
Многие продукты нашей компании работают с изображениями. Некоторое время назад мы решили добавить в такие сервисы «умный» поиск по фотографиям, их теггирование. Такая функциональность будет входить в Computer Vision API для дальнейшего использования в продуктах компании. Одним из важных способов теггирования изображений является теггирование по сценам, когда в результате мы получаем что-то такое:
В сообществе Computer Vision достаточно хорошо изучена задача распознавания объектов (Object recognition). Одно из главных соревнований в области машинного зрения — ImageNet, и алгоритмы (свёрточные нейронные сети с 2012 года), которые побеждали в дисциплине распознавания объектов, как правило, становились state-of-the-art. Однако распознавание сцен исследовано значительно меньше, только с прошлого года эта задача входит в ImageNet. Главное отличие распознавания сцен (Scene recognition, Place recognition, Place classification) от распознавания объектов заключается в том, что сцены — более комплексные сущности. Например, для того чтобы определить, что на картинке изображён котёнок, алгоритму необходимо детектировать и распознать одну сущность — непосредственно котёнка.

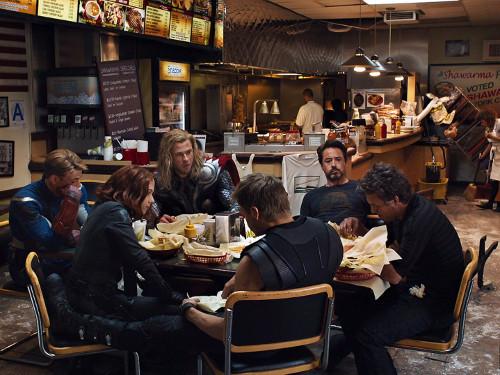
Однако для определения того, что на картинке ресторанчик, надо найти различные предметы, характерные для него: стол, стулья, прилавок, кухню, подсвеченное меню, посетителей и т. д. Таким образом, для распознавания сцены необходимо определить контекст, несколько объектов и их взаимодействие между собой.
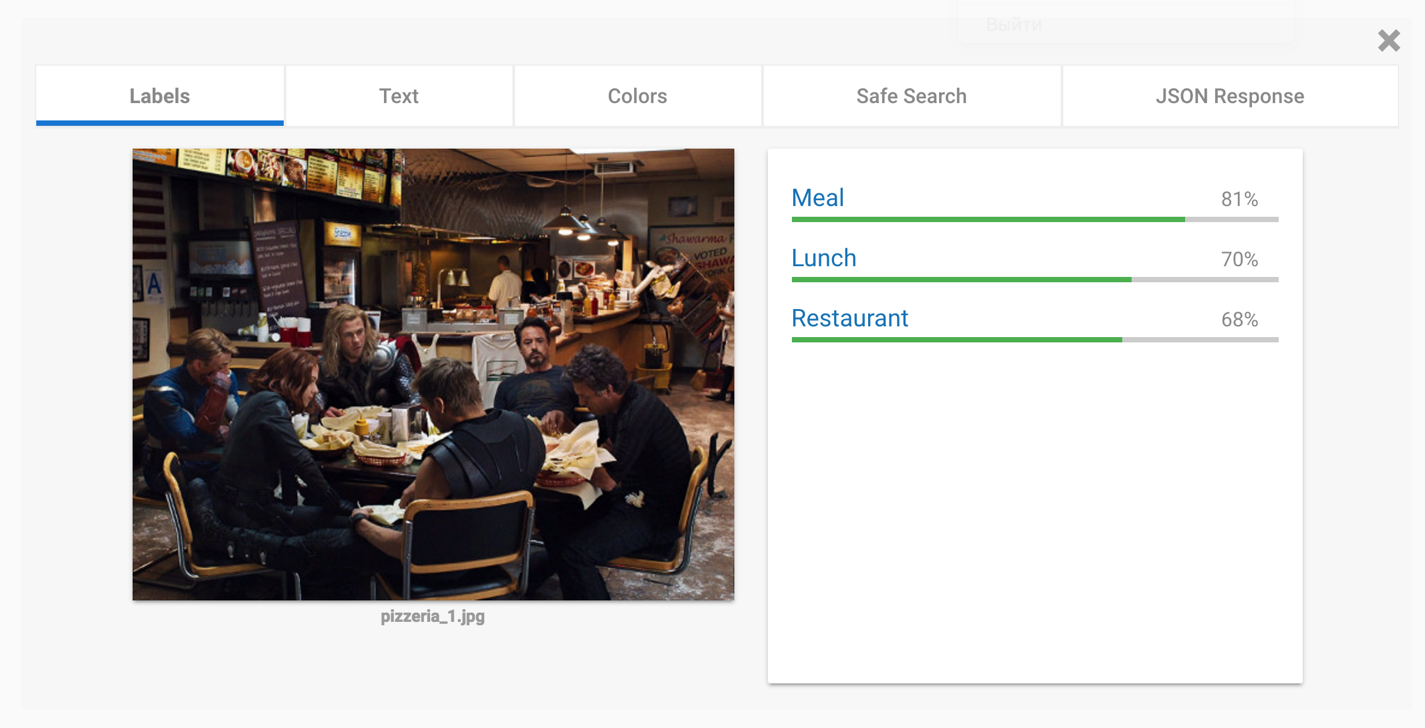
Современные Computer Vision API умеют работать со сценами. Убедимся в этом на примерах CV API от Google и Microsoft. Оба включают в себя в числе прочего тегирование по сценам. Примеры работы Google CV API:
И Microsoft CV API:
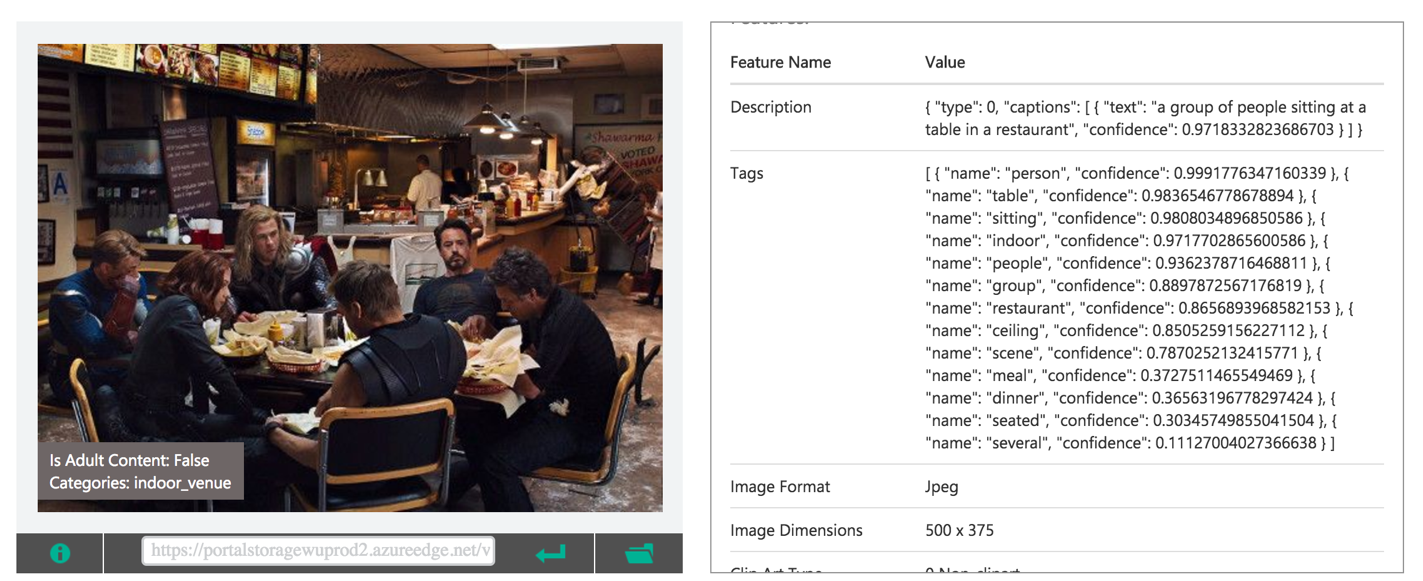
Как видно из приведённых выше примеров, оба сервиса включают в себя распознавание сцен и находят на тестовой картинке ресторан. Наша задача состояла в том, чтобы добавить схожую функциональность в наше Computer Vision API.
Распознавание сцен стало активно развиваться параллельно с началом бума свёрточных нейронных сетей (convolutional neural networks, CNN), т. е. примерно с начала 2010-х годов, когда стали появляться в свободном доступе базы данных. Так как наша модель — это глубокая CNN, то для её обучения нам требовались достаточно большие и разнообразные датасеты. В таблице представлены основные базы данных.
В 2014 году появилась база Places, а в 2016-м — её вторая, расширенная версия Places2 от MIT. Эту базу можно скачать в двух видах: Places2-Standard и Places2-Challenge. Places2-Standard представляет собой уменьшенную версию Places2-Challenge, в которой классы более сбалансированы. В ImageNet 2016 года было включено соревнование Scene classification, основанное на Places2-Challenge. Лучший результат в этом соревновании с top-5 ошибки 9,01 % показала китайская команда Hikvision Research Institute. Примеры из базы Places2 приведены ниже, на таких данных происходило обучение нашей сети.

Обучение современной глубокой CNN даже на Places2-Standard занимает несколько суток. Для того чтобы протестировать и отладить различные архитектуры и подобрать параметры модели и обучения за приемлемое время, мы решили пойти по пути, который активно используется в Object recognition. Там модели сначала проверяют и отлаживают на небольших базах CIFAR-10 и CIFAR-100, а затем лучшие из них обучают на большом датасете из ImageNet. Мы урезали базу SUN до 89 классов, 50 тысяч изображений в тренировочном множестве и 10 тысяч в валидационном. На полученном датасете SUN Reduce сеть обучается порядка 6—10 часов и даёт представление о своём поведении при обучении на Places2.
При детальном исследовании Places2 мы решили избавиться от некоторых классов. Причинами для этого послужили отсутствие необходимости в этих классах в production и слишком маленькое количество данных, что создавало перекос в обучающей выборке. Примеры таких категорий — aqueduct, tree house, barndoor. В итоге после чистки получилась база Places Sift, которая состоит из 314 классов, Standard train множество включает в себя около 1,5 миллиона изображений, Challenge train множество — около 7,5 миллиона изображений. Также при изучении категорий стало ясно, что их слишком много и они чересчур подробные для использования «в бою». Поэтому мы объединили некоторые из них в одну, назвав эту процедуру Scene mapping. Вот примеры объединения классов:
Scene mapping применяется только при выводе результатов пользователю и только в некоторых задачах, где это имеет смысл. Обучение CNN происходит на оригинальных классах Places Sift. Также в CV API есть выдача embedding из сети для того, чтобы на основе нашей модели можно было дообучать новые.
С 2012 года (победа в ImageNet команды Университета Торонто, которая использовала CNN AlexNet) свёрточные нейронные сети стали де-факто state-of-the-art во многих областях Computer Vision и демонстрируют значительный потенциал для дальнейшего прогресса, поэтому в наших экспериментах мы рассматривали только этот тип моделей. Я не буду вдаваться в описание основ CNN, этому уже посвящены отдельные посты, например. Для общего представления на картинке ниже изображена классическая сеть LeNet от Яна Лекуна:

Чтобы определиться с архитектурой сети, мы отбирали CNN, основываясь на результатах ImageNet и Places2 за последнюю пару лет. Топовые модели на этих двух соревнованиях можно с некоторой долей условности разделить на семейство Inception (GoogLeNet, Inception 2—4, Inception-ResNet и производные от них) и на семейство Residual Networks (ResNet и различные способы его улучшения). В результате наших экспериментов по распознаванию сцен лучше всех себя показали модели из семейства ResNet, поэтому дальнейшее повествование будет связано с ними.
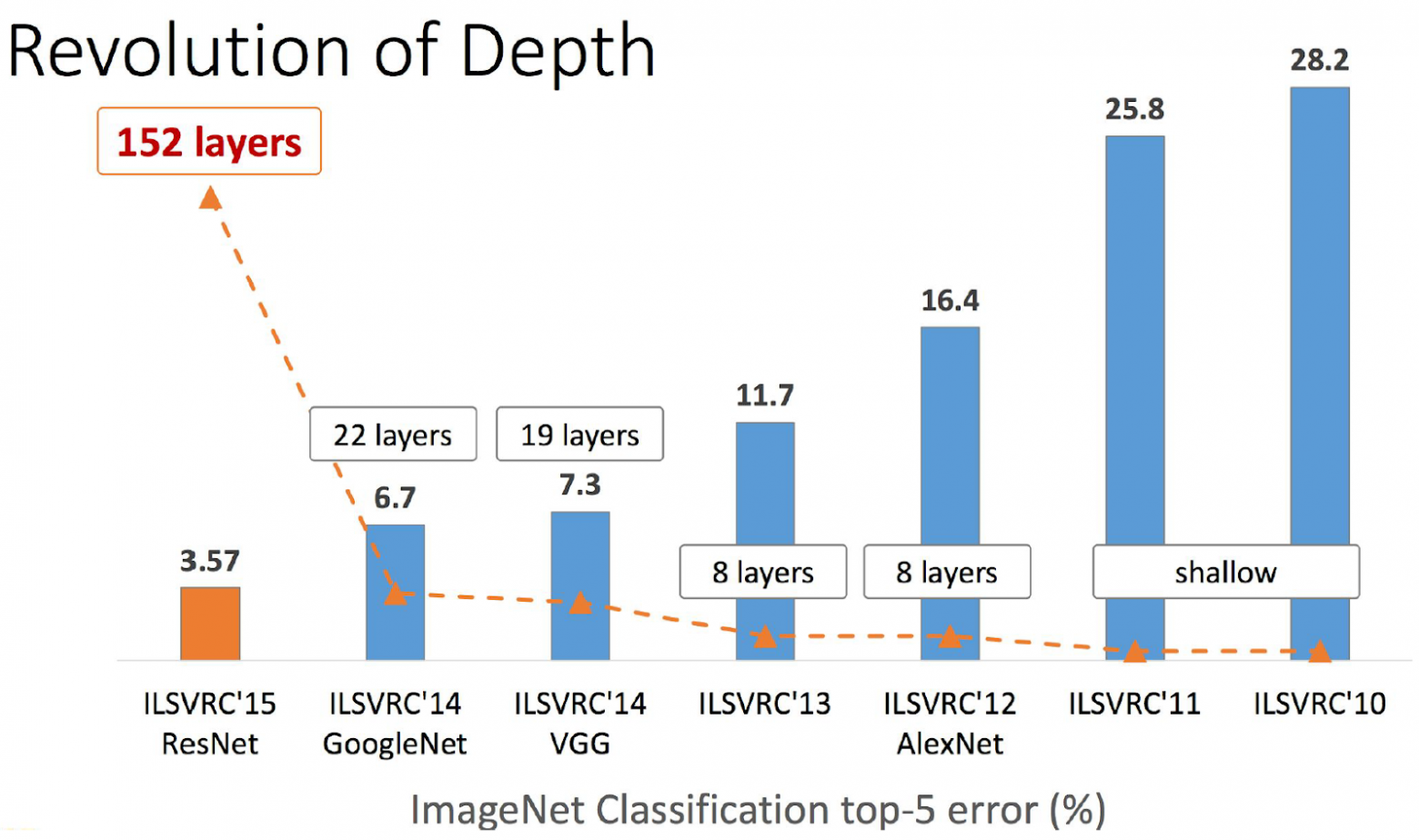
Residual Networks, сокращённо ResNet (можно перевести как «остаточные сети») появились в конце 2015 года и победили в ImageNet 2015. Их изобретатели — команда из азиатского подразделения Microsoft Research. Они смогли построить и успешно обучать сети очень большой глубины, т. е. с большим количеством слоёв. Сравнение победителей разных лет по этому параметру от авторов:
Основной элемент ResNet — Residual-блок (остаточный блок) с shortcut-соединением, через которое данные проходят без изменений. Res-блок представляет собой несколько свёрточных слоёв с активациями, которые преобразуют входной сигнал в
в  . Shortcut-соединение — это тождественное преобразование
. Shortcut-соединение — это тождественное преобразование  .
.
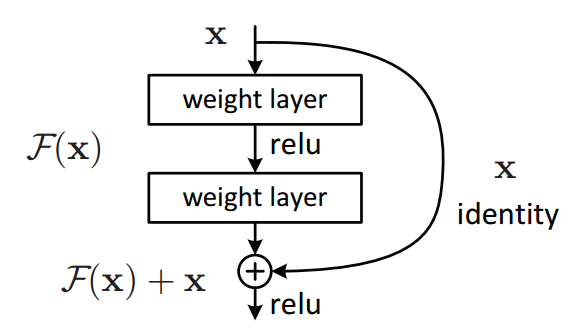
В результате такой конструкции Res-блок учит, как входной сигнал отличается от . Поэтому если на некотором слое сеть уже достаточно хорошо аппроксимировала исходную функцию, порождающую данные, то на дальнейших слоях оптимизатор может в Res-блоках делать веса близкими к нулю, и сигнал будет почти без изменений проходить по shortcut-соединению. В некотором смысле можно сказать, что CNN сама определяет свою глубину.
Важнейший вопрос в такой архитектуре сети — построение Res-блока. Большинство исследований и улучшений в ResNet связаны с этой темой. В 2016 году вышла статья тех же авторов, в которой они предложили новый способ построения Res-блока.
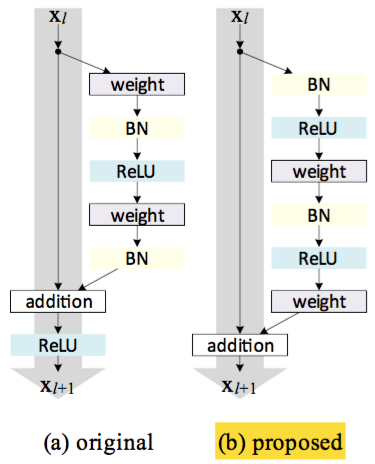
При таком подходе предлагается внести последнюю активацию (ReLU) в Res-блок и переместить слои нормализации (batch normalization) и активации перед свёрточными слоями. Такая конструкция позволяет сигналу без изменений протекать от одного Res-блока к другому. В статье авторы дают математическое объяснение тому, что этот трюк способствует борьбе с затухающим градиентом и, следовательно, позволяет строить сети очень большой глубины. Например, авторы успешно обучили ResNet с 1001 слоем.
Для наших исследований был выбран фреймворк PyTorch из-за его гибкости и скорости работы. Сравнение обучаемых моделей проводилось по замерам top-1 и top-5 ошибки на трёх тестах:
В результате экспериментов было обучено две модели: ResNet-50 и ResNet-200. Обе сети были дотюнены с ImageNet, так как этот подход показал значительное преимущество в нашей задаче перед обучением с нуля. Обученные модели мы сравнили на тестах с benchmark моделью ResNet-152, которую предоставили авторы базы Places2. Top-1 ошибки:

И top-5 ошибки:
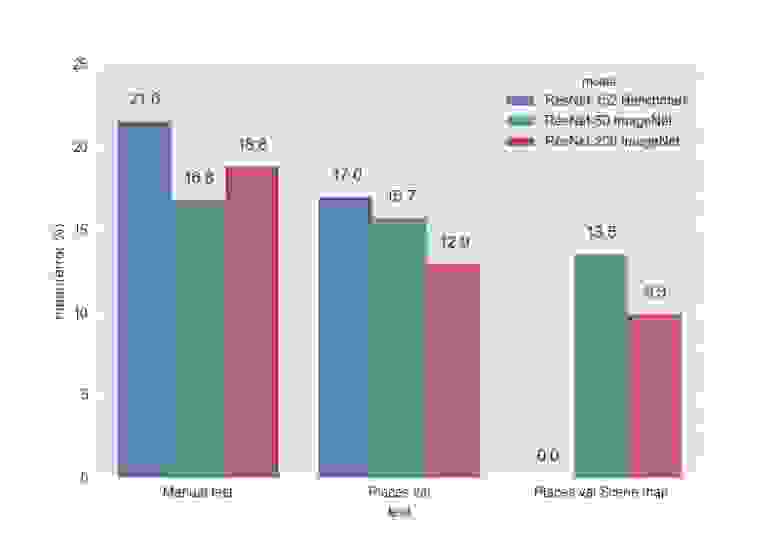
Как видно из графиков, ResNet-200 почти везде побеждает, что, в принципе, и неудивительно.
Конечно, мы не остановились на стандартном ResNet и после получения результатов продолжили исследования по повышению качества нашей CNN. Простое увеличение количества слоёв не даёт улучшения. В статье авторы показывают, что Residual Network — это ансамбль менее глубоких сеток. Ниже приведена иллюстрация из статьи по представлению ResNet в виде ансамбля.
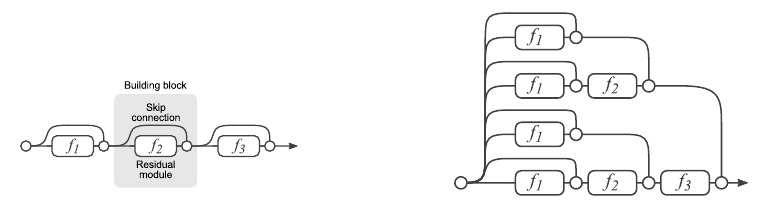
В этой работе утверждается, что последние Res-блоки вносят малый вклад в формирование конечного результата работы всей сети, поэтому простое увеличение количества блоков не даёт ожидаемого результата. Из этих соображений возникла идея увеличивать не глубину, а ширину Residual-блока, т. е. количество фильтров в свёртках.
Появившаяся в 2016 году Wide Residual Network делает именно это. Автор работы берёт обычный ResNet и увеличивает количество каналов в свёртках в Res-блоках, достигая с меньшим количеством параметров качества более глубоких ResNet. Мы использовали модель Wide ResNet-50-2 (WRN-50-2), обученную на ImageNet, которая представляет собой ResNet-50 с увеличением каналов в два раза. Сам автор наглядно проиллюстрировал отличие Wide Res-блока (слева) от классического Res-блока (справа):
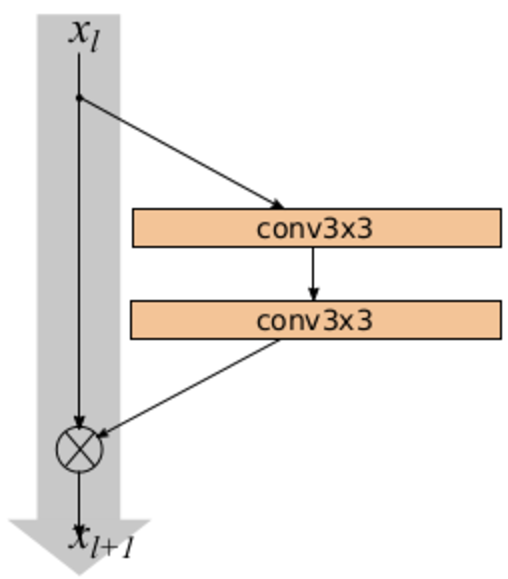
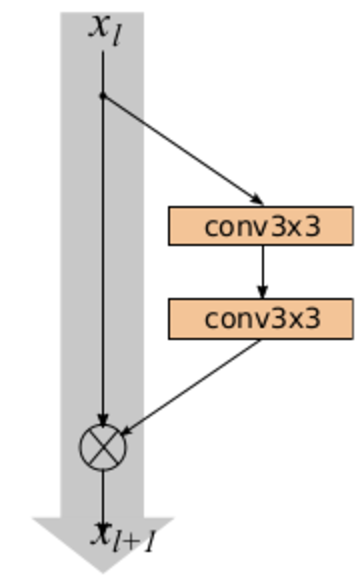
WRN-50-2 показывает близкие результаты к ResNet-200 на ImageNet: 21,9 % top-1 ошибки против 21,7 %. При этом WRN-50-2 почти в два раза быстрее, чем ResNet-200.
Для дальнейшего разбора архитектуры Wide ResNet вернёмся на пару шагов назад к стандартному Res-блоку. Чтобы увеличить эффективность вычислений и уменьшить количество параметров для больших сетей, таких как ResNet-50/101/152, авторы применили подход, который появился в модели Network In Network, а затем был внедрен в Inception-модель. Идея заключается в использовании 1 × 1 свёртки для уменьшения числа каналов перед более дорогой операцией 3 × 3 свёртки, а затем в восстановлении исходного числа каналов посредством ещё одной 1 × 1 свёртки. Res-блок с таким трюком называется bottleneck. Ниже приведено сравнение исходного (слева) и bottleneck-блоков (справа).
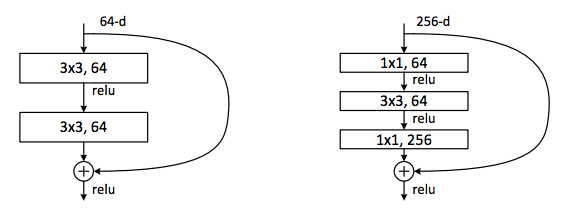
В Wide ResNet увеличение числа каналов происходит как раз для «внутренних» свёрток в bottleneck-блоках. В WRN-50-2 цифра 64 на рисунке справа увеличивается до 128.
Приведём сравнение обученных WRN на наших тестах. Top-1 ошибки:
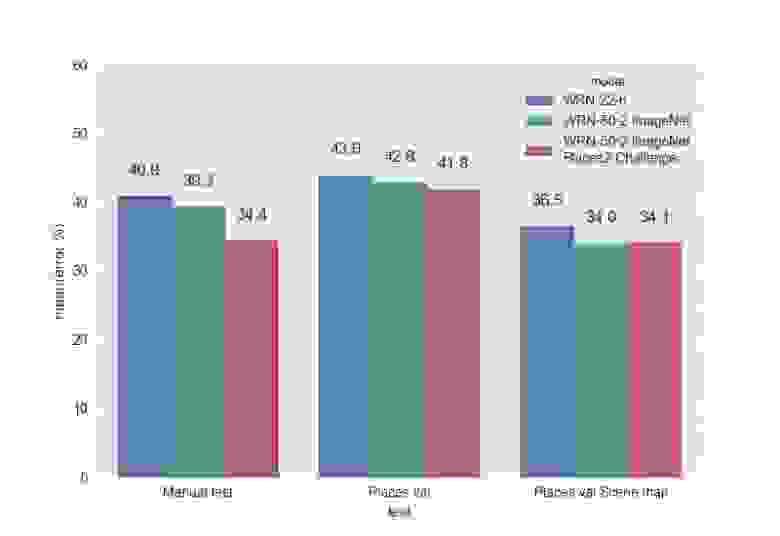
Top-5 ошибки:
Лучшей моделью оказалась WRN-50-2, затюненная с ImageNet и обученная на Places Sift Challenge. Она превзошла ResNet-200, работая при этом почти в два раза быстрее. Замеры скорости работы мы проводили на одной GPU Maxwell Titan X, cuDNN 5.0.05 на батче из 16 изображений. WRN-50-2 показала 83 мс против 154 мс у ResNet-200. Такое увеличение скорости при близком количестве параметров можно объяснить «шириной» Res-блока и, следовательно, большими возможностями для распараллеливания вычислений в нём. Обучение WRN-50-2 заняло около двух недель.
Приведём несколько примеров работы нашей CNN с использованием Scene mapping. Примеры успешной работы (в формате предсказание и соответствующий ему скор):


Predicted:
Пример неудачной работы:

Predicted:
Семейство ResNet продолжает увеличиваться. Мы попробовали использовать несколько последних представителей этого семейства для распознавания сцен. Один из них — сеть PyramidNet, которая показала многообещающие результаты на CIFAR-10/100 и на ImageNet. Основная идея этой CNN заключается в том, чтобы постепенно увеличивать количество каналов в свёртках, а не резко в несколько раз, как это происходит в обычных ResNet. Варианты PyramidNet:
Авторы оригинального ResNet также думают над расширением сети. Они создали модель ResNeXt, которая предлагает «умное» расширение Res-блока. Основная идея заключается в разложении числа каналов в Res-блоке на несколько параллельных потоков, например 32 блока по 4 канала = 128 каналов вместо оригинальных 64 из обычного Res-блока (слева), как показано на картинке ниже.
Такой подход похож на Inception, но все параллельные блоки одинаковы. При той же сложности модели, что и у ResNet, получаем улучшение качества.
К сожалению, ни PyramidNet, ни ResNeXt не смогли превзойти по качеству на наших тестах WRN-50-2 и показали близкие результаты.
В ходе исследований мы попробовали несколько подходов к улучшению качества сети, основанных на том, что для каждого класса сцен есть характерные объекты, и если мы научимся их выделять, то это поможет скорректировать ошибки, которые допускает основная CNN.
Первый из подходов основывается на Class activation map (CAM). Рассмотрим Global average pooling (GAP) — слой нашей сети, после которого идёт Softmax-слой. Обозначим как выход свёрточного слоя перед GAP,
как выход свёрточного слоя перед GAP,  — номер канала, и
— номер канала, и  — пространственные координаты,
— пространственные координаты,  — веса в слое после GAP, соответствующий
— веса в слое после GAP, соответствующий  -ому классу. Тогда:
-ому классу. Тогда:
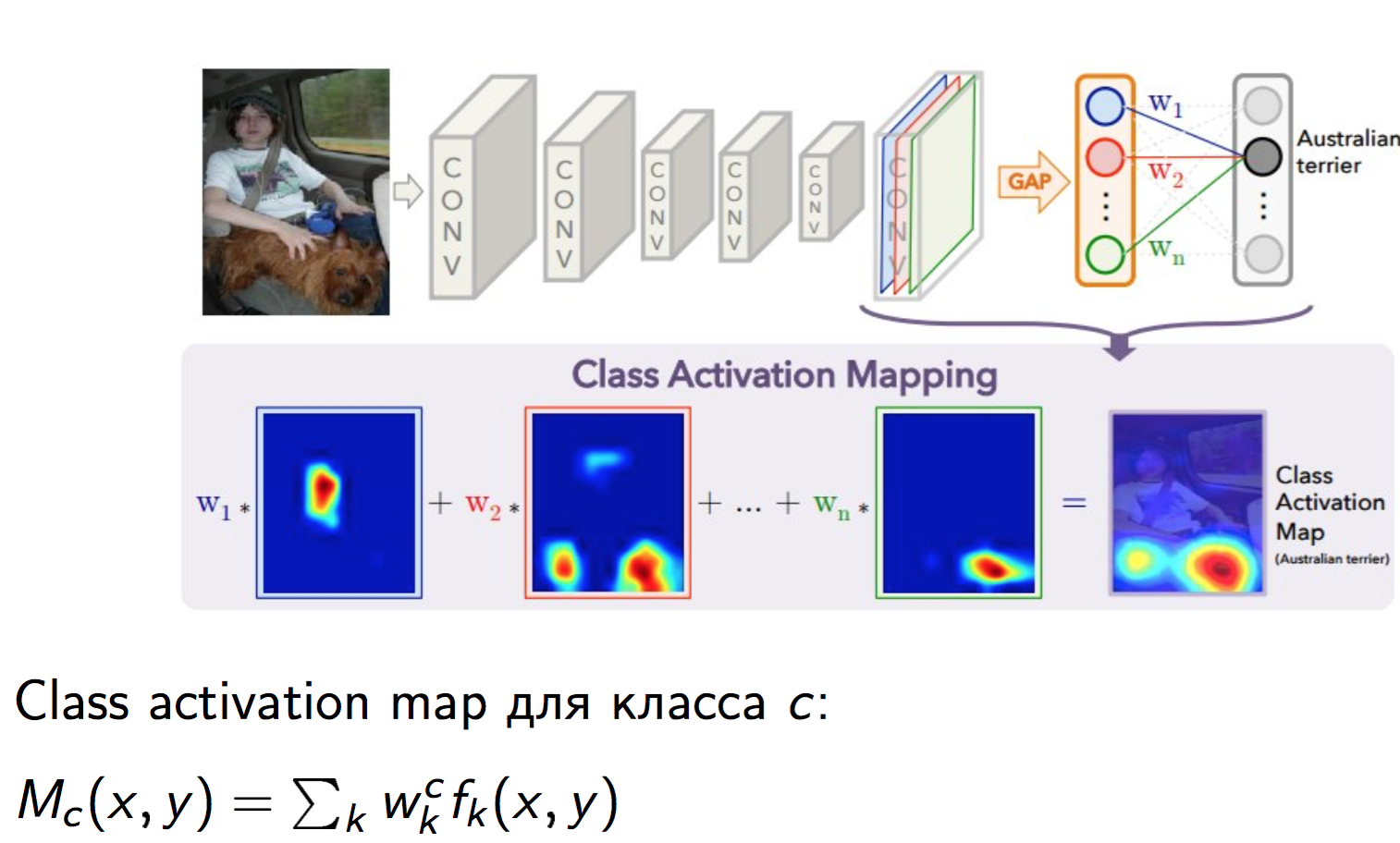
Основная идея заключается в том, что экземпляры одной сцены должны иметь в качестве CAM похожие объекты. Пример CAM для некоторых классов из Places2 после отображения их на исходное изображение:
Для реализации этого подхода мы использовали две сети. Пусть сеть 1 — это новая CNN, например ResNet-50, обученная на ImageNet, а сеть 2 — это наша обученная на Places Sift WRN-50-2. Мы попробовали два вида обучения. Первый алгоритм:
Второй алгоритм состоит из следующих шагов:
Мы экспериментировали с обоими алгоритмами, однако добиться повышения качества не удалось.
Следующий подход, который мы применяли к нашей модели, — это Visual recurrent attention (VRA). Алгоритм достаточно сложен, и за подробностями я предлагаю обратиться к статье, а здесь расскажу об основных его шагах и о том, как мы использовали его в нашей задаче. Основная идея VRA — он «смотрит» на различные патчи изображения, последовательность которых определяется рекуррентной сетью, и делает вывод о классификации всего изображения по этой последовательности. В целом алгоритм выглядит так:
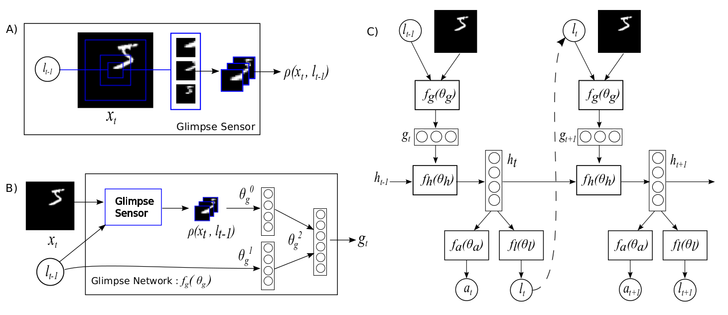
На шаге A из изображения вырезаются несколько патчей в масштабе с центром в поступившей точке
вырезаются несколько патчей в масштабе с центром в поступившей точке  . На этапе B эти патчи вместе с координатами точки прогоняются через две небольшие сети, в результате чего получается их общее векторное представление
. На этапе B эти патчи вместе с координатами точки прогоняются через две небольшие сети, в результате чего получается их общее векторное представление  . Оно поступает в рекуррентную сеть
. Оно поступает в рекуррентную сеть  , которая на каждой итерации выдаёт решение о классификации
, которая на каждой итерации выдаёт решение о классификации  и новую точку центра патчей
и новую точку центра патчей  . проходит некоторое заданное количество шагов.
. проходит некоторое заданное количество шагов.
Мы экспериментировали с VRA, подавая ему на вход не изображение, а карту признаков с одного из слоёв сети WRN-50-2 после прогона через неё входного изображения. Наша идея состояла в том, что механизм Attention поможет выделить характерные для сцены предметы. Однако такой алгоритм очень долго учится, и нам не удалось поднять качество выше 20 % за приемлемое время.
В статье, которую мы рассматривали в разделе про Wide ResNet, есть наблюдение, что некоторые Res-блоки можно выкидывать без сильной потери в качестве. Мы провели эксперименты по удалению нескольких Res-блоков из ResNet-200, однако даже при увеличении таким образом скорости её работы WRN-50-2 остался лучшим выбором модели.
Сейчас наша команда продолжает эксперименты в области Scene recognition. Мы обучаем новые архитектуры CNN (в основном из семейства ResNet), пробуем другие варианты CAM, настраиваем Visual Recurrent Attention и пробуем различные подходы с более хитрой обработкой патчей изображения.
В этом посте мы рассмотрели основные наборы данных для Scene recognition, различные подходы к решению этой задачи, выяснили, что Wide ResNet пока показывает лучший результат, и рассмотрели некоторые методы для улучшения модели.
В заключение могу сказать, что Scene recognition — это нужная, но пока относительно малоизученная область Computer Vision. Задача очень интересная, и в ней можно экспериментировать с различными подходами, которые могут не подходить для классического Object recognition (например, CAM или VRA).
В сообществе Computer Vision достаточно хорошо изучена задача распознавания объектов (Object recognition). Одно из главных соревнований в области машинного зрения — ImageNet, и алгоритмы (свёрточные нейронные сети с 2012 года), которые побеждали в дисциплине распознавания объектов, как правило, становились state-of-the-art. Однако распознавание сцен исследовано значительно меньше, только с прошлого года эта задача входит в ImageNet. Главное отличие распознавания сцен (Scene recognition, Place recognition, Place classification) от распознавания объектов заключается в том, что сцены — более комплексные сущности. Например, для того чтобы определить, что на картинке изображён котёнок, алгоритму необходимо детектировать и распознать одну сущность — непосредственно котёнка.


Однако для определения того, что на картинке ресторанчик, надо найти различные предметы, характерные для него: стол, стулья, прилавок, кухню, подсвеченное меню, посетителей и т. д. Таким образом, для распознавания сцены необходимо определить контекст, несколько объектов и их взаимодействие между собой.
Современные Computer Vision API умеют работать со сценами. Убедимся в этом на примерах CV API от Google и Microsoft. Оба включают в себя в числе прочего тегирование по сценам. Примеры работы Google CV API:

И Microsoft CV API:

Как видно из приведённых выше примеров, оба сервиса включают в себя распознавание сцен и находят на тестовой картинке ресторан. Наша задача состояла в том, чтобы добавить схожую функциональность в наше Computer Vision API.
Данные
Распознавание сцен стало активно развиваться параллельно с началом бума свёрточных нейронных сетей (convolutional neural networks, CNN), т. е. примерно с начала 2010-х годов, когда стали появляться в свободном доступе базы данных. Так как наша модель — это глубокая CNN, то для её обучения нам требовались достаточно большие и разнообразные датасеты. В таблице представлены основные базы данных.
| База | SUN | LSUN | Places2-Standard | Places2-Challenge |
| Количество категорий | 397 | 10 | 365 | 365 |
| Количество изображений | 108 754 | 9 895 373 | 1 803 486 | 8 026 628 |
| Изображений на класс | > 100 | 168 103 — 3 033 042 | 3068 — 5000 | 3068 — 40 000 |
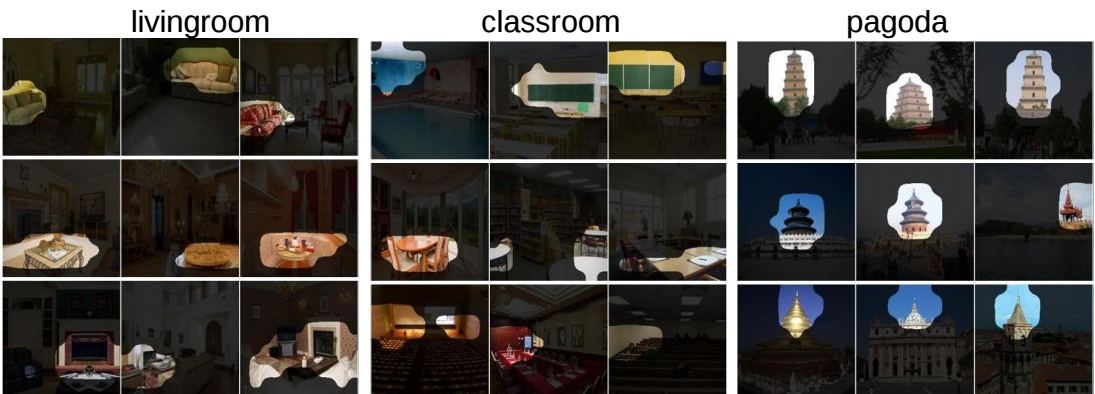
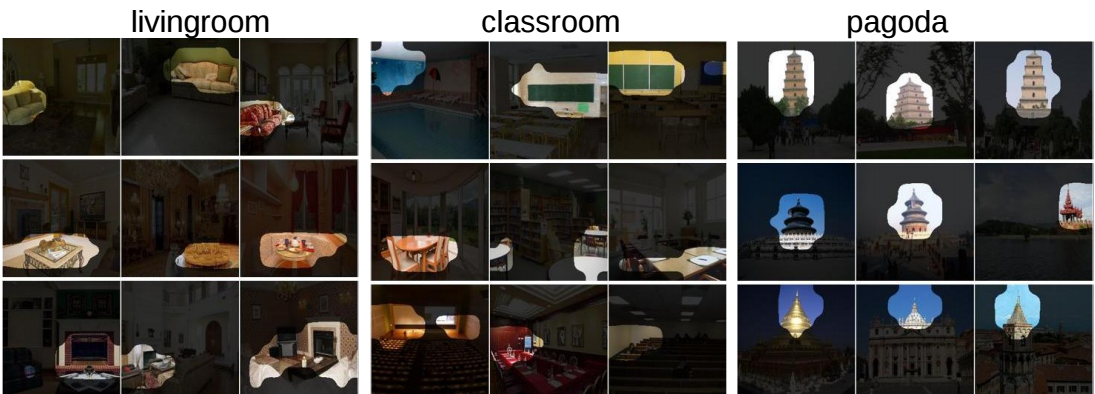
В 2014 году появилась база Places, а в 2016-м — её вторая, расширенная версия Places2 от MIT. Эту базу можно скачать в двух видах: Places2-Standard и Places2-Challenge. Places2-Standard представляет собой уменьшенную версию Places2-Challenge, в которой классы более сбалансированы. В ImageNet 2016 года было включено соревнование Scene classification, основанное на Places2-Challenge. Лучший результат в этом соревновании с top-5 ошибки 9,01 % показала китайская команда Hikvision Research Institute. Примеры из базы Places2 приведены ниже, на таких данных происходило обучение нашей сети.

Обучение современной глубокой CNN даже на Places2-Standard занимает несколько суток. Для того чтобы протестировать и отладить различные архитектуры и подобрать параметры модели и обучения за приемлемое время, мы решили пойти по пути, который активно используется в Object recognition. Там модели сначала проверяют и отлаживают на небольших базах CIFAR-10 и CIFAR-100, а затем лучшие из них обучают на большом датасете из ImageNet. Мы урезали базу SUN до 89 классов, 50 тысяч изображений в тренировочном множестве и 10 тысяч в валидационном. На полученном датасете SUN Reduce сеть обучается порядка 6—10 часов и даёт представление о своём поведении при обучении на Places2.
При детальном исследовании Places2 мы решили избавиться от некоторых классов. Причинами для этого послужили отсутствие необходимости в этих классах в production и слишком маленькое количество данных, что создавало перекос в обучающей выборке. Примеры таких категорий — aqueduct, tree house, barndoor. В итоге после чистки получилась база Places Sift, которая состоит из 314 классов, Standard train множество включает в себя около 1,5 миллиона изображений, Challenge train множество — около 7,5 миллиона изображений. Также при изучении категорий стало ясно, что их слишком много и они чересчур подробные для использования «в бою». Поэтому мы объединили некоторые из них в одну, назвав эту процедуру Scene mapping. Вот примеры объединения классов:
- bamboo forest, forest broadleaf, forest path, forest road, rainforest -> forest;
- hospital, hospital room, nursery, operating room -> hospital;
- hotel outdoor, hotel room, inn outdoor, youth hostel -> hotel.
Scene mapping применяется только при выводе результатов пользователю и только в некоторых задачах, где это имеет смысл. Обучение CNN происходит на оригинальных классах Places Sift. Также в CV API есть выдача embedding из сети для того, чтобы на основе нашей модели можно было дообучать новые.
Подходы, решения
С 2012 года (победа в ImageNet команды Университета Торонто, которая использовала CNN AlexNet) свёрточные нейронные сети стали де-факто state-of-the-art во многих областях Computer Vision и демонстрируют значительный потенциал для дальнейшего прогресса, поэтому в наших экспериментах мы рассматривали только этот тип моделей. Я не буду вдаваться в описание основ CNN, этому уже посвящены отдельные посты, например. Для общего представления на картинке ниже изображена классическая сеть LeNet от Яна Лекуна:
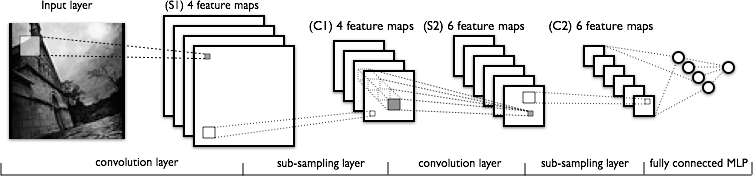
Чтобы определиться с архитектурой сети, мы отбирали CNN, основываясь на результатах ImageNet и Places2 за последнюю пару лет. Топовые модели на этих двух соревнованиях можно с некоторой долей условности разделить на семейство Inception (GoogLeNet, Inception 2—4, Inception-ResNet и производные от них) и на семейство Residual Networks (ResNet и различные способы его улучшения). В результате наших экспериментов по распознаванию сцен лучше всех себя показали модели из семейства ResNet, поэтому дальнейшее повествование будет связано с ними.
Residual Networks, сокращённо ResNet (можно перевести как «остаточные сети») появились в конце 2015 года и победили в ImageNet 2015. Их изобретатели — команда из азиатского подразделения Microsoft Research. Они смогли построить и успешно обучать сети очень большой глубины, т. е. с большим количеством слоёв. Сравнение победителей разных лет по этому параметру от авторов:
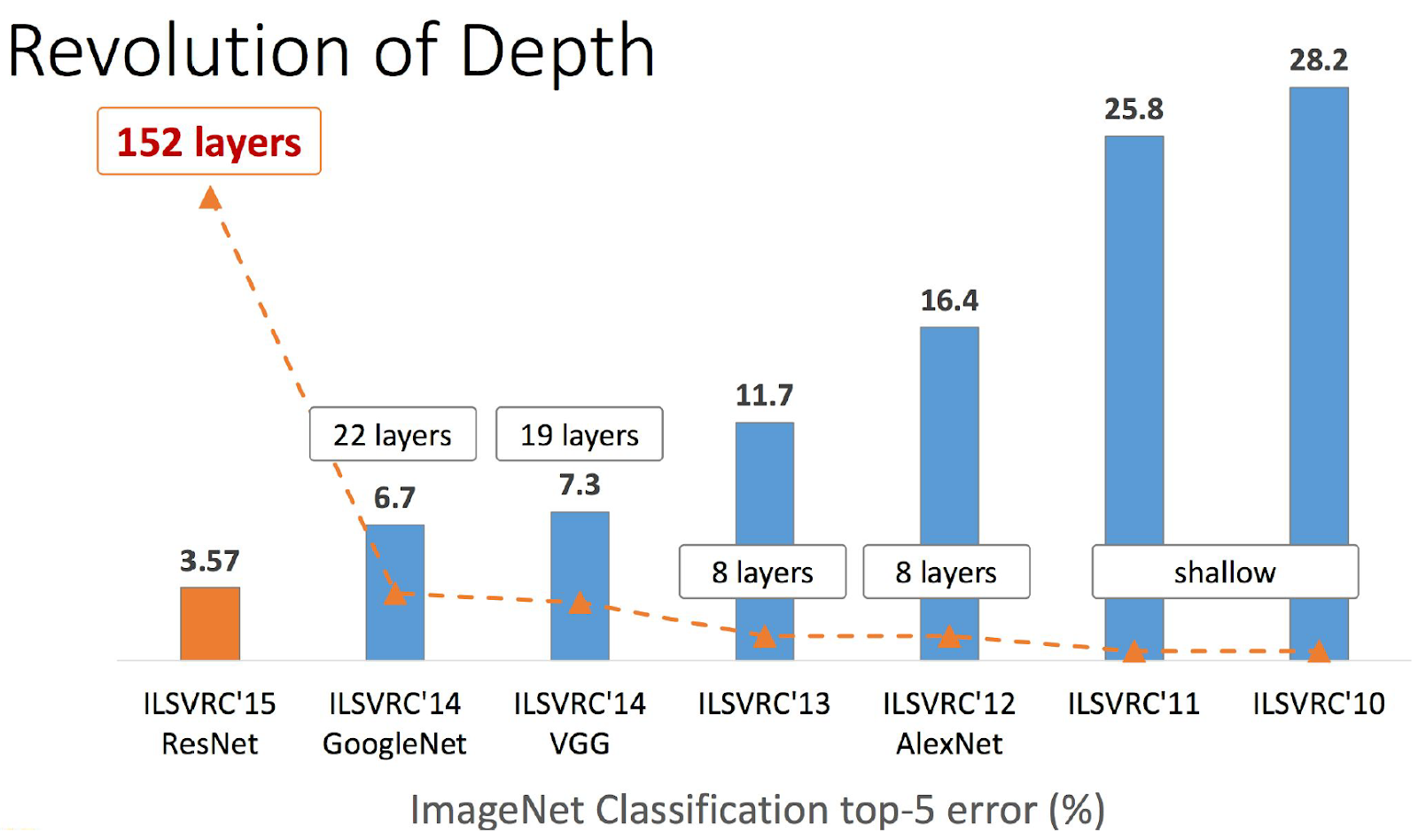
Основной элемент ResNet — Residual-блок (остаточный блок) с shortcut-соединением, через которое данные проходят без изменений. Res-блок представляет собой несколько свёрточных слоёв с активациями, которые преобразуют входной сигнал
в . Shortcut-соединение — это тождественное преобразование .
В результате такой конструкции Res-блок учит, как входной сигнал
отличается от . Поэтому если на некотором слое сеть уже достаточно хорошо аппроксимировала исходную функцию, порождающую данные, то на дальнейших слоях оптимизатор может в Res-блоках делать веса близкими к нулю, и сигнал будет почти без изменений проходить по shortcut-соединению. В некотором смысле можно сказать, что CNN сама определяет свою глубину.Важнейший вопрос в такой архитектуре сети — построение Res-блока. Большинство исследований и улучшений в ResNet связаны с этой темой. В 2016 году вышла статья тех же авторов, в которой они предложили новый способ построения Res-блока.

При таком подходе предлагается внести последнюю активацию (ReLU) в Res-блок и переместить слои нормализации (batch normalization) и активации перед свёрточными слоями. Такая конструкция позволяет сигналу без изменений протекать от одного Res-блока к другому. В статье авторы дают математическое объяснение тому, что этот трюк способствует борьбе с затухающим градиентом и, следовательно, позволяет строить сети очень большой глубины. Например, авторы успешно обучили ResNet с 1001 слоем.
Для наших исследований был выбран фреймворк PyTorch из-за его гибкости и скорости работы. Сравнение обучаемых моделей проводилось по замерам top-1 и top-5 ошибки на трёх тестах:
- Places val — валидационное множество из Places Sift.
- Places val Scene map — валидационное множество из Places Sift + Scene mapping.
- Manual test — изображения, предоставленные нашими коллегами из их облаков, размеченные вручную. Этот тест ближе всего к «боевому» применению CNN, однако из-за относительно малого количества данных он менее робастный.
В результате экспериментов было обучено две модели: ResNet-50 и ResNet-200. Обе сети были дотюнены с ImageNet, так как этот подход показал значительное преимущество в нашей задаче перед обучением с нуля. Обученные модели мы сравнили на тестах с benchmark моделью ResNet-152, которую предоставили авторы базы Places2. Top-1 ошибки:

И top-5 ошибки:
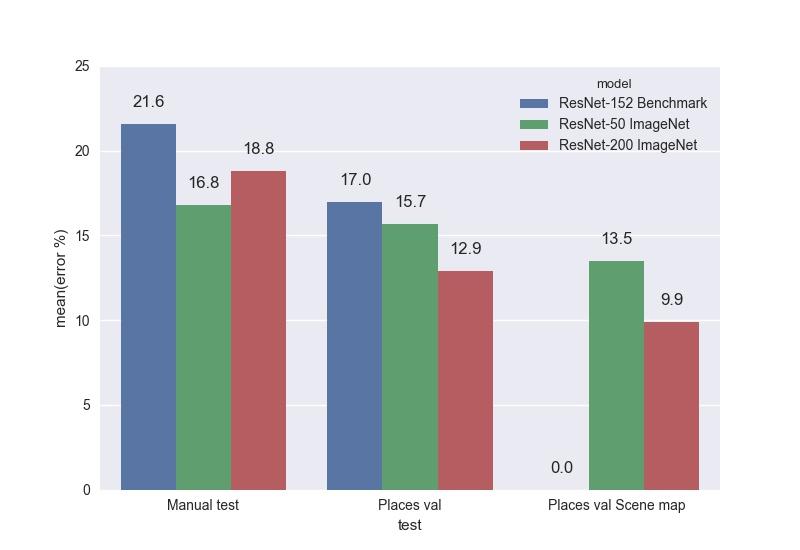
Как видно из графиков, ResNet-200 почти везде побеждает, что, в принципе, и неудивительно.
Wide Residual Network
Конечно, мы не остановились на стандартном ResNet и после получения результатов продолжили исследования по повышению качества нашей CNN. Простое увеличение количества слоёв не даёт улучшения. В статье авторы показывают, что Residual Network — это ансамбль менее глубоких сеток. Ниже приведена иллюстрация из статьи по представлению ResNet в виде ансамбля.
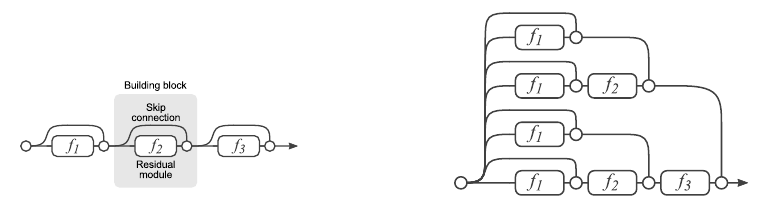
В этой работе утверждается, что последние Res-блоки вносят малый вклад в формирование конечного результата работы всей сети, поэтому простое увеличение количества блоков не даёт ожидаемого результата. Из этих соображений возникла идея увеличивать не глубину, а ширину Residual-блока, т. е. количество фильтров в свёртках.
Появившаяся в 2016 году Wide Residual Network делает именно это. Автор работы берёт обычный ResNet и увеличивает количество каналов в свёртках в Res-блоках, достигая с меньшим количеством параметров качества более глубоких ResNet. Мы использовали модель Wide ResNet-50-2 (WRN-50-2), обученную на ImageNet, которая представляет собой ResNet-50 с увеличением каналов в два раза. Сам автор наглядно проиллюстрировал отличие Wide Res-блока (слева) от классического Res-блока (справа):

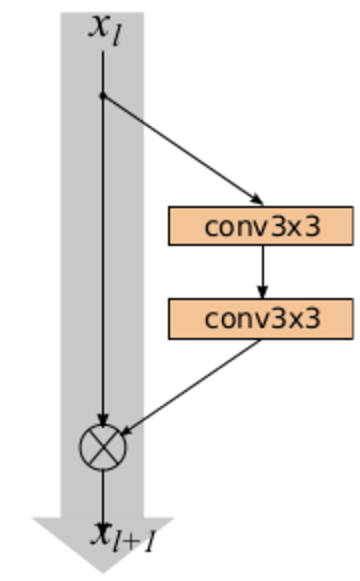
WRN-50-2 показывает близкие результаты к ResNet-200 на ImageNet: 21,9 % top-1 ошибки против 21,7 %. При этом WRN-50-2 почти в два раза быстрее, чем ResNet-200.
Для дальнейшего разбора архитектуры Wide ResNet вернёмся на пару шагов назад к стандартному Res-блоку. Чтобы увеличить эффективность вычислений и уменьшить количество параметров для больших сетей, таких как ResNet-50/101/152, авторы применили подход, который появился в модели Network In Network, а затем был внедрен в Inception-модель. Идея заключается в использовании 1 × 1 свёртки для уменьшения числа каналов перед более дорогой операцией 3 × 3 свёртки, а затем в восстановлении исходного числа каналов посредством ещё одной 1 × 1 свёртки. Res-блок с таким трюком называется bottleneck. Ниже приведено сравнение исходного (слева) и bottleneck-блоков (справа).
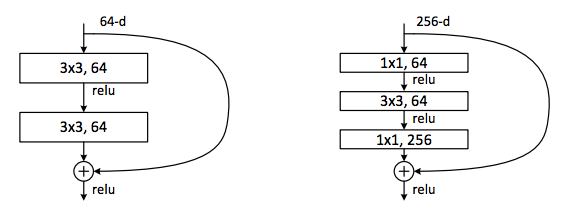
В Wide ResNet увеличение числа каналов происходит как раз для «внутренних» свёрток в bottleneck-блоках. В WRN-50-2 цифра 64 на рисунке справа увеличивается до 128.
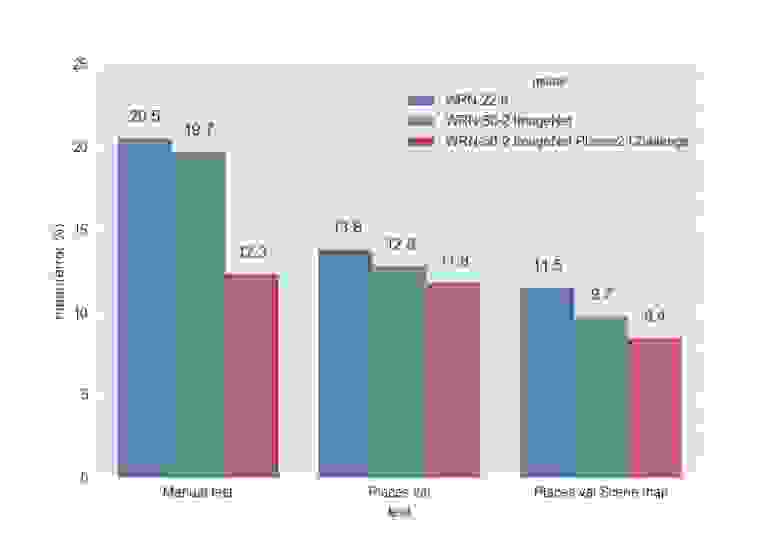
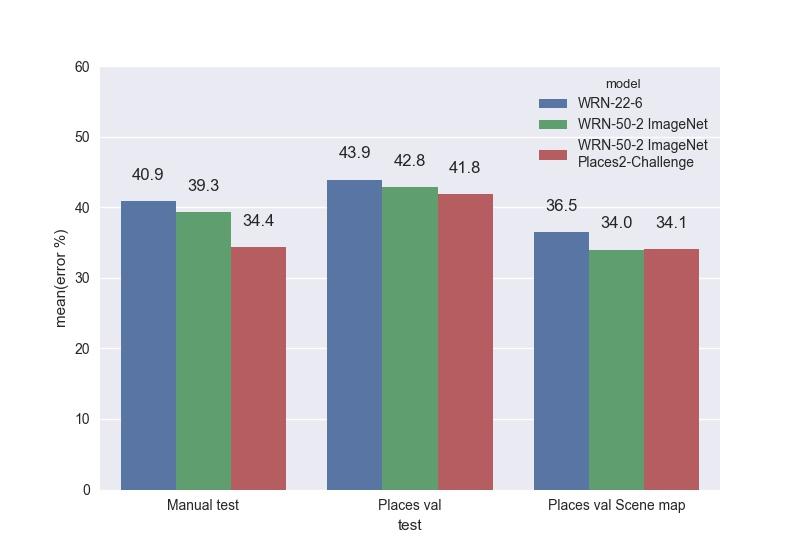
Приведём сравнение обученных WRN на наших тестах. Top-1 ошибки:
Top-5 ошибки:
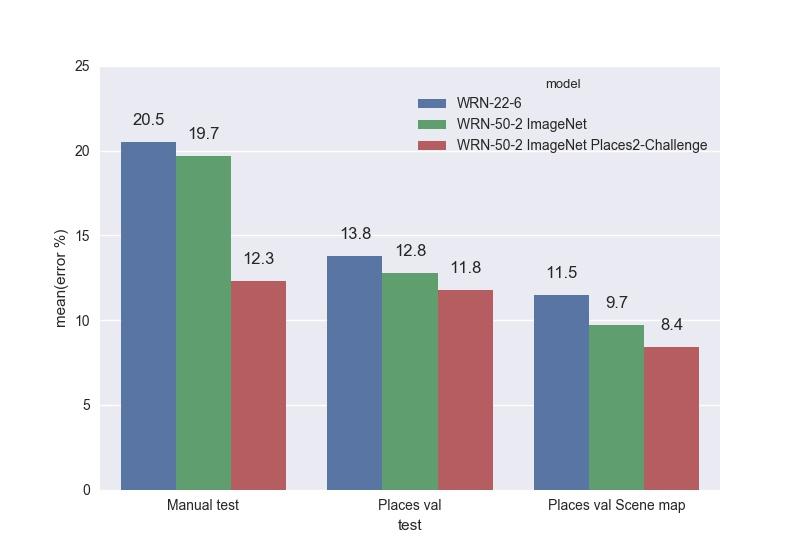
Лучшей моделью оказалась WRN-50-2, затюненная с ImageNet и обученная на Places Sift Challenge. Она превзошла ResNet-200, работая при этом почти в два раза быстрее. Замеры скорости работы мы проводили на одной GPU Maxwell Titan X, cuDNN 5.0.05 на батче из 16 изображений. WRN-50-2 показала 83 мс против 154 мс у ResNet-200. Такое увеличение скорости при близком количестве параметров можно объяснить «шириной» Res-блока и, следовательно, большими возможностями для распараллеливания вычислений в нём. Обучение WRN-50-2 заняло около двух недель.
Примеры работы
Приведём несколько примеров работы нашей CNN с использованием Scene mapping. Примеры успешной работы (в формате предсказание и соответствующий ему скор):
| Predicted | Scene mapping |
|
|

| Predicted | Scene mapping |
|
|

Predicted:
- harbor 0,42
- coast 0,13
- cliff 0,12
- promenade 0,07
- ocean 0,04
Пример неудачной работы:

Predicted:
- palace 0,21
- museum 0,16
- plaza 0,12
- yard 0,1
- church 0,13
Другие ResNet
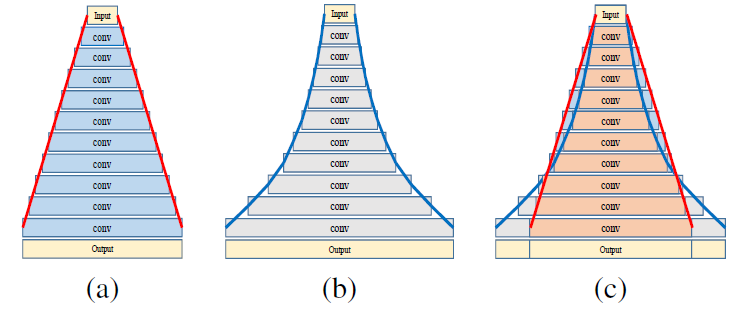
Семейство ResNet продолжает увеличиваться. Мы попробовали использовать несколько последних представителей этого семейства для распознавания сцен. Один из них — сеть PyramidNet, которая показала многообещающие результаты на CIFAR-10/100 и на ImageNet. Основная идея этой CNN заключается в том, чтобы постепенно увеличивать количество каналов в свёртках, а не резко в несколько раз, как это происходит в обычных ResNet. Варианты PyramidNet:
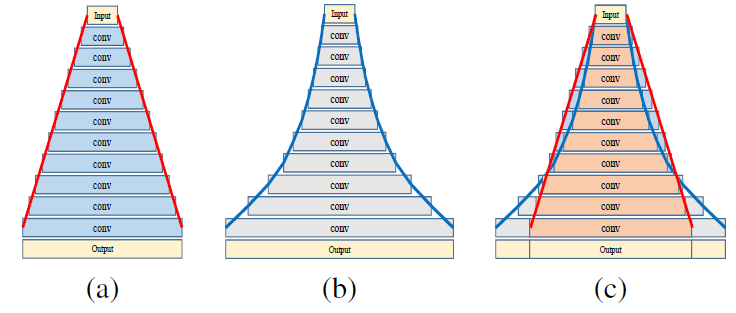
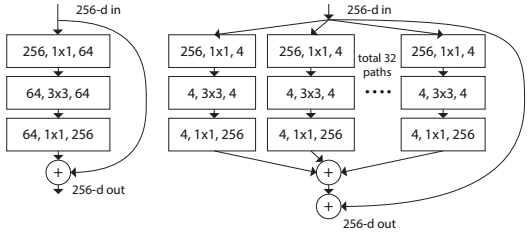
Авторы оригинального ResNet также думают над расширением сети. Они создали модель ResNeXt, которая предлагает «умное» расширение Res-блока. Основная идея заключается в разложении числа каналов в Res-блоке на несколько параллельных потоков, например 32 блока по 4 канала = 128 каналов вместо оригинальных 64 из обычного Res-блока (слева), как показано на картинке ниже.
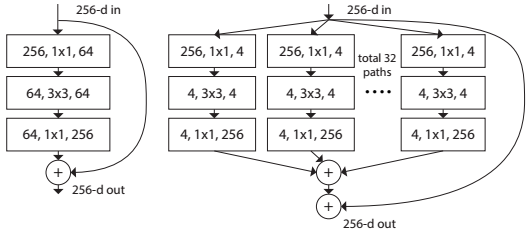
Такой подход похож на Inception, но все параллельные блоки одинаковы. При той же сложности модели, что и у ResNet, получаем улучшение качества.
К сожалению, ни PyramidNet, ни ResNeXt не смогли превзойти по качеству на наших тестах WRN-50-2 и показали близкие результаты.
«Креативные» подходы к улучшению CNN
В ходе исследований мы попробовали несколько подходов к улучшению качества сети, основанных на том, что для каждого класса сцен есть характерные объекты, и если мы научимся их выделять, то это поможет скорректировать ошибки, которые допускает основная CNN.
Первый из подходов основывается на Class activation map (CAM). Рассмотрим Global average pooling (GAP) — слой нашей сети, после которого идёт Softmax-слой. Обозначим
как выход свёрточного слоя перед GAP, — номер канала, и — пространственные координаты, — веса в слое после GAP, соответствующий -ому классу. Тогда: 
Основная идея заключается в том, что экземпляры одной сцены должны иметь в качестве CAM похожие объекты. Пример CAM для некоторых классов из Places2 после отображения их на исходное изображение:
Для реализации этого подхода мы использовали две сети. Пусть сеть 1 — это новая CNN, например ResNet-50, обученная на ImageNet, а сеть 2 — это наша обученная на Places Sift WRN-50-2. Мы попробовали два вида обучения. Первый алгоритм:
- Входное изображение прогоняется через сеть 2, и на него отображается CAM.
- Полученный CAM прогоняется через сеть 1.
- Результат сети 1 добавляется в функцию потерь сети 2.
- Сеть 2 обучается с этой новой функцией потерь.
Второй алгоритм состоит из следующих шагов:
- Входное изображение прогоняется через сеть 2, и на него отображается CAM.
- Полученный CAM прогоняется через сеть 1.
- Обучается только сеть 1.
- При выводе используется ансамбль из сетей 1 и 2.
Мы экспериментировали с обоими алгоритмами, однако добиться повышения качества не удалось.
Следующий подход, который мы применяли к нашей модели, — это Visual recurrent attention (VRA). Алгоритм достаточно сложен, и за подробностями я предлагаю обратиться к статье, а здесь расскажу об основных его шагах и о том, как мы использовали его в нашей задаче. Основная идея VRA — он «смотрит» на различные патчи изображения, последовательность которых определяется рекуррентной сетью, и делает вывод о классификации всего изображения по этой последовательности. В целом алгоритм выглядит так:

На шаге A из изображения
вырезаются несколько патчей в масштабе с центром в поступившей точке . На этапе B эти патчи вместе с координатами точки прогоняются через две небольшие сети, в результате чего получается их общее векторное представление . Оно поступает в рекуррентную сеть , которая на каждой итерации выдаёт решение о классификации и новую точку центра патчей . проходит некоторое заданное количество шагов.Мы экспериментировали с VRA, подавая ему на вход не изображение, а карту признаков с одного из слоёв сети WRN-50-2 после прогона через неё входного изображения. Наша идея состояла в том, что механизм Attention поможет выделить характерные для сцены предметы. Однако такой алгоритм очень долго учится, и нам не удалось поднять качество выше 20 % за приемлемое время.
В статье, которую мы рассматривали в разделе про Wide ResNet, есть наблюдение, что некоторые Res-блоки можно выкидывать без сильной потери в качестве. Мы провели эксперименты по удалению нескольких Res-блоков из ResNet-200, однако даже при увеличении таким образом скорости её работы WRN-50-2 остался лучшим выбором модели.
Заключение
Сейчас наша команда продолжает эксперименты в области Scene recognition. Мы обучаем новые архитектуры CNN (в основном из семейства ResNet), пробуем другие варианты CAM, настраиваем Visual Recurrent Attention и пробуем различные подходы с более хитрой обработкой патчей изображения.
В этом посте мы рассмотрели основные наборы данных для Scene recognition, различные подходы к решению этой задачи, выяснили, что Wide ResNet пока показывает лучший результат, и рассмотрели некоторые методы для улучшения модели.
В заключение могу сказать, что Scene recognition — это нужная, но пока относительно малоизученная область Computer Vision. Задача очень интересная, и в ней можно экспериментировать с различными подходами, которые могут не подходить для классического Object recognition (например, CAM или VRA).
