
В крупных компаниях есть люди, которые занимаются только тем, что контролируют состояние ИБ и ждут, когда начнутся проблемы. Речь идёт не про охранников перед мониторами, а про выделенных людей (как минимум одного в смене) в отделе информационной безопасности.

Большую часть времени оператор SOC-центра работает с SIEMами. SIEM-системы собирают данные с различных источников по всей сети и совместно с другими решениями сопоставляют события и оценивают угрозу — как индивидуально для каждого пользователя и сервиса, так и в целом для групп пользователей и узлов сети. Как только кто-то начинает себя вести слишком подозрительно, оператору SOC-центра поступает уведомление. Если уровень подозрительности зашкаливает, сначала изолируется подозрительный процесс или рабочее место, а уже потом приходит уведомление. Дальше начинается расследование инцидента.
Очень упрощая, за каждое подозрительное действие пользователь получает штрафные очки. Если действие характерно для него или его коллег — очков мало. Если действие нетипичное — очков много.
Для UBA-систем (User Behaviour Analytics) последовательность действий также имеет значение. По отдельности резкий скачок объёма трафика, подключение к новому IP или копирование данных с файлового сервера случается время от времени. А вот если сначала юзер открыл письмо, потом у него было обращение к только что зарегистрированному домену, а затем он начал шариться по соседним машинам и отправлять странный зашифрованный трафик в Интернет — это уже подозрение в атаке.
Обычно на среднем уровне развития отдела ИБ у типовой компании есть набор систем защиты — файрволы (часто NGFW), потоковые антивирусы, системы защиты от DDoS, DLP-система с агентами на рабочих станциях и так далее. Но всё это редко увязывается в единую информационную сеть, которая сопоставляет события и находит неочевидные корреляции.
«Ещё неопытные» отличаются от «уже опытных» выстроенными процессами работы с постоянно меняющейся инфраструктурой компании. То есть система динамическая, а вся инфраструктура рассматривается как живой организм, растущий и непрерывно развивающийся. Исходя из этой парадигмы и задаются все правила работы, процедуры и регламенты взаимодействия в рамках существующей экосистемы.
Если такого подхода нет, то даже при том, что данные как-то собираются, а инциденты как-то фиксируются, мы часто видим, что ответственные не знают, как реагировать на те или иные ситуации. Знаю, вы сейчас готовы мне не поверить. Но вот недавно был яркий пример. Госкомпания при замене оборудования не успела вовремя накатить правильные конфиги и поймала вирус-шифровальщик. Звонят и спрашивают: «Что делать-то прямо сейчас?» ИТ хочет блокировать полностью, зачистить сегмент сети, переустановив все ОС, ИБ говорит, что там критичные данные и непонятно, до чего дотянулась вирусня, — и не даёт разрешения ничего трогать. Время уходит.
Мы посоветовали изолировать сегмент на межсетевом экране, сделать полный снепшот всех рабочих станций сегмента и передать его нам на форензику. Пока проводится анализ, для зашифрованных станций переустановить ОС с нуля, для остальных — проверить на руткит, запустив антивирус с LiveCD. Затем вернуть станции в сеть, но продолжать пристально мониторить трафик на прокси и NGFW на предмет распространения заразы и провести аудит безопасности для ключевых систем.
В итоге заказчик пересмотрел риски ИБ и переделал всю защиту на нормальную, с централизованным контролем настроек рабочих станций, серверов и сетевого оборудования, централизованной системой контроля запускаемых приложений, контролем целостности ключевых систем и более жёсткими настройками на средствах защиты информации.
Ну, в первую очередь тем, что SIEM-системы реактивны по своей природе. У них есть ключевое преимущество — они связывают и объединяют кучу систем разных вендоров. То есть не надо менять и переделывать всю инфраструктуру с нуля — берёте свои имеющиеся компоненты защиты и ставите поверх них SIEM-систему. Проблема в том, что SIEM-система начинает работать только тогда, когда злоумышленник уже проник в инфраструктуру. Поэтому для эффективного SOC-центра классические SIEM-системы необходимо дополнять системами класса UBA и данными Threat Intelligence, которые позволяют обнаружить злоумышленника ещё на ранних стадиях атаки, в идеале — на этапе подготовки ко взлому.
Через несколько недель обучения UBA-системы, что есть инцидент, а что — обычная повторяющаяся рутина, остаётся порядка десятка основных тревог в день. Допустим, восемь из них требуют быстрого анализа, но заканчиваются банально — это баги, сбои железа, нетипичная, но разрешённая активность пользователей. Ещё одна — ситуация, когда скрипт-кидди пытается прорваться через защиту. И последняя — реальная утечка данных или целенаправленная атака. Такие случаи требуют более детального расследования, в том числе ретроспективного анализа большого объёма данных на глубину порядка нескольких месяцев. Тут SOC-центрам хорошо помогают системы анализа данных, построенные на базе технологий класса Big Data.
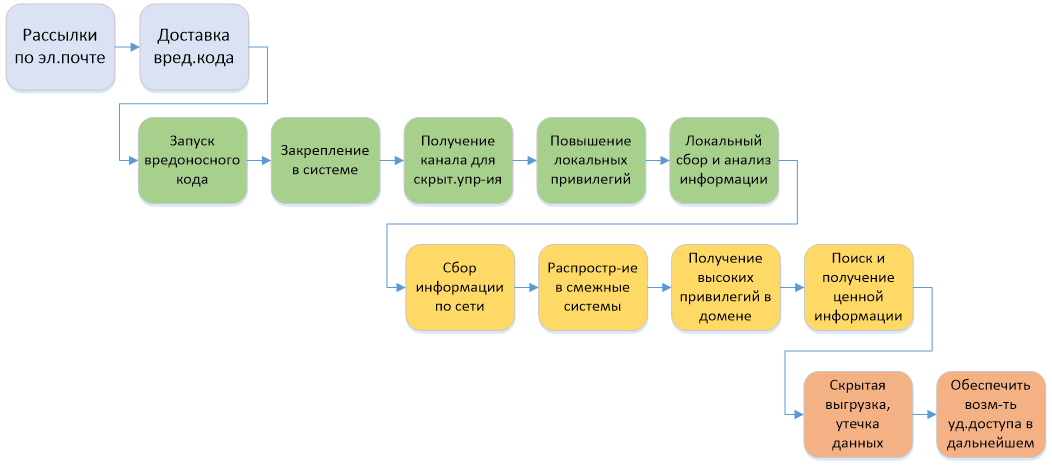
Рисунок 1. Типовой сценарий APT-атаки
SIEM и UBA смотрят, кто и что делал, что изменил и как, чтобы понять, скомпрометирован или нет узел или сотрудник.
Во-вторых, нужны люди, которые занимаются обнаружением и расследованием инцидентов ИБ. Т. е. их задача — не поддержка инфраструктуры, а активное участие в оперативном реагировании на инциденты ИБ. За день на крупную розничную сеть вполне возможна сотня потенциальных инцидентов ИБ. Большая часть — это автоматические атаки на веб-ресурсы или неучтённые взаимодействия с внешними системами, но часть из них вполне реальные внешние APT-атаки и внутренний фрод.
В-третьих, должны быть проработаны регламенты и процедуры взаимодействия различных подразделений в момент атаки, так называемые Play Book, в соответствии с которыми проводится локализация и расследование инцидента ИБ. Во многих ситуациях у SOC-сотрудников должны быть высокие полномочия. Например, они должны иметь право мгновенно приостановить работу продакшена, если идёт массовая утечка данных. В банке рубануть питание в такой ситуации — предел смелости. Но если заранее всё продумать и зафиксировать план действий в регламенте, можно будет выбрать меньшее зло в каждой конкретной ситуации. Всё это делается для того, чтобы как можно раньше обнаружить инцидент и минимизировать потенциальный ущерб.
У нас реализован свой SOC-центр, к которому мы подключили как свою инфраструктуру, так и ряд наших заказчиков. В его основе — SIEM-система, которую мы дополнили нашей собственной разработкой на основе Big Data с машинным обучением для обнаружения аномалий и APT-атак. На первой линии у нас выделенная группа Helpdesk — «универсальные солдаты», которые и базовый траблшутинг проведут, и простые инциденты смогут закрыть. Вторая линия — это аналитики, специалисты ИБ, которых привлекаем к расследованию сложных инцидентов и глубокой форензике. А ещё есть команда пентестеров, которая время от времени проверяет периметр сети на прочность. Все команды общаются друг с другом через HPSM для удобства и поддержки единой базы знаний.
Одна из важнейших фишек систем поведенческого анализа, которые развёртываются в рамках SOC-центров, — это обучение и калибровка. То есть те самые оценки действий пользователей и узлов по шкале потенциальной опасности, формируемые в реальном времени. Если рабочая станция пользователя скомпрометирована, то его поведение в системе будет довольно сильно отличаться от коллег.
Это важно локализовывать на основе типового поведения. Например, если человек работает сетевиком в крупной компании и запускает кучу странных тулз, SIEM увидит, что рядом у него работает ещё пятеро таких же людей — значит, всё норм. А вот если бухгалтер начнёт делать нечто похожее на выкрутасы инженера — тревога будет сразу.
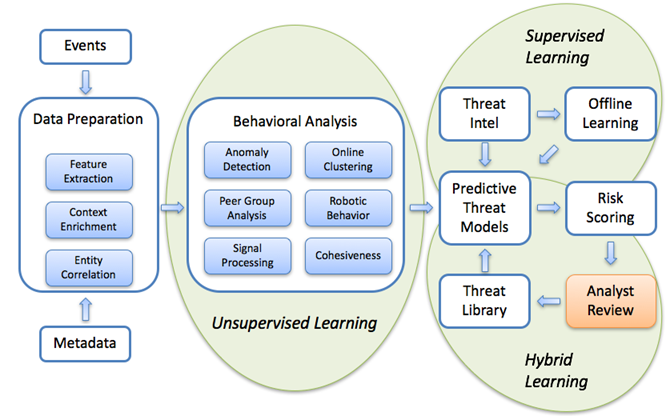
Рисунок 2. Модели машинного обучения для обнаружения аномальной активности в сети
На практике при внедрениях во время калибровок мы находили:
Очень хорошая штука — оценка модели и свёртывание кучи инцидентов до корневой причины. Например, отказ аплинка между дата-центрами — это одна большая проблема, а не сотни мини-отказов рабочих станций, серверов и сетевого оборудования. Операторы должны разбираться, поэтому сделано чаще всего примерно так:
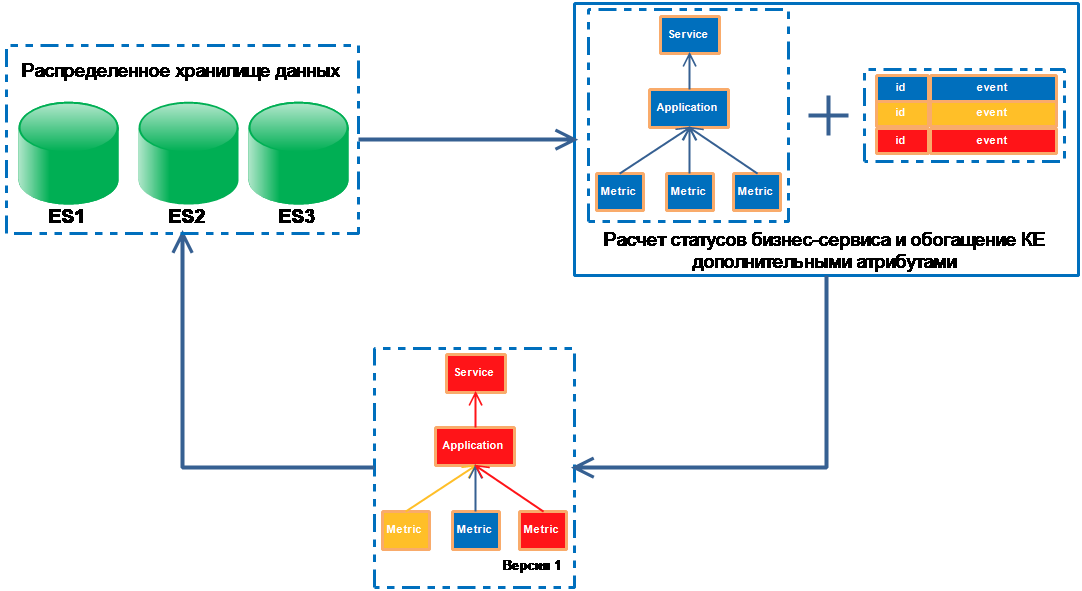
Рисунок 3. Формирование ресурсно-сервисной модели
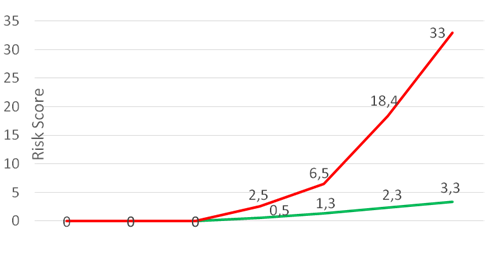
Очень хорошая штука — объединение разрозненных инцидентов в единый киллчейн. Есть ряд стадий, через которые проходит хакер в ходе взлома инфраструктуры, начиная от подготовки к сканированию и заканчивая кражей данных и уничтожением логов. Признаки такой активности можно отслеживать в течение месяцев и заносить в «карточку» пользователя, что даёт возможность операторам быстро выявить «нулевого пациента».
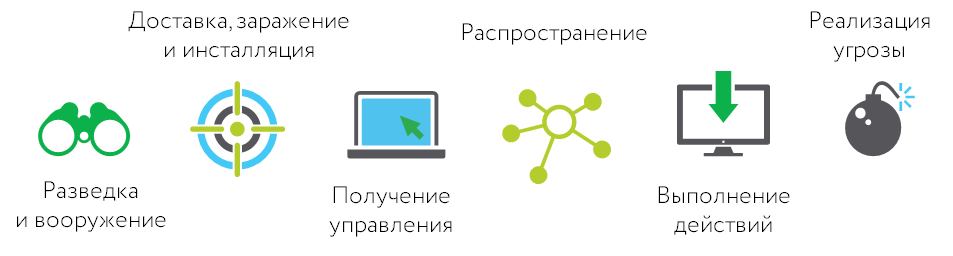
Рисунок 4. Пример киллчейна
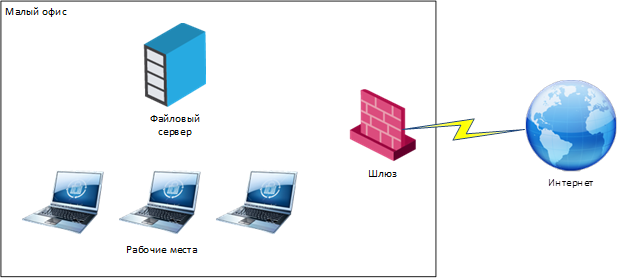
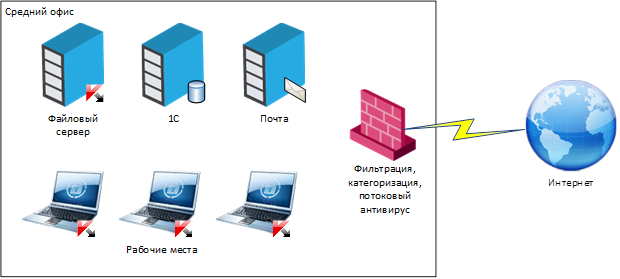
В итоге всё выглядит примерно так:
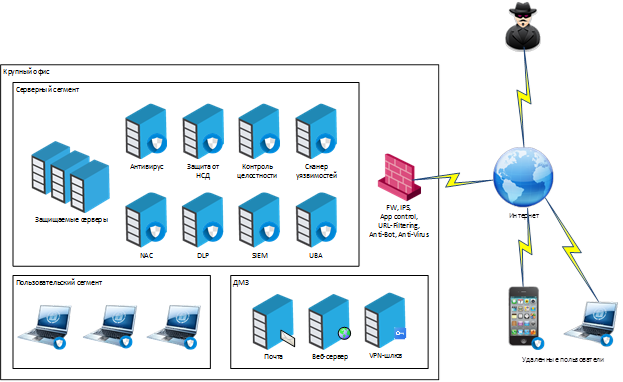
А это пример набора систем защиты, которые связаны между собой в рамках SOC и обмениваются данными через SIEM:

Кстати, если вы начинающий специалист и давно хотите поработать в сфере информационной безопасности, у нас есть кое-что для вас. Мы ищем младшего менеджера по продвижению решений ИБ. Нужно будет разбираться и в актуальных решениях, и в вендорах и их продуктах. Общаться с заказчиками, составлять коммерческие предложения и так далее. В общем, скучно не будет. За подробностями пишите мне на почту.

Большую часть времени оператор SOC-центра работает с SIEMами. SIEM-системы собирают данные с различных источников по всей сети и совместно с другими решениями сопоставляют события и оценивают угрозу — как индивидуально для каждого пользователя и сервиса, так и в целом для групп пользователей и узлов сети. Как только кто-то начинает себя вести слишком подозрительно, оператору SOC-центра поступает уведомление. Если уровень подозрительности зашкаливает, сначала изолируется подозрительный процесс или рабочее место, а уже потом приходит уведомление. Дальше начинается расследование инцидента.
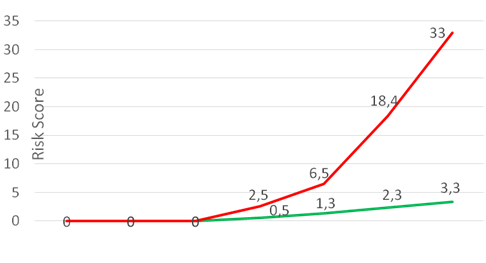
Очень упрощая, за каждое подозрительное действие пользователь получает штрафные очки. Если действие характерно для него или его коллег — очков мало. Если действие нетипичное — очков много.
Для UBA-систем (User Behaviour Analytics) последовательность действий также имеет значение. По отдельности резкий скачок объёма трафика, подключение к новому IP или копирование данных с файлового сервера случается время от времени. А вот если сначала юзер открыл письмо, потом у него было обращение к только что зарегистрированному домену, а затем он начал шариться по соседним машинам и отправлять странный зашифрованный трафик в Интернет — это уже подозрение в атаке.
Как работают с инфобезопасностью обычно?
Обычно на среднем уровне развития отдела ИБ у типовой компании есть набор систем защиты — файрволы (часто NGFW), потоковые антивирусы, системы защиты от DDoS, DLP-система с агентами на рабочих станциях и так далее. Но всё это редко увязывается в единую информационную сеть, которая сопоставляет события и находит неочевидные корреляции.
«Ещё неопытные» отличаются от «уже опытных» выстроенными процессами работы с постоянно меняющейся инфраструктурой компании. То есть система динамическая, а вся инфраструктура рассматривается как живой организм, растущий и непрерывно развивающийся. Исходя из этой парадигмы и задаются все правила работы, процедуры и регламенты взаимодействия в рамках существующей экосистемы.
Если такого подхода нет, то даже при том, что данные как-то собираются, а инциденты как-то фиксируются, мы часто видим, что ответственные не знают, как реагировать на те или иные ситуации. Знаю, вы сейчас готовы мне не поверить. Но вот недавно был яркий пример. Госкомпания при замене оборудования не успела вовремя накатить правильные конфиги и поймала вирус-шифровальщик. Звонят и спрашивают: «Что делать-то прямо сейчас?» ИТ хочет блокировать полностью, зачистить сегмент сети, переустановив все ОС, ИБ говорит, что там критичные данные и непонятно, до чего дотянулась вирусня, — и не даёт разрешения ничего трогать. Время уходит.
Мы посоветовали изолировать сегмент на межсетевом экране, сделать полный снепшот всех рабочих станций сегмента и передать его нам на форензику. Пока проводится анализ, для зашифрованных станций переустановить ОС с нуля, для остальных — проверить на руткит, запустив антивирус с LiveCD. Затем вернуть станции в сеть, но продолжать пристально мониторить трафик на прокси и NGFW на предмет распространения заразы и провести аудит безопасности для ключевых систем.
В итоге заказчик пересмотрел риски ИБ и переделал всю защиту на нормальную, с централизованным контролем настроек рабочих станций, серверов и сетевого оборудования, централизованной системой контроля запускаемых приложений, контролем целостности ключевых систем и более жёсткими настройками на средствах защиты информации.
Чем построение SOC-центра отличается от внедрения SIEM-системы?
Ну, в первую очередь тем, что SIEM-системы реактивны по своей природе. У них есть ключевое преимущество — они связывают и объединяют кучу систем разных вендоров. То есть не надо менять и переделывать всю инфраструктуру с нуля — берёте свои имеющиеся компоненты защиты и ставите поверх них SIEM-систему. Проблема в том, что SIEM-система начинает работать только тогда, когда злоумышленник уже проник в инфраструктуру. Поэтому для эффективного SOC-центра классические SIEM-системы необходимо дополнять системами класса UBA и данными Threat Intelligence, которые позволяют обнаружить злоумышленника ещё на ранних стадиях атаки, в идеале — на этапе подготовки ко взлому.
Через несколько недель обучения UBA-системы, что есть инцидент, а что — обычная повторяющаяся рутина, остаётся порядка десятка основных тревог в день. Допустим, восемь из них требуют быстрого анализа, но заканчиваются банально — это баги, сбои железа, нетипичная, но разрешённая активность пользователей. Ещё одна — ситуация, когда скрипт-кидди пытается прорваться через защиту. И последняя — реальная утечка данных или целенаправленная атака. Такие случаи требуют более детального расследования, в том числе ретроспективного анализа большого объёма данных на глубину порядка нескольких месяцев. Тут SOC-центрам хорошо помогают системы анализа данных, построенные на базе технологий класса Big Data.

Рисунок 1. Типовой сценарий APT-атаки
SIEM и UBA смотрят, кто и что делал, что изменил и как, чтобы понять, скомпрометирован или нет узел или сотрудник.
Во-вторых, нужны люди, которые занимаются обнаружением и расследованием инцидентов ИБ. Т. е. их задача — не поддержка инфраструктуры, а активное участие в оперативном реагировании на инциденты ИБ. За день на крупную розничную сеть вполне возможна сотня потенциальных инцидентов ИБ. Большая часть — это автоматические атаки на веб-ресурсы или неучтённые взаимодействия с внешними системами, но часть из них вполне реальные внешние APT-атаки и внутренний фрод.
В-третьих, должны быть проработаны регламенты и процедуры взаимодействия различных подразделений в момент атаки, так называемые Play Book, в соответствии с которыми проводится локализация и расследование инцидента ИБ. Во многих ситуациях у SOC-сотрудников должны быть высокие полномочия. Например, они должны иметь право мгновенно приостановить работу продакшена, если идёт массовая утечка данных. В банке рубануть питание в такой ситуации — предел смелости. Но если заранее всё продумать и зафиксировать план действий в регламенте, можно будет выбрать меньшее зло в каждой конкретной ситуации. Всё это делается для того, чтобы как можно раньше обнаружить инцидент и минимизировать потенциальный ущерб.
Практика
У нас реализован свой SOC-центр, к которому мы подключили как свою инфраструктуру, так и ряд наших заказчиков. В его основе — SIEM-система, которую мы дополнили нашей собственной разработкой на основе Big Data с машинным обучением для обнаружения аномалий и APT-атак. На первой линии у нас выделенная группа Helpdesk — «универсальные солдаты», которые и базовый траблшутинг проведут, и простые инциденты смогут закрыть. Вторая линия — это аналитики, специалисты ИБ, которых привлекаем к расследованию сложных инцидентов и глубокой форензике. А ещё есть команда пентестеров, которая время от времени проверяет периметр сети на прочность. Все команды общаются друг с другом через HPSM для удобства и поддержки единой базы знаний.
Одна из важнейших фишек систем поведенческого анализа, которые развёртываются в рамках SOC-центров, — это обучение и калибровка. То есть те самые оценки действий пользователей и узлов по шкале потенциальной опасности, формируемые в реальном времени. Если рабочая станция пользователя скомпрометирована, то его поведение в системе будет довольно сильно отличаться от коллег.
Это важно локализовывать на основе типового поведения. Например, если человек работает сетевиком в крупной компании и запускает кучу странных тулз, SIEM увидит, что рядом у него работает ещё пятеро таких же людей — значит, всё норм. А вот если бухгалтер начнёт делать нечто похожее на выкрутасы инженера — тревога будет сразу.
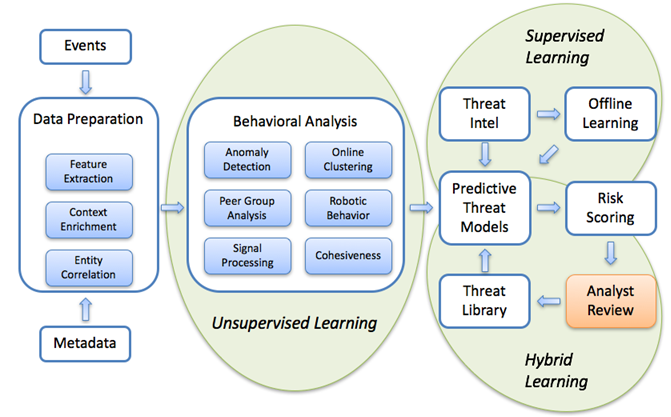
Рисунок 2. Модели машинного обучения для обнаружения аномальной активности в сети
На практике при внедрениях во время калибровок мы находили:
- Тех, кто решил помайнить криптовалюту.
- Нашли неисчислимое количество людей, которые отправляют файлы себе на личную почту. Настроили фильтры автоблокировки — если таких файлов много, почта блокируется.
- Словили пару людей на потенциальной утечке отчёта, но это просто бухгалтерия пришла в движение целиком и система не успела обучиться.
- Заказчик как-то сам спалил первую «боевую» тревогу — https-трафик заворачивался через какой-то странный IP. Оказалось, что финансовый отдел работал с банк-клиентами, которые перенаправляли страницу на внешний ресурс для оценки скомпрометированности браузера, а уже оттуда трафик шёл собственно до банкинга. Выглядело действительно странно, но пообщались с банком, это норма.
- В одном из филиалов крупной компании нашли админа, который ставил «левый» софт себе на рабочую станцию, отключив перед этим половину систем ИБ. А спалили его на том, что он скачал очередной кряк с вирусом и умудрился начать распространять его по внутреннему сегменту сети. Заказчик изолировал сегмент, а мы занимались форензикой.
- Поймали пару товарищей, использующих учётки коллег для своих дел. Коллега в Иркутске, и тут хоп — из офиса работает на своей машине. Непорядок. Или учётка вдруг сгенерила 10 тысяч попыток входа в систему за пару минут — кое-кто написал робота, но при смене паролей забыл скормить ему новую учётку.
- Ну и засекли несколько атак. Типовая выглядит так: сначала пришло письмо с высоким подозрением на спам. Потом пользователь обратился к вебсайту со свежей регистрацией домена. Дальше пауза, всё спокойно. Через 2 недели ночью кто-то удалённо подключился и начал качать данные с файлового сервера. В этот момент был создан инцидент для ручной обработки, через 4 минуты была включена фильтрация только по «белому листу», затем к утру сделали полный разбор полётов. Полная автоматизация не использовалась — она требует осторожности, потому что если есть система, всё блокирующая, то сама атака может пойти на неё.
Ещё пара фишек
Очень хорошая штука — оценка модели и свёртывание кучи инцидентов до корневой причины. Например, отказ аплинка между дата-центрами — это одна большая проблема, а не сотни мини-отказов рабочих станций, серверов и сетевого оборудования. Операторы должны разбираться, поэтому сделано чаще всего примерно так:
- заранее определяются ключевые бизнес-процессы;
- формируется каталог ИТ-сервисов, обеспечивающих работу бизнес-процессов;
- для каждого ИТ-сервиса определяются его основные компоненты: серверы, сетевое оборудование, набор прикладного ПО;
- строится ресурсно-сервисная модель, представляющая из себя иерархический граф, узлами которого являются ключевые компоненты, а рёбрами — связи между ними.

Рисунок 3. Формирование ресурсно-сервисной модели
Очень хорошая штука — объединение разрозненных инцидентов в единый киллчейн. Есть ряд стадий, через которые проходит хакер в ходе взлома инфраструктуры, начиная от подготовки к сканированию и заканчивая кражей данных и уничтожением логов. Признаки такой активности можно отслеживать в течение месяцев и заносить в «карточку» пользователя, что даёт возможность операторам быстро выявить «нулевого пациента».

Рисунок 4. Пример киллчейна
Эволюция системы защиты
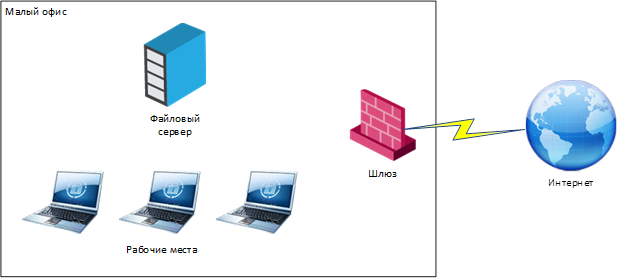
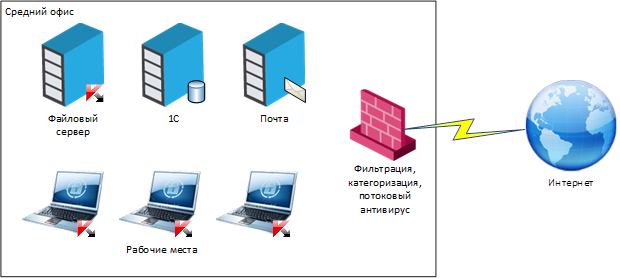
В итоге всё выглядит примерно так:
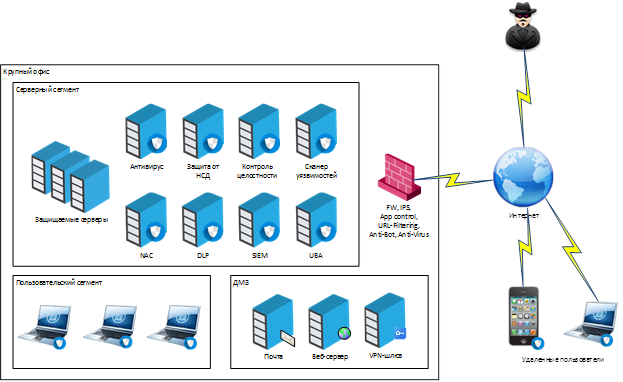
А это пример набора систем защиты, которые связаны между собой в рамках SOC и обмениваются данными через SIEM:

Кстати, если вы начинающий специалист и давно хотите поработать в сфере информационной безопасности, у нас есть кое-что для вас. Мы ищем младшего менеджера по продвижению решений ИБ. Нужно будет разбираться и в актуальных решениях, и в вендорах и их продуктах. Общаться с заказчиками, составлять коммерческие предложения и так далее. В общем, скучно не будет. За подробностями пишите мне на почту.
Ссылки
- Мы нашли крупную компанию, которая 5 лет не занималась информационной безопасностью, и она ещё жива
- Безопасность футбольных стадионов: некоторые неявные особенности
- Микросегментация сетей в примерах: как эта хитро закрученная штука реагирует на разные атаки
- Направленные ИТ-атаки в сфере крупного бизнеса: как это происходит в России
- Моя почта – dberezin@croc.ru
