Comments 15
Очень круто, спасибо.
Очень интересно, спасибо) а главное — математики самый минимум;)
А на последнем графике зависимость ошибки от времени для тренировочного множества?
если да, то какая ошибка на тестовой выборке?
скажем, если на тренировочную выборку чуть-чуть нашуметь, будет ли сеть достоверно воспроизводить модель? как мне кажется, с шумом все достоинства вторых производных сойдут на нет.
если да, то какая ошибка на тестовой выборке?
скажем, если на тренировочную выборку чуть-чуть нашуметь, будет ли сеть достоверно воспроизводить модель? как мне кажется, с шумом все достоинства вторых производных сойдут на нет.
Много красивой математики. Безусловный плюс в карму, но вопрос, а не кажется ли вам, что отсутствие реализаций этого метода не случайно?
1) Вторую производную быстрее получить буквально. Посчитав первую производную, а потом сдвинув вдоль линии градиента и предположив, что всё малое отличие от первой производной относится ко второй.
2) Вторую производную вдоль одной линии, а не всю эту адскую матрица можно при желании посчитать аналитически. Я когда-то это проделал, вычислительного времени это занимает всего в три раза больше, чем вычисление первой производной. Однако занятие изрядно бессмысленное смотри пункт первый.
3) Метод имеет смысл только если предполагать функцию ошибки не только слабо наклонной, но ещё и не содержащей множества локальных минимумов. Потому что любой алгоритм со вторыми производными вязнет в локальных минимумах намертво. А гладкая функция ошибки, на сколько я успел понять, большая редкость.
В свете этого либо я умею получать вторые производные, но не понимаю чего-то важного, либо вы, как и когда-то, вложили кучу интеллектуальных усилий в дело вместо того чтобы взять задачу грубой рассчётной силой в три раза быстрее. Ради красоты алгоритма или потому что ещё по чему. Я, например, про взять вторую производную напрямую тупо не догадался. :((((
1) Вторую производную быстрее получить буквально. Посчитав первую производную, а потом сдвинув вдоль линии градиента и предположив, что всё малое отличие от первой производной относится ко второй.
2) Вторую производную вдоль одной линии, а не всю эту адскую матрица можно при желании посчитать аналитически. Я когда-то это проделал, вычислительного времени это занимает всего в три раза больше, чем вычисление первой производной. Однако занятие изрядно бессмысленное смотри пункт первый.
3) Метод имеет смысл только если предполагать функцию ошибки не только слабо наклонной, но ещё и не содержащей множества локальных минимумов. Потому что любой алгоритм со вторыми производными вязнет в локальных минимумах намертво. А гладкая функция ошибки, на сколько я успел понять, большая редкость.
В свете этого либо я умею получать вторые производные, но не понимаю чего-то важного, либо вы, как и когда-то, вложили кучу интеллектуальных усилий в дело вместо того чтобы взять задачу грубой рассчётной силой в три раза быстрее. Ради красоты алгоритма или потому что ещё по чему. Я, например, про взять вторую производную напрямую тупо не догадался. :((((
Много красивой математики. Безусловный плюс в карму, но вопрос, а не кажется ли вам, что отсутствие реализаций этого метода не случайно?
Спасибо!
Думаю, что реализации этого метода «из коробки» в TensorFlow нет, так как TensorFlow обычно использую для других задач: работа с изображением, звуком, с натуральным языком. В этих случаях количество параметров исчисляется сотнями тысяч. Методам второго порядка там делать нечего.
В Matlab реализация есть, и даже предлагается как алгоритм первого выбора: "trainlm is often the fastest backpropagation algorithm in the toolbox, and is highly recommended as a first-choice supervised algorithm, although it does require more memory than other algorithms." (Levenberg-Marquardt backpropagation — MATLAB trainlm). Matlab используют инженеры и учёные, у них маленькие нейронные сети для аппроксимации сложных функций, похоже, встречаются чаще.
В свете этого либо я умею получать вторые производные, но не понимаю чего-то важного, либо вы, как и когда-то, вложили кучу интеллектуальных усилий в дело вместо того чтобы взять задачу грубой рассчётной силой в три раза быстрее. Ради красоты алгоритма или потому что ещё по чему.
Мне просто было интересно. А команда моего друга-нефтяника перепробовала кучу подходов, но сработал только этот. С остальными методами они просто не смогли дождаться приемлемой точности, несмотря на очень хорошее «железо». У них довольно жесткое условие было: либо добиваются требуемой точности, либо решение будет никому не нужно.
Спасибо огромное! Очень интересно и изложение захватывающее.
Пожалуйста, продолжайте!
Пожалуйста, продолжайте!
потрясающая статья. Спасибо за ваш труд. Отличный баланс математики и её практического применения
А как можно рисовать в матлабе такую визуализацию архитектуры сети?
Честно говоря, не работал с Matlab. Просто довольно часто на форумах встречал скриншоты из этой системы. Прочитать, как визуализировать, можно, например, здесь:
blogs.mathworks.com/loren/2015/08/04/artificial-neural-networks-for-beginners По ссылке есть визуализация для классификации. По-моему, выглядит очень хорошо и понятно:
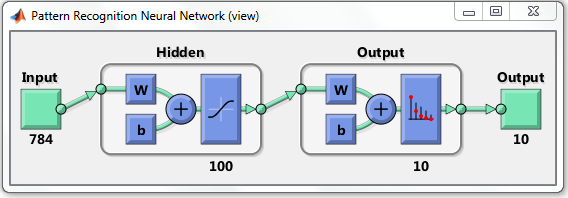
blogs.mathworks.com/loren/2015/08/04/artificial-neural-networks-for-beginners По ссылке есть визуализация для классификации. По-моему, выглядит очень хорошо и понятно:
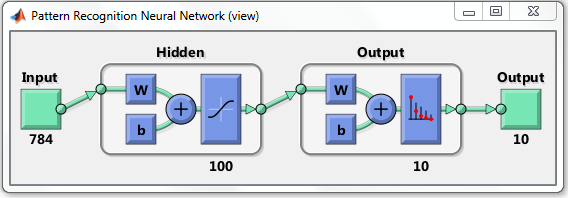
Отвечу. После того, как вы создали каким-то образом сеть, функция view(net) вам нарисует такую картинку.
Пример из доки матлаба:
[x,t] = iris_dataset;
net = patternnet;
net = configure(net,x,t);
view(net)Люто плюсую :) Хорошо. Очень хорошо.
А скажите, пожалуйста, каков мотив для выбора именно трехслойки с такими количествами нейронов? Почему не однослойка? Ведь любую функцию (а в данном случае аппроксимировалась функция), можно аппроксимировать однослойкой?
Любую сеть можно апроксимировать однослойкой, но в этой теореме ничего не сказано про размеры этой однослойки. Грубо говоря вы можете одного и того же результата можете добиться однослойкой на 10000 нейронов в слое и год обучения, или двухслойкой на 500 нейронов, или трёхслойкой на 30.
Всё зависит от задачи. Если задача — запомнить огромное случайное число — лучше всего подойдёт однослойка, если задача имеет возможности для вычленения обобщающего знания — ваш выбор — глубокое обучение и много слоёв. Чем больше уровней обобщения в целевой функции можно предположить, тем больше слоёв.
Всё зависит от задачи. Если задача — запомнить огромное случайное число — лучше всего подойдёт однослойка, если задача имеет возможности для вычленения обобщающего знания — ваш выбор — глубокое обучение и много слоёв. Чем больше уровней обобщения в целевой функции можно предположить, тем больше слоёв.
Уже ответили, но немного добавлю.
В статье этот выбор не совсем «обоснованный». Надо было протестировать реализацию (поискать ошибки в коде), попробовал разные варианты, выбрал тот, где шаг считается не очень долго, а значение функции потерь уменьшается сильно. Для реальной работы так делать, конечно, не стоит. Надо полноценно проверять разные архитектуры кросс-валидацией, и только потом осознанно выбирать наиболее подходящую.
Это очень интересный вопрос. С одной стороны, есть универсальная теорема аппроксимации, которая утверждает, что при достаточном количестве нейронов однослойный перцептрон может аппроксимировать любую непрерывную функцию с любой точностью при удачном подборе параметров. С другой стороны, эта теорема не отвечает на 2 важных вопроса:
1. Достаточно — это сколько? И может ли оказаться, что для многослойной сети достаточное количество будет гораздо меньше, чем для однослойной?
2. Как удачно подобрать параметры, когда количество нейронов достаточное?
Пока ответов на эти вопросы нет, и зачастую ML похоже на алхимию: "попробуйте нейронную сеть с 1, 2, 3, 4 слоями, с количеством нейронов 1X-4X, где X размерность входного вектора, кросс-валидацией выберите подходящую архитектуру". Вместо ответов есть опыт-наблюдения:
А скажите, пожалуйста, каков мотив для выбора именно трехслойки с такими количествами нейронов?
В статье этот выбор не совсем «обоснованный». Надо было протестировать реализацию (поискать ошибки в коде), попробовал разные варианты, выбрал тот, где шаг считается не очень долго, а значение функции потерь уменьшается сильно. Для реальной работы так делать, конечно, не стоит. Надо полноценно проверять разные архитектуры кросс-валидацией, и только потом осознанно выбирать наиболее подходящую.
Почему не однослойка? Ведь любую функцию (а в данном случае аппроксимировалась функция), можно аппроксимировать однослойкой?
Это очень интересный вопрос. С одной стороны, есть универсальная теорема аппроксимации, которая утверждает, что при достаточном количестве нейронов однослойный перцептрон может аппроксимировать любую непрерывную функцию с любой точностью при удачном подборе параметров. С другой стороны, эта теорема не отвечает на 2 важных вопроса:
1. Достаточно — это сколько? И может ли оказаться, что для многослойной сети достаточное количество будет гораздо меньше, чем для однослойной?
2. Как удачно подобрать параметры, когда количество нейронов достаточное?
Пока ответов на эти вопросы нет, и зачастую ML похоже на алхимию: "попробуйте нейронную сеть с 1, 2, 3, 4 слоями, с количеством нейронов 1X-4X, где X размерность входного вектора, кросс-валидацией выберите подходящую архитектуру". Вместо ответов есть опыт-наблюдения:
- Зачастую многослойной сетью получается добиться лучшего результата меньшим количеством параметров. Где-то слышал, что приводился пример функции, которая аппроксимировалась конечной сетью с двумя слоями, но однослойная требовала бесконечного числа параметров. Возможно, я неправильно понял.
- Обучать многослойную сеть проще. Можно привести аналогию с ассемблером. Теоретически, любую программу можно написать на ассемблере. Практически, это очень сложно. Но как только написана программа на С, перевести в ассемблер её можно запросто. Где-то слышал, что учёные проделывали схожее для нейронных сетей — подбирали параметры для многослойной, и на базе этого вычисляли параметры для однослойной сети. Но подобрать параметры сразу для однослойной не получалось.
Sign up to leave a comment.
Реализация алгоритма Левенберга-Марквардта для оптимизации нейронных сетей на TensorFlow