
С момента появления Node.js диагностика совершенствовалась в несколько этапов, от отладки приложений до глубокого анализа производительности. В этот раз речь пойдет о стратегиях использования таких инструментов, как core dump debuggers, flame graphs, ошибках в production и утечке памяти.
Мы расшифровали для Хабра доклад Николая Матвиенко из Grid Dynamics с нашей конференции HolyJS. Далее повествование идёт от лица спикера.
Чтобы понять, на каком этапе эволюции инструментов диагностики мы сейчас находимся, я предлагаю обратиться к истории. На временной шкале я изобразил наиболее значимые моменты.
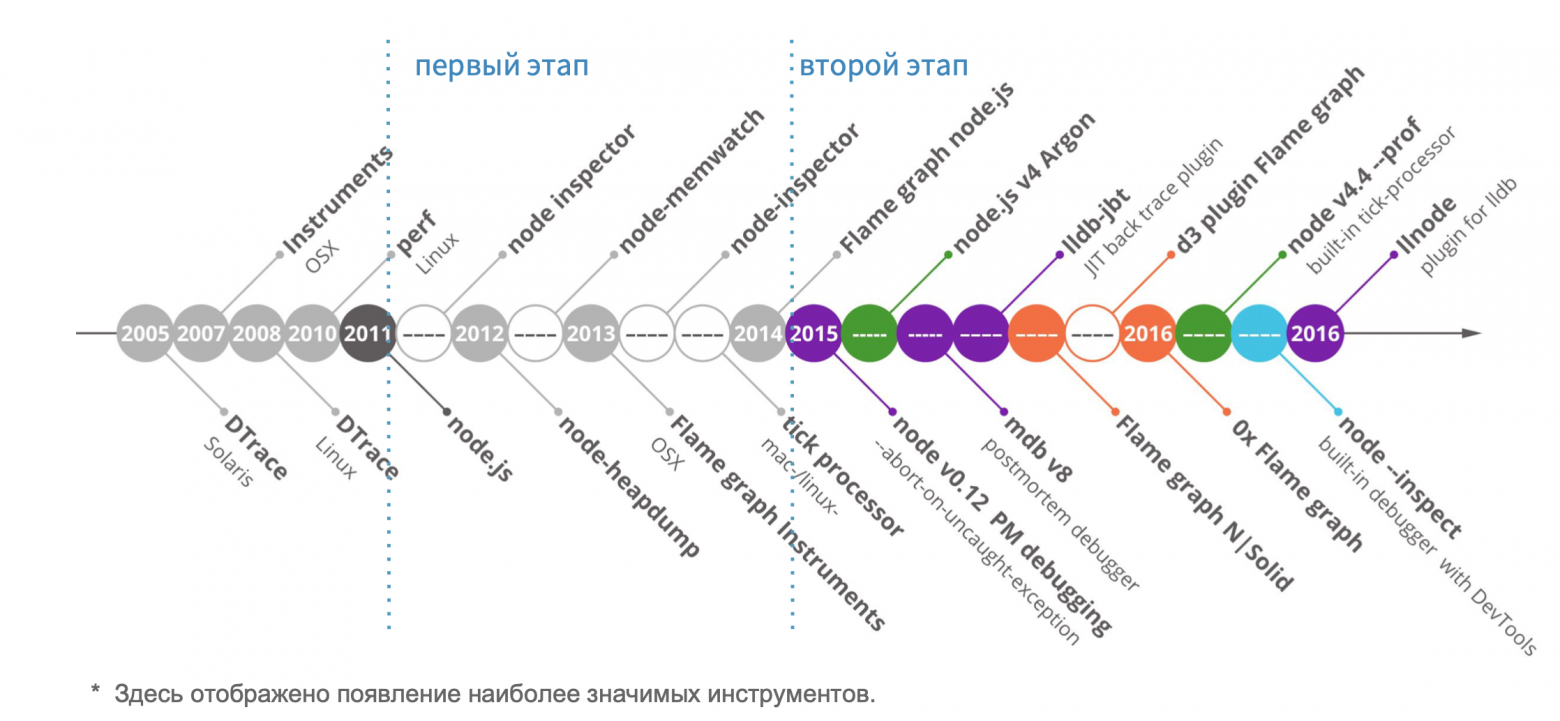
Сначала в свет вышли такие инструменты, как DTrace, Instruments, perf — это системные профайлеры, которые появились задолго до Node.js, при этом они используются по сей день. С появлением Node.js к нам приходят Node-ориентированные инструменты — здесь стоит выделить node inspector, node-heapdump, node-memwatch. Этот период я отметил серым и условно называю его смутным временем. Вы помните, что там был раскол комьюнити: в тот период io.js отделился от Node.js, и у комьюнити не было общего понимания, куда двигаться дальше и кого выбирать. Но в 2015 году io.js и Node.js объединились, и мы увидели Node.js v4 Argon. У комьюнити появился четкий вектор развития, и Node.js в production начали использовать такие крупные компании, как Amazon, Netflix, Alibaba.
И здесь становятся востребованными эффективные инструменты, готовые работать в production.
С 2017 года я условно выделяю третий этап.

С этого момента Node.js развивается уже качественно. Здесь стоит отметить полноценный переход на Turbofan и развитие Async Hooks.
В 2015 году мы вышли в релиз на версии Node.js 0.12 и постепенно обновлялись сначала до четвертой версии и впоследствии — до шестой. Сейчас мы планируем переход на восьмую версию.
В релизный год мы использовали инструменты из первого этапа, которые были малофункциональными для работы в production. У нас хороший опыт работы с инструментами второго этапа, и сейчас мы пользуемся инструментами третьего этапа. Но с переходом на новые версии Node.js мы столкнулись с тем, что теряем поддержку полезных нам инструментов. По сути мы встали перед выбором. Либо мы переходим на новую версию Node.js, которая является более оптимизированной и быстрой, чем предыдущая, но у нас нет инструментов, и мы не можем ее диагностировать. Либо мы остаемся на старой версии Node.js, которая работает медленнее, но у нас к ней есть инструменты, и мы знаем ее слабые места. Либо есть третий вариант, когда появляются новые инструменты, а они поддерживают, например, Node v4 и выше, а предыдущие — нет.
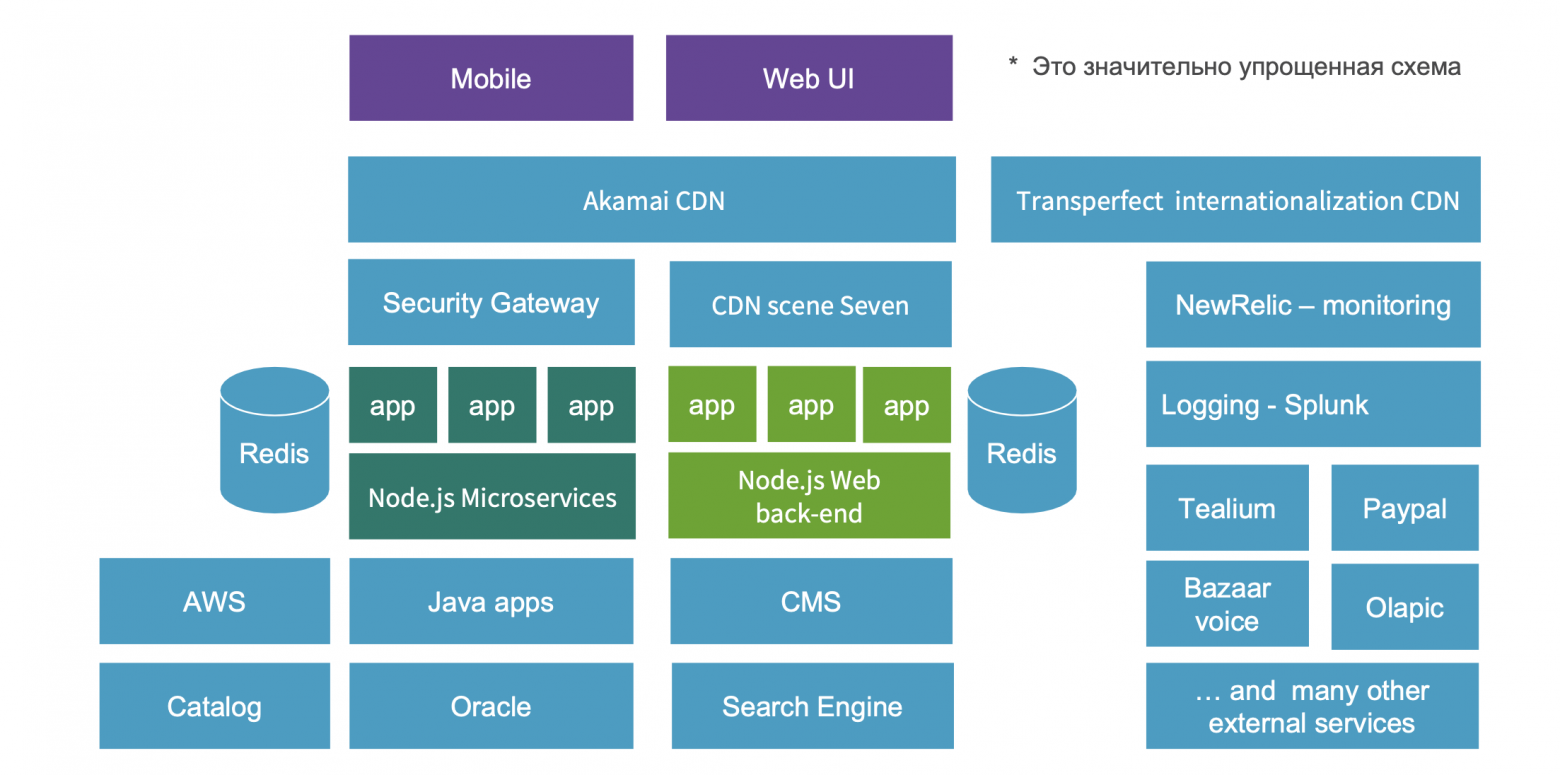
Наше приложение — это крупный e-commerce проект, где Node.js-приложения (это Web UI backend и Node.js-микросервисы) занимают центральное место в enterprise-архитектуре.
Проблема в этом месте может прийти с любой стороны. В дни повышенных нагрузок, типа Black Friday, когда компания за несколько дней зарабатывает 60% от годовой прибыли, особенно важно поддерживать высокую пропускную способность. Если случается какая-то неисправность, собирается локальный консилиум, где присутствуют все руководители систем, в том числе и я от Node.js. Если проблема на стороне Node.js, необходимо максимально быстро выбрать стратегию, подобрать под нее инструменты и устранить неисправность, поскольку компания теряет тысячи долларов в минуту.

Ниже я хотел бы на конкретных примерах показать, как мы в production поступаем в случаях ошибок, утечек памяти и спада производительности.
Существует несколько посылов для отладки в production.

Рассмотрим простой пример: некий сервис для резервирования продуктов. Controller использует service, который отправляет коллекцию продуктов на REST API, возвращает данные, и в controller падает ошибка.


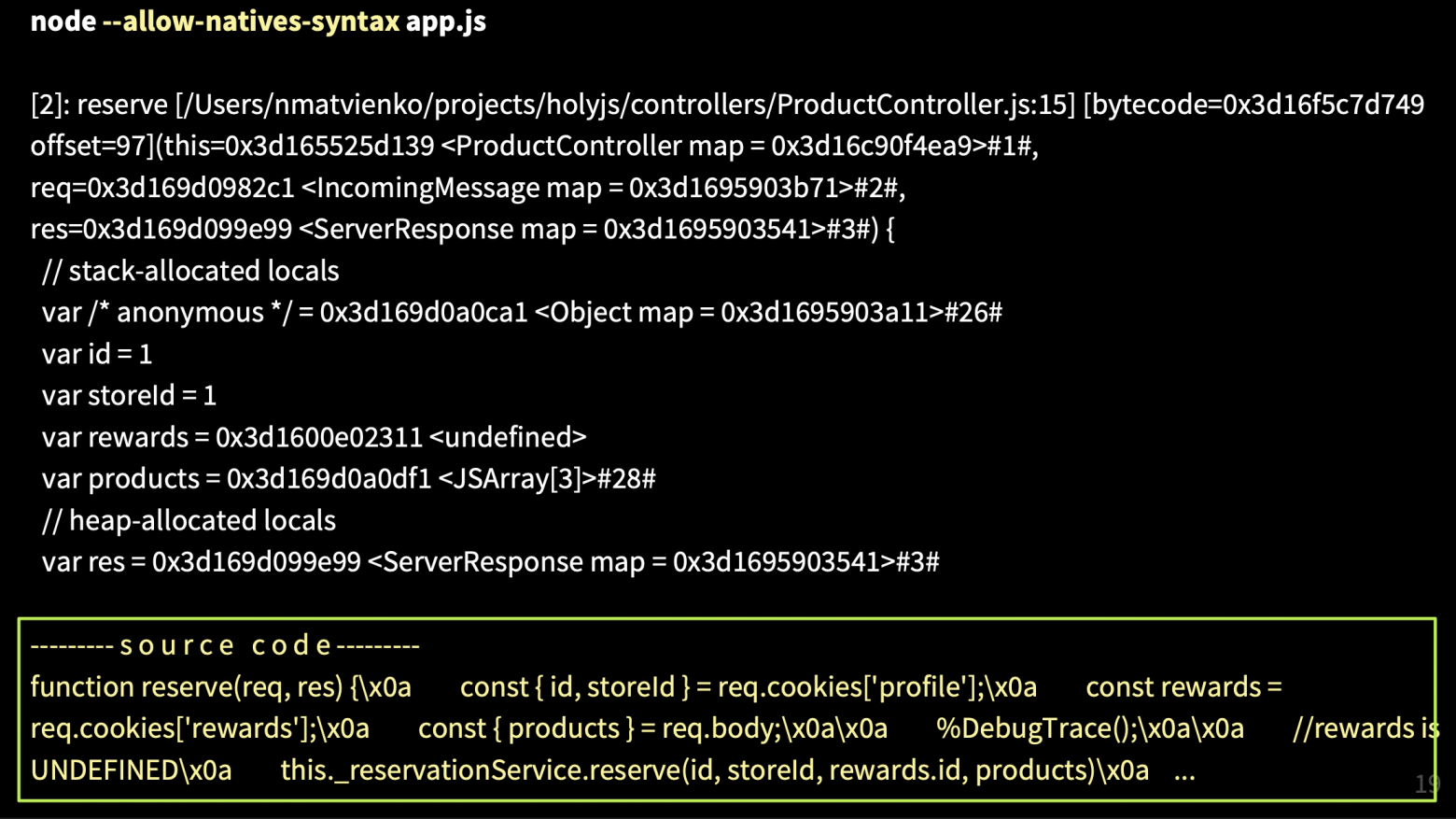
На картинке вы видите листинг ProductController. В методе reserve мы получаем profile из cookies, также берем rewards аккаунт, где хранятся бонусные баллы, id и другая полезная информация, также из cookies. И эта cookies отсутствует — undefined. В случае, когда id берется из rewards, падает ошибка. Локально мы бы поставили breakpoint (красная точка), получили состояние всех объектов и узнали причину, почему у нас падает код.

Я покажу, как это работает под капотом, чтобы вы поняли, что такое Stack Trace. Если написать команду %DebugTrace() — нативная команда V8 и запустить Node.js с опцией --allow-natives-syntax, то есть разрешить нативный синтаксис в V8, то получим большое сообщение с Stack Trace.
В самом верху во втором фрейме у нас будет находиться функция reserve до метода контроллера, и мы увидим там ссылку на контекст ProductController — this, параметры request, response, получим локальные переменные, часть которых хранится в стеке, а другая — в Heap (управляемая куча). Также у нас есть исходный код, и хорошо было бы иметь что-то подобное в production при отладке, чтобы получать состояние объектов.
Такую поддержку реализовали в 2015 году с версии 0.12. Если мы запустим Node c флагом --abort-on-uncaught-exception, создастся core dump — это слепок памяти всего процесса, который содержит Stack Trace и Heap Dump.
Для тех, кто забыл, напомню: память условно состоит из Call Stack и Heap.

В Call Stack желтые кирпичики — это фреймы. В них находятся функции, а функция содержит в себе входные параметры, локальные переменные и адрес возврата. А все объекты, кроме small integer (SMI), хранятся в управляемой куче, на что есть адреса.
Мы разобрались, из чего состоит core dump, теперь перейдем к процессу его создания.
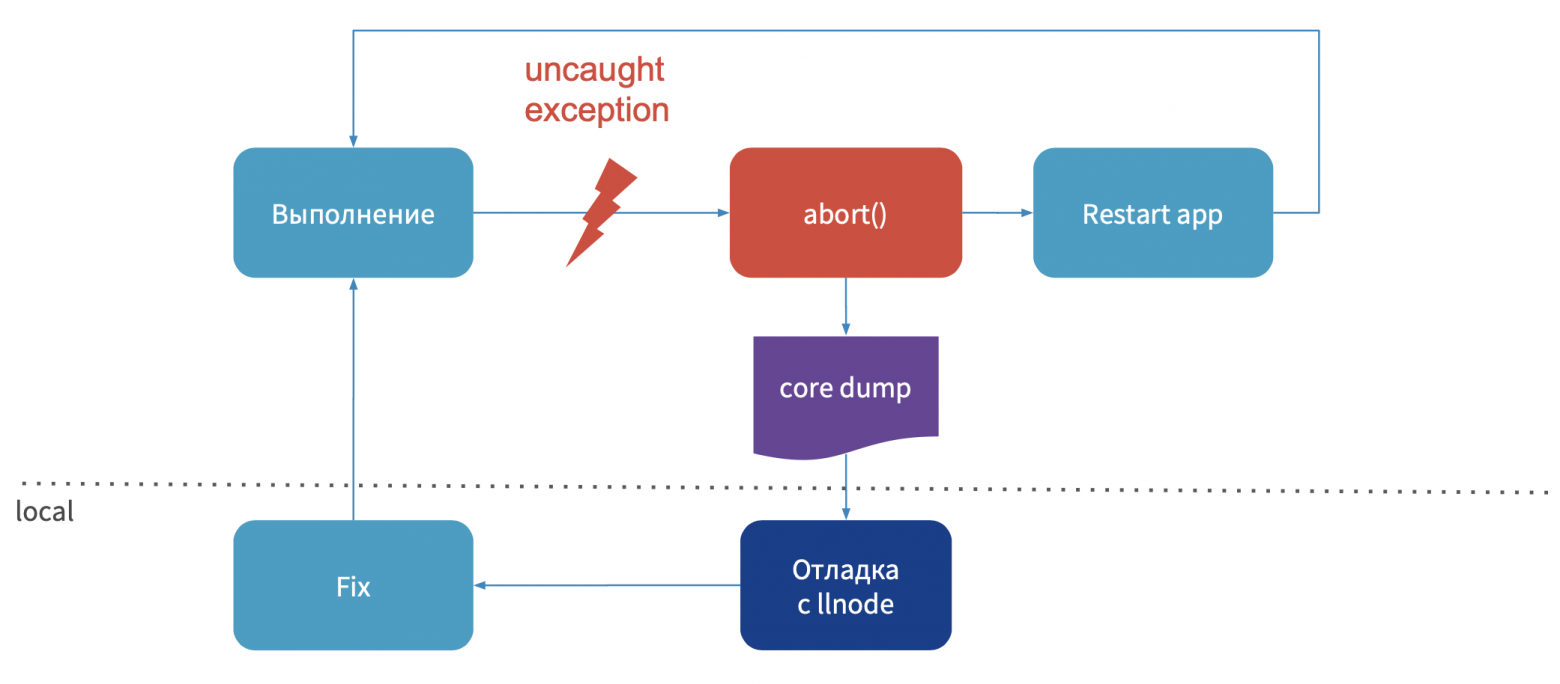
Тут все просто: выполняется процесс вашего приложения, происходит ошибка, процесс падает, создается core dump, потом приложение перезапускается. Далее вы удаленно подключаетесь к production или вытаскиваете к себе на локальный компьютер этот core dump, отлаживаете его отладчиком, делаете hot-fix и публикуете. Теперь, когда мы поняли, как выглядит этот процесс, необходимо узнать, какие дебаггеры можно использовать.

Все они появились до самой Node.js. Для того, чтобы читать JS Stack Trace, в разное время к ним написали несколько плагинов. Большинство из них уже устарело и не поддерживается последней версией Node.js. Я перепробовал практически все и в этом докладе хочу выделить llnode. Он кроссплатформенный (кроме Windows), работает с последними версиями Node.js, начиная с четвертой. Я покажу, как можно использовать этот дебаггер, чтобы отлаживать ошибки в production.
Рассмотрим описанный выше пример — резервирование продуктов.

Настраиваем среду, устанавливаем возможность создания core dump и запускаем наше Node-приложение с флагом --abort-on-uncaught-exception. Далее получаем process pid, делаем запрос пользователю, у которого отсутствует cookies reward, и получаем сообщение, что ошибка появилась в ProductController в методе reserve.

Далее получаем сообщение, что был создан core dump — слепок памяти. Получив core dump или доступ к нему, мы проверяем его наличие — он весит 1,3 ГБ. Немало.

Запустив данный core dump отладчиком при помощи команды llnode, мы можем получить Stack Trace при помощи команды bt.
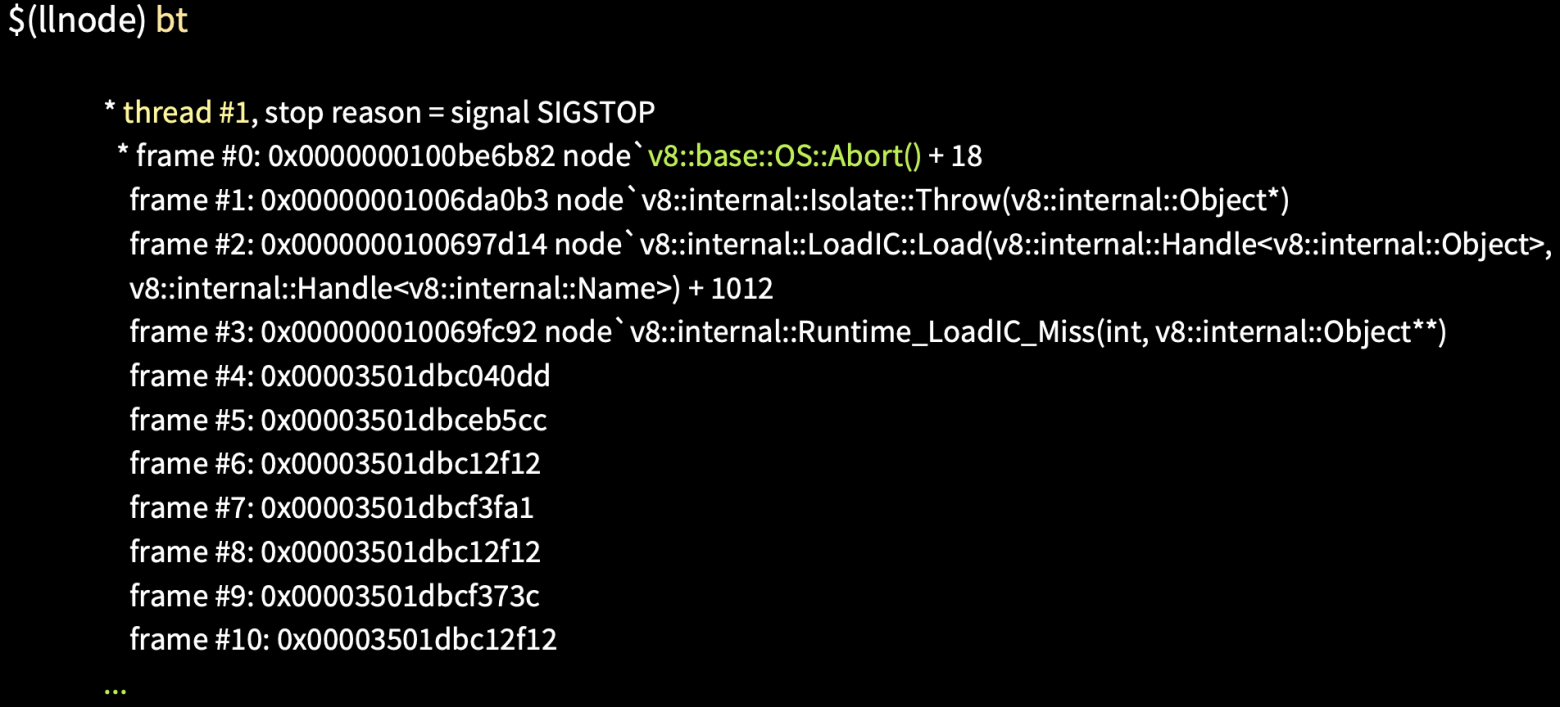
На изображении видно (выше и ниже — более подробно), что в фреймах с 4 по 20 никакой информации нет.

Дело в том, что это JS Stack Trace, который C++ дебаггеры читать не умеют. Для того, чтобы его прочитать, как раз используется плагин.
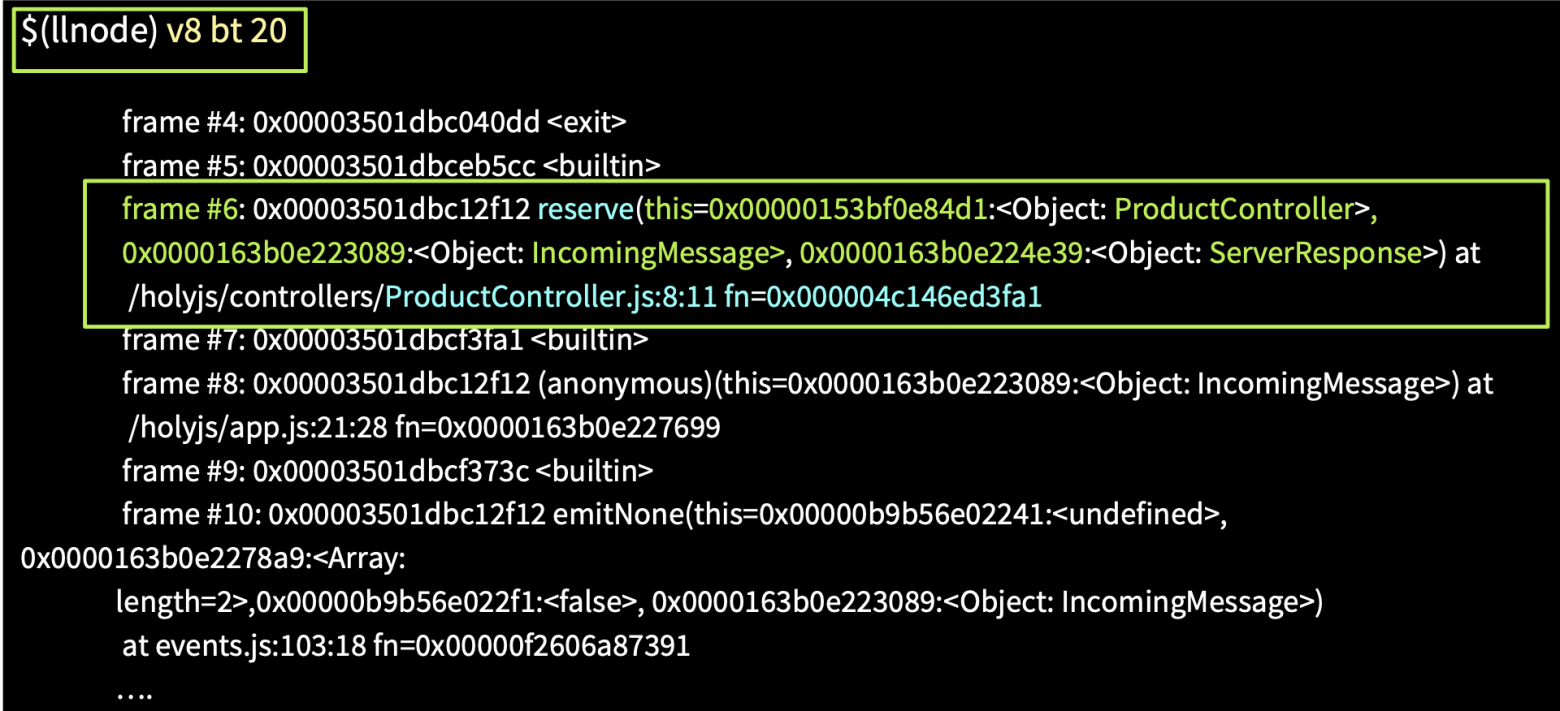
Запустив команду V8 bt, мы получим JS Stack Trace, где в шестом фрейме увидим функцию reserve. В фрейме присутствует ссылка на контекст this ProductController, параметры: IncomingMessage — Request, ServerResponse и голубым выделен адрес функции в памяти. По этому адресу мы можем получить ее исходный код из core dump.
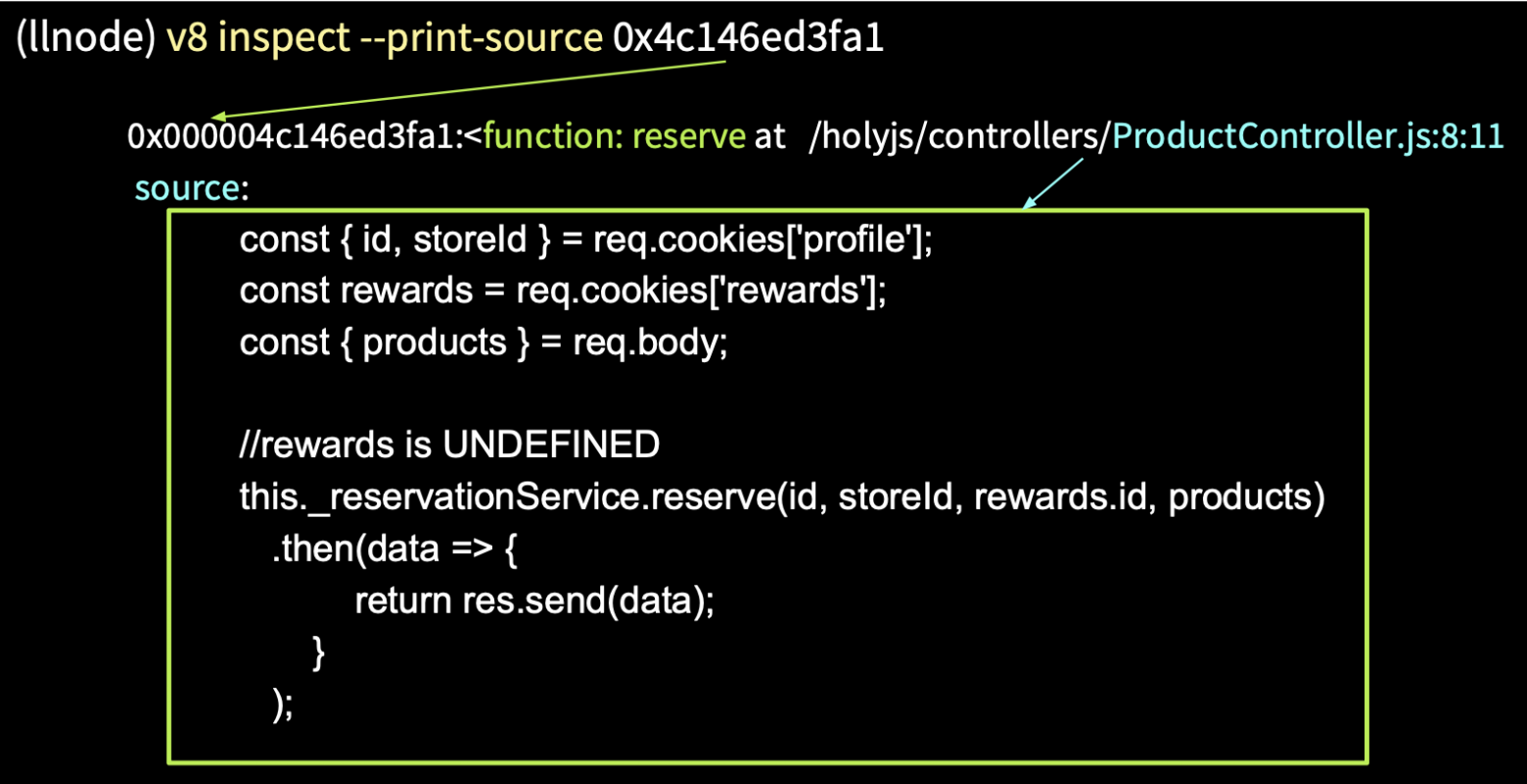
Далее мы пишем команду v8 inspect --print-source [адрес] и получаем из памяти исходный код нашей функции.
Вернемся к Stack Trace, там были параметры request и response, и узнаем, что было в request.

На изображении мы видим команду v8 inspect с указанием адреса. После того, как она выполнится, мы получим состояние объекта request. Здесь нас интересует свойство cookies, url, метод POST и body. Узнаем, какие продукты были переданы на сервер.
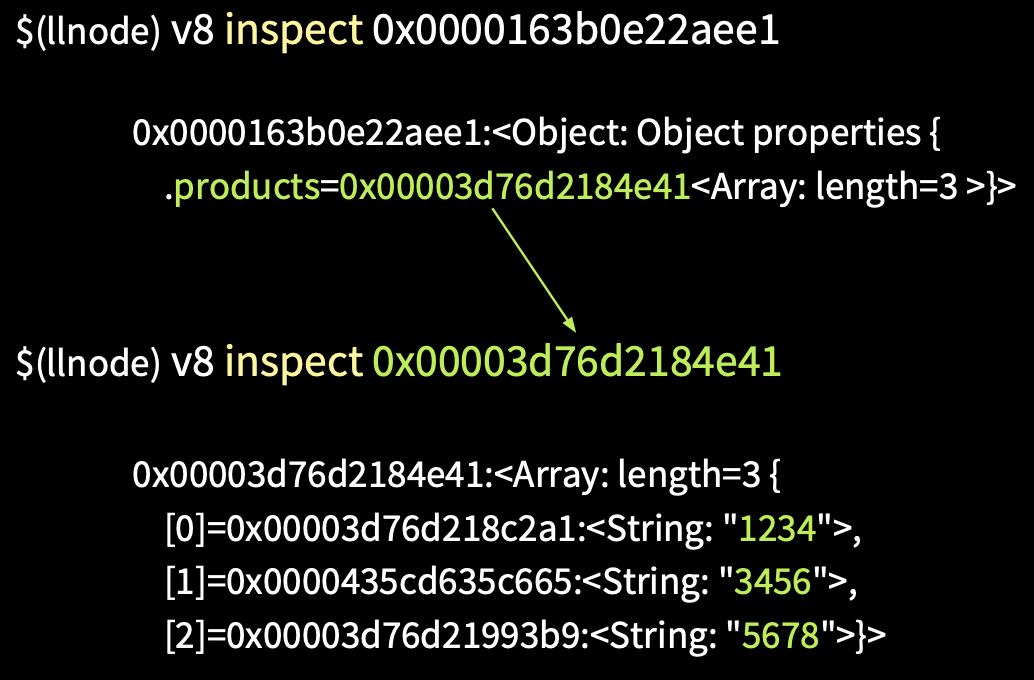
Пропишем команду v8 inspect [адрес body].

Получаем объект, в котором массив состоит из трех элементов в свойстве products. Берем его адрес, инспектируем и получаем массив из id.
Здесь проблемы нет. Посмотрим, что же было в объекте req.cookies.

Это объект из двух свойств: profile и rewards — undefined. Узнаем, у какого пользователя отсутствует rewards-аккаунт.

Пропишем команду v8 inspect [адрес profile] и получим его id и storeid. Таким образом нам удалось в production без исходного кода получить source code и восстановить сессию пользователя.
Здесь был очень удобный случай, а если вы используете фреймворк, который содержит в себе ErrorHandler Middleware, то в отличие от предыдущего примера, где у нас были ссылки из Stack Trace на контекст this, request, response, если ErrorHandler не переписывать, то у вас в Stack Trace будут последние вызовы самого Express и не с чем будет работать. У вас не будет ссылок.

Я приведу пример, как это происходит.

Тот же самый пример с методом reserve, но уже ошибка падает глубоко в сервисе, который работает в асинхронном режиме. Для того, чтобы ее отловить, подпишемся на события процесса unhadledRejection, где мы делаем process.abort(), чтобы создать core dump.

Ниже показано, как выглядит в этом случае backtrace.

Нет никакой информации о ProductController, о reserve. В этом фрейме есть вызов process.on и больше ничего полезного. Такие случае бывают в production, когда ошибка не была перехвачена и в Stack Trace никакой информации нет. Дальше я покажу, как, работая только с управляемой кучей без Stack Trace, найти все объекты.
Мы можем получить все экземпляры объекта по типу IncomingMessage. Это будет большой список всех request, которые были переданы, но нам нужно найти тот единственный, вследствие которого упал процесс.
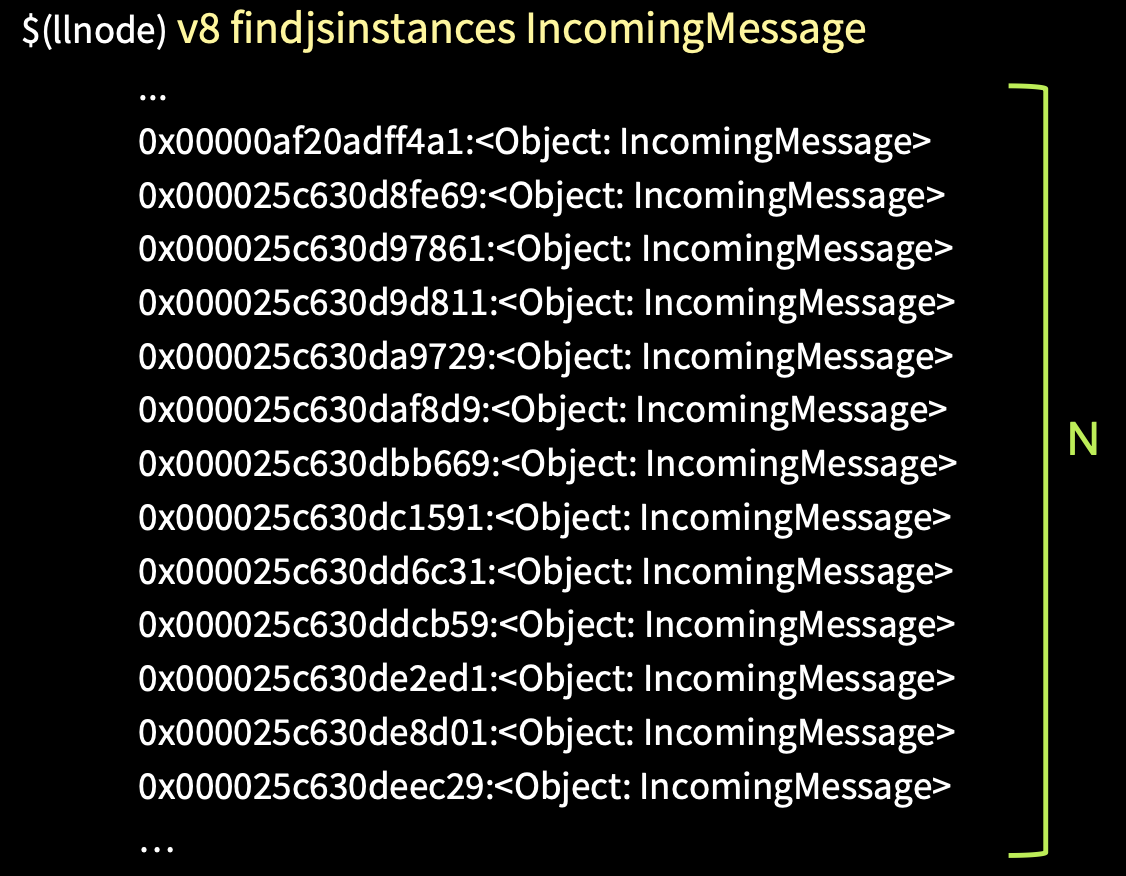
В данном случае нам потребуются логи, и в них нам необходимо получить request id — это X-Transaction-ID.

В llnode есть возможность в памяти по значению строки найти ссылки, которые ссылаются на нее. Если мы напишем команду v8 findrefs --string [значение строки], то найдем объект, у которого есть свойство X-Transaction-ID, и он ссылается на эту строку. Выясним, что это за объект.
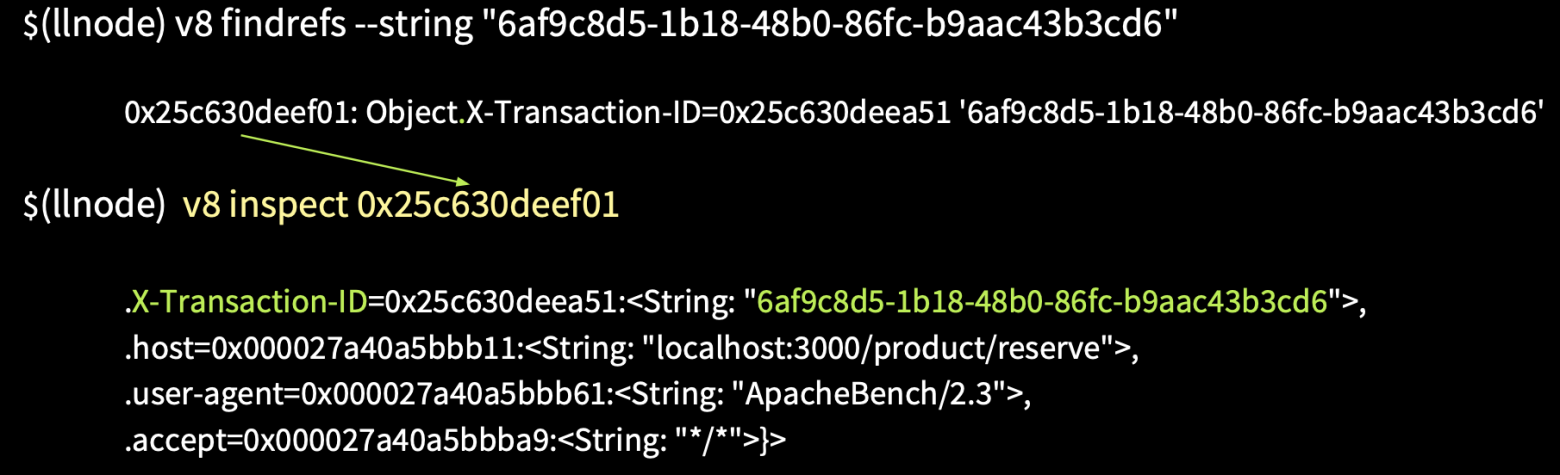
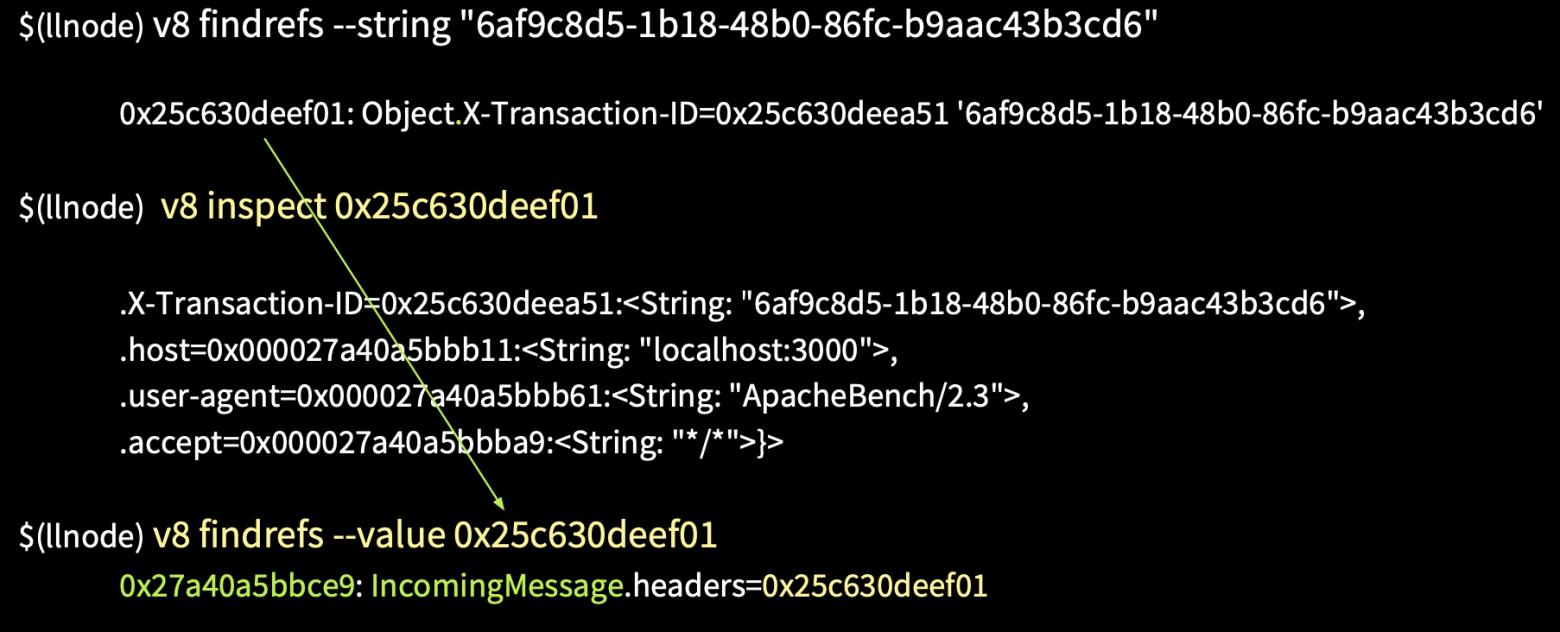
Напишем команду v8 inspect [адрес], после чего получим объект headers. Далее узнаем, что же ссылается на этот объект, и мы получаем объект IncommingMessage. Таким образом, не имея Stack Trace и адресов, мы смогли восстановить сессию пользователя.
Давайте углубимся в более сложный пример, когда вам необходимо получить локальные переменные — они находятся в сервисах.
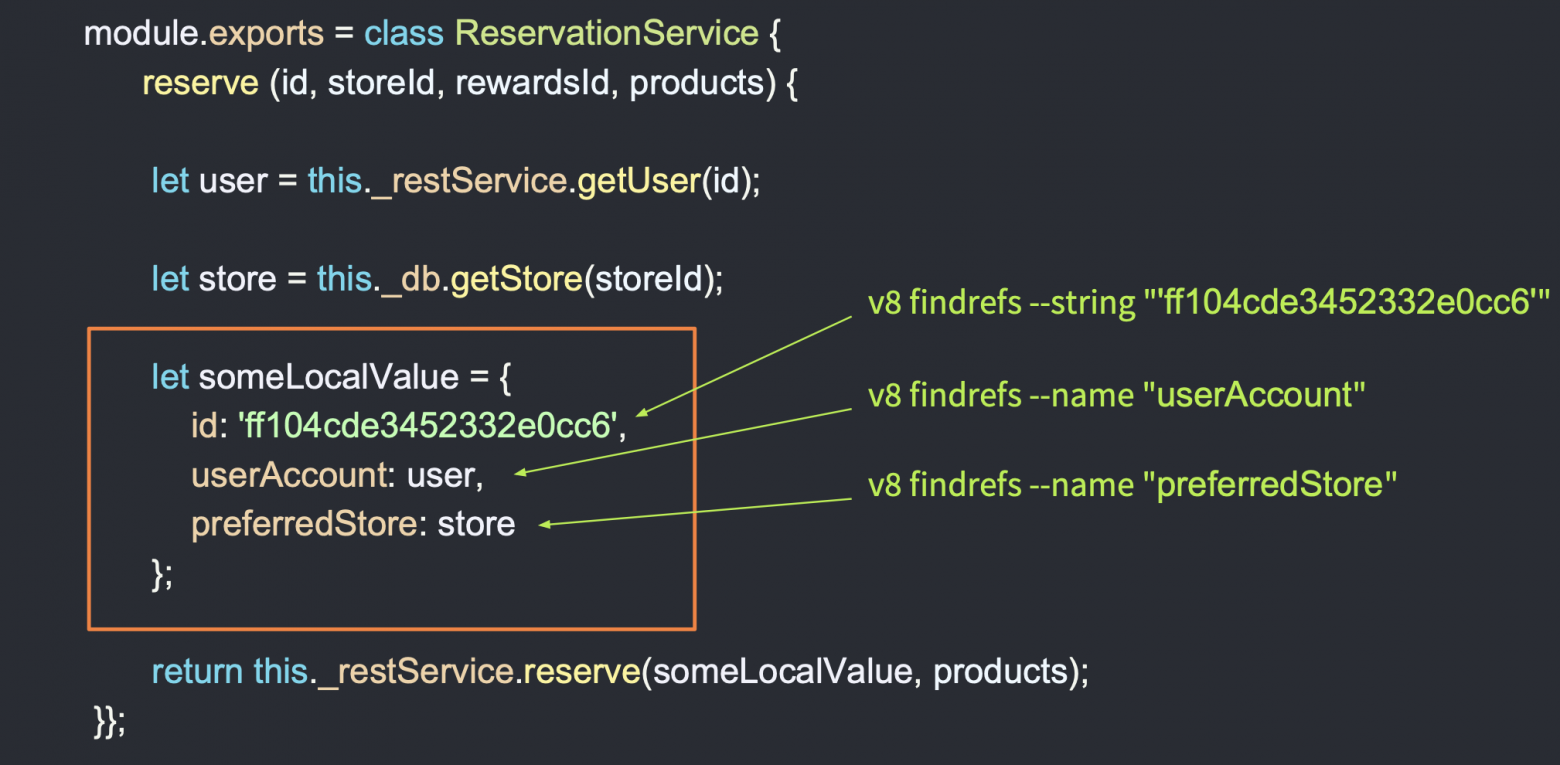
Предположим, что ошибка упала где-то глубоко и полученных данных мало. В данном случае используется REST API. Из базы данных берутся объекты, и все они присваиваются некоторой локальной переменной, которая называется someLocalValue. И у нас нет объекта, который ссылается на someLocalValue. Как в таком случае получить локальную переменную из памяти? Можно найти этот объект, например, по значению id, если вы его получили из логов, но также можно получить объекты из памяти по названию его свойств, т. е. с командой v8 findrefs name мы можем найти объекты, которые имеют свойство userAccount, preferredStore, и таким образом мы получим необходимые нам локальные переменные!
Итак, возьмемся за реальный кейс — ошибки в production.

На каждую ошибку мы создаем core dump. Но что здесь не так? Ошибок очень много — 3620 за минуту, а core dump весит 1,3 ГБ, и время, которое требуется для того, чтобы его создать и слить на систему, — порядка 15-20 секунд. Здесь явно не хватает логики, которая будет селектировать создание core dump.
Например, у вас выполняется приложение и возникает ошибка, или вы отловили ошибку, которую вам сложно воспроизвести. Далее процесс попадает в ErrorHandler, где у вас есть логика — необходимо ли для этой ошибки делать process.abort, чтобы создать core dump, либо мы продолжаем выполнение программы.
Если ошибка уникальна и ее нужно обработать, при помощи node-report создается отчет, далее вызывается process.abort и создается core dump, и процесс перезапускается. Ваш сервер опять работает, обслуживает трафик, и уже позже вы получаете доступ к отчету, core dump и логи, далее с помощью отладчика отлаживаете, делаете hotfix и публикуете.
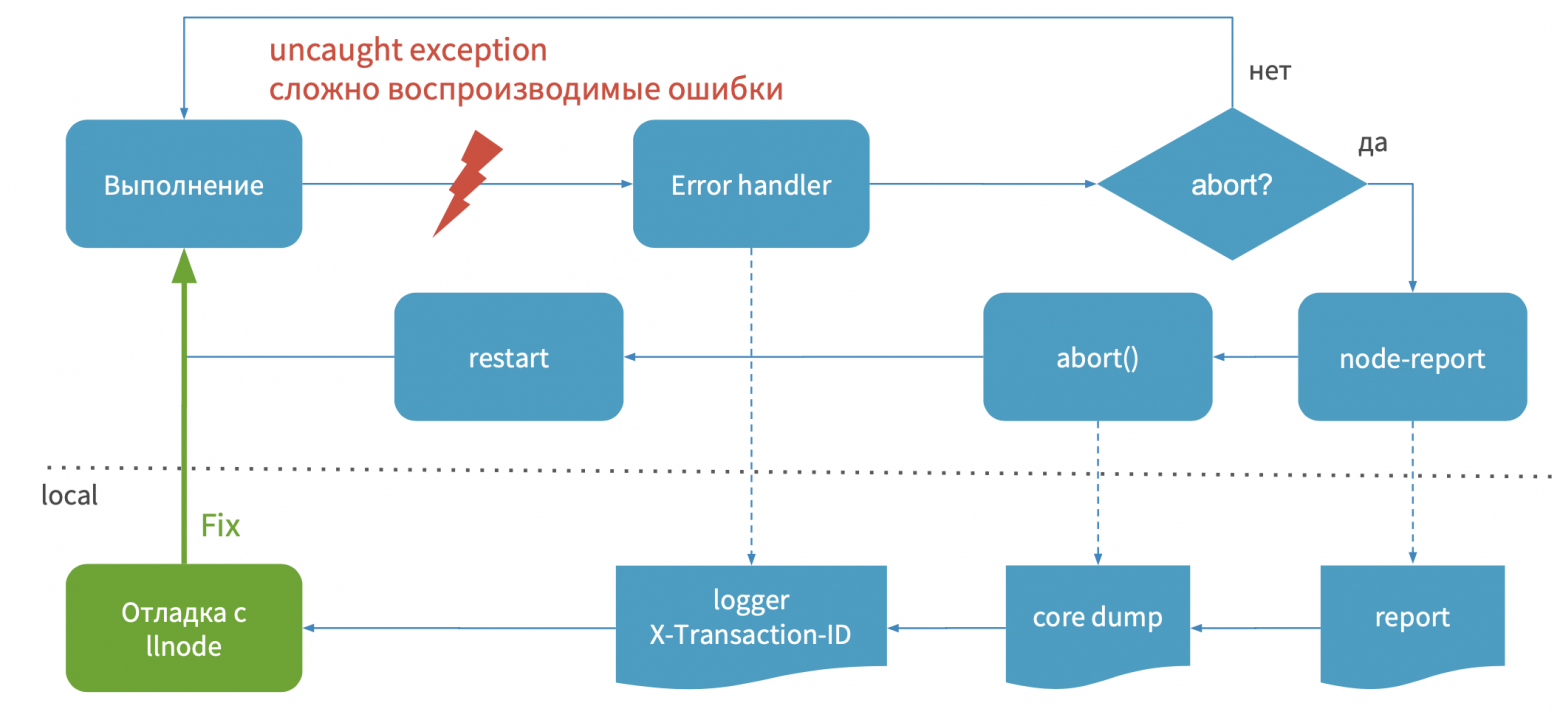
Ниже на изображении приведен пример логики, которая делает селекцию. Я называю это реестром ошибок. Он ограничивает создание core dump.

Это некоторый класс, который использует у себя In-Memory Databases, и когда вы находите ошибку, проверяете, зарегистрирована ли она в реестре или нет. Если нет, то смотрите, нужно ли ее регистрировать. Если да, то сбрасываете процесс, создаете core dump. В таком случае вы не будете создавать core dump на ошибки, которые повторяются. Вы будете их селектировать. Это ускорит процесс отладки.

Я считаю, что процесс отладки в production — это некое детективное расследование, где node-report скажет, что произошло, где и при каких обстоятельствах было совершено преступление против вашего процесса по JS Stack Trace. Логи дадут вам зацепки, улики, ценную информацию. Отладчик позволит найти объекты, которые имели место быть в момент преступления, то есть в этих функциях.
Вот таким образом мы работаем в production и отлаживаем ошибки.
Перейдем к поиску утечек памяти.
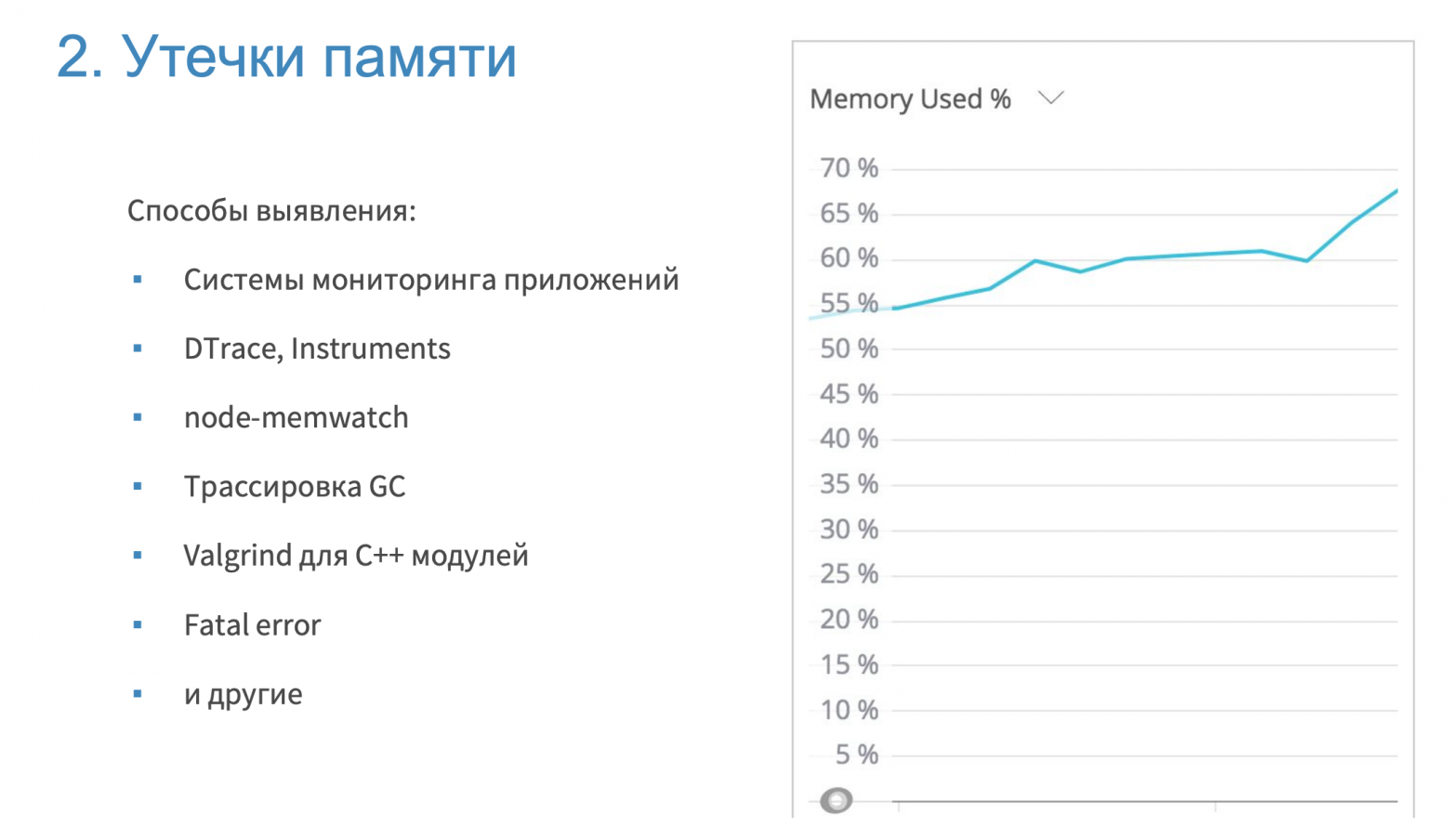
Существует множество способов определения утечек памяти (некоторые упомянуты на изображении выше).

Например, в графиках нагрузки процессора и памяти можно заметить определенную корреляцию. И в ситуациях, когда у вас есть утечка памяти, нагружается сборщик мусора, который забирает больше процессорного времени.
Рассмотрим пример утечки.
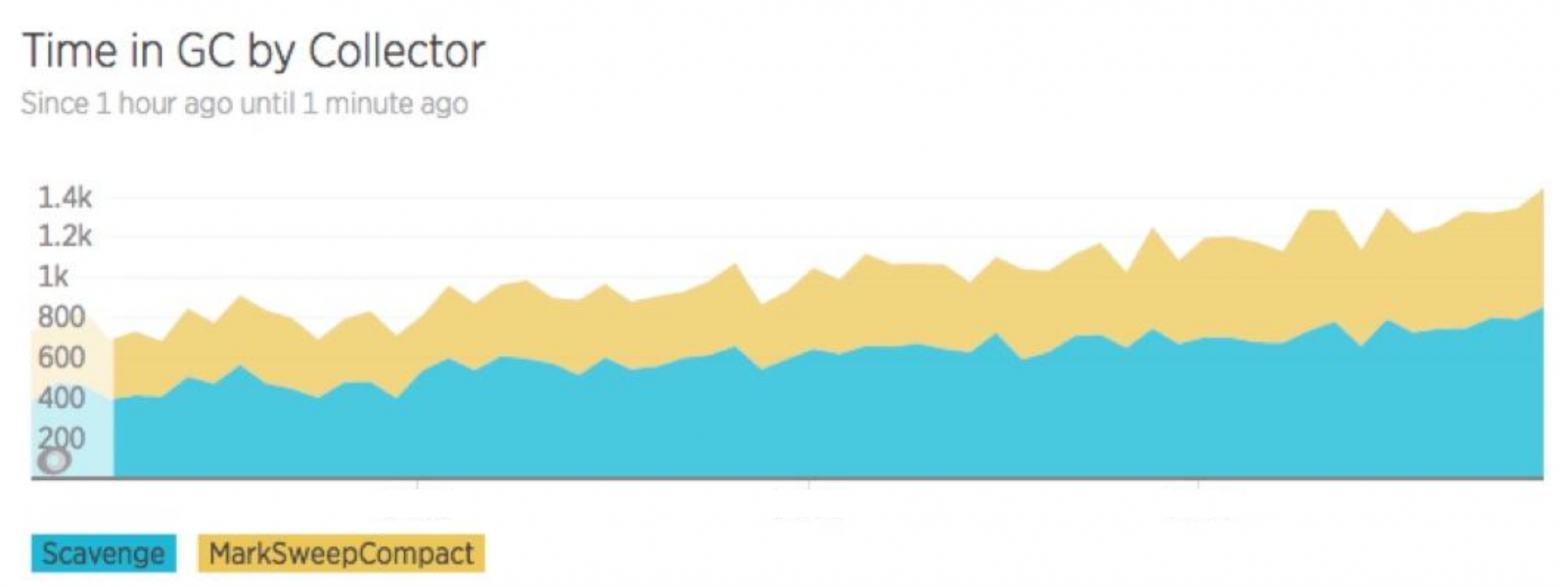
На изображении выше показан график работы сборщика мусора. Scavenge — работает в пространстве молодых объектов. MarkSweep — в пространстве старых объектов. На графике видно, что количество сборок мусора растет, значит, память утекает и необходима более частая сборка мусора. Чтобы понять, где и в каком из пространств она утекает, мы используем трассировку работы сборщика мусора.

На изображении выше виден список областей памяти, который отображает их состояния при каждой итерации сборки мусора. Там есть old space, new space и другие. Когда мы получали source code из core dump, мы брали его из code space.

Из опыта я могу сказать, что если память утекает в пространстве новых объектов, то виноваты в этом дорогостоящие операции клонирования, merge и так далее. Если память течет в большом пространстве старых объектов, то это упущенные замыкания, таймеры. А если память утекает в пространстве large space, где не работает сборщик мусора, то это сериализация/десериализация больших JSON.
Ниже на изображении приведен пример трассировки Scavenge, которая работает в области молодых объектов. Тут нет утечки памяти.

Как это можно выяснить? У нас два столбика, выделенные жирным зеленым шрифтом. Эта память, которая была выделена под ваш процесс до сборки и после сборки. Значения равны, и это говорит о том, что после сборки мусора выделенная память не увеличилась. Синим шрифтом выделено время, потраченное на сборку мусора. В документации указано, что на это требуется 1 миллисекунда по умолчанию. У нас в проекте это порядка 3 секунд, и мы считаем это нормой. На верхнем изображении внизу видны три строчки, это тоже сборка мусора, но уже итеративная, то есть у вас сканируется и очищается не вся память, а по кусочкам. Там также видно количество итераций.
Ниже на изображении пример утечки памяти в том же самом пространстве. В сиреневых столбцах видно, что объем занимаемой памяти растет, то есть после сборки мусора он каждый раз увеличивается.
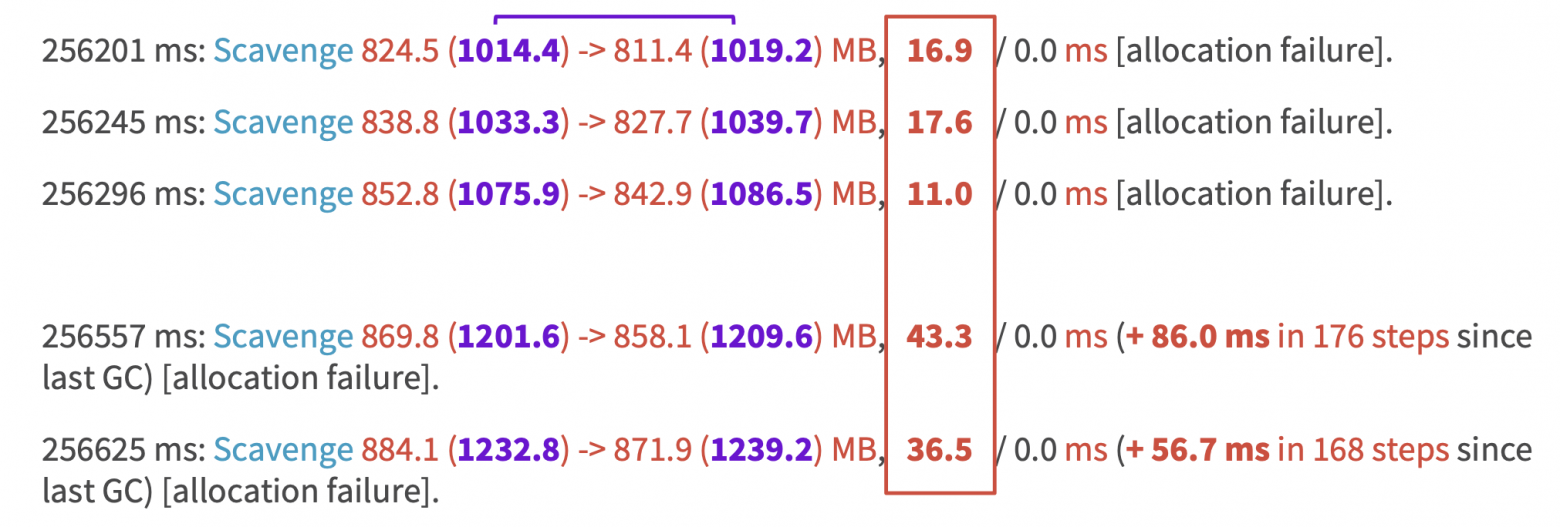
Как же обстоят дела в пространстве старых объектов?

Здесь мы видим, что процесс выполняется дольше: 90 мс, 110 мс и т. д. Это очень много. Более того, он выполняется еще итеративно, что тоже требует времени в фоновом потоке.
Под капотом Node.js имеет несколько потоков. Один — для профилирования, несколько — для сборки мусора и поток для выполнения самого приложения.
Рассмотрим пример ниже, чтобы понять, как выявить утечки памяти.

Заметьте, Middleware, который обрабатывает request, фиксирует время старта выполнения в начале, и когда request закончился, он фиксирует время после выполнения, где вызывается некоторая функция для его процессинга — someProcessOperation. В эту функцию мы передаем request. Здесь присутствует замыкание. Объект request удержан после его отправки. А на него еще могут быть другие ссылки, что тянет за собой множество объектов. Что нужно делать в таком случае? Нам не нужен весь объект request. Мы можем передать только его id и url. Таким образом мы избежим утечки памяти.

Как можно это выяснить?

Я покажу, как мы делаем это с дебаггером llnode (в случае Fatall Error, когда после краха приложения из-за нехватки памяти Node.js создаст coredump). В предыдущем случае мы получали core dump, когда у нас падал exception и процесс завершался. В этот раз мы, разумеется, не стали вызывать process.abort() на работающем приложении, чтобы получить core dump, а вооружились инструментом gcore, который позволяет на уровне инфраструктуры сделать запрос на process id и получить core dump по требованию. Однако тут мы столкнулись с инфраструктурным ограничением, из-за чего пришлось искать другие варианты.
Месяц назад была опубликована библиотека, которая называется gen-core. Данный инструмент позволяет сделать форк вашего процесса, убить его, не нанеся вреда вашему основному процессу, и получить core dump.
Ниже на изображении приведен пример работы gen-core.

Здесь DiagnosticController по REST API сможет сделать core dump.
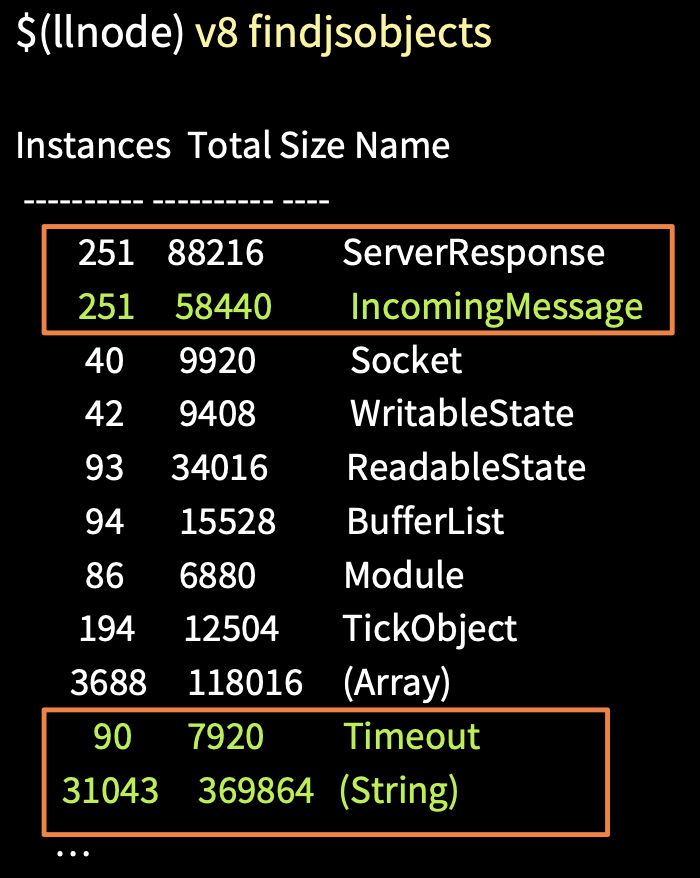
У нас есть команда findjsobjects, при помощи которой мы можем просканировать всю кучу и сделать группировку по типам, получить отчет о количестве экземпляров объекта каждого типа, о их размере в памяти и т. д. На изображении выше видно, что экземпляров ServerResponse и IncomingMessage достаточно много, также есть объекты Timeout и String. Строки сами по себе очень большие и занимают много памяти. Зачастую они находятся в пространстве large space, где не работает сборщик мусора.
Давайте выясним, почему у нас много объектов request. Помним, что объект request был удержан в Middleware.
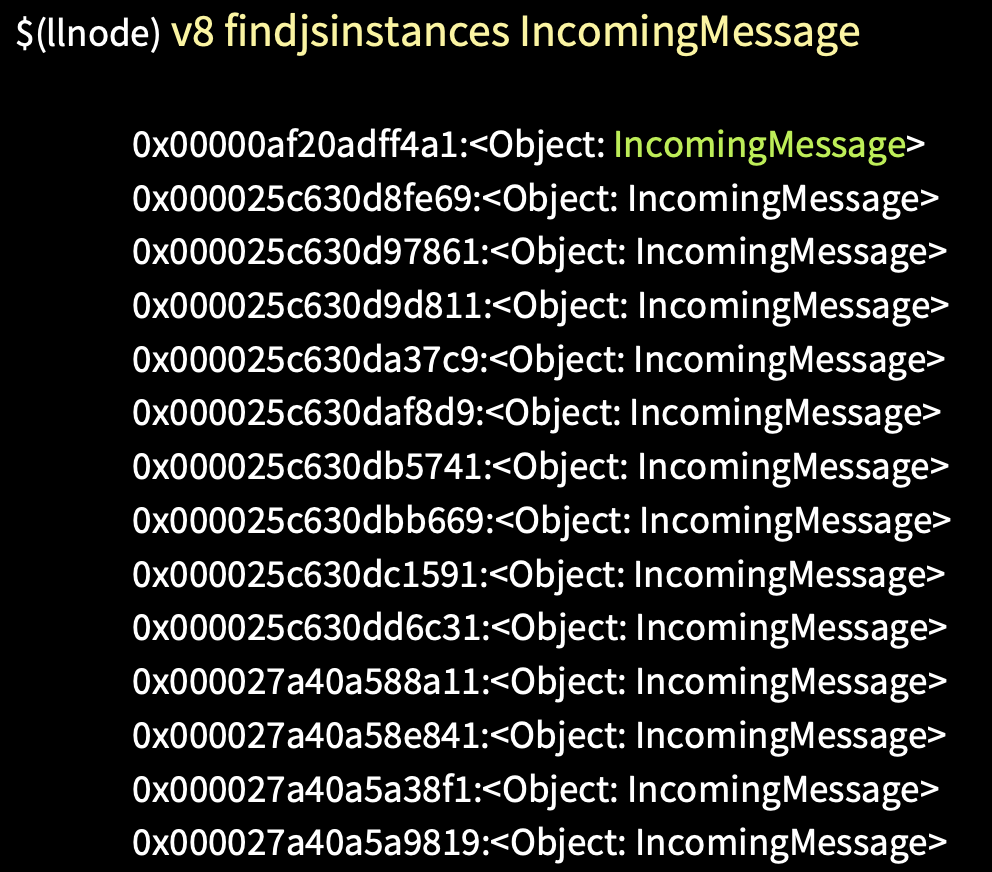
Есть команда findjsinstances [тип], и с ее помощью мы получаем список объектов request.
Берем адрес первого объекта и при помощи команды v8 findrefs -v ищем в памяти объект, который имеет ссылку на него.
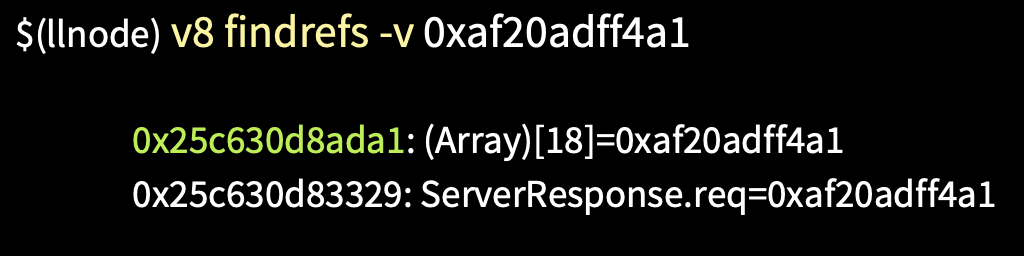
Это два объекта. Первый — массив из 18 элементов, а второй — это объект request. Узнаем, что это за массив и почему он удерживает наши объекты request.

Используем команду v8 findrefs -v [адрес этого массива] и получаем, что этот массив находится в объекте типа Profiller и свойстве processingQueue. Таким образом мы смогли узнать, где в памяти удерживают наши объекты request. Дальше мы идем в source code или получаем его оттуда и смотрим, где вызывается processingQueue.

Мы используем команду findjsinstances [ тип Timeout ], получаем список всех таймаутов и далее будем искать, где они используются.

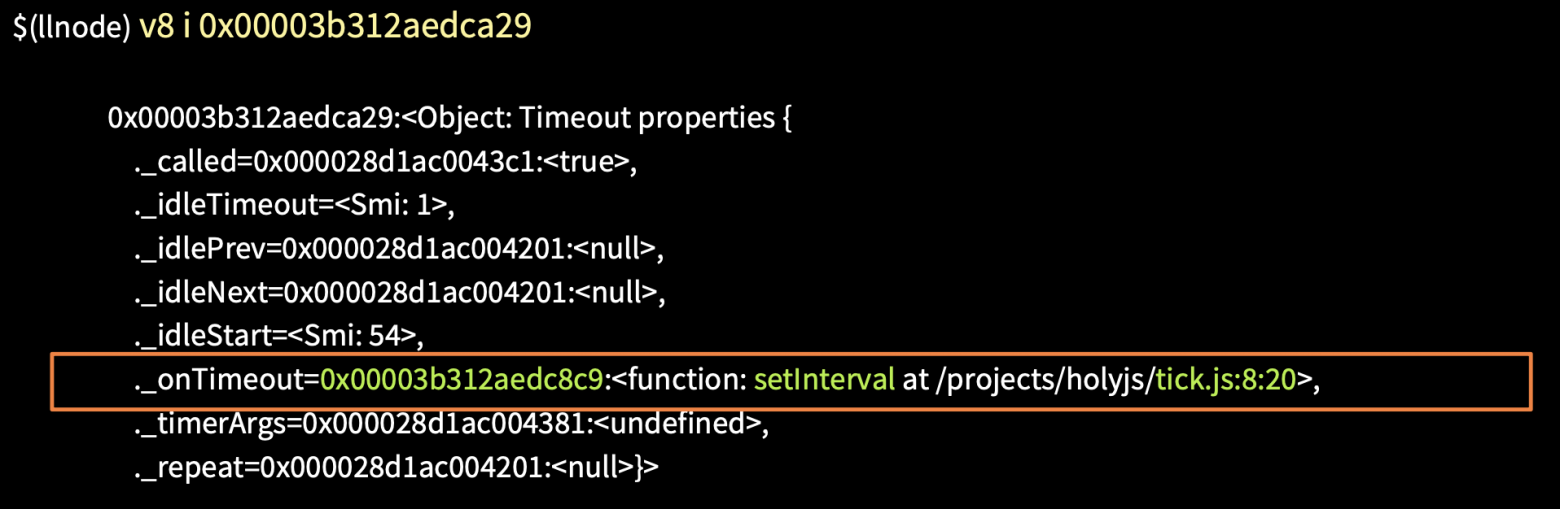
При помощи команды v8 i получаем первый таймаут.
В свойстве onTimeout мы можем увидеть, что вызывается функция setInterval и адрес с местом расположения файла. Таким образом мы быстро узнали, где у нас забытый таймер и почему он выполняется.
Если использовать команду %DebugTrackRetainingPath(x), которая добавлена была совсем недавно в V8 (в Node.js еще нет ее поддержки), скачать исходники V8, собрать и использовать дебаггер V8 и запустить приведенный выше на изображении JS, то мы получим ссылки любой нужной нам переменной до объекта root. Не стоит забывать и о вызове сборщика мусора. В примере это вызов gc().

Мы запускаем debug8 с флагами --allow-natives-syntax, --track-retaining-path, --expose-gc и файлом test.js. В листинге мы получаем пошагово, кто и что удерживает объект до root.
Таким образом, мы разобрали поиск утечек памяти в production.

На изображении выше вы видите реальный пример, когда после очередного релиза мы просели по производительности в пять раз. Очень сильно выросло время отдачи Web UI приложения.
Для таких случаев есть простой и эффективный алгоритм действий, который продемонстрирован ниже.

Хотя в 2013 году в Node.js был добавлен профайлер, tick-processor (инструмент, который обрабатывает логи V8 и делает отчет) появился там только в прошлом году. До этого мы использовали либо профайлер V8, который имел tick-processor у себя, либо приходилось скачивать сам V8, собирать, и там в инструментах активировать этот процессор.
Профайлер дает вам информацию на высоком уровне, он поможет определить природу проблемы и увидеть, какие функции выполнялись дольше всего.

Существует удобное представление данных этого лога в графическом виде, и оно называется flame graph. Разработал его в 2013 году Брендан Грегг.
Кто помнит, в 2015 году получение графа было настоящей головной болью, но сейчас он создается одной командой с помощью 0x.

Теперь разберемся, как с ним работать.
Чтобы выделить профайл нашего приложения, нижними кнопками уберем все лишнее. В итоге мы видим, что работа приложения занимает лишь небольшую часть от всего времени выполнения.
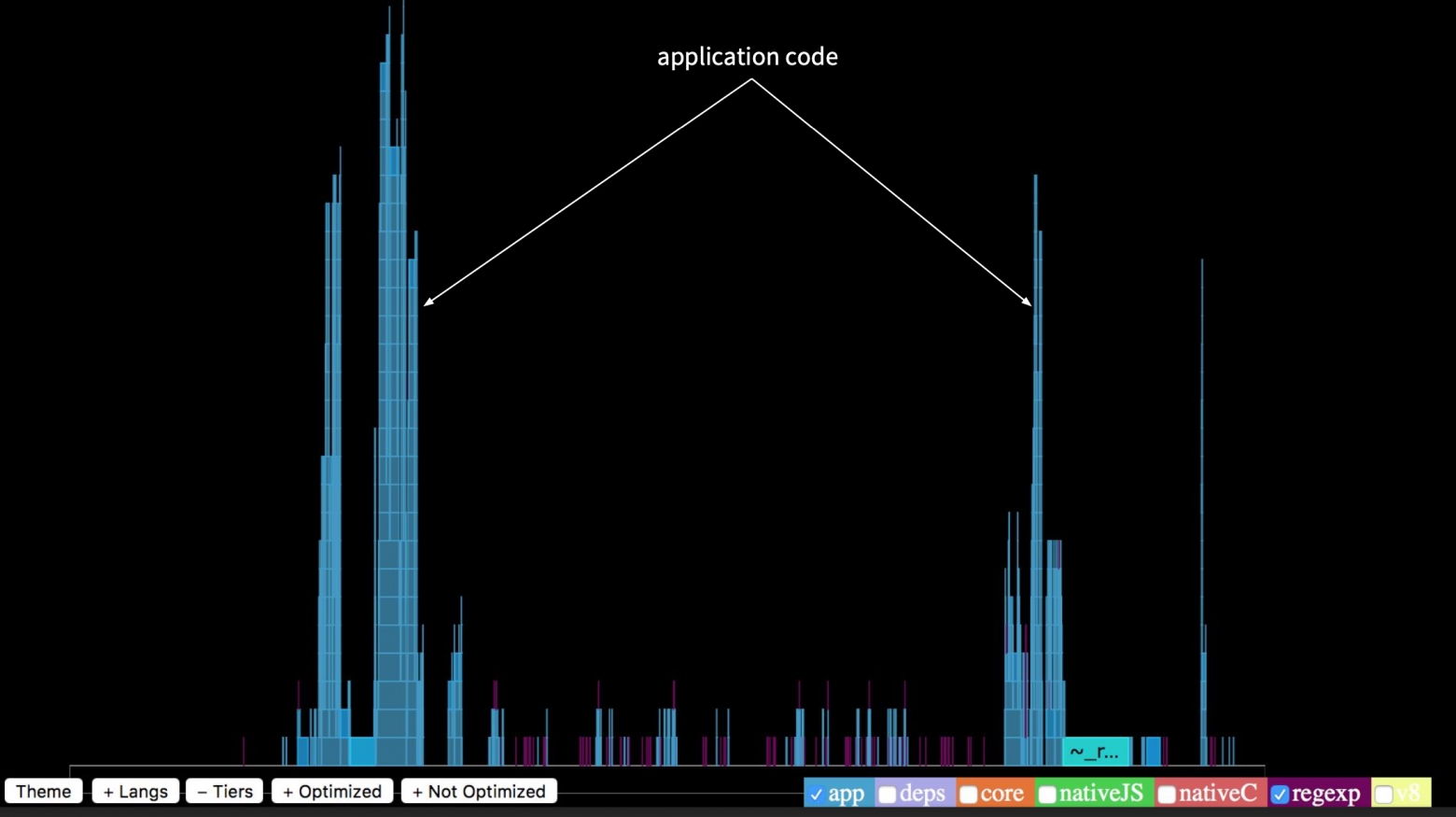
Stack Trace последовательности вызова функции конечна и умещается на экране. Что же тогда выполняется долго? Если мы включим подсветку работы npm-пакетов, то увидим, что они выполняются в девять раз дольше, чем само приложение. Это очень много.
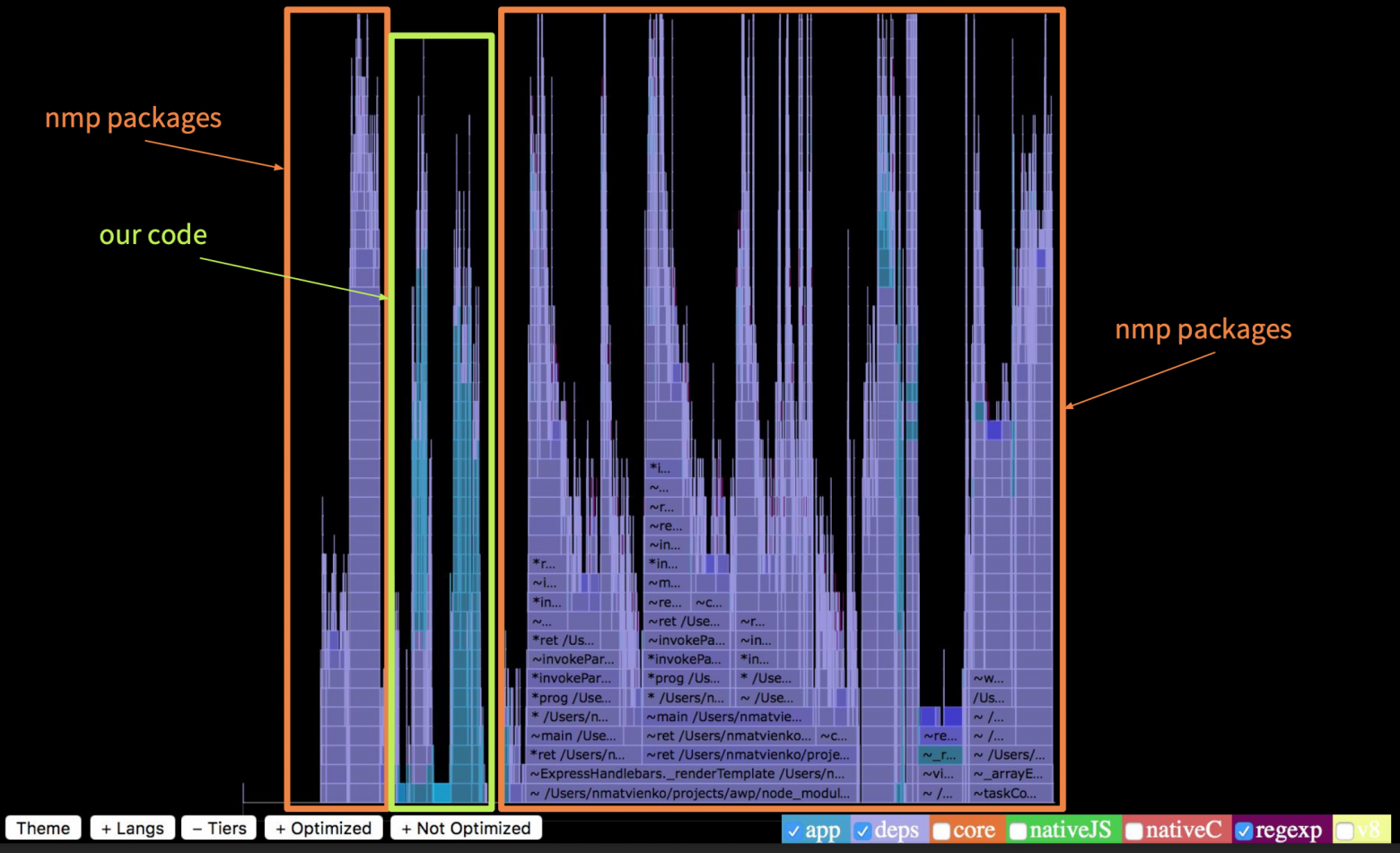
Если мы подсветим оптимизированные функции, то увидим, что их очень мало. Около 90% вызовов были не оптимизированы.

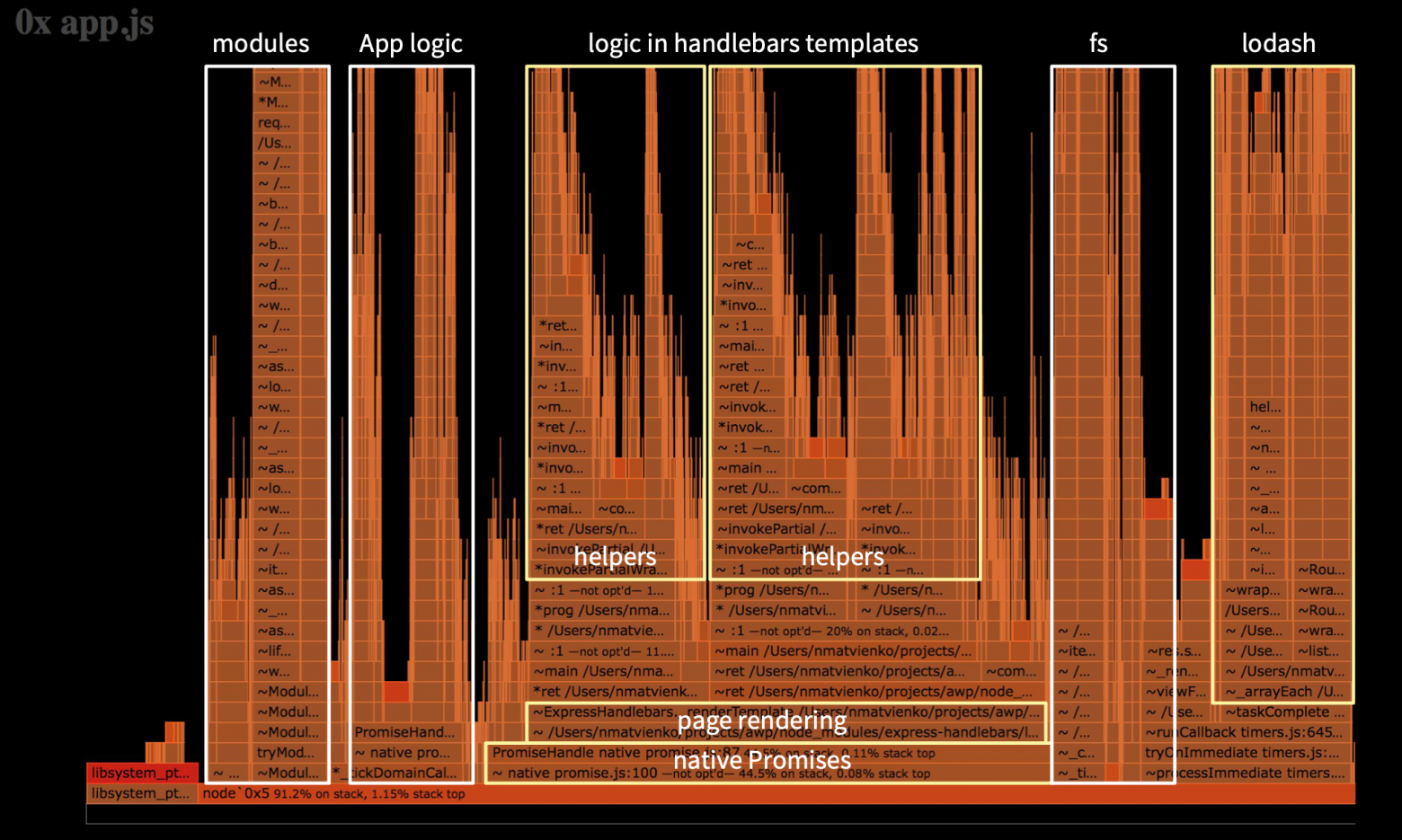
Если мы глянем на верхушки вызовов, то увидим, что в нашем приложении очень много стека было в handlebars, кроме того у нас был lodash merge, который делал merge объектов, у нас были сторонние утилиты, которые также требовали времени.

Если мы разберем тот же граф нашего приложения, то увидим, что в основе фундамента находится нативный промис, который до Турбофана выполнялся долго. Но больше всего по времени занимает рендеринг страниц. Наше приложение в процентном соотношении — это десятая часть всей логики.
Что мы исправили?
Ниже представлен граф, который мы видим уже после внесенных исправлений.

Здесь стоит обратить внимание на правую часть, где handlebars helpers. Ранее отрисовка view занимала больше половины графа, а сейчас — одну десятую. Мы достаточно хорошо все оптимизировали, и теперь работа самого приложения занимает примерно половину всего времени. Это не значит, что оно стало работать дольше,- это все другие процессы стали работать меньше по времени.
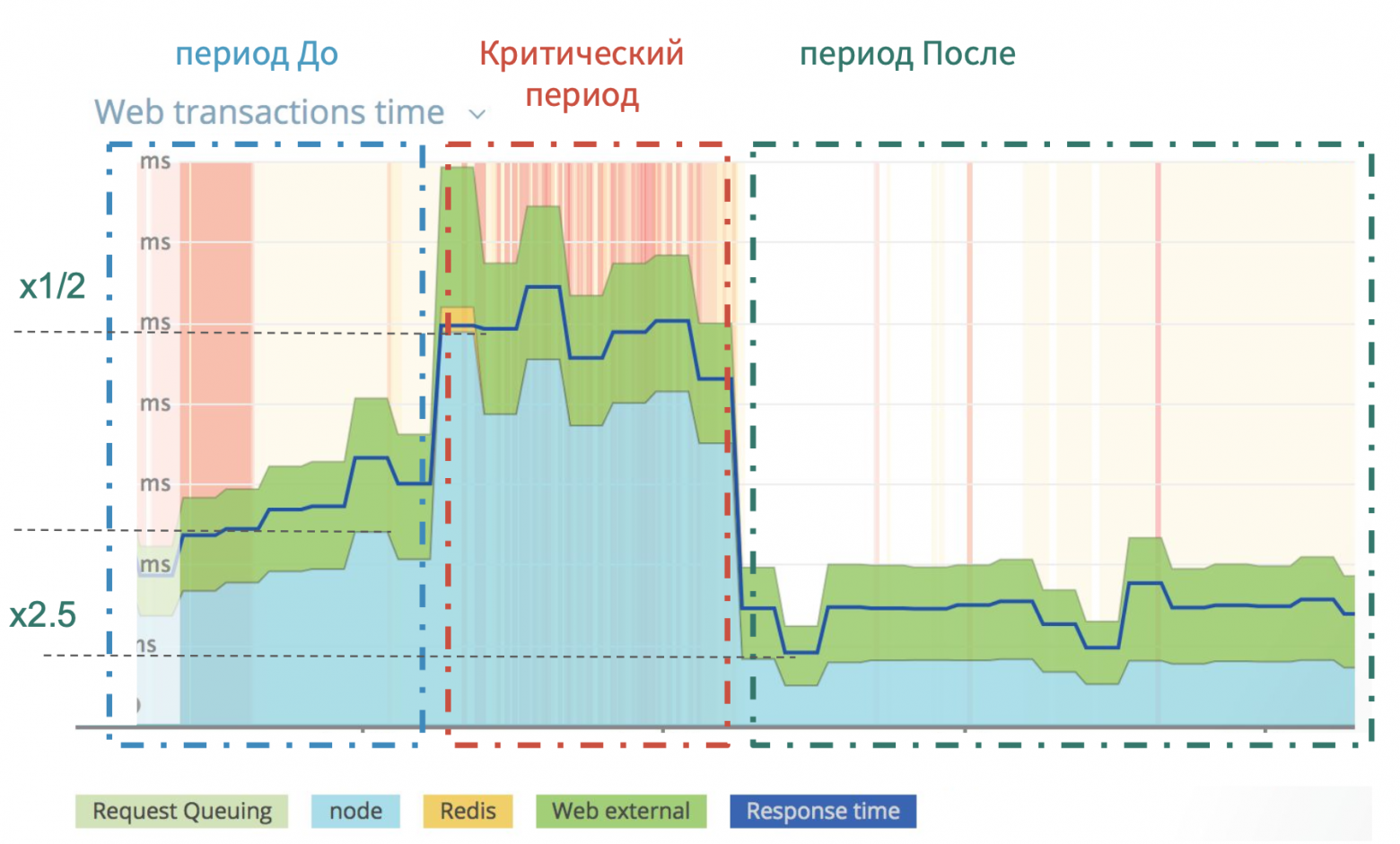
На изображении сверху видно, что на этапе до выхода критического релиза график рос, и мы понемногу теряли в производительности. Потом произошел резкий скачок. В критическом периоде мы были 3,5 недели и искали недочеты, вносили изменения.
Суть проблемы была в том, что ошибка (парсинг строк JSON) была заложена в приложении задолго до этого релиза, и выстрелила лишь в определенный момент. В итоге после всех исправлений и оптимизаций мы выиграли в производительности в два раза, если за точку отсчета брать первоначальный уровень.
Использованные в докладе ресурсы
Мы расшифровали для Хабра доклад Николая Матвиенко из Grid Dynamics с нашей конференции HolyJS. Далее повествование идёт от лица спикера.
Чтобы понять, на каком этапе эволюции инструментов диагностики мы сейчас находимся, я предлагаю обратиться к истории. На временной шкале я изобразил наиболее значимые моменты.
Этапы развития диагностики Node.js до 2017 года

Сначала в свет вышли такие инструменты, как DTrace, Instruments, perf — это системные профайлеры, которые появились задолго до Node.js, при этом они используются по сей день. С появлением Node.js к нам приходят Node-ориентированные инструменты — здесь стоит выделить node inspector, node-heapdump, node-memwatch. Этот период я отметил серым и условно называю его смутным временем. Вы помните, что там был раскол комьюнити: в тот период io.js отделился от Node.js, и у комьюнити не было общего понимания, куда двигаться дальше и кого выбирать. Но в 2015 году io.js и Node.js объединились, и мы увидели Node.js v4 Argon. У комьюнити появился четкий вектор развития, и Node.js в production начали использовать такие крупные компании, как Amazon, Netflix, Alibaba.
И здесь становятся востребованными эффективные инструменты, готовые работать в production.
С 2017 года я условно выделяю третий этап.

С этого момента Node.js развивается уже качественно. Здесь стоит отметить полноценный переход на Turbofan и развитие Async Hooks.
В 2015 году мы вышли в релиз на версии Node.js 0.12 и постепенно обновлялись сначала до четвертой версии и впоследствии — до шестой. Сейчас мы планируем переход на восьмую версию.
В релизный год мы использовали инструменты из первого этапа, которые были малофункциональными для работы в production. У нас хороший опыт работы с инструментами второго этапа, и сейчас мы пользуемся инструментами третьего этапа. Но с переходом на новые версии Node.js мы столкнулись с тем, что теряем поддержку полезных нам инструментов. По сути мы встали перед выбором. Либо мы переходим на новую версию Node.js, которая является более оптимизированной и быстрой, чем предыдущая, но у нас нет инструментов, и мы не можем ее диагностировать. Либо мы остаемся на старой версии Node.js, которая работает медленнее, но у нас к ней есть инструменты, и мы знаем ее слабые места. Либо есть третий вариант, когда появляются новые инструменты, а они поддерживают, например, Node v4 и выше, а предыдущие — нет.
Наше приложение — это крупный e-commerce проект, где Node.js-приложения (это Web UI backend и Node.js-микросервисы) занимают центральное место в enterprise-архитектуре.

Проблема в этом месте может прийти с любой стороны. В дни повышенных нагрузок, типа Black Friday, когда компания за несколько дней зарабатывает 60% от годовой прибыли, особенно важно поддерживать высокую пропускную способность. Если случается какая-то неисправность, собирается локальный консилиум, где присутствуют все руководители систем, в том числе и я от Node.js. Если проблема на стороне Node.js, необходимо максимально быстро выбрать стратегию, подобрать под нее инструменты и устранить неисправность, поскольку компания теряет тысячи долларов в минуту.

Ниже я хотел бы на конкретных примерах показать, как мы в production поступаем в случаях ошибок, утечек памяти и спада производительности.
Отладка приложений в production
Существует несколько посылов для отладки в production.

Рассмотрим простой пример: некий сервис для резервирования продуктов. Controller использует service, который отправляет коллекцию продуктов на REST API, возвращает данные, и в controller падает ошибка.


На картинке вы видите листинг ProductController. В методе reserve мы получаем profile из cookies, также берем rewards аккаунт, где хранятся бонусные баллы, id и другая полезная информация, также из cookies. И эта cookies отсутствует — undefined. В случае, когда id берется из rewards, падает ошибка. Локально мы бы поставили breakpoint (красная точка), получили состояние всех объектов и узнали причину, почему у нас падает код.

Я покажу, как это работает под капотом, чтобы вы поняли, что такое Stack Trace. Если написать команду %DebugTrace() — нативная команда V8 и запустить Node.js с опцией --allow-natives-syntax, то есть разрешить нативный синтаксис в V8, то получим большое сообщение с Stack Trace.
В самом верху во втором фрейме у нас будет находиться функция reserve до метода контроллера, и мы увидим там ссылку на контекст ProductController — this, параметры request, response, получим локальные переменные, часть которых хранится в стеке, а другая — в Heap (управляемая куча). Также у нас есть исходный код, и хорошо было бы иметь что-то подобное в production при отладке, чтобы получать состояние объектов.

Такую поддержку реализовали в 2015 году с версии 0.12. Если мы запустим Node c флагом --abort-on-uncaught-exception, создастся core dump — это слепок памяти всего процесса, который содержит Stack Trace и Heap Dump.
Для тех, кто забыл, напомню: память условно состоит из Call Stack и Heap.

В Call Stack желтые кирпичики — это фреймы. В них находятся функции, а функция содержит в себе входные параметры, локальные переменные и адрес возврата. А все объекты, кроме small integer (SMI), хранятся в управляемой куче, на что есть адреса.
Мы разобрались, из чего состоит core dump, теперь перейдем к процессу его создания.

Тут все просто: выполняется процесс вашего приложения, происходит ошибка, процесс падает, создается core dump, потом приложение перезапускается. Далее вы удаленно подключаетесь к production или вытаскиваете к себе на локальный компьютер этот core dump, отлаживаете его отладчиком, делаете hot-fix и публикуете. Теперь, когда мы поняли, как выглядит этот процесс, необходимо узнать, какие дебаггеры можно использовать.

Все они появились до самой Node.js. Для того, чтобы читать JS Stack Trace, в разное время к ним написали несколько плагинов. Большинство из них уже устарело и не поддерживается последней версией Node.js. Я перепробовал практически все и в этом докладе хочу выделить llnode. Он кроссплатформенный (кроме Windows), работает с последними версиями Node.js, начиная с четвертой. Я покажу, как можно использовать этот дебаггер, чтобы отлаживать ошибки в production.
Рассмотрим описанный выше пример — резервирование продуктов.

Настраиваем среду, устанавливаем возможность создания core dump и запускаем наше Node-приложение с флагом --abort-on-uncaught-exception. Далее получаем process pid, делаем запрос пользователю, у которого отсутствует cookies reward, и получаем сообщение, что ошибка появилась в ProductController в методе reserve.

Далее получаем сообщение, что был создан core dump — слепок памяти. Получив core dump или доступ к нему, мы проверяем его наличие — он весит 1,3 ГБ. Немало.

Запустив данный core dump отладчиком при помощи команды llnode, мы можем получить Stack Trace при помощи команды bt.

На изображении видно (выше и ниже — более подробно), что в фреймах с 4 по 20 никакой информации нет.

Дело в том, что это JS Stack Trace, который C++ дебаггеры читать не умеют. Для того, чтобы его прочитать, как раз используется плагин.

Запустив команду V8 bt, мы получим JS Stack Trace, где в шестом фрейме увидим функцию reserve. В фрейме присутствует ссылка на контекст this ProductController, параметры: IncomingMessage — Request, ServerResponse и голубым выделен адрес функции в памяти. По этому адресу мы можем получить ее исходный код из core dump.
Далее мы пишем команду v8 inspect --print-source [адрес] и получаем из памяти исходный код нашей функции.

Вернемся к Stack Trace, там были параметры request и response, и узнаем, что было в request.

На изображении мы видим команду v8 inspect с указанием адреса. После того, как она выполнится, мы получим состояние объекта request. Здесь нас интересует свойство cookies, url, метод POST и body. Узнаем, какие продукты были переданы на сервер.
Пропишем команду v8 inspect [адрес body].

Получаем объект, в котором массив состоит из трех элементов в свойстве products. Берем его адрес, инспектируем и получаем массив из id.

Здесь проблемы нет. Посмотрим, что же было в объекте req.cookies.

Это объект из двух свойств: profile и rewards — undefined. Узнаем, у какого пользователя отсутствует rewards-аккаунт.

Пропишем команду v8 inspect [адрес profile] и получим его id и storeid. Таким образом нам удалось в production без исходного кода получить source code и восстановить сессию пользователя.
Здесь был очень удобный случай, а если вы используете фреймворк, который содержит в себе ErrorHandler Middleware, то в отличие от предыдущего примера, где у нас были ссылки из Stack Trace на контекст this, request, response, если ErrorHandler не переписывать, то у вас в Stack Trace будут последние вызовы самого Express и не с чем будет работать. У вас не будет ссылок.

Я приведу пример, как это происходит.

Тот же самый пример с методом reserve, но уже ошибка падает глубоко в сервисе, который работает в асинхронном режиме. Для того, чтобы ее отловить, подпишемся на события процесса unhadledRejection, где мы делаем process.abort(), чтобы создать core dump.

Ниже показано, как выглядит в этом случае backtrace.

Нет никакой информации о ProductController, о reserve. В этом фрейме есть вызов process.on и больше ничего полезного. Такие случае бывают в production, когда ошибка не была перехвачена и в Stack Trace никакой информации нет. Дальше я покажу, как, работая только с управляемой кучей без Stack Trace, найти все объекты.
Мы можем получить все экземпляры объекта по типу IncomingMessage. Это будет большой список всех request, которые были переданы, но нам нужно найти тот единственный, вследствие которого упал процесс.

В данном случае нам потребуются логи, и в них нам необходимо получить request id — это X-Transaction-ID.

В llnode есть возможность в памяти по значению строки найти ссылки, которые ссылаются на нее. Если мы напишем команду v8 findrefs --string [значение строки], то найдем объект, у которого есть свойство X-Transaction-ID, и он ссылается на эту строку. Выясним, что это за объект.

Напишем команду v8 inspect [адрес], после чего получим объект headers. Далее узнаем, что же ссылается на этот объект, и мы получаем объект IncommingMessage. Таким образом, не имея Stack Trace и адресов, мы смогли восстановить сессию пользователя.

Давайте углубимся в более сложный пример, когда вам необходимо получить локальные переменные — они находятся в сервисах.

Предположим, что ошибка упала где-то глубоко и полученных данных мало. В данном случае используется REST API. Из базы данных берутся объекты, и все они присваиваются некоторой локальной переменной, которая называется someLocalValue. И у нас нет объекта, который ссылается на someLocalValue. Как в таком случае получить локальную переменную из памяти? Можно найти этот объект, например, по значению id, если вы его получили из логов, но также можно получить объекты из памяти по названию его свойств, т. е. с командой v8 findrefs name мы можем найти объекты, которые имеют свойство userAccount, preferredStore, и таким образом мы получим необходимые нам локальные переменные!
Итак, возьмемся за реальный кейс — ошибки в production.

На каждую ошибку мы создаем core dump. Но что здесь не так? Ошибок очень много — 3620 за минуту, а core dump весит 1,3 ГБ, и время, которое требуется для того, чтобы его создать и слить на систему, — порядка 15-20 секунд. Здесь явно не хватает логики, которая будет селектировать создание core dump.
Например, у вас выполняется приложение и возникает ошибка, или вы отловили ошибку, которую вам сложно воспроизвести. Далее процесс попадает в ErrorHandler, где у вас есть логика — необходимо ли для этой ошибки делать process.abort, чтобы создать core dump, либо мы продолжаем выполнение программы.
Если ошибка уникальна и ее нужно обработать, при помощи node-report создается отчет, далее вызывается process.abort и создается core dump, и процесс перезапускается. Ваш сервер опять работает, обслуживает трафик, и уже позже вы получаете доступ к отчету, core dump и логи, далее с помощью отладчика отлаживаете, делаете hotfix и публикуете.

Ниже на изображении приведен пример логики, которая делает селекцию. Я называю это реестром ошибок. Он ограничивает создание core dump.

Это некоторый класс, который использует у себя In-Memory Databases, и когда вы находите ошибку, проверяете, зарегистрирована ли она в реестре или нет. Если нет, то смотрите, нужно ли ее регистрировать. Если да, то сбрасываете процесс, создаете core dump. В таком случае вы не будете создавать core dump на ошибки, которые повторяются. Вы будете их селектировать. Это ускорит процесс отладки.

Я считаю, что процесс отладки в production — это некое детективное расследование, где node-report скажет, что произошло, где и при каких обстоятельствах было совершено преступление против вашего процесса по JS Stack Trace. Логи дадут вам зацепки, улики, ценную информацию. Отладчик позволит найти объекты, которые имели место быть в момент преступления, то есть в этих функциях.
Вот таким образом мы работаем в production и отлаживаем ошибки.
Поиск утечек памяти
Перейдем к поиску утечек памяти.

Существует множество способов определения утечек памяти (некоторые упомянуты на изображении выше).

Например, в графиках нагрузки процессора и памяти можно заметить определенную корреляцию. И в ситуациях, когда у вас есть утечка памяти, нагружается сборщик мусора, который забирает больше процессорного времени.
Рассмотрим пример утечки.

На изображении выше показан график работы сборщика мусора. Scavenge — работает в пространстве молодых объектов. MarkSweep — в пространстве старых объектов. На графике видно, что количество сборок мусора растет, значит, память утекает и необходима более частая сборка мусора. Чтобы понять, где и в каком из пространств она утекает, мы используем трассировку работы сборщика мусора.

На изображении выше виден список областей памяти, который отображает их состояния при каждой итерации сборки мусора. Там есть old space, new space и другие. Когда мы получали source code из core dump, мы брали его из code space.

Из опыта я могу сказать, что если память утекает в пространстве новых объектов, то виноваты в этом дорогостоящие операции клонирования, merge и так далее. Если память течет в большом пространстве старых объектов, то это упущенные замыкания, таймеры. А если память утекает в пространстве large space, где не работает сборщик мусора, то это сериализация/десериализация больших JSON.
Ниже на изображении приведен пример трассировки Scavenge, которая работает в области молодых объектов. Тут нет утечки памяти.

Как это можно выяснить? У нас два столбика, выделенные жирным зеленым шрифтом. Эта память, которая была выделена под ваш процесс до сборки и после сборки. Значения равны, и это говорит о том, что после сборки мусора выделенная память не увеличилась. Синим шрифтом выделено время, потраченное на сборку мусора. В документации указано, что на это требуется 1 миллисекунда по умолчанию. У нас в проекте это порядка 3 секунд, и мы считаем это нормой. На верхнем изображении внизу видны три строчки, это тоже сборка мусора, но уже итеративная, то есть у вас сканируется и очищается не вся память, а по кусочкам. Там также видно количество итераций.
Ниже на изображении пример утечки памяти в том же самом пространстве. В сиреневых столбцах видно, что объем занимаемой памяти растет, то есть после сборки мусора он каждый раз увеличивается.

Как же обстоят дела в пространстве старых объектов?

Здесь мы видим, что процесс выполняется дольше: 90 мс, 110 мс и т. д. Это очень много. Более того, он выполняется еще итеративно, что тоже требует времени в фоновом потоке.
Под капотом Node.js имеет несколько потоков. Один — для профилирования, несколько — для сборки мусора и поток для выполнения самого приложения.
Рассмотрим пример ниже, чтобы понять, как выявить утечки памяти.

Заметьте, Middleware, который обрабатывает request, фиксирует время старта выполнения в начале, и когда request закончился, он фиксирует время после выполнения, где вызывается некоторая функция для его процессинга — someProcessOperation. В эту функцию мы передаем request. Здесь присутствует замыкание. Объект request удержан после его отправки. А на него еще могут быть другие ссылки, что тянет за собой множество объектов. Что нужно делать в таком случае? Нам не нужен весь объект request. Мы можем передать только его id и url. Таким образом мы избежим утечки памяти.

Как можно это выяснить?

Я покажу, как мы делаем это с дебаггером llnode (в случае Fatall Error, когда после краха приложения из-за нехватки памяти Node.js создаст coredump). В предыдущем случае мы получали core dump, когда у нас падал exception и процесс завершался. В этот раз мы, разумеется, не стали вызывать process.abort() на работающем приложении, чтобы получить core dump, а вооружились инструментом gcore, который позволяет на уровне инфраструктуры сделать запрос на process id и получить core dump по требованию. Однако тут мы столкнулись с инфраструктурным ограничением, из-за чего пришлось искать другие варианты.
Месяц назад была опубликована библиотека, которая называется gen-core. Данный инструмент позволяет сделать форк вашего процесса, убить его, не нанеся вреда вашему основному процессу, и получить core dump.
Ниже на изображении приведен пример работы gen-core.

Здесь DiagnosticController по REST API сможет сделать core dump.
Как искать утечки памяти, используя llnode

У нас есть команда findjsobjects, при помощи которой мы можем просканировать всю кучу и сделать группировку по типам, получить отчет о количестве экземпляров объекта каждого типа, о их размере в памяти и т. д. На изображении выше видно, что экземпляров ServerResponse и IncomingMessage достаточно много, также есть объекты Timeout и String. Строки сами по себе очень большие и занимают много памяти. Зачастую они находятся в пространстве large space, где не работает сборщик мусора.
Давайте выясним, почему у нас много объектов request. Помним, что объект request был удержан в Middleware.
Есть команда findjsinstances [тип], и с ее помощью мы получаем список объектов request.

Берем адрес первого объекта и при помощи команды v8 findrefs -v ищем в памяти объект, который имеет ссылку на него.

Это два объекта. Первый — массив из 18 элементов, а второй — это объект request. Узнаем, что это за массив и почему он удерживает наши объекты request.

Используем команду v8 findrefs -v [адрес этого массива] и получаем, что этот массив находится в объекте типа Profiller и свойстве processingQueue. Таким образом мы смогли узнать, где в памяти удерживают наши объекты request. Дальше мы идем в source code или получаем его оттуда и смотрим, где вызывается processingQueue.

Мы используем команду findjsinstances [ тип Timeout ], получаем список всех таймаутов и далее будем искать, где они используются.

При помощи команды v8 i получаем первый таймаут.
В свойстве onTimeout мы можем увидеть, что вызывается функция setInterval и адрес с местом расположения файла. Таким образом мы быстро узнали, где у нас забытый таймер и почему он выполняется.

Как выявить утечку памяти на этапе проектирования приложения
Если использовать команду %DebugTrackRetainingPath(x), которая добавлена была совсем недавно в V8 (в Node.js еще нет ее поддержки), скачать исходники V8, собрать и использовать дебаггер V8 и запустить приведенный выше на изображении JS, то мы получим ссылки любой нужной нам переменной до объекта root. Не стоит забывать и о вызове сборщика мусора. В примере это вызов gc().

Мы запускаем debug8 с флагами --allow-natives-syntax, --track-retaining-path, --expose-gc и файлом test.js. В листинге мы получаем пошагово, кто и что удерживает объект до root.
Таким образом, мы разобрали поиск утечек памяти в production.
Профилирование производительности приложения

На изображении выше вы видите реальный пример, когда после очередного релиза мы просели по производительности в пять раз. Очень сильно выросло время отдачи Web UI приложения.
Для таких случаев есть простой и эффективный алгоритм действий, который продемонстрирован ниже.

Хотя в 2013 году в Node.js был добавлен профайлер, tick-processor (инструмент, который обрабатывает логи V8 и делает отчет) появился там только в прошлом году. До этого мы использовали либо профайлер V8, который имел tick-processor у себя, либо приходилось скачивать сам V8, собирать, и там в инструментах активировать этот процессор.
Профайлер дает вам информацию на высоком уровне, он поможет определить природу проблемы и увидеть, какие функции выполнялись дольше всего.

Существует удобное представление данных этого лога в графическом виде, и оно называется flame graph. Разработал его в 2013 году Брендан Грегг.
Кто помнит, в 2015 году получение графа было настоящей головной болью, но сейчас он создается одной командой с помощью 0x.

Теперь разберемся, как с ним работать.
Чтобы выделить профайл нашего приложения, нижними кнопками уберем все лишнее. В итоге мы видим, что работа приложения занимает лишь небольшую часть от всего времени выполнения.

Stack Trace последовательности вызова функции конечна и умещается на экране. Что же тогда выполняется долго? Если мы включим подсветку работы npm-пакетов, то увидим, что они выполняются в девять раз дольше, чем само приложение. Это очень много.

Если мы подсветим оптимизированные функции, то увидим, что их очень мало. Около 90% вызовов были не оптимизированы.

Если мы глянем на верхушки вызовов, то увидим, что в нашем приложении очень много стека было в handlebars, кроме того у нас был lodash merge, который делал merge объектов, у нас были сторонние утилиты, которые также требовали времени.

Если мы разберем тот же граф нашего приложения, то увидим, что в основе фундамента находится нативный промис, который до Турбофана выполнялся долго. Но больше всего по времени занимает рендеринг страниц. Наше приложение в процентном соотношении — это десятая часть всей логики.

Что мы исправили?
- Уменьшение CPU затратных операций: merge, JSON, string parse
- Удаление логики из view templates
- Ревью npm-зависимостей и обновление пакетов
- Обновление Node.js (обход V8 optimization killers) — в процессе
Ниже представлен граф, который мы видим уже после внесенных исправлений.

Здесь стоит обратить внимание на правую часть, где handlebars helpers. Ранее отрисовка view занимала больше половины графа, а сейчас — одну десятую. Мы достаточно хорошо все оптимизировали, и теперь работа самого приложения занимает примерно половину всего времени. Это не значит, что оно стало работать дольше,- это все другие процессы стали работать меньше по времени.

На изображении сверху видно, что на этапе до выхода критического релиза график рос, и мы понемногу теряли в производительности. Потом произошел резкий скачок. В критическом периоде мы были 3,5 недели и искали недочеты, вносили изменения.
Суть проблемы была в том, что ошибка (парсинг строк JSON) была заложена в приложении задолго до этого релиза, и выстрелила лишь в определенный момент. В итоге после всех исправлений и оптимизаций мы выиграли в производительности в два раза, если за точку отсчета брать первоначальный уровень.
Вывод
- Производительность должна быть частью требований
- Нужно производить замеры при внедрении сторонних библиотек
- Замер стоит производить на staging/pre-production environments
- Нужно собирать архив результатов замеров
Использованные в докладе ресурсы
Если вас заинтересовал этот доклад, вероятно, вам будет интересно и на следующей конференции HolyJS. Вся информация вроде дат проведения — на сайте.
