Всем привет!
Наш эксперимент со ступенями по курсу «Разработчик Java» продолжается и, как ни странно, даже вполне успешно (вроде): как оказалось, что плечо планирования в пару месяцев со следующим переходом на новую ступень в любое удобное время — это куда удобнее, чем если выделять практически полгода на такой сложный курс. Так что есть подозрение, что именно сложные курсы мы скоро начнём потихоньку переводить на такую систему.
Но это я о нашем, об отусовском, извините. Как всегда мы продолжаем изучение интересных тем, которые хоть и не затрагиваются в нашей программе, но которые обсуждаются у нас — поэтому на один из вопросов, что задавался нашим преподавателям, мы подготовили перевод наиболее интересной на наш взгляд статьи.
Поехали!

Коллекции в JDK являются стандартными библиотечными реализациями списков и мап. Если вы посмотрите на снимок памяти типичного большого приложения, написанного на Java, вы увидите тысячи или даже миллионы экземпляров
Во-первых, нужно отметить, что внутренние коллекции JDK — это не какая-то магия. Они написаны на Java. Их исходный код поставляется вместе с JDK, поэтому вы можете открыть его в своей IDE. Их код также можно легко найти в интернете. И, как выясняется, большинство коллекций не очень изящны в плане оптимизации объема потребляемой памяти.
Рассмотрим, например, одну из самых простых и самых популярных коллекций — класс
Когда вы создаете
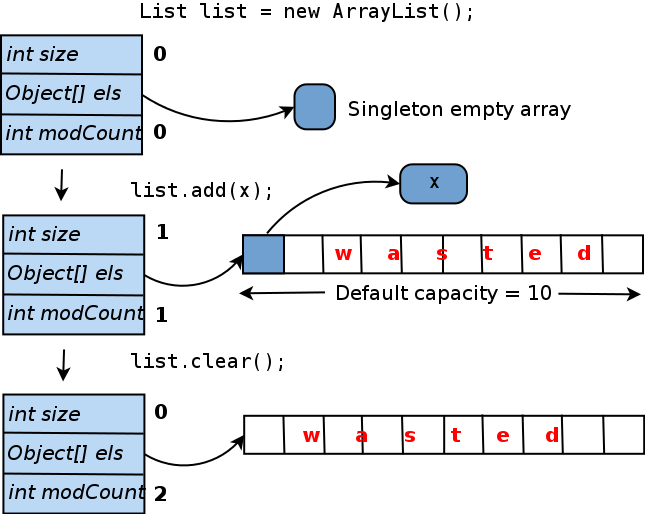
Сколько памяти здесь потрачено впустую? В абсолютных значениях она рассчитывается как (размер указателя объекта). Если вы используете JVM HotSpot (который поставляется с Oracle JDK), размер указателя будет зависеть от максимального размера кучи (для более подробной информации см. https://blog.codecentric.de/ru/2014/02/35gb-heap-less-32gb-java-jvm-memory-oddities/). Обычно, если вы укажете
На самом деле, пустой
Рассмотрим еще один часто встречающуюся коллекцию — класс

Как вы можете видеть,
Если вы обнаружили неиспользуемые или малоиспользуемые коллекции в своем приложении, как их исправить? Ниже приведены некоторые распространенные рецепты. Здесь предполагается, что наша проблемная коллекция —
Если большинство экземпляров списка никогда не используются, попробуйте инициализировать его лениво. Таким образом, код, который ранее выглядел как…
… должен быть переделан в нечто вроде
Имейте в виду, что вам иногда потребуется принять дополнительные меры для решения возможных конкуренций. Например, если вы поддерживаете
Если большинство экземпляров вашего списка или мапы содержат только несколько элементов, попробуйте инициализировать их с более подходящей начальной емкостью, например.
Если ваши коллекции пусты или содержат только один элемент (или пару «ключ-значение») в большинстве случаев, вы сможете рассмотреть одну крайнюю форму оптимизации. Она работает только в том случае, если коллекция полностью управляется в пределах текущего класса, то есть другой код не может получить к нему доступ напрямую. Идея состоит в том, что вы меняете тип своего поля данных, например, из List в более общий Object, чтобы теперь он мог указывать либо на реальный список, либо непосредственно на единственный элемент списка. Вот краткий эскиз:
Очевидно, что код с такой оптимизацией менее понятен и его сложнее поддерживать. Но это может оказаться полезным, если вы уверены, что таким образом сэкономите много памяти или избавитесь от длинных пауз сборщика мусора.
Вы вероятно уже задумались: откуда же я узнаю, какие коллекции в моем приложении перерасходуют память и сколько?
Если коротко: это трудно узнать без правильных инструментов. Попытка угадать объем используемой или потраченной структурами данных памяти в большом сложном приложении почти никогда ни к чему не приведёт. И, не зная точно, куда уходит память, вы можете потратить много времени в погоне за неправильными целями, в то время как ваше приложение упорно продолжает падать с
По этому, вам следует проверить кучу приложения с помощью специального инструмента. По опыту, наиболее оптимальным способом анализа памяти JVM (измеряется как количество доступной информации в сравнении с воздействием этого инструмента на производительность приложения) — это получить дамп кучи, а затем просмотреть его в автономном режиме. Дамп кучи — это, по сути, полный снимок кучи. Его можно получить в любой момент, вызвав утилиту jmap, либо можно настроить JVM для автоматического создания дампа, если приложение падает с
Дамп кучи — это двоичный файл размером с кучу JVM, поэтому его можно читать и анализировать только с помощью специальных инструментов. Существует несколько таких инструментов, как с открытым исходным кодом, так и коммерческие. Наиболее популярным инструментом с открытым исходным кодом является Eclipse MAT; есть также VisualVM и некоторые менее мощные и менее известные инструменты. Коммерческие инструменты включают профилировщики Java общего назначения: JProfiler и YourKit, а также один инструмент, созданный специально для анализа дампа кучи — JXRay (дисклеймер: последнее разработал автор).
В отличие от других инструментов, JXRay сразу анализирует дамп кучи на наличие большого количества распространенных проблем, таких как повторяющиеся строки и другие объекты, а также недостаточно эффективные структуры данных. Проблемы с описанными выше коллекциями относятся к последней категории. Инструмент генерирует отчет со всей собранной информацией в формате HTML. Преимущество такого подхода заключается в том, что вы можете просматривать результаты анализа в любом месте в любое время и легко делиться ими с другими. Вы также можете запускать инструмент на любой машине, включая большие и мощные, но «безголовые» машины в центре обработки данных.
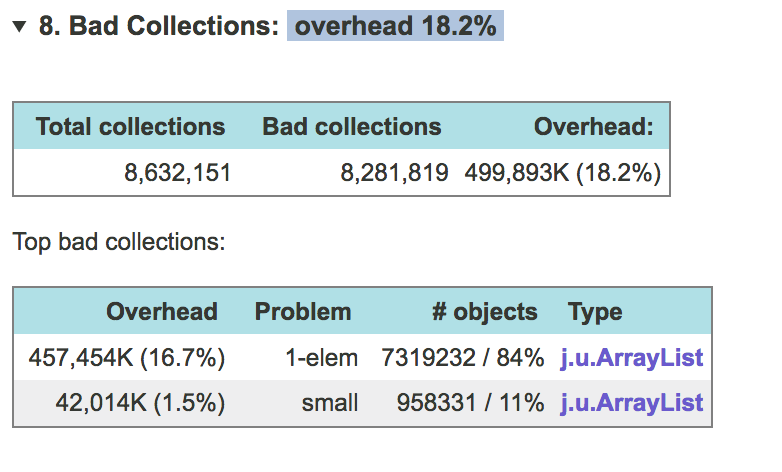
JXRay вычисляет оверхэд (сколько памяти вы сэкономите, если избавитесь от конкретной проблемы) в байтах и в процентах от используемой кучи. Он объединяет коллекции одного и того же класса, которые имеют одинаковую проблему…
… и затем группирует проблемные коллекции, которые доступны из некоторого корня сборщика мусора через одну и ту же цепочку ссылок, как в примере ниже
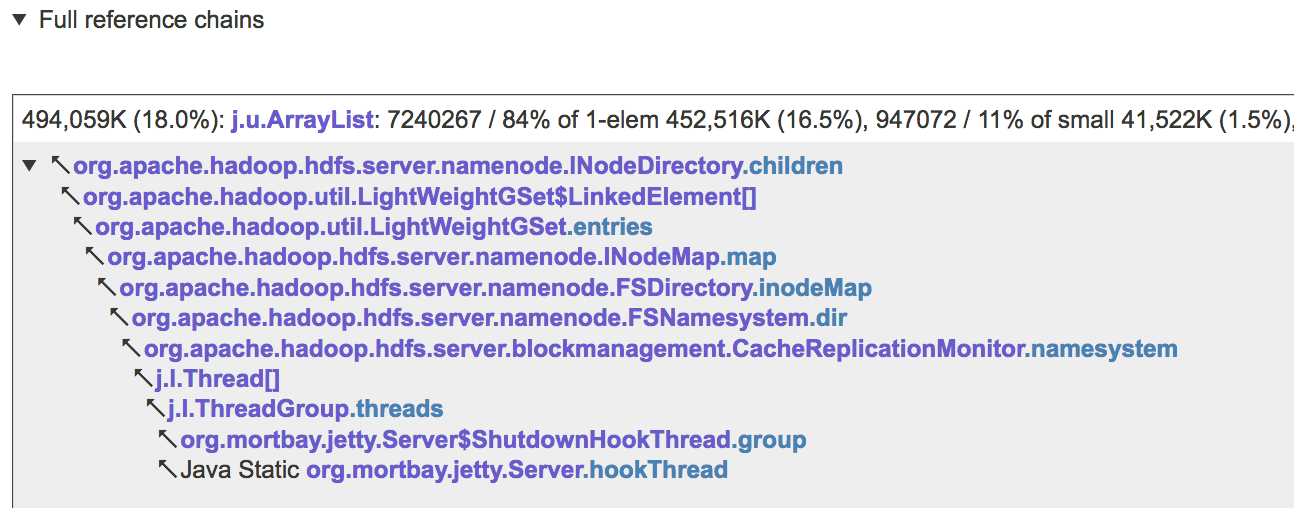
Знание о том, какие цепочки ссылок и/или отдельные поля данных (например,
Таким образом, недостаточно эффективно настроенные Java-коллекции могут тратить много памяти. Во многих ситуациях эту проблему легко решить, но иногда вам может потребоваться изменить свой код нетривиальными способами для достижения значительного улучшения. Очень сложно угадать, какие коллекции нужно оптимизировать, чтобы оказать наибольшее влияние. Чтобы не тратить время на оптимизацию не тех частей кода, вам нужно получить дамп кучи JVM и проанализировать его с помощью соответствующего инструмента.
THE END
Нам, как всегда, интересны ваши мнения и вопросы, которые вы можете оставить тут или заскочить на открытый урок и поспрашивать наших преподавателей там.
Наш эксперимент со ступенями по курсу «Разработчик Java» продолжается и, как ни странно, даже вполне успешно (вроде): как оказалось, что плечо планирования в пару месяцев со следующим переходом на новую ступень в любое удобное время — это куда удобнее, чем если выделять практически полгода на такой сложный курс. Так что есть подозрение, что именно сложные курсы мы скоро начнём потихоньку переводить на такую систему.
Но это я о нашем, об отусовском, извините. Как всегда мы продолжаем изучение интересных тем, которые хоть и не затрагиваются в нашей программе, но которые обсуждаются у нас — поэтому на один из вопросов, что задавался нашим преподавателям, мы подготовили перевод наиболее интересной на наш взгляд статьи.
Поехали!

Коллекции в JDK являются стандартными библиотечными реализациями списков и мап. Если вы посмотрите на снимок памяти типичного большого приложения, написанного на Java, вы увидите тысячи или даже миллионы экземпляров
java.util.ArrayList, java.util.HashMap и т. д. Коллекции незаменимы для хранения данных и манипулирования ими. Но думали ли вы когда-нибудь о том, все ли коллекции в вашем приложении оптимально используют память? Иначе говоря, если ваше приложение падает с постыдным OutOfMemoryError или вызывает длительные паузы сборщика мусора, проверяли ли вы когда-нибудь использованные коллекции на наличие утечек.Во-первых, нужно отметить, что внутренние коллекции JDK — это не какая-то магия. Они написаны на Java. Их исходный код поставляется вместе с JDK, поэтому вы можете открыть его в своей IDE. Их код также можно легко найти в интернете. И, как выясняется, большинство коллекций не очень изящны в плане оптимизации объема потребляемой памяти.
Рассмотрим, например, одну из самых простых и самых популярных коллекций — класс
java.util.ArrayList. Внутри каждый ArrayList оперирует массивом Object[] elementData. Именно здесь хранятся элементы списка. Посмотрим, как этот массив обрабатывается.Когда вы создаете
ArrayList конструктором по умолчанию, то есть вызываете new ArrayList(), elementData указывает на общий массив нулевого размера (elementData также может быть установлен в null, но массив обеспечивает некоторые незначительные преимущества реализации). Когда вы добавляете первый элемент в список, создается реальный уникальный массив elementData, и предоставленный объект вставляется в него. Для того, чтобы избежать изменения размера массива каждый раз, при добавлении нового элемента, он создается с длиной равной 10 («емкость по умолчанию»). Вот и получается: если вы больше не добавите элементы в этот ArrayList, 9 из 10 слотов в массиве elementData останутся пустыми. И даже если вы очистите список, размер внутреннего массива не сократится. Ниже приведена диаграмма этого жизненного цикла: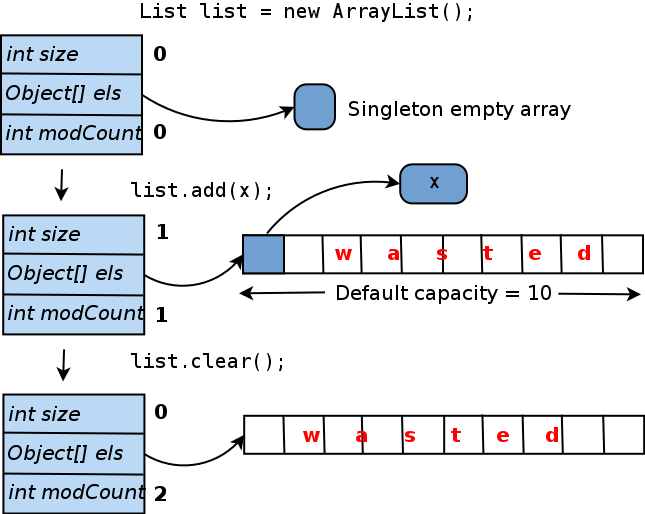
Сколько памяти здесь потрачено впустую? В абсолютных значениях она рассчитывается как (размер указателя объекта). Если вы используете JVM HotSpot (который поставляется с Oracle JDK), размер указателя будет зависеть от максимального размера кучи (для более подробной информации см. https://blog.codecentric.de/ru/2014/02/35gb-heap-less-32gb-java-jvm-memory-oddities/). Обычно, если вы укажете
-Xmx меньше 32 гигабайт, размер указателя будет составлять 4 байта; для больших куч — 8 байтов. Таким образом, ArrayList, инициализированный конструктором по умолчанию, с добавлением только одного элемента, тратит впустую либо 36, либо 72 байта.На самом деле, пустой
ArrayList тоже тратит память впустую, поскольку он не несет никакой рабочей нагрузки, но размер самого объекта ArrayList не равен нулю и больше, чем вы, вероятно, думаете. Это потому, что, с одной стороны, каждый объект, управляемый JVM HotSpot, имеет 12- или 16-байтовый заголовок, который используется JVM для внутренних целей. Далее, большинство объектов коллекции содержат поле size, указатель на внутренний массив или другой объект “носителя рабочей нагрузки”, поле modCount для отслеживания изменений содержимого и т. д. Таким образом, даже наименьшему возможному объекту, представляющему пустую коллекцию, вероятно, понадобится не менее 32 байт памяти. Некоторые, например ConcurrentHashMap, занимают гораздо больше.Рассмотрим еще один часто встречающуюся коллекцию — класс
java.util.HashMap. Его жизненный цикл аналогичен жизненному циклу ArrayList:
Как вы можете видеть,
HashMap, содержащий только одну пару «ключ-значение», тратит 15 внутренних ячеек массива, что соответствует 60 или 120 байтам. Эти цифры невелики, но важны масштабы потерь памяти для всех коллекций в вашем приложении. И получается, что некоторые приложения могут тратить достаточно много памяти таким образом. Например, некоторые популярные компоненты Hadoop с открытым исходным кодом, которые проанализировал автор, теряют около 20 процентов от своей кучи в некоторых случаях! Для продуктов, разработанных менее опытными инженерами, и не подвергающихся регулярному анализу производительности, потери памяти могут быть еще выше. Достаточно случаев, когда, например, 90% узлов в огромном дереве содержат только один или два потомка (или вообще ничего), и другие ситуации, когда куча забита 0-, 1- или 2-элементными коллекциями.Если вы обнаружили неиспользуемые или малоиспользуемые коллекции в своем приложении, как их исправить? Ниже приведены некоторые распространенные рецепты. Здесь предполагается, что наша проблемная коллекция —
ArrayList, на которую ссылается поле данных Foo.list.Если большинство экземпляров списка никогда не используются, попробуйте инициализировать его лениво. Таким образом, код, который ранее выглядел как…
void addToList(Object x) {
list.add(x);
}… должен быть переделан в нечто вроде
void addToList(Object x) {
getOrCreateList().add(x);
}
private list getOrCreateList() {
// Чтобы сохранить память, мы не создаем список до его первого использования
if (list == null) list = new ArrayList();
return list;
}Имейте в виду, что вам иногда потребуется принять дополнительные меры для решения возможных конкуренций. Например, если вы поддерживаете
ConcurrentHashMap, который может быть обновлен несколькими потоками одновременно, код, который инициализирует его отложено, не должен позволять двум потокам создавать две копии этой мапы случайно:private Map getOrCreateMap() {
if (map == null) {
//Удостоверимся, что другой поток не опережает нас
synchronized (this) {
if (map == null) map = new ConcurrentHashMap();
}
}
return map;
}Если большинство экземпляров вашего списка или мапы содержат только несколько элементов, попробуйте инициализировать их с более подходящей начальной емкостью, например.
list = new ArrayList(4); // Внутренний массив будет создан с длиной 4Если ваши коллекции пусты или содержат только один элемент (или пару «ключ-значение») в большинстве случаев, вы сможете рассмотреть одну крайнюю форму оптимизации. Она работает только в том случае, если коллекция полностью управляется в пределах текущего класса, то есть другой код не может получить к нему доступ напрямую. Идея состоит в том, что вы меняете тип своего поля данных, например, из List в более общий Object, чтобы теперь он мог указывать либо на реальный список, либо непосредственно на единственный элемент списка. Вот краткий эскиз:
// *** Старый код ***
private List<Foo> list = new ArrayList<>();
void addToList(Foo foo) { list.add(foo); }
// *** Новый код ***
// Если список пуст, это значение равно null. Если список содержит только один элемент,
// он указывает прямо на этот элемент. В противном случае он указывает на
// реальный объект ArrayList.
private Object listOrSingleEl;
void addToList(Foo foo) {
if (listOrSingleEl == null) { // Пустой список
listOrSingleEl = foo;
} else if (listOrSingleEl instanceof Foo) { // Одноэлементный
Foo firstEl = (Foo) listOrSingleEl;
ArrayList<Foo> list = new ArrayList<>();
listOrSingleEl = list;
list.add(firstEl);
list.add(foo);
} else { // Реальный список со множеством элементов
((ArrayList<Foo>) listOrSingleEl).add(foo);
}
}Очевидно, что код с такой оптимизацией менее понятен и его сложнее поддерживать. Но это может оказаться полезным, если вы уверены, что таким образом сэкономите много памяти или избавитесь от длинных пауз сборщика мусора.
Вы вероятно уже задумались: откуда же я узнаю, какие коллекции в моем приложении перерасходуют память и сколько?
Если коротко: это трудно узнать без правильных инструментов. Попытка угадать объем используемой или потраченной структурами данных памяти в большом сложном приложении почти никогда ни к чему не приведёт. И, не зная точно, куда уходит память, вы можете потратить много времени в погоне за неправильными целями, в то время как ваше приложение упорно продолжает падать с
OutOfMemoryError.По этому, вам следует проверить кучу приложения с помощью специального инструмента. По опыту, наиболее оптимальным способом анализа памяти JVM (измеряется как количество доступной информации в сравнении с воздействием этого инструмента на производительность приложения) — это получить дамп кучи, а затем просмотреть его в автономном режиме. Дамп кучи — это, по сути, полный снимок кучи. Его можно получить в любой момент, вызвав утилиту jmap, либо можно настроить JVM для автоматического создания дампа, если приложение падает с
OutOfMemoryError. Если вы загуглите «дамп кучи JVM», вы сразу увидите большое количество статей, в которых подробно объясняется, как получить дамп.Дамп кучи — это двоичный файл размером с кучу JVM, поэтому его можно читать и анализировать только с помощью специальных инструментов. Существует несколько таких инструментов, как с открытым исходным кодом, так и коммерческие. Наиболее популярным инструментом с открытым исходным кодом является Eclipse MAT; есть также VisualVM и некоторые менее мощные и менее известные инструменты. Коммерческие инструменты включают профилировщики Java общего назначения: JProfiler и YourKit, а также один инструмент, созданный специально для анализа дампа кучи — JXRay (дисклеймер: последнее разработал автор).
В отличие от других инструментов, JXRay сразу анализирует дамп кучи на наличие большого количества распространенных проблем, таких как повторяющиеся строки и другие объекты, а также недостаточно эффективные структуры данных. Проблемы с описанными выше коллекциями относятся к последней категории. Инструмент генерирует отчет со всей собранной информацией в формате HTML. Преимущество такого подхода заключается в том, что вы можете просматривать результаты анализа в любом месте в любое время и легко делиться ими с другими. Вы также можете запускать инструмент на любой машине, включая большие и мощные, но «безголовые» машины в центре обработки данных.
JXRay вычисляет оверхэд (сколько памяти вы сэкономите, если избавитесь от конкретной проблемы) в байтах и в процентах от используемой кучи. Он объединяет коллекции одного и того же класса, которые имеют одинаковую проблему…

… и затем группирует проблемные коллекции, которые доступны из некоторого корня сборщика мусора через одну и ту же цепочку ссылок, как в примере ниже

Знание о том, какие цепочки ссылок и/или отдельные поля данных (например,
INodeDirectory.children выше) указывают на коллекции, которые тратят большую часть памяти, позволяет быстро и точно определить код, который отвечает за проблему, а затем внести необходимые изменения.Таким образом, недостаточно эффективно настроенные Java-коллекции могут тратить много памяти. Во многих ситуациях эту проблему легко решить, но иногда вам может потребоваться изменить свой код нетривиальными способами для достижения значительного улучшения. Очень сложно угадать, какие коллекции нужно оптимизировать, чтобы оказать наибольшее влияние. Чтобы не тратить время на оптимизацию не тех частей кода, вам нужно получить дамп кучи JVM и проанализировать его с помощью соответствующего инструмента.
THE END
Нам, как всегда, интересны ваши мнения и вопросы, которые вы можете оставить тут или заскочить на открытый урок и поспрашивать наших преподавателей там.
