Comments 24
Живу в Украине. Тут доступ к едрпоу (ваш егрюл) абсолютно бесплатный, читаю и не могу поверить, особенно цены. (((
Приветствую, коллеги! А что случилось с номерами телефонов в апдейтах ЕГРЮЛ в 2018? На 01.01.2018 телефоны были, а теперь нет((
> Заплатить 150 000 ₽ за один справочник или 300 000 ₽ за два
это разовый платеж или ежегодный?
это разовый платеж или ежегодный?
Ох ещё бы рекламу прикрыть, открыл ООО — замучали предложениями открыть счёт, ИП — то же самое :)
В тексте неточность, доступ не по ftp, а http. Кстати, весь 17й год в комплекте с егрип шла АИС из которой можно было скрейпить ДР и место рождения. Кто-нибудь в курсе, собираются вернуть такое?
Интересна была бы статья про то, как вы егрюл обрабатываете. Начиная с хранения — orm фреймворк такие жирные xml тянет или нет? какая субд, какие ттх у системы вышли — иногда наложки выкатывают после 2недельной паузы сразу с миллион обновлений юл, с какой скоростью обрабатывается. сколько запросов к апи в сутки и сколько каких серверов обслуживает. ну и да, про специфику егрюл — как решали проблемы что например в одном юл два пупкиных ви с разными инн. нутро ж подсказывает, что это один человек, но как это обработать…
Отличные вопросы, спасибо! Поговорю с ребятами-разработчиками, которые работают «на земле». Может быть, сделаем отдельную статью.
Присоединяюсь к предыдущему оратору, и вы обещали статью на этой неделе… Очень жду, очень интересно. Пока это просто хантинг с вашей стороны :)
Вот же статья, которую обещал habr.com/company/hflabs/blog/414885 :)
На вопросы mspain ответили там же в комментариях. Правда, не так уж интересно получилось.
На вопросы mspain ответили там же в комментариях. Правда, не так уж интересно получилось.
в одном юл два пупкиных ви с разными инн. нутро ж подсказывает, что это один человек, но как это обработать…
Смотрю спецификацию, таблица 4.100 «Сведения о ФИО и (при наличии) ИНН ФЛ (СвФЛЕГРЮЛТип)» — там ИНН, Фамилия, Имя, Отчество.
На самом деле не обязательно. Насколько я понимаю, с точки зрения ФНС, люди идентифицируются по ИНН.
С точки зрения ФНС это разные люди… Вот тут обсуждают проблему двух ИНН. Если верить гуглу, у человека может быть два ИНН — один на физлицо, второй на него как на ИП.
Но может ли человек быть одновременно учредителем и соучредителем от имени ИП имени себя для своего ООО — не знаю. Вероятно, это незаконно и следить за этим должен тот же ФНС.
P.S. Не имею отношения к HF Labs, если что.
>На самом деле не обязательно
Не обязательно, но вероятность что в шараге ОООшной встретилось два разных Баранчука Васиссуалия Моисеевича почти нулевая. И соответственно, 99.Х% что это косяк налоговой и физлицо одно.
>соучредителем от имени ИП имени себя для своего ООО
Кажется вы не разобрались в вопросе :)
Не обязательно, но вероятность что в шараге ОООшной встретилось два разных Баранчука Васиссуалия Моисеевича почти нулевая. И соответственно, 99.Х% что это косяк налоговой и физлицо одно.
>соучредителем от имени ИП имени себя для своего ООО
Кажется вы не разобрались в вопросе :)
Не обязательно, но вероятность что в шараге ОООшной встретилось два разных Баранчука Васиссуалия Моисеевича почти нулевая. И соответственно, 99.Х% что это косяк налоговой и физлицо одно.
Вообще говоря, проверять такие косяки — как раз задача налоговой.
Я бы на месте обработчика этих данных вумное лицо не делал и подобные «вероятно-баги» решать не брался.
Потому что в каком-нибудь АО с 500 учредителями вполне вероятно появление двух Смирновых Андреев Александровичей с разными ИНН и, действительно, разных людей.
У меня сейчас нет доступа к дампу ФНС, мне нечем подтвердить это мнение. Просто поверьте на слово ;-)
Я и не утверждаю, что надо слить ФЛ в одно. Но обрабатывать это надо с учётом. Иначе и выходит: «есть СПАРК, а есть остальные дешевые и убогие аналоги».
«есть СПАРК, а есть остальные дешевые и убогие аналоги».
Не осознал проблемы.
Как обрабатывать — непонятно. Как я писал выше — два ИНН у физлица — это не нормально, это косяк налоговой.
Но исправлять его на стороне негосударственной аналитики мы не можем… хотя бы потому, что можем легко в результате предоставить пользователям недостоверную информацию. А работаем мы с бизнес-данными, на основе нашей аналитики человек может принять критичное для своего бизнеса решение.
Мы даже не имеем права написать: «Иванов Иван Иванович, ИНН XXXX и И.И.И., ИНН YYYY» — возможно одно и то же лицо.
Отмечу, что размер архива не бывает больше 50 Мб.
Два года назад делал для руспрофайла импорт данных из ЕГРЮЛ. Наступил на все грабли, которые мог.
Жирные XML (а они доходили до 50 метров каждая) стандартный пхп-шный XML Parser не брал, падал сразу (выделил процессу 4 гектара — стал падать на 2-3 XML-ке, принудител ьное освобождение памяти не помогало).
Опыта в кастомных парсерах у меня немного, пришлось писать костыльное, на первый взгляд, решение, которое потом оказалось весьма эффективным.
Жирные XML-ки (в каждой до 1000 выгрузок) режем регуляркой на отдельные выгрузки — это строчки
Строчки зипуем, пишем в базу.
Зачем? В перспективе планировалась возможность сравнивать изменения в истории компании по выгрузкам. Каждый раз парсить файлы на предмет нужной выгрузки — я счел совершенно нерациональным подходом и решил хранить «сырую» выгрузку.
Ну, кроме сырой выгрузки хранилась еще всякая служебная информация — атрибуты
и другая мета, полезная для.
Потом сырые данные вынимались, каждая такая выгрузка заворачивалась в валидный XML, он парсился, нужные данные раскладывались куда нужно…
Реализовали ли анализ истории компании по выгрузкам и реализовывали ли — не знаю, это было уже без меня (личный конфликт с ПМ-ом уровня «я думал, ты догадаешься, как надо было сделать» закончился закономерно).
Теперь по поводу скорости обработки: понятно, что импорт из XML «сырых» данных в базу практически ограничен только скоростью I/O. Суточный diff всасывался со свистом, менее чем за минуту.
Анализ и полный разбор выгрузки, хотя и выглядел сложным с точки зрения спецификации, на деле оказался довольно простым. Нет, там действительно довольно мозголомная структура, но по сути все просто — анализируем ноду, разбираем атрибуты, пошагово разбираем субноды. В сумме что-то около 120 таблиц (пришлось прибегнуть к денормализации для ускорения парсинга, но, конечно, не везде, только в паре мест).
Хотя сейчас я бы написал парсинг иначе, более оптимально.
На продакшене, если мне не изменяет память, один дифф обрабатывался максимум секунду, минимум менее сотой доли секунды (действительно, есть компании, у которых СвЮЛ-запись весит под 40 метров, например, список учредителей может быть под 4000 человек).
Ну и по итогам парсинга выяснились довольно забавные вещи.
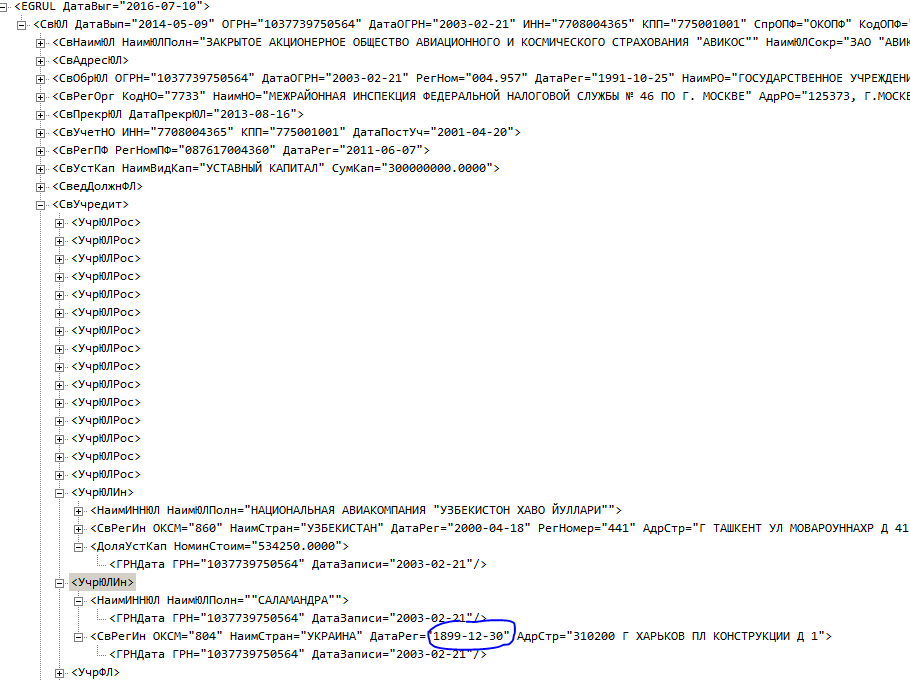
Дата выгрузки в позапрошлом веке
Самое длинное название региона (на 2016 год): поселок Центральной Усадьбы Совхоза 40 Лет Октября Машоновского сельского поселения Зарайского района Московской области
Самое длинное название компании в СвЮЛ/СвНаимЮЛ/НаимЮЛПолн (до 1000 символов) не влезает — там что-то в духе профсоюз союза профсоюзов ответственных работников…
С именами собственными отдельная песня — чего только люди в ФИО учредителя не пишут! Чуть ли не ребусы встречаются.
P.S.
К слову, кроме телефонов, в ЕГРЮЛ есть поля и для более критичных данных.
Два года назад делал для руспрофайла импорт данных из ЕГРЮЛ. Наступил на все грабли, которые мог.
Жирные XML (а они доходили до 50 метров каждая) стандартный пхп-шный XML Parser не брал, падал сразу (выделил процессу 4 гектара — стал падать на 2-3 XML-ке, принудител ьное освобождение памяти не помогало).
Опыта в кастомных парсерах у меня немного, пришлось писать костыльное, на первый взгляд, решение, которое потом оказалось весьма эффективным.
Жирные XML-ки (в каждой до 1000 выгрузок) режем регуляркой на отдельные выгрузки — это строчки
<СвЮЛ ...>....</СвЮЛ>Строчки зипуем, пишем в базу.
Зачем? В перспективе планировалась возможность сравнивать изменения в истории компании по выгрузкам. Каждый раз парсить файлы на предмет нужной выгрузки — я счел совершенно нерациональным подходом и решил хранить «сырую» выгрузку.
Ну, кроме сырой выгрузки хранилась еще всякая служебная информация — атрибуты
<ЕГРЮЛ ДатаВыг=... >и другая мета, полезная для.
Потом сырые данные вынимались, каждая такая выгрузка заворачивалась в валидный XML, он парсился, нужные данные раскладывались куда нужно…
Реализовали ли анализ истории компании по выгрузкам и реализовывали ли — не знаю, это было уже без меня (личный конфликт с ПМ-ом уровня «я думал, ты догадаешься, как надо было сделать» закончился закономерно).
Теперь по поводу скорости обработки: понятно, что импорт из XML «сырых» данных в базу практически ограничен только скоростью I/O. Суточный diff всасывался со свистом, менее чем за минуту.
Анализ и полный разбор выгрузки, хотя и выглядел сложным с точки зрения спецификации, на деле оказался довольно простым. Нет, там действительно довольно мозголомная структура, но по сути все просто — анализируем ноду, разбираем атрибуты, пошагово разбираем субноды. В сумме что-то около 120 таблиц (пришлось прибегнуть к денормализации для ускорения парсинга, но, конечно, не везде, только в паре мест).
Хотя сейчас я бы написал парсинг иначе, более оптимально.
На продакшене, если мне не изменяет память, один дифф обрабатывался максимум секунду, минимум менее сотой доли секунды (действительно, есть компании, у которых СвЮЛ-запись весит под 40 метров, например, список учредителей может быть под 4000 человек).
Ну и по итогам парсинга выяснились довольно забавные вещи.
Дата выгрузки в позапрошлом веке
{kind=link}
Самое длинное название региона (на 2016 год): поселок Центральной Усадьбы Совхоза 40 Лет Октября Машоновского сельского поселения Зарайского района Московской области
Самое длинное название компании в СвЮЛ/СвНаимЮЛ/НаимЮЛПолн (до 1000 символов) не влезает — там что-то в духе профсоюз союза профсоюзов ответственных работников…
С именами собственными отдельная песня — чего только люди в ФИО учредителя не пишут! Чуть ли не ребусы встречаются.
P.S.
К слову, кроме телефонов, в ЕГРЮЛ есть поля и для более критичных данных.
{kind=link}
Спасибо, что так подробно расписали! Это интересно, передал ребятам-разработчикам.
К сожалению, у вас JAVA (насколько я могу судить по списку вакансий), а так бы я еще и предложил своё CV передать ;-)
Все верно, у нас Java без альтернатив. Вы так шикарно все расписали, что даже жаль, что мы разошлись!
>(выделил процессу 4 гектара — стал падать на 2-3 XML-ке, принудител ьное освобождение памяти не помогало)
>К сожалению, у вас JAVA
Читая про ваши приключения с пыхыпы и «выделил процессу 4 гектара — стал падать на 2-3 XML-ке», можно считать, что «К СЧАСТЬЮ, у них java» :))))
Никаких проблем с жором памяти не замечал, программе выделено намного меньше 4ГБ, а уж про удобство жавовского JAXB и говорить не стоит. Если ребята с прямыми руками, у них XML автоматически конвертируется в Java объекты. Дальше работать одно удовольствие. Читаешь про приседания с php и радуешься, что не php-шник :)
>К сожалению, у вас JAVA
Читая про ваши приключения с пыхыпы и «выделил процессу 4 гектара — стал падать на 2-3 XML-ке», можно считать, что «К СЧАСТЬЮ, у них java» :))))
Никаких проблем с жором памяти не замечал, программе выделено намного меньше 4ГБ, а уж про удобство жавовского JAXB и говорить не стоит. Если ребята с прямыми руками, у них XML автоматически конвертируется в Java объекты. Дальше работать одно удовольствие. Читаешь про приседания с php и радуешься, что не php-шник :)
А вы попробуйте. Возьмите XML-файл метров на 50 и попробуйте распарсить. А заодно расскажите нам про сложности выделения памяти для JAVA-машин в виртуальных контейнерах.
Про удобство JAXB говорите джавистам, мне эта аббревиатура не говорит ни-че-го.
И, к слову, даже нативный PHP-шный парсер XML на выходе дает… объект. С которым можно работать привычными стрелочками.
Про удобство JAXB говорите джавистам, мне эта аббревиатура не говорит ни-че-го.
И, к слову, даже нативный PHP-шный парсер XML на выходе дает… объект. С которым можно работать привычными стрелочками.
Да, еще к парсингу данных. Выше речь шла о полном разборе выгрузки по юрлицу.
Сокращенный парсинг — название, ИНН, ОГРН, руководитель, адреса, реквезиты, оквэды итп парсились почти мгновенно, актуальная база из 10 млн юрлиц составлялась примерно за час-полтора. Ну, насколько я помню.
Сокращенный парсинг — название, ИНН, ОГРН, руководитель, адреса, реквезиты, оквэды итп парсились почти мгновенно, актуальная база из 10 млн юрлиц составлялась примерно за час-полтора. Ну, насколько я помню.
Sign up to leave a comment.
Как устроен ЕГРЮЛ — единый госреестр юридических лиц