Привет, Хабр!
Со штрихкодами современный человек сталкивается каждый день, даже не задумываясь об этом. Когда мы покупаем в супермаркете продукты, их коды считываются именно с помощью штрихкода. Также посылки, товары на складах, и прочее и прочее. Однако, мало кто знает, как же реально это работает.
Как устроен баркод, и что закодировано на этой картинке?

Попробуем разобраться, заодно напишем декодер таких кодов.
Использование штрихкодов имеет давнюю историю. Первые попытки автоматизации начинались еще в 50х, патент на устройство считывания кодов был получен в 1952г. Инженер, занимавшийся сортировкой вагонов на железной дороге, захотел упростить процесс. Идея была очевидной — кодировать номер с помощью полос и считывать их с помощью фотоэлементов. В 1962г коды стали официально использоваться для идентификации вагонов на американской железной дороге (система KarTrak), в 1968 прожектор заменили лазерным лучом, что позволило повысить точность и уменьшить размер считывателя. В 1973г появился формат «универсального кода продукта» (Universal Product Code), и в 1974 с использованием сканера кодов был продан первый продукт (жевательная резинка Wrigley’s — это же США;) в супермаркете. В 1984 треть магазинов использовали штриходы, в России же они начали использоваться примерно с 90х годов.
Разных кодов под разные задачи сейчас используется довольно много, к примеру, последовательность «12345678» может быть представлена такими способами (и это еще не все):

Приступим к побитовому разбору. Далее, все ниженаписанное будет относиться к виду «Code-128» — просто потому, что его формат довольно простой и понятный. Желающие поэкспериментировать с другими видами, могут открыть онлайн-генератор и посмотреть самостоятельно.
На первый взгляд штрихкод кажется просто беспорядочной последовательностью линий, на самом деле, его структура четко фиксирована:

1 — Пустое место, нужное для четкого определения начала кода
2 — Стартовый символ. Для Code-128 возможны 3 варианта (называемых А, В и С): 11010000100, 11010010000 или 11010011100, им соответствуют разные кодовые таблицы (подробнее в Википедии).
3 — Собственно код, содержащий нужные нам данные
4 — Контрольная сумма
5 — Стоп символ. Для Code-128 это 1100011101011.
6(1) — Пустое место.
Теперь о том, как кодируются биты. Тут все очень просто — если взять ширину самой тонкой линии за «1», то линия двойной ширины даст код «11», тройная «111», и так далее. Пустое место будет «0» или «00» или «000» по тому же самому принципу. Желающие могут сравнить стартовый код на картинке, чтобы убедиться что правило выполняется.
Теперь можно начинать программировать.
В принципе, это самая сложная часть, и разумеется, алгоритмически ее можно реализовать по-разному. Не уверен, что приведенный ниже алгоритм оптимальный, но для учебного примера его вполне достаточно.
Для начала загрузим изображение, растянем его по ширине, возьмем из середины изображения горизонтальную линию, преобразуем ее в ч/б и загрузим в виде массива.
На штрихкоде черному соответствует «1», а в RGB наоборот, 0, так что массив нужно инвертировать. Заодно вычислим среднее значение.
Запускаем программу, чтобы убедиться, что баркод загружен корректно:
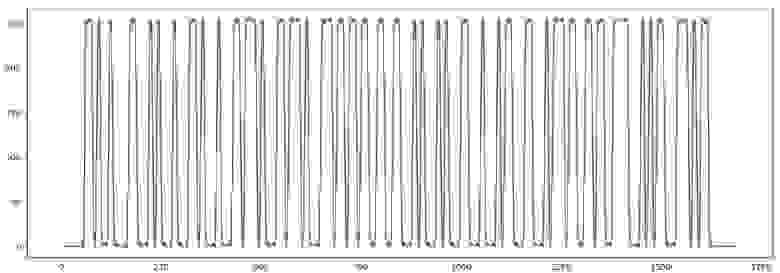
Теперь нужно определить ширину одного «бита». Для этого мы выделим начало стартовой последовательности «1101», записывая моменты перехода графика через среднюю линию.
Мы записываем только переходы через середину, так что код «1101» будет записан как «101», но нам этого достаточно чтобы узнать его ширину в пикселах.
Теперь собственно декодирование. Находим очередной переход через середину, и определяем число бит, попавших в интервал. Поскольку совпадение не абсолютное (код может быть слегка изогнут или растянут), используем округление.
Не уверен что это оптимальный вариант, возможно, есть способ лучше, желающие могут написать в комментариях.
Если все было сделано правильно, то мы получаем на выходе примерно такую последовательность:
Здесь никаких сложностей в принципе, нет. Символы в Code-128 кодируются 11-битным кодом, который имеет 3 разновидности (А, В и С) и может хранить либо разные кодировки символов, либо цифры от 00 до 99.
В нашем случае, начало последовательности 11010010000, что соответствует «Code B». Было жутко влом вбивать вручную все коды из Википедии, поэтому таблица была просто скопирована из браузера и ее парсинг был тоже сделан на Python (hint: на продакшене так делать не надо).
Теперь осталось самое простое. Разбиваем нашу битовую последовательность на 11-символьные блоки:
Наконец, формируем строку и выводим ее на экран:
Ответ на то, что закодировано в таблице, приводить не буду, пусть это будет домашним заданием для читателей (использование готовых программ для смартфонов будет считаться читерством:).
В коде также не реализована проверка CRC, желающие могут сделать это самостоятельно.
Разумеется, алгоритм неидеален, и был написан за полчаса. Для более профессиональных целей есть готовые библиотеки, например pyzbar. Код с использованием такой библиотеки займет всего 4 строчки:
(предварительно нужно установить библиотеку, введя команду «pip install pyzbar»)
Дополнение: о подсчете CRC написал в комментариях пользователь vinograd19:
Интересна история контрольной цифры. Она возникла эволюционно.
Контрольная цифра нужна для того, чтобы избежать неправильного декодирования. Если штрихкод был 1234, а его распознали как 7234, то нужна валидация, которая предупредит замену 1 на 7. Валидация может быть неточная, чтобы хотя бы в 90% невалидные номера определялись заранее.
1-й подход: Давайте просто возьмем сумму. Чтобы в остатке от деления на 10 был 0. Ну то есть первые 12 символов несут информационную нагрузку, а последняя цифры подбирается так, чтобы сумма цифр делилась на 10. Декодируем последовательность, если сумма не делится на десять — значит декодировали с багом и нужно сделать это еще раз. Например, код 1234 — валидный. 1+2+3+4 = 10. Код 1216 — тоже валидный, а вот 1218 — нет.
Это позволяет избежать проблем с автоматикой. Однако в момент создания штрихкодов был фоллбек в виде набивания номер на клавишах. И там есть плохой кейс: если поменять порядок следования двух цифр, то контрольная сумма не меняется, и это плохо. То есть если штрихкод 1234 был вбит как 2134, контрольная сумма сойдется, а вот номер мы вбили неправильный. Оказывается, неправильный порядок цифр — это распространенный кейс, если стучать по клавишам быстро.
2-й подход. Хорошо, давайте сумму сделаем чуть сложнее. Чтобы цифры на четных местах учитывались дважды. Тогда при изменении порядка, сумма точно не сойдется к нужной. Например код 2364 валидный (2 + 3+3 + 6 + 4+4 = 20), а код 3264 — невалидный (3+ 2+2 + 6 + 4+4 = 19). Но тут оказался еще один плохой пример вбития. Некоторые клавиатуры такие, что десять цифр располагаются в два ряда. первый ряд 12345 и под ним второй второй ряд 67890. Если вместо клавишы «1» нажать правее клавишу «2», то контрольная сумма предупредит неправильный ввод. А вот если вместо клавишу «1» нажать ниже клавишу «6» — то может не предупредить. Ведь 6=1+5, и в случае когда эта цифра стоит на четном месте при вычислении контрольной суммы, мы имеем 2*6 = 2*1 + 2*5. То есть контрольная сумму увеличилась ровно на 10, поэтому ее последняя цифра не изменилась. Например контрольные суммы кодв 2134 и 2634 одинаковые. Та же ошибка будет, если мы вместо 2 нажмем 7, вместо 3 нажмем 8 и тд.
3-й подход. Ок, давайте что ли возьмем опять сумму, только цифры, стоящие на четных местах будем учитывать… трижды. То есть код 1234565 — валидный, потому как 1 + 2*3 + 3 + 4*3 + 5 + 6*3 +5 = 50.
Описанный способ стал стандартом вычисления контрольной суммы EAN13 за небольшими правками: число цифр стало фиксированным и равно 13, где 13-ая — это та самая контрольная цифра. Цифры на нечетных местах считаются трижды, на четных — один раз.
Как можно видеть, даже такая простая вещь как штрихкод, имеет в себе немало интересного. Кстати, еще один лайфхак для тех, кто дочитал до сюда — текст под штрихкодом (если он есть) полностью дублирует его содержание. Это сделано для того, чтобы в случае нечитабельности кода, оператор мог ввести его вручную. Так что узнать содержимое штрихкода обычно просто — достаточно посмотреть на текст под ним.
Как подсказали в комментариях, наиболее популярным в торговле является код EAN-13, битовое кодирование там такое же, а структуру символов желающие могут посмотреть самостоятельно.
Если у читателей не пропал интерес, отдельно можно рассмотреть QR-коды.
Спасибо за внимание.
Со штрихкодами современный человек сталкивается каждый день, даже не задумываясь об этом. Когда мы покупаем в супермаркете продукты, их коды считываются именно с помощью штрихкода. Также посылки, товары на складах, и прочее и прочее. Однако, мало кто знает, как же реально это работает.
Как устроен баркод, и что закодировано на этой картинке?

Попробуем разобраться, заодно напишем декодер таких кодов.
Введение
Использование штрихкодов имеет давнюю историю. Первые попытки автоматизации начинались еще в 50х, патент на устройство считывания кодов был получен в 1952г. Инженер, занимавшийся сортировкой вагонов на железной дороге, захотел упростить процесс. Идея была очевидной — кодировать номер с помощью полос и считывать их с помощью фотоэлементов. В 1962г коды стали официально использоваться для идентификации вагонов на американской железной дороге (система KarTrak), в 1968 прожектор заменили лазерным лучом, что позволило повысить точность и уменьшить размер считывателя. В 1973г появился формат «универсального кода продукта» (Universal Product Code), и в 1974 с использованием сканера кодов был продан первый продукт (жевательная резинка Wrigley’s — это же США;) в супермаркете. В 1984 треть магазинов использовали штриходы, в России же они начали использоваться примерно с 90х годов.
Разных кодов под разные задачи сейчас используется довольно много, к примеру, последовательность «12345678» может быть представлена такими способами (и это еще не все):

Приступим к побитовому разбору. Далее, все ниженаписанное будет относиться к виду «Code-128» — просто потому, что его формат довольно простой и понятный. Желающие поэкспериментировать с другими видами, могут открыть онлайн-генератор и посмотреть самостоятельно.
На первый взгляд штрихкод кажется просто беспорядочной последовательностью линий, на самом деле, его структура четко фиксирована:

1 — Пустое место, нужное для четкого определения начала кода
2 — Стартовый символ. Для Code-128 возможны 3 варианта (называемых А, В и С): 11010000100, 11010010000 или 11010011100, им соответствуют разные кодовые таблицы (подробнее в Википедии).
3 — Собственно код, содержащий нужные нам данные
4 — Контрольная сумма
5 — Стоп символ. Для Code-128 это 1100011101011.
6(1) — Пустое место.
Теперь о том, как кодируются биты. Тут все очень просто — если взять ширину самой тонкой линии за «1», то линия двойной ширины даст код «11», тройная «111», и так далее. Пустое место будет «0» или «00» или «000» по тому же самому принципу. Желающие могут сравнить стартовый код на картинке, чтобы убедиться что правило выполняется.
Теперь можно начинать программировать.
Получаем битовую последовательность
В принципе, это самая сложная часть, и разумеется, алгоритмически ее можно реализовать по-разному. Не уверен, что приведенный ниже алгоритм оптимальный, но для учебного примера его вполне достаточно.
Для начала загрузим изображение, растянем его по ширине, возьмем из середины изображения горизонтальную линию, преобразуем ее в ч/б и загрузим в виде массива.
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
image_path = "barcode.jpg"
img = Image.open(image_path)
width, height = img.size
basewidth = 4*width
img = img.resize((basewidth, height), Image.ANTIALIAS)
hor_line_bw = img.crop((0, int(height/2), basewidth, int(height/2) + 1)).convert('L')
hor_data = np.asarray(hor_line_bw, dtype="int32")[0]
На штрихкоде черному соответствует «1», а в RGB наоборот, 0, так что массив нужно инвертировать. Заодно вычислим среднее значение.
hor_data = 255 - hor_data
avg = np.average(hor_data)
plt.plot(hor_data)
plt.show()
Запускаем программу, чтобы убедиться, что баркод загружен корректно:
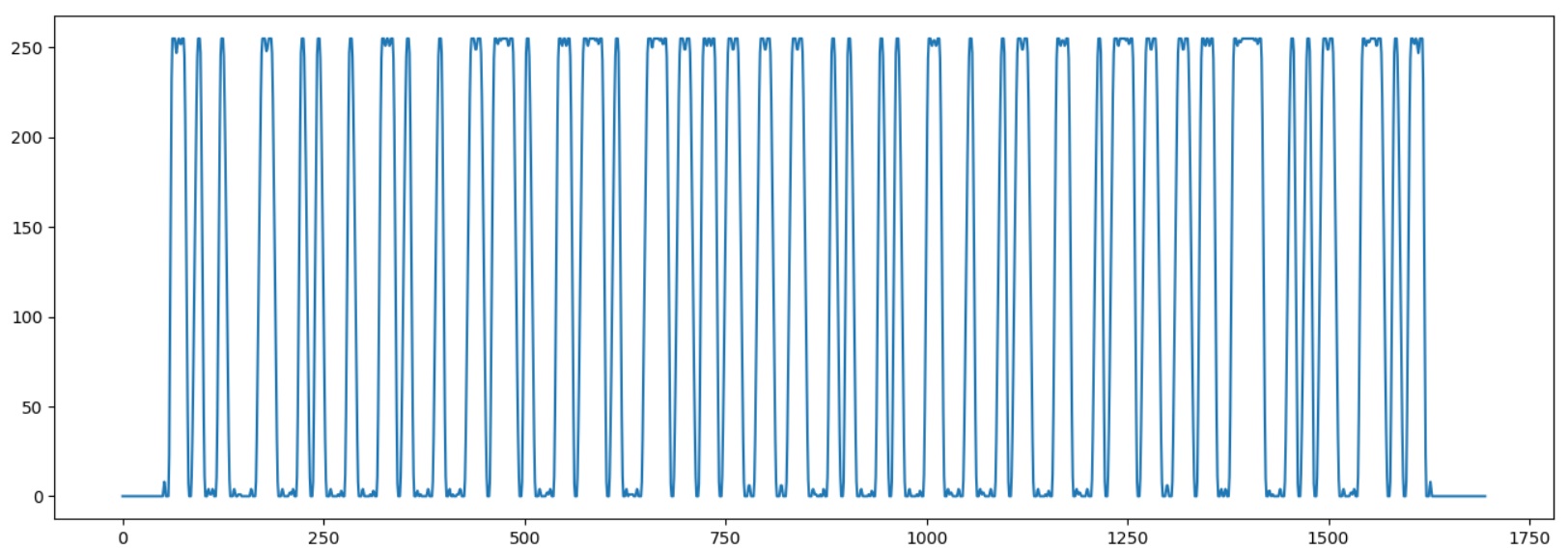
Теперь нужно определить ширину одного «бита». Для этого мы выделим начало стартовой последовательности «1101», записывая моменты перехода графика через среднюю линию.
pos1, pos2 = -1, -1
bits = ""
for p in range(basewidth - 2):
if hor_data[p] < avg and hor_data[p + 1] > avg:
bits += "1"
if pos1 == -1:
pos1 = p
if bits == "101":
pos2 = p
break
if hor_data[p] > avg and hor_data[p + 1] < avg:
bits += "0"
bit_width = int((pos2 - pos1)/3)
Мы записываем только переходы через середину, так что код «1101» будет записан как «101», но нам этого достаточно чтобы узнать его ширину в пикселах.
Теперь собственно декодирование. Находим очередной переход через середину, и определяем число бит, попавших в интервал. Поскольку совпадение не абсолютное (код может быть слегка изогнут или растянут), используем округление.
bits = ""
for p in range(basewidth - 2):
if hor_data[p] > avg and hor_data[p + 1] < avg:
interval = p - pos1
cnt = interval/bit_width
bits += "1"*int(round(cnt))
pos1 = p
if hor_data[p] < avg and hor_data[p + 1] > avg:
interval = p - pos1
cnt = interval/bit_width
bits += "0"*int(round(cnt))
pos1 = p
Не уверен что это оптимальный вариант, возможно, есть способ лучше, желающие могут написать в комментариях.
Если все было сделано правильно, то мы получаем на выходе примерно такую последовательность:
11010010000110001010001000110100010001101110100011011101000111011011
01100110011000101000101000110001000101100011000101110110011011001111
00010101100011101011Декодирование
Здесь никаких сложностей в принципе, нет. Символы в Code-128 кодируются 11-битным кодом, который имеет 3 разновидности (А, В и С) и может хранить либо разные кодировки символов, либо цифры от 00 до 99.
В нашем случае, начало последовательности 11010010000, что соответствует «Code B». Было жутко влом вбивать вручную все коды из Википедии, поэтому таблица была просто скопирована из браузера и ее парсинг был тоже сделан на Python (hint: на продакшене так делать не надо).
CODE128_CHART = """
0 _ _ 00 32 S 11011001100 212222
1 ! ! 01 33 ! 11001101100 222122
2 " " 02 34 " 11001100110 222221
3 # # 03 35 # 10010011000 121223
...
93 GS } 93 125 } 10100011110 111341
94 RS ~ 94 126 ~ 10001011110 131141
103 Start Start A 208 SCA 11010000100 211412
104 Start Start B 209 SCB 11010010000 211214
105 Start Start C 210 SCC 11010011100 211232
106 Stop Stop - - - 11000111010 233111""".split()
SYMBOLS = [value for value in CODE128_CHART[6::8]]
VALUESB = [value for value in CODE128_CHART[2::8]]
CODE128B = dict(zip(SYMBOLS, VALUESB))
Теперь осталось самое простое. Разбиваем нашу битовую последовательность на 11-символьные блоки:
sym_len = 11
symbols = [bits[i:i+sym_len] for i in range(0, len(bits), sym_len)]
Наконец, формируем строку и выводим ее на экран:
str_out = ""
for sym in symbols:
if CODE128A[sym] == 'Start':
continue
if CODE128A[sym] == 'Stop':
break
str_out += CODE128A[sym]
print(" ", sym, CODE128A[sym])
print("Str:", str_out)
Ответ на то, что закодировано в таблице, приводить не буду, пусть это будет домашним заданием для читателей (использование готовых программ для смартфонов будет считаться читерством:).
В коде также не реализована проверка CRC, желающие могут сделать это самостоятельно.
Разумеется, алгоритм неидеален, и был написан за полчаса. Для более профессиональных целей есть готовые библиотеки, например pyzbar. Код с использованием такой библиотеки займет всего 4 строчки:
from pyzbar.pyzbar import decode
img = Image.open(image_path)
decode = decode(img)
print(decode)
(предварительно нужно установить библиотеку, введя команду «pip install pyzbar»)
Дополнение: о подсчете CRC написал в комментариях пользователь vinograd19:
Интересна история контрольной цифры. Она возникла эволюционно.
Контрольная цифра нужна для того, чтобы избежать неправильного декодирования. Если штрихкод был 1234, а его распознали как 7234, то нужна валидация, которая предупредит замену 1 на 7. Валидация может быть неточная, чтобы хотя бы в 90% невалидные номера определялись заранее.
1-й подход: Давайте просто возьмем сумму. Чтобы в остатке от деления на 10 был 0. Ну то есть первые 12 символов несут информационную нагрузку, а последняя цифры подбирается так, чтобы сумма цифр делилась на 10. Декодируем последовательность, если сумма не делится на десять — значит декодировали с багом и нужно сделать это еще раз. Например, код 1234 — валидный. 1+2+3+4 = 10. Код 1216 — тоже валидный, а вот 1218 — нет.
Это позволяет избежать проблем с автоматикой. Однако в момент создания штрихкодов был фоллбек в виде набивания номер на клавишах. И там есть плохой кейс: если поменять порядок следования двух цифр, то контрольная сумма не меняется, и это плохо. То есть если штрихкод 1234 был вбит как 2134, контрольная сумма сойдется, а вот номер мы вбили неправильный. Оказывается, неправильный порядок цифр — это распространенный кейс, если стучать по клавишам быстро.
2-й подход. Хорошо, давайте сумму сделаем чуть сложнее. Чтобы цифры на четных местах учитывались дважды. Тогда при изменении порядка, сумма точно не сойдется к нужной. Например код 2364 валидный (2 + 3+3 + 6 + 4+4 = 20), а код 3264 — невалидный (3+ 2+2 + 6 + 4+4 = 19). Но тут оказался еще один плохой пример вбития. Некоторые клавиатуры такие, что десять цифр располагаются в два ряда. первый ряд 12345 и под ним второй второй ряд 67890. Если вместо клавишы «1» нажать правее клавишу «2», то контрольная сумма предупредит неправильный ввод. А вот если вместо клавишу «1» нажать ниже клавишу «6» — то может не предупредить. Ведь 6=1+5, и в случае когда эта цифра стоит на четном месте при вычислении контрольной суммы, мы имеем 2*6 = 2*1 + 2*5. То есть контрольная сумму увеличилась ровно на 10, поэтому ее последняя цифра не изменилась. Например контрольные суммы кодв 2134 и 2634 одинаковые. Та же ошибка будет, если мы вместо 2 нажмем 7, вместо 3 нажмем 8 и тд.
3-й подход. Ок, давайте что ли возьмем опять сумму, только цифры, стоящие на четных местах будем учитывать… трижды. То есть код 1234565 — валидный, потому как 1 + 2*3 + 3 + 4*3 + 5 + 6*3 +5 = 50.
Описанный способ стал стандартом вычисления контрольной суммы EAN13 за небольшими правками: число цифр стало фиксированным и равно 13, где 13-ая — это та самая контрольная цифра. Цифры на нечетных местах считаются трижды, на четных — один раз.
Заключение
Как можно видеть, даже такая простая вещь как штрихкод, имеет в себе немало интересного. Кстати, еще один лайфхак для тех, кто дочитал до сюда — текст под штрихкодом (если он есть) полностью дублирует его содержание. Это сделано для того, чтобы в случае нечитабельности кода, оператор мог ввести его вручную. Так что узнать содержимое штрихкода обычно просто — достаточно посмотреть на текст под ним.
Как подсказали в комментариях, наиболее популярным в торговле является код EAN-13, битовое кодирование там такое же, а структуру символов желающие могут посмотреть самостоятельно.
Если у читателей не пропал интерес, отдельно можно рассмотреть QR-коды.
Спасибо за внимание.
