 Привет, Хабр! Изучите, как следует реализовывать эффективные алгоритмы на основе важнейших структур данных на языке Java, а также как измерять производительность этих алгоритмов. Каждая глава сопровождается упражнениями, помогающими закрепить материал.
Привет, Хабр! Изучите, как следует реализовывать эффективные алгоритмы на основе важнейших структур данных на языке Java, а также как измерять производительность этих алгоритмов. Каждая глава сопровождается упражнениями, помогающими закрепить материал.- Научитесь работать со структурами данных, например, со списками и словарями, разберитесь, как они работают.
- Напишите приложение, которое читает страницы Википедии, выполняет синтаксический разбор и обеспечивает навигацию по полученному дереву данных.
- Анализируйте код и учитесь прогнозировать, как быстро он будет работать и сколько памяти при этом потреблять.
- Пишите классы, реализующие интерфейс Map, пользуйтесь при этом хеш-таблицей и двоичным деревом поиска.
- Создайте простой веб-поисковик с собственным поисковым роботом: он будет индексировать веб-страницы, сохранять их содержимое и возвращать нужные результаты.
Отрывок «Обход дерева»
В этой главе мы рассмотрим приложение для поисковой системы, которое будем разрабатывать на протяжении оставшейся части книги. Я (автор) описываю элементы поисковой системы и представляю первое приложение, поискового робота, который загружает и анализирует страницы из «Википедии». В данной главе также представлена рекурсивная реализация поиска в глубину и итеративная реализация, использующая Deque из Java для реализации стека типа «последним вошел, первым вышел».
Поисковые системы
Поисковая система, такая как Google Search или Bing, принимает набор поисковых терминов и возвращает список веб-страниц, которые релевантны этим терминам. На сайте thinkdast.com можно прочитать больше, но я объясню, что нужно, по мере продвижения.
Рассмотрим основные компоненты поисковой системы.
- Сбор данных (crawling). Понадобится программа, способная загружать веб-страницу, анализировать ее и извлекать текст и любые ссылки на другие страницы.
- Индексирование (indexing). Нужен индекс, который позволит найти поисковый запрос и страницы, его содержащие.
- Поиск (retrieval). Необходим способ сбора результатов из индекса и определения страниц, наиболее релевантных поисковым терминам.
Начнем с поискового робота. Его цель — обнаружение и загрузка набора веб-страниц. Для поисковых систем, таких как Google и Bing, задача состоит в том, чтобы найти все веб-страницы, но часто эти роботы ограничиваются меньшим доменом. В нашем случае мы будем читать только страницы из «Википедии».
В качестве первого шага мы создадим поискового робота, который читает страницу «Википедии», находит первую ссылку, переходит по ней на другую страницу и повторяет предыдущие действия. Мы будем использовать этот поисковик, чтобы проверить гипотезу Getting to Philosophy («Путь к философии»). В ней говорится:
«Щелкнув на первой ссылке, написанной строчными буквами, в основном тексте статьи в “Википедии” и повторив затем это действие для последующих статей, вы, скорее всего, попадете на страницу со статьей о философии».
Ознакомиться с этой гипотезой и ее историей можно по адресу thinkdast.com/getphil.
Проверка гипотезы позволит создавать основные части поискового робота, не нуждаясь в обходе всего Интернета или даже всей «Википедии». И я думаю, что это упражнение довольно интересное!
В нескольких главах мы будем работать над индексатором, а затем перейдем к поисковику.
Парсинг HTML
Когда вы загружаете веб-страницу, ее содержимое написано на языке гипертекстовой разметки (HyperText Markup Language, HTML). Например, ниже представлен простейший HTML-документ:
<!DOCTYPE html>
<html>
<head>
<title>This is a title</title>
</head>
<body>
<p>Hello world!</p>
</body>
</html>Фразы This is a title («Это название») и Hello world! («Привет, мир!») — текст, который действительно отображается на странице; другие элементы — теги, указывающие, как должен отображаться текст.
Нашему роботу при загрузке страницы нужно проанализировать код HTML, чтобы извлечь текст и найти ссылки. Для этого мы будем использовать jsoup — библиотеку Java с открытым исходным кодом, предназначенную для загрузки и парсинга (синтаксического анализа) HTML.
Результат парсинга HTML — дерево DOM (Document Object Model), содержащее элементы документа, включая текст и теги.
Дерево — связанная структура данных, состоящая из вершин, которые представляют текст, теги и другие элементы документа.
Связь между вершинами определяется структурой документа. В предыдущем примере первым узлом, называемым корнем, является тег , который включает ссылки на две содержащиеся в нем вершины и ; эти узлы — дочерние элементы корневого узла.
Узел имеет одну дочернюю вершину , а узел — одну дочернюю вершину
(абзац, от англ. paragraph). На рис. 6.1 представлено графическое изображение данного дерева.
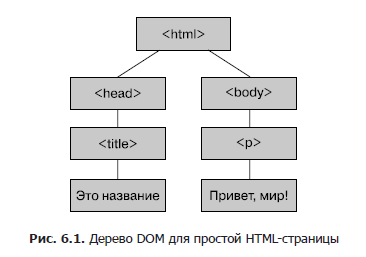
Каждая вершина включает ссылки на свои дочерние узлы; кроме того, каждый узел содержит ссылку на своего родителя, поэтому вверх и вниз по дереву можно перемещаться из любого узла. Дерево DOM для реальных страниц обычно сложнее, чем описанный пример.
В большинстве браузеров есть инструменты для проверки DOM просматриваемой страницы. В Chrome можно щелкнуть правой кнопкой мыши на любой части веб-страницы и в появившемся меню выбрать пункт Просмотреть код. В Firefox можно щелкнуть правой кнопкой мыши и выбрать в контекстном меню пункт Исследовать элемент. Safari предоставляет инструмент Web Inspector, информация о котором находится на сайте thinkdast.com/safari. Инструкции для Internet Explorer можно прочитать, перейдя по ссылке: thinkdast.com/explorer.
На рис. 6.2 показан скриншот с избражением дерева DOM для страницы «Википедии» о Java. Выделенный элемент — первый абзац основного текста статьи, который содержится в элементе <div> с id=«mw-content-text». Мы будем использовать этот идентификатор элемента, чтобы определить основной текст каждой загружаемой нами статьи.
Применение jsoup
Библиотека jsoup позволяет легко загружать и анализировать веб-страницы и перемещаться по дереву DOM. Например:
String url = "http://en.wikipedia.org/wiki/Java_(programming_language)";
// загрузка и парсинг документа
Connection conn = Jsoup.connect(url);
Document doc = conn.get();
// выбирает текст контента и разделяет его по параграфам
Element content = doc.getElementById("mw-content-text");
Elements paragraphs = content.select("p");Элемент Jsoup.connect принимает URL в виде строки и устанавливает соединение с веб-сервером; метод get загружает код HTML, анализирует его и возвращает объект Document, который представляет собой DOM.

Этот объект включает методы для навигации по дереву и выбора узлов. На самом деле он предоставляет так много методов, что это может сбить с толку. Следующий пример демонстрирует два способа выбора узлов.
- getElementByld принимает параметр строкового типа и ищет дерево для элемента с соответствующим полем id. Найдя его, он выбирает узел <div id=«mw-content-text» lang=«en» dir=«ltr» class=«mw-content-ltr»>, который появляется на каждой странице «Википедии», чтобы идентифицировать элемент <div>, содержащий основной текст страницы, в отличие от боковой панели навигации и других элементов.
- select принимает String, обходит дерево и возвращает все элементы с тегами, соответствующими String. В данном примере он возвращает все теги абзацев, которые появляются в content. Возвращаемое значение — объект типа Elements.
Прежде чем продолжить, вы должны просмотреть документацию этих классов, чтобы знать, какие действия они могут выполнять. Наиболее важные классы — Element, Elements и Node, прочитать о которых можно, перейдя по ссылкам thinkdast.com/jsoupelt, thinkdast.com/jsoupelts и thinkdast.com/jsoupnode.
Класс Node представляет собой вершину в дереве DOM. Существует несколько субклассов, расширяющих Node, включая Element, TextNode, DataNode и Comment. Класс Elements — коллекция объектов типа Element.
На рис. 6.3 представлена диаграмма классов UML, показывающая отношения между ними. Линия с пустой стрелкой говорит о расширении одного класса другим. Например, эта диаграмма указывает на то, что Elements расширяет ArrayList. Мы вернемся к диаграммам классов UML в одноименном разделе главы 11.

Итерация по дереву DOM
Для того чтобы облегчить вам жизнь, я предоставляю класс WikiNodelterable, позволяющий проходить по дереву DOM. Ниже приведен пример, который показывает, как использовать этот класс:
Elements paragraphs = content.select("p");
Element firstPara = paragraphs.get(0);
Iterable<Node> iter = new WikiNodeIterable(firstPara);
for (Node node: iter) {
if (node instanceof TextNode) {
System.out.print(node);
}
}Этот пример начинается с того момента, на котором остановился предыдущий. Он выбирает первый абзац в paragraphs и затем создает класс WikiNodeIterable, который реализует интерфейс Iterable. Данный класс выполняет поиск в глубину, создавая узлы в том порядке, в котором они будут показываться на странице.
В текущем примере мы отображаем Node, только если он является TextNode, и игнорируем другие его типы, в частности объекты типа Element, представляющие теги. Результат — простой текст абзаца HTML без какой-либо разметки. Его вывод:
Java is a general-purpose computer programming language that is concurrent, class- based, object-oriented, [13] and specifically designed…
Java — универсальный компьютерный язык программирования, который является объектно-ориентированным языком, основанным на классах, с возможностью параллельного программирования [13] и специально разработан...
Поиск в глубину
Существует несколько способов разумного обхода дерева. Мы начнем с поиска в глубину (depth-first search, DFS). Поиск начинается с корня дерева и выбора первого дочернего узла. Если у последнего есть дети, то снова выбирается первый дочерний узел. Когда попадается вершина без детей, нужно вернуться, перемещаясь вверх по дереву к родительскому узлу, где выбирается следующий ребенок, если он есть. В противном случае нужно снова вернуться. Когда исследован последний дочерний узел корня, обход завершается.
Есть два общепринятых способа реализации поиска в глубину: рекурсивный и итеративный. Рекурсивная реализация проста и элегантна:
private static void recursiveDFS(Node node) {
if (node instanceof TextNode) {
System.out.print(node);
}
for (Node child: node.childNodes()) {
recursiveDFS(child);
}
}Этот метод вызывается для каждого Node в дереве, начиная с корня. Если Node является TextNode, то печатается его содержимое. При наличии у Node детей происходит вызов recursiveDFS для каждого из них по порядку.
В текущем примере мы распечатываем содержимое каждого TextNode до посещения его дочерних узлов, то есть это пример прямого (pre-order) обхода. О прямом, обратном (post-order) и симметричном (in-order) обходе можно прочитать, перейдя по ссылке thinkdast.com/treetrav. Для данного приложения порядок обхода не имеет значения.
Выполняя рекурсивные вызовы, recursiveDFS использует стек вызовов (см. thinkdast.com/callstack) с целью отслеживать дочерние вершины и обрабатывать их в правильном порядке. В качестве альтернативы можно использовать структуру данных стека, чтобы отслеживать узлы самостоятельно; это позволит избежать рекурсии и обойти дерево итеративно.
Стеки в Java
Прежде чем объяснять итеративную версию поиска в глубину, я рассмотрю структуру данных стека. Мы начнем с общей концепции стека, а затем поговорим о двух Java-interfaces, которые определяют методы стека: Stack и Deque.
Стек представляет собой структуру данных, похожую на список: это коллекция, которая поддерживает порядок элементов. Основное различие между стеком и списком состоит в том, что первый включает меньше методов. По общепринятому соглашению стек предоставляет методы:
- push, добавляющий элемент в вершину стека;
- pop, который производит удаление и возвращает значение самого верхнего элемента стека;
- peek, возвращающий самый верхний элемент стека без изменения самого стека;
- isEmpty, который показывает, является ли стек пустым.
Поскольку pop всегда возвращает самый верхний элемент, то стек еще называется LIFO, что значит «последним вошел, первым вышел» (last in, first out). Альтернатива стеку — очередь, возвращающая элементы в том же порядке, в котором они были добавлены, то есть «первым вошел, первым вышел» (first in, first out), или FIFO.
На первый взгляд непонятно, почему стеки и очереди полезны: они не дают никаких особых возможностей, которые нельзя было бы получить от списков; фактически возможностей у них даже меньше. Так почему бы не применять списки всегда? Есть две причины, оправдывающие применение стеков и очередей.
1. Если вы ограничиваете себя небольшим набором методов (то есть небольшим API), то ваш код будет более читабельным и менее подверженным ошибкам. Например, при использовании списка для представления стека можно случайно удалить элемент в неправильном порядке. С API стека такая ошибка в буквальном смысле невозможна. А лучший способ избежать ошибок — сделать их невозможными.
2. Если структура данных предоставляет небольшой API, то ее легче реализовать эффективно. Например, простой способ реализации стека — одиночный список. Вталкивая (push) элемент в стек, мы добавляем его в начало списка; выталкивая (pop) элемент, мы удаляем его из самого начала. Для связного списка добавление и удаление из начала — операции постоянного времени, поэтому данная реализация эффективна. И наоборот, большие API сложнее реализовать эффективно.
Реализовать стек в Java можно тремя путями.
1. Применить ArrayList или LinkedList. При использовании ArrayList нужно помнить о добавлении и удалении из конца, чтобы эти операции выполнялись за постоянное время. Следует избегать добавления элементов в неправильное место или их удаления в неправильном порядке.
2. В Java есть класс Stack, предоставляющий стандартный набор методов стека. Но этот класс — старая часть Java: он несовместим с Java Collections Framework, который появился позже.
3. Вероятно, лучший выбор — использовать одну из реализаций интерфейса Deque, например ArrayDeque.
Deque образовано от double-ended queue, это значит «двусторонняя очередь». В Java интерфейс Deque предоставляет методы push, pop, peek и isEmpty, поэтому его можно использовать как стек. Он содержит и другие методы, информация о которых доступна на сайте thinkdast.com/deque, но пока мы не будем применять их.
Итеративный поиск в глубину
Ниже приводится итеративная версия DFS, использующая ArrayDeque для представления стека объектов типа Node:
private static void iterativeDFS(Node root) {
Deque<Node> stack = new ArrayDeque<Node>();
stack.push(root);
while (!stack.isEmpty()) {
Node node = stack.pop();
if (node instanceof TextNode) {
System.out.print(node);
}
List<Node> nodes = new ArrayList<Node>(node.
chiidNodesQ);
Collections.reverse(nodes);
for (Node child: nodes) {
stack.push(chiid);
}
}
}Параметр root — корень дерева, которое мы хотим обойти, поэтому начинаем с создания стека и добавления в него данного параметра.
Цикл продолжается до тех пор, пока стек не окажется пустым. При каждом проходе происходит выталкивание Node из стека. Если получен TextNode, то печатается его содержимое. Затем в стек добавляются дочерние вершины. Чтобы обрабатывать потомков в правильном порядке, нужно выталкивать их в стек в обратном порядке; это делается копированием дочерних вершин в ArrayList, перестановкой элементов на месте, а затем итерацией реверсированного ArrayList.
Одно из преимуществ итеративной версии поиска в глубину заключается в том, что ее проще реализовать как Iterator в Java; как это сделать, описано в следующей главе.
Но сначала последнее замечание об интерфейсе Deque: помимо ArrayDeque, Java предоставляет еще одну реализацию Deque, нашего старого друга LinkedList. Последний реализует оба интерфейса: List и Deque. Полученный интерфейс зависит от его использования. Например, при назначении объекта LinkedList переменной Deque:
Deqeue<Node> deque = new LinkedList<Node>();можно применить методы из интерфейса Deque, но не все методы из интерфейса List. Присвоив его переменной List:
List<Node> deque = new LinkedList<Node>();можно использовать методы List, но не все методы Deque. И присваивая их следующим образом:
LinkedList<Node> deque = new LinkedList<Node>();можно использовать все методы. Но при объединении методов из разных интерфейсов код будет менее читабельным и более подверженным ошибкам.
» Более подробно с книгой можно ознакомиться на сайте издательства
» Оглавление
» Отрывок
Для Хаброжителей скидка 20% по купону — Java
