В этом случае есть один обработчик. Когда происходит событие и прилетает команда зарегистрировать денежные требования, он на нее реагирует. Внутри все то же, что и раньше, но особенность в том, что здесь идет группировка по процессу.
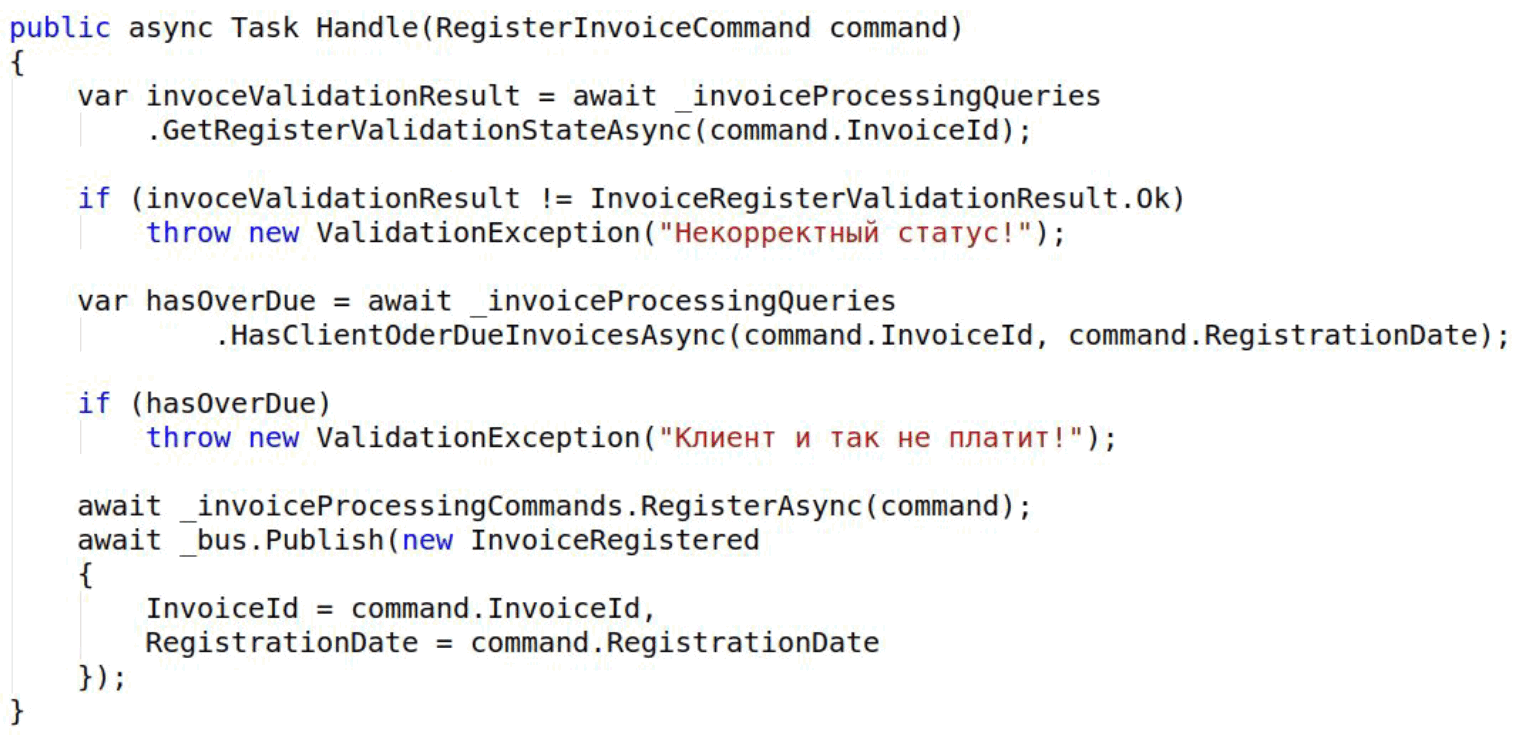
Из-за этого стало чуть проще, стало меньше изменений в каждом файле.
Что нужно помнить, работая с CQRS? Нужно лучше подходить к проектированию, потому что переписать процесс немного сложней. Присутствует небольшой оверхед, чуть больше классов стало, но это совсем не критично. Код стал менее связанным, правда, это не столько из-за CQRS, сколько из-за перехода на шину. Но именно CQRS нас побудил использовать такое событийное взаимодействие. Код стал чаще добавляться, чем меняться. Классов стало больше, но они теперь более специализированы.
Надо ли всем все бросать и массово переходить на CQRS? Нет, надо смотреть, какой сценарий работы лучше подходит под конкретный проект. Например, если у вас подсистема работает со справочниками, CQRS не нужен, классический слоеный подход дает более простой и удобный результат.
Полная версия выступления на Panda Meetup доступна ниже.
Если вы хотите глубже погрузиться в тему, имеет смысл изучить эти ресурсы:
CQRS architecture style – от Microsoft
Блог Александра Бындю
Contoso University Examples with CQRS, MediatR, AutoMapper and more – от Jimmy Bogard
CQRS — от Martin Fowler
Rebus

Вы когда-нибудь обращали внимание, как выглядит ваше корпоративное приложение? Почему оно не может быть таким, как у Apple и Google? Да потому что у нас постоянная нехватка времени. Требования меняются часто, срок их изменений обычно «вчера». И что самое неприятное, бизнес очень не любит ошибок.

Чтобы как-то с этим жить, разработчики начали делить свои приложения на части. Начиналось все просто – с данных. Многим знакома схема, когда данные отдельно, клиент отдельно, при этом логика хранится там же, где данные.

Хорошая схема. У крупнейших СУБД есть вполне работоспособные процедурные расширения SQL. Про Oracle вообще ходит пословица «Где есть Oracle, там есть логика». Трудно поспорить об удобстве и скорости такой конфигурации.
Но у нас корпоративное приложение, и есть проблема: логику сложно масштабировать. Да и неразумно загружать мощности СУБД, которой и так хватает проблем с извлечением и обновлением данных, еще и тривиальными бизнес-задачами.
Ну и инструменты программирования бизнес-логики, встроенные в СУБД, если честно, слабоваты для создания нормальных корпоративных приложений. Поддерживать бизнес-логику на T-SQL/PL-SQL – это боль. Неспроста ООП-языки так распространились среди корпоративных приложений: C#, Java, за примером далеко ходить не надо.

Казалось бы, логичное решение: выделим бизнес-логику. Она будет жить на своем сервере, база – на своем, клиент – отдельно.
Что можно улучшить в этой трехзвенной архитектуре? В слое бизнес-логики замешана архитектура, этого хотелось бы избежать. Бизнес-логика вообще ничего не хочет знать и о хранении данных. UI – это тоже отдельный мир, в котором есть свои сущности, не характерные для бизнес-логики.
Поможет увеличение слоев. Это решение выглядит почти идеально, в нем есть какая-то внутренняя красота.

У нас есть DAL (Data Access Layer) – данные отделены от логики, обычно это CRUD репозиторий с применением ORM, плюс хранимые процедуры для сложных запросов. Такой вариант позволяет и разрабатывать достаточно быстро, и иметь приемлемое быстродействие.
Бизнес-логика может идти в составе сервисов или быть отдельным слоем. Взаимодействие между слоями может осуществляться через транспортные объекты (DTO).
Запрос от UI у нас идет на сервис, тот общается с бизнес-логикой, лезет в DAL для доступа к данным. Такой подход называется N-tier, и у него есть явные преимущества.
У каждого слоя свои очевидные цели и задачи, что нам, как программистам, так нравится. Каждый конкретный слой занимается только своим делом. Сервисы можно масштабировать горизонтально. Подход понятен даже начинающему разработчику, человек быстро понимает, как работает система. Очень легко проследить все взаимодействия, как идет запрос от начала до конца.
Еще консистентность: все подсистемы проекта работают с одними данными, вам не нужно беспокоиться, что мы в одном месте записали данные, а в другой части пользователь их не видит.
Слоеный пирог 1. N-Tier
Ниже пример типичного фрагмента приложения, построенного по этим принципам. У нас есть денежное требование, здесь я рассмотрел Anemic-модель. И есть классический репозиторий, работа с которым идет через ORM.

Это типичный сервис, их еще называют менеджерами. Он работает с репозиторием, получает запросы и отдает ответы клиентами. В этом сервисе мы видим некоторую мешанину: у нас есть процесс по обработке, процесс по работе с UI и процесс для каких-то внутренних контролирующих подразделений, они слабо связаны между собой.
Вот как выглядит типичный метод этого сервиса. Например, регистрация денежного требования.

Мы получаем данные, выполняем какие-то бизнес-проверки. Затем идет обновление, а после него — какие-то пост-действия, например, отправка нотификации или запись в юзер лог.
В таком подходе, несмотря на всю его красоту, есть свои проблемы. Очень часто в корпоративных приложениях нагрузка несимметрична: операций чтения на порядок-два больше, чем записи. С масштабированием самой базы данных здесь уже возникает проблема. Конечно, это делается, причем даже средствами СУБД в масштабах базы, называется партиционирование. Но это сложно. Если это сделать не с той квалификацией или сделать раньше, чем это нужно, партиционирования уже не получится.
Например, в одной из наших систем объем данных достиг 25 ТБ, появились проблемы. Мы сами пробовали масштабироваться, пригласили крутых парней из известной компании. Они посмотрели и сказали: нам потребуется 14 часов полного простоя базы. Мы подумали и сказали: ребята, не пойдет, бизнес это не примет.
Помимо объема базы растет и количество методов в сервисах и репозиториях. Например, в сервисе по денежным требованиям более сотни методов. Это сложно поддерживать, возникают постоянные конфликты при merge request, code review проводить тяжелее. А если учесть, что процессы разные, над ними работают разные группы разработчиков, то задача отследить все изменения, связанные с какой-то проблемой, становится настоящей головной болью.
Слоеный пирог 2. CQRS
Так что же делать? Есть решение, которое придумали еще в древнем Риме: разделять и властвовать.

Как говорится, все новое — хорошо забытое старое. Еще в 1988 году Бертран Мейер сформулировал принцип императивного программирования CQS – Command-query separation – для работы с объектами. Все методы четко делятся на два типа. Первый – Query – запросы, которые возвращают результат, не изменяя состояние объекта. То есть когда вы смотрите денежные требования клиента, никто в базу не должен писать, что клиент такой-то посмотрел то-то, никаких side-эффектов в запросе не должно быть.
Второй – Commands – команды, которые изменяют состояние объекта, не возвращая данные. То есть вы приказали что-то изменить, и в ответ не ждете отчет на 10 тысяч строк.

Здесь четко отделена модель данных для чтения от модели для записи. Большая часть бизнес-логики отрабатывает на операциях записи. Чтение же может работать по материализованным представлениям или вообще по другой базе. Их можно разделить и синхронизировать через события или какие-то внутренние службы. Тут много вариантов.
CQRS не сложен. Мы должны четко выделить команды, которые изменяют состояние системы, но при этом ничего не возвращают. Тут подход может быть и более взвешенный. Не особо страшно, если команда вернет результат выполнения: ошибку или, например, идентификатор созданной сущности, то в этом никакого криминала нет. Важно, чтобы команда не занималась работой с запросом, она не должна искать данные и возвращать бизнес-сущности.
Запросы — там все просто. Не изменяет состояние, чтобы не было побочных эффектов. Это означает, что если мы два раза подряд вызвали запрос, и не было других команд, состояние объекта в обоих случаях должно остаться идентичным. Это позволяет параллелить запросы. Интересно, что отдельная модель для запросов не нужна для работы, т.к. нет смысла привлекать для этого бизнес-логику из доменной модели.
Наш CQRS-проект
Вот что мы хотели сделать в своем проекте:

У нас существующее приложение функционирует с 2006 года, у него классическая слоеная архитектура. Старомодная, но до сих пор работающая. Никто ее не хочет менять и даже не знает, на что заменить. Настал момент, когда нужно было разрабатывать что-то новое, с нуля практически. В 2011-2012 году Event Sourcing и CQRS были очень модной темой. Мы подумали, что это классно, что таким образом сможем хранить оригинальное состояние объекта и события, которые к нему привели.
То есть мы как бы не обновляем объект. Есть оригинальное состояние и рядом – то, что к нему применили. В этом случае есть громаднейший плюс — мы можем восстановить состояние объекта на любой момент истории. Фактически, журнал становится не нужен. Поскольку мы храним события, нам понятно, что конкретно случилось. То есть не просто у клиента обновилось значение в ячейке «адрес», у нас будет зафиксировано именно событие, например, переезд клиента.
Понятно, что такая схема работает медленно при получении данных, поэтому у нас есть отдельная база с материальными представлениями для выбора. Ну и синхронизация по событиям: при каждом поступлении событий на изменение состояния происходит публикация. В теории вроде все хорошо, но… Я так и не встретил людей, которые это в полной мере реализовали на продакшене, на высоких нагрузках с приемлемой для бизнеса консистентностью.

Схему можно развить дальше, если разделить обработчики и команды/запросы. Вот, в качестве примера, у нас команда — зарегистрированное денежное требование: имеется дата, сумма, клиент и другие поля.
На обработчик регистрации денежного требования мы ставим ограничение, что он может принимать только нашу команду (where TCommand: ICommand). Мы можем писать обработчики, не меняя старых, просто по методу добавления сложных требований. Например, сначала обнови дату, потом запиши значение, а здесь пошли клиенту уведомление — все это пишется в разных обработчиках на одну команду.
Как же нам все это вызвать? Есть диспетчер, который знает, где у него все эти обработчики хранятся.

Диспетчер передаётся (например, через DI контейнер) в API. И когда приходит команда, он делает только execute. Он знает, где находится контейнер, где команды, и их выполняет. С запросами — аналогично.
В чем проблема такой схемы: все взаимодействия становятся менее очевидными. Мы строим иерархию на типах, которые регистрируются в контейнерах, а потом реагируют на свои команды/запросы. Требуется очень четко спроектировать архитектуру. Любое действие одним методом с одним параметром уже не ограничивается. Вы пишете команду, пишете обработчик, регистрируете в контейнере. Возрастает количество оверхеда. В большом проекте возникают проблемы с элементарной навигацией. Мы решили пойти более классическим путем.
Для асинхронного взаимодействия была использована сервисная шина Rebus.

Для простых задач ее более чем хватает.
CQRS заставляет немного по-другому подойти к коду, сконцентрироваться на процессе, ведь все действия рождаются в рамках процесса. Мы выделили репозиторий для запросов, отдельно сделали команды, относящиеся к обработке, и отдельно запросы, относящиеся к обработке. Для чтения мы не стали использовать отдельный репозиторий, просто в командах работаем с ORM.

Вот, например, метод, из которого выкинуто все лишнее. В команде регистрации денежного требования мы регистрируем требование и публикуем событие в шину, что зарегистрировано денежное требование.
Кто в этом заинтересован, тот отреагирует на него. Например, там сработает идентификация пользователя и журналирование.
Вот пример запроса. Тоже стало все просто: мы читаем и в репозиторий отдаем.

Хочу отдельно остановиться на Rebus.Saga. Это паттерн, который позволяет разбить бизнес-транзакцию на атомарные действия. Это позволяет блокировать не все сразу, а понемногу и по очереди.

Первый элемент совершает действия и шлет сообщение, второй подписчик на него реагирует, отрабатывает, шлет свое сообщение, на которое реагирует уже третья часть системы. Если все закончилось хорошо, Saga генерирует собственное сообщение заданного типа, на которое будут реагировать уже другие подписчики.
Посмотрим, как в этом случае выглядит класс по обработке денежного требования. Все четко: есть команды, есть запросы, которые относятся к процессу регистрации, ну шина с логами.

В этом случае есть один обработчик. Когда происходит событие и прилетает команда зарегистрировать денежные требования, он на нее реагирует. Внутри все то же, что и раньше, но особенность в том, что здесь идет группировка по процессу.

Из-за этого стало чуть проще, стало меньше изменений в каждом файле.
Выводы
Что нужно помнить, работая с CQRS? Нужно лучше подходить к проектированию, потому что переписать процесс немного сложней. Присутствует небольшой оверхед, чуть больше классов стало, но это совсем не критично. Код стал менее связанным, правда, это не столько из-за CQRS, сколько из-за перехода на шину. Но именно CQRS нас побудил использовать такое событийное взаимодействие. Код стал чаще добавляться, чем меняться. Классов стало больше, но они теперь более специализированы.
Надо ли всем все бросать и массово переходить на CQRS? Нет, надо смотреть, какой сценарий работы лучше подходит под конкретный проект. Например, если у вас подсистема работает со справочниками, CQRS не нужен, классический слоеный подход дает более простой и удобный результат.
Полная версия выступления на Panda Meetup доступна ниже.
Если вы хотите глубже погрузиться в тему, имеет смысл изучить эти ресурсы:
CQRS architecture style – от Microsoft
Блог Александра Бындю
Contoso University Examples with CQRS, MediatR, AutoMapper and more – от Jimmy Bogard
CQRS — от Martin Fowler
Rebus
