Уровни игры Montezuma’s Revenge на Atari
Компания DeepMind продемонстрировала процесс обучения ИИ (слабой его формы) для прохождения игр на Atari. Обучение производилось путем демонстрации системе видео прохождения игр с YouTube. Такой способ используют многие игроки-люди, у которых по той либо иной причине не получалось пройти какую-то игру.
Обычно для решения такой задачи необходимо использовать так называемый метод обучения с подкреплением (reinforcement learning). Методика эта достаточно популярна, поскольку позволяет тренировать ботов для выполнения различных специфических задач. Как только система добивается какого-либо результата, она получает небольшое вознаграждение.
Разработчики создают алгоритмы и модели, которые в состоянии оценить игровое окружение, включая и возможные вознаграждения за прохождение (очки, бонусы и т.п.). Такие системы изучают игру шаг за шагом, постепенно продвигаясь к финалу.
Новый метод, разработанный в DeepMind, отличается от всех прочих. Специалисты компании смогли обучить ИИ проходить такие игры под Atari, как Montezuma’s Revenge, Pitfall и Private Eye. При этом акцент на очках и призах не делался — обучение шло по туториалам с YouTube. И это позволило добиться необычных для ИИ результатов.
Дело в том, что игры вроде того же Montezuma’s Revenge сложны для «понимания» машинами. Здесь нет четкого задания, не совсем понятно, куда нужно идти, какие предметы собирать и что с ними делать в дальнейшем. Машина просто теряется, поскольку в процессе продвижения она не получает наград и обучение с подкреплением здесь становится бесполезным или почти бесполезным.
В игре, о которой идет речь, нужно управлять персонажем с именем Panama Joe. В итоге он должен добраться до сокровищницы в старом храме. По легенде, эти сокровища принадлежат Монтесуме. Для начала нужно обнаружить первый критически важный для прохождения игры предмет — золотой ключ. Для его обнаружения нужно пройти около 100 шагов. Но это если знать, что примерно делать. Если нет — существует огромное количество возможностей 10018 изначальных действий. Это слишком много для любого ИИ, созданного человеком. Ну и награду здесь не получишь, все очень и очень специфично.
Один из способов дать компьютеру понять, что делать — продемонстрировать сценарии прохождения. Собственно, не только машины, но и люди учатся выполнять разного рода задачи по примерам. Танцы, действия художника, пайка — все это лучше всего посмотреть 1 раз, а не 100 раз услышать, как нужно делать.
В DeepMind пришли к мнению, что это лучший способ показать компьютеру способ выполнения задачи с неявным результатом. Технология, созданная специалистами, действительно помогла. Для обучения примером использовались два метода: TDC (temporal distance classification) и CDC (cross-modal temporal distance classification).
В первом случае ИИ обучают определять расстояние в игровом окружении, замечать разницу между двумя разными фреймами. ИИ также «понимает», что нужно делать для перехода из одного места в другое. Для обучения в YouTube видео выделяют пары фреймов в случайном порядке.
Во втором случае добавляется еще и «понимание» звукового сопровождения. Звуки практически во всех играх соответствуют выполнению определенных действий. Например, прыжки, получение предметов и т.п. Таким образом, компьютер обучают воспринимать звуки как важные игровые элементы. Видеоряд + звук позволяют компьютеру весьма неплохо продвигаться в процессе прохождения игры.
Вот действия обученного ИИ в игре Montezuma’s Revenge. Прохождение двух остальных игр, упомянутых в самом начале — здесь.
Правда, полностью от роли вознаграждений отказаться не удалось — до сих пор ИИ зависит от тех же очков. Но обычный метод обучения системы, который использовался ранее, не позволял добраться хотя бы до золотого ключика, за который дается первая сотня очков. Так что ИИ, как слепой котенок, тыкался во все стороны, не понимая, что делать. Правда, система «подкрепления» также модифицирована.
В процессе прохождения каждый 16-й видеофрейм записи прохождения игры ИИ сравнивается с фреймами видео прохождения игры людьми. Если сравнение показывает высокую степень схожести, то ИИ получает награду. С течением времени ИИ начинает выполнять ту же последовательность действий, что и человек, для того, чтобы получить схожий фрейм.
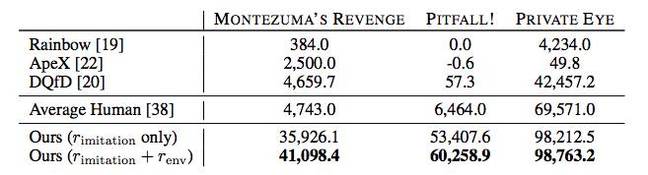
Более того, ИИ во многих случаях показывает лучшие результаты, чем игроки-люди или другие алгоритмы прохождения, включая Rainbow, ApeX, и DQfD.
В принципе, все это впечатляет, но пока что неясна практическая польза достижений DeepMind. Можно ли использовать способ обучения ИИ, предложенный компанией, где-либо кроме прохождения старых игр? Но зная о достижениях DeepMind в сфере ИИ, можно не сомневаться, что так либо иначе все это можно использовать с практической целью — вряд ли специалисты начали бы работу над вопросом ради «фана».
