Comments 284
Интерпретатор бэйсика на PHP?
Почему Вы считаете, что он будет работать со скоростью PHP7?
Компилятор языка — одна функция на 500+ строк
Как минимум медленнее на накладные расходы.
разница в скорости исполнения оказалась незначительная ( не смог даже устойчиво вычислить процент потерь, видимо менее 1% )
Как он в принципе может работать быстрее чем код, изначально написанный на этом языке?
Простейший код — не может.
А сложный — вполне, если транслятор еще и оптимизатором является.
stackoverflow.com/questions/20929783/how-is-dart2js-code-faster-than-javascript
dart2js is able to perform optimizations that would not normally be manually added in JavaScript code.
В абзаце первом сказано, выделю главную мысль:
not normally be manually added
Это английское слово означает «вручную». То есть сверх того, что автоматически способен оптимизировать V8, так что V8 тут вообще постольку-поскольку.
Абзац второй из текста по приведенной мною ссылке:
Of course, you can run automated tools on JavaScript source to generate better JavaScript as well, this is what the Closure compiler does
В этом абзаце говорится про еще один вариант с хорошей оптимизацией (опять таки быстрее обычного «ручного» JavaScript, и речь даже о другом языке и о другой цепочке, которую нужно пройти исходному коду чтобы быть оптимизированным. То есть Dart тут ничего нового не открыл. Возможность получать более оптимизированный JS-код существует и помимо Dart.
Ну и последний третий абзац:
Technically, you can manually achieve the same speed with handwritten JavaScript if you know all the tricks.
Здесь написано, что:
«вы можете и достичь той же (высокой) скорости, написав соответствующий код на JavaScript вручную, если вы знаете (и будете) использовать все трюки (и оптимизации)» — в скобках приведено мое пояснение.
Повторяю еще раз, но уже разжевываю:
Я писал:
Простейший код — не может.
Жую: небольшой объем кода или легко оптимизируется человеком или вы не заметите разницу в производительности по причине небольшого объема кода и небольшого же количества неоптимизированных мест в нем.
Я писал:
А сложный — вполне, если транслятор еще и оптимизатором является.
Жую: человеку не по силам (или попросту лениво) оптимизировать большие объемы кода. Поэтому сложный код как правило не сильно-то и оптимизируется. Более того, напротив, в сложных проектах зачастую применяются фреймворки и библиотеки, которые только дальше абстрагируют нас (что затрудняет ручную оптимизацию) и содержат дополнительные исполняемые инструкции. Уже много лет как дешевле купить более мощный компьютер, чем заплатить программисту за дополнительную оптимизацию. Но, в принципе, вам никто не мешает вручную делать быстрый код такого же качества как выдают автоматические инструменты dart2js и GWT/Closure. Другой вопрос — а согласятся ли это оплачивать ваш заказчик/работодатель, потому как вручную = дорого на сложных проектах.
У меня другой вопрос, почему движок Javascript в браузере не может выполнять те же самые оптимизации с исходным кодом?
Сделайте. Ведь и Chromium и Firefox — открытые проекты.
Вангую:
Требуется довольно длительная подготовки скачиваемого с сайтов JS (компиляции/оптимизации) прежде чем получим готовый результат и сможем отобразить страницу. Время отображения страницы все же критично.
Когда-нибудь и до этого руки дойдут у разработчиков.
Это не точная информация, «где-то видел, где-то слышал». В любом случае подобная ленивая деоптимизация существует: docs.google.com/document/d/1ELgd71B6iBaU6UmZ_lvwxf_OrYYnv0e4nuzZpK05-pg/edit
P.S. Не могу не подметить иронию на счёт накидывания JS кода на TurboFan (что по ссылке выше) %)
а крупных проектов пока нет, может первым будете?
Зачем пишут новые языки программирования? Денег это точно не приносит. Код неприятный и очень сложный. Перспективы туманные, поддержки никакой.
Еще и мизерное количество языков программирования разработанных у нас.
Мне захотелось сделать некоммерческий проект на грани своих возможностей и расширить свои границы. Кроме того, после этого проекта я понял что смогу реализовать практически любой синтаксис или языковую конструкцию. Но есть ограничение — нужно на несколько месяцев погрузится в вязание парсеров, что также приятно как ежедневный визит к зубному на это время.
Правильно, автор. Все мы качаемся на пет-прожектах. Но теперь вам нужно ещё прокачаться и переписать код в приличном виде, чтобы его стали понимать не только вы и у проекта могли появиться ещё контрибьюторы.
А вот про обучение кого-либо веб-программированию — это вы лучше забудьте пока. Всё-таки вам самому ещё учиться и учиться, а студентам желательно иметь дело со 100%-работающими инструментами. Ну и про бейсик ниже уже сказали :)
Вроде бы в XXI веке парсинг как раз более-менее тривиальная часть (ну кроме излишне заковыристых грамматик), главное – семантика, особенно если она существенно отличается от целевого языка.
— Это всё-таки не компилятор, а транслятор подмножества BASIC в PHP. Ещё точнее — шаблонизатор.
— Парсер, токенайзер, регулярные выражения и вот это всё-всё-всё в одной godlike функции — это осознанное решение или просто так получилось?
Честно, я не вижу где это можно применить, кроме уроков информатики вместо знаменитого «исполнитель черепашка»
То, что у вас получилось — это не компилятор, а процедурный препроцессор. Компилятором можно назвать две вещи:
1) Комплексную систему, которая в конечном варианте возвращает набор команд для процессора. В современном мире компилятор обычно делится на фронтэнд (лексер, парсер, генератор ir) и бекенд (оптимизация ir, генерация конечного кода).
2) Код, который переводит набор грамматических правил в код парсера (но это называется «компилятор компиляторов», а не просто компилятор).
3+) Может ещё какой вариант, который я не учёл. Но в сейчас это не тот случай точно.
По коду:
Он плохой. Писать так в 2018ом году — печально. Если пожелаете, то могу раскрыть эту тему в комментариях подробнее. Сейчас останавливаться на этом не хочется, т.к. ошибок очень много.
Далее:
Имеется специальный отладочный режим позволяющий увидеть все окружение скрипта и ошибки, чего очень не хватает в PHP и решается с помощью вставок логирования.
1) xdebug
2) phpdbg
3) в качестве киллертулзы: vld
Компилятор достаточно гибок, можно менять ключевые слова местами или пропускать их внутри команд, так как параметры команд разбиваются ключевыми словами, а не идут через запятую, например:
Это не гибкость «компилятора» всё же, а просто реализация грамматики.
В целом, по коду прослеживается зачаточная логика парсера, но он довольно примитивный и не поддерживаемый. Я прекрасно представляю сколько времени тратится на реализацию подобных вещей, но всё же не стоило его так впустую тратить, когда есть куча готовых инструментов.
Что предлагаю:
1) Вам стоит посмотреть хотя бы в сторону EBNF грамматики. Я, конечно, не супер-пупер программист, но могу в качестве варианта предложить вам воспользоваться моей реализацией (вообще это форк, но если посмотреть на код, то он таким уже давно не является) нисходящей LL(k) грамматики и компилятором оной: github.com/railt/compiler Ну или оригиналом: github.com/hoaproject/Compiler
2) Посмотреть в сторону PSR стандартов (ну и в целом: getjump.github.io/ru-php-the-right-way) и переписать код, учитывая оные (обратите внимание, что в PSR-1 есть пункт с «побочными эффектами», он довольно важен, т.к. ваш проект сильно страдает этой проблемой, что мешает использовать его даже «фор-фан»).
Я программировал тогда по фану, и т.к. разработка языка программирования напоминает вязание и нужно было связать вместе целую кучу разных парсеров, поэтому делал так как мне удобно. Была вероятность вначале что у меня ничего не получится, пока не заработал прототип.
Под консоль он пока не запускается, нужна доработка кода приема параметров.
Но некоторую мысль вы уловили, отсутствие некоторых возможностей, повышенная сложность и ошибки

Всё это из-за того, что положили болт на качество и писали в стиле 90х годов.
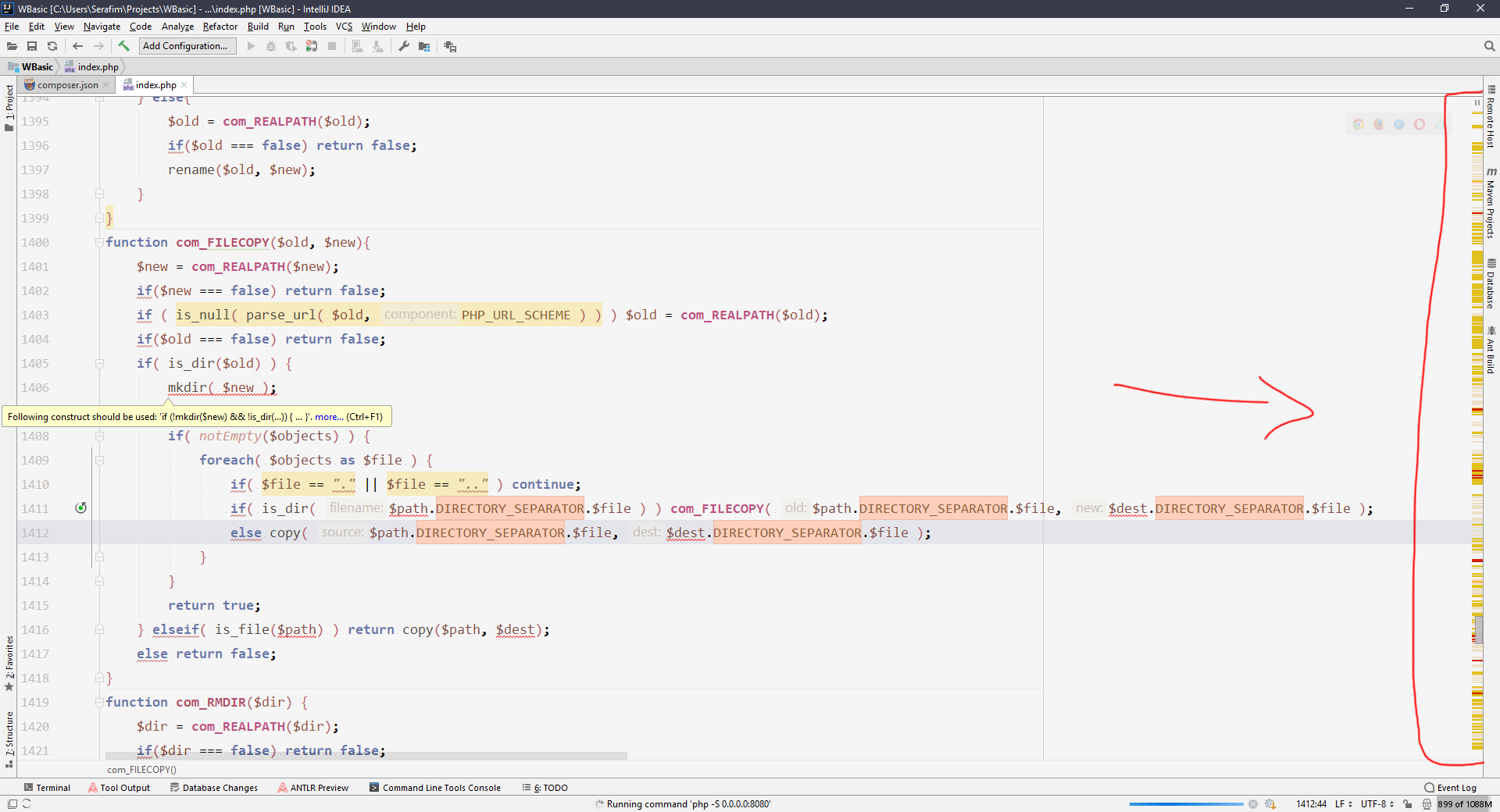
Каждая жёлтая и красная строчка — это потенциальная или 100%-ая ошибка. Каждая бледно-жёлтая — это неоптимальный или потенциально ошибочный код (ну и грамматические ошибки или ошибки кодстайла). А если прогнать этот код через профилировщик, то вообще можно вешаться можно, подозреваю.
на самом деле все не так уж и плохо работает, как вам кажется. можете вставлять любой код из примеров документации он рабочий.
самая большая проблема у меня не написание кода, а отсутствие поддержки сообществом. пока я не знаю как решить эту проблему.
P.S. Сейчас с вашей стороны это лишь звучит как оправдание. При этом оно довольно слабое, т.к. пользоваться проектом тоже неудобно. Точнее не так. Ей удобно пользоваться только в том варианте, который вы предложили (index.bas и вперёд), а любой другой вариант не предусмотрен и более того — вреден, т.к. может поломать уже существующие решения (см. «побочные эффекты», о чём я упоминал выше).
Я думал больше будет.
Спасибо за ваши комментарии по коду, но не уверен что смогу его кардинально переписать, у меня будет ломка психики.
Вот этот коммит, например, добавляет поддержку оператора PRINT и условных выражений (IF/IF ELSE): github.com/SerafimArts/WBasic/commit/9f2163b84eb3325b5e48f54808bf9001485be6b9 (т.е. расширять всё элементарно)
Возможно это вам поможет.
1) Всё что надо сделать, чтобы запустить — это написать пару строк: github.com/SerafimArts/WBasic/blob/master/example.php Т.е. для того, чтобы реализовать вашу логику с index.bas достаточно добавить 3 строчки кода с is_file + eval. Причём стоит заметить, что я никаких серьёзных ошибок в коде не допускал. Т.е. можно писать и удобно и вполне примелемого качества.
2) Для того, чтобы реализовать всё это с нуля потребовался час времени (10:26 ваш комментарий и 11:32 мой).
3) Заметьте, что я писал код с полным соответствием PSR-12 и докблоками. Это не тяжело, но зато потом относительно легко читать.
4) Анализ ошибок. Это одна из самых важных вещей в парсинге. В вашем варианте конструкция:
IF A = 23 THEN
PRINT "YES"
ELSE
REM ничего не делаем =)
Вернёт:
Parse error: syntax error, unexpected ')' in ...\index.php(85): eval()'d code on line 1
В моём:
Railt\Parser\Exception\UnexpectedTokenException: Unexpected token «ELSE» (T_OP_ELSE) in ...\example.bas on line 4
Подобные подробные ошибки достигаются за счёт анализа грамматики (как и логика самого парсинга). В данном случае IF требует обязательное закрытие своего тела: github.com/SerafimArts/WBasic/blob/master/resources/grammar.pp2#L85-L86 А так, как этого не было сделано, то берётся последняя успешная продукция (т.е. ELSE с необязательным телом) и указывается на то, что с ним что-то не так с ссылкой на линию и файл, в котором обнаружена ошибка.
Ну, конечно, могу предложить посмотреть на исходники PHP, там для лексера используется re2c, а для парсера bison и отказаться от использования этого языка, т.к. он слишком много зависимостей с собой тащит (там в сумме больше 30+ одно ядро).
и я знаю что есть готовые библиотеки лексеров и парсеров, с которыми мне пришлось бы воевать, т.к. я не контролирую их поведение, и как только выйду за их границы мне придется их модифицировать или подстраиваться под них, что меня не устраивает, для чего это? блок компиляции всего 500 строк, и он полностью справляется со всеми конструкциями.
в нем есть преимущества
Это какие же?
считайте это стилем русской инженерной школы — быстро, дешево, с большими допусками, но надежно и работает.
для меня — я смог реализовать данный проект от идеи до релиза. у многих это не получается.
Это не преимущество вашего подхода, это вы просто иначе не умеете.
у многих это не получается.
А у многих — получается, причем на основе той методики, которую вы отвергаете.
считайте это стилем русской инженерной школы
Нет, не буду. К русской инженерной школе ваше поделие отношения не имеет.
надежно и работает.
Это тоже не про ваш язык.
Странно слышать какие-то утверждения про инженерную школу от человека, который, очевидно, сам инженером не является, даже на уровне самоучки. Отказ от использования готовых, проверенных временем инструментов, от использования в разработке общепринятых подходов программной, на минутку, инженерии, попахивает чем-то очень далёким от инженерного подхода к решению задачи.
«Дешёво»?
При просмотре кода становится очевидно, что это что-то не дешёвое. И главная причина — низкое качество самого кода. Например, функция com_compile. Это кошмар на 500+ строк с множеством вложенных ветвлений. Написать такую функцию один раз может быть и «просто и дёшево», в чём я сомневаюсь. Но поддержка подобного кода обойдётся во много раз дороже, чем поддержка любого из предложенных в комментариях «плохого и сложного» решения.
«Надёжно и работает»?
Работает — может быть. Но работает, очевидно, как-то. Явно не надёжно. И причина этого в низком качестве кода, которое было Вам продемонстрировано на примере скриншота, где большая часть кода подсвечена, как содержащая потенциальные ошибки. Профессиональные разработчики стремятся к минимизации количества предупреждений от инструментов анализа, в идеале — к полному отсутствию таких предупреждений.
в итоге попробовал написать свою версию языка бейсик под веб. я не отдел майкрософта, мне пришлось писать и документацию по языку, и программировать лексические конструкции которые отсутствуют например в визуал бейсике. Например посмотрите раздел работы с массивами, он лучше чем сделано во многих языках.
Например посмотрите раздел работы с массивами, он лучше чем сделано во многих языках.
Это тот, в котором перемешаны массивы и словари (а про множества я даже спрашивать не буду)?
И чем он лучше, чем работа с коллекциями в Python (не говоря о numpy) или .net? В вашем прекрасном языке можно написать [1, 2, 3] ** 2 и получить [1, 4, 9]? Можно писать итераторы? А как насчет генераторов?
Например посмотрите раздел работы с массивами, он лучше чем сделано во многих языках.
Как в одну строчку получить все элементы (строкового) массива, начинающиеся с qwe и длиной более 5 символов?
и в нем есть преимущества
с моей точки зрения предложенный стиль программирования через чур громоздкий и некомфортный
Да ладно? Это вам методы по 3 строчки некомфортны или корутины?
Ещё раз, вот это «легковесный» и «понятный»:
github.com/vindozo/wbasic/blob/master/wbasic.php
А вот это «громоздкий» и «некомфортный»:
github.com/SerafimArts/WBasic/blob/master/src/Builder.php
? Я думаю, что это не так.
и я знаю что есть готовые библиотеки лексеров и парсеров, с которыми мне пришлось бы воевать
Да, прошу заметить, что это самопальная библиотека. Она написана мной для себя же в процессе обучения «написания своих языков», т.е. примерно за год штудирования непосредственной теории и практики. Никто не мешал вам сделать так же. Я просто поделился своим опытом, т.к. через ваш вариант проходил ещё в самом начале «пути».
считайте это стилем русской инженерной школы — быстро, дешево, с большими допусками, но надежно и работает.
Это только ваш стиль. Пожалуйста, не обобщайте и не приобщайте сюда сообщество.
после того как вы год потратили на штудирование и написание свой библиотеки, в какие языки ее использовали для разработки?
Для GraphQL SDL (диалекта): github.com/railt/railt. Проекту уже полтора года и до сих пор в мастере. Начинал именно для этого языка. Одна из относительно стабильных версий, например, используется в продакшене на некоторых проектах группы компаний Rambler, что, для себя я считаю небольшим достижением для «пет-проекта».
И да, силы ещё остались, хотя до сих пор не могу нормально стабилизировать виртуальную машину. Раз 10 или 15 переписывал.
А если есть — пользователи не могут работать.
> все в мире сбалансировано и правит всем закон равновесия.
Какими-то высокодуховными девами из фконтакта повеяло. Специально делать такой панк-код (по аналогии с грязным звуком) — это для какой-то особенной тусовки, здесь таким не увлекаются.
> отсутствие поддержки сообществом
Так её и не будет, поддерживать мусорный код никто не захочет — его можно только костылить, но костыли потонут внутри.
если в целом реакция на проект будет положительна, то почему бы не исправить их в версии 1.2, ну а если нет, то нет смысла продолжать.
а) идею проекта
б) его реализацию
Вы надеетесь, что идея настолько хороша, что потом можно будет задним числом исправить реализацию. Но это не совсем так, поэтому разумным шагом была бы разработка документации, вычитка и чистка кода, приведение к единому стилю и выпуск версии 1.2 уже не для себя, а для гипотетического сообщества. Вам надо вывести его с уровня «домашний эксперимент» на «интересный проект, может кому-то пригодится».
Мало того, что там куча ошибок, мало того, что код совершенно неподдерживаемый (потому и сообщества нет — сюрприз!), так вы еще и настолько яркая и творческая личность, что стандарты — это не для вас, конечно.
Вперед и с песней! Воспринимайте критику в штыки, занимайтесь производством говнокода, а то мало в PHP кидаются тухлыми помидорами, надо бы еще добавить! Но только не удивляйтесь отсутствию сообщества. С такими подходами работать с вами на добровольных началах никто не захочет.
А как отличить "полезную" концепцию от "вредной" изучая только "полезные"?
Вот смотрите. При вас кто-то обжег руку, схватившись, к примеру, за паяльник. Обязательно ли вам повторять этот неудачный опыт ;)?
В ужасе выброшу паяльники и начну паять исключительно феном :)))
Если уж паять начал то обожжешся рано или поздно. С опытом только вероятность/площадь ожога меньше становится.
Basic был вторым языком, который я учил (в школе еще, после факультативно изученного С). И вы знаете, лучше б я за паяльник схватился… :)
О да, у меня изучение паскаля после асма вызывало аналогичные эмоции. Однако никто ж не заставляет кодить на "неудачных" концепциях, а вот знать их (хотя бы поверхностно) весьма полезно. А как говорится лучший способ изучить ЯП — начать кодить на нем.
Мне показалось что он отражает мировозрение англоговорящих программистов. Возможно что если бы с нуля велась разработка под русский менталитет, он бы был более свободен и подвижен. Поэтому я реализовал возможность менять ключевые слова местами или пропускать их внутри команд. Но это только первая ласточка.
На самом деле я пытался сформулировать язык следующего поколения под русский менталитет, но если я не смогу решить проблему (а нахрена?) на текущем проекте то последующих проектов видимо не будет в этом направлении. И с этим столкнутся все последующие русские разработчики языков программирования.
Да Brainf*ck имеет более чистый синтаксис, простите. Эти запятые бесконечные в вызовах, к примеру отрисовки окружности… Как вспомню, так вздрогну.
Пытаюсь вспомнить… что же здесь ужасного? Вспомним, что в приницпе, никто не заставляет использовать встроенные графические библиотеки — верно? Пожалуйста, используйте сторонние, вызывайте их конвенционально через call DrawCircle(.......).
А в простом виде, если не рисовать дуги и пр. ничего там ужасного нет:
CIRCLE (320, 100), 200
Одно время была эпоха Rails, когда разработчики писали на нём не зная вообще о языке ничего. Сейчас такая же эпоха с Laravel, где каждый второй не знает даже основ PHP (достаточно открыть тостер и убедиться самому). Эти ребята как раз и начинали с инструментов и добром это не всегда оканчивалось, увы.
Выбор языка (и других инструментов, сервисов и систем) зависит от проекта. И как сделать этот выбор — тоже отдельный разговор.
Разумеется, прежде всего должно быть высшее образование по профильной области.
А вот это отдельный разговор, и я бы даже сказал холивар. Я придерживаюсь позиции «желания учиться», вместо «наличия корочки». И судя по опыту собеседований, вполне себе резонно придерживаюсь.
Расскажу историю из жизни.
В одной большой-пребольшой, международной-премеждународной компании компании была команда русских разработчиков. Одна из многих, ясен пень. И были в той команде все с высшим образованием, да только не все — с профильным.
А когда проект подошел к концу и стали подбивать бабки, выяснилось, что top performers, которые, собственно, и вытянули весь проект на себе — это почти исключительно люди именно с непрофильным высшим. Плюс единственная в команде девушка (она, как ни странно, с профильным). Остальные в течение нескольких лет радостно били баклуши и писали отчеты, делая только необходимый минимум.
Здесь самое время для возгласа «значит, менеджмент был херовый!». Заранее согласен. Ибо компания, как я уже писал, большая и международная.
Это, конечно, ничего не значащий чей-то личный опыт.
Знаете, иногда из непрофильных вузов приходят такие на собеседования, которые и азов то не знают. Вот спросишь у них про нормализацию базы данных — молчат. Ставить индекс на поле пол (м/ж) — говорят да, если по этому полю идет поиск. Про составной индекс, конечно, не знают. Ну и так далее.
Ведь далеко не все способны на самообразование, и еще программа нужна, чтобы самое важное не пропустить. Как там у Козьмы Пруткова: " Многие вещи нам непонятны не потому, что наши понятия слабы; но потому, что сии вещи не входят в круг наших понятий." А в профильном вузе все-таки изучают самые необходимые предметы. Другое дело, что не все ВУЗ-ы одинаково полезны, и не все студенты одинаково прилежны.
Знаете, иногда из непрофильных вузов приходят такие на собеседования, которые и азов то не знают.
А иногда и из профильных вузов такие приходят.
Знаете, иногда из непрофильных вузов приходят такие на собеседования, которые и азов то не знают. Вот спросишь у них про нормализацию базы данных — молчат. Ставить индекс на поле пол (м/ж) — говорят да, если по этому полю идет поиск. Про составной индекс, конечно, не знают. Ну и так далее.
Но не случается с теми, кто вместо того, чтобы тратить 5 лет непонятно на что получал опыт и дорос до миддла/сеньора (за 5 лет это более чем возможно).
Так что это скорее аргумент в пользу тех, кто 5 лет работал, а не тех, кто закончил ВУЗ имея крайне посредственные знания в актуальных технологиях (а скорее всего их просто не имея).
Если же вы обучаетесь на работе, то получаете узкое образование в рамках той работы, которую выполняете.
Разумеется, прежде всего должно быть высшее образование по профильной области.
Муа-ха-ха. Ну то есть мяу. Я бы еще понял, если бы вы сказали "систематическое" вместо "высшее", но в такой формулировке это просто не выдерживает критики. Особенно на фоне того, что крупные компании перестают требовать дипломы (вообще дипломы, не только профильные).
Я рассматриваю ВУЗ как некий фильтр. Если кандидат его прошел, это говорит о его способности доводить дело до конца, и вообще о его способностях. А если не сумел — это настораживающий признак.
у себя мы наблюдали, что кандидаты, который закончили ВУЗ, показывали гораздо более высокие результаты
Любой ВУЗ или профильный ВУЗ?
(про методику измерения даже спрашивать не буду)
А те, кто не сумел его закончить, не смогли у нас работать.
Вы не делаете разделения между "не смог закончить ВУЗ", "не захотел заканчивать ВУЗ" и "не стал поступать в ВУЗ"?
Если кандидат его прошел, это говорит о его способности доводить дело до конца, и вообще о его способностях
Угу, иногда — способности доводить до конца ненужное дело (иными словами, подверженность sunken costs fallacy).
Различий не делаю, для меня ВУЗ — фильтр. Прошел — хорошо, не прошел — настораживает.
Что же касается доведения до конца ненужного дела, то это на совести руководства, которое выдает задание и контролирует, как оно выполняется.
Если же сам себе дело придумал — то сам и в ответе.
Вы сами понимаете, что в профильном ВУЗе можно получить более полное образование по теме.
Ключевое слово здесь "можно". А можно и не получить. А можно самостоятельно получить "более полное образование по теме". Когда к вам приходит разработчик с десятилетним опытом, возможно, его опыт актуальнее любого ВУЗа.
Так вернемся к вашему "у себя мы наблюдали" — есть статистически значимая разница между людьми с профильным высшим образованием и людьми с любым другим высшим образованием?
Что же касается доведения до конца ненужного дела, то это на совести руководства, которое выдает задание и контролирует, как оно выполняется.
Именно так. И если руководство "выдало" некорректное задание, то все равно будем копать до конца.
У нас есть опыт успешного найма сотрудников с не совсем профильным образованием.
Значит, утверждение "прежде всего должно быть высшее образование по профильной области" — неверно.
Но нет успеха в попытках работать с людьми без диплома, так уж получилось.
Угу. Перейдем к вопросу о статистически значимых наблюдениях и корректной постановке эксперимента, или уже не стоит?
Статистику специально не собирали, это просто мое наблюдение. Количество успешно принятых кандидатов без диплома у нас равно нулю.
В любом случае я считаю, что кандидату, получившему диплом, особенно профильный, доверия больше. Но тут каждый директор может считать по своему.
Верно, т.к. больше профильных знаний, меньше пробелов в знаниях.
Если бы оно было верно, у вас бы не работали люди без профильного высшего. Вы, не замечая этого, переходите от "полезно" к "должно быть", и от "у меня так" к "в индустрии так".
Статистику специально не собирали, это просто мое наблюдение. Количество успешно принятых кандидатов без диплома у нас равно нулю.
Ха. Это неудивительно, если начинать с позиции "для меня ВУЗ — фильтр. Прошел — хорошо, не прошел — настораживает.". Как эксперимент, это не выдерживает никакой критики, вы же понимаете?
В любом случае я считаю, что кандидату, получившему диплом, особенно профильный, доверия больше.
Ну да, вот и еще одно подтверждение вашего предвзятого отношения.
Я считаю что должно быть так, хотя из всего есть исключения.
Что ж, это хороший повод не идти к вам в компанию.
У нас не эксперимент, реальная работа более 10 лет.
Просто надо понимать, что полученные в ходе этой реальной работы данные неприменимы для корректных выводов.
Отношение к людям без диплома в плане приема на работу у меня предвзятое, опять же на основании моего опыта.
Самоподдерживающаяся система.
Но нет успеха в попытках работать с людьми без диплома, так уж получилось.
У вас — нет. У Гугля — есть: " “proportion of people without any college education at Google has increased over time” — now as high as 14 percent on some teams".
… стиль разработки такой же как на PHP – правите файлы на сервере, открываете страничку, смотрите результат…
Простите, но нет. Это не стиль разработки на php (или любом другом языке программирования).
Может стоит пойти по пути наибольшего сопротивления и посмотреть на результат?
Английский универсален все таки.
Вот представьте как будет выглядеть тот же бейсик например на китайском :))
А вот примерно так и будет выглядеть:
en.wikipedia.org/wiki/Chinese_BASIC
Реально для создания Web-приложений не нужны языки с кириллицей (опять же по моему мнению). Этот процесс включает в себя много различных технологий, а не только языки программирования (базы данных, Web-серверы, клиентские скрипты и т.п.). Считаю что у тех программистов, которые не владеют английским свободно, нет шансов сделать что-нибудь стоящее в этой области.
Российские разработчики не должны вариться в собственном соку на кириллице, а должны создавать продукты мирового качества и распространять их по всему миру. Пример — почтовый сервер CommunigatePro, созданный Владимиром Бутенко, который, к великому сожалению, недавно скончался: www.cnews.ru/news/top/2018-08-30_umer_osnovatel_communigate_vladimir_butenko.
Можно сказать, я учился в студенческие годы на исходных текстах ядра ОС MISS, созданной Бутенко. И его почтовый сервер — сильная разработка действительно отечественного программиста.
На самом деле я считаю что мы много потеряли, сделав ставку на англоязычные языки программирования и не развивая собственные.
возможно, наши бы программы смогли перейти на новый уровень если бы избавились от костлявой грамматики английского. С бейсика тянутся все эти жесткие конструкции типа IF… THEN… ELSE…
А как бы выглядела русская концепция экспертной системы?
наши бы программы смогли перейти на новый уровень если бы избавились от костлявой грамматики английского
А конкретный пример?
А как бы выглядела русская концепция экспертной системы?
А точно так же. Если что, if-then-else — это если-то-иначе, совершенно естественная для русского языка конструкция.
ну или ДА НЕТ НАВЕРНОЕ?
к тому же IF мне напоминает больше недоразвитый цикл на одну или ноль итераций. и на нем основана вся логика программ? как то примитивненько.
Так же, как и в английском — probably, approximately и don't mind if I do.
мне кажется это проблема косности менталитета, англоязычные разработчики даже представить себе не смогут другие конструкции проверки условий.
что то не появилось этого пока в языках.
Если вы про что-то не слышали, еще рано думать, что этого не существует: nondeterministic programming, probabilistic programming languages.
англоязычные разработчики даже представить себе не смогут другие конструкции проверки условий.
А напомните мне еще раз, что конкретно в английском языке мешает представить другие конструкции проверки условий?
#define maybe if (rand() % 2)
У вас тут фундаментальная ошибка в определении причины и следствия. Это не IF является недоразвитым циклом, а цикл — это синтаксический сахар над IF GOTO
к тому же IF мне напоминает больше недоразвитый цикл на одну или ноль итераций. и на нем основана вся логика программ?
Мало ли что кому напоминает. "Если-то" — это одна из базовых моделей мышления.
Ну и да, это снова не зависит от языка, что в русском, что в английском это будет выражено более-менее одинаково.
Еще раз, разработка программ и приложений не сводится к языкам, процесс сложный и включает в себя множество уже разработанных систем и компонент. Реальность такова, что без знания английского языка сейчас сделать ничего невозможно. А главное — незачем.
В мировом масштабе не имеют, в российском у 1с 90% рынка учетных программ не в последнюю очередь благодаря русскому синтаксису языка, уменьшающему порог входа и вообще облегчающему восприятие кода.
В области разработки программ, считаю, вообще не имеет смысл говорить о российских масштабах. Эти разработки уже давно стали международными. Вот, например, поисковый сервер Sphinx, созданный русским разработчиком Андреем Аксеновым. Или всемирно известный прокси nginx — разработчик Игорь Сысоев.
Вот на это нужно ориентироваться, а не изобретать какие-то особые языки с кириллицей.
Нужно не уменьшать порог входа, а учить нормальным средствам проектирования программ.
Какое отношение язык имеет к нормальности-ненормальности средств проектирования? Добавление русского языка не делает 1С ни лучше ни хуже, оно делает его просто значительно более удобным для разработки. Когда делаются сайты, предполагающие посещение людьми из разных стран, используется глобализация, это удобно, я совершенно не понимаю, почему нельзя сделать глобализацию в средствах разработки.
В области разработки программ, считаю, вообще не имеет смысл говорить о российских масштабах. Эти разработки уже давно стали международными.
Есть огромное количество разработок, которые не просто не являются международными, но и вообще не выходят за пределы компании, для которой разрабатываются и составляют ее коммерческую тайну. На мой взгляд все утверждения о том, что писать программы нужно только на анлийском — это въевшийся стереотип. Как уже писал выше — глобализация подняла бы общий уровень разработки, потому что по своему опыту могу сказать, как человек, свободно разговаривающий на английском и поработавший как с 1С, так и с англоязычными средствами разработки — код на русском мозгом воспринимается значительно проще, хотя конечно по началу будет непривычно.
На мой взгляд все утверждения о том, что писать программы нужно только на анлийском — это въевшийся стереотип.
Программы нужно писать не "на английском", а на понятном языке программирования. Вот с комментариями сложнее.
Но тут ведь вопрос простой: вы готовы к тому, что весь ваш код будет ограничен в рамках только русскоязычной аудитории? Что вы сам не можете использовать не-русскоязычные наработки?
а) Я писал выше, что огромное количество программ не являются продуктами для массовой продажи вообще, не говоря уж о международном рынке, например разработка сайта или корпоративной системы для конкретной компании, которая останется только в компании и вообще может составлять коммерческую тайну. Это редкий случай? Нет
б) Я смогу использовать нерусскоязычные наработки. Это же просто код. Вы можете написать if, вы можете написать если, компилятор будет воспринимать и то и то. Также функции, вы можете оставить их на английском и вызывать в своем коде (например 1С так делает со сторонними библиотеками и проблемы нет), а можете перевести на русский, и здесь возникает следующий пункт…
в) Не вижу большой сложности создать инструмент, который будет переводить наработки с одного языка на другой. С ключевыми словами вообще проблем нет, а какой-то словарь ru-en для названий функций и переменных создать не вижу проблемы, например автоматический перевод с возможностью редактирования.
Я писал выше, что огромное количество программ не являются продуктами для массовой продажи вообще, не говоря уж о международном рынке
А при чем тут продажа? Я говорю об OSS и просто последующем использовании.
разработка сайта или корпоративной системы для конкретной компании, которая останется только в компании и вообще может составлять коммерческую тайну. Это редкий случай? Нет
В моей практике это намного более редкий случай, чем можно подумать. Начиная с необходимости показать код службе поддержки и заканчивая его же демонстрацией на собеседовании. Мне как-то прислали на разбор код, где все идентификаторы были из французского. Я потратил на этот кейс раза в три больше времени, чем обычно.
Также функции, вы можете оставить их на английском и вызывать в своем коде
И получите код, который негомогенен — а это вызывает существенно больше проблем при чтении, нежели гомогенный код на неродном языке.
Не вижу большой сложности создать инструмент, который будет переводить наработки с одного языка на другой.
А вы просто попробуйте.
С ключевыми словами вообще проблем нет
Правда? Переведите ключевое слово let или var.
какой-то словарь ru-en для названий функций и переменных создать не вижу проблемы
На его поддержку уйдет больше сил, чем на написание программы.
Не вижу большой сложности создать инструмент, который будет переводить наработки с одного языка на другой.
А вы просто попробуйте.
И в чем же могут быть проблемы? Какие-то сложности выцепить из кода ключевые слова и названия идентификаторов и перевести их в соответствии со словарем? Это задача для тестового задания на позицию джуниора =)
Правда? Переведите ключевое слово let или var.
перем — точный перевод для var
какой-то словарь ru-en для названий функций и переменных создать не вижу проблемы…
На его поддержку уйдет больше сил, чем на написание программы.
Вы просто посчитайте, сколько новых, ранее не использованных в проекте слов, вы используете для именования переменных в задании, разработка которого занимает один день, вычтите из них те, которые какой-нибудь автоматический переводчик сможет перевести корректно, и то что останется — это даже не работа программиста, это работа аутсорсового копеечного переводчика. Локализация пользовательской части сайтов отнимает намного больше времени.
Какие-то сложности выцепить из кода ключевые слова и названия идентификаторов и перевести их в соответствии со словарем?
Потому что именование — одна из самых сложных задач в программировании. Словаря недостаточно, нужен контекст.
В качестве упражнения можете попробовать корректно перевести API.ContractBased.SystemContract.
перем — точный перевод для var
Точный, но неудачный. Я не готов читать "перем симвСчт".
Вы просто посчитайте, сколько новых, ранее не использованных в проекте слов, вы используете для именования переменных в задании
Проблема в том, что даже если слово использовалось мной ранее, еще не факт, что перевод его в этом контексте будет совпадать.
работа аутсорсового копеечного переводчика
В том-то и дело, что нельзя отдавать перевод аутсорсинговому переводчику (про копеечных я и вовсе молчу, им ничего нельзя отдавать), потому что он не знает, что было в моей голове, когда я придумывал именование. Он не в предметной области. Он не профессионал в разработке.
Точный, но неудачный. Я не готов читать «перем симвСчт».
А тысячи американцев и англичан не готовы читать var symbCnt, но они читают. Как и десятки тысяч разработчиков под 1С, которые читают Перем и не видят в этом никаких проблем.
Проблема в том, что даже если слово использовалось мной ранее, еще не факт, что перевод его в этом контексте будет совпадать.
Не думаю что это частая проблема, и даже не смог навскидку придумать русские слова в разработке, которые в рамках одного проекта будут иметь необходимость по разному их перевести( с аутсорсом ок, забудем про эту идею). В любом случае вы хозяин, переменных не так много и это не будет критично. В конце концов что, всегда во всех проектах переменные названы корректно? Нет.
А тысячи американцев и англичан не готовы читать var symbCnt, но они читают.
Во-первых, вы у них не спрашивали, вы не знаете. Если что, разные языки по-разному относятся к разным моделям сокращений. Во-вторых, вы уже не видите той смешной проблемы, что симвСчт — это не symbCnt, это charCnt, и правильный перевод на русский — чслСимв. Потому что порядок слов в русском и английском разный. И это мы еще не переходили к тому печальному факту, что русский язык — флективный, в отличие от английского.
Не думаю что это частая проблема, и даже не смог навскидку придумать русские слова в разработке, которые в рамках одного проекта будут иметь необходимость по разному их перевести
Слово "запись", например. Или "строка". Продолжать?
В любом случае вы хозяин, переменных не так много и это не будет критично.
Идентификаторов много. Мне лень лезть в метрики проекта, но там тысячи code units.
В конце концов что, всегда во всех проектах переменные названы корректно? Нет.
Поэтому давайте сделаем еще хуже? Спасибо, нет, мне существующих проблем хватает.
Потому что порядок слов в русском и английском разный
Ну как сказать.
Критичен порядок слов только в английском.
В русском — можно и подстроиться.
Вы не видите разницы между "порядок слов" и "слов порядок"? Подстроиться, конечно, можно, но это дополнительное когнитивное усилие, которых при чтении кода лучше избегать, там и так работы хватает.
Вы не видите разницы между «порядок слов» и «слов порядок»?
В английском — изменение порядка слов меняет весь смысл на корню.
В русском — порядок слов влияет всего лишь на стилистику/оттенки.
Это ровно до тех пор, пока у вас есть падежи. "Число символов" и "символов число" — все еще более-менее понятно (хотя, конечно, второе уже вызывает вопросы, потому что любое отклонение от нормы вызывает вопросы), но вот "числ симв" и "симв числ" — уже нет.
но это дополнительное когнитивное усилие
но вот «числ симв» и «симв числ» — уже нет.
в программировании допускают довольно много вольностей, понятные только в контексте конкретного кода, с его конкретными соглашениями о стиле. и ничуть не связанная с правилами языка человеческого (хоть английского, хоть русского).
например, приложите правила венгерской нотации к вашему примеру.
в английском кроме порядка слов есть много еще чего, что помогает понимать смысл сказанного, но что зачастую упускают в именовании идентификаторов (артикли, be/do, размещение предлога у фразовых глаголов), и в результате с точки зрения английского языка код превращается в бред…
например, в вашем примере — чем является первое слово? сказуемым? подлежащим? а в названии функции? а в названии переменной? определенные соглашения (скажем что в названиях функции первое слово — сказуемое) и есть те соглашения, что помогают понять смысл.
смысл понять помогают соглашения программистов о их волапюке, а вовсе не исходные правила английского языка (которые зачастую нарушаются в именовании идентификаторов)
и ничуть не связанная с правилами языка человеческого
У кого как. У вас не связаны? Поздравляю вас.
в английском кроме порядка слов есть много еще чего, что помогает понимать смысл сказанного, но что зачастую упускают в именовании идентификаторов
Люди, которых волнует читабельность кода — и у которых есть возможность этим управлять — не опускают те слова, которые влияют на читабельность.
например, в вашем примере — чем является первое слово? сказуемым? подлежащим? а в названии функции? а в названии переменной?
В названии переменной не может быть ни сказуемого, ни подлежащего, там может быть существительное, прилагательное, глагол (ну и практически любая часть речи, на самом деле). И тут проблема как раз в том, что у нас есть два существительных подряд. В английском их связь задается порядком. В русском, в первую очередь, падежом.
определенные соглашения (скажем что в названиях функции первое слово — сказуемое)
Обычно в названиях функции первое слово — глагол.
Обычно в названиях функции первое слово — глагол.
Вот именно!
Все дело в соглашениях программистов!
А не в правилах человеческого языка.
Язык программистов, который они используют для идентификаторов — это волапюк, составленный из слов какого-то языка — не более того.
Это никак не отменяет того факта, что из каких-то языков этот волапюк составлять проще, чем из других.
Это никак не отменяет того факта, что из каких-то языков этот волапюк составлять проще, чем из других.
По сравнению с чем проще?
С тем, к чему вы уже привыкли?
А у вас была практика с программированием на русском языке, ну хотя бы с полгода плотно каждый рабочий день, чтобы вы к нему привыкли и уже смогли бы оценивать объективно?
У меня — была такая практика.
Меня, помнится, колбасило, когда довелось вникать в 1С: Предприятие. Все пытался англоязычных идентификаторы писать. Более того, 1С: Предприятие позволяет легко в коде переходить на русские или на английские операторы без каких-либо переключений в системе. То есть можно писать сплошной англоязычный программистский волапюк.
Так же поступали все программисты, которых я наблюдал в момент их знакомства с 1С.
Потом подавляющее большинство переходят на русский — так гораздо удобнее. Для конкретной этой ситуации с 1С.
Дело в том, что 1С предполагает глубокое погружение в прежде всего в предметную область. А термин «вычет на ребенка с налога на доходы физических лиц» куда как проще написать на русском.
В 1С мне удобно пользоваться русским.
Для написания сайтов мне удобно пользоваться английским.
С учетом имеющегося опыта с разных сторон — вообще не вижу никаких проблем в том, на каком языке писать идентификаторы.
Нужно использовать тот язык, что ближе к предметной области.
Пока работаешь в одного — это не важно. Вот при работе в коллективе все эти неоднозначности твоего перевода уже плохо.
Так правильнее термины которые используешь ты и твой пользователь/твой заказчик. А то мало ли чего ты там напереведешь.
По сравнению с чем проще?
По сравнению с другими языками.
А у вас была практика с программированием на русском языке, ну хотя бы с полгода плотно каждый рабочий день, чтобы вы к нему привыкли и уже смогли бы оценивать объективно?
У меня была практика попробовать один раз перевести одну программу. Мне хватило.
Нужно использовать тот язык, что ближе к предметной области.
Угу. Когда большая часть твоей предметной области — это платформы, API и тому подобная разработка ядер, приходится пользоваться английским.
А термин «вычет на ребенка с налога на доходы физических лиц» куда как проще написать на русском.
А потом, значит, ты пишешь 'SerializeToJson(документОВычетеНаРебенка)`. Потому что рядом две предметных области.
Вот при работе в коллективе все эти неоднозначности твоего перевода уже плохо.
При работе в коллективе плохо даже иметь разный выбор слов без перевода. См. ubiquitous dictionary.
И в чем же могут быть проблемы? Какие-то сложности выцепить из кода ключевые слова и названия идентификаторов и перевести их в соответствии со словарем? Это задача для тестового задания на позицию джуниора =)
Боюсь ваш джуниор чуть-чуть помрёт над этой задачей. Ну или поседеет до миддла-сеньора.
А вы сможете нормально перевести обычный кейворд «let»?
let let = 23; // Представим, что в этом языке можно использовать кейворды в качестве имён переменных
let a = "${let} \"a\""; // И даже есть интерполяция в стиле PHP
1С для объявления использует ключевое слово перем, это точный перевод для var, подойдет и для let…
Вы упустили из внимания тот факт, что var и let надо переводить по-разному.
Если имеется ввиду js, то это связано исключительно со спецификой истории развития языка.
Ну так у каждого языка будет такая специфика, которую вам тоже придется учитывать. Есть вот милые языки, в которых различается var и val.
Какой смысл в слове let?
"Let x-one be our initial approach". Какой в ней смысл в слове "let"? Тот же и здесь.
Если вы переведете его как локал или лок
… и получить конфликт со словом lock? Спасибо, снова нет.
Даже если перевод будет странным, вы очень быстро к этому привыкнете.
Нет. Я не привыкаю к "странным переводам" — вплоть до того, что я не читаю переводную литературу, если могу читать оригинал.
Если вы не хотите писать на русском — тогда вы во всем увидите проблему.
Ну да, я не хочу писать на русском, потому что нет такого средства, которое позволяет мне писать на русском, при этом сохраняя полное взаимодействие с англоговорящими коллегами. Вообще нет языка прграммирования, который бы позволил мне писать на русском, не противореча при этом моему чувству языка.
Здесь не о чем спорить. Не у всех есть английские коллеги, которые анализируют ваш код и не у всех программные конструкции на русском противоречат вашему чувству языка. То что русский язык может использоваться в разработке говорит сверхуспешный опыт 1С, все остальное частности, привычки и т.д.
То что русский язык может использоваться в разработке говорит сверхуспешный опыт 1С
Сверхуспешный опыт внутри одной страны. Я сразу сказал: если вас это устраивает, если вам не интересен мировой опыт — окей, так можно.
Сверхуспешный опыт внутри одной страны. Я сразу сказал: если вас это устраивает, если вам не интересен мировой опыт — окей, так можно.
Если вы собираетесь работать/работаете на международном рынке — то использование для идентификаторов стандарта де-факто для общения — английского языка — логично.
А в остальном — у вас подменена понятий.
Или вы утверждаете, что программы успешны только благодаря неким волшебным свойствам языка, на котором пишутся идентификаторы? Что английский это какое-то чудо повышающее производительность труда программиста?
Вы просто не сталкивались с кодом немецких, итальянских, испанских или французских программистов, который написан без учета общемировой публикации исходников.
Уверяю вас — использование родного языка для них вполне себе нормальная ситуация. Тем более что они используют латиницу, которую поддерживают для использования в идентификаторах все языки программирования
Если вы собираетесь работать/работаете на международном рынке
Я с этого и начал, если что — что русский можно использовать только если никогда не собираешься взаимодействовать с внешним миром.
Что английский это какое-то чудо повышающее производительность труда программиста?
Ну да, потому что использование английского позволяет интегрировать существующие решения вне зависимости от того, кем и где они разработаны.
Вы просто не сталкивались с кодом немецких, итальянских, испанских или французских программистов, который написан без учета общемировой публикации исходников.
Вы, видимо, не читали мои комментарии несколько раньше в этой дискуссии, где я как раз писал, что сталкивался как-то с кодом французов, и это было проклятьем в отладке. При этом это им было нужно, чтобы я отладил их код.
Уверяю вас — использование родного языка для них вполне себе нормальная ситуация.
Ага, нормальная. С описанными выше последствиями.
Тем более что они используют латиницу, которую поддерживают для использования в идентификаторах все языки программирования
Вы не в курсе, что ни французский, ни испанский в "общепринятую латиницу" не влезают? И между peña и pena есть фундаментальная разница?
Я с этого и начал, если что — что русский можно использовать только если никогда не собираешься взаимодействовать с внешним миром
А че тут обсуждать-то?
Разумеется, если речь идет о выходе на международный уровень — нужен английский.
Это настолько очевидно, что вообще никто это и не оспаривал в комментариях тут. Вы придумаете воображаемых оппонентов.
Вы не в курсе, что ни французский, ни испанский в «общепринятую латиницу» не влезают? И между peña и pena есть фундаментальная разница?
Все в пределах уже обсужденного нами с вами тут в комментариях программистского волапюка.
А че тут обсуждать-то?
А вы почитайте дискуссию, там внезапно выясняется, что можно придумать автопереводчик, который избавит от необходимости писать на английском.
Это настолько очевидно, что вообще никто это и не оспаривал в комментариях тут.
https://habr.com/post/423713/#comment_19132465
"все утверждения о том, что писать программы нужно только на анлийском — это въевшийся стереотип. Как уже писал выше — глобализация подняла бы общий уровень разработки"
https://habr.com/post/423713/#comment_19132551
"Не вижу большой сложности создать инструмент, который будет переводить наработки с одного языка на другой."
И напомню, что Axapta это не какая-то левая подделка, это майкрософтовский продукт.
Вообще-то, IBM-овский, а затем (и в основном) — Navision. А майкрософтовский — это Dynamics AX, и у него сейчас весьма занятная жизнь. Кстати, если искать с учетом этого ребрендинга, цифры уже другие.
P.S. Я намекаю на то, что str_replace тут не подойдёт (т.к. заменит сразу все вхождения). И даже обычный лексер не будет работать (т.к. проигнорирует то, что имя переменной переводить нельзя, хоть токены и одинаковые).
Не понимаю в чем смысл вопроса…
И что, у вас действительно все джуниоры могут это с «пол пинка», как вы заверяете?
А в чем, простите, выражается опыт работы, если не в "умении писать алгоритмы"?
Давайте «на пальцах»: Написание парсера довольно трудоёмкая задача, если делать всё с нуля. Именно это и реализовал в некотором виде автор сего поста, где мы все вместе развели демагогию в комментариях. Готовы ли вы взять его к себе в команду на должность сеньора? Может миддла? Умение писать алгоритмы автор уже изобразил вполне (и это без сарказма, человек действительно постарался в этом плане).
Ну по-моему dimoff66 всё же прав. Опыт работы != писать алгоритмы.
Опыт работы — больше, чем писать алгоритмы. Но написание алгоритмов тоже приходит с опытом.
Готовы ли вы взять его к себе в команду на должность сеньора? Может миддла?
Нет. Именно потому, что я считаю, что он не умеет писать алгоритмы. Выбор стратегии реализации — тоже часть навыка "писать алгоритмы". Знание, где можно взять регексп, а где надо брать полный парсер — тоже часть этого навыка.
Выбор стратегии реализации — тоже часть навыка «писать алгоритмы».
О, а это по-моему уже проектирование, декомпозиция и архитектура. Что-то из. Всё же «алгоритмы» это императивная часть программирования, а описанные мною термины — декларативная. Выбор стратегии реализации — это есть проектирование декларативной части. Не?
Знание, где можно взять регексп, а где надо брать полный парсер — тоже часть этого навыка.
А это уже знание экосистемы и количество знаний. Умение найти формочку на просторах
Ниже DimOFF с языка снял тезис:
Я занимаюсь программированием 25 лет, последние 17 профессионально, но если я захочу изучить C# и пойти работать, то я буду таки джуниором.
У меня ровно такое же мнение и только потому, что я знаю, что знание языка или умение написать сортировку Шелла — это далеко не главное в современной разработке. Есть ещё и знание экосистемы. Без знания какого-нибудь Vue или React дальше джуна/миддла в JS не уехать, например.
Всё же «алгоритмы» это императивная часть программирования [...] Выбор стратегии реализации — это есть проектирование декларативной части. Не?
Это до тех пор, пока вы не начинаете писать алгоритмы на функциональных языках, где их запись внезапно оказывается неимперативной.
А это уже знание экосистемы и количество знаний.
Нет, это знание того, что html нельзя разобрать регэкспом безотносительно того, в какой экосистеме вы находитесь. Знание того, что хэштаблица — это (ожидаемое) O(1), а связанный список — O(n) (на чтение).
У меня ровно такое же мнение и только потому, что я знаю, что знание языка или умение написать сортировку Шелла — это далеко не главное в современной разработке
А у меня вот знакомый недавно из senior C# ушел в senior Java.
Более того, даже если посмотреть на то, что вы назвали как критерии — умение проектировать и декомпоновать — эти вещи тоже не зависят от языка. Поэтому опытный программист, переходя с языка на язык, конечно, теряет в эффективности, но это не "упал на junior-уровень", и, что важнее, подъем обратно происходит намного быстрее, чем когда ты первый раз идешь по этой дороге.
Без знания какого-нибудь Vue или React дальше джуна/миддла в JS не уехать, например.
… или можно писать сервер-сайд и никогда не слышать этих слов.
А откуда взять ту алгоритмическую логику, которую надо реализовывать?
Англоязычность языков программирования никак не затрудняет разработку программ, особенно если учесть, что практически все описания технологий и инструментов на английском языке. А переводы отстают по времени, искажены и неполны. Такова реальность.
Если читать только переводные книги трехлетней давности, то будете всегда отставать от передового уровня средств разработки и эксплуатации.
Если вы будете брать на работу Web-программистов, не знающих английского языка, они не смогут сделать ничего путного. Просто посмотрите на весь стек технологий Web-приложений. Он выходит далеко за PHP, Perl или Python.
Не хочу никого обидеть, но на мой взгляд сейчас попытки создания кириллических языков серверного программирования возникают только от непонимания общей сложности и многогранности задачи.
Конечно, можно потратить много сил на создание такого языка, но уверяю вас, настоящие специалисты не будут им пользоваться — просто незачем. В их руках уже есть удобные готовые инструменты необходимой мощности, которые работают и позволяют решать все текущие задачи.
Что касается софта, то его разработка стоит безумных денег. Поэтому обычно все сводится к сертификации какой-нибудь версии Линукса. Думаю, что реальнее также сертифицировать уже имеющиеся инструменты и средства, а не разрабатывать свои «с нуля». Если речь, конечно, идет про разработку Web-приложений и приложений аналогичной сложности. Сомневаюсь, правда, что это требуется в оборонке.
Раньше на ВДНХ в павильоне Космос стояли бортовые компьютеры, на отечественной аппаратной базе и со своими ассемблерами. Вот на этом уровне можно, а Web-приложения — там все сложно. И снова, для хорошего специалиста в области ИТ английский язык — необходимое, а не опциональное знание.
Если вы будете брать на работу Web-программистов, не знающих английского языка, они не смогут сделать ничего путного.
Это очень большое и ничем не оправданное преувеличение, тут бессмысленно дальше дискутировать. И опять же, вопрос не в создании нового языка. Речь лишь о переводе либо того, что сделал автор, либо любого существующего. В чем проблема компилятора или препроцессора помимо IF THEN и FUNCTION обрабатывать также ЕСЛИ, ТОГДА, ФУНКЦИЯ. Нет никакой проблемы, а имена на кириллице многие продукты Майкрософт к примеру позволяют писать сколько я себя помню… Разве что в С++ нельзя использовать кириллицу.
Если вы опытный разработчик и читаете на английском, то сможете разобраться с этими ошибками самостоятельно или с помощью Stack Overflow. И не нужны вам никакие имена на кириллице и операторы, это будет вас только путать. Ничего ровным счетом они не упрощают.
А потом еще по почте будете получать крокозябры, и хорошо если только вы, а не клиенты.
По поводу «И не нужны вам никакие имена на кириллице и операторы, это будет вас только путать.» это ваше личное мнение и может не иметь никакого отношения к действительности. В моем случае — точно не имеет. Я писал на русском под 1С, я пишу последние три года на английском вэб-проекты. И русский код легко читается мною без комментариев, в то время как английский приходится сразу комментировать, чтобы легко воспринимать, при том, что я свободно разговариваю и читаю на английском.
Код 1С на мой взгляд выглядит ужасно, но этот продукт вообще не имеет отношения к Web-разработке. Что же касается языков для создания Web-проектов, думаю, не случайно там нет ничего с кириллицей. Было бы востребовано — давно бы сделали.
Код 1С на мой взгляд выглядит ужасно
Абсолютно так же, как для англоговорящих выглядит любой язык программирования.
но этот продукт вообще не имеет отношения к Web-разработке
Во-первых пока не имеет. 1С уже реализовывает вэб-сервисы и создание мобильных приложений. Могут и полноценный вэб-сервер сделать рано или поздно. А во вторых какая разница — вэб или не вэб? Методы написания языковых конструкций от этого не отличаются.
а изучать английский в ВУЗ-е нужно, вместе с ИТ-предметами, вот как я считаю. Конечно, это мой опыт, у вас свой.
Для чтения документаций недостаточно английского, нужен технический английский. Его проще изучить работая с программой, чем на курсах.
А во вторых какая разница — вэб или не вэб?
Вот когда попробуете сделать интеграцию с веб-сервисом, в котором люди выставили русские слова в качестве идентификаторов, тогда и поймете, какая разница.
Для чтения документаций недостаточно английского, нужен технический английский.
… который нарабатывается в процессе чтения документации. Вот чтобы писать документацию по-английски, нужно уже прилагать усилия.
Во-первых пока не имеет. 1С уже реализовывает вэб-сервисы и создание мобильных приложений. Могут и полноценный вэб-сервер сделать рано или поздно
1С: Предприятие уже 15 лет как умеет веб-интерфейс (разумеется специализированный).
Еще с версии 7.7 (если кто не в курсе — сейчас актуальная 8.3, ну а 8.0 вышла в 2003 году). Бэкенд тогда был 1С, но фронтенд — на ASP.
Ну а где-то с версии 8.2 (2009 год) — реализация фронтенда уже на встроенных средствах 1С. С версией и годом могу ошибаться.
Мы, например, открываем интернет-магазины, которым 1С нужен только для формирования документации в налоговую. Все остальное можно делать средствами магазина или подключаемых внешних сервисов. Но обсуждение 1С — тема отдельного разговора.
Насколько я знаю, 1С приходится использовать по необходимости, как стандарт де-факто в подготовке отчетности для налоговой.
Это заявление лишено смысла. У 1С нет монополии на сдачу бухгалтерской отчетности, есть множество других программ для сдачи отчетности. К тому же 1С: Бухгалтерия — лишь одна из конфигураций, на 1С крупные и очень крупные компании ведут производство, управленческий учет, торговлю, поскольку по гибкости и скорости доработки им нет равных. Все, что касается учета, доработать на 1С в разы быстрее, чем на любом из известных мне фреймворков вэб-разработки.
Но обсуждение 1С — тема отдельного разговора.
Да, но вы должны иметь для этого представление о ней чуть большее чем «насколько я знаю», иначе общение будет бессмысленным. =)
Некоторые исторически используют 1С Предприятие для ведения учета, но только исторически. Сейчас есть уже более удобные и современные сервисы CRM и ERP, сервисы фулфилмента.
На мой взгляд, новым клиентам, которым требуется автоматизация, нужно смотреть на более современные инструменты.
Все, что касается учета, доработать на 1С в разы быстрее, чем на любом из известных мне фреймворков вэб-разработки.
Потому что не надо сравнивать 1C с фреймворками веб-разработки (а если сравнивать, то в формате "за сколько на 1С можно разработать веб-сервис для xxx, и, поверьте мне, мы один раз делали такую интеграцию лет пять назад, все прокляли). Сравнивайте с ERP-платформами.
1С до сих пор не сумела сделать нормальный облачный сервис с API. То, что они называют облаком, это виртуалки Windows, на которых работает обычная 1С. И дальше опять загрузки-выгрузки файлов, либо сложная интеграция.
SAP — Доработки в разы дороже за счет высокой стоимости специалистов и в 10 раз больше времени на аналогичные изменения функционала
AXAPTA — Разработка занимает намного больше времени
ПАРУС — Нет открытого кода
ГАЛАКТИКА — Нет открытого кода
Поэтому у 1С 90% рынка
С ERP-платформами будет не в разы а в десятки раз:
Где NetSuite? Где SalesForce? Где Sage? Вы вообще в квадрат Гартнер заглядывали?
Поэтому у 1С 90% рынка
В России.
При этом вы делаете утверждения типа "Вообще думаю, что тот системный подход, который они [1С] используют, рано или поздно выведет их на лидирующие позиции в мировой разработке."
Да, и при этом я делаю такие утверждения исходя из сравнения с ведущими мировыми системами, представленными на рынке России,
Вы видели место этих "ведущих мировых систем" в том же магическом квадрате?
исходя из качества продукта как такового.
В каких конкретно цифрах вы меряете "качество продукта", и почему вы считаете, что это "качество" у 1С выше, чем у конкурентов на мировом рынке?
и почему вы считаете, что это «качество» у 1С выше, чем у конкурентов на мировом рынке?
Я не писал этого. Вы приписываете мне то, что я не говорил. Это затрудняет общение. Еще раз: если вы можете сравнить лидирующие западные системы — пожалуйста приведите сравнение с 1С, если нет — то благодарю за беседу.
вы можете сравнить лидирующие западные системы — пожалуйста приведите сравнение с 1С
А вы можете привести такое сравнение?
И конечно если вы ссылаетесь на квадрат Гартнера было бы исключительно любезно дать на него ссылку для ERP систем.
Но одной из лучших по моему ощущению будет.
Но подтвердить это ощущение вы ничем не можете, потому что вы, собственно, не знакомы с тем множеством, к которому предлагаете отнести 1С. Просто "я так вижу".
(вы, я так понимаю, тоже не знакомы с чайником Рассела)
Бремя доказательства лежит на утверждающем.
«Я нигде не утверждал, что 1С лучше всех существующих в мире систем от Гибралтара до Новой Зеландии.»
Вы утверждали, что "рано или поздно [системный подход] выведет их на лидирующие позиции в мировой разработке".
Я даже этого не утверждал.
https://habr.com/post/423713/#comment_19132955
Ничего невозможно утверждать про будущее.
Вполне возможно. Это называется "прогноз".
была какая-то система на три головы выше САП, Оракл или Аксапты — она заняла бы их место на российском рынке
(Подождите, а откуда внезапно взялся оракл (который и есть нетсьют)? В вашем исходном сравнении его не было.)
Это предположение, конечно, неверно, потому что есть ERP-системы, которые просто не заинтересованы в продвижении на российском рынке.
Понимаете, есть региональные рынки, на которых есть региональные вендоры, хорошо знающие специфику этого рынка. За счет этого знания они на этом рынке могут быть лидерами (то же самое, кстати, бывает со специфическими рынками по индустрии, типа строительной). Это ничего не говорит о том, как их технологическая платформа соотносится с технологическими платформами конкурентов — только о том, что она достаточно хороша, чтобы вендор справлялся. Не более того.
В качестве иллюстрации можно инвертировать эту фразу: если бы 1С была на три головы выше САП и Аксапты — как вы, как мне кажется, утверждаете — она бы заняла их место на, скажем, рынке США. Раз этого не произошло, значит...
Подождите, а откуда внезапно взялся оракл (который и есть нетсьют)? В вашем исходном сравнении его не было.
Могу добавить. На последнем месте работы связанном с 1С в одной из страховых компаний для учета использовался оракл. Все то же самое — раздутый штат программистов с сомнительным КПД по причине того, что все что делается на 1С за час, в Оракле требует день.
Если это одна из ведущих ерп систем, то мой «прогноз» обрел еще больше основательности.
раздутый штат программистов с сомнительным КПД по причине того, что все что делается на 1С за час, в Оракле требует день.
..."делается" или "программисты делали"?
Если это одна из ведущих ерп систем
Одна из ведущих ERP-систем — это Oracle ERP Cloud, еще одна — Oracle NetSuite. А с какой вы работали?
...«делается» или «программисты делали»?
Спасибо конечно за предположение, что это именно я гений, который все делал в разы быстрее посредственностей из Оракл, но полагаю что все таки «делается». Но все равно очень тронут вашим предположением, почти до слез.
А с какой вы работали?
Только в предыдущем комментарии вы написали, что оракл и есть нет сьют, а теперь спрашиваете меня нет сьют оракл или что-то еще? Не знаю, вам виднее.
полагаю что все таки «делается».
Снова безосновательно, потому что выборки нет, да?
Не знаю, вам виднее.
Мне никак не виднее, с чем вы работали. Но судя по всему, данных для корректного сравнения 1C на мировом рынке у вас нет.
Скажу так — если не получилось изучить английский в ВУЗ-е, то лучше идти на курсы)
Если вы прежде чем изучать программирование предлагаете идти на курсы английского языка
Английский нынче преподают в школе, в объеме, достаточном для чтения. Не везде и не во всякой, но это упущение, которое должно быть исправлено.
Программирование как профессиональную дисциплину в непрофильных школах пока не преподают (и, надеюсь, не будут).
английский приходится сразу комментировать, чтобы легко воспринимать, при том, что я свободно разговариваю и читаю на английском.
Чтение кода — это нарабатываемый навык. Я читаю код, содержащий английские идентификаторы, намного легче, чем код, содержащий русские.
Не забывайте, что использование «англоязычных» языков программирования, а также использование английского языка для именования переменных и комментариев позволяют в случае необходимости аутсорсить разработку в другие страны, если это экономически оправданно. Никто не любит так называемый «индусский код», аутсорсить в другие страны не патриотично, т.к. не создаёт рабочих мест в «родной» стране компании, но зачастую это экономически выгодно. При этом, насколько я понимаю, может происходить и с продуктами, которые не выходят за пределы использующей их компании.
habr.com/post/423713/#comment_19132551
Там у 1с есть язык на кириллице. Обратите внимание. Зачем английские ключевые слова?!
Ладно 1С, вон даже такой гигант как Microsoft не гнушается использовать кириллицу в именах функций! Пруф
КУБЧИСЛОЭЛМНОЖ вместо CUBESETCOUNT, как вам таке?!
Однажды много лет назад, я не использовал нормальную IDE, и провел несколько «занимательных» часов дебага print_r-ми, когда опечатался в имени функции вместо «c» кириллическое «с». Так и открыл для себя эту возможность языка.
Если разработано для России, было бы интересно для всех функций и конструкций иметь русские аналоги, как это организовано в 1С — ЕСЛИ ИНАЧЕ и т.п.
Кроме того, возможно отказаться в базовых командах вообще от какого либо языка.
например
SUB A( X, Y)
IF A>B THEN A=B
END Aзаменить на
A(X,Y) -> {
? A>B { A=B }
} (A)
Все новые языки пишут так или иначе на других языках программирования.
и так избавимся от засилья иностранных БЕЙСИК и прочих PHP.
Какую задачу кроме самообразования вы решали своим новым языком?
Потому что это низачем не нужно. Намного эффективнее держать в языке мало ключевых элементов, а всю подобную функциональность выносить в стандартную библиотеку или библиотеки-расширения, особенно учитывая, что для серверных веб-приложений графика нужна достаточно редко, а вот нужно для сервер функциональности типа роутинга, обработчиков и так далее у вас все равно нет.
В вашем языке, как вы говорите — 200 команд. В C# — 79 ключевых слов, в Python — 33, и при этом возможности обоих этих языков несравнимо шире.
Вообще, разделение на команду и подпрограмму — бессмысленно, чего уж.
Например, были не только команды и функции, утрачено понятие «Теорема» и доказательство теорем, поиск подходящей теоремы. Вы удивились, что работа с базой часть языка, а как вам например запросы на поиск подходящих теорем?
все гораздо хуже чем вы думаете. вы в курсе что было утрачено?
Расскажите же нам.
Например, были не только команды и функции, утрачено понятие «Теорема» и доказательство теорем, поиск подходящей теоремы.
Утрачено, ага.
Вы удивились, что работа с базой часть языка, а как вам например запросы на поиск подходящих теорем?
… а зачем это в языке программирования для разработки серверных веб-приложений?
Нашёл упоминание.
SWITCH ON COMPUTER ' Включаем компьютер,
SWITCH OFF SWET V KOMNATE ' включаем свет в комнате
' Программа поиска простых чисел
' по алгоритму DO-DO-DO (давай-давай-давай)
' на языке BArSIC (r - Рачительный)
K=10000: DIM P%(K): P%(1)=2: N=1: I=1
DO ' давай
DO ' давай
N = N + 2
S = INT(SQR(N))
J = 0
DO ' давай
J = J + 1
P = P%(J)
LOOP UNTIL P >= S OR N / P=INT(N/P)
LOOP UNTIL N / P > INT(N / P)
I = I + 1
P%(I) = N
LOOP UNTIL I = K
SWITCH ON PRINTER ' включаем принтер
FOR I = 1 TO K: LPRINT I, P%(I): NEXT
SWITCH OFF PRINTER ' выключаем принтер
SWITCH ON DISK ' включаем дисковод
OPEN "DATA" FOR OUTPUT AS #1 ' открываем файл
FOR I = 1 TO K: PRINT #1, I, P%(I): NEXT
CLOSE ' закрываем файл
SWITCH OFF DISK ' выключаем дисковод
SWITCH OFF SWET V KOMNATE ' гасим свет в комнате
SWITCH OFF COMPUTER ' выключаем компьютерУ вас баг — свет дважды выключили.Да, об этом я и написал в заголовке спойлера.
А то, что программа включает компьютер, на котором собирается выполняться, вас не смутило?
(Самое смешное, что язык BARSIC тоже есть.)
Судя по статье и комментариям, сегодня должно быть 1-е апреля. Посмотрел на календарь: нет, вторая половина сентября.
Автору: дерзайте! Перепишите ядро Linux (или Windows) на PHP. Они тоже пишутся на языках программирования. А еще лучше на вашем WBasic. Будет у нас отечественный Linux. Чтобы каждый смог разобраться и пропатчить ядро под WBasic.
Проект вызывает смешанные чувства.
Вызывают уважение энтузиазм и предполагаемая цель (обучение школьников, если я правильно понимаю).
Всё остальное, начиная с технических аспектов реализации — очень плохо.
Риторика "Сделано в России" явно осталась от репортажа в районной многотиражке, где она смотрелась уместно, но выглядит дико при публикации на техническом ресурсе.
Логика при оценке собственного продукта у автора отказывает начисто
есть шанс, что вы можете создать популярный продукт, поскольку продуктовая конкуренция отсутствует
— это что вообще? Как связаны востребованность продукта и самопальность инструмента разработки?
«Сделано в России» — язык программирования WBASIC для разработки серверных веб-приложений