
Многие с подозрением относятся к перспективе чего-нибудь форкнуть и дописать самостоятельно. Зачастую цена слишком высока. Особенно странно слышать о собственных JDK, которые якобы есть в каждой достаточно крупной компании. Что за чертовщина, с жиру бесятся? В этой статье будет подробный рассказ о компании, которой всё это приносит реальную коммерческую выгоду, и которая проделала чудовищную работу, ведь они:
- Разработали мультитенантную виртуальную Java-машину;
- Придумали механизм работы объектов, не приносящих оверхеда на сборку мусора;
- Сделали что-то вроде аналога ReadyNow из Azul Zing;
- Запилили собственные корутины с yield-ами и континуациями (и даже готовы поделиться опытом с Loom, о котором я писал осенью);
- Прикрутили ко всем этим чудесам собственную подсистему диагностики.
Как всегда, видео, полная текстовая расшифровка и слайды ждут вас под катом. Добро пожаловать в ад одного из самых сложных направлений адаптации открытых проектов!

Доктор, откуда вы берёте такие картинки? Уголок «обложек O'Reilly»: бэкграунд для КДПВ предоставлен Joshua Newton и изображает священный танец Сангьянг Джаран в городе Убуде, Индонезия. Это классический балийский перформанс, состоящий из огня и трансового танца. Человек с непокрытыми пятками двигается вокруг костра, разведённого на кокосовой шелухе, распихивая ногами разное и танцуя в трансовом состоянии под действием конского духа. Идеальная иллюстрация для собственного JDK, правда?
Слайды и описание доклада (они вам не понадобятся, в этом хабратопике есть всё, что нужно).
Здравствуйте, меня зовут Санхонг Ли, я работаю в Alibaba, и я хотел бы рассказать о том, какие изменения мы внесли в OpenJDK для нужд нашего бизнеса. Пост состоит из трёх частей. В первой я расскажу о том, как в Alibaba используется Java. Вторая часть, на мой взгляд, самая важная — в ней мы обсудим, как мы настраиваем OpenJDK для потребностей нашего бизнеса. Третья часть будет об инструментах, которые мы создали для диагностики.
Но прежде, чем перейти к первой части, я хотел бы вкратце рассказать вам о нашей компании.
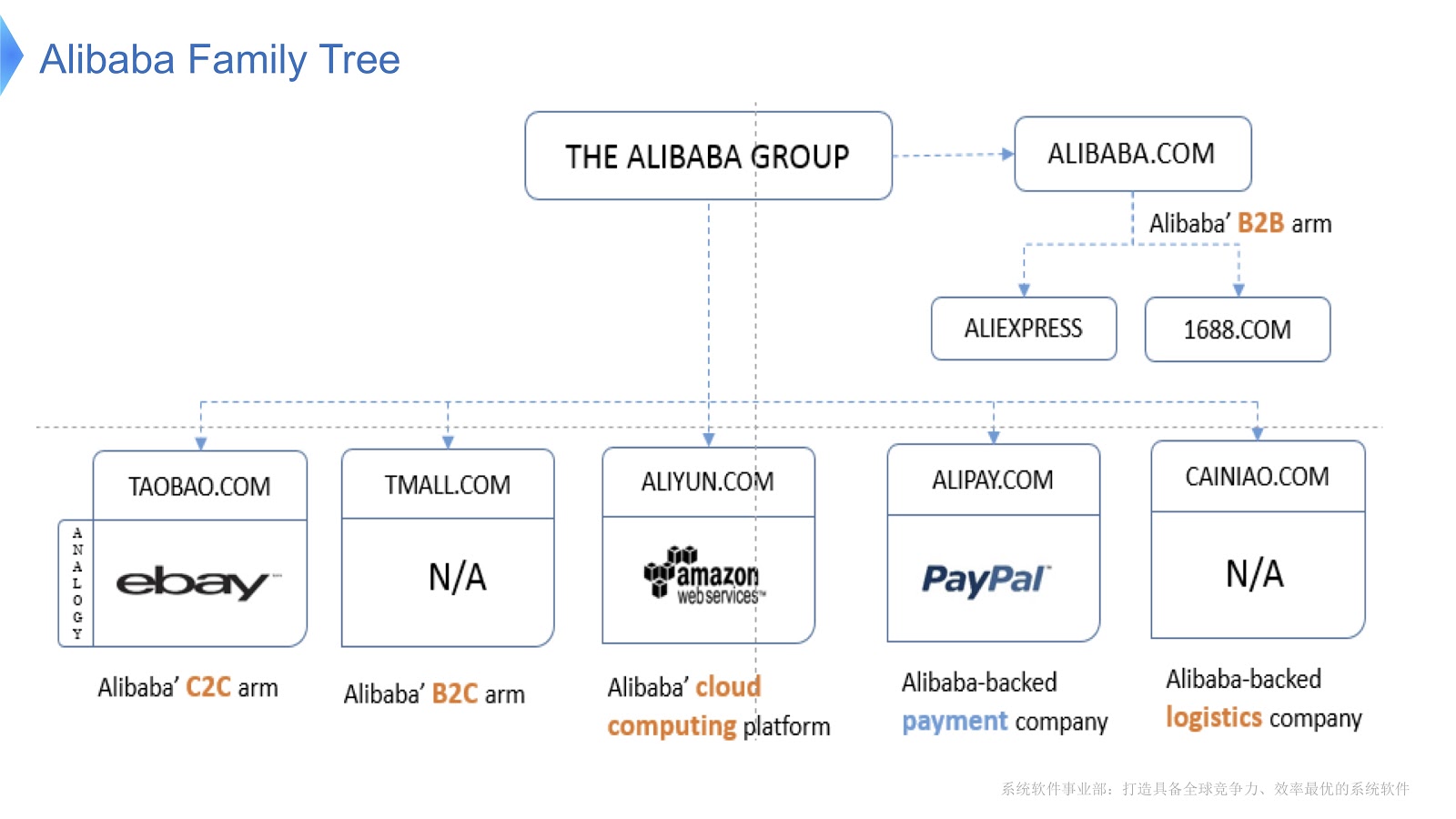
На диаграмме изображена внутренняя структура Alibaba. Она состоит из различных компаний, основная специализация которых — организация электронного рынка и предоставление финансовых и логистических платформ. Думаю, в России большинство знакомы с AliExpress. В Alibaba есть специальная команда программистов, которые занимаются разработкой и поддержкой всего распределенного стека, обеспечивающего обслуживание клиентов Aliexpress по всему миру.
Чтобы получить представление о масштабах работы Alibaba, давайте посмотрим, что происходит в Китае в День холостяков. Он отмечается каждый год 11 ноября, и в этот день люди покупают особенно много товаров через Alibaba. Насколько мне известно, из праздников во всём мире в этот происходит больше всего покупок.
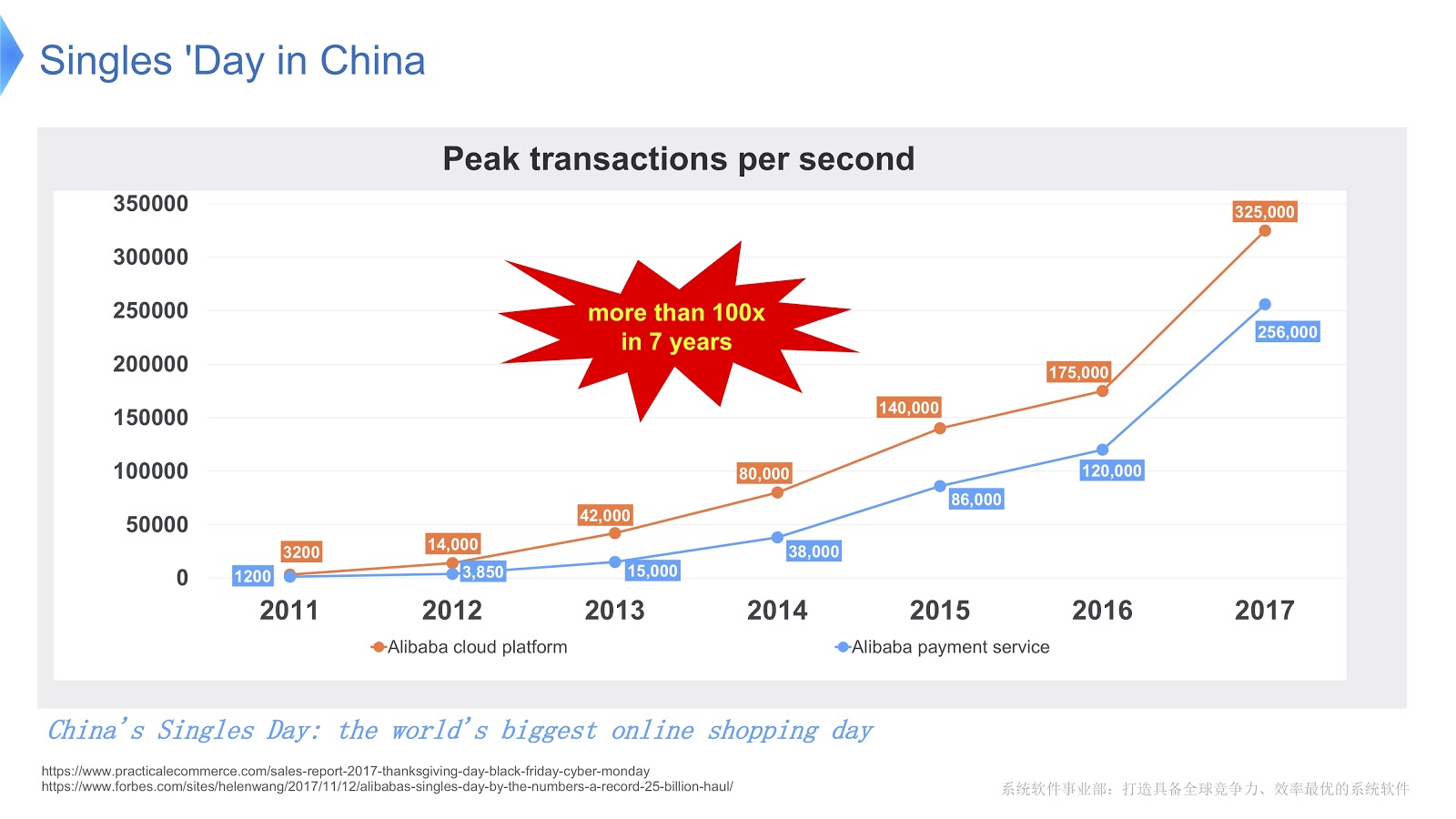
На картинке выше вы видите диаграмму, которая показывает нагрузку на нашу систему поддержки. Красная линия показывает работу нашей службы заказов и показывает пиковое число транзакций в секунду, в прошлом году оно составило 325 тысяч. Синяя линия относится к службе оплаты, и у неё этот показатель составляет 256 тысяч. Я бы хотел поговорить о том, как оптимизировать стек, обслуживающий настолько большое количество транзакций.
Обсудим основные технологии, которые работают в Alibaba вместе с Java. В первую очередь нужно сказать, что в качестве основы у нас выступает ряд опенсорсных приложений. Для обработки больших данных мы используем HBase Hadoop. В качестве контейнера мы используем Tomcat и OSGi. Java у нас используется в колоссальных масштабах — в нашем датацентре развёрнуты миллионы экземпляров JVM. Нужно также сказать, что наша архитектура сервисно-ориентированная, то есть мы создаём множество сервисов, которые общаются друг с другом при помощи RPC-вызовов. Наконец, наша архитектура гетерогенная. Для улучшения производительности многие алгоритмы написаны при помощи библиотек на С и С++, поэтому они общаются с Java при помощи JNI-вызовов.

История нашей работы с OpenJDK началась в 2011 году, во время OpenJDK 6. Есть три важных причины, по которым мы выбрали именно OpenJDK. Во-первых, мы можем напрямую изменять его код в соответствии с потребностями бизнеса. Во-вторых, когда возникают неотложные проблемы, мы можем разрешить их собственными силами быстрее, чем ждать официального релиза. Для нашего бизнеса это жизненно важно. В-третьих, наши Java-разработчики пользуются нашими собственными инструментами для быстрой и качественной отладки и диагностики.
Прежде чем перейти к техническим вопросам, хочется перечислить основные трудности, которые нам приходится преодолевать. Во-первых, у нас запущено огромное количество экземпляров JVM — в этой ситуации остро встаёт вопрос сокращения издержек, связанных с аппаратным обеспечением. Во-вторых, я уже говорил, что мы обслуживаем колоссальное количество транзакций. Благодаря сборщику мусора, Java обещает нам «бесконечную память». Кроме того, она выигрывает в производительности на низком уровне благодаря JIT-компилятору. Но у этого есть и оборотная сторона: более продолжительное время stop-the-world при сборке мусора. Кроме того, Java нужны дополнительные циклы CPU для компиляции Java-методов. Это значит, что компиляторы соревнуются за циклы CPU. Обе проблемы обостряются по мере усложнения приложения.
Третья трудность связана с тем, что у нас запущено множество приложений. Думаю, все здесь знакомы с инструментами, идущими вместе с OpenJDK, такими, как JConsole или VisualVM. Проблема в том, что они не дают необходимой нам точной информации для настройки. Кроме того, когда мы используем эти инструменты (например, JConsole или VisualVM) в продакшене, низкий оверхед является не просто пожеланием, а необходимым требованием. Пришлось написать собственные инструменты для диагностики.

На картинке в общих чертах представлены изменения, которые мы внесли в OpenJDK. Давайте взглянем, как мы преодолели те трудности, о которых я говорил выше.
Мультитенантная JVM
Одно из решений мы называем мультитенантной JVM. Она позволяет безопасно запускать несколько веб-приложений в одном контейнере. Другое решение называется GCIH (GC Invisible Heap). Это механизм, который предоставляет вам полноценные Java-объекты, которые при этом не требуют затрат по сборке мусора. Далее, чтобы снизить издержки на контексты тредов, мы реализовали корутины на нашей Java-платформе. Помимо этого мы написали механизм, который назвали JWarmup — его функция очень похожа на ReadyNow. Кажется, Дуглас Хокинс упоминал его в своем докладе. Наконец, мы разработали собственный инструмент для профилирования, ZProfiler.
Давайте подробнее взглянем на то, как мы реализуем мультитенантность на основе OpenJDK.
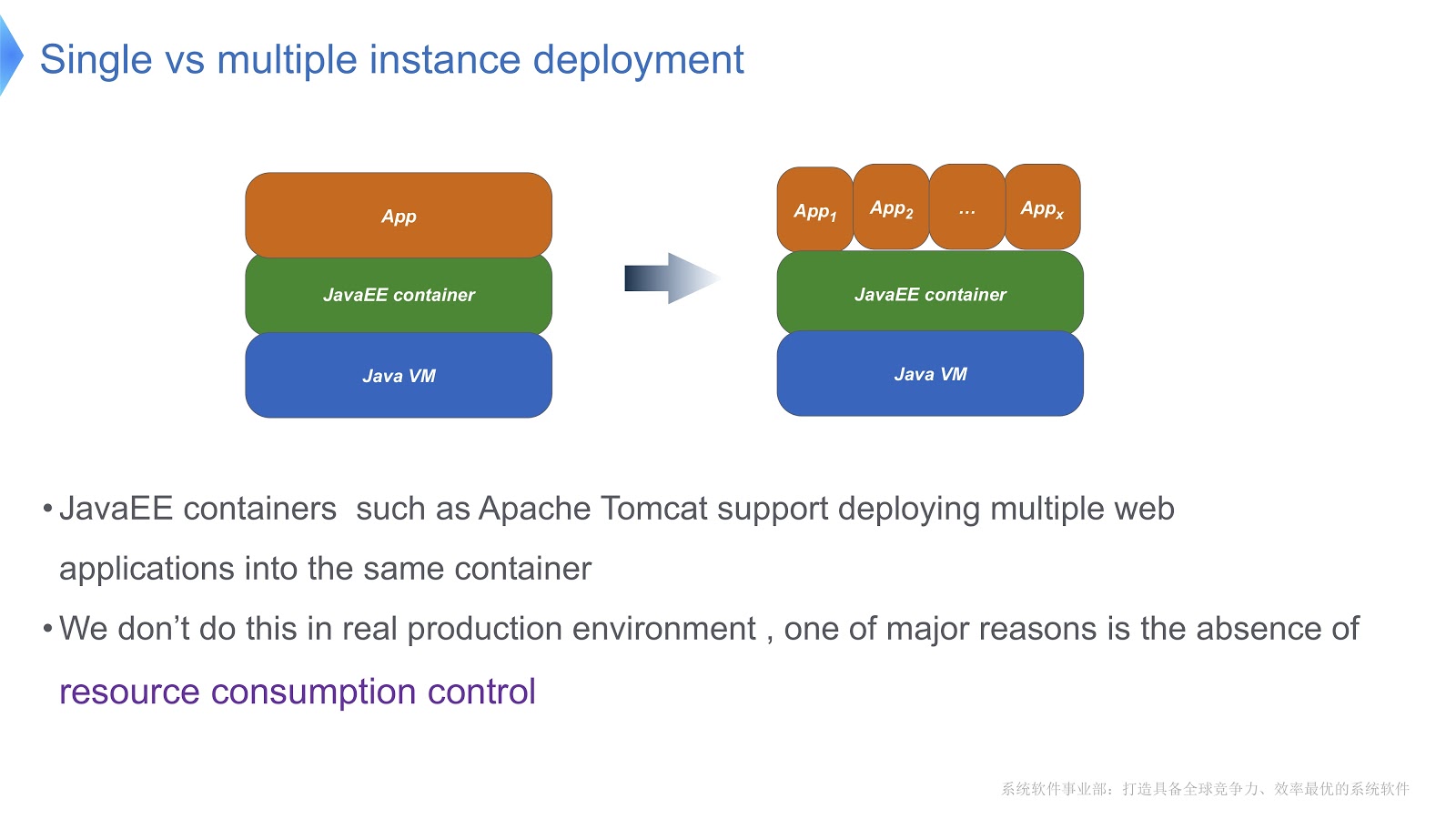
Взгляните на картинку выше — думаю, большинство из вас знакомы с подобной схемой. Сравним традиционный подход с мультитенантным. Если ваше приложение запущено с помощью Apache Tomcat, вы тоже можете запустить несколько экземпляров в одном контейнере. Но Tomcat не обеспечивает стабильное потребление ресурсов для каждого из них. Скажем, если одному из запущенных приложений необходимо больше времени CPU, чем другим, как вы будете контролировать распределение времени CPU? Как обеспечите, чтобы данное приложение не повлияло на работу других? Главным образом этот вопрос и заставил нас обратиться к мультитенантной технологии.
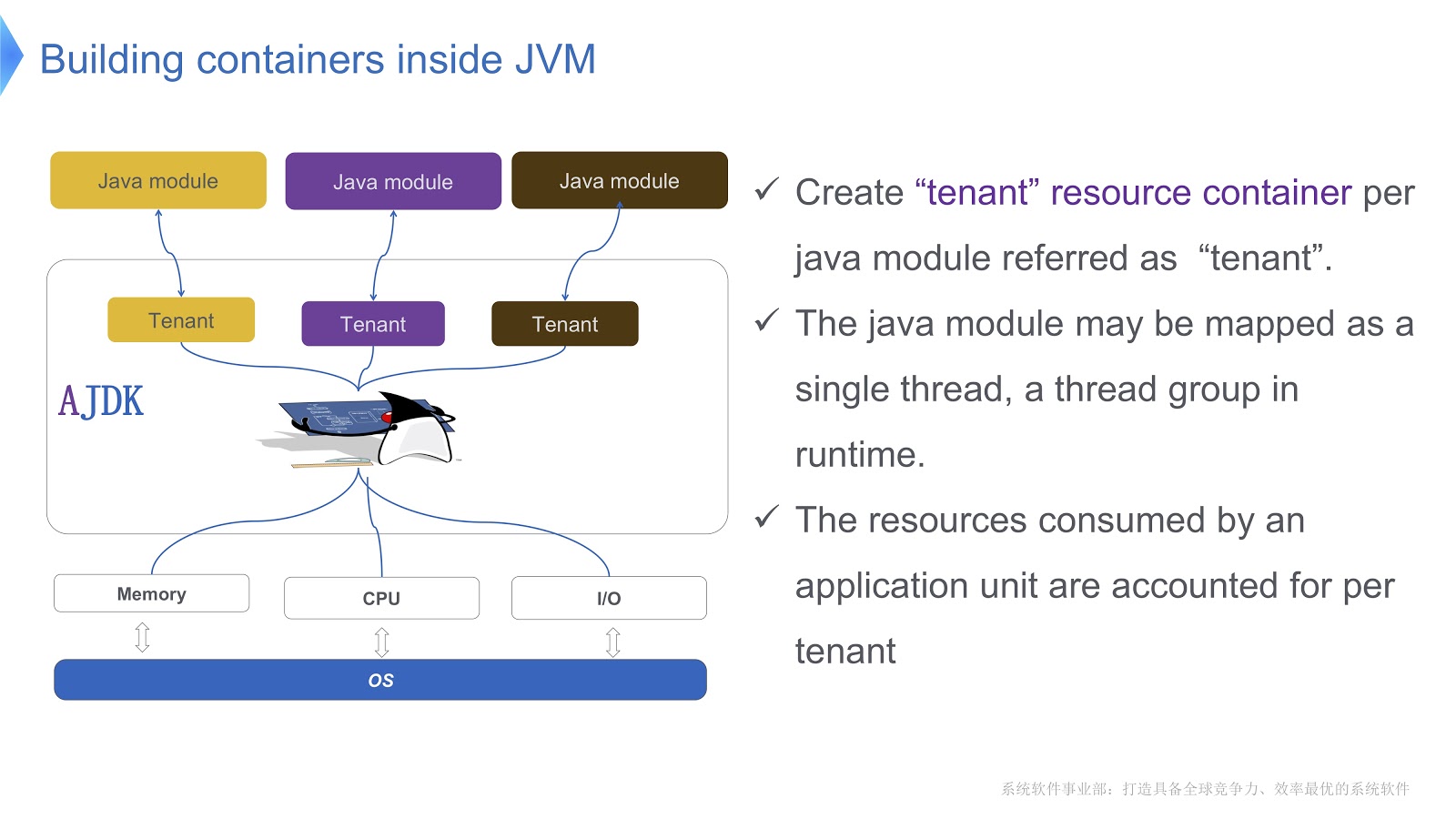
На картинке схематично представлено то, как мы её реализуем. Мы создаём несколько контейнеров для тенантов внутри JVM. Каждый из этих контейнеров предоставляет надёжный контроль потребления ресурсов для каждого Java-модуля. В одном контейнере может быть развёрнуто несколько модулей. Каждому модулю может быть сопоставлен один тред или группа тредов в рантайме.
Давайте познакомимся с тем, как выглядит API контейнера тенанта. У нас есть класс конфигурации тенанта, в котором хранится информация о потреблении ресурсов. Далее, есть класс собственно контейнера.
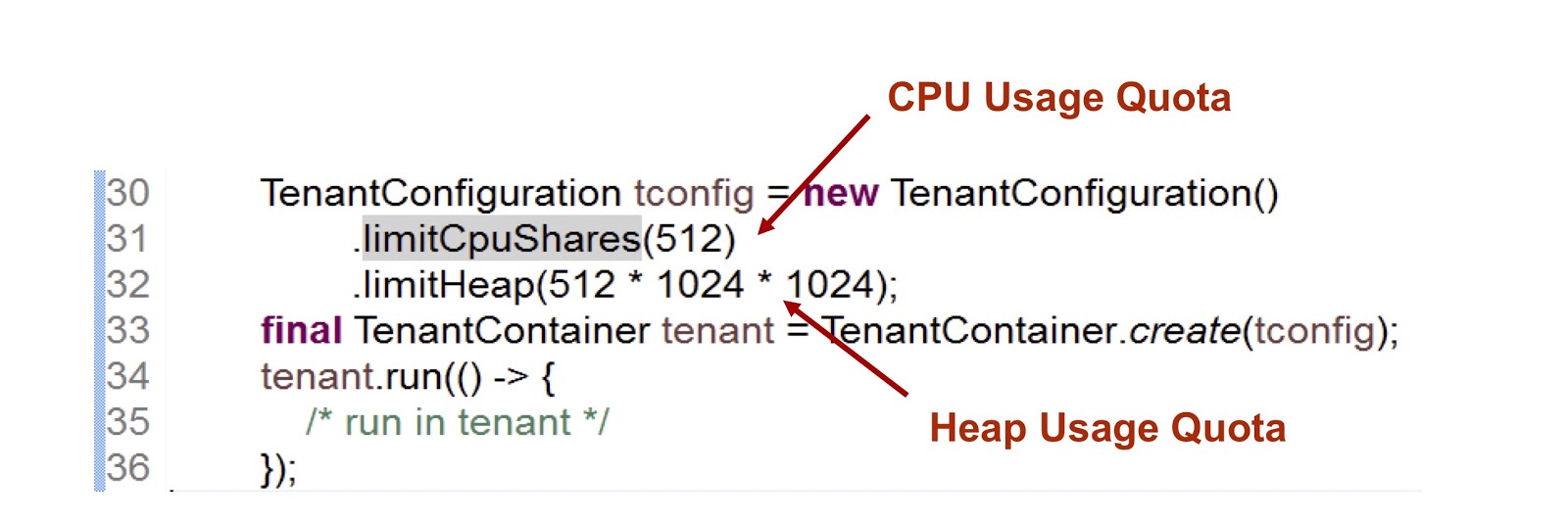
В представленном отрывке кода мы создаём одного тенанта, а затем указываем, сколько времени CPU и памяти ему предоставляется. Первый показатель — это целое число, которое означает доступную тенанту долю времени CPU, в данном случае мы указали 512. Очень похожий подход мы применяем в случае с cgroups, подробнее я на этом ещё остановлюсь. Второй показатель — это максимальный размер кучи, который может использовать тенант.
Рассмотрим, как тенант взаимодействует с тредом. Класс TenantContainer предоставляет метод .run(), и когда тред в него заходит, он автоматически прикрепляется к тенанту, а когда он его покидает, происходит обратная процедура. Так что весь код выполняется внутри метода .run(). Кроме того, любой тред, созданный внутри метода .run(), прикрепляется к тенанту родительского треда.
Мы подошли к очень важному вопросу — как происходит управление CPU в мультиарендной JVM? Наше решение было только что реализовано на платформе Linux x64. Там существует механизм контрольных групп, cgroups. Он позволяет выделять процесс в отдельную группу, а затем указывать свой режим потребления ресурсов для каждой группы. Попробуем перенести этот подход в контекст Hotspot JVM. В Hotstpot Java-треды организованы как нативные треды.

Это показано на схеме выше: каждый Java-тред находится во взаимно однозначном соответствии с нативным тредом. В нашем примере у нас есть контейнер TenantA, в котором находится два нативных треда. Чтобы получить возможность управлять распределением времени CPU, мы помещаем оба нативных треда в одну контрольную группу. Благодаря этому мы можем регулировать потребление ресурсов, полагаясь исключительно на функциональность [контрольных групп](https://en.wikipedia.org/wiki/Cgroups).
Давайте взглянем на более подробный пример.
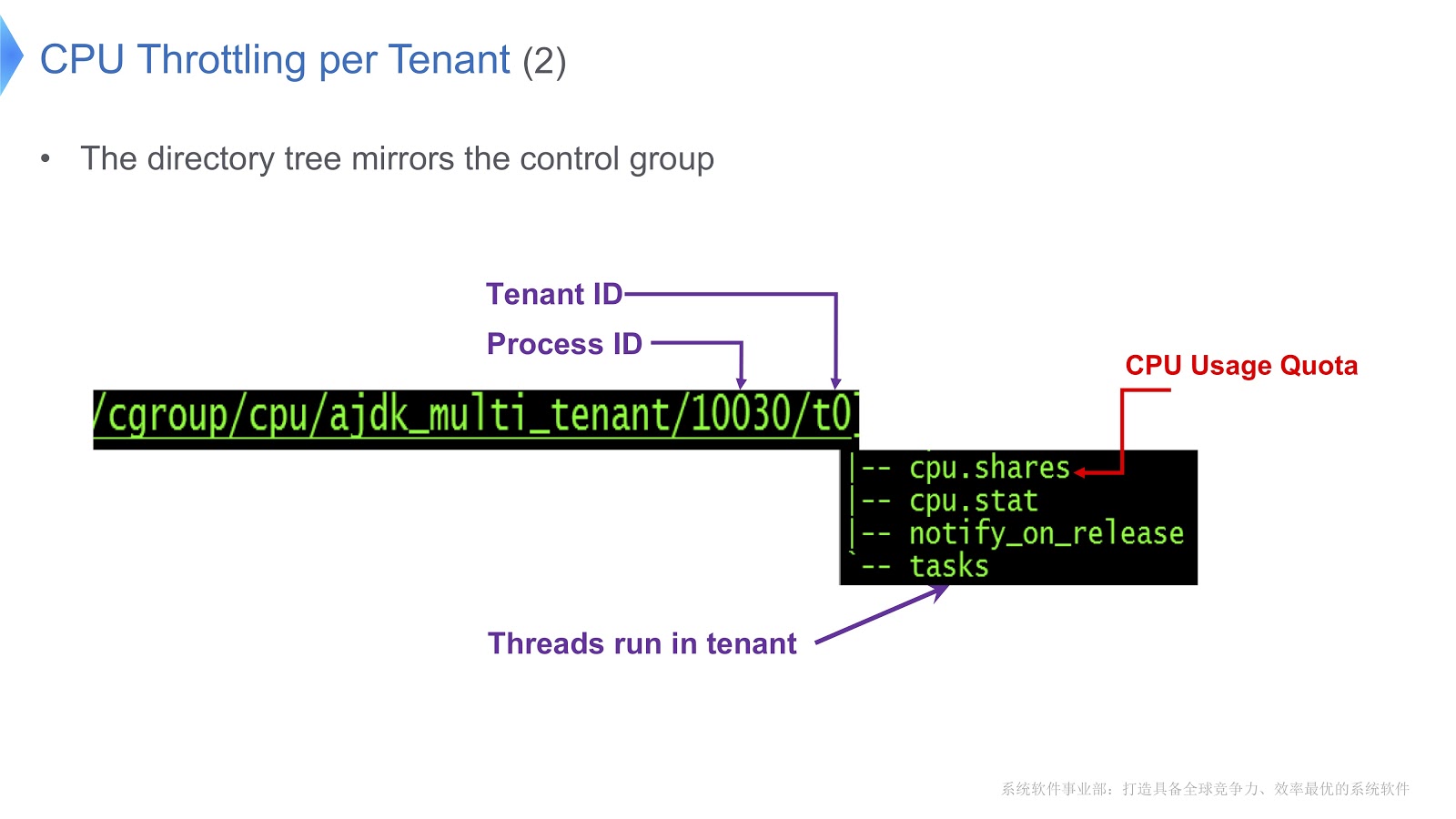
Control groups в Linux отображаются в директорию. В нашем примере мы создали каталог /t0 для тенанта 0. В этом каталоге находится каталог /t0/tasks, здесь будут находиться все треды для t0. Другой важный файл — /t0/cpu.shares. В нём указывается, сколько времени CPU будет предоставлено данному тенанту. Вся эта структура унаследована от контрольных групп — мы просто обеспечили прямое соответствие между Java-тредом, нативным тредом и контрольной группой.
Другой важный вопрос относится к управлению кучей каждого тенанта.
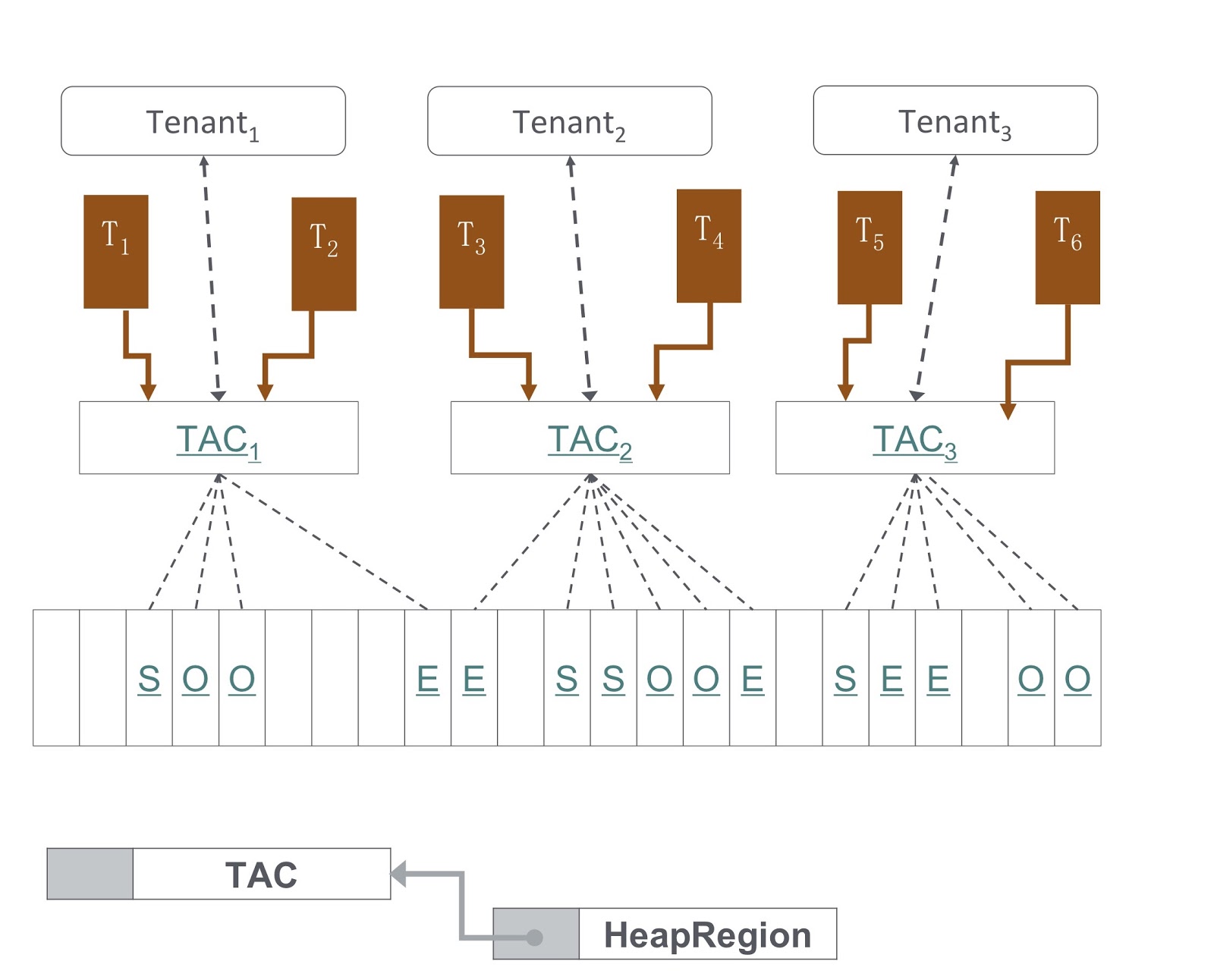
На картинке вы видите схему того, как оно реализовано. Наш подход основан на G1GC. Внизу картинки показано, что G1GC делит кучу на участки одинакового размера. На основе них мы создаём Tenant Allocation Contexts, TAC-и, при помощи которых тенант управляет своим участком кучи. Через TAC мы ограничиваем размер участка кучи, доступный тенанту. Здесь действует принцип, согласно которому каждый участок кучи содержит объекты только одного тенанта. Чтобы его реализовать, нам было необходимо внести изменения в процесс копирования объекта при сборке мусора — нужно было обеспечить, чтобы объект копировался в правильный участок кучи.
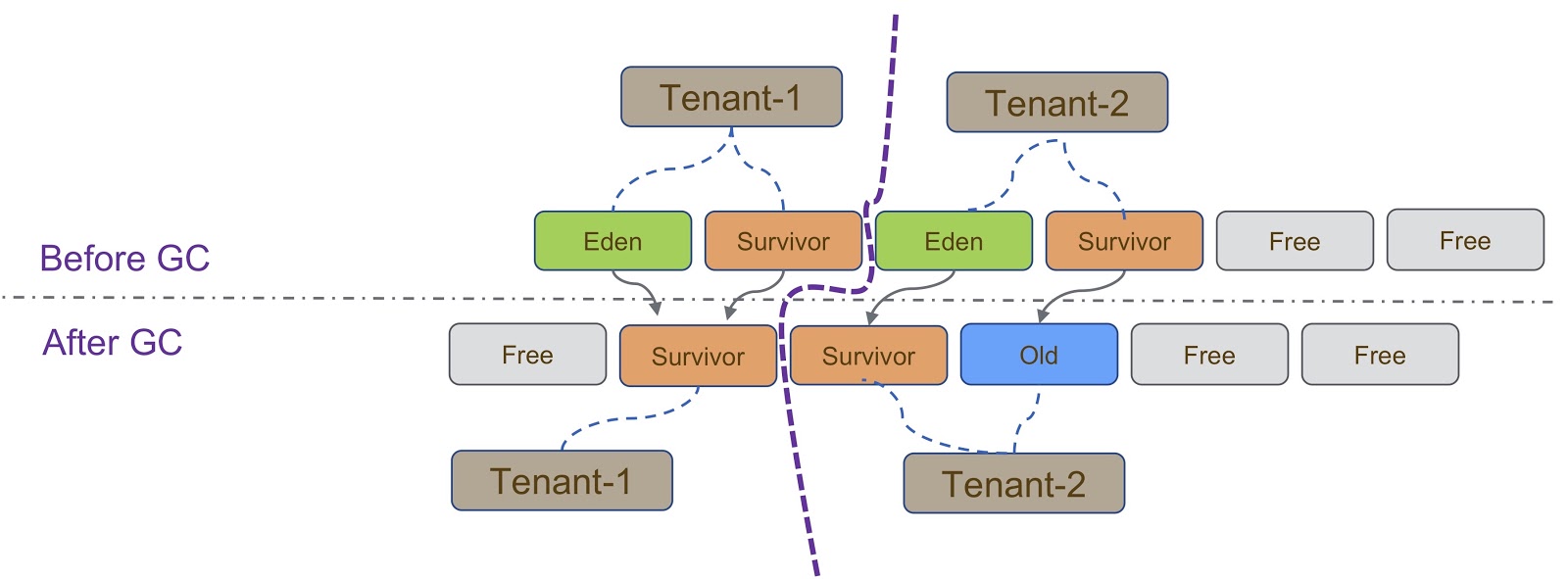
Схематично этот процесс изображён на схеме выше. Как я уже говорил, наша реализация основана на G1GC. G1GC — копирующий сборщик мусора, поэтому во время сборки мусора нам необходимо убедиться, что объект скопирован в правильный участок кучи. На слайде все объекты, созданные Tenant-1, должны быть скопированы в его участок кучи, аналогично с Tenant-2.
Есть и другие соображения, которые возникают при изоляции тенантов друг от друга. Здесь нужно сказать о TLAB (Thread Local Allocation Buffer) — это механизм быстрого выделения памяти. Пространство TLAB зависит от участка кучи. Как я уже говорил, у разных тенантов разные группы участков кучи.

Специфика работы с TLAB показана на слайде — когда тред переключается с Tenant 1 на Tenant 2, нам необходимо убедиться, что для пространства TLAB используется правильный участок кучи. Это можно обеспечить двумя способами. Первый способ — когда Thread A переключается с Tenant 1 на Tenant 2, мы просто избавляемся от старого, и создаём новый в Tenant 2. Этот метод относительно легко реализовать, но он тратит впустую место в TLAB, что нежелательно. Второй способ более сложный — сделать так, чтобы TLAB знал о тенантах. Это значит, что у нас будет несколько буферов TLAB для одного треда. Когда Thread A переключается с Tenant 1 на Tenant 2, нам нужно поменять буфер и использовать тот, который был создан в Tenant 2.
Другой механизм, о котором нужно сказать в связи с разграничением тенантов — это IHOP (Initiating Thread Occupancy Percent). Изначально IHOP рассчитывался на основе всей кучи, но в случае мультитенантного механизма его необходимо рассчитывать на основе только одного участка кучи.
Давайте подробнее рассмотрим, чем является GCIH (GC Invisible Heap). Этот механизм создаёт участок в куче, скрытый от сборщика мусора, и, соответственно, никак не затрагиваемый сборкой мусора. Этот участок управляется тенантом GCIH.

Здесь важно сказать, что мы предоставляем публичный API нашим Java-разработчикам. Пример работы с ним можно увидеть на экране. Он позволяет при помощи метода moveIn() перемещать объекты из обычной кучи в участок кучи GCIH. Его преимущество в том, что с этими объектами по-прежнему можно взаимодействовать, как с обычными Java-объектами, они устроены очень похоже. Но при этом они не требуют затрат на сборку мусора. Вывод, на мой взгляд, в том, что, если вы хотите ускорить сборку мусора, вам необходимо настроить поведение сборщика мусора в соответствии с потребностями вашего приложения.
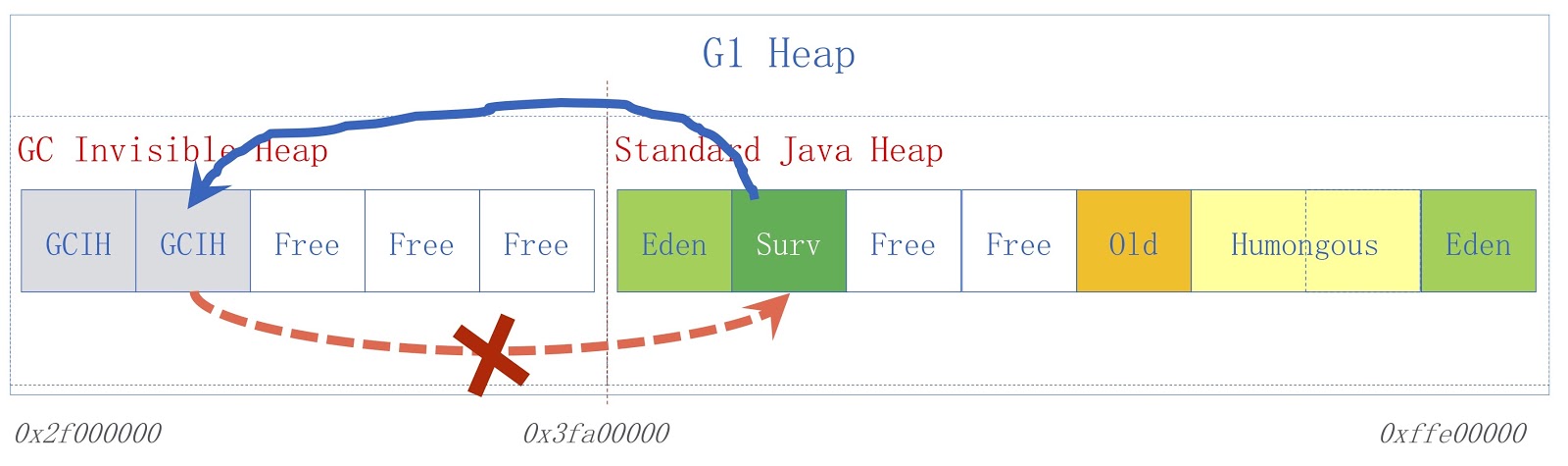
На картинке представлена высокоуровневая схема GCIH. Справа изображена обычная Java-куча, слева — пространство, выделенное под GCIH. Ссылки из обычной кучи на объекты в GCIH допустимы, а вот ссылки из GCIH на обычную кучу — нет. Чтобы понять, почему это так, рассмотрим пример. У нас есть объект «А» в GCIH, который содержит ссылку на объект «Б» в обычной куче. Проблема в том, что объект «Б» может быть перемещён сборщиком мусора. Как я уже говорил, мы не делаем обновлений в GCIH, так что после работы сборщика мусора в объекте «А» может содержаться недопустимая ссылка на объект «Б». Решить эту проблему можно при помощи pre-write barrier — о них речь шла в предыдущем докладе. В качестве примера предположим, что кому-то необходимо сохранить ссылку из обычной Java-кучи на GCIH до того сохранения, которое мы предполагали, это приведет к появлению исключения предиктора с флагом-индикатором того, что было нарушено правило.
Что касается конкретного применения, мультитенантная JVM используется в нашей Taobao Personalization Platform, сокращённо TPP. Это система рекомендаций для нашего приложения электронных покупок. TPP может разворачивать несколько микросервисов в одном контейнере, а при помощи мультитенантной JVM мы регулируем память и время CPU, предоставляемое каждому микросервису.
Что касается GCIH, она используется в другой нашей системе, UM Platform. Это онлайн-приложение для дисконтирования. Владелец этого приложения использует GCIH для предварительного кэширования данных GCIH на локальной машине, чтобы не обращаться за объектами к удалённому серверу кэша или удалённой базе данных. В результате мы облегчаем нагрузку на сеть и осуществляем меньше сериализаций и десериализаций.
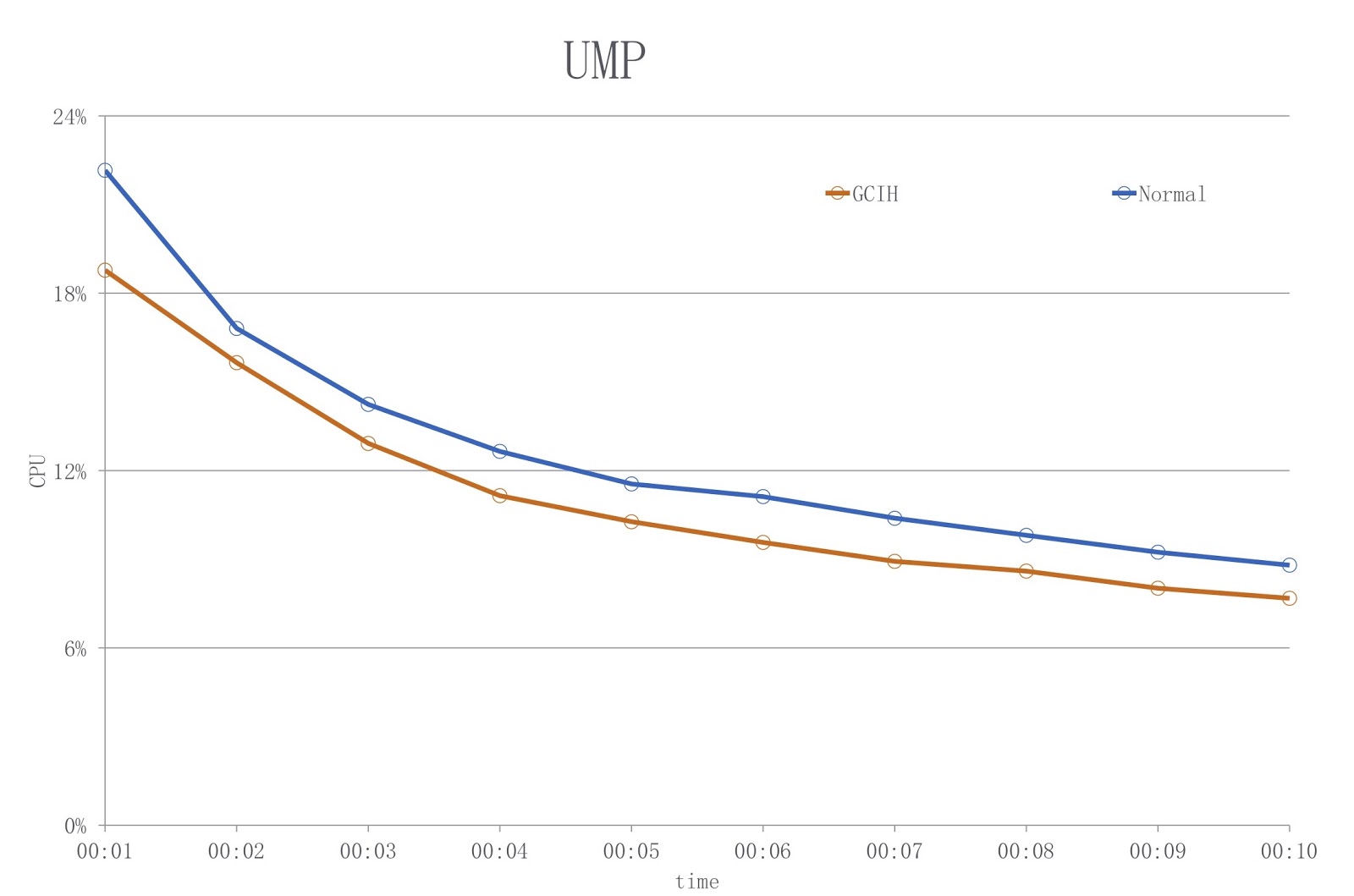
На картинке представлена диаграмма, на которой синим цветом показана нагрузка при использовании обычного JDK, а красным — GCIH. Как видим, мы сокращаем использование CPU на 18% с лишним.
Насколько мне известно, похожую проблему решала компания BellSoft, и их решение было похожим на GCIH, но они использовали другой подход для сокращения издержек по сериализации и десериализации.
Корутины в Java
Давайте теперь вернёмся к Alibaba и рассмотрим, как в Java можно реализовать корутины. Но вначале поговорим о истоках, о том, зачем вообще этим нужно заниматься. В Java всегда очень легко было писать приложения с многопоточностью. Но проблема при создании таких приложений в том, что, как я уже говорил, в Hotspot Java-треды уже реализованы как нативные треды. Поэтому, когда в вашем приложении много тредов, издержки по смене контекста треда становятся очень высокими.

Рассмотрим пример, в котором у нас будет 4 треда I/O и 200 тредов с логикой вашего приложения. В таблице на экране представлены результаты запуска этой простой демки — видно, насколько много времени CPU занимает смена контекстов. Решением для этой проблемы может быть реализация корутин в Java.
Чтобы её обеспечить, нам нужны были две вещи. Во-первых, в Alibaba JDK необходимо было добавить поддержку продолжений. Эта работа была основана на патче JKU, подробнее на ней мы ещё остановимся. Во-вторых, мы добавили user-mode шедулер, который будет ответственным за продолжения в треде. В-третьих, в Alibaba очень много приложений. Поэтому наше решение очень важно для наших Java-разработчиков, и его необходимо было сделать абсолютно прозрачным для них. А это значит, что в нашем бизнес-приложении не должно было быть практически никаких изменений в коде. Назвали мы наше решение Wisp. Наша реализация сопрограмм в Java широко используется в Alibaba, так что можно считать доказанным, что оно работает в Java. Познакомимся с ним подробнее.

Начнём с примера, код которого представлен выше — это вполне обычное Java-приложение. Вначале создаётся пул тредов. Затем создаётся другая Runnable-задача, которая принимает сокет. После этого выполняется чтение из потока. Далее мы создаём ещё одну Runnable-задачу, при помощи которой подключаемся к серверу и, наконец, записываем данные в поток. Как видите, всё выглядит вполне стандартно. Если запустить код на обычном JDK, каждая из этих Runnable-задач будет выполняться в отдельном треде. Но в нашем решении механика будет совсем другая.
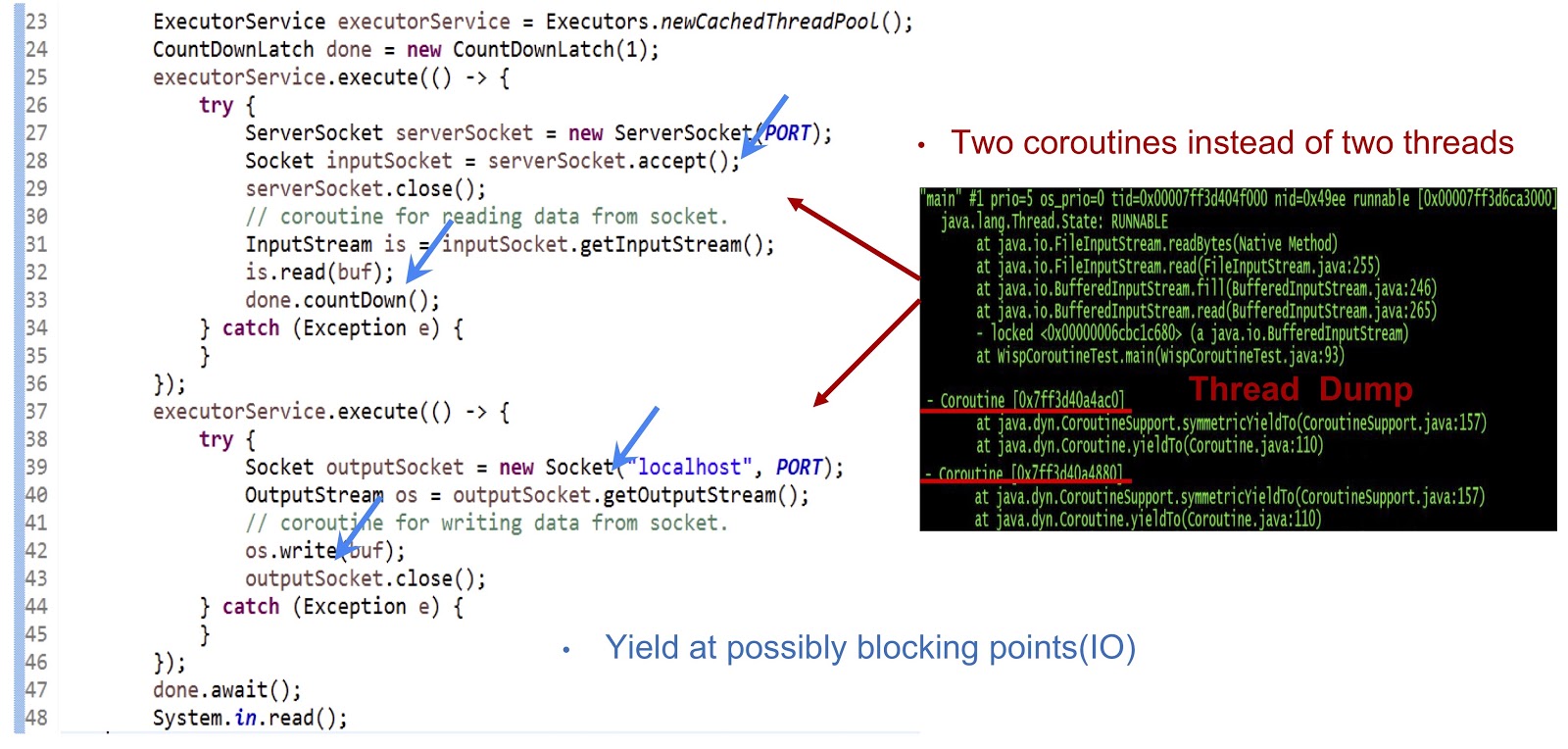
Как видно из дампа треда, представленного на слайде, мы создаём две сопрограммы в одном треде, а не два треда. Теперь необходимо добиться того, чтобы это решение работало. Главное здесь — сделать генерацию yieldTo-событий во всех возможных точках блокировки. В нашем примере этими точками будут serverSocket.accept(), is.read(buf), подключение к сокету и os.write(buf). Благодаря yield-событиям в этих точках мы сможем передавать управление от одной корутины к другой внутри одного треда. Если обобщить, то наш подход заключается в том, что мы добиваемся асинхронной производительности при помощи корутин, но при этом наши программисты могут писать код в синхронном стиле, поскольку такой код значительно проще, и его легче поддерживать и отлаживать.
Давайте рассмотрим, как именно мы обеспечили поддержку продолжений в Alibaba JDK. Как я уже сказал, эта работа основана на многоязычном проекте виртуальной машины, созданном сообществом — он находится в общем доступе. Мы использовали этот патч в Alibaba JDK и исправили некоторые баги, возникшие в нашей среде продакшна.
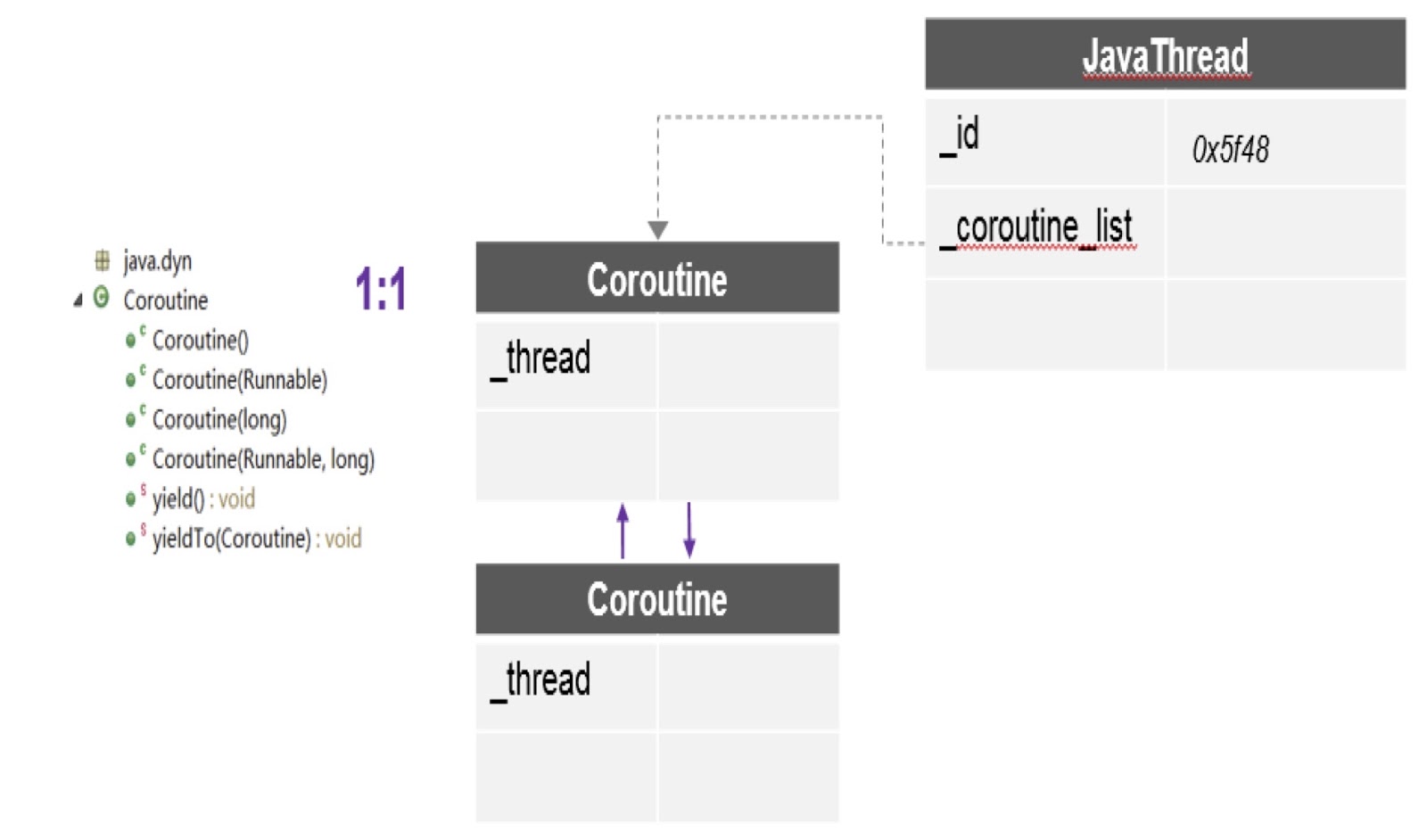
Как видно на схеме, здесь в одном треде может быть несколько корутин, и для каждой создаётся отдельный стек. Кроме того, патч, о котором я говорил, предоставляет нам самый важный здесь API — yieldTo, при помощи него происходит передача управления от одной корутины другой.
Перейдём к тому, как мы реализовали user-mode шедулер для корутин. Мы используем селектор, и при помощи него регистрируем несколько каналов. Когда происходит какое-либо событие I/O (socket read, socket write, socket connect или socket accept) оно записывается как ключ для селектора. Поэтому при завершении этого события мы получаем оповещение от селектора. Таким образом, мы используем селектор для планирования сопрограмм в случае блокировки I/O. Рассмотрим пример того, как это будет работать.
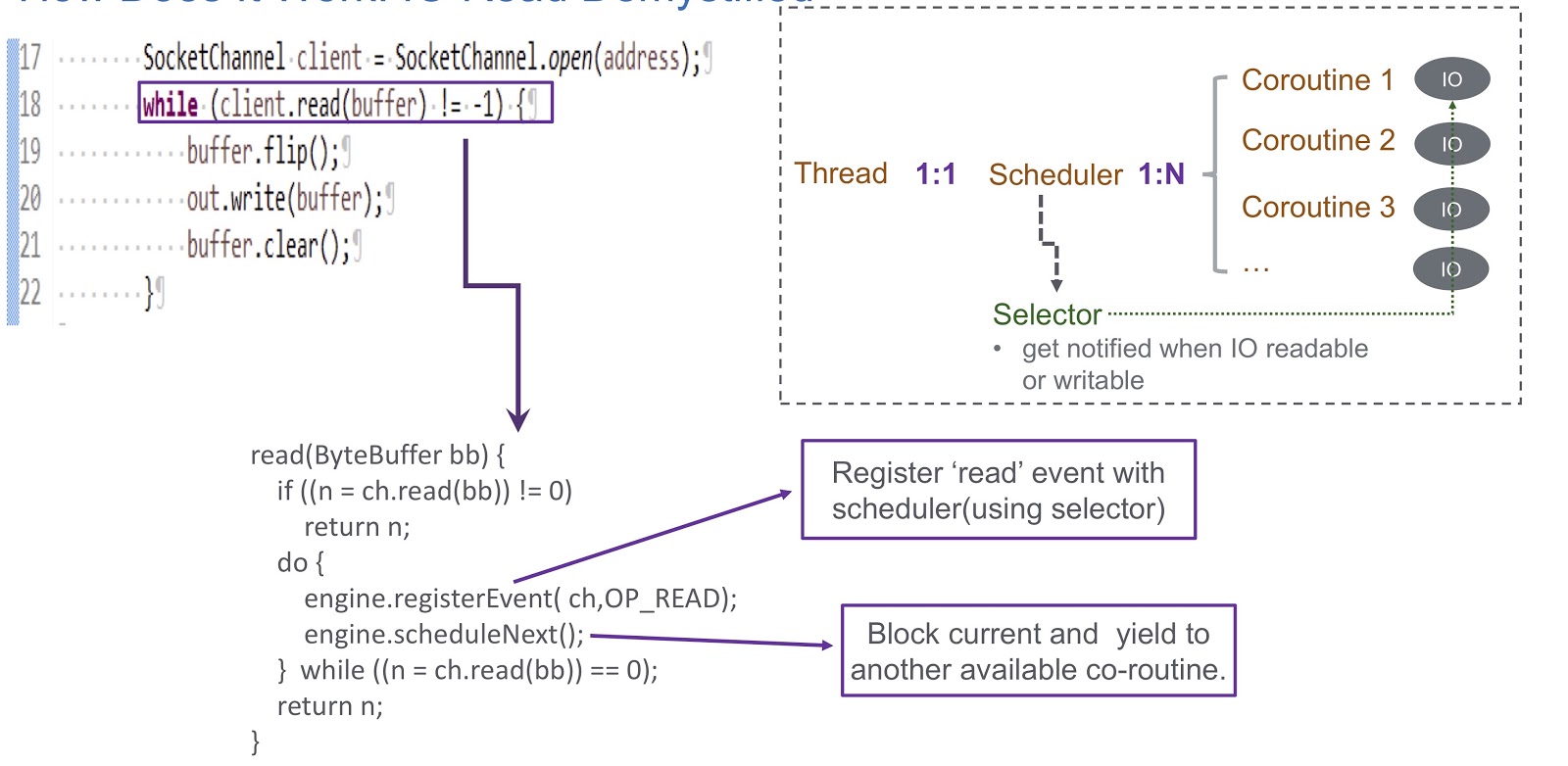
На картинке мы видим сокет и синхронный вызов client.read(buffer). Внизу слайда написан код, который будет выполняться внутри этого вызова. Вначале там проверяется, можно ли осуществлять чтение из канала или нет. Если да, то мы возвращаем полученный результат. Самое интересное происходит, если чтение выполнять нельзя. Тогда мы регистрируем событие чтения в нашем планировщике при помощи selector. Это даёт возможность запланировать выполнение какой-либо другой корутины. Взглянем на то, как это происходит. У нас есть тред, в котором создаётся планировщик. Тред и наша корутина находятся во взаимно однозначном соответствии друг с другом. Шедулер позволяет нам управлять корутинами этого треда. Что же происходит в случае блокировки I/O? Когда происходят события I/O, шедулер получает оповещение, и в этой ситуации он целиком полагается на селектор. После такого события шедулер получает возможность запланировать следующую доступную корутину.
Давайте подведём итог обзору работы нашего шедулера, который мы назвали WispEngine. Для каждого нашего треда мы выделяем отдельный WispEngine. Когда происходит блокировка корутины, мы регистрируем определённые события (socket read/write и так далее) при помощи WispEngine. Некоторые события связаны связаны с парковкой треда, например, если вы вызываете thread.sleep() с задержкой в 100 миллисекунд. В этом случае у вас будет сгенерировано событие парковки треда, которое затем будет зарегистрировано в селекторе. Другой важный вопрос — когда шедулер назначает выполнение следующей доступной корутины. Здесь есть два основных условиях. Первое — это когда генерируются определённые события, например, события I/O или события тайм-аута. Здесь всё довольно просто: предположим, вы делаете вызов thread.sleep() с задержкой в 200 миллисекунд. Когда они истекают, у шедулера есть возможность выполнить следующую доступную корутину. Или здесь речь может идти о некоторых событиях распарковки, которые генерируются, скажем, при вызове object.notify() или object.notifyAll() Второе условие — когда пользователь подаёт новые запросы, и мы создаём корутину для обслуживания этих запросов, а затем шедулер назначает её выполнение.
Здесь также нужно сказать о созданном нами сервисе, WispThreadExecutor.

На экране представлен пример кода, и мы видим, что это обычный ExecutorService, создаётся таким же образом. У него доступны методы .execute() и submit() для Runnable-задач, но проблема в том, что все прошедшие через метод submit() Runnable-задачи будут выполняться в корутине, а не в треде. Это решение полностью прозрачно для тех, кто будет реализовать наше приложение, они смогут пользоваться нашим API для сопрограмм.

Я подхожу к последней трудной части поста — как решить вопрос синхронизации в корутинах. Это сложный вопрос, поэтому давайте рассмотрим его на упрощённом примере. Здесь у нас есть корутина А (test::foo) и корутина В (test::bar). Вначале мы назначаем выполнение test:foo в корутине А. Затем корутина А вызывает wait(). Если ничего не предпринять, то текущий тред окажется заблокирован вызовом wait(). Как видно из этого дампа треда, возникнет взаимоблокировка, и у нас не будет возможности назначить выполнение следующей корутины.
Как решить эту проблему? Hotspot предоставляет три типа блокировок. Первая — fast lock. Здесь владелец блокировки определяется адресом в стеке. Как я уже говорил, у каждой из наших корутин есть отдельный стек. Поэтому в случае с fast lock нам никакой дополнительной работы делать не нужно. Аналогичной поддержки для biased lock в нашей системе нет. Мы попробовали это на нашем продакшене и выяснилось, что при отсутствии biased lock производительность не уменьшается. Для нас это вполне подходит.
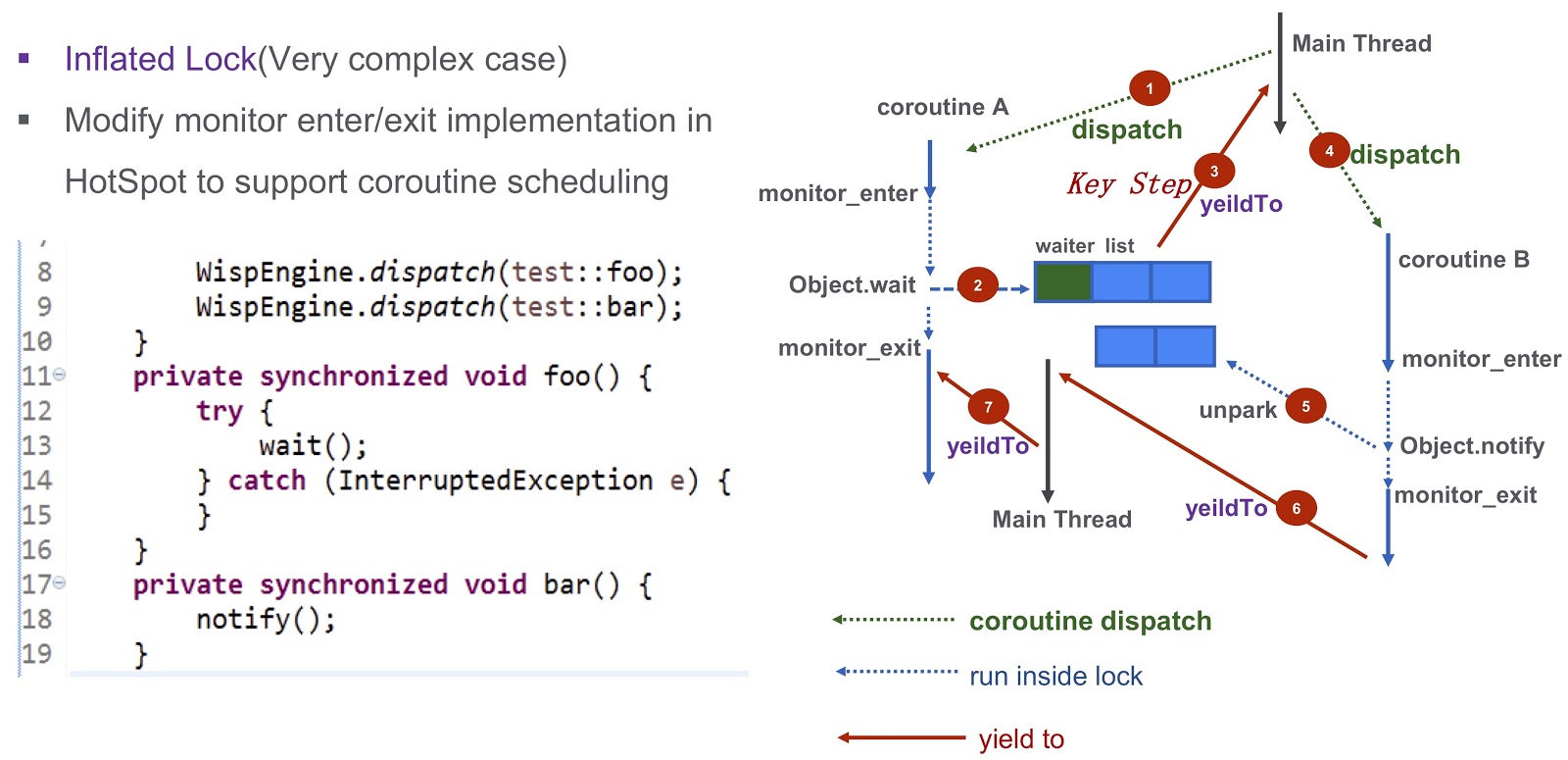
Поговорим о более сложном случае — inflated lock. Взглянем снова на пример, который я приводил выше. У нас есть корутина А (.foo()) и корутина B (.bar()). Вначале мы назначаем выполнение корутины А и запускаем её. Затем она вызывает Object.wait, после чего она попадает в список ожидания. После этого мы делаем очень важный шаг: генерируем событие yieldTo, которое передаёт управление главному треду. Далее мы запускаем корутину B. В ней делается вызов Object.notify, и генерируются соответствующие события unpark. В конечном итоге они разбудят сопрограмму А. После того, как будет закончено выполнение bar(), появится возможность передать управление корутине А. Таким образом, взаимоблокировка, о которой я говорил ранее, полностью преодолена.
Давайте теперь обсудим производительность. Мы используем корутины в одном из наших онлайн-приложений Carts. На основании него мы можем сравнить работу корутин с работой обычного JDK.
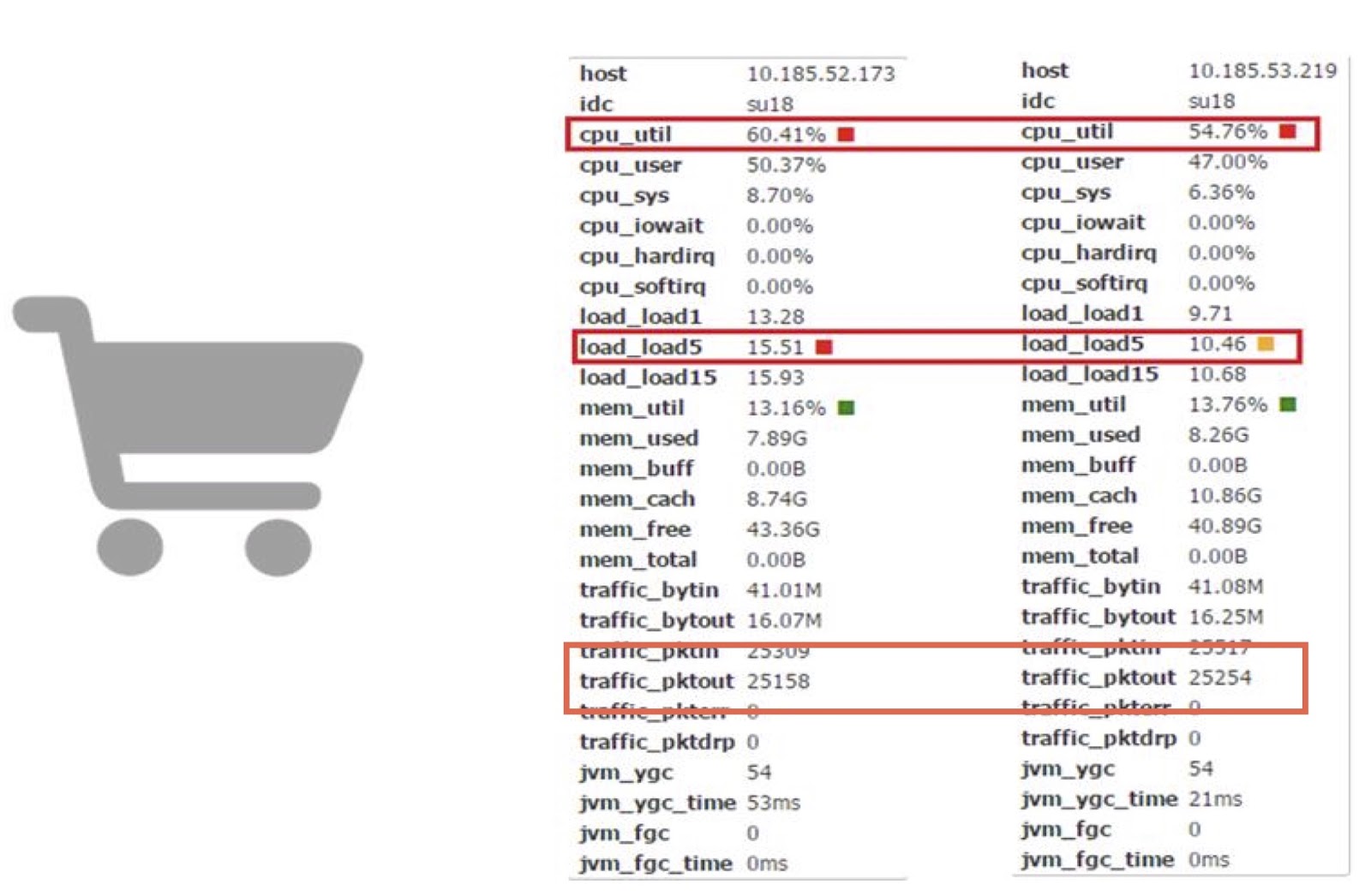
Как видите, они позволяют нам сократить потребление времени процессора почти на 10%. Я понимаю, что у большинства из вас, скорее всего, нет возможности делать напрямую такие сложные изменения в коде JDK. Но главный вывод здесь, на мой взгляд, в том, что если потери производительности стоят денег и получившаяся сумма достаточна велика, можно попытаться улучшить производительность при помощи библиотеки корутин.
JWarmup
Перейдём к другому нашему инструменту — JWarmup. Он очень похож на другое средство, ReadyNow. Как мы знаем, в Java есть проблема разогрева — компилятор на этом этапе требует дополнительных циклов CPU. Это вызывало у нас неполадки — например, возникала ошибка TimeOut Error. При масштабировании эти проблемы только ухудшаются, а в нашем случае речь идёт об очень сложном приложении — больше 20 тыс. классов и больше 50 тыс. методов.
Прежде, чем мы начали пользоваться JWarmup, собственники нашего приложения использовали имитированные данные для разогрева. На этих данных JIT-компилятор выполнял предварительную компиляцию, пока запросы ещё не поступили. Но имитированные данные отличаются от реальных, поэтому для компилятора они не репрезентативны. В некоторых случаях происходила неожиданная деоптимизация, производительность страдала. Решением этой проблемы стал JWarmup. У него два основных этапа работы — запись и компиляция. В Alibaba есть два типа сред, бета и продакшн. И те, и другие получают реальные запросы от пользователей, после чего одну и ту же версию приложения разворачивают в этих двух средах. В бета-среде происходит только сбор данных профилирования, на основе которых затем выполняется предварительная компиляция в продакшне.

Давайте посмотрим более подробно, какого рода информация мы собираем. Нам необходимо записать, какие именно классы инициализируются, какие методы компилируются, затем эти данные сбрасываются в журнал на жёстком диске, который доступен компилятору. Наиболее сложный момент — это инициализация классов. Её порядок полностью зависит от логики приложения. На слайде представлен пример — инициализация класса Bar должна происходить после выполнения Foo.test(), поскольку она использует foo.count. В этой ситуации мы выполняем инициализацию в момент, когда вся необходимая логика уже выполнена.
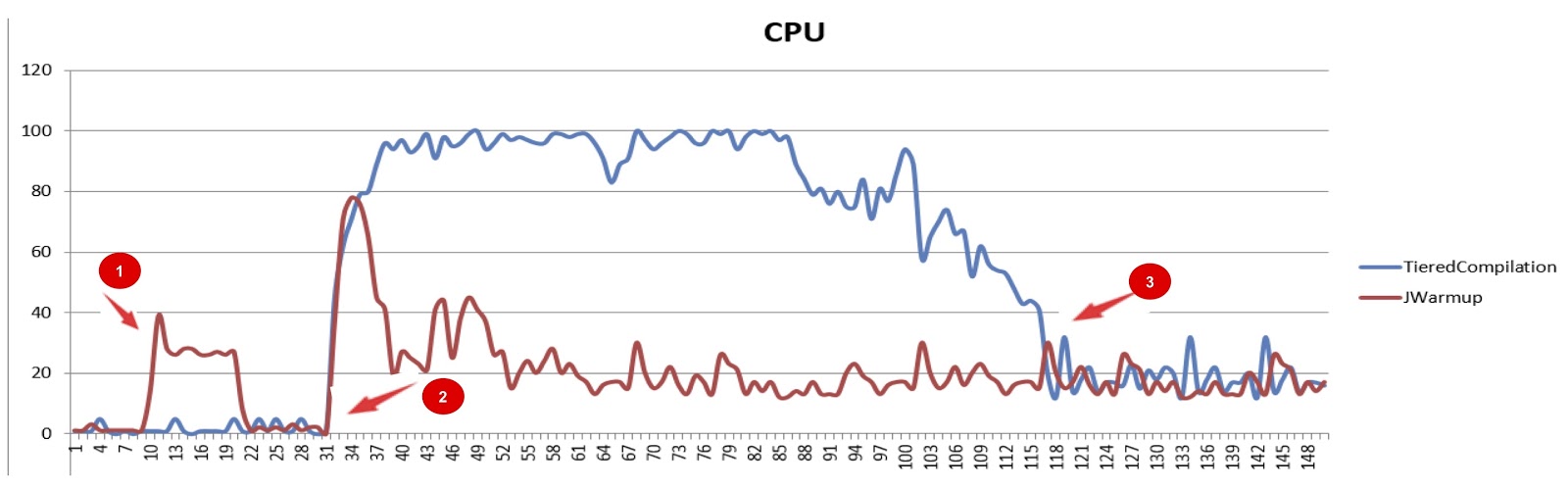
На картинке представлено сравнение производительности JWarmup и ступенчатой компиляции (tiered compilation), красный и синий графики соответственно. По оси х отложено время, по оси у — время CPU. На первом этапе у JWarmup происходит предварительная компиляция кода, поэтому он потребляет больше времени CPU, чем обычный JDK. Но затем, когда начинают поступать реальные запросы от пользователей, мы видим существенное улучшение в производительности по сравнению со стандартным JDK. Наконец, на последнем этапе при ступенчатой компиляции все наиболее часто используемые методы уже скомпилированы, и потребление ресурсов снова падает.
Необходимо сказать ещё несколько слов о JWarmup. Мы не можем записать класс, если он был сгенерирован динамически, скажем, некоторым groovy-скриптом, или при помощи Java-рефлексии, или прокси. Такие классы мы просто игнорируем. Кроме того, нам приходится отключать некоторые оптимизации, например «null check elimination». В противном случае у нас может происходить неожиданная деоптимизация. Наконец, наша текущая реализация JWarmup несовместима со ступенчатой компиляцией, так что если вы хотите пользоваться JWarmup, её необходимо отключить.
Средства диагностики
И напоследок поговорим о средствах диагностики, которые мы создали в Alibaba.
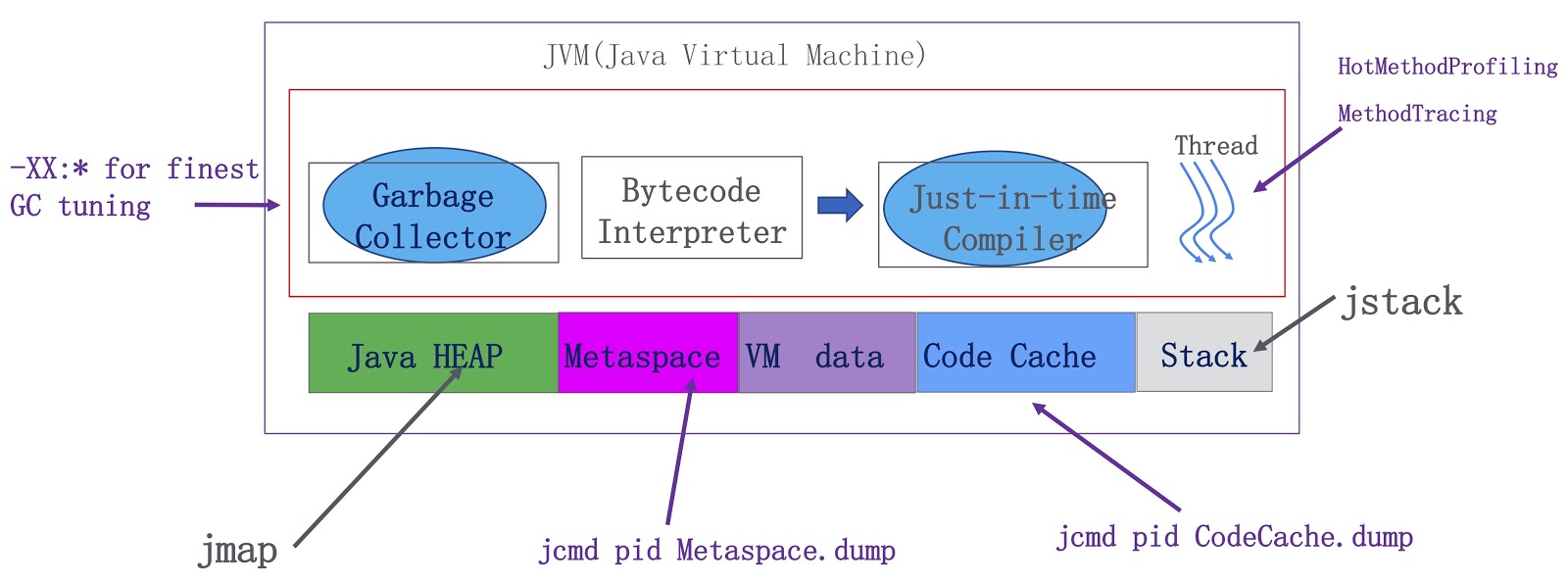
Схема описывает их функционирование. Здесь изображены компоненты JVM — сборщик мусора, интерпретатор байткода и компилятор, а также треды в рантайме. С точки зрения памяти мы имеем Java-кучу, metaspace, данные VM (предназначенные для внутреннего использования в VM) и кэш кода для JIT-компилятора. Мы добавили значительно больше возможностей профилирования для OpenJDK. Во-первых, сборщик мусора теперь работает на основе значительно более точной информации, что позволяет нам существенно улучшить его производительность. Во-вторых, мы реализовали два важных фичи для запуска тредов. Первая называется HotMethodProfiling, она позволяет определить, какие методы используют больше всего времени CPU. Кстати говоря, если вам необходимо профилировать ваши методы, я предлагаю воспользоваться Honest Profiler, это очень хороший опенсорсный инструмент, он работает по тому же принципу, что и наша фича HotMethodProfiling. Другая фича называется MethodTracing. Мы инструментируем метод на входе и на выходе на уровне компиляции, так что мы знаем, сколько времени занимает его выполнение. Помимо этого, мы добавили возможность создания дампа для metaspace и кэша кода. На основе дампа кэша кода мы можем сказать нашим Java-разработчикам, какой загрузчик классов потребляет больше памяти этого кэша. Благодаря дампу metaspace можно понять, фрагментировано оно или нет. Это очень полезно при разработке на Java.
Далее, мы также создали инструмент для диагностики, который назвали ZProfiler.
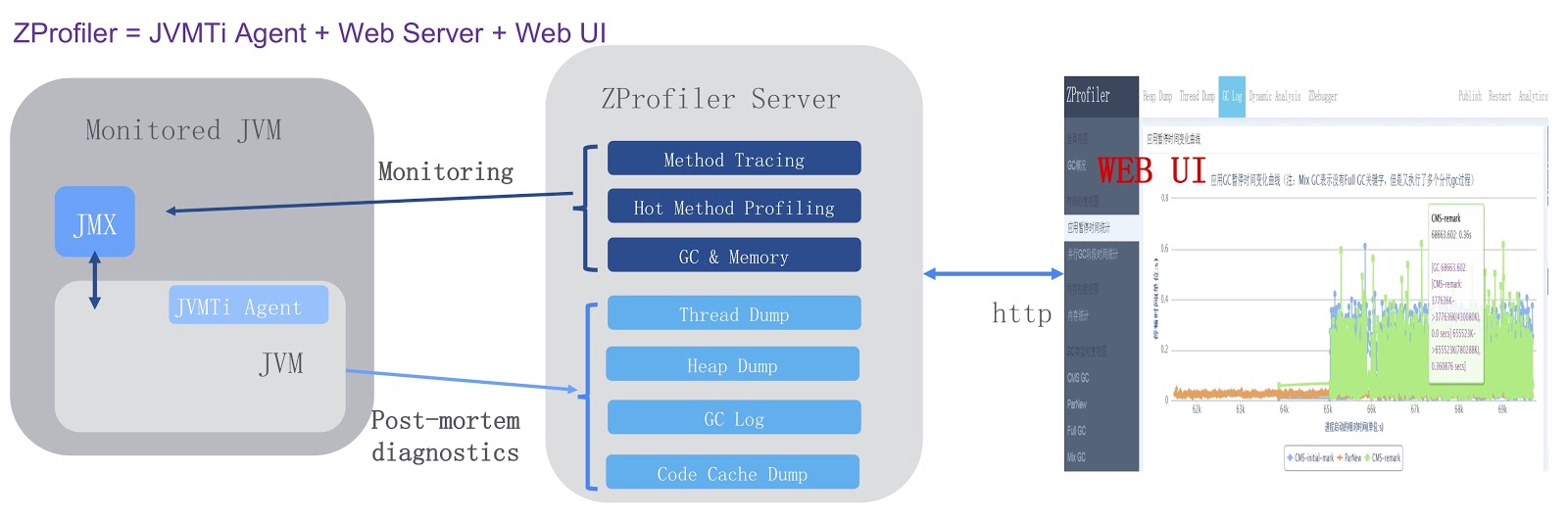
Схематично его работа изображена на картинке выше. Для него мы разработали агент JVMTi, который запускается внутри процесса JVM (на схеме слева). Кроме того, мы создали сервер ZProfiler на основе Apache Tomcat. Он напрямую развёрнут в нашем дата-центре. Это позволяет серверу ZProfiler напрямую обращаться к целевой JVM. Наконец, у ZProfiler есть веб-UI, которым могут пользоваться наши разработчики. ZProfiler предоставляет две основных функциональности. Во-первых, простым щелчком мыши на в UI можно получить очень точную информацию о целевой JVM. Во-вторых, ZProfiler предоставляет post-mortem диагностику. Например, если в нашей среде продакшна произошла ошибка OutOfMemoryError, одним щелчком мыши можно сгенерировать дамп кучи, и этот файл будет загружен с сервера целевой JVM на сервер ZProfiler, после чего результаты анализа будут доступны разработчикам. Это очень эффективное решение, которое позволяет обходиться без, скажем, Eclipse MAT.
Подведу итоги. Мы создали несколько решений для возникших перед нами проблем. Это мультитенантная JVM, GCIH, корутины для Alibaba JDK, а также JWarmup — средство, очень похожее на ReadyNow и коммерческую Zing JVM. Наконец, мы создали инструмент ZProfiler. В заключение я хотел бы сказать, что мы с радостью готовы предоставить сообществу те улучшения, которые мы создали на основе OpenJDK. По этому поводу уже идёт диалог, в частности, обсуждается возможность добавить JWarmup к OpenJDK. Кроме того, мы планируем участвовать в проекте OpenJDK под названием Loom, это реализация корутин для Java. На этом у меня всё, спасибо за внимание.
Минутка рекламы. Доклад, который вы только что прочитали, был сделан на конференции JPoint в 2018 году. На дворе уже 2019 год, и следующий JPoint состоится в Москве, 5-6 апреля. Программа всё ещё на стадии формирования, но уже можно увидеть таких известных товарищей как Rafael Winterhalter и Sebastian Daschner. Билеты можно приобрести на официальном сайте конференции. Чтобы оценить качество остальных докладов с прошлой конференции, можно посмотреть архив видеозаписей на YouTube. Встретимся на JPoint!
