Маркетинг в Х5 – это большие объемы данных. «Пятёрочка», например, отправляет более 30 млн коммуникаций каждый месяц, и это число постоянно растёт. Одному клиенту одновременно можно отправить несколько предложений, и важно правильно выбрать, какие именно. Акции магазина должны быть интересны клиенту и экономически обоснованы для ритейлера. В этом посте расскажем, как мы начали определять действительно востребованные предложения с помощью машинного обучения и исключать эффект спама.

Над тем, чтобы улучшить коммуникации с покупателями «Пятерочки», «Перекрестка» и «Карусели», в Х5 Retail Group работает большая команда.
Сейчас для поддержания этой системы требуется работа десятков людей и систем: аккуратное накопление данных в Oracle, анализ данных и настройка кампаний в SAS, настройка правил начисления бонусов в Comarch. Аналитики каждый день принимают решения о том, как подобрать наиболее релевантное на данный момент предложение, выбирая из огромного множества вариантов, основываясь на исторических данных о результатах акций. Работаем и над тем, чтобы коммуникации были по адресу и не имели ничего общего со спамом.
Мы задумались, как перевести процесс подбора актуального для клиента предложения в автоматический режим с использованием машинного обучения, чтобы при этом:
Так мы пришли к реализации самоорганизующихся систем и началась эпоха разработки системы Reinforcement Learning в X5.
Немного о Reinforcement Learning
*RL (Reinforcement Learning) — это обучение с подкреплением. Один из способов машинного обучения, в ходе которого испытуемая система (агент) обучается, взаимодействуя с некоторой средой.
Теория обучения с подкреплением оперирует двумя понятиями: действие и состояние. Исходя из состояния объекта, алгоритм принимает решение о выборе действий. В результате совершенного действия объект попадает в новое состояние и так далее.
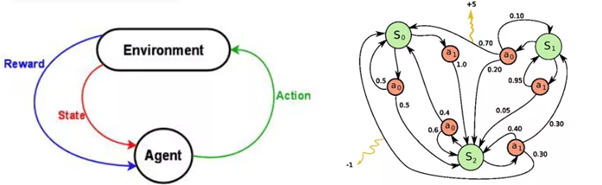
Если предположить, что:
…то описанная система должна решать поставленную цель и агенты (клиенты) сами будут выбирать себе действия (вознаграждения и кампании) ради их комфорта и осмысленных отношений с магазином.
Что предлагает мировой разум RL
Сначала мы искали примеры решения подобных задач, описанные в открытых источниках.
Нашли несколько интересных примеров:
Про инструменты:
Про применение RL к аналогичным задачам в маркетинге:
Но все они не подходили под наш случай или не внушали доверия.
Этап 1. Прототип решения
Поэтому мы решили разработать свой подход.
Чтобы минимизировать риски и не попадать в ситуацию, когда долго разрабатывали систему без реального использования, а потом она в итоге не взлетела, мы решили начать с прототипа, который не реализовывал бы метод RL в чистом виде, но имел понятный бизнес-результат.
В основе базовых реализаций обучения с подкреплением лежит матрица «состояние-действие-результат», обновляемая каждый раз при получении новой информации от среды.
Чтобы уменьшить пространство состояний, в рамках прототипа был сделан переход от клиента к сегменту, где все клиенты были разделены 29 групп на основе параметров:
Таким образом, задача свелась к обучению матрицы следующего вида:
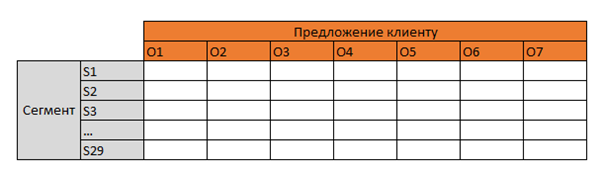
На пересечении матрица должна была заполняться значением функции цели.
В первой версии алгоритма в качестве функции цели был выбран удельный отклик на кампанию.
Первый прототип мы разработали за пару недель на SQL (Oracle) и Python. У нас были исторические данные по коммуникациям, поэтому мы смогли частично заполнить матрицу предполагаемым весом пар «сегмент-предложение». К сожалению, оказалось, что для некоторых пар не хватает данных. Нас это не остановило, мы жаждали боевых испытаний.
Департамент маркетинга «Пятерочки» доверил нам данные о двух миллионах клиентов на 10 недель экспериментов. На это время эти покупатели были отключены от всех остальных коммуникаций. Половину клиентов мы определили в контрольную группу, на остальных группах тестировали прототип.
Теория RL говорила нам о том, что мы должны не только выбирать наилучшее действие, но и непрерывно продолжать обучение. Поэтому каждый раз на небольшом проценте клиентов мы тестировали случайную кампанию. Соответственно, остальные клиенты получали оптимальное предложение (лучшая кампания). Таким образом, мы получили свою реализацию ε – жадного метода выбора наиболее оптимального предложения.

После трех запусков системы стало ясно, что выбор лучшей кампании по отклику не приводит к увеличению удельного РТО на кампанию (именно этот показатель является главным мерилом эффективности любой целевой кампании в любой организации).
Изменив функцию цели (а значит, и алгоритм выбора лучшей кампании) непосредственно на инкрементальное РТО, мы узнали, что самые успешные с этой точки зрения кампании являются убыточными с точки зрения ROI.
Так к восьмому запуску системы мы поменяли функцию цели в третий раз, теперь на ROI.
Выводы из разработки прототипа
Ниже приведены графики эффективности по основным показателям:



Можно заметить, что к последнему запуску эффективность прототипа (по инкрементальному РТО) превзошла средний результат кампаний, запускаемых аналитиками, а если рассматривать только “лучшие” сегменты и предложения, то разница — больше чем в два раза.
На будущее мы сделали для себя следующие выводы:
Итого:
Этап 2. Допиливаем систему
Вдохновившись результатами первого этапа, мы решили доработать систему и внести следующие функциональные улучшения:
1) перейти от выбора предложения сегменту клиентов к выбору предложения индивидуально для клиента, описывая его набором метрик:
2) уточнить функцию цели, добавив в нее помимо отклика рост РТО :).
Теперь, выбирая индивидуальное предложение для клиента, мы ориентируемся на ожидаемое значение целевой функции Q1:
Сейчас пилотирование второго подхода в самом разгаре, но мы уже превзошли предыдущие результаты.
Что дальше
К счастью, результаты радуют не только команду внедрения и разработки, но и бизнес-заказчиков, поэтому в будущем, помимо функциональных доработок, планируется создать аналогичные системы, работающие для real-time- и онлайн-маркетинга.
Кроме того, внимательный читатель заметит, что до настоящего момента мы не использовали RL в чистом виде, а только его концепцию. Тем не менее, даже при таком упрощении мы наблюдаем положительный результат и теперь готовы двигаться дальше, усложняя наш алгоритм. Своим примером мы хотим вдохновить других идти «от простого к сложному».
Редакция Хабра X5 благодарит компанию Glowbyte Consulting за помощь в подготовке поста. Пилот выполнен объединенной командой из шести специалистов «Пятерочки» и Glowbyte.
Кстати, мы ищем менеджера по развитию продуктов Big Data, специалиста по работе с данными, специалиста по аналитике и менеджера программ лояльности.

Над тем, чтобы улучшить коммуникации с покупателями «Пятерочки», «Перекрестка» и «Карусели», в Х5 Retail Group работает большая команда.
Сейчас для поддержания этой системы требуется работа десятков людей и систем: аккуратное накопление данных в Oracle, анализ данных и настройка кампаний в SAS, настройка правил начисления бонусов в Comarch. Аналитики каждый день принимают решения о том, как подобрать наиболее релевантное на данный момент предложение, выбирая из огромного множества вариантов, основываясь на исторических данных о результатах акций. Работаем и над тем, чтобы коммуникации были по адресу и не имели ничего общего со спамом.
Мы задумались, как перевести процесс подбора актуального для клиента предложения в автоматический режим с использованием машинного обучения, чтобы при этом:
- учитывалась накопленная информация по клиентам и прошлым кампаниям
- система сама училась на новых данных
- планирование было просчитано больше, чем на один шаг вперед
Так мы пришли к реализации самоорганизующихся систем и началась эпоха разработки системы Reinforcement Learning в X5.
Немного о Reinforcement Learning
*RL (Reinforcement Learning) — это обучение с подкреплением. Один из способов машинного обучения, в ходе которого испытуемая система (агент) обучается, взаимодействуя с некоторой средой.
Теория обучения с подкреплением оперирует двумя понятиями: действие и состояние. Исходя из состояния объекта, алгоритм принимает решение о выборе действий. В результате совершенного действия объект попадает в новое состояние и так далее.

Если предположить, что:
- агент – клиент
- действие – коммуникация с клиентом
- состояние – состояние (Набор метрик) клиента
- функция цели – дальнейшее поведение клиента (например, увеличение выручки или отклик на целевую кампанию)
…то описанная система должна решать поставленную цель и агенты (клиенты) сами будут выбирать себе действия (вознаграждения и кампании) ради их комфорта и осмысленных отношений с магазином.
Что предлагает мировой разум RL
Сначала мы искали примеры решения подобных задач, описанные в открытых источниках.
Нашли несколько интересных примеров:
Про инструменты:
Про применение RL к аналогичным задачам в маркетинге:
- www.researchgate.net/publication/221653839_Cross_channel_optimized_marketing_by_reinforcement_learning
- cseweb.ucsd.edu/~elkan/254spring02/sequential.pdf
- www0.cs.ucl.ac.uk/staff/d.silver/web/Publications_files/concurrent-rl.pdf
- arxiv.org/pdf/1504.01840.pdf
- habrahabr.ru/company/ods/blog/325416
Но все они не подходили под наш случай или не внушали доверия.
Этап 1. Прототип решения
Поэтому мы решили разработать свой подход.
Чтобы минимизировать риски и не попадать в ситуацию, когда долго разрабатывали систему без реального использования, а потом она в итоге не взлетела, мы решили начать с прототипа, который не реализовывал бы метод RL в чистом виде, но имел понятный бизнес-результат.
В основе базовых реализаций обучения с подкреплением лежит матрица «состояние-действие-результат», обновляемая каждый раз при получении новой информации от среды.
Чтобы уменьшить пространство состояний, в рамках прототипа был сделан переход от клиента к сегменту, где все клиенты были разделены 29 групп на основе параметров:
- средний чек
- частота покупок
- стабильность корзины
- наполнение корзины
- лояльность клиента (доля количества недель с покупками к количеству недель, в течение которых человек участвовал в программе лояльности магазина)
Таким образом, задача свелась к обучению матрицы следующего вида:

На пересечении матрица должна была заполняться значением функции цели.
В первой версии алгоритма в качестве функции цели был выбран удельный отклик на кампанию.
Первый прототип мы разработали за пару недель на SQL (Oracle) и Python. У нас были исторические данные по коммуникациям, поэтому мы смогли частично заполнить матрицу предполагаемым весом пар «сегмент-предложение». К сожалению, оказалось, что для некоторых пар не хватает данных. Нас это не остановило, мы жаждали боевых испытаний.
Департамент маркетинга «Пятерочки» доверил нам данные о двух миллионах клиентов на 10 недель экспериментов. На это время эти покупатели были отключены от всех остальных коммуникаций. Половину клиентов мы определили в контрольную группу, на остальных группах тестировали прототип.
Теория RL говорила нам о том, что мы должны не только выбирать наилучшее действие, но и непрерывно продолжать обучение. Поэтому каждый раз на небольшом проценте клиентов мы тестировали случайную кампанию. Соответственно, остальные клиенты получали оптимальное предложение (лучшая кампания). Таким образом, мы получили свою реализацию ε – жадного метода выбора наиболее оптимального предложения.

После трех запусков системы стало ясно, что выбор лучшей кампании по отклику не приводит к увеличению удельного РТО на кампанию (именно этот показатель является главным мерилом эффективности любой целевой кампании в любой организации).
Изменив функцию цели (а значит, и алгоритм выбора лучшей кампании) непосредственно на инкрементальное РТО, мы узнали, что самые успешные с этой точки зрения кампании являются убыточными с точки зрения ROI.
Так к восьмому запуску системы мы поменяли функцию цели в третий раз, теперь на ROI.
Выводы из разработки прототипа
Ниже приведены графики эффективности по основным показателям:
- Чистый отклик клиента на коммуникацию
- Инкрементальное РТО
- Маржинальность



Можно заметить, что к последнему запуску эффективность прототипа (по инкрементальному РТО) превзошла средний результат кампаний, запускаемых аналитиками, а если рассматривать только “лучшие” сегменты и предложения, то разница — больше чем в два раза.
На будущее мы сделали для себя следующие выводы:
- Заранее проговорить с бизнесом KPI может быть недостаточно. KPI бизнес-заказчика тоже меняются. (Так мы перешли от РТО к маржинальности).
- Косвенные цели (в нашем случае отклик) — это хорошо, но рано или поздно вас попросят учитывать непосредственные показатели эффективности.
- Найдены лучшие пары сегмент-кампания, которые показывают стабильно хорошие результаты. Эти кампании были запущены на всей базе и регулярно приносят прибыль.
Итого:
- схема работает
- стоит учитывать затраты клиента (победа по иРТО не обеспечила роста ROI)
- хотелось бы учитывать историю откликов
- теперь не так страшно переходить на уровень клиента
Этап 2. Допиливаем систему
Вдохновившись результатами первого этапа, мы решили доработать систему и внести следующие функциональные улучшения:
1) перейти от выбора предложения сегменту клиентов к выбору предложения индивидуально для клиента, описывая его набором метрик:
- Флаг отклика на последнее предложение
- Отношение РТО клиента за 2 недели к РТО за 6 недель
- Отношение количества дней с последней покупки к среднему расстоянию между транзакциями
- Число недель с момента последней коммуникации
- Отношение суммы использованных бонусов за месяц к сумме РТО за месяц
- Достижение цели на предшествующих двух неделях
- Флаги откликов на предложения с разными типами вознаграждений
- выбирать не 1, а цепочку из двух последующих кампаний
2) уточнить функцию цели, добавив в нее помимо отклика рост РТО :).
Теперь, выбирая индивидуальное предложение для клиента, мы ориентируемся на ожидаемое значение целевой функции Q1:
- Q = 1, если клиент откликнулся на кампанию и его 2-х недельный РТО на протяжении эпизода вырос на m%
- Q = 0, если клиент НЕ откликнулся на кампанию и его 2-х недельный РТО на протяжении эпизода вырос на m%
- Q = 0, если клиент откликнулся на кампанию и его 2-х недельный РТО на протяжении эпизода вырос МЕНЕЕ, чем на m%
- Q = -1, если клиент НЕ откликнулся на кампанию и его 2-х недельный РТО на протяжении эпизода вырос МЕНЕЕ, чем на m%
Сейчас пилотирование второго подхода в самом разгаре, но мы уже превзошли предыдущие результаты.
Что дальше
К счастью, результаты радуют не только команду внедрения и разработки, но и бизнес-заказчиков, поэтому в будущем, помимо функциональных доработок, планируется создать аналогичные системы, работающие для real-time- и онлайн-маркетинга.
Кроме того, внимательный читатель заметит, что до настоящего момента мы не использовали RL в чистом виде, а только его концепцию. Тем не менее, даже при таком упрощении мы наблюдаем положительный результат и теперь готовы двигаться дальше, усложняя наш алгоритм. Своим примером мы хотим вдохновить других идти «от простого к сложному».
Редакция Хабра X5 благодарит компанию Glowbyte Consulting за помощь в подготовке поста. Пилот выполнен объединенной командой из шести специалистов «Пятерочки» и Glowbyte.
Кстати, мы ищем менеджера по развитию продуктов Big Data, специалиста по работе с данными, специалиста по аналитике и менеджера программ лояльности.
