Comments 73
по сравнению с fsin/fcos/fsincos какой выигрыш в производительности?
latency/Reciprocal throughput какой получился?
Параллельно за 1 проход сразу несколько аргументов пробовали обрабатывать (так обычно быстрее)?
latency/Reciprocal throughput какой получился?
Параллельно за 1 проход сразу несколько аргументов пробовали обрабатывать (так обычно быстрее)?
Сделал тест в одном потоке — 1 млрд вызовов с присваиванием переменной:
CPU.(FPU) ~ 32.7 (максимум 42.8) млн/сек.
Math.Sin ~ 58 (максимум 70.1) млн/сек.
Мой SIMD.Sinf ~ 147.0 (161.2) млн/сек.
Результат плавает из-за загрузки системы. Корректно измерить не получается.
Без скобок результат параллельной работы Chrome. В скобках максимум при «простое» системы. Windows 10 (x64).
CPU.(FPU) ~ 32.7 (максимум 42.8) млн/сек.
Math.Sin ~ 58 (максимум 70.1) млн/сек.
Мой SIMD.Sinf ~ 147.0 (161.2) млн/сек.
Результат плавает из-за загрузки системы. Корректно измерить не получается.
Без скобок результат параллельной работы Chrome. В скобках максимум при «простое» системы. Windows 10 (x64).
Если цель производительность/цена, то за аналогичную цену получим на 2-2.5 порядка большую производительность на GPU например используя 6 Nvidia GTX 1050-Ti.
Вот пример оптимизации библиотечной sincos с аппроксимационными полиномами
devtalk.nvidia.com/default/topic/960757/cuda-programming-and-performance/a-faster-and-more-accurate-implementation-of-sincosf-/1
Вот пример оптимизации библиотечной sincos с аппроксимационными полиномами
devtalk.nvidia.com/default/topic/960757/cuda-programming-and-performance/a-faster-and-more-accurate-implementation-of-sincosf-/1
И?
Там, где не нужна особая точность, можно использовать формулу Бхаскара:
sinx = 16x(π−x)/(5π²−4x(π−x)), x ∈ [0, π]
Она даёт максимальную ошибку 0.0016.
sinx = 16x(π−x)/(5π²−4x(π−x)), x ∈ [0, π]
Она даёт максимальную ошибку 0.0016.
С такой ошибкой, можно попытаться реализовать функцию таблично. Пара умножений(интерполяция), проверка условия и выбор из таблицы на ~10000 элементов, не?
Табличный метод быстрее, но есть больше памяти. Вопрос только в том, что именно надо экономить в каждом конкретном случае.
У меня есть таблицы. Они действительно быстрее.
Но вот размер массива для Single при точности угла:
0,1 (~56.25 Кб)
0,01 (~562.5 Кб)
0,001 (~5,49 Мб)
0,0001 (~54,9 Мб)
0,00001 (~549,3 Мб)
0,000001 (~5,36 Гб)
0,0000001 (~53,64 Гб)
Но вот размер массива для Single при точности угла:
0,1 (~56.25 Кб)
0,01 (~562.5 Кб)
0,001 (~5,49 Мб)
0,0001 (~54,9 Мб)
0,00001 (~549,3 Мб)
0,000001 (~5,36 Гб)
0,0000001 (~53,64 Гб)
А никто не заставляет рассчитывать каждое значение. Предлагается взять ряд узловых точек, а между ними воспользоваться линейной аппроксимацией
Для точных табличных вычислений совсем не обязательно использовать такие гигантские объёмы, если использовать тригонометрические тождества. В своей библиотеке я считаю синусы с точностью ≈30 знаков используя 4 таблицы по 64 элемента.
Вот это уже интересно. Поидее в виду симметричности в памяти можно хранить лишь часть таблицы 0...45 градусов.
Симметричность — само собой. Алгоритм основан на тождестве

после каждой итерации которого b приближается к нулю. Синус и косинус таким образом считаются одновременно.
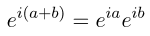
после каждой итерации которого b приближается к нулю. Синус и косинус таким образом считаются одновременно.
Неверно. От 0 до 90.
Нет, верно. При использовании тригонометрических тождеств 45° достаточно.
Т.е. по вашему Sin 15° = Sin 75°?
Вот по модулю Sin 105° = Sin 75°, но это переход через 90°.
Симметричность проходит через квадранты, а по октетам требуются доп. вычисления.
Вот по модулю Sin 105° = Sin 75°, но это переход через 90°.
Симметричность проходит через квадранты, а по октетам требуются доп. вычисления.
По-нашему, sin(45°)=cos(45°), а «тригонометрические тождества» и означают дополнительные вычисления.
Это означает что sin(15) = cos(90 — 15), ось симметрии проходит через угол в 45 градусов. Тоесть это означает что достаточно хранить в памяти таблицу sin и cos для углов 0...45 чтобы вычислять sin и cos таблично для любого угла с дополнительной проверкой условия и одной арифметической операцией.
Да. Ценное замечание. На выходных переделаю SinCos в единую функцию. Будет и быстрее и, что самое важное, точность будет до 15 знака, т.е. весь Double, т.к. до 45° ряд сходится замечательно вплоть до 17 знаков. Спасибо!
Вообще то неверно. По запросу они равны или если вам так угодно тождественны, а вот по ряду и ответу нет. Симметричность идет до PI / 2.0, а это 90°. Нельзя вычислить sin 75°, зная, что это всего лишь cos 15°. По ряду это более 45°, а значит симметричность нужно брать от квадрантов. Мое предыдущее ликование было преждевременным.
Считаем в радианах же, так вот:
Sin 15° — 0,258819045102520
Cos 15° — 0,965925826289068 < — ряд выше 45°
Sin 75° — 0,965925826289068 < — ряд выше 45°
Cos 75° — 0,258819045102520
Так что симметрия должна быть относительно 90°, т.е. по квадрантам.
Считаем в радианах же, так вот:
Sin 15° — 0,258819045102520
Cos 15° — 0,965925826289068 < — ряд выше 45°
Sin 75° — 0,965925826289068 < — ряд выше 45°
Cos 75° — 0,258819045102520
Так что симметрия должна быть относительно 90°, т.е. по квадрантам.
del
Если вывести графики синуса и косинуса одновременно, симметрия относительно 45° легко прослеживается:

И в вашем примере с 75° и 15° симметрия также легко прослеживается:

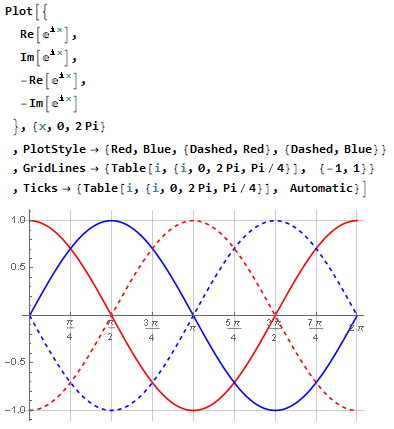
И в вашем примере с 75° и 15° симметрия также легко прослеживается:

А теперь имея только таблицу значений sin от 0 до π/4 посчитайте линейными методами sin(π/3).
А теперь идите в начало ветки и ищите там фразу «тригонометрические тождества» и формулу с комплексной переменной.
Синус и косинус таким образом считаются одновременно.И занимают памяти как одна таблица для sin от 0 до π/2.
Для обеспечения одной и той же точности две таблицы от 0 до pi/4 с синусами и косинусами будут занимать меньше места, чем одна таблица с синусом от 0 до pi/2. Нужно будет только значения из них комплексно перемножить — это два сложения и четыре умножения.
Алгебраически это интересно. Но в Delphi модуль для работы с комплексными числами имеет чёрный ящик ассемблерные вставки; а в прочих вариантах применяется операция деления.
Sin 30° = 1/2, как вашим методом вычислить Sin 60°, который равен Sqrt(3)/2? Они же симметричны относительно 45°?!
Точно так же, как и в прошлый раз — поменять действительную и мнимую часть местами:
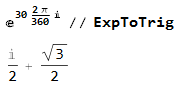
В таблице хранится и синус, и косинус. Если синус и косинус используются для вращения векторов — они обычно считаются от одного и того же угла, поэтому и имеет смысл вычислять их одновременно. И даже если косинус не нужен — на последней стадии вычислений его можно просто не вычислять.
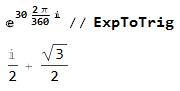
В таблице хранится и синус, и косинус. Если синус и косинус используются для вращения векторов — они обычно считаются от одного и того же угла, поэтому и имеет смысл вычислять их одновременно. И даже если косинус не нужен — на последней стадии вычислений его можно просто не вычислять.
У меня нет таблиц. Ваш метод не подходит.
Мой метод работает быстрее и точнее — поэтому ваш метод мне не подходит тоже. И лично я не вижу принципиальной разницы между выделением памяти под таблицы и выделением памяти под это:
скрытый текст
FSinTab: array[0..7] of Double =
(1.0 / 6.0, //3!
1.0 / 120.0, //5!
1.0 / 5040.0, //7!
1.0 / 362880.0, //9!
1.0 / 39916800.0, //11!
1.0 / 6227020800.0, //13!
1.0 / 1307674368000.0, //15!
1.0 / 355687428096000.0); //17!
(1.0 / 6.0, //3!
1.0 / 120.0, //5!
1.0 / 5040.0, //7!
1.0 / 362880.0, //9!
1.0 / 39916800.0, //11!
1.0 / 6227020800.0, //13!
1.0 / 1307674368000.0, //15!
1.0 / 355687428096000.0); //17!
Или я не понял посыла статьи, или Вас ждет небольшое разочарование, ведь для синуса/косинуса и ряда других тригонометрических функций есть соответствующие инструкции, и наличие их 128-битных вариантов гарантируется при наличии самого простого SSE.
128 бит — это AVX. Его пока поддерживают не все процессоры. SinCos в SIMD вообще отсутствует. Там только квадратный корень есть.
Нет, 128-битные регистры — это атрибут SSE, а AVX — это уже 256 бит. Но насчет хардварной тригонометрии я действительно не прав — детальный гугл показал, что эти функции принадлежат интеловской проприетарной библиотеке.
Вообще если уж используется SSE, то грех умножать скаляры. Можно ведь сложить в вектора и умножать по 2 double'а за раз. И условных переходов у Вас многовато, наверняка они много времени отъедают. Например, в конце, когда нужно поменять знак в зависимости от модуля угла, можно вместо умножения использовать xor с масками от cmpss.
Вообще если уж используется SSE, то грех умножать скаляры. Можно ведь сложить в вектора и умножать по 2 double'а за раз. И условных переходов у Вас многовато, наверняка они много времени отъедают. Например, в конце, когда нужно поменять знак в зависимости от модуля угла, можно вместо умножения использовать xor с масками от cmpss.
Все верно. Эта библиотека по подписке немало стоит. Так что свой вариант выгоднее.
Сравнение (cmp) занимает ровно 1 такт.
Сравнение (cmp) занимает ровно 1 такт.
Почему не встроенные 80-битные регистры FPU?
Вы перепутали Хабр и Gist. Без описания того, что вы делаете и почему, простыня кода не становится статьей.
Это сделано для ускорения вычислений. Там же все написано. Ряд Тейлора прекрасно описан на Вики (раздел Тригонометрические функции): ru.wikipedia.org/wiki/%D0%A0%D1%8F%D0%B4_%D0%A2%D0%B5%D0%B9%D0%BB%D0%BE%D1%80%D0%B0
Лучше чем там, я не распишу.
Лучше чем там, я не распишу.
Готовый предрасчитанный ряд на несколько тысяч значений + линейные аппроксимации будут сильно быстрее. Это если вам именно скорость важна. И не только для тригонометрии годится. Единственно что в этом случае грозит — вымывание ряда из кеша процессора. Без вымывания — просто полет. Когда-то учил ИНС, так делал для функций активации. Песня.
Да, скорость очень важна. При трансформации, например, 10 тысяч объектов это очень заметно.
Ну тогда попробуйте построить в памяти свои «таблицы брадиса». Индекс массива — агрумент (привести к целочисленному дело техники надеюсь), а значения — предрассчитанные sin или cos. Т.к. sin и cos неплохо аппроксимируются даже линейно в итоге должно быть сильно быстрее Тейлора и вообще всего возможного. Можно конечно улучшить точность квадратичной или кубической аппроксимациями, но тогда проигрыш в скорости будет сразу заметен, т.к. простая пропорция это очень быстро, не обогнать.
Кстати этот прием всегда описывался при программировании 3D графики, еще в стародавние времена.
В кубической аппроксимациями тоже есть место для оптимизации. Можно вообще ничего не считать, а просто хранить уже посчитанные 4 коэффициента, а сам кубический полином считать схемой Горнера — будет 3 сложения и 3 умножения.
Можно вообще использовать аппроксимацию рациональным полиномом, а коэффициенты для него считать методом наименьших квадратов.
Можно вообще использовать аппроксимацию рациональным полиномом, а коэффициенты для него считать методом наименьших квадратов.
Да, конечно, все так. Автор просто скорость хотел, вот я ему самое быстрое и посоветовал, две операции или шесть — разница в три раза. Опять-таки кеширование таблицы даже важнее числа операций, если она большая и много коэффициентов, то вылезет из кеша, а это сразу аппаратные уже тормоза. И серьезные, на порядок минимум.
В разрезе скорости МНК не вариант я думаю, но математически — да, можно получить любую нужную точность. Впрочем как и Тейлором.
В разрезе скорости МНК не вариант я думаю, но математически — да, можно получить любую нужную точность. Впрочем как и Тейлором.
У меня готовая таблица с точность 0.001. Скорость выборок более 500 млн в сек.
Это более чем в 10 раз быстрее моего метода и в 12-13 раз быстрее CPU или библиотечного. Но интерполяция значений не требуется из за достатка точности.
Это более чем в 10 раз быстрее моего метода и в 12-13 раз быстрее CPU или библиотечного. Но интерполяция значений не требуется из за достатка точности.
В разрезе скорости МНК не вариантчерез МНК коэффициенты считается заранее и один раз, их не нужно постоянно пересчитывать. Таким образом часто неэлементарные функции считают — вот тут, например.
А ещё рассчитанные значения можно хранить вместе с производными и использовать кубическую, а не линейную интерполяцию.
А delphi разве всё еще где-то актуален??
И вообще всё это ковбойство с ассемблером в наше время ну вот совершенно вот ни к чему, если только ты не компилятор пишешь. В твоём Core-i7 6950X Extreme есть например AVX2 с аппаратным векторизованным sin/cos, который хороший векторизующий компилятор скорее всего сам и врубит, или до которого ты в крайнем случае с минимальным геморроем через какую-нибудь серьезную матбиблиотеку достучишься, например Eigen для плюсов. Скорее всего сразу в разы быстрее c ним станем. Еще на порядок быстрее будет с GPU.
И вообще всё это ковбойство с ассемблером в наше время ну вот совершенно вот ни к чему, если только ты не компилятор пишешь. В твоём Core-i7 6950X Extreme есть например AVX2 с аппаратным векторизованным sin/cos, который хороший векторизующий компилятор скорее всего сам и врубит, или до которого ты в крайнем случае с минимальным геморроем через какую-нибудь серьезную матбиблиотеку достучишься, например Eigen для плюсов. Скорее всего сразу в разы быстрее c ним станем. Еще на порядок быстрее будет с GPU.
Зачем учиться думать самому — компилятор всегда думает за вас.
Вы лучше учитесь думать абстракциями, намного плодотворнее время потратите, может и зарплата вырастет заодно. Компилятор — всего лишь инструмент, абстракция над машинными инструкциями. Да, бывают моменты когда ее нужно приподнять, но будет ли это целесообразно и лучшей тратой вашего времени?
Конкретно в вашем описанном случае я думаю нет — компилятор/матбиблиотека умеют в AVX2, а ваш код нет, шах и мат. Что целесообразнее — курить сейчас Intel Software Developer's Manuals и молиться чтобы ассемблер в delphi поддерживал AVX2, или же просто подключить подходящую библиотеку? А если у пользователя AMD? А если лет через 10 никому н*х этот x86 уже не нужен будет и весь мир на ARM будет сидеть, кто оплатит переписывание вашего куска кода?
Конкретно в вашем описанном случае я думаю нет — компилятор/матбиблиотека умеют в AVX2, а ваш код нет, шах и мат. Что целесообразнее — курить сейчас Intel Software Developer's Manuals и молиться чтобы ассемблер в delphi поддерживал AVX2, или же просто подключить подходящую библиотеку? А если у пользователя AMD? А если лет через 10 никому н*х этот x86 уже не нужен будет и весь мир на ARM будет сидеть, кто оплатит переписывание вашего куска кода?
И вообще всё это ковбойство с ассемблером в наше время ну вот совершенно вот ни к чему,
Потому, что одно из главных качеств в наше время кода — переносимость. А ассемблер не переносим по определению. Тем более в виде вставок в высокоуровневый код
Только вот у меня вопрос к автору — зачем вычислять отдельно cos(x) если
cos(x) = sin(П/2 — x)
Хватит одного синуса
Так у меня косинус выражен через синус. Там есть небольшая почти незаметная вставочка:
if Minus then AMod := Abs(A) — PI90 else AMod := Abs(A) + PI90; Это вся разница между sin и cos.
if Minus then AMod := Abs(A) — PI90 else AMod := Abs(A) + PI90; Это вся разница между sin и cos.
По переносимости: в самых кроссплатформенных С\С++ программах обычно для обеспечения переносимости используют кучу различных кусков кода с условной компиляцией под разные компиляторы\платформы.
В SIMD (на уровне инструкций) есть только SQRT. Delphi прекрасная среда, не уступающая по своим возможностям VS.
Лет 15-20 назад, да, прикольная была система, но поезд давно ушел. Кому она сейчас нужна, кроме тех у кого горы legacy паскаля в проекте? Геймдев чуть менее чем на 100% сидит на плюсах. UI/RAD почти всем сейчас нужен через веб, там рулит javascript в т.ч. уже и на бэкэнде (nodejs), время настольных приложений постепенно уходит
>Delphi прекрасная среда, не уступающая по своим возможностям VS
Джуновский такой комментарий как будто вы всю жизнь ни на чем кроме делфи не сидели. Как по мне так оба просто инструменты, одни из многих, для достижения цели проекта, и не факт что лучшие
>Delphi прекрасная среда, не уступающая по своим возможностям VS
Джуновский такой комментарий как будто вы всю жизнь ни на чем кроме делфи не сидели. Как по мне так оба просто инструменты, одни из многих, для достижения цели проекта, и не факт что лучшие
Во-первых, статья не совсем про Delphi, она про асмовский код, который запросто можно использовать и в C++. Во-вторых, Delphi — хоть и не бурно развивающаяся, но очень даже неплохая система, с помощью которой делать UI сильно приятнее, чем с помощью, прости Господи, жабаскрипта. Ну и в-третьих, а чисто для развлечения программировать запрещено, все должно быть обусловлено положением на рынке?
Как по мне так оба просто инструменты, одни из многих, для достижения цели проекта, и не факт что лучшиеPM-овский такой комментарий.
Поезд все там же, просто с первого пути перевели на 7-й, но не в тупик.
Продукт развивается и вполне успешно.
Продукт развивается и вполне успешно.
Ради интереса сравните скорость обычных функций из модуля Math при компиляции приложения в 64-битном режиме, т.к. в 64-битном режиме Delphi использует SSE.
За основу для вычислений взял разложение по ряду Тейлора.
Почему? Почему не CORDIC, или если так уж хочется ряды, то почему не Чебышев?
Sign up to leave a comment.
Быстрый Sin и Cos на встроенном ASM для Delphi