Comments 192
У меня довольно долго опосля появления Р4 стоял NAS на туалатин селероне, ибо я по-прежнему считал его очень удачным, быстрым и холодным решением на фоне первых Р4. Да и вообще питал теплые чувства к P6 архитектуре и взял ноут только, когда вышел первый мобильный merom, переждав обрезки Р4. Хотя в защиту Р4 могу сказать, что 130нм Норсвуд 2.4 с 512 кэшем очень неплохо гнался, и под этим самым разгоном вполне меня радовал.
Я любил P4. Был компьютер на первом P4 1.4 ГГц (Willamette?), который разогнался почти до 2.8 ГГц.
Как же был удивлён, когда заменил его на P4 где-то на 2.4 ГГц, тот разогнался до 2.6 ГГц и дальше не захотел!
Похоже, P4 все недолюбливали
Да, пришлось выкинуть отличный и дорогой корпус 3R System AIR Silver — системы на Р4 в нем дико перегревались, а других у меня уже не было.

На этом пути наиболее интересными и стабильными были системы на Pentium 266MMX и Pentium 2 350, продержавшиеся у меня довольно долго.
Все свои многочисленные системы на Pentium 4 я вспоминаю как страшный сон, особенно чудо под именем Pentium D930.
Покой и стабильность обрел только с Core 2 Quad (все еще в эксплуатации), далее везде.
А вчера наконец приехал threadripper 1950x — мне был критичен рендер трехмерки и ничего хоть близко сравнимого по соотношению цена/производительностью у интела и рядом нет. А как он упакован… просто космос, даже отвертку для откручивая соккета положили. Сказал интелу «ну пока». Чувствую, надолго.
Я начинал с80486DX2 (66 MHz) — как раз с картинки. Обходился без охлаждения.
Особенно впечатлил первый Атлон 64 на 1,6ГГц вроде, хотя память может уже подводить. Помню, что Р4 к тому времени были далеко за 2 ГГц, и все равно не могли его одолеть.
До этого атлона, когда в 2003-04 подрабатывал сборкой и настройкой компов, от силы один новый 4 пень на 5 атлонов или дуронов, особенно популярными были модели 1700+ и 1800+. У одного клиента только помню пень на 1,5 ГГц — вероятно, 423. Третьи пни на 1,1–1,2 были гораздо популярнее, но чуть раньше. Тогда же была схожая тема, что GeForce 3 (Ti) лучше, чем 4 (MX 440).
Другое дело, что появившийся позже 9000 за эти же деньги смотрелся в разы интересней.
Тот же Радеон 7500 продавался честнее, как предыдущее поколение карт.
Кушать все хотят, тем более вон на фоне процессоров это ещё цветочки)
И, повторюсь, цена у неё была ниже, чем у 3ти, т.е. соответственно производительности. Глянул в вики — многие технологии от 4ти там таки были, та же компрессия памяти (2ти очень затыкался на ПСП, 4мх сильно менее — даже на сдрам памяти в разгоне был быстрее, с 128бит ддр — почти догонял 4200 в стоке в дх7). Технологии до появления FX-серии были очень дорогой фишкой, это тогда начали несколько чипов клепать, а не переделывать старые.
А по технологиям, у МХ было много всего, но не было самого главного, из-за чего все хотели ДжиФорс 4.
Начиная с DOS 4.0 размер раздела до 2 гб, а при нештатном размере сектора вроде и 4 гб.
А RAMBUS была не только дорогая — ее так и не смогли заставить работать больше двух планок на материнку. В остальные слоты приходилось ставить заглушки.
Pentium стал суперскалярным, с 2мя конвеерами, но все еще исполнял инструкции нативно.
850 чипсете нормально работал с 4мя планками RDRAM
RISC 486 был на уровне ядра, оставаясь снаружи CISC, как и в современых x86\x64.
Не подскажете, где про это можно почитать?
Я все время был уверен, что первый х86 процессор, который транслировал нативные х86 инструкции в свои собственные, а не исполнял их напрямую, был Nx586
Я не утверждаю, что я прав, я хотел бы разобраться.
Как я понимаю, плюс RISC в том, что инструкции короткие, то есть мало шагов надо для исполнения одной инструкции, соответственно исполнительный блок проще, путь сигналов короче, и, при прочих равных, частота его работы может быть выше.
Плюс CISC в том, что инструкции есть на любой вкус и программировать на ассемблере проще, одна CISC инструкция может заменить сразу несколько RISC.
Соответственно, чтобы процессор был RISC внутри и CISC снаружи, он должен полученные CISC инструкции переводить в свои собственные инструкции, и исполнять непосредственно их. При этом CISC инструкции нативно он исполнять не может — в этом нет смысла, иначе зачем их переводить в RISC?
То есть тут я тоже не понимаю, как процессор может быть RISC частично.
books.google.fr/books?id=fuJbAwAAQBAJ&pg=PA275&lpg=PA275&dq=RISC+core+486&source=bl&ots=RFLy72QEA9&sig=qo-vaXma0VJJ_glFlOPG-38CnWg&hl=fr&sa=X&ved=2ahUKEwiwk6XvuOLcAhUKdxoKHWgBCAMQ6AEwA3oECAcQAQ#v=onepage&q=RISC%20core%20486&f=false
Все еще не совсем понятно, и не все страницы доступны для чтения, источников тоже не нашел, но это крайне интересно, я ранее ничего такого не видел.
www-5.unipv.it/mferretti/cdol/aca/Charts/01-risc-MF.pdf
но из него, по крайней мере, следует, что вся RISCовость 486 заключалась в конвейеризации простых инструкций, то есть как бы выделении сабсета нативных х86 команд, которые походили на RISC, то есть были короткими и простыми. Они выполнялись на конвейере, в то время, как более сложные х86 команды выполнялись вне этого конвейера. В статье также написано, что только для сложных команд использовался микрокод, тогда получается, что это было как бы 2 процессора в одном — часть была hard wired для простых инструкций, другая основана на микрокоде для сложных. И, видимо, сложные еще и не конвейеризировались. Интересно все это, но под RISC-ядром я подразумевал нечто совершенно иное. То, что вошло в итоге в Р6.
Идея RISC не в том, что у него команд меньше, а в том, что они простые. Одна команда может содержать либо обращение к памяти, либо арифметику — но не то и другое сразу. Что позволяет поднять частоту.
Ничего подобного в 486м нет.
Инструкции RISC-процессора — не короткие. Например, у ARM = 32 бита.
В частности, это значит, что процессор всегда знает, где начинается следующая команда; т.е. ему не надо ждать распознавания очередной команды, чтобы начать загружать и распознавать следующую.
Кроме того, RISC-инструкции внутри себя устроены так, чтобы увеличить параллелизм. Это значит, что конвейер RISC-процессора, скорее всего, будет короткий. Вроде бы, длинный конвейер — это хорошо или как минимум не плохо; однако, это только на прямых участках кода. Безусловные переходы при длинном конвейере выполняются плохо, условные — ещё хуже, табличные (включая возврат из подпрограммы) — вообще мрак, а аппаратные прерывания — кромешный ужас. А RISC-процессор может готовить аргументы команды ещё до того, как распознал команду — там вариантов очень мало.
К моменту, когда появились RISC-процессоры — программировать на ассемблере брались очень немногие, большинство людей программировали на ЯВУ. А вот для компилятора RISC-процессор куда более удобен.
«Чтобы процессор был RISC внутри и CISC снаружи» — надо иметь раздельный кэш для команд и для данных. Наружние CISC-команды компилируются в RISC-команды, результат компиляции хранится в кэше (обратите внимание: ёмкость такого кэша указывается не в байтах, а в командах).
Теперь при исполнении закэшированного кода — можно воспользоваться преимуществами RISC.
PS: Моя хабра-репутация не позволяет мне писать чаще чем раз в сутки. Поэтому лучше пишите в личку.
Не любят тут людей, мыслящих не-мейнстримно.
Инструкции RISC-процессора — не короткие. Например, у ARM = 32 бита.
Под «короткими» я подразумевал не длину команды в байтах, а количество шагов исполнения, то есть как раз длину конвейера.
Кэш у 80486, насколько я помню, был единым для команд и данных.
Но мне казалось, что раздельный кэш = внутренная гарвардская архитектура, разве RISC не возможен в фон неймановской?
Но мне казалось, что раздельный кэш = внутренная гарвардская архитектура, разве RISC не возможен в фон неймановской?Возможен. Более того: Pentium Pro, где впервые появились микрооперации отдельяющие обращение в память от вычсилений, то есть тот самый «CISC снаружи, RISC внутри» — имеет общий кеш L1 для кода и данных.
Почему вообще в Pentium Pro (и в Nx586 до него) появилась эта идея — превращать CISC команды в RISC-команды? Нет, не для того, чтобы их сохранять в tracing cache — эта идея появилась в P4, показала себя паршиво, от неё отказались, потом она опять вернулась как «кеш L0 для инструкций». В общем ерунда это. То есть да — такой эффект есть, но это эффект «второго порядка».
Главное же отличие инструкций, которые обращаются в память от «вычислительных» инструкций — это их непредсказуемость.
Данные могут быть в кеше, а могут и не быть, две инструкции могут зависеть друг от друга, а могут и не зависеть. Да даже если никаких кешей нет, и команды друг от друга не зависят — может же оказаться, что память у нас просто медленная! В общем сплошная беда с ними.
А вот инструкции, которые с кешами не работают (за исключением деления и всяких синусов-косинусов) — мы знаем точно сколько времени на них потребуется и на что они повлияют.
Вот для чего команды делят на два класса в процессорах класса «CISC снаружи, RISC внутри». Без этого суперскалярность фактически невозможна (то есть теоретически, наверное, сделать-то можно, но практически — суперскалярные CISC процессоры без RISC ядра науке не известны).
Пока я занимался всей этой тригонометрией, я не очень-то жаловал обозначения для синусов, косинусов, тангенсов и так далее. Для меня «sin f» выглядел как s раз i раз n раз f! Так я изобрел другое обозначение, как знак квадратного корня (это была Сигма с вытянутыми длинными концами) и поместил под ним f. Тангенс обозначался буквой Тау с расширенным верхом, а косинус Гаммой, немного напоминающей квадратный корень.
Обратный синус обозначался той же Сигмой, отображенной слева направо, так, что она начиналась с горизонтальной линии, под которой располагалась величина. Это был обратный синус, НЕ sin-1 f — это казалось безумием! И у них это было в книгах! Для меня sin-1 был обратной величиной 1/sin. Мои обозначения были лучше.
Мне не нравилось f(x), мне казалось, что это x, обозначенный f раз. Мне
также не нравилось dy/dx — появлялось желание сократить это до d's — поэтому я придумал другой знак, что-то вроде знака &. Для логарифмов я использовал заглавную L, продолженную вправо, так, чтобы можно было поместить туда величину логарифма, и тому подобное. Я полагал, мои обозначения были достаточно хороши, если не лучше общепринятых, что нет разницы, какими обозначениями вы пользуетесь, но позже понял, что разница все же существует. Однажды я объяснял что-то парню из колледжа и, не задумываясь, стал записывать все своими обозначениями, а он спросил: «Это что за чертовщина?» Тогда только я догадался, если я хочу объяснить что-либо кому-то еще, я должен использовать стандартные обозначения, и мне пришлось
расстаться с моей системой.
Так вот Karpion — расставаться со своей системой не хочет, а вместо этого требует, чтобы все «входили в его положение» и при общении с ним использовали термины не так и не для того, для чего они используются во всей другой литературе.
Мой вам совет: не стоит оно того. Чтобы получить от Karpion'а какое-то знание, а потом перевести его на человеческий язык у вас уйдёт больше времени, чем на то, чтобы узнать то же самое у кого-то, кто не пытается вытребовать себе право «мыслящих не-мейнстримно» путём смешивания всех понятий в кучу.
Поэтому я резко против формулировки «RISC-процессор имеет систему команд с коротким конвейером» — эта фраза порождает у слушателей вредные ассоциации. Тут надо скорее говорить о том, что система команд заточена на высокий параллелизм — т.е. при составлении набора команд думали об этом.
Про кэш у 80486 я не помню. Могу однозначно сказать, что L2 там был внешний, а внешний кэш однозначно был общим (вообще говоря, внешний кэш можно было бы сделать раздельным — но так не делали). А вот внутренний L1 — не помню; думаю, что на тот момент он был общий, т.е. кэшировал содержимое памяти.
Я рассматриваю эволюцию процессоров/компьютеров так:
Сначала были фон-неймановские и гарвадские компьютеры.
По ходу дела — фон-неймановские оказались эффективнее (т.к. у гарвардских ресурсы изначально разделены на два типа — и горе тому, кто сильно промахнулся в оценке того, как их правильно распределить). Гарвардские были вытеснены в основном в нишу embedded, где нужна высокая эффективность, а распределение ресурсов хорошо предсказуемо — ибо известно, какая задача там будет выполняться.
Однако, через какое-то время гарвардские схемы стали появляться в отдельных элементах фон-неймановских компьютеров. Это и кэш; и запрет самоизменяющихся в ходе выполнения программ; в Android это вообще довольно сильно. Да собственно: конвейер — для кода, регистры — для данных, уже гарвардская схема.
А вот формулировка «внутренная гарвардская архитектура» для меня звучит необычно. Мне вообще не нравится дуализм «внешнее-внутренне», т.к. в реальных системах обычно имеется намного больше слоёв.
Что же касается вопроса «разве RISC не возможен в фон неймановской?»…
Есть чистый RISC — он не нуждается в раздельном кэше; ну или если нуждается (например, для предсказания ветвлений или типа того), то нуждается гораздо слабее, чем CISC. Можно и вообще без кэша.
Есть чистый CISC — он не использует раздельный кэш (например, потому что до этого ещё не додумались; или пока что не умеют делать достаточно много транзисторов на кристалле). Можно и вообще без кэша.
А есщё есть вариант, вызвавший у Вас недоумение: «процессор — RISC внутри и CISC снаружи». У меня это тоже вызывало недоумение, пока я не прочёл про раздельный кэш. И тогда, сопоставив два этих факта, я вывел непротиворечивую картину: «процессор бывает RISC внутри и CISC снаружи — только при раздельном кэше (или, Вашими словами — при внутренней гарвардской архитектуре)». Кэш — необходим, и именно раздельный; с khim я тут не согласен.
PS: Допустим, в процессоре — многоуровневый кэш. В этом случае все нижние слои (допустим четыре нижних слоя) будут общими, а все верхние слои (допустим, три верхних) — раздельными. В формулировке «все нижние/верхние» — это «от нуля и более».
Иными словами, раздельный кэш никогда не окажется под общим.
Это я так, для пояснения.
Да, она, в некотором смысле, непротиворечива… и в каком-то другом, альтернативном мире она могла бы быть правдой — но она описана в других обозначениях, в других терминах, чем вся документация, мануалы и прочее.
Поэтому я резко против формулировки «RISC-процессор имеет систему команд с коротким конвейером» — эта фраза порождает у слушателей вредные ассоциации.Как вы верно заметили — RISC это не о конвеере и не о малом наборе команд. У POWER8 число команд измеряется сотнями, а количество транзисторов — миллионами, но тем не менее это — типичный RISC. А вот 6502, у которого транзисторов меньше пяти тысяч — это типичный CISC.
Почему? Да потому что команды POWER'а следуют подходу Load/store architecture, команды либо что-то вычисляют, либо обращаются в память! А у 6502 — наоборот: какая-нибудь команда «ADC (123, X)» делает целую кучу разных вещей: складывает 123 с X'ом, смотрит в эту ячейку памяти и в соседнюю с ней, находит там адрес, образется в память ещё раз и вот только после этого складывает содержимое этого адреса с аккумулятором.
Да, в ранней литературе были разные способы описать CISC и RISC, но сегодня всё устаканилось и основным признаком RISC'а считается Load/store architecture.
Что касается Гарвардской и Фон-Неймановской архитектуры, то это — вообще совершенно другая характеристика процессора. Ранние архитектуры склоняются скорее к Фон-Неймановским архитектурам (и CISC 6502 и RISC ARM2 какой-нибудь — вполне классические Фон-Неймановские архитектуры), более поздние — Гарвардские. Потому что Гарвардская архитектура эффективнее, но требует больше транзисторов.
И тогда, сопоставив два этих факта, я вывел непротиворечивую картину: «процессор бывает RISC внутри и CISC снаружи — только при раздельном кэше (или, Вашими словами — при внутренней гарвардской архитектуре)». Кэш — необходим, и именно раздельный; с khim я тут не согласен.И вот в этом месте — мы изобретаем какую-то альтернативную историю.
Причём тут вообще кеш? CISC снаружи, RISC внутри — это всего лишь построение архитектуры процессора, где ядро работает не с исходными инструкциями, а μopsами, которые реализуют Load/store architecture и никто, кроме декодера с «оригинальными» инструкциями в ядре процессора не работает. Всё. Вот совсем всё!
Стоит ли у вас декодер до кеша или после, и даже есть ли у вас вообще кеш — неважно. Важно — есть ли у вас μopsы и соотвествует ли их архитектура RISC'у.
Действительно, появление процессоров класса CISC-on-RISC — совпало по премени с появлением систем с разделёнными L1 кешами… ну так ними и полноценные RISC'и со временем обзавелись — это просто эффективнее. Но вот кеши эти в первых процессорах такого типа хранили таки байты. Потом появилась разметка (около байта была записана длина команды). А уже μopsы в кеше — это Pentium 4… что, кстати, себя сильно не оправдало. В современных процессорах есть L0 кеш такого типа, но он используется в основном для очень маленьких циклов.
И вот это, собственно — пример того, почему Karpion может писать раз в сутки. Ибо читать эту «альтернативную историю» — никому не интересно.Меня минусовали в основном за утверждения «невидимая рука рынка в этой конкретной области не работает, эту проблему может решить только государство». Т.е. — за политику.
Да, она, в некотором смысле, непротиворечива…Ну так я ввожу свои понятия из-за того, что описания в общепринятых обозначениях — противоречивы.
Например, в своё время я читал, что локальные сети отличаются от глобальных — то ли размером (протяжённостью), то ли количеством пользователей (в разных книгах приводился тот или другой критерий). При этом буквально на той же (или на следующей) странице утверждалось, что Ethernet, Novell Netware и MS Network — это локальные сети (при том, что размер всех трёх м.б. сколь угодно большим, в т.ч. размером с Землю); а Internet — это глобальная сеть. Т.е. противоречие было совершенно явным, но его никто не видел.
Кстати, в первые годы существования Internet — в нём было меньше пользователей, чем в MS Network крупной корпорации в наше время. Т.е. и количество пользователей — никак не показатель.
Мне кажется, Вас должны сильно напрягать понятия типа «скалярное произведение функций» — ведь скалярное произведение определяется как произведение длин векторов на косинус угла между ними, а у функций нет ни длины, ни угла между ними.
Что жу касается документации и мануалов — то там бывает лютый бред.
У POWER8 число команд измеряется сотнямиБольшая проблема ещё и в том, что считать одной командой, а что — разными командами. Например, ADD, ADC и SUB — вполне можно считать одной командой, где выполняемая операция является одним из аргументов.
а количество транзисторов — миллионамиПосле появления внутреннего кэша — количество транзисторов перестало зависеть от архитектуры.
Да, в ранней литературе были разные способы описать CISC и RISC, но сегодня всё устаканилось и основным признаком RISC'а считается Load/store architecture.Странно. Мне всегда казалось, что гораздо важнее — иметь однородный набор регистров; а не так, как у *86, когда для любого регистра можно найти операцию, где его нельзя заменить на другой (например, IN/OUT [DX],AX — оба регистра незаменимы).
Ранние архитектуры склоняются скорее к Фон-Неймановским архитектурам (и CISC 6502 и RISC ARM2 какой-нибудь — вполне классические Фон-Неймановские архитектуры)Ну, я бы не сказал, что 6502 и ARM — это ранние архитектуры.
CISC снаружи, RISC внутри — это всего лишь построение архитектуры процессора, где ядро работает не с исходными инструкциями, а μopsами, которые реализуют Load/store architectureНу, допустим, декодер получает «внешнюю» команду типа ADD [адрес_памяти], регистр — тут надо загрузить данные, сложить их с регистром и запихнуть обратно. Декодер делает из одной команды три и передаёт их на выполнение. А в чём можно выиграть от такого декодирования, если три команды будут выполняться достаточно долго?
Стоит ли у вас декодер до кеша или после, и даже есть ли у вас вообще кеш — неважно.А вот если декодер проанализирует весь поток команд на достаточную глубину — то можно будет сформировать очень оптимизированный код. Одна беда — подобная глубокая оптимизация делается очень долго; поэтому смысл в ней м.б. только если результат оптимизации где-то хранится и используется много раз.
А то место, где что-то хранится и используется много раз — как раз и называется «кэш».
Но вот кеши эти в первых процессорах такого типа хранили таки байты.А что ещё можно хранить в кэше?
Например, в своё время я читал, что локальные сети отличаются от глобальных — то ли размером (протяжённостью), то ли количеством пользователей (в разных книгах приводился тот или другой критерий). При этом буквально на той же (или на следующей) странице утверждалось, что Ethernet, Novell Netware и MS Network — это локальные сети (при том, что размер всех трёх м.б. сколь угодно большим, в т.ч. размером с Землю); а Internet — это глобальная сеть.Ещё один великолепный образчик примера: смотрю в книгу — вижу фигу.
Вас не смутило то, что эти книги читали тысячи, возможно миллионы, читателей, изучали рецензенты — и никакого протиовречия не видели? Да, локальные сети отличаются от глобальных размером. И да, размер-таки имеет значение.
Смею предпложить, что речь в книжке шла о премерах технологий используемых в локальных сетях и, возможно, там даже обсуждалось, почему их в приципе нельзя масштабировать на весь земной шар.
Проще всего понять почему это невозможно на примере Ethernet'а. У него есть так называемое slot time — врямя за которое два любых участника сети должны иметь возможность обменяться сигналами. И даже в старом древнем 10-мегабитном Ethernet'е это время — всего-навсего 51.2 μsec. За это время сигнал даже в вакууме не может преодолеть 20км (а в проводе он движется ещё медленнее), так что ни о каких глобальных сетях и мечтать не приходится.
Причины, по которым NetBEUI и IPX не могут быть расширены на всё Землю — несколько другого класса, но тоже похожие. Дело в том, что в этих сетях клиенты посылают друг-другу «keep-alive» сигналы, количество которых, понятно, растёт как квадрат от количества клиентов. И уже при нескольких тысячах клиентов эти служебные пакеты занимают всю пропускную способность канала. Тем самым с мечтами о сетями на всю Землю, увы, приходится распрощаться.
Т.е. противоречие было совершенно явным, но его никто не видел.И вот именно тут у вас и возникает проблема: ситуация «противоречие явное, но его никто не видит» обычно обозначает, что никакого противоречия нет, однако для того, чтобы это увидеть — нужно поискать дополнительную информацию. Вы же вместо этого переселяетесь в какой-то воображаемый мир, имеющий мало общего с реальностью.
Иногда противоречие, правда, отсуствовало на время написания книги, но появилось потом. Так, современные версии MS Network и Novell Netware — конечно могут быть использованы в глобальной сети. Но это произошло потому, что они, помимо родных NetBEUI и IPX сегодня умеют использовать TCP/IP — но было бы странно требовать от авторов книги уметь предвидеть будущее.
Мне кажется, Вас должны сильно напрягать понятия типа «скалярное произведение функций» — ведь скалярное произведение определяется как произведение длин векторов на косинус угла между ними, а у функций нет ни длины, ни угла между ними.Почему вдруг? Одно из определений использует косинус угла, да. Однако у многих математических понятий есть сильно больше, чем одно определение. В частности гораздо более часто используемое на практике алгебраическое определение прекрасно обощается на функции…
Большая проблема ещё и в том, что считать одной командой, а что — разными командами. Например, ADD, ADC и SUB — вполне можно считать одной командой, где выполняемая операция является одним из аргументов.Тут вы, конечно, правы. Проще, пожалуй, сравнить не ADD и ADC (которые обычно всё-таки считаются разными на всех процессорах), а, скажем, команда сложения векторов. У Intel — это четыре команды (отдельно для 8-битных, 16-битных, 32-битных и 64-битных чисел), а ARM — одна.
Но это как раз не сильно важно, так как уже давно договорились считать, что CISC от RISC отличается не по количеству команд.
Странно. Мне всегда казалось, что гораздо важнее — иметь однородный набор регистров; а не так, как у *86, когда для любого регистра можно найти операцию, где его нельзя заменить на другой (например, IN/OUT [DX],AX — оба регистра незаменимы).Эти идеи как раз пали жертвой эффективности. Рассмотрите ARM Thumb: в Thumb1 при пересылке из R0 в R5 флаги выставляются, при пересылке из R3 в R10 — нет, «младшие» регистры кладутся в память одной командой, старшие — только по одному… в Thumb2 это пофиксили, но R13 нельзя сохранить вместе с остальными регистрами всё равно… а R14 сохранить можно… а восстановить можно только R15…
Ну, я бы не сказал, что 6502 и ARM — это ранние архитектуры.Раньше разве что 4004, но все они гораздо дальше от нас, чем друг от друга.
Или вы про дискретную логику? Да, этот доисторический период тоже интересен — но там совсем другие заморочки…
Ну, допустим, декодер получает «внешнюю» команду типа ADD [адрес_памяти], регистр — тут надо загрузить данные, сложить их с регистром и запихнуть обратно. Декодер делает из одной команды три и передаёт их на выполнение. А в чём можно выиграть от такого декодирования, если три команды будут выполняться достаточно долго?Конечно если у нас программа состоит из одной инсрукции и кроме неё в ней вообще ничего нет, то никакой разницы, конечно.
А вот если у нас таких инструкций много… Если мы исполняем эту интрукцияю как «единое целое», то мы вынуждены под неё задейстовать блок на чипе, который умеет образаться в память и выполнять арифметические операции. А если эта команда разбита на три, то в то время пока загрузчик вытаскивает данные из памяти сумматор может складывать данные в каких-нибудь других инструкциях.
А вот если декодер проанализирует весь поток команд на достаточную глубину — то можно будет сформировать очень оптимизированный код. Одна беда — подобная глубокая оптимизация делается очень долго; поэтому смысл в ней м.б. только если результат оптимизации где-то хранится и используется много раз.Эта «гениальная» идея — центральная в архитектуре Pentium 4. И она же — привела к его чудовищной неэффективности. Проблема не в том, что оптимизация делается долго. Проблема в том, что когда мы пытаемся отпимизировать что-то «не имея всех карт на руках» (не зная, в частности, есть данные в кеше или нет), то мы можем всё сделать так, что в 90% случаев всё будет великолепно, но оставшиеся 10% случаев — нас уничтожат. Потому что мы не знаем заранее — займёт обращение к памяти один такт или двести (да, двести! именно столько занимает обращение к памяти на современных процессорах, если данных нет ни в одном кеше). И мы регулярно делаем вычисления, результат которым нам приходится выкинуть.
На в процессорах до Pentium 4, ни в процессорах после него этого подход не использовался. Он вернулся в сильно ограниченном и урезанном виде только несколько лет назад. И используется только для очень коротких циклов, как я говорил.
Микрооперации, как бы — вы же сами только что написали, что так и нужно делать… Но… Так не делают… Pentium 4 — неудачное исключение… Ну и L0 в современных процессорах — но он крошечный…Но вот кеши эти в первых процессорах такого типа хранили таки байты.
А что ещё можно хранить в кэше?
Мне кажется, Вас должны сильно напрягать понятия типа «скалярное произведение функций» — ведь скалярное произведение определяется как произведение длин векторов на косинус угла между ними, а у функций нет ни длины, ни угла между ними.
Если вы обратите внимание на то, что внутри интеграла в таком скалярном произведении функций, вы заметите, что функции представляются бесконечномерными векторами.
Помните, чему равно скалярное произведение в 3D? V(vx,vy,vz) U(ux,uy,uz) VxU=vx*ux+vy*uy+vz*uz. Так вот, интеграл от (F(x)*G(x))dx и есть сумма произведений точек v=F(x) и u=G(x). Вот и весь секрет скалярного произведения функций.
То, что Вы назвали «скалярное произведение в 3D» — это разложение скалярного произведения в декартовой системе координат, оно же — в ортонормированном базисе. А в исходном определении — никакого базиса нет, перемножаемые векторы «висят в пустоте» (в смысле — не в декартовой сетке).
Разложение скалярного произведение в декартовскую форму — надо доказывать. И отдельно обратить внимание на то, что при изменении базиса (при повороте системы координат) произведение не изменится.
Тогда как исходное определение — совершенно точно от системы координат не зависит, ибо нет там координат. Этим оно, кстати, и нравится математикам.
Что же касается скалярного произведения функций — то оно совсем не обязательно «интеграл произведения функций». В простейшем случае — там бывает нормирующий множитель (неотрицательная функция).
А можно придумать ещё более сложные варианты типа интеграла по иксу от такого:
a(x) * (b(x-1)+b(x+1))
где a(x) и b(x) = перемножаемые функции.
А ведь есть ещё более извращённые скалярные произведения — например, дивергенция векторного поля расписывается как скалярное произведение {очень-псевдо}-вектора «Набла» на это векторное поле. (Фраза «очень-псевдо» означает, что Набла отличается от нормального вектора гораздо сильнее, чем обычный псевдо-вектор.)
Я не готов тут рассказывать про дивергенцию и прочие применения Наблы (ротор и градиент). Кто не в теме (или просто забыл) — в Википедию.
Так что с расширенным толкованием понятий — в математике всё в порядке. Например, математики расширили понятие векторного произведения векторов — на пространство произвольной размерности и произвольное количество векторов. Т.е. можно взять произведение четырёх векторов в семимерном пространства. Правда, произведение будет не вектором, а трёхмерной (кубической) матрицей; вот если векторов будет шесть (на один меньше размерности пространства), то будет действительно вектор (ну, точнее — псевдо-вектор).
А попытка удержать понятия (значения терминов) в прежнем состоянии — резко тормозит прогресс. Что, собственно, мы сейчас и видим.
Вполне вероятен вариант, который old_gamer упомянул, но я не помню сейчас цены уже.
П4 1,6 ГГц 2х первых вариантов с кешем 256 КБ по производительности в играх проигрывал 1,3 ГГц целерону сокет 370 с ядром туалатин.
У меня долгое время был с целероном 1,2 ГГц с ядром туалатин разогнанным до 1,6 ГГц переключением шины со 100 на 133 МГц.
П.С. исправтьте пожалуйста «частоте профессора» :)
и «интернет экспортера»
Только «режет» глаз постоянное использование оборота «представлял из себя». Грамотнее конечно писать «представлял собой». Исправьте, если можете.

А Атомы как-то совершенно мимо меня прошли, я, если честно, о них даже и не думал при написании статьи… Они были чистыми 32 бит, или все 64-бит?
А для полного раскрытия темы не хватает ранних Атомов
Что можно цивильного сказать по ранние Атомы? )
Ну знаете, они побыстрее большинства описанных в статье процессоров будут.
У меня на хозяйстве есть несколько компов с Атомами (N270 Q2'08, N280 Q1'09 и D525 Q2'10)
Это боль — даже под ХР с 2 гигами памяти и SSD на борту — они еле шевелятся под непрерывной 100% загрузкой процессора на обычных офисных задачах. И началось это с ними довольно давно.
При том, что Core 2 Duo E6600 Q3'06, Core 2 Quad Q6600 Q1'07 и Core 2 Quad Q8400 Q2'09 — на офисных задачах работают без каких-либо заметных проблем.
Ну блин, вы по энергопотреблению их сравните.
N270 — 2.5 w
E6600 — 65w
Неудивительно, что они еле шевелятся. Был у меня пегатрон маленький комп на 270 как раз. Продал к чертям, ибо никакой.
Ну блин, вы по энергопотреблению их сравните.
Все эти «атомы» — десктопы от рождения. Там энергопотребление не существенно.
На момент их выпуска они позиционировались как полноценные офисные машины.
Вот одна из них (AT5NM10T-I):

P.S. Кстати во многих случаях энергопотребление — очень даже существенно, если это какая-нибудь касса или электичество в стране не самое дешевое.
Некоторые веб-сайты со «свителками и перделками» будут тормозить, возможно — ну так это не к Атомам претензии.
В результате только побраузить можно было, но остальное — труба.
А уж если какой фоновый процесс запустить типа анализатора движения через веб камеру, то вообще хоть плач.
В результате это чудо было продано, а его место занял ноутбук в закрытом состоянии.
Я планировал на кухне спрятать за монитор и получить просиотр киношек, инета и скайп.А чем вы всё это хотели смотреть и какие киношки? XBMC отлично работет на Xbox (оригинальном), а он куда медленнее Атома.
Конечно если вы хотите на малопотребляющий проц повеcить 4K-рипы, то из этого мало что выйдет…
А так где-то до сих пор валяется нетбук N130 на таком проце, с ХП СП2, так работает всё хорошо, если не лазить в интернет. Музыку крутит, видео тоже, но максимум .264 в HD качестве, 1080 не тянет.
Ещё один артефакт, связанный с RDRAM — злополучные платы производства Intel на чипсете i820. Изначально чипсет был рассчитан на работу с RDRAM (да-да, Rambus в связке с Pentium III!). Продавалось это плохо, поэтому к чипсету решили добавить чип MTH (memory translation hub), который обеспечивал работу с SDRAM PC-100. Закупили по дешёвке аж штук 20 таких матерей, долго и мучительно продавали, но в итоге почти все пришлось поменять из-за спонтанных зависаний. Проявлялись под высокой нагрузкой, в основном в играх, редко, но регулярно. Как выяснилось позже, виноват был именно MTH, вот платы и сливали по символической цене.
И платы в коробках VIA тоже помню. Помню и статьи на ixbt, где угадывали, кто реально произвел какую плату в коробке VIA. Весело было )
Не купил и благодарен авторам подобных статей за привитый скептицизм в отношении подобных заявлений.
Многие пользователи, думающие о своем кошельке, сегодня предпочтут VIA Apollo Pro133A, обладающий практически такими же характеристиками. С другой стороны, нельзя отрицать и то, что перспективы i820 выглядят гораздо более заманчиво, чем у чипсетов конкурентов. Технология RDRAM при поддержке Intel скорее всего приживется и системы на i820 станут не только доступны, но и необходимы рядовому пользователю. Но это — завтра.
«Завтра» так и не наступило.
По ощущениям такой прирост при разгоне ощущался не вооруженным глазом. Это был единственный раз когда я разгонял, так как потом прирост в 1%-5% меня не устраивал :)
Еще не упомянули про линейку Pentium Pro, у меня был WS на 2 таких процессора, Win2000 на них летала, но у процессоров отсутствовало MMX и в плане игр и развлечения он был печален :)
Кто то хоть раз отжимал кнопку Turbo специально и какой в этом был смысл подскажите? :)
А турбо на 286 помогала в Диггер играть )
Прирост скорости был более 50%.
Но она далеко не всегда понижала частоту. Иногда она просто вводила wait states, слышал даже, что были реализации, где она отключала кэш на плате (но не видел сам таких).
Из-за таких различий в исполнении, замедление тоже было на разных платах разным, и совместимостью там и не пахло, на самом деле.
На Duron, скорее всего, было где-то 100, так что замедление было 200-кратным. На самом деле не вплоне XT, но очень чувствительно.
А 486DX в 386DX сокет таки можно ))
Вся жизнь пронеслась перед глазами. Первый мой ПК был XT-совместимый тайваньский клон с процессором 8088. Там был CGA адаптер и 2 5-дюймовых флопа. Вот, начиная с этого раритета, я почти все поколения процессоров поюзал. А прошло то всего каких-то 35 лет...
Это была вроде последняя версия, работавшая на Вин 9х
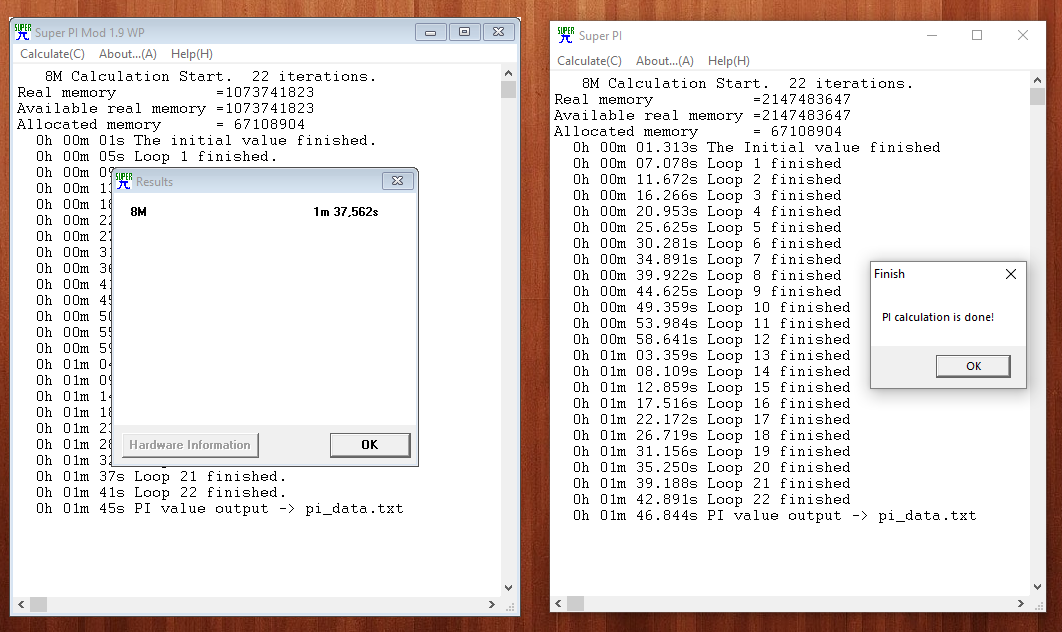
Но 1 мин для i7 звучит жестоко… Скорее там 1 секунда должна быть, или меньше.
Вполне в пределах того, что ожидал из цифр в статье.
Думаю, дело в версии. Попробуйте 1.1
По поводу вашего результата, не забывайте также, что это жутко устаревшее ПО. Там используется только FPU, когда современные процессоры показывают Асю свою мощь на SIMD. Так что результат в целом закономерен.
У меня под рукой ничего быстрого на Винде нет.
Попробую на Райзен3 установить Винду, когда болванки придут.
Ещё идея. Сколько у вас итераций делает тест?
У меня 22
Но у меня 2 разных, на 95 не то, что на ХР. Их результаты друг с другом бьются. Выложу оба.
yadi.sk/d/3FgttnxSdJXtQg
yadi.sk/d/zSUXYjLlX1Bk9A
Meltdown & Spectre? Винда? Заговор? Или просто пора апгрейдится на P4) Надо будет проверить на Athlon 64 X2, если заведу)
Есть теория, что FPU каким был в P4, таким и остался теперь, ибо никому особо не нужен теперь с SIMD. Приложение однопоточное, частоты близки, вот и результаты близки.
Попробуйте на Атлоне, если получится.
Явно ошибка какая-то, тут 1м за это время явно более быстрый процессор не успевает просчитать ;) Долго следил за этис тредом, всё пытался понять, о чём речь, наконец понял)
Версия 1.1 от 21 сентября 1995 года.
А как обидно было купив топовую систему на чипсете i925XE с процессором P4 3.6 Ghz узнать, что выходящий в следующем году процессор с индексом D(двухъядерный) на нее просто не встанет(вероятно во блаж маркетологам)…
Корки 65-45 тоже были хороши, кто-то делал обновление биоса, кто-то зажал и выпускал новые ревизии материнок.
А не тот хабра-твиттер, который у них сейчас.
Мне показалось, или некоторые материнки редких переходных разновидностей ISA+PCI?
Мне не удалось найти программу-кодировщик MP3, которая работает под Windows 95
Эээ может быть LAME спасет лонгрид?
LAME compiles on Windows, DOS, GNU/Linux, MacOS X, *BSD, Solaris, HP-UX, Tru64 Unix, AIX, Irix, NeXTstep, SCO Unix, UnixWare, Ultrix, Plan 9, OpenVMS, MacOS Classic, BeOS, QNX, RiscOS, AmigaOS, OS/2, SkyOS, FreeMiNT(Atari) and probably a few more.
Может в качестве теста/бенчмарка использовать System Speed Test 4.78?
не обижайтесь, это просто мелкие придирки.
А так аплодирую стоя, месье знает толк (в хорошем смысле) в извращениях.
Мой боевой путь на PC платформе: 8086-4,77 (Искра 1030), TurboXT 8088-12, первая личная машинка на UMS U5S-33 (разгонялась до 50), далее 5х86-133(160) на SIS486/7, далее P166MMX на Zida100, и далее К6, Celeron и т.д.
Начинал со спектрума, потом 286 и т.д., штук 10-15 точно. Всегда всё про них знал досконально, разгонял все что мог. Игроман был конченный.
Толи я постарел, толи действительно както все стало скучновато в этой области.
После освобождения от RAMBUS, Intel предложила россыпь чипсетов для DDR SDRAM, сначала одноканальный i845D, затем — двухканальные i865 и i875. Чипсет i915, поддерживающий шину PCI Express и DDR2 SDRAM, формально, был рассчитан на 64х разрядные Pentium 4 в исполнении Socket LGA 775, однако некоторые производители предлагали платы для Socket 478 с таким чипсетом.Незаслуженно забыт обрезок от i865 — скромный трудяга i848
Хотел бы я купить книгу про современную историю компьютеров, написанную в вашем стиле. Я много чего хотел бы.
Но выкинуть рука не подымется, чот слишком много молодости у меня с этим хламом связано =)
Athlon действительно поражали.
У меея был 3й системник на нем: когда его "штатный" поенциал кончился, я взял в руки карандаш, зарисовал перемычку…
Короче мой 1.4 спокойно работал зимой на 2.8 и летом на 2.6.
Как сей час помню медный павлиний хвост Zlaman, торчащий из лежащего на боку корпуса денег на новый не было, да и не ясно было зачем а вот охлаждать было нужно!
Самый первый мой (именно мой) компьютер был LEO в корпусе full tower. Это был 486 DX3 (тут я уже не уверен) и он имел свою коробку, мышку м клавиатуру! Просто космос по всем понятиями, даже сей час. А еще у него был супер глюк: Win95 на него ставилась только с отключенным 5-ти дюймовым дисководом, иначе инсталляция висла (это спустя лет 7 я узнал что это глюк и как его обходить)… Именно по этому я пропустил эту систему, так как сразу на нем встала 98я...
Корпус дил со мной долго, даже упомянутый выше атлон работал именно в нем.
Папки в коробкпх с цветными иллюсирациями, золотое теснение на первой странице мануала…
Папки так и жили со мной очень много лет (хранил в них все те же мануалы, но от новых систем, пока, в очредной переезд я не отпустил их в вольное плаванье.
З.Ы. я так и не могу найти его фото в сети, а у меня с того времени ничего нет.
Ну и хорошо!
Я тут нашел скан книжечки… Точно такая же, но для 486го…
https://archive.org/details/leo386_comp
Не знаю, как оно влияло на производительность, но вот самомодифицирующийся код делать мешало.
В следующем году ему на замену был выпущен 32-битный двуядерный Core Duo.
Далее для ноутбуков сделали 64-битный Core 2, и 32-битность на некоторое время задержалась только в атомах.
WinAmp 2.x на AMD K5 PR133 (100MHz) загружал проц на ~30%, как сейчас помню:)
32-битные процессоры Intel: от 3 до 4 — Бесполезный пятничный лонгрид