Здравствуйте уважаемые пользователи Хабра!
Меня зовут Никита, в текущий момент времени я тружусь backend-разработчиком в стартапе мобильного приложения. Наконец у меня появилась действительно нетривиальная и достаточно интересная задача решением которой хочу поделиться с Вами.
О чем собственно пойдет разговор? В разрабатываемом мобильном приложении имеется работа с изображениями. Как можно нетрудно догадаться: где есть картинки, там скорее всего появятся превьюхи. Еще одно условие, практически первая общая задача которая была мне поставлена: сделать чтобы все это работало и масштабировалось в облаке на Амазоне. Если немного лирики: был телефонный разговор со знакомым партнера по бизнесу в режиме громкой связи, где я получил пачку ценных указаний главная мысль которых звучит просто: уходите от серверного мышления. Ну ок, уходим так уходим.
Генерация изображений это достаточно дорогая операция в плане ресурсов. Этот участок бэкэнда предсказуемо плохо показал себя на таком, своего рода «нагрузочном тестировании», которое я проводил на очень дохлой VDS-ке при практически дефолтных настройках LAMP, по крайней мере без дополнительного тюнинга, где все неоптимизированные места вылезут сразу и гарантированно. По этой причине я принял решение данную задачу убрать подальше от пхп-бэкэнда. Пусть он занимается тем что дает более-менее однородную нагрузку, а именно запросы к БД, логика приложения и JSON-ответы и тому подобная малоинтересная API-шная рутина. Те, кто знаком с Амазоном скажут: а в чем проблема? Почему нельзя настроить масштабирование EC2 инстансов в автоматическом режиме и оставить на PHP эту задачу? Отвечаю: «так микросервиснее». А если серьезно — есть масса нюансов в контексте архитектуры бэкэнда, выходящих за пределы данной статьи, по этому оставлю данный вопрос без ответа. Каждый на него ответит сам в контексте своей архитектуры, если он возникнет. Я всего лишь хочу предложить решение и милости прошу под кат.
Вводная: изображения хранятся в условном s3 bucket.mydomain, далее по тексту везде упоминается как bucket. Содержимое bucket считается статическим и общедоступным, но листинг запрещен, по этому каждый объект имеет ACL «public-read», при том что сам bucket non public read, файловая структура внутри bucket имеет вид folder/subfolder/filename.ext.
Данная статья не описывает полностью архитектуру файловой работы бэкэнда, здесь описывается лишь часть (упрощено) на примере с превью для фотографии. Остальные участки работы бэкэнда с файловой системой выходят за пределы данной статьи.
Я сторонник решений когда картинка нужного размера предварительно сгенерирована и просто отдается с файловой системы. Хотя был опыт наложения watermark`ов динамически, (т.е. изображение по-новой генерировалось всегда) который показал достаточно неплохие результаты (я ожидал большей нагрузки чем оказалось). Не стоит прям сильно бояться делать их динамически, в такой подход тоже имеет право на жизнь, но в целом считаю самым оптимальным решением считаю когда превью генерируется 1 раз по какому-то событию и далее отдается из файловой системы, если оно там присутствует, в случае если нет — производится попытка его сгенерировать снова. Это дает достаточно неплохую управляемость и может быть полезено если вдруг изменились требования к размерам превью. Данный подход и был реализован в текущей задаче. Но тут есть один важный момент — необходимо «договориться» (возможно с самим собой) о uri-схеме. В моем случае (опять же повторюсь упрощенно) это выглядит так:
Появилось новое слово preset, что это? В процессе реализации я подумал, а если парсить второй сегмент uri на предмет ширины/высоты то это получается можно самому себе вырыть яму. А что будет если какой нибудь умник захочет от 1 до over9000 перебрать значения второго сегмента uri? По этому договорился с остальными участниками процесса разработки на тему какого размера нужны превьюшки. Получилось несколько «пресетов» разного размера имя которого передается в качестве второго сегмента uri. Опять же возвращаясь к вопросу управляемости, в случае если по какой-то причине понадобится изменить размер превью, достаточно будет поправить переменные окружения в prewmanager, о котором пойдет речь чуть позже и удалить неактуальные файлы с файловой системы.
В общем виде схема работы выглядит как на рисунке:
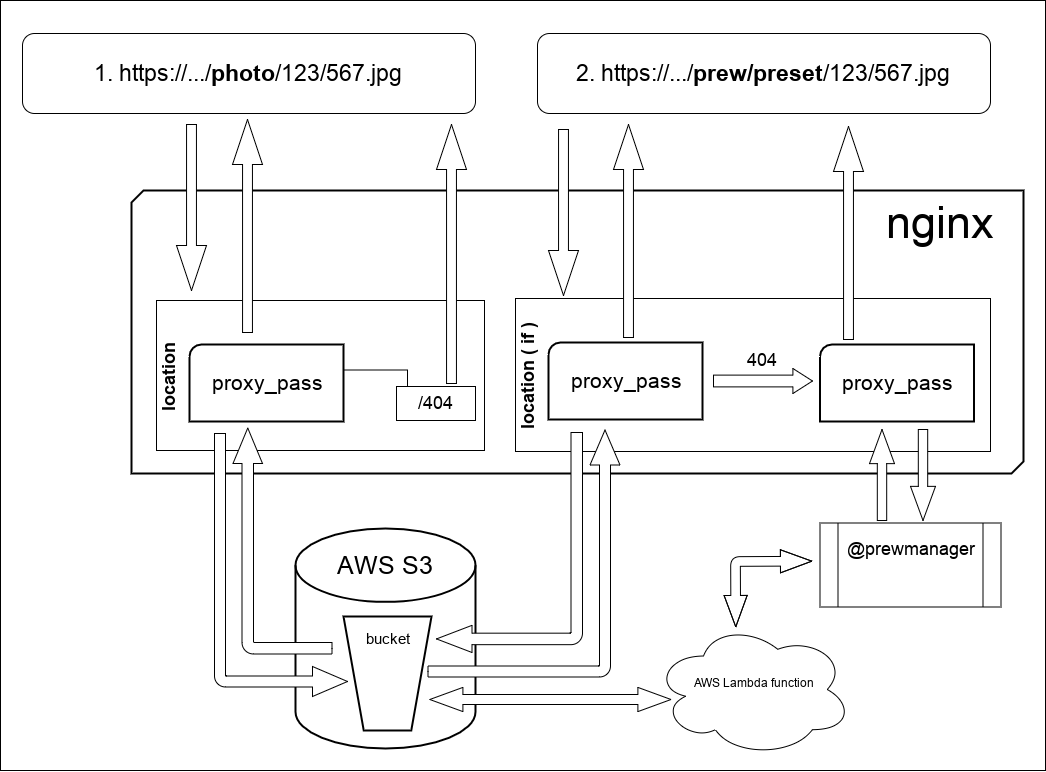
Что здесь происходит:
В запросе 1, который /photo/ nginx проксирует запрос на s3. В принципе он то же самое делает и в запросе 2 поскольку сами файлы и превью хранятся в одном bucket т.к. следуя официальной документации по AWS, количество объектов внутри bucket неограничено. Но есть одно отличие, на схеме указан if. Занимается он тем, что меняет способ обработки 403/404 ответа от s3. Кстати про 403 ответ. Дело все в том, что если обращаться к хранилищу БЕЗ credentials (мой случай) т.е. фактически имея доступ ТОЛЬКО к public-read объектам, то из-за отсутствия права на листинг (амазон вместо 404 отдаст 403, этим обусловлена запись в конфиге: error_page 403 404 =404 /404.jpg; Кусок конфига где описывается данная работа выглядит вот так:
Как вы могли заметить prewmanager-е проксируется на какой-то сетевой сервис. Вот в нем и есть вся соль данной статьи. Этот сервис, написан на nodejs, он запускает aws lambda, написанную на go, «блокирует» дальнейшие вызовы для обрабатываемого uri до завершения работы lambda-функции и отдает результат работы aws lambda всем ожидающим. К сожалению целиком код prewmanager-а привести не могу, по этому попробую проиллюстрировать отдельными участками (уж простите) первой полнофункциональной версии скрипта. В продакшене более красивая версия, но увы. Однако тем не менее в качестве «понять логику работы» и возможно использовать как скетч этот код на мой взгляд вполне сгодится.
Откуда взялся редис и зачем? В этой задаче я так рассудил: поскольку мы в облаке где инстансы с редисом я могу масштабировать сколь душе угодно с одной стороны, а с другой когда встал вопрос о блокировке повторных вызовов функции с теми же параметрами ну что если не редис, который к тому же уже используется в проекте? Локально держать в памяти и писать наколеночный «гарбадж коллектор»? Зачем когда можно просто сунуть эти данные (или флаг блокировки в редис) с определенным временем жизни и обо всем этом позаботится этот замечательный инструмент. Ну логично-же.
Ну и напоследок приведу целиком код функции для AWS Lambda который был написан на Go. Прошу больно не пинать поскольку это третий бинарь после «hello world» и еще там по-мелочи, который был мной написан и скомпилирован. Вот ссылка на гитхаб где он выложен, прошу пулл-реквесты если что-то не так. Но в целом все работает, но как говорится нет предела совершенству. Для работы функции необходим JSON-payload, если поступят просьбы, добавлю на гитхаб инструкцию как тестировать функцию, пример JSON-payload`a и т.д.
Пару слов о настройке AWS Lambda: там все просто. Создать функцию, прописать enviroment-ы, максимальное время и выделение памяти. Залить архив и пользоваться. Но есть нюанс, который выходит за рамки данной статьи: IAM имя ему. Пользователя, роль, права тоже придется настроить, без этого боюсь ничего не выйдет.
В заключение хочу сказать что данная система уже протестирована в продакшен, правда хайлоадными нагрузками похвастаться не могу, но в целом вообще никаких проблем не было. В контексте текущей политической ситуации: да мы одни из первых попали под блокировку Амазона. Буквально в первый же день. Но шум поднимать не стали и отвлекать от работы юристов, а настроили nginx на российском хостинге. Вообще я считаю что Amazon s3 это настолько удобное, хорошо документированное и поддерживаемое хранилище, что из-за лысыхиз браззерс советников по мемасам и прочих хирургов-нехирургов отказываться от него как минимум не стоит. И вот приведенный выше конфиг nginx, поскольку вся статика у меня на поддомене размещена, почти строчка в строчку с минимальными изменениями был перенесен на сервер в РФ и втечение рабочего дня все об этом и забыли.
Всех благодарю за внимание.
Меня зовут Никита, в текущий момент времени я тружусь backend-разработчиком в стартапе мобильного приложения. Наконец у меня появилась действительно нетривиальная и достаточно интересная задача решением которой хочу поделиться с Вами.
О чем собственно пойдет разговор? В разрабатываемом мобильном приложении имеется работа с изображениями. Как можно нетрудно догадаться: где есть картинки, там скорее всего появятся превьюхи. Еще одно условие, практически первая общая задача которая была мне поставлена: сделать чтобы все это работало и масштабировалось в облаке на Амазоне. Если немного лирики: был телефонный разговор со знакомым партнера по бизнесу в режиме громкой связи, где я получил пачку ценных указаний главная мысль которых звучит просто: уходите от серверного мышления. Ну ок, уходим так уходим.
Генерация изображений это достаточно дорогая операция в плане ресурсов. Этот участок бэкэнда предсказуемо плохо показал себя на таком, своего рода «нагрузочном тестировании», которое я проводил на очень дохлой VDS-ке при практически дефолтных настройках LAMP, по крайней мере без дополнительного тюнинга, где все неоптимизированные места вылезут сразу и гарантированно. По этой причине я принял решение данную задачу убрать подальше от пхп-бэкэнда. Пусть он занимается тем что дает более-менее однородную нагрузку, а именно запросы к БД, логика приложения и JSON-ответы и тому подобная малоинтересная API-шная рутина. Те, кто знаком с Амазоном скажут: а в чем проблема? Почему нельзя настроить масштабирование EC2 инстансов в автоматическом режиме и оставить на PHP эту задачу? Отвечаю: «так микросервиснее». А если серьезно — есть масса нюансов в контексте архитектуры бэкэнда, выходящих за пределы данной статьи, по этому оставлю данный вопрос без ответа. Каждый на него ответит сам в контексте своей архитектуры, если он возникнет. Я всего лишь хочу предложить решение и милости прошу под кат.
Вводная: изображения хранятся в условном s3 bucket.mydomain, далее по тексту везде упоминается как bucket. Содержимое bucket считается статическим и общедоступным, но листинг запрещен, по этому каждый объект имеет ACL «public-read», при том что сам bucket non public read, файловая структура внутри bucket имеет вид folder/subfolder/filename.ext.
Данная статья не описывает полностью архитектуру файловой работы бэкэнда, здесь описывается лишь часть (упрощено) на примере с превью для фотографии. Остальные участки работы бэкэнда с файловой системой выходят за пределы данной статьи.
Я сторонник решений когда картинка нужного размера предварительно сгенерирована и просто отдается с файловой системы. Хотя был опыт наложения watermark`ов динамически, (т.е. изображение по-новой генерировалось всегда) который показал достаточно неплохие результаты (я ожидал большей нагрузки чем оказалось). Не стоит прям сильно бояться делать их динамически, в такой подход тоже имеет право на жизнь, но в целом считаю самым оптимальным решением считаю когда превью генерируется 1 раз по какому-то событию и далее отдается из файловой системы, если оно там присутствует, в случае если нет — производится попытка его сгенерировать снова. Это дает достаточно неплохую управляемость и может быть полезено если вдруг изменились требования к размерам превью. Данный подход и был реализован в текущей задаче. Но тут есть один важный момент — необходимо «договориться» (возможно с самим собой) о uri-схеме. В моем случае (опять же повторюсь упрощенно) это выглядит так:
- /photo/some/file.jpg — отдать исходный файл
- /prew/preset/some/file.jpg — отдать превью для file.jpg
Появилось новое слово preset, что это? В процессе реализации я подумал, а если парсить второй сегмент uri на предмет ширины/высоты то это получается можно самому себе вырыть яму. А что будет если какой нибудь умник захочет от 1 до over9000 перебрать значения второго сегмента uri? По этому договорился с остальными участниками процесса разработки на тему какого размера нужны превьюшки. Получилось несколько «пресетов» разного размера имя которого передается в качестве второго сегмента uri. Опять же возвращаясь к вопросу управляемости, в случае если по какой-то причине понадобится изменить размер превью, достаточно будет поправить переменные окружения в prewmanager, о котором пойдет речь чуть позже и удалить неактуальные файлы с файловой системы.
В общем виде схема работы выглядит как на рисунке:
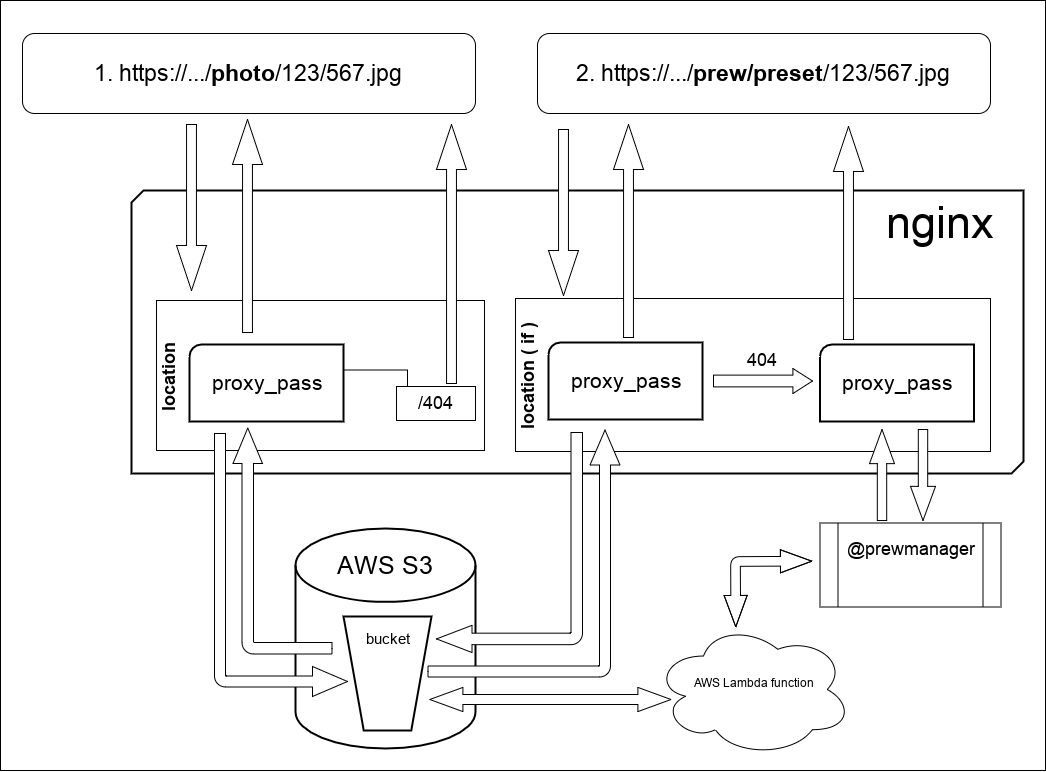
Что здесь происходит:
В запросе 1, который /photo/ nginx проксирует запрос на s3. В принципе он то же самое делает и в запросе 2 поскольку сами файлы и превью хранятся в одном bucket т.к. следуя официальной документации по AWS, количество объектов внутри bucket неограничено. Но есть одно отличие, на схеме указан if. Занимается он тем, что меняет способ обработки 403/404 ответа от s3. Кстати про 403 ответ. Дело все в том, что если обращаться к хранилищу БЕЗ credentials (мой случай) т.е. фактически имея доступ ТОЛЬКО к public-read объектам, то из-за отсутствия права на листинг (амазон вместо 404 отдаст 403, этим обусловлена запись в конфиге: error_page 403 404 =404 /404.jpg; Кусок конфига где описывается данная работа выглядит вот так:
location / {
set $s3_bucket 'bucket.s3.amazonaws.com';
set $req_proxy_str $s3_bucket$1;
error_page 403 404 =404 /404.jpg;
if ($request_uri ~* /prew/(.*)){
error_page 403 404 = @prewmanager;
}
proxy_http_version 1.1;
proxy_set_header Authorization '';
proxy_set_header Host $s3_bucket;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_hide_header x-amz-id-2;
proxy_hide_header x-amz-request-id;
proxy_hide_header Set-Cookie;
proxy_ignore_headers "Set-Cookie";
proxy_buffering off;
proxy_intercept_errors on;
proxy_pass http://$req_proxy_str;
}
location /404.jpg {
root /var/www/error/;
internal;
}
location @prewmanager {
proxy_pass http://prewnamager_host:8180;
proxy_redirect http://prewnamager_host:8180 /;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
access_log off ;
}
Как вы могли заметить prewmanager-е проксируется на какой-то сетевой сервис. Вот в нем и есть вся соль данной статьи. Этот сервис, написан на nodejs, он запускает aws lambda, написанную на go, «блокирует» дальнейшие вызовы для обрабатываемого uri до завершения работы lambda-функции и отдает результат работы aws lambda всем ожидающим. К сожалению целиком код prewmanager-а привести не могу, по этому попробую проиллюстрировать отдельными участками (уж простите) первой полнофункциональной версии скрипта. В продакшене более красивая версия, но увы. Однако тем не менее в качестве «понять логику работы» и возможно использовать как скетч этот код на мой взгляд вполне сгодится.
// тут были requre, process.env.* и т.д.
const lambda = new AWS.Lambda({...});
const rc = redis.createClient(...);
const getAsync = promisify(rc.get).bind(rc);
function make404Response(response) {
// тут берем с файловой системы картинку и отдаем с 404 кодом -- типовая задача
}
function makeErrorResponse(response) {
// аналогично функции выше только картинка другая
}
// AWS Lambda возвращает в base64 данные картинки и content-type
function makeResultResponse(response, response_payload) {
let buff = new Buffer(response_payload.data, 'base64');
response.statusCode = 200;
response.setHeader('Content-Type', response_payload.content_type);
response.end(buff);
return;
}
http.createServer(async function(request, response) {
// тут был разбор uri, генерация строкового ключа для редиса и т.д.
// для redis, если ключа нет (null) значит необходимо запускать работу AWS lambda
// и устанавливаем блокировку чтобы не запускалась функция дважды и более раз на данный запрос
// если ключ есть -- дожидаемся ответа через функцию
let reply = false;
try {
reply = await getAsync(redis_key);
} catch (err) { }
if(reply === null) {
// ставим блокировку на 30 секунд
rc.set(redis_key, 'blocked', 'EX', 30);
// и выполняем операции в ламбде
// пресеты, если требуемого пресета нет -- 404
switch (preset) {
case "preset_name_1":
var request_payload = {
src_key: "photo/" + aws_ob_key,
src_bucket: src_bucket,
dst_bucket: dst_bucket,
root_folder: dst_root,
preset_name: preset,
rewrite_part: "photo",
width: 1440
};
var params = {
FunctionName: "my_lambda_function_name",
InvocationType: "RequestResponse",
LogType: "Tail",
Payload: JSON.stringify(request_payload),
};
lambda.invoke(params, function(err, data) {
if (err) {
makeErrorResponse(response);
} else {
rc.set(redis_key, data.Payload, 'EX', 30);
let response_payload = JSON.parse(data.Payload);
if(response_payload.status == true) {
makeResultResponse(response, response_payload);
} else {
console.log(response_payload.error);
makeErrorResponse(response);
}
}
});
break;
...
default:
make404Response(response);
}
} else if (reply === false) {
// это если редис не отзывается
makeErrorResponse(response);
} else {
// тут в нормальной ситуации возможны 2 варианта
// когда уже запрос выполняется -- blocked
// когда он уже выполнился, т.е. есть данные
if(reply == 'blocked') {
let res;
let i = 0;
const intervalId = setInterval(async function() {
try {
res = await getAsync(redis_key);
} catch (err) { }
if (res != null && res != 'blocked') {
let response_payload = JSON.parse(res);
if(response_payload.status == true) {
makeResultResponse(response, response_payload);
} else {
console.log(response_payload.error);
makeErrorResponse(response);
}
clearInterval(intervalId);
} else {
i++;
// вечно это продолжаться не должно
if(i > 100) {
makeErrorResponse(response);
clearInterval(intervalId);
}
}
}, 500);
}
}
}).listen(port);
Откуда взялся редис и зачем? В этой задаче я так рассудил: поскольку мы в облаке где инстансы с редисом я могу масштабировать сколь душе угодно с одной стороны, а с другой когда встал вопрос о блокировке повторных вызовов функции с теми же параметрами ну что если не редис, который к тому же уже используется в проекте? Локально держать в памяти и писать наколеночный «гарбадж коллектор»? Зачем когда можно просто сунуть эти данные (или флаг блокировки в редис) с определенным временем жизни и обо всем этом позаботится этот замечательный инструмент. Ну логично-же.
Ну и напоследок приведу целиком код функции для AWS Lambda который был написан на Go. Прошу больно не пинать поскольку это третий бинарь после «hello world» и еще там по-мелочи, который был мной написан и скомпилирован. Вот ссылка на гитхаб где он выложен, прошу пулл-реквесты если что-то не так. Но в целом все работает, но как говорится нет предела совершенству. Для работы функции необходим JSON-payload, если поступят просьбы, добавлю на гитхаб инструкцию как тестировать функцию, пример JSON-payload`a и т.д.
Пару слов о настройке AWS Lambda: там все просто. Создать функцию, прописать enviroment-ы, максимальное время и выделение памяти. Залить архив и пользоваться. Но есть нюанс, который выходит за рамки данной статьи: IAM имя ему. Пользователя, роль, права тоже придется настроить, без этого боюсь ничего не выйдет.
В заключение хочу сказать что данная система уже протестирована в продакшен, правда хайлоадными нагрузками похвастаться не могу, но в целом вообще никаких проблем не было. В контексте текущей политической ситуации: да мы одни из первых попали под блокировку Амазона. Буквально в первый же день. Но шум поднимать не стали и отвлекать от работы юристов, а настроили nginx на российском хостинге. Вообще я считаю что Amazon s3 это настолько удобное, хорошо документированное и поддерживаемое хранилище, что из-за лысых
Всех благодарю за внимание.
