
Привет, Хабр! Два года назад мы писали о том, как перешли на PHP 7.0 и сэкономили миллион долларов. На нашем профиле нагрузки новая версия оказалась в два раза более эффективной по использованию CPU: ту нагрузку, которую раньше у нас обслуживали ~600 серверов, после перехода начали обслуживать ~300. В результате на протяжении двух лет у нас был запас мощностей.
Но Badoo растёт. Количество активных пользователей постоянно увеличивается. Мы совершенствуемся и развиваем нашу функциональность, благодаря чему пользователи проводят в приложении всё больше времени. А это, в свою очередь, отражается на количестве запросов, которое за два года увеличилось в 2—2,5 раза.
Мы оказались в ситуации, когда двукратный выигрыш в производительности нивелировался более чем двукратным ростом запросов, и мы опять стали приближаться к пределам нашего кластера. В ядре PHP снова ожидаются полезные оптимизации (JIT, предзагрузка), но они запланированы только на PHP 7.4, а эта версия выйдет не раньше, чем через год. Поэтому трюк с переходом сейчас повторить не удастся — нужно оптимизировать сам код приложения.
Под катом я расскажу, как мы подходим к таким задачам, какими пользуемся инструментами, и приведу примеры оптимизаций, идей и подходов, которые мы применяем и которые помогли нам в своё время.
Зачем оптимизировать
Самый простой и очевидный способ решить проблему производительности — добавить железа. Если ваш код выполняется на одном сервере, то добавление ещё одного удвоит производительность вашего кластера. Переводя эти затраты на рабочее время разработчика, мы задаёмся вопросом: сможет ли он за это время получить двукратный рост производительности за счёт оптимизаций? Возможно, да, а, возможно, нет: зависит от того, насколько оптимально уже работает система и насколько хорош разработчик. С другой стороны, купленный сервер останется в собственности компании, а потраченное время уже не вернёшь.
Получается, что на небольших объёмах правильным решением чаще будет добавление железа.
Но возьмём нашу ситуацию. Сейчас, после того как выигрыш от перехода на PHP 7.0 был нивелирован ростом активности и количества пользователей, у нас снова 600 серверов обслуживают запросы к PHP-приложению. Для того чтобы увеличить мощность в полтора раза, нам нужно добавить 300 серверов.
Возьмём для расчёта среднюю стоимость сервера — 4000 долларов. 300 * 4000 = 1 200 000 долларов — стоимость увеличения мощности в полтора раза.
То есть в наших условиях мы можем вложить значительное количество рабочего времени в оптимизацию системы, и это всё равно будет более выгодно, чем покупка железа.
Capacity planning
Прежде чем что-то предпринимать, важно понять, есть ли проблема. Если её нет, то стоит попытаться предсказать, когда она может появиться. Этот процесс называют capacity planning.
Железобетонным показателем наличия проблем с производительностью является время ответа. Ведь, по сути, не имеет значения, загружен CPU (или другие ресурсы) на 6% или 146%: если клиент получает сервис необходимого качества за удовлетворительное время, значит, всё работает хорошо.
Недостаток ориентации на время ответа заключается в том, что обычно оно начинает увеличиваться, только когда проблема уже появилась. Если же её ещё нет, то предсказать её появление сложно. Кроме того, время ответа отражает результаты влияния всех факторов (тормозящие сервисы, сеть, диски и т. д.) и не даёт понимания причин проблем.
В нашем случае узким местом обычно является CPU, поэтому при планировании размера и производительности кластеров мы в первую очередь обращаем внимание на метрики, связанные с его использованием. Мы собираем CPU usage со всех наших машин и строим графики со средним значением, медианой, 75-м и 95-м перцентилем:
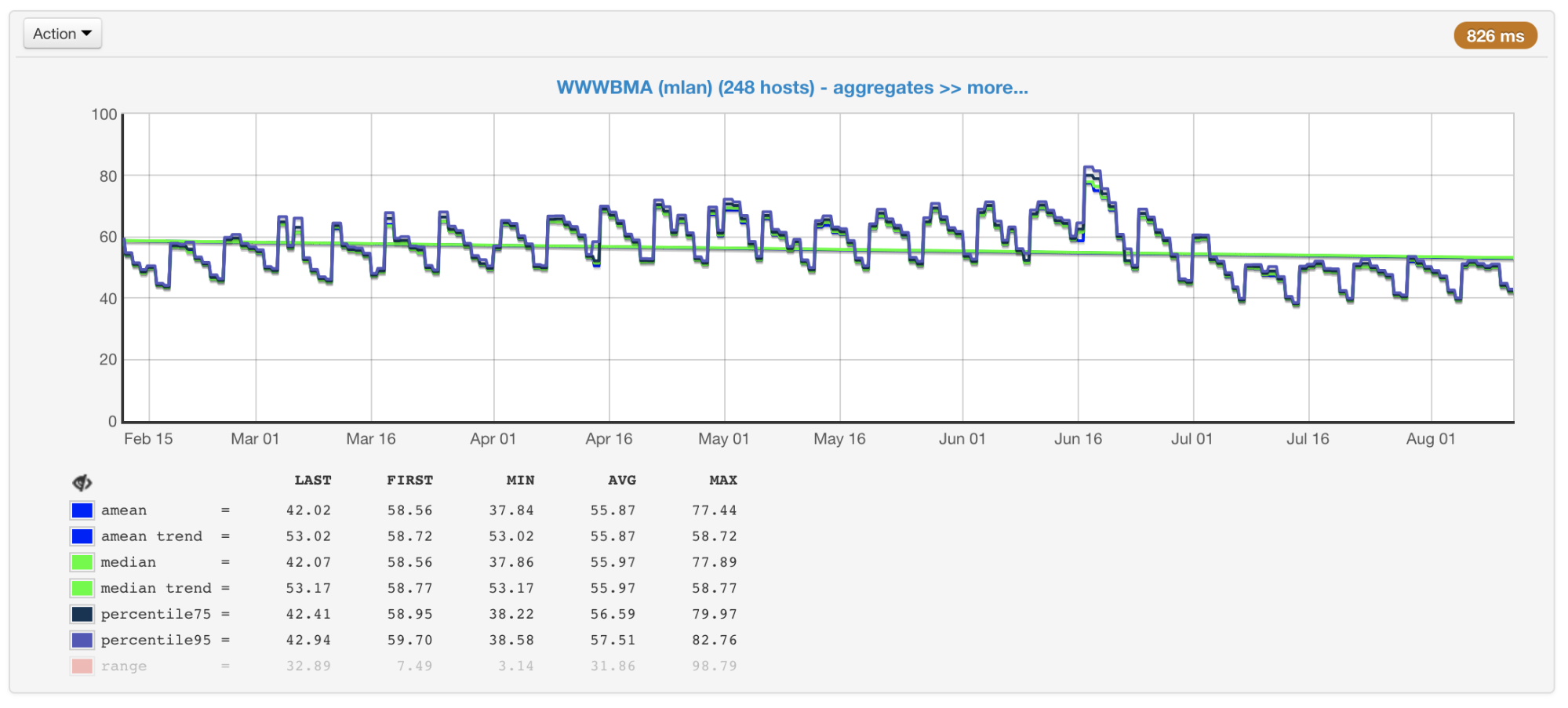
Загрузка CPU машин кластера в процентах: среднее значение, медиана, перцентили
В наших кластерах сотни машин, которые туда добавлялись в течение многих лет. Они разные по конфигурации и производительности (кластер не гомогенный). Наш балансировщик учитывает это (статья и видео) и нагружает машины в соответствии с их возможностями. Для того чтобы контролировать этот процесс, у нас также есть график максимально и минимально загруженных машин.

Наиболее и наименее загруженные машины кластера
Если посмотреть на эти графики (или просто на вывод команды top) и увидеть загрузку CPU 50%, то можно подумать, что у нас ещё есть запас на двукратный рост нагрузки. Но на самом деле обычно это не так. И вот почему.
Hyper-threading
Представим одно ядро без гипертрединга. Нагрузим его одним CPU-bound-потоком. Увидим в топе загрузку на 100%.
Теперь включим на этом ядре гипертрединг и нагрузим его точно так же. В топе мы увидим уже два логических ядра, а общая загрузка будет 50% (обычно на одном 0%, а на другом — 100%).
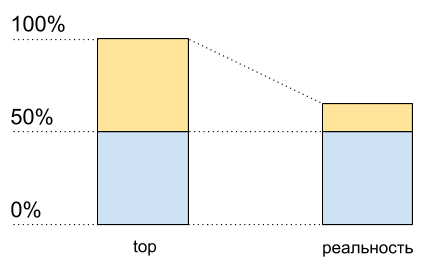
Утилизация CPU: данные top и то, что происходит на самом деле
Как будто процессор загружен только на 50%. Но физически дополнительного свободного ядра не появилось. Гипертрединг позволяет в некоторых случаях выполнять на одном физическом ядре больше одного процесса одновременно. Но это далеко не удвоение производительности в типичных ситуациях, хотя на графике CPU usage это и выглядит как ещё половина ресурсов: от 50% до 100%.
Это значит, что после 50% CPU usage при включённом гипертрединге будет расти не так же, как он рос до этого.
Я написал вот такой код для демонстрации (это некий синтетический случай, в реальности результаты будут отличаться):
Код скрипта
<?php
$concurrency = $_SERVER['argv'][1] ?? 1;
$hashes = 100000000;
$chunkSize = intval($hashes / $concurrency);
$t1 = microtime(true);
$children = array();
for ($i = 0; $i < $concurrency; $i++) {
$pid = pcntl_fork();
if (0 === $pid) {
$first = $i * $chunkSize;
$last = ($i + 1) * $chunkSize - 1;
for ($j = $first; $j < $last; $j++) {
$dummy = md5($j);
}
printf("[%d]: %d hashes in %0.4f sec\n", $i, $last - $first, microtime(true) - $t1);
exit;
} else {
$children[$pid] = 1;
}
}
while (count($children) > 0) {
$pid = pcntl_waitpid(-1, $status);
if ($pid > 0) {
unset($children[$pid]);
} else {
exit("Got a error pid=$pid");
}
}У меня на ноутбуке два физических ядра. Запустим этот код с разными входными данными, чтобы измерить производительность его работы с разным количеством параллельных процессов C.
Результаты измерений

Построим график по результатам запусков:
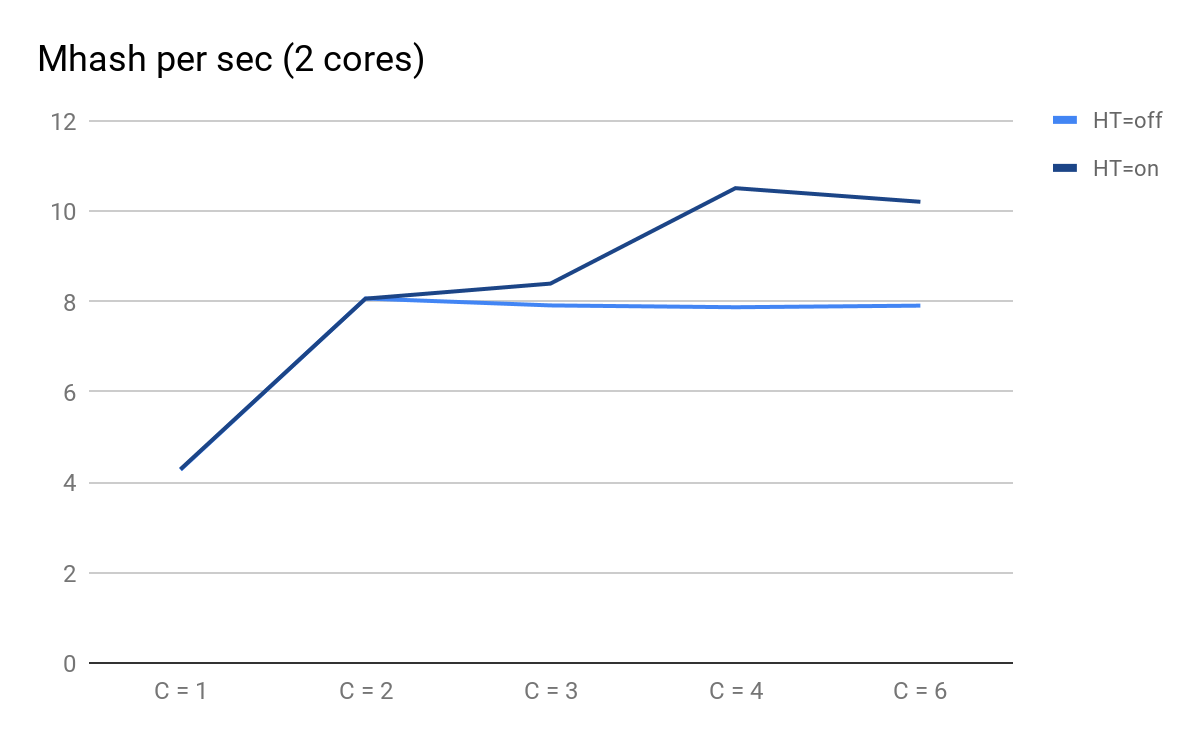
Производительность скрипта в зависимости от количество параллельных процессов
На что можно обратить внимание:
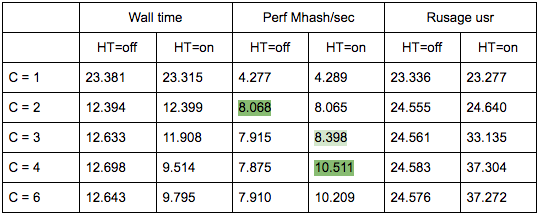
- C = 1 и C = 2 предсказуемо одинаковы для HT=on и HT=off, производительность увеличивается в два раза при добавлении физического ядра;
- на С = 3 становятся заметны преимущества от HT: для HT=on мы смогли получить дополнительную производительность, притом что для HT=off с C=3 и дальше она начинает предсказуемо медленно уменьшаться;
- на С = 4 мы видим все преимущества от HT; мы смогли выжать дополнительно ещё 30% производительности, но в сравнении с С=2 в это время CPU usage у нас увеличился с 50% до 100%.
Итого, видя в топе 50% загрузки CPU, при выполнении этого скрипта мы получаем 8,065 Mhash/sec, а при 100% — 10,511 Mhash/sec. Это значит, что на отметке 50% топа мы получаем 8,065/10,511 ~ 77% максимальной производительности системы и на самом деле в запасе у нас остаётся около 100% — 77% = 23%, а не 50%, как это могло показаться.
Этот факт необходимо учитывать при планировании.
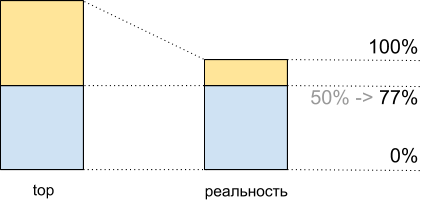
Утилизация CPU для демоскрипта: данные top и то, что происходит на самом деле
Неравномерность трафика
Помимо гипертрединга, планирование усложняет ещё и неравномерность трафика в зависимости от времени суток, дня недели, сезона и другой периодичности. Для нас, например, пиковым является вечер воскресенья.

Количество запросов в секунду, пик вечером воскресенья
Не всегда количество запросов меняется очевидным образом. Например, пользователи могут как-то взаимодействовать с другими пользователями: активность одних может генерировать пуши/email’ы другим и таким образом вовлекать их в процесс. К этому добавляются промокампании, которые увеличивают трафик и к которым тоже надо быть готовыми.
Всё это также важно учитывать при планировании: например, строить тренд по пиковым дням и держать в голове возможную нелинейность роста пиков.
Профилирование и инструменты измерения
Предположим, мы выяснили, что существуют проблемы с производительностью, поняли, что виной тому не базы данных/сервисы/прочее, и всё-таки решили оптимизировать код. Для этого в первую очередь нам нужен профайлер или какие-то инструменты, позволяющие находить узкие места и впоследствии видеть результаты наших оптимизаций.
К сожалению, для PHP на сегодняшний день нет хорошего универсального инструмента.
perf
perf — это инструмент профилирования, встроенный в ядро Linux. Является семплирующим профайлером, который запускается отдельным процессом, поэтому не добавляет напрямую оверхед к профилируемой программе. Косвенно добавленный оверхед равномерно «размазывается», поэтому не искажает измерения.
При всех своих плюсах perf способен работать только со скомпилированным кодом и с JIT и не умеет работать с кодом, выполняющимся «под виртуальной машиной». Поэтому сам PHP-код профилировать в нём не получится, зато отлично видно, как работает PHP внутри, включая различные PHP-расширения, и сколько на это тратится ресурсов.
Мы, например, при помощи perf нашли несколько узких мест, в том числе место со сжатием, о котором я расскажу ниже.
Пример:
perf record --call-graph dwarf,65528 -F 99 -p $(pgrep php-cgi | paste -sd "," -) -- sleep 20
perf report(если процесс и perf выполняются под разными пользователями, то perf нужно запускать из-под sudo).

Пример вывода perf report для PHP-FPM
XHProf и XHProf aggregator
XHProf — расширение для PHP, которое расставляет таймеры вокруг всех вызовов функций/методов, а также содержит инструменты для визуализации полученных таким образом результатов. В отличие от perf, он позволяет оперировать терминами PHP-кода (при этом что происходит в расширениях не увидеть).
К недостаткам можно отнести две вещи:
- все измерения собираются в рамках одного запроса, поэтому не дают информацию о картине в целом;
- оверхед хоть и не такой большой, как, например, при использовании Xdebug, но он есть, и в некоторых случаях результаты сильно искажаются (чем чаще вызывается какая-либо функция и чем она проще, тем сильнее искажение).
Вот пример, иллюстрирующий последний пункт:
function child1() {
return 1;
}
function child2() {
return 2;
}
function parent1() {
child1();
child2();
return;
}
for ($i = 0; $i < 1000000; $i++) {
parent1();
}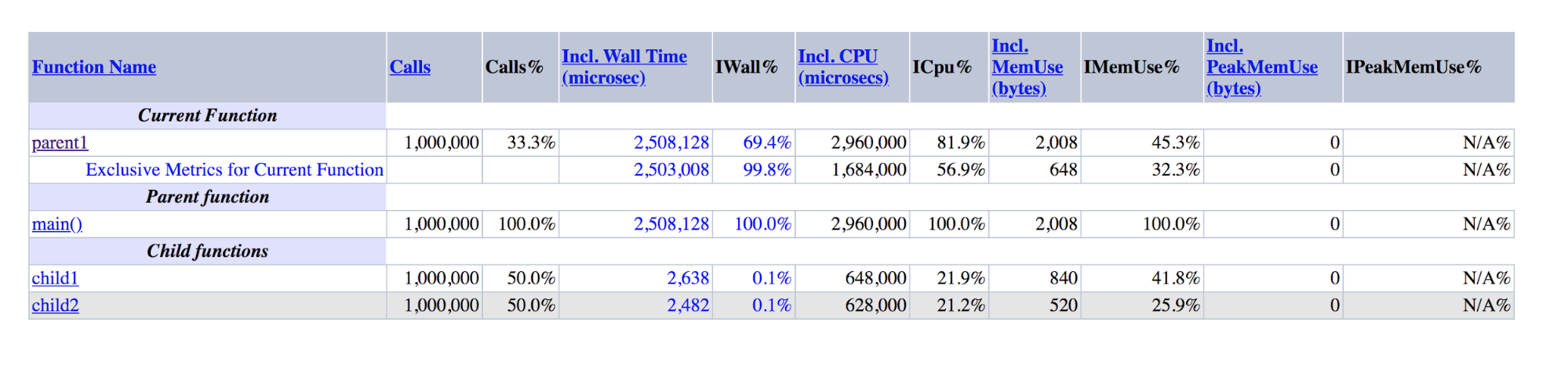
Вывод XHProf для демоскрипта: parent1 на порядки превышает сумму child1 и child2
Видно, что parent1() выполнялась в ~500 раз дольше, чем child1() + child2(), хотя в действительности эти цифры должны быть примерно равны, как равны main() и parent1().
Если с последним недостатком сложно бороться, то для борьбы с первым мы сделали надстройку над XHProf, которая агрегирует профайлы разных реквестов и визуализирует агрегированные данные.
Помимо XHProf, есть множество других менее известных профайлеров, работающих по похожему принципу. Они обладают схожими преимуществами и недостатками.
Pinba
Pinba позволяет мониторить производительность в разрезе скриптов (экшенов) и по предварительно расставленным таймерам. Все измерения в разрезе скриптов делаются из коробки, для этого никаких дополнительных действий не требуется. По каждому скрипту и таймеру выполняется getrusage, поэтому нам точно известно, сколько процессорного времени было потрачено на тот или иной участок кода (в отличие от семплирующих профайлеров, где это время может оказаться временем ожидания сети, диска и т. д.). Pinba отлично подходит для сохранения исторических данных и получения картины как в целом, так и в рамках конкретных типов запросов.
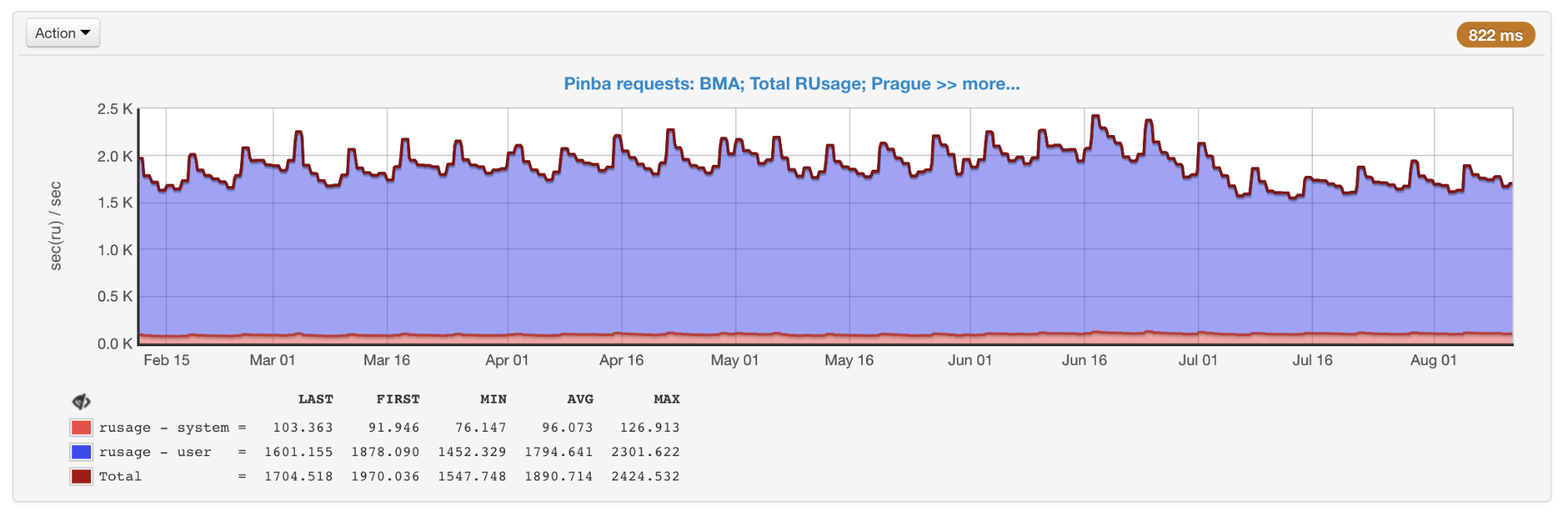
Общий rusage всех скриптов, полученный из Pinba
К недостаткам можно отнести то, что таймеры, которые профилируют конкретные участки кода, а не скрипты целиком, необходимо расставлять в коде заранее, а также наличие оверхеда, который (как в XHProf) может искажать данные.
phpspy
phpspy — относительно новый проект (первый коммит на GitHub был полгода назад), который выглядит перспективным, поэтому мы за ним пристально следим.
С точки зрения пользователя phpspy похож на perf: запускается параллельный процесс, который периодически копирует участки памяти PHP-процесса, разбирает их и получает оттуда стек-трейсы и другие данные. Это делается достаточно специфичным способом. Для того чтобы минимизировать оверхед, phpspy не останавливает PHP-процесс и копирует память прямо во время его работы. Это приводит к тому, что профайлер может получить неконсистентное состояние, стек-трейсы могут быть битыми. Но phpspy умеет обнаруживать это и отбрасывает такие данные.
В перспективе при помощи этого инструмента можно будет собирать как данные по картине в целом, так и профайлы конкретных типов запросов.
Сравнительная таблица
Чтобы структурировать различия между инструментами, сделаем сводную таблицу:

Сравнение основных возможностей профайлеров
Flame Graphs
Оптимизации и подходы
С помощью этих инструментов мы постоянно следим за производительностью и использованием наших ресурсов. Когда они используются неоправданно или мы приближаемся к порогу (для CPU мы эмпирически выбрали значение в 55%, чтобы иметь запас времени в случае роста), как я писал выше, одним из вариантов решения проблемы является оптимизация.
Хорошо, если оптимизация уже сделана кем-то другим, как это было в случае с PHP 7.0, когда эта версия оказалась гораздо более производительной, чем предыдущие. Мы вообще стараемся использовать современные технологии и инструменты, в том числе своевременно обновляемся на свежие версии PHP. Согласно публичным бенчмаркам, PHP 7.2 на 5—12% быстрее PHP 7.1. Но нам этот переход, увы, дал значительно меньше.
За всё время мы реализовали огромное количество оптимизаций. К сожалению, большая их часть, сильно связана с нашей бизнес-логикой. Я расскажу о тех, которые могут быть актуальны не только для нас, либо идеи и подходы из которых можно использовать за пределами нашего кода.
Сжатие zlib => zstd
Мы используем компрессию для больших мемкеш-ключей. Это позволяет нам тратить в три—четыре раза меньше памяти на хранение за счёт дополнительных расходов CPU на сжатие/распаковку. Мы использовали для этого zlib (наше расширение для работы с мемкешем отличается от тех, которые поставляются с PHP, но в официальных тоже используется zlib).
В perf на продакшене было примерно так:
+ 4.03% 0.22% php-cgi libz.so.1.2.11 [.] inflate
+ 3.38% 0.00% php-cgi libz.so.1.2.11 [.] deflate7—8% времени уходило на компрессию/декомпрессию.
Мы решили протестировать разные уровни и алгоритмы сжатия. Оказалось, что zstd работает на наших данных почти в десять раз быстрее, проигрывая по месту в ~1,1 раза. Достаточно простое изменение алгоритма сэкономило нам ~7,5% CPU (это, напомню, на наших объёмах равнозначно ~45 серверам).
Важно понимать, что соотношение эффективности работы разных алгоритмов сжатия может сильно отличаться в зависимости от входных данных. Есть различные сравнения, но точнее всего это можно оценить только на реальных примерах.
IS_ARRAY_IMMUTABLE как хранилище редко изменяемых данных
Работая с реальными задачами, приходится иметь дело с такими данными, которые нужны часто и при этом редко меняются и имеют ограниченный размер. У нас подобных данных много, хороший пример — конфигурация сплит-тестов. Мы проверяем, попадает ли пользователь под условия того или иного теста, и в зависимости от этого показываем ему экспериментальную или обычную функциональность (это происходит практически во время каждого запроса). В других проектах таким примером могут быть конфиги и разнообразные справочники: страны, города, языки, категории, бренды и т. п.
Так как такие данные запрашиваются часто, их получение может создавать ощутимую дополнительную нагрузку как на само приложение, так и на сервис, в котором эти данные хранятся. Последнюю проблему можно решить, например, с помощью APCu, которое в качестве хранилища использует память той же машины, где запущен PHP-FPM. Но даже в этом случае:
- будут затраты на сериализацию/десериализацию;
- нужно как-то инвалидировать данные при изменении;
- есть некоторый оверхед по сравнению с доступом к просто переменной в PHP.
В PHP 7.0 появилась оптимизация IS_ARRAY_IMMUTABLE. Если объявить массив, все элементы которого известны на момент компиляции, то он будет обработан и помещён в память OPCache единожды, PHP-FPM-воркеры будут ссылаться на эту общую память, не расходуя свою до попытки изменения. Из этого также следует, что include такого массива будет занимать константное время вне зависимости от размера (обычно ~1 микросекунду).
Для сравнения: пример времени получения массива из 10 000 элементов через include и apcu_fetch:
$t0 = microtime(true);
$a = include 'test-incl-1.php';
$t1 = microtime(true);
printf("include (%d): %d microsec\n", count($a), ($t1-$t0) * 1e6);
$t0 = microtime(true);
$a = apcu_fetch('a');
$t1 = microtime(true);
printf("apcu_fetch (%d): %d microsec\n", count($a), ($t1-$t0) * 1e6);
//include (10000): 1 microsec
//apcu_fetch (10000): 792 microsec
Проверить, была ли применена эта оптимизация, можно очень просто, если посмотреть на сгенерированные опкоды:
$ cat immutable.php
<?php
return [
'key1' => 'val1',
'key2' => 'val2',
'key3' => 'val3',
];
$ cat mutable.php
<?php
return [
'key1' => \SomeClass::CONST_1,
'key2' => 'val2',
'key3' => 'val3',
];
$ php -d opcache.enable=1 -d opcache.enable_cli=1 -d opcache.opt_debug_level=0x20000 immutable.php
$_main: ; (lines=1, args=0, vars=0, tmps=0)
; (after optimizer)
; /home/ubuntu/immutable.php:1-8
L0 (4): RETURN array(...)
$ php -d opcache.enable_cli=1 -d opcache.opt_debug_level=0x20000 mutable.php
$_main: ; (lines=5, args=0, vars=0, tmps=2)
; (after optimizer)
; /home/ubuntu/mutable.php:1-8
L0 (4): T1 = FETCH_CLASS_CONSTANT string("SomeClass") string("CONST_1")
L1 (4): T0 = INIT_ARRAY 3 T1 string("key1")
L2 (5): T0 = ADD_ARRAY_ELEMENT string("val2") string("key2")
L3 (6): T0 = ADD_ARRAY_ELEMENT string("val3") string("key3")
L4 (6): RETURN T0
В первом случае видно, что в файле есть единственный опкод — возврат готового массива. Во втором случае происходит его поэлементное формирование каждый раз при исполнении этого файла.
Таким образом, можно генерировать структуры в виде, не требующем дальнейшего преобразования в рантайме. Например, вместо того чтобы каждый раз для автолоада разбирать названия класса по знакам «_» и «\», можно предварительно сгенерировать карту соответствий «Класс => Путь». В этом случае функция преобразования будет сводиться к одному обращению к хеш-таблице. Такую оптимизацию делает Composer, если включить опцию optimize-autoloader.
Для инвалидации таких данных специально ничего делать не нужно — PHP сам перекомпилирует файл при изменении так же, как это делается при обычном деплое кода. Единственный недостаток, о котором нужно не забывать: если файл будет очень большим, то первый запрос после его изменения вызовет перекомпиляцию, которая может занимать ощутимое время.
Производительность include/require
В отличие от примера со статическим массивом, подключение файлов с объявлениями классов и функций происходит не так быстро. Несмотря на наличие OPCache, движок PHP должен скопировать их в память процесса, рекурсивно подключив зависимости, что в итоге может занимать сотни микросекунд или даже миллисекунды на файл.
Если создать новый пустой проект на Symfony 4.1 и поставить get_included_files() первой строкой в экшене, можно увидеть, что уже подключено 310 файлов. В реальном проекте это число может доходить до тысяч за запрос. Стоит обратить внимание на следующие вещи.
Отсутствие автолоадинга функций
Есть Function Autoloading RFC, но никакого его развития не видно уже несколько лет. Поэтому если зависимость в Composer определяет функции вне класса и эти функции должны быть доступны пользователю, то это делается путём обязательного подключения файла с этими функциями на каждую инициализацию автолоадера.
Например, удалив из composer.json одну из зависимостей, объявляющую множество функций и легко заменяемую сотней строк кода, мы выиграли пару процентов CPU.
Автолоадер вызывается чаще, чем может показаться
Для демонстрации идеи создадим такой файл с классом:
<?php
class A extends B implements C
{
use D;
const AC1 = \E::E1;
const AC2 = \F::F1;
private static $as3 = \G::G1;
private static $as4 = \H::H1;
private $a5 = \I::I1;
private $a6 = \J::J1;
public function __construct(\K $k = null) {}
public static function asf1(\L $l = null) :? LR { return null; }
public static function asf2(\M $m = null) :? MR { return null; }
public function af3(\N $n = null) :? NR { return null; }
public function af4(\P $p = null) :? PR { return null; }
}Зарегистрируем автолоадер:
spl_autoload_register(function ($name) {
echo "Including $name...\n";
include "$name.php";
});И сделаем несколько вариантов использования этого класса:
include ‘A.php’
Including B...
Including D...
Including C...
\A::AC1
Including A...
Including B...
Including D...
Including C...
Including E...
new A()
Including A...
Including B...
Including D...
Including C...
Including E...
Including F...
Including G...
Including H...
Including I...
Including J...
Можно заметить, что, когда мы просто каким-то образом подключаем класс, но не создаём его инстанс, будут подключены родитель, интерфейсы и трейты. Это делается рекурсивно для всех подключаемых по мере резолва файлов.
При создании инстанса к этому добавляется резолв всех констант и полей, что приводит к подключению всех необходимых для этого файлов, что, в свою очередь, также вызовет рекурсивное подключение трейтов, родителей и интерфейсов новоподключённых классов.

Подключение связанных классов для процесса создания инстанса и остальных случаев
Какого-то универсального решения этой проблемы нет, нужно просто иметь её в виду и следить за связями между классами: одна строчка может потянуть за собой подключение сотен файлов.
Настройки OPCache
Если вы используете метод атомарного деплоя при помощи изменения симлинка, предложенный Расмусом Лердорфом, создателем PHP, то для решения проблемы «залипания» симлинка на старой версии вам приходится включать opcache.revalidate_path, как это рекомендуется, например, в этой статье про OPCache, переведённой Mail.Ru Group.
Проблема в том, что эта опция ощутимо (в среднем в полтора—два раза) увеличивает время на include каждого файла. Суммарно это может потреблять значительное количество ресурсов (у нас отключение этой опции дало выигрыш в 7—9%).
Чтобы её отключить, нужно сделать две вещи:
- заставить веб-сервер резолвить симлинки;
- перестать подключать файлы внутри PHP-скрипта по путям, содержащим симлинки, либо принудительно резолвить их через readlink() или realpath().
Если все файлы подключаются автолоадером Composer, то второй пункт будет выполнен автоматически после выполнения первого: Сomposer использует константу __DIR__, которая будет разрезолвлена верно.
OPCache имеет ещё несколько опций, которые могут дать прирост производительности в обмен на гибкость. Подробнее про это можно прочитать в статье, которую я упоминал выше.
Несмотря на все эти оптимизации, include всё равно не будет бесплатным. Для борьбы с этим в PHP 7.4 планируется добавление preload.
APCu, блокировки
Хотя мы не говорим здесь о базах данных и сервисах, в коде также могут возникать различного рода блокировки, которые увеличивают время выполнения скрипта.
По мере роста запросов мы заметили резкое замедление ответа в пиковые моменты. После выяснения причин оказалось, что, хотя APCu и является самым быстрым способом получения данных (по сравнению с Memcache, Redis и прочими внешними хранилищами), он тоже может работать медленно при частой перезаписи одинаковых ключей.
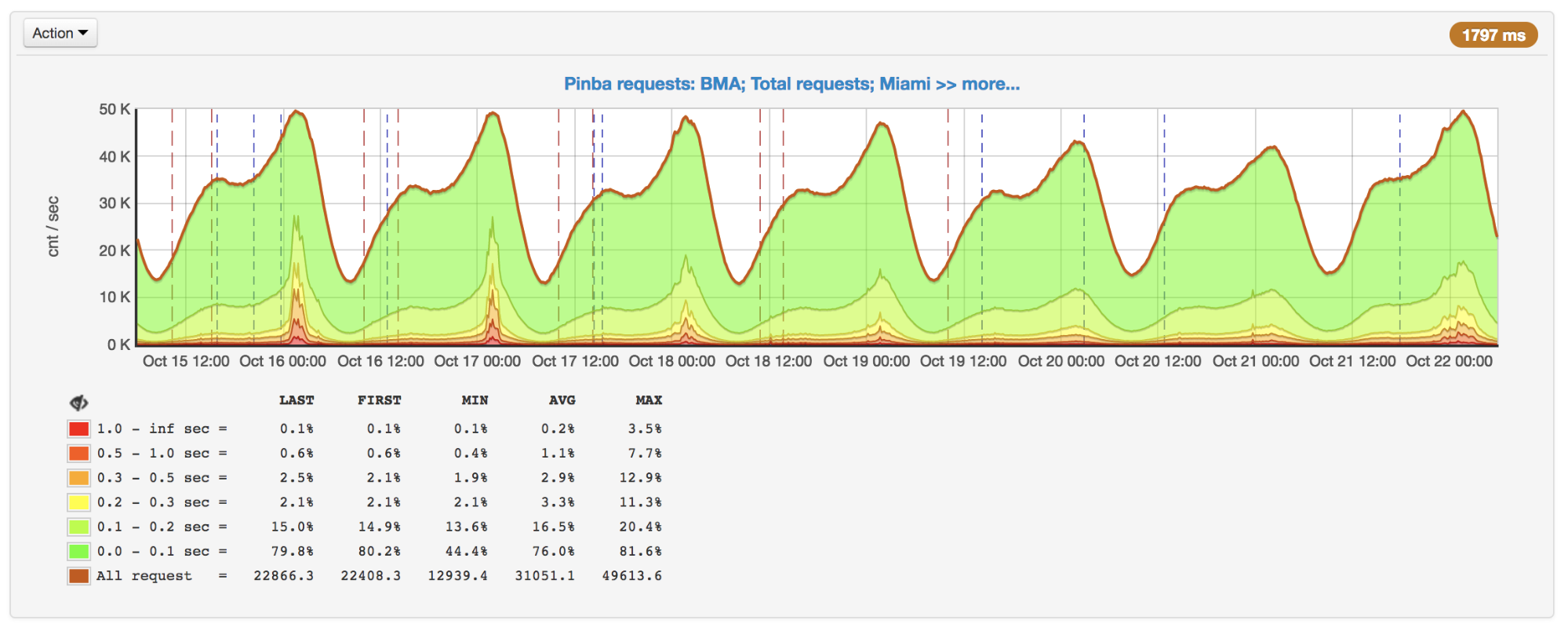
Количество запросов в секунду и время выполнения: всплески в пиках 16 и 17 октября
При использовании APCu в качестве кеша эта проблема не так актуальна, потому что кеширование обычно подразумевают редкую запись и частое чтение. Но некоторые задачи и алгоритмы (например, Circuit Breaker (реализация на PHP)) подразумевают также и частую запись, что вызывает блокировки.
Универсального решения этой проблемы нет, но в случае с Circuit Breaker её можно решить, например, путём вынесения его в отдельный сервис, поставленный на машины с PHP.
Пакетная обработка
Даже если не брать в расчёт include, обычно всё равно значительная часть времени выполнения запроса тратится на первичную инициализацию: фреймворк (например, сборка DI-контейнера и инициализация всех его зависимостей, роутинг, выполнение всех listeners), поднятие сессии, User’а и так далее.
Если ваш бекенд является внутренним API для чего-то, то наверняка какие-то запросы на клиентах можно объединить в пачки и отправлять единым запросом. В таком случае инициализация будет выполнена один раз для нескольких запросов.
Если на клиентах это сделать невозможно, попробуйте найти запросы, которые можно обрабатывать асинхронно. Их можно принимать каким-то простейшим скриптом, который не инициализирует ничего и просто откладывает их в очередь. А уже её можно будет обрабатывать пачками.
Разумная утилизация ресурсов
У нас в Badoo есть разные кластеры, которые заточены под разные нужды. Помимо кластера с PHP-FPM, где сотни серверов загружены по CPU, а диски простаивают, у нас есть один специфичный кластер баз данных из пары сотен машин, который прямо противоположен первому: с огромными дисками и сильно загруженный по IO, CPU которого простаивали.
Очевидным решением здесь был запуск PHP-FPM на втором кластере — по сути, мы бесплатно получили пару сотен дополнительных машин в кластер PHP.
Нагрузка может быть разделённой не только по типу (CPU, IO), но и по времени. Например, возможно, в рабочее время сотрудники компании строят отчёты, гоняют тесты, компилируют или делают что-то ещё на большом количестве серверов, а пик использования приложения приходится на нерабочее время. В таком случае можно использовать ресурсы простаивающего кластера, когда другой особенно сильно загружен. А построение отчётов, может быть, вообще можно произвольно переносить по времени.
Заключение
Так мы решаем подобного рода задачи у себя. В результате даже в условиях постоянного роста трафика и активности нам удаётся не добавлять новое железо в кластеры с PHP уже в течение нескольких лет.
Краткое резюме:
- на небольших объёмах железо обычно дешевле оптимизаций;
- не оптимизируйте без явной необходимости;
- если всё-таки нужно оптимизировать, то измеряйте: скорее всего, проблема не в коде;
- правильно интерпретируйте измерения: не всегда всё линейно и очевидно (гипертрединг, пики, нелинейность активности);
- не полагайтесь на догадки: профилируйте и правильно интерпретируйте результаты;
- изменить настройки сжатия, OPCache или обновить версию PHP, как правило, проще, чем оптимизировать код;
- но и тут измеряйте: чужие решения могут не подойти вам (как, например, нам использование PHP 7.2 не дало столько, сколько обещают бенчмарки);
- смотрите на проблему шире: возможно, помогут оптимизации клиентов или более разумное использование ресурсов.
А какие инструменты и утилиты используете вы?
Спасибо за внимание!
