
Привет, Хабр. Меня зовут Алексей Рак, я разработчик голосового помощника Алиса в минском офисе Яндекса. Эту позицию я получил, пройдя здесь, в этой же команде, трехмесячную стажировку в прошлом году. О ней я и собираюсь вам рассказать. Если хотите сами попробовать — вот ссылка на стажировку 2019 года.

Я учусь на 4 курсе БГУ, в 2018 году окончил Школу анализа данных, жил и живу в Минске.
Сначала я, как и другие выпускники ШАДа, получил ссылку на стажировку 2018 года. В течение недели после отправки анкеты требовалось выделить время, 6 часов подряд, на выполнение онлайн-контеста. Он содержал задачи про теорию вероятности, умение кодить, придумывать алгоритмы. Писать код можно было на том языке, на котором умеешь. Несколько задач я написал на C++, несколько — на Python, язык выбирал в зависимости от удобства применения к конкретной задаче.
Когда отправляешь решение, то по нему сразу приходит вердикт, после чего задачу можно решить заново, чтобы получить более правильный ответ. У меня на все задачи ушла пара часов из 6. Часть задач я решил не с первой попытки.
Через несколько дней рекрутеры со мной связались и позвали на первое очное собеседование в минский офис. Оно было с Алексеем Колесовым — руководителем бригады акустических моделей и биометрии, где мне предстояло работать. Собеседование состояло в том, чтобы порешать задачи на листе бумаге или на доске и поотвечать на вопросы по теории вероятности, алгоритмам, машинному обучению. Я думаю, что бэкграунд олимпиадного программирования позволил бы мне справиться с онлайн-контестом, даже если бы я не учился в ШАДе, а вот на собеседовании опыт ШАДа мне действительно пригодился.
Спустя несколько дней состоялась вторая встреча, где мне задали еще две задачи на знание алгоритмов: разминочную и основную. С каждой задачей было так: я предлагал решение, отвечал на несколько вопросов по этому решению, а затем писал код на листе бумаги.
Еще через несколько дней мне сообщили, что я принят на стажировку. Она должна была продлиться три полных месяца (так в итоге и получилось). Переход на постоянную позицию не обещали, но сказали, что такой вариант возможен.
В первый день, разобравшись с оргвопросами и получив ноутбук, я пошел пообедать с коллегами. Мы пообщались, затем я собрал командный репозиторий и занялся первой задачей — составлением простого Python-скрипта, чтобы начать запускать уже готовую программу в несколько потоков и тем самым ускорить ее выполнение. В процессе создания скрипта я познакомился с системой код-ревью — когда другие ребята в команде верифицируют твой код. Зная, что с ним будут иметь дело сначала твои ближайшие коллеги, а в будущем и другие разработчики, ты стараешься писать понятнее. В олимпиадном программировании всё несколько иначе: важна скорость, с которой ты программируешь, а просматривать написанное, скорее всего, больше не потребуется даже тебе самому. С другой стороны, когда мне до Яндекса приходилось сталкиваться с ситуацией, что код все-таки придется читать, я тоже старался делать его более-менее понятным.
По ходу стажировки я еще несколько раз решал задачи, подобные этому скрипту, но мое основное время занимал гораздо более масштабный проект — новый декодер для споттера Алисы.
Чтобы на устройствах и в приложениях Яндекса, где помощника можно вызвать голосом, всё работало так, как ожидает пользователь, нужен качественный споттер — механизм голосовой активации. Чаще всего активационная фраза (которую нужно произнести для запуска Алисы) содержит само слово «Алиса».
Споттер включает в себя подготовку фич (признаков для машинного обучения), нейронную сеть и декодер.
Прежняя версия декодера работала за счет обработки векторов вероятностей. Существует акустическая модель — нейросеть, которая для каждого фрейма (фрагмента речи длительностью 10–20 миллисекунд) возвращает вероятность, что он сейчас был произнесен. Фреймы могут накладываться друг на друга. В декодере содержалась матрица с вероятностями для 100 последних «услышанных» устройством фреймов. Звуку каждой буквы соответствует некий вектор вероятностей. Алгоритм находил в векторе для буквы А элемент с самой большой вероятностью, после чего рассматривал только правую относительно этого элемента часть матрицы. Затем операция повторялась для букв Л, И, С и А — всякий раз матрица «обрезалась» по найденному элементу. Звуки А в начале и конце слова на самом деле разные — второй из них принято называть Шва, он похож на А, Э и О одновременно.
Если итоговая вероятность оказывалась больше, чем пороговое значение, то алгоритм считал, что слово действительно было произнесено, и активировал Алису для пользователя.
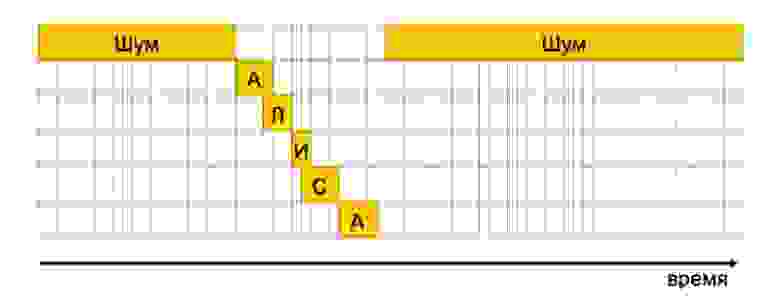
Такая схема приводила к тому, что помощник иногда самопроизвольно включался не только когда люди говорили «Алиса», но и услышав другие слова, например «Александр». Звуки в первой части этого слова («Алекса») следуют в том же порядке и в основном совпадают со звуками в слове «Алиса». Отличие только в буквах Е и К, но Е по своему звучанию очень близка к И, а наличие буквы К алгоритм никак не учитывал.
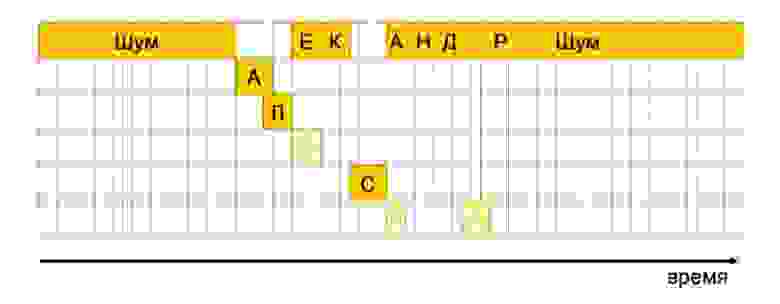
В теории, можно искать в произносимой речи не только слово «Алиса», но и похожие слова. Их не так много: «Александр», «Алекса», «арестовали», «лестница», «аристарх». Если бы алгоритм считал, что пользователь с большой вероятностью сказал одно из них, то можно было бы запрещать активацию вне зависимости от результата работы основного декодера.
Однако голосовая активация должна действовать даже без интернета. Поэтому декодер — локальный механизм. Он работает благодаря нейронной сети, которая каждый раз запускается прямо на устройстве пользователя (например, на телефоне), не связываясь с серверами Яндекса. А поскольку всё происходит локально, то производительность (того же телефона по сравнению с целым дата-центром) оставляет желать лучшего. Распознавать не только слово «Алиса» означало бы существенно усложнить работу этой небольшой нейросети и превысить ограничения по производительности. Активация стала бы работать медленнее, помощник откликался бы с большой задержкой.
Нужен был принципиально другой декодер. Коллеги предложили мне реализовать идею Hidden Markov Model, HMM: на момент начала моей стажировки она уже была хорошо описана сообществом, а также нашла применение в помощнике Alexa от Amazon.
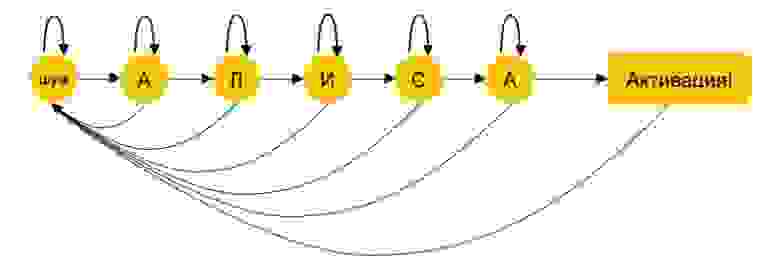
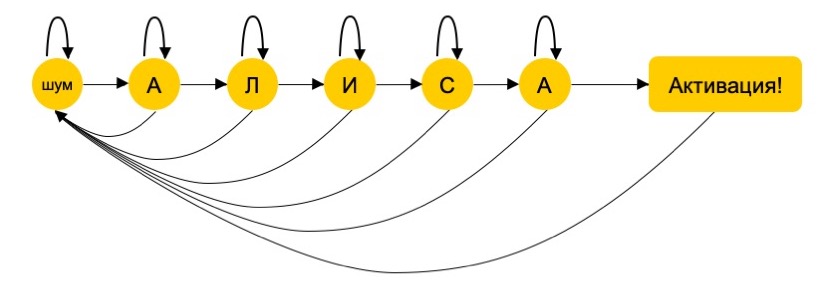
HMM-декодер строит граф из 6 вершин: по одной для каждого звука в слове «Алиса», плюс еще одна для всех остальных звуков — другой речи или шума. Вероятности переходов между вершинами оцениваются на выборке записанной и проаннотированной речи. Для каждого услышанного звука считается 6 вероятностей: на совпадение с каждой из пяти букв и с шестой вершиной (то есть с каким-либо звуком помимо встречающихся в слове «Алиса»). Если пользователь скажет «Александр», декодер собьется на К: вероятность, что произнесенный звук не является частью активационной фразы, будет слишком большой, и помощник не сработает.
В ближайшее время эти изменения станут доступны всем пользователям Алисы и библиотеки SpeechKit.
Из трех месяцев стажировки полтора у меня ушло на написание HMM-декодера. В конце этих полутора месяцев руководитель сказал мне, что переход на постоянную позицию и на бессрочный договор будет возможен (хотя и не гарантирован), если я продолжу работать так же продуктивно. Примерно в это же время я взял отпуск на две недели, чтобы съездить на сборы по олимпиадному программированию. Вернувшись, я занялся новой задачей — обучением споттеров для различных устройств: Яндекс.Телефона, бортового компьютера с Яндекс.Авто и других.
Спустя пару недель, примерно за месяц до конца стажировки, состоялось мое первое собеседование по поводу постоянной позиции, а еще через несколько дней — второе, заключительное. Я общался с руководителями смежных команд. На первом из собеседований мне задавали теоретические вопросы: про машинное обучение, нейронные сети, логистическую регрессию, методы оптимизации. Кроме того, спрашивали про регуляризацию, то есть про уменьшение степени переобучения заданного алгоритма и про то, к каким алгоритмам какие методы регуляризации применяются. Второе собеседование было практическим: мы общались по скайпу с коллегой из Москвы, а я в процессе набирал код в простом онлайн-редакторе.
По собственной инициативе я устроился не на полную ставку, а на ¾ — дело в том, что моя учеба в БГУ еще не закончена. На постоянной позиции я в том числе занимаюсь автоматическим подбором пороговых значений и других гиперпараметров. В каждый момент времени система получает вероятность того, что ключевое слово «Алиса» было произнесено. Финальный классификатор сравнивает эту вероятность с пороговым значением и, если порог преодолен, активирует Алису. Раньше порог подбирался силами разработчиков, текущая задача — научиться делать это автоматически.
Так я попал в Яндекс, сохранив свое место в команде Алисы.

Как я устраивался
Я учусь на 4 курсе БГУ, в 2018 году окончил Школу анализа данных, жил и живу в Минске.
Сначала я, как и другие выпускники ШАДа, получил ссылку на стажировку 2018 года. В течение недели после отправки анкеты требовалось выделить время, 6 часов подряд, на выполнение онлайн-контеста. Он содержал задачи про теорию вероятности, умение кодить, придумывать алгоритмы. Писать код можно было на том языке, на котором умеешь. Несколько задач я написал на C++, несколько — на Python, язык выбирал в зависимости от удобства применения к конкретной задаче.
Когда отправляешь решение, то по нему сразу приходит вердикт, после чего задачу можно решить заново, чтобы получить более правильный ответ. У меня на все задачи ушла пара часов из 6. Часть задач я решил не с первой попытки.
Через несколько дней рекрутеры со мной связались и позвали на первое очное собеседование в минский офис. Оно было с Алексеем Колесовым — руководителем бригады акустических моделей и биометрии, где мне предстояло работать. Собеседование состояло в том, чтобы порешать задачи на листе бумаге или на доске и поотвечать на вопросы по теории вероятности, алгоритмам, машинному обучению. Я думаю, что бэкграунд олимпиадного программирования позволил бы мне справиться с онлайн-контестом, даже если бы я не учился в ШАДе, а вот на собеседовании опыт ШАДа мне действительно пригодился.
Спустя несколько дней состоялась вторая встреча, где мне задали еще две задачи на знание алгоритмов: разминочную и основную. С каждой задачей было так: я предлагал решение, отвечал на несколько вопросов по этому решению, а затем писал код на листе бумаги.
Еще через несколько дней мне сообщили, что я принят на стажировку. Она должна была продлиться три полных месяца (так в итоге и получилось). Переход на постоянную позицию не обещали, но сказали, что такой вариант возможен.
Начало работы
В первый день, разобравшись с оргвопросами и получив ноутбук, я пошел пообедать с коллегами. Мы пообщались, затем я собрал командный репозиторий и занялся первой задачей — составлением простого Python-скрипта, чтобы начать запускать уже готовую программу в несколько потоков и тем самым ускорить ее выполнение. В процессе создания скрипта я познакомился с системой код-ревью — когда другие ребята в команде верифицируют твой код. Зная, что с ним будут иметь дело сначала твои ближайшие коллеги, а в будущем и другие разработчики, ты стараешься писать понятнее. В олимпиадном программировании всё несколько иначе: важна скорость, с которой ты программируешь, а просматривать написанное, скорее всего, больше не потребуется даже тебе самому. С другой стороны, когда мне до Яндекса приходилось сталкиваться с ситуацией, что код все-таки придется читать, я тоже старался делать его более-менее понятным.
По ходу стажировки я еще несколько раз решал задачи, подобные этому скрипту, но мое основное время занимал гораздо более масштабный проект — новый декодер для споттера Алисы.
Чтобы на устройствах и в приложениях Яндекса, где помощника можно вызвать голосом, всё работало так, как ожидает пользователь, нужен качественный споттер — механизм голосовой активации. Чаще всего активационная фраза (которую нужно произнести для запуска Алисы) содержит само слово «Алиса».
Споттер включает в себя подготовку фич (признаков для машинного обучения), нейронную сеть и декодер.
Предыдущий декодер
Прежняя версия декодера работала за счет обработки векторов вероятностей. Существует акустическая модель — нейросеть, которая для каждого фрейма (фрагмента речи длительностью 10–20 миллисекунд) возвращает вероятность, что он сейчас был произнесен. Фреймы могут накладываться друг на друга. В декодере содержалась матрица с вероятностями для 100 последних «услышанных» устройством фреймов. Звуку каждой буквы соответствует некий вектор вероятностей. Алгоритм находил в векторе для буквы А элемент с самой большой вероятностью, после чего рассматривал только правую относительно этого элемента часть матрицы. Затем операция повторялась для букв Л, И, С и А — всякий раз матрица «обрезалась» по найденному элементу. Звуки А в начале и конце слова на самом деле разные — второй из них принято называть Шва, он похож на А, Э и О одновременно.
Если итоговая вероятность оказывалась больше, чем пороговое значение, то алгоритм считал, что слово действительно было произнесено, и активировал Алису для пользователя.

Такая схема приводила к тому, что помощник иногда самопроизвольно включался не только когда люди говорили «Алиса», но и услышав другие слова, например «Александр». Звуки в первой части этого слова («Алекса») следуют в том же порядке и в основном совпадают со звуками в слове «Алиса». Отличие только в буквах Е и К, но Е по своему звучанию очень близка к И, а наличие буквы К алгоритм никак не учитывал.

В теории, можно искать в произносимой речи не только слово «Алиса», но и похожие слова. Их не так много: «Александр», «Алекса», «арестовали», «лестница», «аристарх». Если бы алгоритм считал, что пользователь с большой вероятностью сказал одно из них, то можно было бы запрещать активацию вне зависимости от результата работы основного декодера.
Однако голосовая активация должна действовать даже без интернета. Поэтому декодер — локальный механизм. Он работает благодаря нейронной сети, которая каждый раз запускается прямо на устройстве пользователя (например, на телефоне), не связываясь с серверами Яндекса. А поскольку всё происходит локально, то производительность (того же телефона по сравнению с целым дата-центром) оставляет желать лучшего. Распознавать не только слово «Алиса» означало бы существенно усложнить работу этой небольшой нейросети и превысить ограничения по производительности. Активация стала бы работать медленнее, помощник откликался бы с большой задержкой.
Нужен был принципиально другой декодер. Коллеги предложили мне реализовать идею Hidden Markov Model, HMM: на момент начала моей стажировки она уже была хорошо описана сообществом, а также нашла применение в помощнике Alexa от Amazon.
Новый HMM-декодер
HMM-декодер строит граф из 6 вершин: по одной для каждого звука в слове «Алиса», плюс еще одна для всех остальных звуков — другой речи или шума. Вероятности переходов между вершинами оцениваются на выборке записанной и проаннотированной речи. Для каждого услышанного звука считается 6 вероятностей: на совпадение с каждой из пяти букв и с шестой вершиной (то есть с каким-либо звуком помимо встречающихся в слове «Алиса»). Если пользователь скажет «Александр», декодер собьется на К: вероятность, что произнесенный звук не является частью активационной фразы, будет слишком большой, и помощник не сработает.
В ближайшее время эти изменения станут доступны всем пользователям Алисы и библиотеки SpeechKit.
Завершение стажировки и переход на постоянную работу
Из трех месяцев стажировки полтора у меня ушло на написание HMM-декодера. В конце этих полутора месяцев руководитель сказал мне, что переход на постоянную позицию и на бессрочный договор будет возможен (хотя и не гарантирован), если я продолжу работать так же продуктивно. Примерно в это же время я взял отпуск на две недели, чтобы съездить на сборы по олимпиадному программированию. Вернувшись, я занялся новой задачей — обучением споттеров для различных устройств: Яндекс.Телефона, бортового компьютера с Яндекс.Авто и других.
Спустя пару недель, примерно за месяц до конца стажировки, состоялось мое первое собеседование по поводу постоянной позиции, а еще через несколько дней — второе, заключительное. Я общался с руководителями смежных команд. На первом из собеседований мне задавали теоретические вопросы: про машинное обучение, нейронные сети, логистическую регрессию, методы оптимизации. Кроме того, спрашивали про регуляризацию, то есть про уменьшение степени переобучения заданного алгоритма и про то, к каким алгоритмам какие методы регуляризации применяются. Второе собеседование было практическим: мы общались по скайпу с коллегой из Москвы, а я в процессе набирал код в простом онлайн-редакторе.
По собственной инициативе я устроился не на полную ставку, а на ¾ — дело в том, что моя учеба в БГУ еще не закончена. На постоянной позиции я в том числе занимаюсь автоматическим подбором пороговых значений и других гиперпараметров. В каждый момент времени система получает вероятность того, что ключевое слово «Алиса» было произнесено. Финальный классификатор сравнивает эту вероятность с пороговым значением и, если порог преодолен, активирует Алису. Раньше порог подбирался силами разработчиков, текущая задача — научиться делать это автоматически.
Так я попал в Яндекс, сохранив свое место в команде Алисы.
