Привет, Хабр. Я бы хотел рассказать об одном из подходов в решении задачи диаризации дикторов и показать, как этот метод можно реализовать на языке python. Чтобы не отпугивать читателя, я не буду приводить сложные математические формулы (отчасти потому что я и сам «не настоящий сварщик»), а постараюсь изложить всё простым языком и рассказать всё так, чтобы понял разработчик, никогда прежде не сталкивавшийся с машинным обучением.
Готовясь написать эту статью, я выбирал между двумя вариантами изложения: для тех, кто уже знаком с Data Science и тех, кто просто хорошо программирует. В итоге я выбрал второй вариант, решив, что это будет неплохой демонстрацией возможностей DS.
Как говорит нам Википедия, диаризация — это процесс разделения входящего аудиопотока на однородные сегменты в соответствии с принадлежностью аудиопотока тому или иному говорящему. Иными словами, запись нужно разделить на кусочки и пронумеровать: вот в этих местах говорит один человек, а вот в этих другой. С точки зрения машинного обучения, подобного рода задачи принадлежат к классу обучения без учителя и называются кластеризацией. О том, какие методы кластеризации существуют можно почитать например здесь или здесь, я же рассажу только о тех, которые нам пригодятся — это Гауссова Смесь Распределений (Gaussian Mixture Model) и Спектральная Кластеризация (Spectral Clustering). Но о них чуть позже.
Начнём с самого начала.
Вообще говоря, помимо R, язык python является основным при решении задач Data Science, и если вы еще не пробовали программировать на нём, то я очень рекомендую это сделать, потому что python позволяет сделать многие вещи изящно, буквально в несколько строк (кстати, есть даже такой мем).
Существуют две отдельно развивающиеся ветки питона — версии 2 и 3. В моих примерах я использовал версию 3.6, но при желании их легко можно портировать на версию 2.7. Любую из этих веток удобно разворачивать вместе с инсталятором Анаконда, установив который вы сразу же получите интерактивную оболочку для разработки — IPython.
Помимо самой среды разработки понадобятся дополнительные библиотеки: librosa (для работы с аудио и извлечением признаков), webrtcvad (для сегментации) и pickle (для записи обученных моделей в файл). Все они устанавливаются простой командой в Anaconda Prompt
Начнём с извлечения признаков — данных, с которыми будут работать модели машинного обучения. В принципе, звуковой сигнал сам по себе — это уже данные, а именно упорядоченный массив значений амплитуды звука, к которому добавляется заголовок, содержащий количество каналов, частоту дискретизации и прочую информацию. Но анализировать эти данные напрямую мы не сможем, поскольку они не содержат таких вещей, глядя на которые, наша модель может сказать — ага, вот эти куски принадлежат одному и тому же человеку.
В задачах обработки речи существует несколько подходов к извлечению признаков. Одним из них является получение мел-частотных кепстральных коэффициентов (Mel Frequency Cepstral Coefficients). О них здесь уже писали, поэтому я лишь слегка напомню.
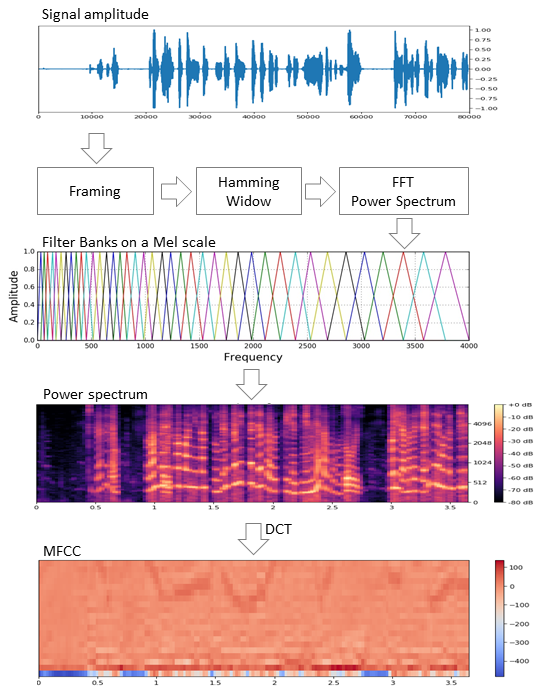
Исходный сигнал нарезают на фреймы длиной 16-40 мс. Далее, применив к фрейму окно Хемминга, делают быстрое преобразование Фурье и получают спектральную плотность мощности. Затем специальной «гребёнкой» фильтров, расположенных равномерно по мел-шкале делают мел-спектрограмму, к которой применяют дискретное косинусное преобразование (DCT) — широко используемый алгоритм сжатия данных. Полученные таким образом коэффициенты представляют из себя некую сжатую характеристику фрейма, при этом, поскольку фильтры, которые мы применяли, расположены были в мел-шкале, коэффициенты несут больше информации в диапазоне восприятия человеческого уха. Как правило, используют от 13 до 25 MFCC на фрейм. Поскольку помимо самого спектра индивидуальность голоса формируется скоростью и ускорениями, MFCC комбинируют с первой и второй производными.
Вообще, MFCC — это самый распространённый вариант работы с речью, но помимо них существуют и другие признаки — LPC (Linear Predictive Coding) и PLP (Perceptual Linear Prediction), а еще иногда можно встретить LFCC, где вместо мел-шкалы используется линейная.
Посмотрим, как извлечь MFCC в python.
Как видим, делается это действительно всего в несколько строк. Теперь перейдём к первому алгоритму кластеризации.
Модель смеси Гауссовых распределений предполагает что наши данные — это смесь многомерных распределений Гаусса с определёнными параметрами.
При желании можно легко найти и детальное описание модели и как работает EM-алгоритм, обучающий эту модель, я же обещал не наводить тоску сложными формулами и поэтому покажу красивые примеры из этой статьи.
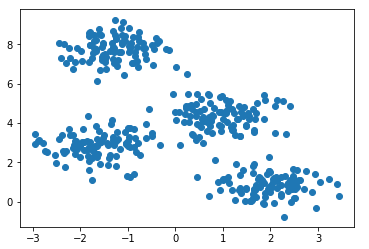
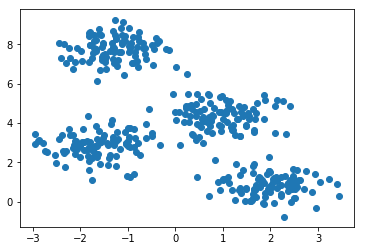
Сгенерируем четыре кластера и нарисуем их.
Создадим модель, обучим на наших данных и снова отрисуем точки но уже с учётом предсказанной моделью принадлежности к кластерам.
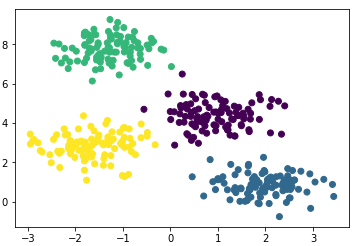
Модель неплохо справилась с искусственными данными. В принципе, регулируя число компонент смеси и тип матрицы ковариаций (число степеней свободы гауссиан), можно описывать достаточно сложные данные.
Итак, мы знаем как делать параметризацию данных и умеем обучать модель смеси гауссовых распределений. Теперь можно было бы попробовать сделать кластеризацию в лоб — обучая GMM на извлеченных из диалога MFCC. И, наверное, в каком-то идеальном сферически-вакуумном диалоге, в котором каждый диктор будет укладываться в свою гауссиану, мы получим хороший результат. Понятное дело, что в реальности такого никогда не будет. На самом деле с помощью GMM моделируют не диалог, а каждого человека в диалоге — т. е. представляют, что голос каждого диктора в извлечённых признаках описывается своим набором гауссиан.
Подытоживая, мы потихоньку подбираемся к основной теме.
Традиционно процесс диаризации состоит из трёх последовательных блоков — обнаружение речи (Voice Activity Detection), сегментация и кластеризация (есть модели, в которых последние два шага совмещены, см. LIA E-HMM).
В первом шаге происходит отделение речи от различного рода шумов. Алгоритм VAD определяет является ли поданный на него кусок аудиозаписи речью, или это, например, звучит сирена или кто-то чихнул. Понятное дело, что для того, чтобы такой алгоритм был качественным необходимо обучение с учителем. А это в свою очередь означает, что необходимо размечать данные — иными словами создавать базу данных с записями речи и всевозможных шумов. Мы поступим лениво — возьмём готовый VAD, который работает не идеально, но для начала нам хватит.
Второй блок нарезает данные с речью на сегменты с одним активным говорящим. Классическим подходом в этом плане является алгоритм определения смены диктора на основе байесовского информационного критерия — BIC. Суть этого метода заключается в следующем — скользящим окном проходятся по аудиозаписи и в каждой точке прохода отвечают на вопрос: «Как данные в этом месте лучше описываются — одним распределением или двумя?». Для ответа на этот вопрос вычисляется параметр , исходя из знака которого принимается решение о смене диктора. Проблема в том, что этот метод будет работать не очень хорошо в случае частой смены диктора, да еще в присутствии шумов (которые очень характерны для записи телефонного разговора).
, исходя из знака которого принимается решение о смене диктора. Проблема в том, что этот метод будет работать не очень хорошо в случае частой смены диктора, да еще в присутствии шумов (которые очень характерны для записи телефонного разговора).
В условиях, когда дикторы друг друга не перебивают, и их голоса не накладываются друг на друга, VAD, который мы будем использовать, более менее справляется с задачей сегментации, поэтому первые два шага у нас будут выглядеть следующим образом.
В действительности люди конечно будут говорить одновременно. Более того, VAD в некоторых местах сплоховал, из-за того, что запись не живая, а представляет собой склейку, в которой вырезаны паузы. Вы можете попробовать повторить нарезку на сегменты, увеличив агрессивность VAD'а с 2-х до 3-х.
Теперь у нас есть отдельные сегменты, и мы решили, что будем с помощью GMM моделировать каждого диктора. Извлечём признаки из сегмента и на этих данных обучим модель. Сделаем так на каждом сегменте и получившиеся модели сравним между собой. Вполне оправдано ожидать, что модели, обученные на сегментах, принадлежащих одному и тому же человеку, будут как-то схожи. Но тут мы сталкиваемся со следующей проблемой, извлекая признаки из аудиофайла длиной 1 сек с частотой дискретизации 8000 Гц при размере окна 10 мс, мы получим набор из 800 векторов MFCC. На таких данных наша модель обучиться не сможет, потому что это ничтожно мало. Даже, если это будет не одна секунда, а десять, данных все равно будет недостаточно. И здесь на помощь приходит Универсальная Фоновая Модель (UBM — Universal Background Model), её еще называют дикторонезависимой. Идея заключается в следующем. Мы обучим GMM на большой выборке данных (в нашем случае это полная запись интервью) и получим на выходе акустическую модель обобщённого диктора (это и будем наша UBM). А затем, используя специальный алгоритм адаптации (о нём чуть ниже), мы будем «подгонять» эту модель под признаки, извлекаемые из каждого сегмента. Этот подход широко используется не только для диаризации, но и в системах распознавания по голосу. Для распознания человека по голосу сначала нужно обучить модель на нём и без UBM нужно было бы иметь в распоряжении по несколько часов записи речи этого человека.
Из каждой адаптированной GMM мы извлечём вектор коэффициентов сдвига (он же медиана или мат. ожидание, если угодно) и, основываясь, на данных об этих векторах со всех сегментов, будем делать кластеризацию (ниже будет понятно почему именно вектор сдвигов).
(он же медиана или мат. ожидание, если угодно) и, основываясь, на данных об этих векторах со всех сегментов, будем делать кластеризацию (ниже будет понятно почему именно вектор сдвигов).
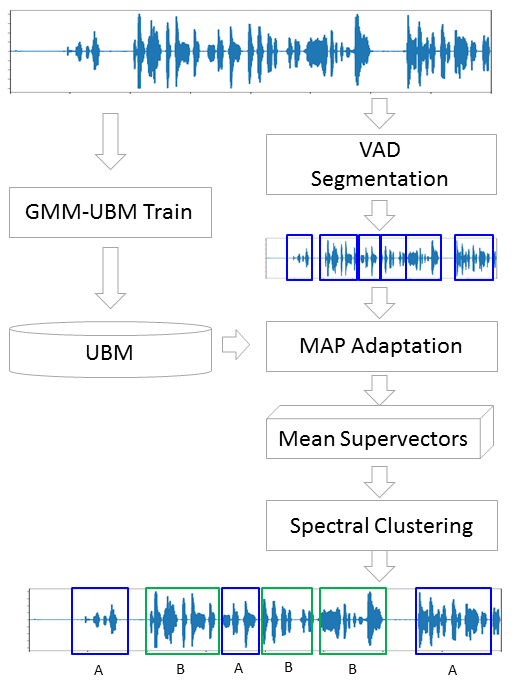
Метод, которым мы будем подгонять UBM под каждый сегмент называется Maximum A-Posteriori Adaptation. В общем случае алгоритм следующий. Сначала рассчитывается апостериорная вероятность на адаптационных данных и достаточные статистики для веса, медианы и дисперсии каждой гауссианы. Затем полученные статистики комбинируются с параметрами UBM и получаются параметры адаптированной модели. В нашем случае мы будем адаптировать только медианы, не затрагивая остальных параметров. Не смотря на то, что обещал не углубляться в математику, приведу всё-таки три формулы, потому что MAP адаптация — ключевой момент в этой статье.
Здесь — апостериорная вероятность,
— апостериорная вероятность,  — достаточная статистика для ,
— достаточная статистика для ,  — медиана адаптированной модели,
— медиана адаптированной модели,  — коэффициент адаптации,
— коэффициент адаптации,  — фактор соответствия.
— фактор соответствия.
Если все это кажется белибердой и вызывает уныние — не отчаивайтесь. На самом деле для понимания работы алгоритма необязательно вникать в эти формулы, его работу легко можно продемонстрировать следующим примером:

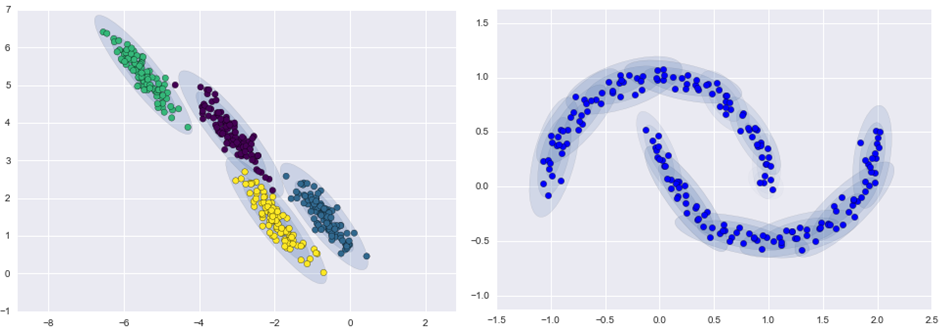
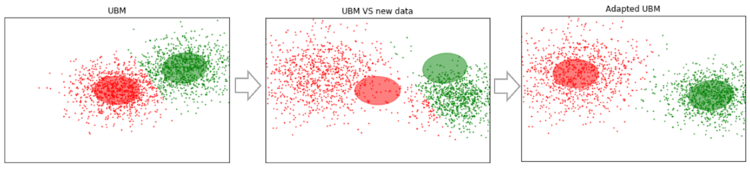
Допустим у нас есть какие-то достаточно большие данные, и мы обучили на них UBM (левый рисунок, UBM — это двухкомпонентная смесь гауссовых распределений). Появляются новые данные, которые не укладываются в нашу модель (рисунок посередине). С помощью указанного алгоритма мы будем смещать центры гауссиан так, чтобы они ложились на новые данные (рисунок справа). Применяя этот алгоритм на экспериментальных данных, мы будем ожидать, что на сегментах с одним и тем же диктором гауссианы будут смещаться в одном направлении, образуя таким образом кластеры. Именно поэтому для кластеризации сегментов мы будем использовать данные о сдвиге.
Итак, давайте проведём MAP адаптацию для каждого сегмента. (Для справки: помимо MAP Adaptation широко используется метод MLLR — Maximum Likelihood Linear Regression и некоторые его модификации. Также пробуют эти два метода объединять.)
Теперь, когда для каждого сегмента у нас есть данные о, мы наконец переходим к финальному шагу.
Спектральная кластеризация вкратце описана в статье, ссылку на которую я приводил в самом начале. Алгоритм строит полный граф, где вершины — это наши данные, а рёбра между ними — это мера схожести. В задачах распознавания голоса в качестве такой меры используется косинусная метрика, поскольку она учитывает угол между векторами, игнорируя их магнитуду (которая не несёт информации о дикторе). Построив граф, рассчитываются собственные векторы матрицы Кирхгофа (которая по сути является представлением полученного графа) и затем применяется какой-нибудь стандартный метод кластеризации, например метод k-средних. Укладывается всё это в две строчки кода
Описанный алгоритм был опробован с различными параметрами:
В итоге, субъективно оптимальным остались параметры: MFCC 13, GMM covariance_type = 'full' n_components = 16.
К сожалению, у меня не хватило терпения (эту статью я начал писать больше месяца назад) для того, чтобы разметить полученные сегменты и посчитать DER (Diariztion Error Rate). Субъективно работу алгоритма я оцениваю как «в принципе неплохо, но далеко от идеала». Сделав кластеризацию на векторах, полученных из первой сотни сегментов (с одним проходом MAP), а затем выделив те, где говорит интервьюер (девушка, она там говорит гораздо меньше гостя), кластеризация выдаёт список![$[1, 2, 25, 26, 46, 48, 49, 61, 85, 86]$](https://habrastorage.org/getpro/habr/formulas/b5f/5b8/c96/b5f5b8c962e564d107227d8156c32384.svg) , что является 100% попаданием. При этом выпадают сегменты, где присутствуют оба диктора (например 14), но это уже можно свалить на ошибку VAD'а. Причём такие сегменты начинают учитываться с увеличением числа проходов MAP. Важный момент. Интервью, с которым мы работали — более менее «чистое». Если добавляются различные музыкальные вставки, шумы и прочие неречевые штуки, кластеризация начинает хромать. Поэтому в планах попробовать обучить собственный VAD (потому что webrtcvad, например, не отделяет музыку от речи).
, что является 100% попаданием. При этом выпадают сегменты, где присутствуют оба диктора (например 14), но это уже можно свалить на ошибку VAD'а. Причём такие сегменты начинают учитываться с увеличением числа проходов MAP. Важный момент. Интервью, с которым мы работали — более менее «чистое». Если добавляются различные музыкальные вставки, шумы и прочие неречевые штуки, кластеризация начинает хромать. Поэтому в планах попробовать обучить собственный VAD (потому что webrtcvad, например, не отделяет музыку от речи).
В связи с тем, что изначально я работал с телефонным разговором, у меня не было необходимости оценивать количество дикторов. Но не всегда количество дикторов предопределено, даже если это интервью. Например в этом интервью в середине звучит анонс, наложенный на музыку, и озвученный дополнительными двумя людьми. Поэтому интересно было бы попробовать метод оценки количества дикторов, указанный в первой статье в разделе списка литературы (основанный на анализе собственных значений нормализованной матрицы Лапласа).
Помимо материалов, расположенных по ссылкам в тексте и Jupyter ноутбуках, для подготовки этой статьи были использованы следующие источники:
Добавлю также некоторые проекты по диаризации:
Весь код выложен на гитхабе. Для удобства я сделал несколько Jupyter ноутбуков с демонстрацией отдельных вещей — MFCC, GMM, MAP Adaptation и Diarization. В последнем находится основной процесс. Также в репозитории pickle-файлы с некоторыми предобученными моделями и само интервью.
Готовясь написать эту статью, я выбирал между двумя вариантами изложения: для тех, кто уже знаком с Data Science и тех, кто просто хорошо программирует. В итоге я выбрал второй вариант, решив, что это будет неплохой демонстрацией возможностей DS.
Постановка задачи
Как говорит нам Википедия, диаризация — это процесс разделения входящего аудиопотока на однородные сегменты в соответствии с принадлежностью аудиопотока тому или иному говорящему. Иными словами, запись нужно разделить на кусочки и пронумеровать: вот в этих местах говорит один человек, а вот в этих другой. С точки зрения машинного обучения, подобного рода задачи принадлежат к классу обучения без учителя и называются кластеризацией. О том, какие методы кластеризации существуют можно почитать например здесь или здесь, я же рассажу только о тех, которые нам пригодятся — это Гауссова Смесь Распределений (Gaussian Mixture Model) и Спектральная Кластеризация (Spectral Clustering). Но о них чуть позже.
Начнём с самого начала.
Подготовка окружения
Спойлер
Не был уверен, стоит ли оставлять этот раздел — не хотелось превращать статью в совсем уж туториал. Но в итоге оставил. Кому не нужно, тот пропустит, а тем, кто будет делать всё с нуля, этот шаг облегчит старт.
Вообще говоря, помимо R, язык python является основным при решении задач Data Science, и если вы еще не пробовали программировать на нём, то я очень рекомендую это сделать, потому что python позволяет сделать многие вещи изящно, буквально в несколько строк (кстати, есть даже такой мем).
Существуют две отдельно развивающиеся ветки питона — версии 2 и 3. В моих примерах я использовал версию 3.6, но при желании их легко можно портировать на версию 2.7. Любую из этих веток удобно разворачивать вместе с инсталятором Анаконда, установив который вы сразу же получите интерактивную оболочку для разработки — IPython.
Помимо самой среды разработки понадобятся дополнительные библиотеки: librosa (для работы с аудио и извлечением признаков), webrtcvad (для сегментации) и pickle (для записи обученных моделей в файл). Все они устанавливаются простой командой в Anaconda Prompt
pip install [library]Feature Extraction
Начнём с извлечения признаков — данных, с которыми будут работать модели машинного обучения. В принципе, звуковой сигнал сам по себе — это уже данные, а именно упорядоченный массив значений амплитуды звука, к которому добавляется заголовок, содержащий количество каналов, частоту дискретизации и прочую информацию. Но анализировать эти данные напрямую мы не сможем, поскольку они не содержат таких вещей, глядя на которые, наша модель может сказать — ага, вот эти куски принадлежат одному и тому же человеку.
В задачах обработки речи существует несколько подходов к извлечению признаков. Одним из них является получение мел-частотных кепстральных коэффициентов (Mel Frequency Cepstral Coefficients). О них здесь уже писали, поэтому я лишь слегка напомню.
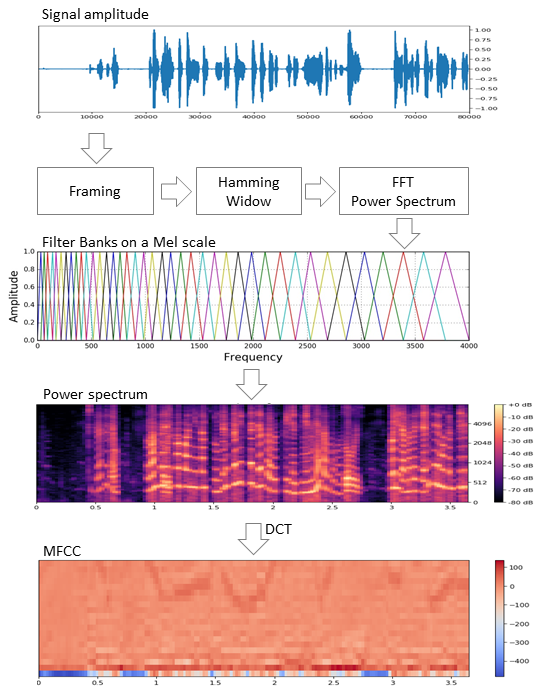
Исходный сигнал нарезают на фреймы длиной 16-40 мс. Далее, применив к фрейму окно Хемминга, делают быстрое преобразование Фурье и получают спектральную плотность мощности. Затем специальной «гребёнкой» фильтров, расположенных равномерно по мел-шкале делают мел-спектрограмму, к которой применяют дискретное косинусное преобразование (DCT) — широко используемый алгоритм сжатия данных. Полученные таким образом коэффициенты представляют из себя некую сжатую характеристику фрейма, при этом, поскольку фильтры, которые мы применяли, расположены были в мел-шкале, коэффициенты несут больше информации в диапазоне восприятия человеческого уха. Как правило, используют от 13 до 25 MFCC на фрейм. Поскольку помимо самого спектра индивидуальность голоса формируется скоростью и ускорениями, MFCC комбинируют с первой и второй производными.
Вообще, MFCC — это самый распространённый вариант работы с речью, но помимо них существуют и другие признаки — LPC (Linear Predictive Coding) и PLP (Perceptual Linear Prediction), а еще иногда можно встретить LFCC, где вместо мел-шкалы используется линейная.
Посмотрим, как извлечь MFCC в python.
import numpy as np
import librosa
mfcc=librosa.feature.mfcc(y=y, sr=sr,
hop_length=int(hop_seconds*sr),
n_fft=int(window_seconds*sr),
n_mfcc=n_mfcc)
mfcc_delta=librosa.feature.delta(mfcc)
mfcc_delta2=librosa.feature.delta(mfcc, order=2)
stacked=np.vstack((mfcc, mfcc_delta, mfcc_delta2))
features=stacked.T #librosa возвращает где MFCC идут в ряд, а для модели нужно будет в столбец.
Как видим, делается это действительно всего в несколько строк. Теперь перейдём к первому алгоритму кластеризации.
Gaussian Mixture Model
Модель смеси Гауссовых распределений предполагает что наши данные — это смесь многомерных распределений Гаусса с определёнными параметрами.
При желании можно легко найти и детальное описание модели и как работает EM-алгоритм, обучающий эту модель, я же обещал не наводить тоску сложными формулами и поэтому покажу красивые примеры из этой статьи.
Сгенерируем четыре кластера и нарисуем их.
from sklearn.datasets.samples_generator import make_blobs
X, y_true=make_blobs(n_samples=400, centers=4,
cluster_std=0.60, random_state=0)
plt.scatter(X[:, 0], X[:, 1]);
Создадим модель, обучим на наших данных и снова отрисуем точки но уже с учётом предсказанной моделью принадлежности к кластерам.
from sklearn.mixture import GaussianMixture
gmm = GaussianMixture(n_components=4)
gmm.fit(X)
labels=gmm.predict(X)
plt.scatter(X[:, 0], X[:, 1], c=labels, s=40, cmap='viridis');
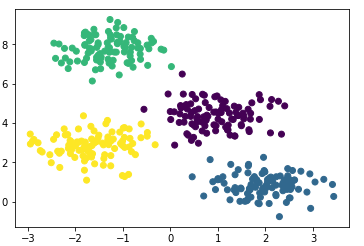
Модель неплохо справилась с искусственными данными. В принципе, регулируя число компонент смеси и тип матрицы ковариаций (число степеней свободы гауссиан), можно описывать достаточно сложные данные.

Итак, мы знаем как делать параметризацию данных и умеем обучать модель смеси гауссовых распределений. Теперь можно было бы попробовать сделать кластеризацию в лоб — обучая GMM на извлеченных из диалога MFCC. И, наверное, в каком-то идеальном сферически-вакуумном диалоге, в котором каждый диктор будет укладываться в свою гауссиану, мы получим хороший результат. Понятное дело, что в реальности такого никогда не будет. На самом деле с помощью GMM моделируют не диалог, а каждого человека в диалоге — т. е. представляют, что голос каждого диктора в извлечённых признаках описывается своим набором гауссиан.
Подытоживая, мы потихоньку подбираемся к основной теме.
Сегментация
Традиционно процесс диаризации состоит из трёх последовательных блоков — обнаружение речи (Voice Activity Detection), сегментация и кластеризация (есть модели, в которых последние два шага совмещены, см. LIA E-HMM).
В первом шаге происходит отделение речи от различного рода шумов. Алгоритм VAD определяет является ли поданный на него кусок аудиозаписи речью, или это, например, звучит сирена или кто-то чихнул. Понятное дело, что для того, чтобы такой алгоритм был качественным необходимо обучение с учителем. А это в свою очередь означает, что необходимо размечать данные — иными словами создавать базу данных с записями речи и всевозможных шумов. Мы поступим лениво — возьмём готовый VAD, который работает не идеально, но для начала нам хватит.
Второй блок нарезает данные с речью на сегменты с одним активным говорящим. Классическим подходом в этом плане является алгоритм определения смены диктора на основе байесовского информационного критерия — BIC. Суть этого метода заключается в следующем — скользящим окном проходятся по аудиозаписи и в каждой точке прохода отвечают на вопрос: «Как данные в этом месте лучше описываются — одним распределением или двумя?». Для ответа на этот вопрос вычисляется параметр
, исходя из знака которого принимается решение о смене диктора. Проблема в том, что этот метод будет работать не очень хорошо в случае частой смены диктора, да еще в присутствии шумов (которые очень характерны для записи телефонного разговора).Небольшое пояснение
В оригинале я работал с записями телефонных разговоров кол-центра средней продолжительностью около 4-х минут. По понятным причинам эти записи я выложить не могу, поэтому для демонстрации я взял запись интервью с одной радиостанции. В случае с длинным интервью этот метод возможно дал бы приемлемый результат, но на моих данных он не сработал.
В условиях, когда дикторы друг друга не перебивают, и их голоса не накладываются друг на друга, VAD, который мы будем использовать, более менее справляется с задачей сегментации, поэтому первые два шага у нас будут выглядеть следующим образом.
#читаем сигнал
y_, sr = librosa.load('data/2018-08-26-beseda-1616.mp3', sr=SR)
#первым шагом делаем pre-emphasis: усиление высоких частот
pre_emphasis = 0.97
y = np.append(y[0], y[1:] - pre_emphasis * y[:-1])
#все что ниже фактически взято с гитхаба webrtcvad с небольшими изменениями
vad = webrtcvad.Vad(2) # агрессивность VAD
audio = np.int16(y/np.max(np.abs(y)) * 32767)
frames = frame_generator(10, audio, sr)
frames = list(frames)
segments = vad_collector(sr, 50, 200, vad, frames)
if not os.path.exists('data/chunks'): os.makedirs('data/chunks')
for i, segment in enumerate(segments):
chunk_name = 'data/chunks/chunk-%003d.wav' % (i,)
# vad добавляет в конце небольшой кусочек тишины, который нам не нужен
write_wave(chunk_name, segment[0: len(segment)-int(100*sr/1000)], sr)
В действительности люди конечно будут говорить одновременно. Более того, VAD в некоторых местах сплоховал, из-за того, что запись не живая, а представляет собой склейку, в которой вырезаны паузы. Вы можете попробовать повторить нарезку на сегменты, увеличив агрессивность VAD'а с 2-х до 3-х.
GMM-UBM
Теперь у нас есть отдельные сегменты, и мы решили, что будем с помощью GMM моделировать каждого диктора. Извлечём признаки из сегмента и на этих данных обучим модель. Сделаем так на каждом сегменте и получившиеся модели сравним между собой. Вполне оправдано ожидать, что модели, обученные на сегментах, принадлежащих одному и тому же человеку, будут как-то схожи. Но тут мы сталкиваемся со следующей проблемой, извлекая признаки из аудиофайла длиной 1 сек с частотой дискретизации 8000 Гц при размере окна 10 мс, мы получим набор из 800 векторов MFCC. На таких данных наша модель обучиться не сможет, потому что это ничтожно мало. Даже, если это будет не одна секунда, а десять, данных все равно будет недостаточно. И здесь на помощь приходит Универсальная Фоновая Модель (UBM — Universal Background Model), её еще называют дикторонезависимой. Идея заключается в следующем. Мы обучим GMM на большой выборке данных (в нашем случае это полная запись интервью) и получим на выходе акустическую модель обобщённого диктора (это и будем наша UBM). А затем, используя специальный алгоритм адаптации (о нём чуть ниже), мы будем «подгонять» эту модель под признаки, извлекаемые из каждого сегмента. Этот подход широко используется не только для диаризации, но и в системах распознавания по голосу. Для распознания человека по голосу сначала нужно обучить модель на нём и без UBM нужно было бы иметь в распоряжении по несколько часов записи речи этого человека.
Из каждой адаптированной GMM мы извлечём вектор коэффициентов сдвига
(он же медиана или мат. ожидание, если угодно) и, основываясь, на данных об этих векторах со всех сегментов, будем делать кластеризацию (ниже будет понятно почему именно вектор сдвигов).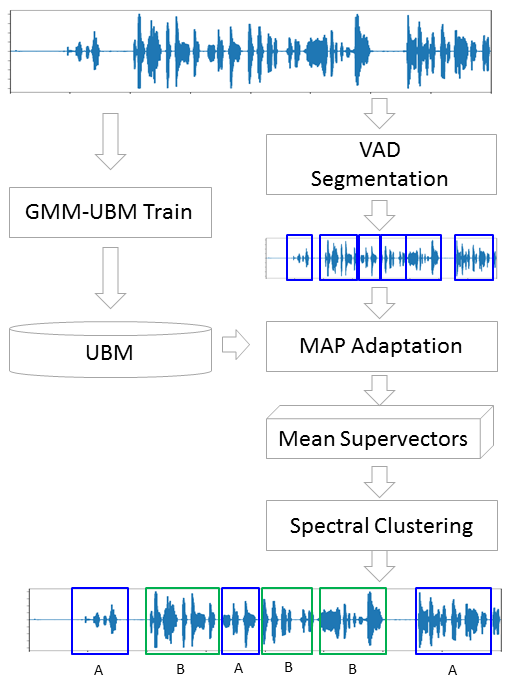
MAP Adaptation
Метод, которым мы будем подгонять UBM под каждый сегмент называется Maximum A-Posteriori Adaptation. В общем случае алгоритм следующий. Сначала рассчитывается апостериорная вероятность на адаптационных данных и достаточные статистики для веса, медианы и дисперсии каждой гауссианы. Затем полученные статистики комбинируются с параметрами UBM и получаются параметры адаптированной модели. В нашем случае мы будем адаптировать только медианы, не затрагивая остальных параметров. Не смотря на то, что обещал не углубляться в математику, приведу всё-таки три формулы, потому что MAP адаптация — ключевой момент в этой статье.



Здесь
— апостериорная вероятность, — достаточная статистика для , — медиана адаптированной модели, — коэффициент адаптации, — фактор соответствия.Если все это кажется белибердой и вызывает уныние — не отчаивайтесь. На самом деле для понимания работы алгоритма необязательно вникать в эти формулы, его работу легко можно продемонстрировать следующим примером:
Допустим у нас есть какие-то достаточно большие данные, и мы обучили на них UBM (левый рисунок, UBM — это двухкомпонентная смесь гауссовых распределений). Появляются новые данные, которые не укладываются в нашу модель (рисунок посередине). С помощью указанного алгоритма мы будем смещать центры гауссиан так, чтобы они ложились на новые данные (рисунок справа). Применяя этот алгоритм на экспериментальных данных, мы будем ожидать, что на сегментах с одним и тем же диктором гауссианы будут смещаться в одном направлении, образуя таким образом кластеры. Именно поэтому для кластеризации сегментов мы будем использовать данные о сдвиге
.Итак, давайте проведём MAP адаптацию для каждого сегмента. (Для справки: помимо MAP Adaptation широко используется метод MLLR — Maximum Likelihood Linear Regression и некоторые его модификации. Также пробуют эти два метода объединять.)
SV = []
# возьмём сегменты от chunk-000 до chunk-100
for i in range(101):
clear_output(wait=True)
fname='data/chunks/chunk-%003d.wav' % (i,)
print('UBM MAP adaptation for {0}'.format(fname))
y_, sr_ = librosa.load(fname, sr=None)
f_ = extract_features(y_, sr_, window=N_FFT, hop=HOP_LENGTH, n_mfcc=N_MFCC)
f_ = preprocessing.scale(f_)
gmm = copy.deepcopy(ubm)
gmm = map_adaptation(gmm, f_, max_iterations=1, relevance_factor=16)
sv = gmm.means_.flatten() #получаем супервектор мю
sv = preprocessing.scale(sv)
SV.append(sv)
SV = np.array(SV)
clear_output()
print(SV.shape)
Теперь, когда для каждого сегмента у нас есть данные о
, мы наконец переходим к финальному шагу.Спектральная кластеризация
Спектральная кластеризация вкратце описана в статье, ссылку на которую я приводил в самом начале. Алгоритм строит полный граф, где вершины — это наши данные, а рёбра между ними — это мера схожести. В задачах распознавания голоса в качестве такой меры используется косинусная метрика, поскольку она учитывает угол между векторами, игнорируя их магнитуду (которая не несёт информации о дикторе). Построив граф, рассчитываются собственные векторы матрицы Кирхгофа (которая по сути является представлением полученного графа) и затем применяется какой-нибудь стандартный метод кластеризации, например метод k-средних. Укладывается всё это в две строчки кода
N_CLUSTERS = 2
sc = SpectralClustering(n_clusters=N_CLUSTERS, affinity='cosine')
labels = sc.fit_predict(SV) # кластеры могут быть не упорядочены, напр. [2,1,1,0,2]
labels = rearrange(labels, N_CLUSTERS) # эта функция упорядочивает кластеры [0,1,1,2,0]
print(labels)
# глядя на результат, понимаем, что 1 - это интервьюер. выведем все номера сегментов
print([i for i, x in enumerate(labels) if x == 1])
Выводы и дальнейшие планы
Описанный алгоритм был опробован с различными параметрами:
- Количество MFCC: 7, 13, 20
- MFCC в комбинации с LPC
- Тип и количество смесей в GMM: full [8, 16, 32], diag [8, 16, 32, 64, 256]
- Методы адаптации UBM: MAP (с covariance_type = 'full') и MLLR (с covariance_type = 'diag')
В итоге, субъективно оптимальным остались параметры: MFCC 13, GMM covariance_type = 'full' n_components = 16.
К сожалению, у меня не хватило терпения (эту статью я начал писать больше месяца назад) для того, чтобы разметить полученные сегменты и посчитать DER (Diariztion Error Rate). Субъективно работу алгоритма я оцениваю как «в принципе неплохо, но далеко от идеала». Сделав кластеризацию на векторах, полученных из первой сотни сегментов (с одним проходом MAP), а затем выделив те, где говорит интервьюер (девушка, она там говорит гораздо меньше гостя), кластеризация выдаёт список
, что является 100% попаданием. При этом выпадают сегменты, где присутствуют оба диктора (например 14), но это уже можно свалить на ошибку VAD'а. Причём такие сегменты начинают учитываться с увеличением числа проходов MAP. Важный момент. Интервью, с которым мы работали — более менее «чистое». Если добавляются различные музыкальные вставки, шумы и прочие неречевые штуки, кластеризация начинает хромать. Поэтому в планах попробовать обучить собственный VAD (потому что webrtcvad, например, не отделяет музыку от речи).В связи с тем, что изначально я работал с телефонным разговором, у меня не было необходимости оценивать количество дикторов. Но не всегда количество дикторов предопределено, даже если это интервью. Например в этом интервью в середине звучит анонс, наложенный на музыку, и озвученный дополнительными двумя людьми. Поэтому интересно было бы попробовать метод оценки количества дикторов, указанный в первой статье в разделе списка литературы (основанный на анализе собственных значений нормализованной матрицы Лапласа).
Список литературы
Помимо материалов, расположенных по ссылкам в тексте и Jupyter ноутбуках, для подготовки этой статьи были использованы следующие источники:
- Speaker Diarization using GMM Supervector and Advanced Reduction Algorithms. Nurit Spingarn
- Feature Extraction Methods LPC, PLP and MFCC In Speech Recognition. Namrata Dave
- MAP estimation for mulivariate gaussian mixture observations of markov chains. Jean-Luc Gauvain and Chin-Hui Lee
- On Spectral Clustering Analysis and an algorithm. Andrew Y. Ng, Michael I. Jordan, Yair Weiss
- Speaker recognition using universal background model on YOHO database. Alexandre Majetniak
Добавлю также некоторые проекты по диаризации:
- Sidekit и расширение для диаризации s4d. Библиотека на python для работы с речью. К сожалению, документация оставляет желать лучшего.
- Bob и разные её части как например bob.bio, bob.learn.em — библиотека на python для обработки сигнала и работы с биометрическими данными. Windows не поддерживается.
- LIUM — готовое решение, написанное на Java.
Весь код выложен на гитхабе. Для удобства я сделал несколько Jupyter ноутбуков с демонстрацией отдельных вещей — MFCC, GMM, MAP Adaptation и Diarization. В последнем находится основной процесс. Также в репозитории pickle-файлы с некоторыми предобученными моделями и само интервью.
