Все мы совершаем ошибки: в данном случае речь идет о поисковых запросах. Количество сайтов для продажи товаров и услуг растет наряду с потребностями пользователей, однако не всегда они могут найти то, что ищут – только потому, что неправильно вводят название необходимого товара. Решение данной проблемы достигается путем реализации нечеткого поиска, то есть использования алгоритма поиска наиболее близких значений с учетом возможных ошибок или опечаток пользователя. Область применения такого поиска достаточно широка – нам же удалось поработать над поиском для крупного интернет-магазина в фудритейл-сегменте.
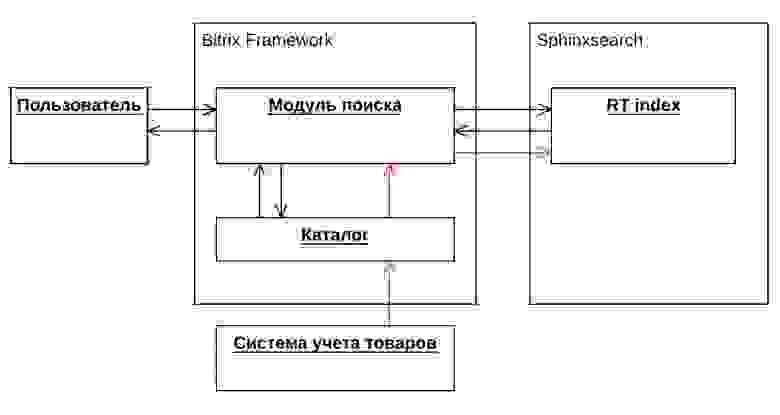
Интернет-магазин разрабатывался на платформе «1С-Битрикс: Управление сайтом». Для реализации поиска мы использовали стандартный модуль поиска системы bitrix и полнотекстовый движок sphinxsearch. В sphinxsearch был применен тип индекса Real Time (RT), который не требует статичного источника данных, а может быть наполнен в любой момент в реальном времени. Это позволяет гибко обновлять поисковой индекс без его полной переиндексации. Поскольку RT индекс в качестве протокола запросов использует только SphinxQL, интеграция осуществлялась именно через него. SphinxQL — mysql-подобный протокол запросов, который реализует возможность подключения через стандартных mysql-клиентов, при этом предоставляет sql-синтаксис с некоторыми ограничениями и своими особенностями. В модуле поиска используются запросы select/insert/replace/delete.
В системе bitrix производился процесс индексации данных товаров, категорий и брендов. Информация по данным сущностям передавалась в sphinx, который в свою очередь производил обновление RT индекса. При обновлении данных в интернет-магазине срабатывает событие, которое обновляет данные в Sphinx. Консистентность данных осуществляется через идентификатор сущности в интернет-магазине.
Когда пользователь производит поиск в интернет-магазине, система производит запрос с поисковой фразой в Sphinx и получает идентификаторы сущностей, также производит выборку из базы информации по ним и формирует страницу с результатами поисковой выдачи.
На момент начала решения проблемы нечеткого поиска общая схема архитектуры поиска на проекте выглядела следующим образом:
Перед нами стояла задача: угадать запрос пользователя, который, возможно, содержит опечатки. Для этого нам необходимо проанализировать каждое слово в запросе и решить, правильно ли его написал пользователь или нет. В случае ошибки следовало подобрать наиболее подходящие варианты. Определение правильности написания слов невозможно без базы слов и словоформ того языка, на котором мы хотим их угадывать. Упрощенно такую базу можно назвать словарем — именно он нам был необходим.
Для подбора вариантов замен для слов, введенных с ошибкой, была выбрана популярная формула расчета расстояния Дамерау–Левенштейна. Данная формула представляет собой алгоритм сравнения двух слов. Результатом сравнения является количество операций для преобразования одного слова в другое. Первоначально расстояние Левенштейна предполагает использование 3-х операций:
Расстояние Дамерау-Левенштейна является при этом расширенной версией расстояния Левенштейна и добавляет еще одну операцию: транспозицию, то есть перестановку двух соседних символов.
Таким образом, количество полученных операций становится количеством ошибок, допущенных пользователем при написании слова. Мы выбрали ограничение в две ошибки, поскольку большее количество не имело смысла: в этом случае мы получаем слишком много вариантов для замены, что повышает вероятность промаха.
Для более релевантного поиска вариантов слов, похожих по звучанию, использована функция metaphone — данная функция преобразует слово в его фонетическую форму. К сожалению, metaphone работает только с буквами английского алфавита, поэтому перед вычислением фонетической формы мы производим транслитерацию слова. Значение фонетической формы хранится в словаре, а также вычисляется в запросе пользователя. Полученные в итоге значения сравниваются функцией расстояния Дамерау-Левенштейна.
Словарь хранится в базе данных MySQL. Чтобы не загружать словарь в память приложения, было решено производить расчет расстояния Дамерау-Левенштейна на стороне базы. Пользовательская функция для вычисления расстояния Дамерау-Левенштейна, написанная на основе функции на Си, написанной Линусом Торвальдсом, вполне удовлетворяла нашим требованиям. Автор функции Diego Torres.
После расчета расстояния Дамерау-Левенштейна нужно было отсортировать результаты по степени сходства для выбора наиболее подходящего. Для этого мы использовали алгоритм Оливера: вычисление схожести двух строк. В php данный алгоритм представлен функцией similar_text. Первые два параметра функции принимают на вход строки, которые необходимо сравнить.Порядок сравнения строк важен, так как функция выдает разные значения в зависимости от того, в каком порядке строки переданы в функцию. Третьим параметром должна быть передана переменная, в которую помещается результат сравнения. Это будет число от 0 до 100, что означает процентное соотношение похожести двух строк. После вычисления результаты сортируются по убыванию процента схожести, далее выбираются варианты с лучшими значениями.
Так как вычисление расстояние Дамерау-Левенштейна производилось по транскрипции слова, в результаты попадали слова с не совсем релевантными значениями. В связи с этим мы ограничили выборку вариантов с процентом совпадения больше 70%.
В процессе разработки мы заметили, что наш алгоритм может угадывать слова на разных раскладках. Поэтому нам было необходимо расширить словарь, добавив в него значения слов на обратной раскладке. В требованиях к поиску фигурировали только две раскладки: русская и английская. Каждое слово поискового запроса пользователя мы дублировали на обратной раскладке и добавляли обработку расчета расстояния Дамерау-Левенштейна. Варианты для прямой и обратной раскладки обрабатываются независимо друг от друга, выбираются варианты с наибольшим процентом схожести. Только для вариантов с обратной раскладкой значением для исправленного поискового запроса будет слово в прямой раскладке.
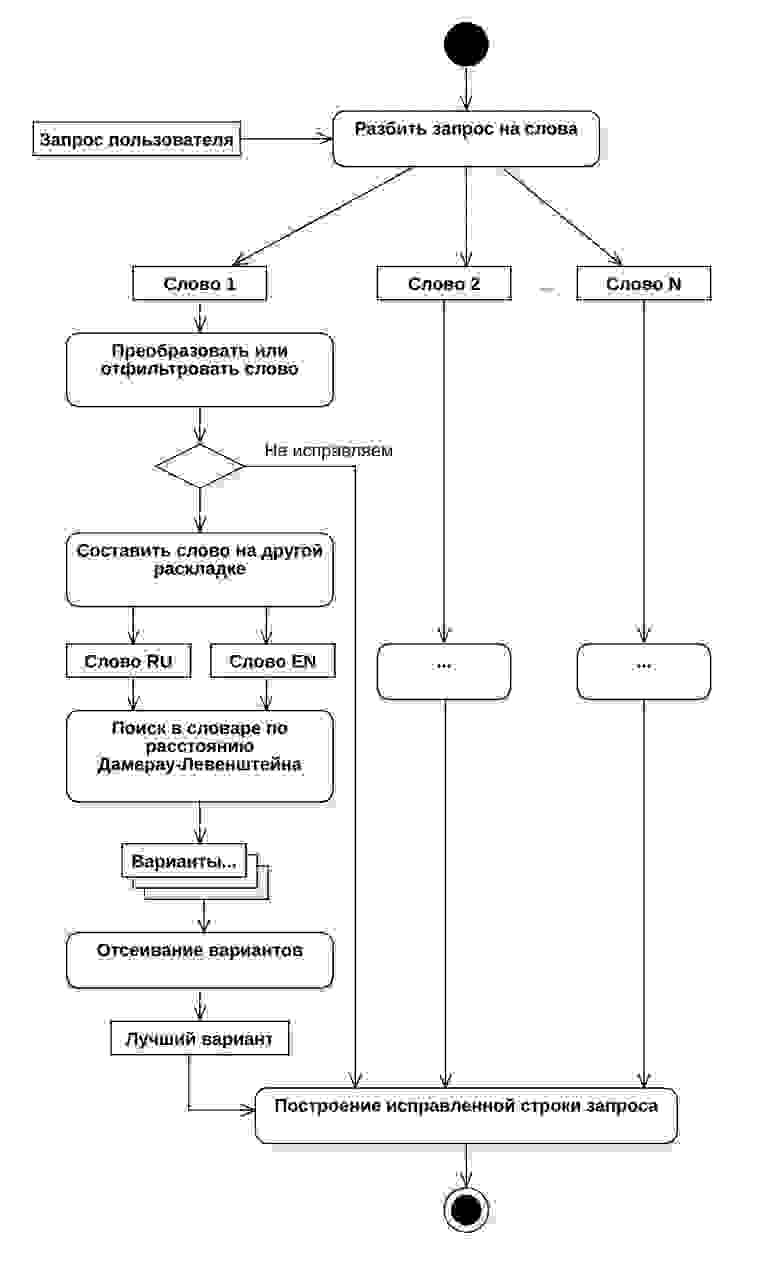
Таким образом сформировался алгоритм действий из 6 основных шагов. В процессе тестирования мы выяснили, что не все слова в запросах пользователей нужно обрабатывать в исходном виде или обрабатывать вообще. Для решения подобных случаев был введен дополнительный шаг, который мы назвали преобразователем или же фильтром. В результате, конечный алгоритм состоял из 7 шагов:
Схематически данный алгоритм выглядит следующим образом:
Когда мы начали тестировать первый прототип без преобразователя, стало очевидно, что нет необходимости пытаться угадывать все слова в запросе пользователя. Для данных ограничений был создан преобразователь. Он позволяет преобразовывать слова в нужный нам вид и отсеивать те, которые, как мы считаем, пытаться угадывать не нужно.
Изначально было решено, что минимальная длина слова, которое следует пропускать через алгоритм, должна быть не менее двух символов. Ведь если пользователь ввел предлог или союз из одного символа, то вероятность угадать практически минимальна. Вторым шагом стало разбиение запроса на слова. В первую очередь мы выбрали набор символов, которые могут содержать слова: буквы, цифры, точка и дефис (тире). Пробелы и остальные символы являются разделителями слов.
Очень часто пользователи вводят числа для указания объема или количества. В этом случае будет некорректно исправлять подобный запрос. Например, пользователь ввел запрос “вода 1,1 литров”. Если мы исправим его запрос на 1,5 или 1,0 — это будет неправильно. В таких случаях мы решили пропускать слова с цифрой. Они, минуя наш алгоритм, передаются в полнотекстовый поиск Sphinx.
Еще одно преобразование связано с точками в названиях брендов — например: Dr.Pepper или Mr.Proper. В случаях, если в середине слова находится символ точки, то мы разбиваем его на два, добавляя пробел. Второй кейс с точкой в середине слова — здесь мы вспоминаем бренды-аббревиатуры. Например, бренд R.O.C.S. — в этом случае мы вырезаем точки и получаем единое слово. Данное преобразование работает, если между точками стоит только одна буква.
В случаях присутствия в слове дефис (тире), следует разбить слово на несколько и попробовать угадать их по отдельности, а затем склеить вместе наилучшие варианты.
В итоге для наиболее точного распознавания запроса был разработан преобразователь — большую часть работы по настройке всего функционала заняла именно эта разработка. Во многом благодаря ему производится корректировка и настройка всего нечеткого поиска. Кратко повторим правила, по которым производится отсеивание и преобразование слов:
Как было упомянуто ранее, чтобы исправить запрос пользователя, необходимо определять, какие слова написаны с ошибкой, а какие нет. Для этого в системе был создан словарь, где должны содержаться слова с правильным написанием.
На первом этапе встал вопрос о наполнении словаря — в результате для его составления мы решили использовать контент каталога. Так как информация по товарам время от времени импортировалась из внешней системы и индексировалась для системы полнотекстового поиска Sphinx, было решено добавить функционал составления словаря на этом этапе. Мы следовали следующей логике: если слова нет в контенте товаров, то к чему пытаться его угадать?
Информация о товаре объединялась в общий текст и проводилась через преобразователь. Режим работы преобразователя был немного модифицирован: при разбиении слов через дефис (тире) в словарь сохранялась каждая из частей отдельно, при замене точек в словарь добавляются исходные и измененные данные. И поскольку при сравнении слов для вычисления расстояния Дамерау-Левенштейна используется транскрипция слова, дополнительно в словарь добавляется транскрипция.
В контенте товаров было много опечаток, для этого в словаре заложен флаг, при установке которого слово больше не используется в поиске. Контент из 35 тыс. товаров позволил создать словарь из 100 тыс. уникальных слов, которого в итоге оказалось недостаточно для некоторых запросов пользователя. В связи с этим пришлось предусмотреть функционал загрузки для его обогащения. Была создана консольная команда, позволяющая загружать словари. Формат файлов с данными словарей должен соответствовать csv. Каждая запись содержит только одно поле с самим полем словаря. Для того, чтобы загруженные данные можно было отличить от данных, сгенерированных на основе контента товаров, был добавлен специальный флаг.
В итоге таблица словаря имеет следующую схему:
До разработки функционала нечеткого поиска в товарах присутствовали поля, которые содержали набор слов с опечатками. При первом прогоне генерации словаря они попали в его контент. В итоге был получен словарь с опечатками, контент которого не подходил для корректной работы функционала. Поэтому была добавлена еще одна консольная команда, которая имела обратную функциональность генерации словаря. Используя контент заданного поля товаров, команда производила поиск слов в словаре и очищала их из словаря. После очистки подобные поля исключались из индексации.
Для реализации минимального необходимого функционала было создано три класса:
Для интеграции в Битрикс потребовалось внести изменения в 2 компонента:
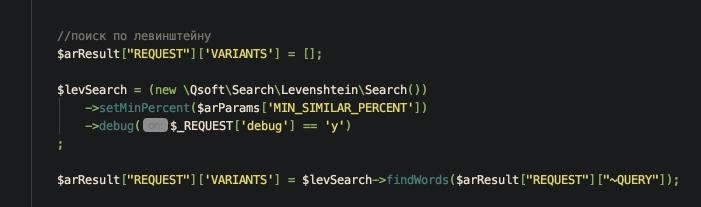
Перед выполнением запроса вызывается метод обработки для выявления ошибок и подбора подходящих вариантов:
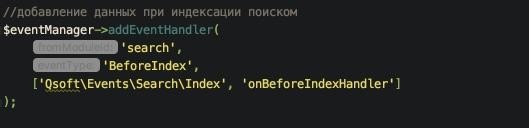
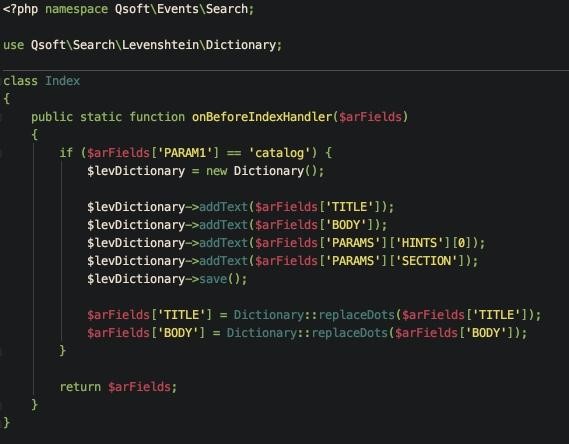
Для составления словаря было зарегистрировано событие на индексацию поисковым модулем элементов инфоблока с товарами (search:BeforeIndex).
Данный подход не идеален с точки зрения производительности. При увеличении размера словаря до 1М+ слов время ответа базы может увеличится в разы. Пока словарь небольшой, производительность нас устраивает. Возможно, в дальнейшем придется реализовать алгоритм через автомат Левенштейна или префиксное дерево.
Итак, ни одна поисковая система не избавлена от появления запросов, нарушающих общепринятые правила орфографии — будь то случайная опечатка или реальное незнание написания слов. Поэтому даже не прибегая к классическим вариантам нечеткого поиска Google или Яндекс можно создать свой собственный, благодаря которому и пользователь, и владелец сайта смогут получить желаемый результат.
Код нашей реализации можно посмотреть в репозитории: github.com/qsoft-dev/damlev-bitrix
Исходное состояние поиска
Интернет-магазин разрабатывался на платформе «1С-Битрикс: Управление сайтом». Для реализации поиска мы использовали стандартный модуль поиска системы bitrix и полнотекстовый движок sphinxsearch. В sphinxsearch был применен тип индекса Real Time (RT), который не требует статичного источника данных, а может быть наполнен в любой момент в реальном времени. Это позволяет гибко обновлять поисковой индекс без его полной переиндексации. Поскольку RT индекс в качестве протокола запросов использует только SphinxQL, интеграция осуществлялась именно через него. SphinxQL — mysql-подобный протокол запросов, который реализует возможность подключения через стандартных mysql-клиентов, при этом предоставляет sql-синтаксис с некоторыми ограничениями и своими особенностями. В модуле поиска используются запросы select/insert/replace/delete.
В системе bitrix производился процесс индексации данных товаров, категорий и брендов. Информация по данным сущностям передавалась в sphinx, который в свою очередь производил обновление RT индекса. При обновлении данных в интернет-магазине срабатывает событие, которое обновляет данные в Sphinx. Консистентность данных осуществляется через идентификатор сущности в интернет-магазине.
Когда пользователь производит поиск в интернет-магазине, система производит запрос с поисковой фразой в Sphinx и получает идентификаторы сущностей, также производит выборку из базы информации по ним и формирует страницу с результатами поисковой выдачи.
На момент начала решения проблемы нечеткого поиска общая схема архитектуры поиска на проекте выглядела следующим образом:

Выбор технологий
Перед нами стояла задача: угадать запрос пользователя, который, возможно, содержит опечатки. Для этого нам необходимо проанализировать каждое слово в запросе и решить, правильно ли его написал пользователь или нет. В случае ошибки следовало подобрать наиболее подходящие варианты. Определение правильности написания слов невозможно без базы слов и словоформ того языка, на котором мы хотим их угадывать. Упрощенно такую базу можно назвать словарем — именно он нам был необходим.
Для подбора вариантов замен для слов, введенных с ошибкой, была выбрана популярная формула расчета расстояния Дамерау–Левенштейна. Данная формула представляет собой алгоритм сравнения двух слов. Результатом сравнения является количество операций для преобразования одного слова в другое. Первоначально расстояние Левенштейна предполагает использование 3-х операций:
- вставка
- удаление
- замена
Расстояние Дамерау-Левенштейна является при этом расширенной версией расстояния Левенштейна и добавляет еще одну операцию: транспозицию, то есть перестановку двух соседних символов.
Таким образом, количество полученных операций становится количеством ошибок, допущенных пользователем при написании слова. Мы выбрали ограничение в две ошибки, поскольку большее количество не имело смысла: в этом случае мы получаем слишком много вариантов для замены, что повышает вероятность промаха.
Для более релевантного поиска вариантов слов, похожих по звучанию, использована функция metaphone — данная функция преобразует слово в его фонетическую форму. К сожалению, metaphone работает только с буквами английского алфавита, поэтому перед вычислением фонетической формы мы производим транслитерацию слова. Значение фонетической формы хранится в словаре, а также вычисляется в запросе пользователя. Полученные в итоге значения сравниваются функцией расстояния Дамерау-Левенштейна.
Словарь хранится в базе данных MySQL. Чтобы не загружать словарь в память приложения, было решено производить расчет расстояния Дамерау-Левенштейна на стороне базы. Пользовательская функция для вычисления расстояния Дамерау-Левенштейна, написанная на основе функции на Си, написанной Линусом Торвальдсом, вполне удовлетворяла нашим требованиям. Автор функции Diego Torres.
После расчета расстояния Дамерау-Левенштейна нужно было отсортировать результаты по степени сходства для выбора наиболее подходящего. Для этого мы использовали алгоритм Оливера: вычисление схожести двух строк. В php данный алгоритм представлен функцией similar_text. Первые два параметра функции принимают на вход строки, которые необходимо сравнить.Порядок сравнения строк важен, так как функция выдает разные значения в зависимости от того, в каком порядке строки переданы в функцию. Третьим параметром должна быть передана переменная, в которую помещается результат сравнения. Это будет число от 0 до 100, что означает процентное соотношение похожести двух строк. После вычисления результаты сортируются по убыванию процента схожести, далее выбираются варианты с лучшими значениями.
Так как вычисление расстояние Дамерау-Левенштейна производилось по транскрипции слова, в результаты попадали слова с не совсем релевантными значениями. В связи с этим мы ограничили выборку вариантов с процентом совпадения больше 70%.
В процессе разработки мы заметили, что наш алгоритм может угадывать слова на разных раскладках. Поэтому нам было необходимо расширить словарь, добавив в него значения слов на обратной раскладке. В требованиях к поиску фигурировали только две раскладки: русская и английская. Каждое слово поискового запроса пользователя мы дублировали на обратной раскладке и добавляли обработку расчета расстояния Дамерау-Левенштейна. Варианты для прямой и обратной раскладки обрабатываются независимо друг от друга, выбираются варианты с наибольшим процентом схожести. Только для вариантов с обратной раскладкой значением для исправленного поискового запроса будет слово в прямой раскладке.
Алгоритм нечеткого поиска
Таким образом сформировался алгоритм действий из 6 основных шагов. В процессе тестирования мы выяснили, что не все слова в запросах пользователей нужно обрабатывать в исходном виде или обрабатывать вообще. Для решения подобных случаев был введен дополнительный шаг, который мы назвали преобразователем или же фильтром. В результате, конечный алгоритм состоял из 7 шагов:
- Разбить запрос на отдельные слова;
- Пропустить каждое слово через преобразователь (о нем далее);
- Для каждого слова составить его форму на другой раскладке;
- Составить транскрипцию;
- Произвести запрос поиска в таблице словаря, сравнивая каждую запись через расстояние Дамерау-Левенштейна;
- Оставить только записи с расстоянием, меньшим или равным двум;
- Через алгоритм Оливера оставить только слова с процентом схожести больше 70%
Схематически данный алгоритм выглядит следующим образом:

Функционал преобразования и фильтрации слов
Когда мы начали тестировать первый прототип без преобразователя, стало очевидно, что нет необходимости пытаться угадывать все слова в запросе пользователя. Для данных ограничений был создан преобразователь. Он позволяет преобразовывать слова в нужный нам вид и отсеивать те, которые, как мы считаем, пытаться угадывать не нужно.
Изначально было решено, что минимальная длина слова, которое следует пропускать через алгоритм, должна быть не менее двух символов. Ведь если пользователь ввел предлог или союз из одного символа, то вероятность угадать практически минимальна. Вторым шагом стало разбиение запроса на слова. В первую очередь мы выбрали набор символов, которые могут содержать слова: буквы, цифры, точка и дефис (тире). Пробелы и остальные символы являются разделителями слов.
Очень часто пользователи вводят числа для указания объема или количества. В этом случае будет некорректно исправлять подобный запрос. Например, пользователь ввел запрос “вода 1,1 литров”. Если мы исправим его запрос на 1,5 или 1,0 — это будет неправильно. В таких случаях мы решили пропускать слова с цифрой. Они, минуя наш алгоритм, передаются в полнотекстовый поиск Sphinx.
Еще одно преобразование связано с точками в названиях брендов — например: Dr.Pepper или Mr.Proper. В случаях, если в середине слова находится символ точки, то мы разбиваем его на два, добавляя пробел. Второй кейс с точкой в середине слова — здесь мы вспоминаем бренды-аббревиатуры. Например, бренд R.O.C.S. — в этом случае мы вырезаем точки и получаем единое слово. Данное преобразование работает, если между точками стоит только одна буква.
В случаях присутствия в слове дефис (тире), следует разбить слово на несколько и попробовать угадать их по отдельности, а затем склеить вместе наилучшие варианты.
В итоге для наиболее точного распознавания запроса был разработан преобразователь — большую часть работы по настройке всего функционала заняла именно эта разработка. Во многом благодаря ему производится корректировка и настройка всего нечеткого поиска. Кратко повторим правила, по которым производится отсеивание и преобразование слов:
- слово должно быть длиннее 2-х символов
- в слове должны содержаться только буквы, символ точки и символ дефис (тире)
- если точка находится в середине слова, после нее добавляется пробел
- если это аббревиатура — точки вырезаются, а буквы склеиваются
- не пытаться угадать слово, если в нем присутствует цифра
- если в слове содержится дефис (тире), то разбить его на несколько, производить поиск по отдельности и в конце склеить
Составление словаря
Как было упомянуто ранее, чтобы исправить запрос пользователя, необходимо определять, какие слова написаны с ошибкой, а какие нет. Для этого в системе был создан словарь, где должны содержаться слова с правильным написанием.
На первом этапе встал вопрос о наполнении словаря — в результате для его составления мы решили использовать контент каталога. Так как информация по товарам время от времени импортировалась из внешней системы и индексировалась для системы полнотекстового поиска Sphinx, было решено добавить функционал составления словаря на этом этапе. Мы следовали следующей логике: если слова нет в контенте товаров, то к чему пытаться его угадать?
Информация о товаре объединялась в общий текст и проводилась через преобразователь. Режим работы преобразователя был немного модифицирован: при разбиении слов через дефис (тире) в словарь сохранялась каждая из частей отдельно, при замене точек в словарь добавляются исходные и измененные данные. И поскольку при сравнении слов для вычисления расстояния Дамерау-Левенштейна используется транскрипция слова, дополнительно в словарь добавляется транскрипция.
В контенте товаров было много опечаток, для этого в словаре заложен флаг, при установке которого слово больше не используется в поиске. Контент из 35 тыс. товаров позволил создать словарь из 100 тыс. уникальных слов, которого в итоге оказалось недостаточно для некоторых запросов пользователя. В связи с этим пришлось предусмотреть функционал загрузки для его обогащения. Была создана консольная команда, позволяющая загружать словари. Формат файлов с данными словарей должен соответствовать csv. Каждая запись содержит только одно поле с самим полем словаря. Для того, чтобы загруженные данные можно было отличить от данных, сгенерированных на основе контента товаров, был добавлен специальный флаг.
В итоге таблица словаря имеет следующую схему:
| Название поля | Тип поля |
|---|---|
| Слово | string |
| Транскрипция | string |
| Добавлено вручную | bool |
| Не использовать | bool |
До разработки функционала нечеткого поиска в товарах присутствовали поля, которые содержали набор слов с опечатками. При первом прогоне генерации словаря они попали в его контент. В итоге был получен словарь с опечатками, контент которого не подходил для корректной работы функционала. Поэтому была добавлена еще одна консольная команда, которая имела обратную функциональность генерации словаря. Используя контент заданного поля товаров, команда производила поиск слов в словаре и очищала их из словаря. После очистки подобные поля исключались из индексации.
Интеграция в Bitrix
Для реализации минимального необходимого функционала было создано три класса:
- DictionaryTable — ORM системы Битрикс для работы со словарем
- Dictionary — класс формирования словаря
- Search — класс реализации поиска
Для интеграции в Битрикс потребовалось внести изменения в 2 компонента:
- bitrix:search.page
- bitrix.search.title
Перед выполнением запроса вызывается метод обработки для выявления ошибок и подбора подходящих вариантов:
Для составления словаря было зарегистрировано событие на индексацию поисковым модулем элементов инфоблока с товарами (search:BeforeIndex).


Планы на будущее
Данный подход не идеален с точки зрения производительности. При увеличении размера словаря до 1М+ слов время ответа базы может увеличится в разы. Пока словарь небольшой, производительность нас устраивает. Возможно, в дальнейшем придется реализовать алгоритм через автомат Левенштейна или префиксное дерево.
Заключение
Итак, ни одна поисковая система не избавлена от появления запросов, нарушающих общепринятые правила орфографии — будь то случайная опечатка или реальное незнание написания слов. Поэтому даже не прибегая к классическим вариантам нечеткого поиска Google или Яндекс можно создать свой собственный, благодаря которому и пользователь, и владелец сайта смогут получить желаемый результат.
Код нашей реализации можно посмотреть в репозитории: github.com/qsoft-dev/damlev-bitrix
