Несколько слов о том, чем мы занимаемся. DINS участвует в разработке и поддержке UCaaS сервиса на международном рынке для корпоративных клиентов. Сервис используют как малые компании и стартапы, так и большой бизнес. Клиенты подключаются через интернет по SIP протоколу поверх TCP, TLS или WSS. Это создает довольно большую нагрузку: почти 1,5 миллиона соединений от оконечных устройств — телефонных аппаратов Polycom/Cisco/Yealink и софт-клиентов для PC/Mac/IOS/Android.
В статье я рассказываю о том, как устроены VoIP точки входа в систему.
Предыстория
На периметре системы (между оконечными устройствами и ядром) стоят коммерческие SBC (Session Border Controller).
С 2012 года мы использовали решения компании Acme Packet, впоследствии приобретённой Oracle. До этого мы использовали NatPASS.
Кратко перечислю функционал, которым мы пользуемся:
• NAT traversal;
• B2BUA;
• Нормализация SIP (allowed/disallowed headers, header manipulation rules, etc)
• TLS&SRTP offload;
• Конвертация транспорта (внутри системы мы используем SIP over UDP);
• Мониторинг MOS (через RTCP-XR);
• ACLs, Bruteforce detection;
• Уменьшение регистрационного трафика за счёт увеличенного contact expiration (низкий expire на стороне доступа, высокий на стороне ядра);
• Per-Method SIP messages throttling.
Коммерческие системы обладают своими очевидными плюсами (функционал из коробки, коммерческая поддержка) и минусами (цена, время поставок, отсутствие возможности или слишком большие сроки реализации новых нужных нам фич, сроки решения проблем и т.д.). Постепенно недостатки стали перевешивать, и стало понятно, что назрела необходимость разработки собственного решения.
Разработка была запущена полтора года назад. В подсистеме бордеров мы традиционно выделили 2 основных компоненты: SIP и Media серверы; над каждой компонентой балансировщики нагрузки. Я здесь работаю над точками входа/балансировщиками, поэтому попробую рассказать о них.
Требования
- Отказоустойчивость: система должна предоставлять сервис при выходе из строя одного или более инстансов в дата-центре или всего дата-центра
- Обслуживаемость: мы хотим иметь возможность переключения нагрузки из одного дата-центра в другие
- Масштабируемость: наращивать мощности хочется быстро и недорого
Балансировка
Мы выбрали IPVS (aka LVS) в режиме IPIP (туннелирование трафика). Не буду вдаваться в сравнительный анализ NAT/DR/TUN/L3DSR, (о режимах можно почитать, например, здесь), упомяну лишь причины:
- Мы не хотим накладывать на бэкенды требование находиться в общей подсети с LVS (в пулах содержатся бэкенды как из своего, так и из удалённых дата-центров);
- Бэкенд должен получать оригинальный source IP клиента (или его NAT), иными словами, source NAT не подходит;
- Бэкенд должен поддерживать одновременную работу с несколькими VIPs.
Мы балансируем и медиа-трафик (получилось очень сложно, собираемся отказываться), поэтому текущая схема деплоя в дата-центре выглядит следующим образом:

Текущая стратегия IPVS балансировки — “sed” (Shortest Expected Delay), о ней подробнее. В отличие от Weighted Round Robin/Weighted Least-Connection она позволяет не переливать трафик на бэкенды с меньшими весами, пока не достигнут определённый порог. Shortest expected delay вычисляется по формуле (Ci+1)/Ui, где Ci — количество соединений на бэкенде i, Ui — вес бэкенда. Например, если в пуле есть бэкенды с весами 50000 и 2, новые соединения будут распределяться по первым до тех пор, пока каждый сервер не достигнет 25000 соединений или пока не достигнут uthreshold — лимит на общее количество соединений.
Подробнее о стратегиях балансировки можно почитать в man ipvsadm.
IPVS-пул выглядит так (здесь и далее приведены выдуманные IP-адреса):
# ipvsadm -ln
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 1.1.1.1:5060 sed
-> 10.11.100.181:5060 Tunnel 50000 5903 4
-> 10.11.100.192:5060 Tunnel 50000 5905 1
-> 10.12.100.137:5060 Tunnel 2 0 0
-> 10.12.100.144:5060 Tunnel 2 0 0 Нагрузка на VIP распределяется по серверам с весом 50000 (они развернуты в том же дата-центре что и конкретный LVS инстанс), если они будут перегружены или попадут в блэклист, нагрузка польется на резервную часть пула, — серверы с весом 2, которые располагаются в соседнем дата-центре.
Точно такой же пул, но с весами наоборот, настроен в соседнем дата-центре (на продакшн-системе количество бэкендов, конечно, сильно больше).
Синхронизация соединений через ipvs sync позволяет резервному LVS знать о всех текущих соединениях.
Для работы синхронизации между дата-центрами был применён ”грязный” приём, который тем не менее отлично работает. Синхронизация IPVS работает только через multicast, который нам было сложно правильно доставить в соседний DC. Вместо multicast мы дублируем синхронизационный трафик посредством iptables target TEE от ipvs-мастера в ip-ip туннель до сервера в соседнем DC, причём целевых хостов/дата-центров может быть несколько:
#### start ipvs sync master role:
ipvsadm --start-daemon master --syncid 10 --sync-maxlen 1460 --mcast-interface sync01 --mcast-group 224.0.0.81 --mcast-port 8848 --mcast-ttl 1
#### duplicate all sync packets to remote LVS servers using iptables TEE target:
iptables -t mangle -A POSTROUTING -d 224.0.0.81/32 -o sync01 -j TEE --gateway 172.20.21.10 # ip-ip remote lvs server 1
iptables -t mangle -A POSTROUTING -d 224.0.0.81/32 -o sync01 -j TEE --gateway 172.20.21.14 # ip-ip remote lvs server 2
#### start ipvs sync backup role:
ipvsadm --start-daemon backup --syncid 10 --sync-maxlen 1460 --mcast-interface sync01 --mcast-group 224.0.0.81 --mcast-port 8848 --mcast-ttl 1
#### be ready to receive sync sync packets from remote LVS servers:
iptables -t mangle -A PREROUTING -d 224.0.0.81/32 -i loc02_srv01 -j TEE --gateway 127.0.0.1
iptables -t mangle -A PREROUTING -d 224.0.0.81/32 -i loc02_srv02 -j TEE --gateway 127.0.0.1На самом деле каждый наш LVS сервер играет сразу обе роли (master & backup), с одной стороны, это просто удобно, так как избавляет от смены ролей при переключении трафика, с другой — необходимо, так как каждый DC по умолчанию обрабатывает трафик своей группы публичных VIPs.
Переключение нагрузки между дата-центрами
В нормальном режиме работы каждый публичный IP-адрес анонсируется в Интернет отовсюду (на данной диаграмме из двух дата-центров). Входящий на VIP трафик маршрутизируется в нужный нам в данный момент DC с помощью BGP атрибута MED (Multi Exit Discriminator) с разными значениями для Active DC и Backup DC. При этом Backup DC всегда готов принять трафик, если с активным что-то случится:

Изменяя значения BGP MEDs и используя cross-location IPVS-sync, мы получаем возможность плавно перевести трафик с бэкендов одного дата-центра в другой, не влияя при этом на установленные телефонные вызовы, которые рано или поздно естественно завершатся. Процесс полностью автоматизирован (для каждого VIP у нас есть кнопка в менеджмент-консоли), и выглядит так:
SIP-VIP активен в DC1 (слева), кластер в DC2 (справа) является резервным, благодаря ipvs-синхронизации у него в памяти есть информация об установленных соединениях. Слева активные VIPs анонсируются со значением MED 100, справа — со значением 500:

Кнопка переключения вызывает изменение т.н. “target_state” (внутреннее понятие декларирующее значения BGP MEDs в данный момент времени). Здесь мы не надеемся что DC1 в порядке и готов обрабатывать трафик, поэтому LVS в DC2 приходит в состояние “force active”, понижая значение MEDs до 50, и таким образом перетягивает трафик на себя. Если бэкенды в DC1 живы и доступны, вызовы не разорвутся. Все новые tcp-соединения (регистрации) отправятся на бэкенды в DC2:
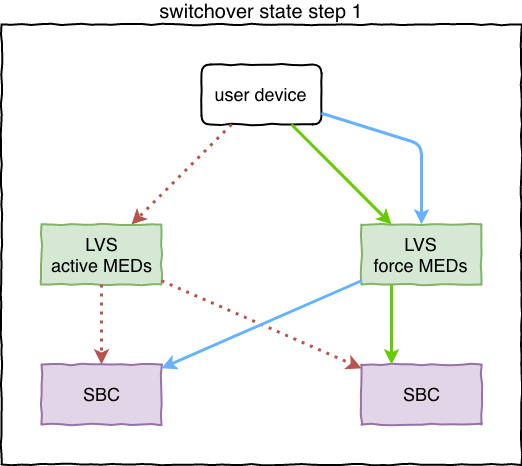
DC1 получил новый target_state репликацией и выставил backup значение MEDs (500). Когда DC2 узнаёт об этом, он нормализует и своё значение (50 => 100). Осталось дождаться завершения всех активных вызовов в DC1 и разорвать установленные tcp-соединения. SBC-инстансы в DC1 вводят нужные сервисы в т.н. состояние "graceful shutdown": на очередные SIP-запросы отвечают “503” и разрывают соединения, при этом новые соединения не принимают. Так же эти инстансы попадают в блэклист на LVS. При разрыве клиент устанавливает новую регистрацию/соединение, которая приходит уже в DC2:
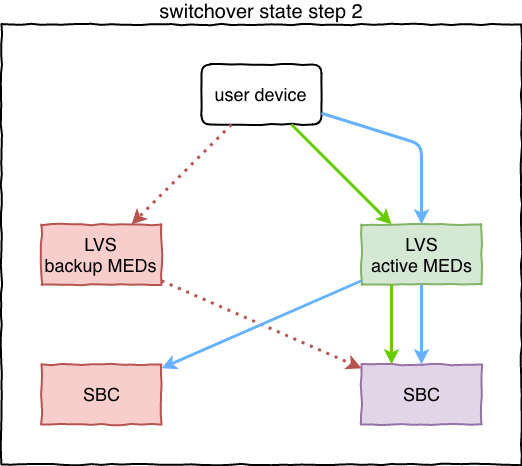
Процесс заканчивается, когда весь трафик в DC2.

DC1 и DC2 поменялись ролями.






В условиях постоянной высокой нагрузки на точки входа оказалось очень удобно иметь возможность переключать трафик в любой момент времени. Этот же механизм запускается автоматически, если backup DC вдруг стал получать трафик. При этом для защиты от флаппинга переключение срабатывает лишь один раз в одну сторону и выставляется блокировка на автоматические переключения, для её снятия требуется вмешательство человека.
Что внутри
VRRP cluster & IPVS manager: Keepalived. Keepalived отвечает за переключение VIPs внутри кластера, а также за backends healthchecking/blacklisting.
BGP Stack: ExaBGP. Отвечает за анонсы маршрутов на VIP-адреса и проставление соответствующих BGP MEDs. Полностью контролируется management сервером. Надёжный BGP-демон, написанный на Python, активно развивается, свою задачу выполняет на 100%.
Management server (API/Monitoring/sub-components management): Pyro4+Flask. Является Provisioning-сервером для Keepalived и ExaBGP, управляет всеми остальными настройками системы (sysctl/iptables/ipset/etc), обеспечивает мониторинг (gnlpy), добавляет и удаляет бэкенды по запросу (они общаются с его API).
Цифры
Виртуальная машина с четырьмя ядрами Intel Xeon Gold 6140 CPU @ 2.30GHz обслуживает поток трафика 300Mbps / 210Kpps (медиа-трафик, около 3 тысяч одновременных вызовов в пик-тайм процессится через них же). CPU utilization при этом — 60%.
Сейчас этого хватает, чтобы обслуживать трафик до 100 тысяч оконечных устройств (настольные телефоны). Для обслуживания всего трафика (больше 1 миллиона оконечных устройств) мы строим около 10 пар таких кластеров в нескольких дата-центрах.
