 Сейчас в прессе часто встречаются новости вида “AI научился писать в стиле автора Х”, или “ML создает искусство”. Посмотрев на это, мы решили – было бы здорово, если эти громкие заявления можно было бы проверить на деле.
Сейчас в прессе часто встречаются новости вида “AI научился писать в стиле автора Х”, или “ML создает искусство”. Посмотрев на это, мы решили – было бы здорово, если эти громкие заявления можно было бы проверить на деле.Можно ли устроить борьбу ботов по написанию стихотворений? Можно ли сделать из этого понятную и воспроизводимую соревновательную историю? Теперь можно точно сказать, что это возможно. А о том, как написать свой первый алгоритм по генерации стихотворений, читайте дальше.
План статьи
1. КлассикAI
Задача участников
По условиям конкурса, участникам необходимо построить модель, генерирующую стихи на заданную тему в стиле одного из русских классиков. Тема и автор подаются модели на вход, а на выходе ожидается стихотворение. Полное описание есть в репозитории конкурса.
С темой условия мягкие: это может быть короткое предложение, фраза или несколько слов. Единственное ограничение — на размер: не более 1000 знаков. Темы, на которых будут тестироваться алгоритмы, будут составлены экспертами. Часть тем будет открыта и общедоступна, но для определения лучшего алгоритма будет использован скрытый набор тем.
Глобальная идея соревнования такая: к любому стихотворению можно составить краткую аннотацию из нескольких слов. Давайте покажем на примере.
Если взять отрывок из «Евгения Онегина» А.С. Пушкина:
«…В тот год осенняя погодаТо кратко содержание его можно уместить в «Татьяна видит в окно первый снег». И тогда идеальная стихотворная модель по этому входу выдаст что-то очень близкое к оригиналу.
Стояла долго на дворе,
Зимы ждала, ждала природа.
Снег выпал только в январе
На третье в ночь. Проснувшись рано,
В окно увидела Татьяна
Поутру побелевший двор,
Куртины, кровли и забор,
На стеклах легкие узоры,
Деревья в зимнем серебре,
Сорок веселых на дворе
И мягко устланные горы
Зимы блистательным ковром.
Все ярко, все бело кругом...» 1823—1830
Для обучения в этом соревновании предлагается датасет из более чем 3000 произведений пяти известных русских поэтов:
1. Пушкин
2. Есенин
3. Маяковский
4. Блок
5. Тютчев
Алгоритм нужно написать так, чтобы он производил генерацию достаточно быстро и имел необходимый интерфейс. По скорости можно равняться на мощности средних современных ПК. Интерфейс и ограничения подробно описаны в разделе «Формат решений».
Чтобы иметь возможность отслеживать прогресс своих решений, а также сравнивать их с другими решениями участников, на протяжении соревнования будет проходить разметка решений через чат-бот. Результаты работы алгоритмов будут оцениваться по двум критериям:
- Качество стихосложения и соответствие стилю заданного классического поэта
- Полнота раскрытия заданной темы в стихотворении
По каждому критерию будет предоставлена 5-балльная шкала. Алгоритм должен будет сочинить стихи на каждую тему из тестового набора. Темы, на которых будут тестироваться алгоритмы, будут составлены экспертами. Часть тем будет открыта и общедоступна, но для выявления лучшего алгоритма будет использован скрытый набор тем.
Полученное в результате работы алгоритма стихотворение может быть отклонено по следующим причинам:
- сгенерированный текст не является стихотворением на русском языке
- сгенерированный текст содержит нецензурную лексику
- сгенерированный текст содержит умышленно включенные оскорбительные фразы или подтекст
Программа соревнования
В отличие от многих, в этом соревновании только один онлайн этап: с 30.07 по 26.08.
На протяжении этого периода можно ежедневно отправлять решения со следующими ограничениями:
- не более 200 решений за время соревнование
- не более 2х успешных решений в день
- не учитываются в дневном лимите решения, проверка которых завершилась с ошибкой
Призовой фонд соответствует сложности задачи: первые три места получат 1 000 000 рублей!
2. Подходы к созданию генераторов стихов
Как уже стало понятно, задача нетривиальная, но и не новая. Попробуем разобраться, как же исследователи подходили к решению это задачи раньше? Давайте посмотрим на наиболее интересные подходы к созданию генераторов стихов последних 30 лет.
1989
В журнале Scientific American N08, 1989 выходит статья А.К. Дьюдни “Компьютер пробует свои силы в прозе и поэзии”. Не будем пересказывать статью, здесь есть ссылка на полный текст, хотим лишь обратить ваше внимание на описание POETRY GENERATOR от Розмари Уэст.
Этот генератор был полностью автоматизированным. В основе этого подхода большой словарь, фразы из которого выбираются случайным образом, и из них формируются словосочетания по набору грамматических правил. Каждая строка делится на части предложения, а далее случайно заменяется другими словами.
Этот генератор был полностью автоматизированным. В основе этого подхода большой словарь, фразы из которого выбираются случайным образом, и из них формируются словосочетания по набору грамматических правил. Каждая строка делится на части предложения, а далее случайно заменяется другими словами.
1996
Более 20 лет назад выпускник известного московского вуза защитил диплом на тему «Лингвистическое моделирование и искусственный интеллект»: автор — Леонид Каганов. Вот ссылка на полный текст.
К 1996 году уже были написаны такие генераторы как:
В качестве основных преимуществ можно выделить то, что программа:
Алгоритм и код можно почитать здесь.
«Лингвистическое моделирование и искусственный интеллект» — так звучит
название моей темы. «Программа, которая сочиняет стихи» — так отвечаю я на
вопросы друзей. «Но ведь подобные программы уже есть?» — говорят мне. «Да — отвечаю я, — но моя отличается тем, что не использует изначальных шаблонов.»
(с) Каганов Л.А.
К 1996 году уже были написаны такие генераторы как:
- BRED.COM, создающий псевдонаучную фразу
- TREPLO.EXE, порождающий забавный литературный текст
- POET.EXE, сочиняющий стихи с заданным ритмом
- DUEL.EXE
«Например, в POET.EXE имеется словарь слов с проставленными ударениями и некоторой другой информацией о них, а также задается ритм и указывается какие строки рифмовать (например, 1 и 4). А все эти программы обладают одним общим свойством — они используют шаблоны и заранее подготовленные словари.»
В качестве основных преимуществ можно выделить то, что программа:
- использует ассоциативный опыт
- производит рифмовку самостоятельно
- имеет возможность тематического сочинения
- позволяет задавать любой ритм стиха
Алгоритм и код можно почитать здесь.
2016
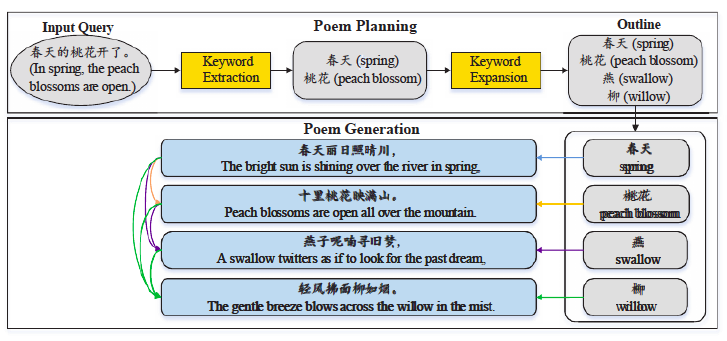
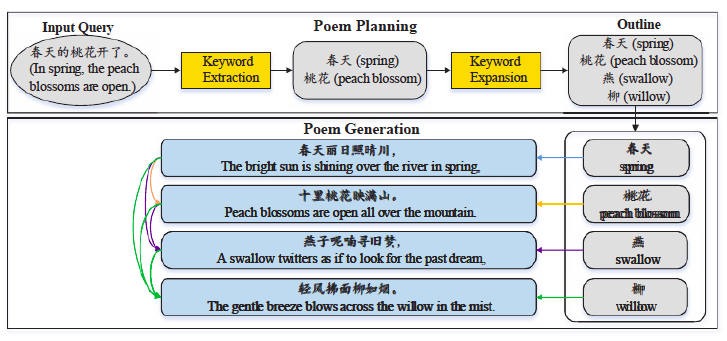
Ученые из Китая генерируют стихотворения на своем языке. У них есть живой репозиторий проекта, который может быть полезен в текущем соревновании.
Если очень коротко, то это работает так (ссылка на источник картинки):
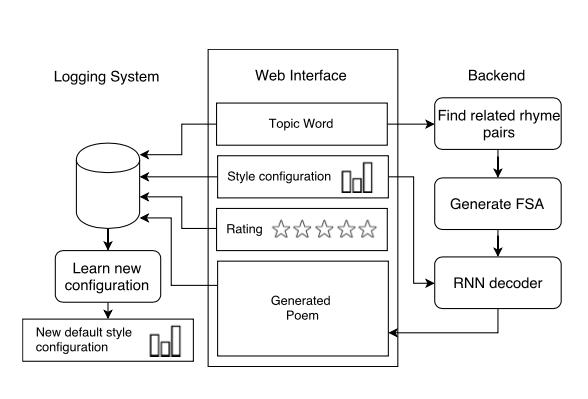
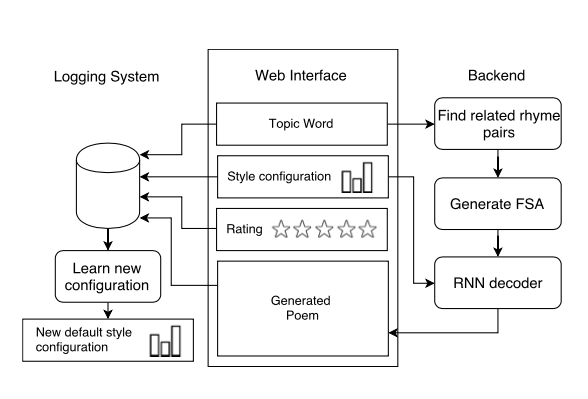
Также в 2016 еще одна группа представила свою разработку Hafez (репозиторий тут).
Этот генератор “сочиняет” стихи на заданную тему, используя:
Их алгоритм (ссылка на источник картинки):
Они обучили алгоритм не только на английском, но и на испанском. Обещают, что все должно работать почти везде. Заявление довольно громкое, так что рекомендуем относиться с осторожностью.
«Chinese Poetry Generation with Planning based Neural Network»
Ученые из Китая генерируют стихотворения на своем языке. У них есть живой репозиторий проекта, который может быть полезен в текущем соревновании.
Если очень коротко, то это работает так (ссылка на источник картинки):
Generating Topical Poetry
Также в 2016 еще одна группа представила свою разработку Hafez (репозиторий тут).
Этот генератор “сочиняет” стихи на заданную тему, используя:
- Словарь с учетом ударений
- Слова по теме
- Рифмующиеся слова из набора слов по теме
- Finite-state acceptor (FSA)
- Выбор лучшего пути через FSA, используя RNN
Их алгоритм (ссылка на источник картинки):
Они обучили алгоритм не только на английском, но и на испанском. Обещают, что все должно работать почти везде. Заявление довольно громкое, так что рекомендуем относиться с осторожностью.
2017
Напоследок хочется упомянуть об очень подробной статье на Хабре «Как научить свою нейросеть генерировать стихи». Если вы никогда не занимались подобными моделями, то вам сюда. Там про генератор стихов на нейроночках: про языковые модели, N-граммные языковые модели, про оценку языковых моделей, про то как запилить архитектуру и доработать входной и выходной слой.
Например, вот так слову добавляется морфологическая разметка (ссылка на источник картинки):
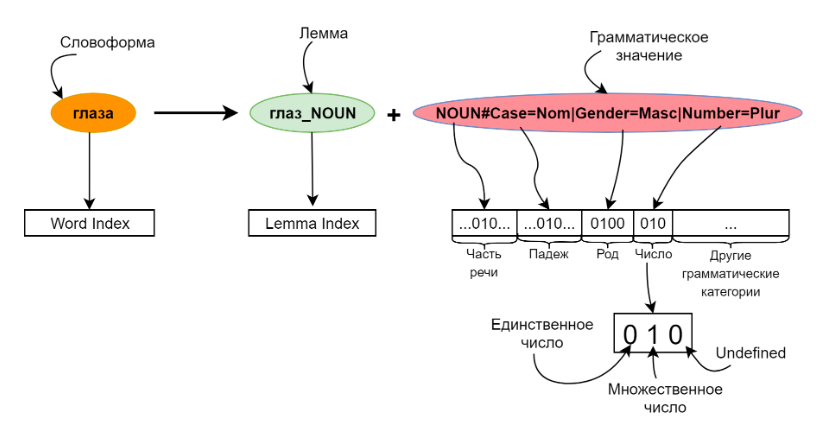
Та статья была написана совместно с Ильей Гусевым, у которого есть библиотека для анализа и генерации стихов на русском языке и поэтический корпус русского языка.
Например, вот так слову добавляется морфологическая разметка (ссылка на источник картинки):

Та статья была написана совместно с Ильей Гусевым, у которого есть библиотека для анализа и генерации стихов на русском языке и поэтический корпус русского языка.
3. Программирование искусственного поэта
Пример простого поэтического генератора
Соревнование с одной стороны может показаться достаточно сложным, однако для него вполне можно сделать простой, но рабочий бейзлайн.
По условию, на вход этой программы поступает идентификатор автора (author_id) и текст темы (seed), в ответ на это модель должна вернуть стихотворение.
Давайте попробуем формализовать тему так, чтобы с ней можно было спокойно оперировать в рамках некоторого векторного семантического пространства. Самый простой выход из этого — получить семантический вектор каждого слова (например, Word2Vec) после чего усреднить их.
Таким образом, мы получаем своеобразный “seed2vec”, который позволяет нам переводить тему в вектор.
На самом деле здесь открывается широкая тема для исследований, т.к. задача выделения темы стоит перед учеными достаточно давно, вот только несколько примеров:
— Выделение топиков через LDA
— lda2vec
— sent2vec
— WMD
Теперь, нужно понять, как использовать author_id для генерации стихотворения именно в стилистике этого автора.
Здесь идея не менее простая: давайте возьмем случайное стихотворение автора из корпуса стихов, после чего будем заменять каждое слово на другое, которое максимально созвучно с оригиналом (имеет одинаковое количество слогов, одинаковое ударение и последние три буквы максимально схожи с оригиналом по расстоянию Левенштейна) и при этом имеет максимально схожий вектор с вектором темы. Например, для темы «Футбол» и строки «И светился как янтарь», выходной строкой может быть «А игрался как вратарь». Таким образом, мы получаем своеобразную стилизацию текста.
В качестве базы слов для замены был использован датасет, который содержит небольшие параграфы текстов из Википедии (описание его использования можно найти в коде бейзлайна на GitHub).
После такой обработки получатся тексты, которые внешне будут напоминать стихи автора, но при этом содержать некоторую тему, которую автор не закладывал.
Результат работы бейзлайна:
Тема: Физика
Стилистика: Блок
приведут и висмут единицы
буйвол древних нелинейных сред
я в доске кельвину на частице
свой явлений свой научный вслед
фарадей севилье тараканья
свой тверской теперь изобретшим
среда фонон грань тяготения
позитронный призрак школьный дым
Тема: Математика
Стилистика: Блок
как кружке лейбницу среди идей
кривым и школьным обучаться
но стадо стадо в творчество учиться
кривая для примеры мозг детей
кривые взят пловец знает из гоба
и в планк пройдет и в суд пройдет в сенат
чем дочь колее тем древнее гоба
и сурья исчезающе терпят
пловец весь тень учится над евклидом
заглавие издается и квот
осваивает он скрепляя трудом
профессору учебный анекдот
Очевидно, что бейзлайн не идеален, на то он и бейзлайн.
Можно легко добавить несколько фичей, которые помогут неплохо улучшить генерацию и поднять вас в топе:
- Нужно убрать повторяющиеся слова, ведь рифмовать слово на само себя не здорово для хорошего поэта
- Сейчас слова никак не согласованы друг с другом, т.к. мы никак не используем информацию о частях речи и падежей слов
- Можно использовать более богатый корпус слов, например, дамп википедии
- Использование других эмбенднгов может так же улучшить, например, FastText работает не на уровне слов, а на уровне n-грамм, что позволяет ему делать эмбендинги для неизвестных слов
- Использовать IDF в качестве веса при взвешивании слов для расчета вектора темы
Тут можно добавлять еще множество пунктов, на ваше усмотрение.
Подготовка решения к отправке
После того, как модель обучена, в проверяющую систему необходимо отправить код алгоритма, запакованный в ZIP-архив.
Решения запускаются в изолированном окружении при помощи Docker, время и ресурсы для тестирования ограничены. Решение должно отвечать следующим техническим требованиям:
Оно должно быть выполнено в виде HTTP-сервера, доступного по порту 8000, который отвечает на два вида запросов:
GET /readyНа запрос необходимо ответить кодом 200 OK в случае, если решение готово к работе. Любой другой код означает, что решение еще не готово. У алгоритма есть ограниченное время на подготовку к работе, за которое можно прочитать данные с диска, создать в оперативной памяти необходимые структуры данных.
POST /generate/<poet_id>Запрос на генерацию стихотворения. Идентификатор поэта, в стиле которого необходимо сочинить, указан в URL. Содержимое запроса — JSON с единственным полем seed, содержащим тему сочинения:
{"seed": "регрессия глубокими нейронными сетями"}В качестве ответа необходимо в отведенное время дать JSON со сгенерированным сочинением в поле poem:
{"poem": "Ведь были сети боевые\nДа говорят еще какие\n..."}Запрос и ответ должны иметь Content-Type: application/json. Рекомендуется использовать кодировку UTF-8.
Контейнер с решением запускается в следующих условиях:
— решению доступны ресурсы:
— 16 Гб оперативной памяти
— 4 vCPU
— GPU Nvidia K80
— решение не имеет доступа к ресурсам интернета
— решению в каталоге /data/ доступны общие наборы данных
— время на подготовку к работе: 120 секунд (после чего на запрос /ready необходимо отвечать кодом 200)
— время на один запрос /generate/: 5 секунд
— решение должно принимать HTTP запросы с внешних машин (не только localhost/127.0.0.1)
— при тестировании запросы производятся последовательно (не более 1 запроса одновременно)
— максимальный размер упакованного и распакованного архива с решением: 10 Гб
Сгенерированное стихотворение (poem) должно удовлетворять формату:
— размер стиха — от 3 до 8 строк
— каждая строка содержит не более 120 символов
— строки разделяются символом \n
— пустые строки игнорируются
Тема сочинения (seed) по длине не превышает 1000 символов.
При тестировании используются стили только 5 перечисленных выше избранных поэтов.
— 16 Гб оперативной памяти
— 4 vCPU
— GPU Nvidia K80
— решение не имеет доступа к ресурсам интернета
— решению в каталоге /data/ доступны общие наборы данных
— время на подготовку к работе: 120 секунд (после чего на запрос /ready необходимо отвечать кодом 200)
— время на один запрос /generate/: 5 секунд
— решение должно принимать HTTP запросы с внешних машин (не только localhost/127.0.0.1)
— при тестировании запросы производятся последовательно (не более 1 запроса одновременно)
— максимальный размер упакованного и распакованного архива с решением: 10 Гб
Сгенерированное стихотворение (poem) должно удовлетворять формату:
— размер стиха — от 3 до 8 строк
— каждая строка содержит не более 120 символов
— строки разделяются символом \n
— пустые строки игнорируются
Тема сочинения (seed) по длине не превышает 1000 символов.
При тестировании используются стили только 5 перечисленных выше избранных поэтов.
Подробная информация по отправке решения в систему с разбором наиболее частых ошибок доступна здесь.
4. Платформа хакатона
Платформа со всей необходимой информацией по этому контесту находится на classic.sberbank.ai. Подробные правила вы найдете здесь. Hа форуме можно получить ответ как по задаче, так и по техническим вопросам, если что-то пойдет не так.

Творческие соревнования ML моделям не даются легко. К задаче генерации стихов подступались многие, но значимого прорыва пока еще нет. Уже сейчас на нашей платформе classic.sberbank.ai участники со всей России соревнуются в решении этой сложной задачи. Надеемся, что решения победителей превзойдут все решения, созданные ранее!
5. Ссылки
Полезные ссылки
Платформа хакатона Классик AI
В Мире Науки — Компьютер пробует свои силы в прозе и поэзии
Hafez — Poetry Generation
Каганов Л.А. «Лингвистическое конструирование в системах искусственного интеллекта»
N+1 «Искусственный Пушкин»
Generating Poetry with PoetRNN
Подросток написал искусственный интеллект, который пишет стихи
«Стихи» искусственного интеллекта Google попали в сеть
Кибер-поэзия и кибер-проза: совсем чуть-чуть искусственного интеллекта
В Мире Науки — Компьютер пробует свои силы в прозе и поэзии
Hafez — Poetry Generation
Каганов Л.А. «Лингвистическое конструирование в системах искусственного интеллекта»
N+1 «Искусственный Пушкин»
Generating Poetry with PoetRNN
Подросток написал искусственный интеллект, который пишет стихи
«Стихи» искусственного интеллекта Google попали в сеть
Кибер-поэзия и кибер-проза: совсем чуть-чуть искусственного интеллекта
