Привет, Хабр! Представляю вашему вниманию перевод статьи "Animal detection in the jungle — 1TB+ of data, 90%+ accuracy and 3rd place in the competition".
Или чему мы научились, как выигрывать призы в таких соревнованиях, полезные советы + некоторые мелочи
TLDR
Суть соревнования — например, вот это случайное видео с леопардом. Все видеоролики длятся 15 секунд, а их 400 тысяч...

Заключительные результаты в 3 часа ночи, когда конкурс закончился — я был в поезде, но мой коллега засабмитил заявку за 10 минут до окончания конкурса
Если вам интересно узнать как мы справились, чему научились, и как вам участвовать в подобном, то прошу под кат.
0. Критерии выбора соревнования и структура поста
В своем блоге мы уже писали как и зачем участвовать в соревнованиях.
Относительно выбора этого соревнования можно сказать так — в конце 2017 большинство соревнований на каггле были не так интересны и/или давали слишком мало денег при почти нулевой или около того обучающей ценности и/или были со 100+ участниками, которые отправили свои результаты в первый день, потому что последние соревнования были не таким уж и сложными. Просто состакай 20 моделей по своему усмотрению. Наиболее яркие примеры из последнего вот и вот — интересны только в теории, и являются не более чем казино с GPU вместо фишек.
По этим причинам (достойный приз, отсутствие сильной маркетинговой поддержки из-за 100+ простых заявок в первый день, челлендж, интересность и новизна) — мы выбрали этот конкурс.

В двух словах — у вас есть ~200k видео для обучения, ~80k видео для теста (и 120k неразмеченных видео!). Видео размечены целиком, по 24 классам животных. То есть видео N имеет определенный класс животного (или его отсутствие). То есть видео1 — класс1, видео2 — класс2 и т.д.
В этом соревновании я участвовал вместе с подписчиком моего телеграм канала (канал, веб-трансляция). Для краткости этот пост будет структурирован таким образом:
- TLDR секция для людей, кто хочет быстро посмотреть работающие решения и ссылки;
- Код и jupyter ноутбуки, которые доступны здесь. Код инкапсулирован и ноутбуки используют Jupyter extensions (codefolding, table of content, collapsiblle headers) для читаемости — но почти не уделялось внимания для превращения кода в туториал, так что читайте на свой страх и риск;
- Весь код, написанный мной, написан на Pytorch, мой коллега в основном использовал Keras.
1. TLDR1 — первоначальный наивный подход + сбор полезных ссылок по теме
Чтобы начать, я собрал список полезных ссылок в том порядке, в котором вы вероятно должны прочитать их, чтобы решить похожую задачу. Для начала, вы должны быть знакомы с computer vision, базовой математикой (линейная алгебра, матанализ и численные методы), машинным обучением и базовыми архитектурами в нем.
Ссылки для старта:
Лучшие статьи про LSTM (оказалось что LSTM / GRU не были лучшим решением, но в начале мы игрались с ними, что дало нам некоторый бонус в конечном решении):
- Понимание концепции LSTM — 1, 2, 3, 4;
- Понимание концепции внимания — 1, 2 в RNN;
- Визуализации LSTM для текстовых моделей — 1, 2.
Примеры имплементаций моделей выше на Pytorch:
- Базовые примеры — 1, 2;
- Продвинутые примеры + attention — 1, 2, 3, 4;
- Интересная статья про attention для Keras и Pytorch.
Академические статьи по теме
Следует отметить, что академические работы обычно усложняют и/или они плохо воспроизводятся и/или решают сложные общие задачи или наоборот надуманные штуки — так что читайте их с некоторой долей скептицизма.
Как бы то ни было, эти работы содержат базовые начальные архитектуры и отмечают, что что-то вроде attention или learnable pooling увеличивает точность:
- Самая подходящая работа Large-scale Video Classification with Convolutional Neural Networks — слишком крутая для наших целей, но содержит полезные примеры начальных архитектур;
- Несколько наивный, но простой пример Large-Scale YouTube-8M Video Understanding with Deep Neural Networks для работы с классификацией видео;
- Работа Learnable pooling with Context Gating for video classification, которая отмечает, что attention / learnable pooling может быть полезен для классификации видео;
- Интересная идея в Multi-Level Recurrent Residual Networks for Action Recognition — использовать MRRN для определения быстрых движений;
- Теоретически эта работа Soft Proposal Networks for Weakly Supervised Object Localization позволила бы нам получить bbox'ы с объектами на видео и натренить их обнаружение, но код, что авторы предоставили (несмотря на то, что там заявлен python) содержит кастомные C++ драйвера для CUDA, так что мы решили не идти этим путем.
2. TLDR2 — наилучшие работающие подходы. Наши пайплайны и пайпланы других призеров
2.1 Наилучшие подходы
Наш (3е место):
Приблизительно на половине соревнования я объединился с Саввой Колбачёвым. Изначально, перед тем как перейти к полноразмерным видео, я попробовал какие то штуки с детектированием движения, склеивания нескольких видео размера 64х64 в одно изображение, матричное разложение. Савва пытался использовать LSTM + какие-то базовые энкодеры для видео размера 64х64, так как у него была машина с карточкой 780GTX так что он мог использовать только микро датасет (64х64 3ГБ 2FPS), но даже этого хватало кажется, чтобы набрать хорошие баллы для попадания в топ-10 списка.
Под спойлерами можно будет посмотреть кратко (подробнее ниже) наш конечный пайплайн и пайплайн первого места. И всякие другие штуки.
Сначала выделить 3 или 4 набора фичей из списка лучших энкодеров (мы пробовали разные resnet с дополнениями и без них, inception4, inception-resnet2, densenet, nasnet и другие модели) — 45 кадров на одно видео. Использовать метаданные в модели. Использовать слой внимания в модели. Потом загрузить все полученные векторы в конечные полносвязные слои.
Конечное решение давало ~90%+ точности и 0.9 ROC AUC очков для каждого класса.

Несколько графиков (GRU + 256 скрытых слоев) среди лучших энкодеров — линии на графиках сверху вниз — дообученные inception resnet2, densenet, resnet, inception4, inception-resnet2
Dmytro (1е место) — очень простой пайплайн:
- Несколько дообученных моделей (resnet, inception, xception) на случайных 32 кадрах из видео;
- Предсказание классов для 32 кадров для каждого видео;
- Вычисление гистограммы для этих предсказаний, чтобы исключить время из модели;
- Запуск простой мета-модели на этих результатах.
Когда мы дообучали end-to-end модель (предобученный Imagenet encoder + предобученный GRU) — получили низкую погрешность на обучающей выборке (0.03) и высокую на валидационной (0.13), что мы посчитали слабостью этого подхода. Оказалось, что Dmytro получил такие же результаты, но тем не менее закончил эксперимент. Мы отказались от этого подхода из-за ограничений времени, но когда нам нужно было сделать выделение фичей из дообученной сетки, я получил более менее тоже самое на моих тестах, но Савва не получил нужных значений на своем пайплайне. Это привело к тому, что мы потратили последнюю неделю на попытки использования новых энкодеров вместо донастройки того, что мы уже получили. Также мы не успели попробовать дообученние энкодеров, которые мы использовали. И попробовать обучить pooling / attention для фичей, что мы получили из энкодеров.

Пример улучшений, что мы пробовали — никаких приростов по сравнению с обычным подходом
2.2 Ключевые киллер фичи, эврика и контр-интуитивные моменты
- Метаданные из видео запиханные в простую сетку дают ~0.6 очков на доске лидеров (60-70% точности);
- Я заработал ~0.4 очков на доске используя только 64х64 видео, тогда как другой парень из коммьюнити утверждал, что сделал всего ~0.03 делая тоже самое;
- Простой слой минимакса дал ~0.06-0.07 очков;
- Низкая производительность end-to-end базового энкодера не обязательно дает низкую производительность всего пайплайна.
- Без дообучения — полученные фичи со skip-connections (то есть, выделение не только с последнего полносвязного слоя, но также некоторых фич с промежуточных) работают лучше, чем выделенные только с последнего слоя. На моем GRU-256 бенчмарке это дало ~0.01 очков прироста без всяких стаканий;
- Значимый прирост был получен простыми фичами — метаданные + обычный минимакс;
- Даже если какая то модель ведет себя хуже, чем соседняя — их ансамбль будет лучше из-за log loss'a.
3. Базовый анализ данных и описание, метрики
3.1 Датасет
Базовый анализ можно посмотреть здесь. Как я говорил раньше весь датасет весит 1ТБ и организаторы соревнования расшарили его через торрент, но можно было скачать и напрямую (но довольно медленно)
В наличии было три версии датасета:
- Полноценный 1ТБ
- Примерно 3ГБ видео размера 64x64 с 2FPS — неожиданно достаточно для достижения 75-80% точности и 0.03 баллов!
- 16х16 версия.
В целом датасет был хорошего качества — каждое видео было плохо аннотировано, но с учетом размера, это было все равно хорошо — отзывчивый саппорт, можно было качнуть через торренты (правда его запилили довольно поздно с одним сидером в США), и валидационная часть датасета была просто крутейшая, что я видел. Наша валидация была всегда примерно на 5% меньше, чем потом мы получали на доске. Всё соревнование заняло 2 месяца, но в моем случае ушло 2-3 недели только для того, чтобы скачать датасет и распаковать архив.
3.2 Базовый анализ
Если честно, я не особо сильно разбирался с датасетом, просто потому что он был огромный, но некоторые ключевые инсайты получить было легко.

Собственно датасет

Метки классов — данные очень несбалансированы. С другой стороны — train / test было сделано круто — так что распределение и там и там было одинаковым

Некоторые распределения

Анализ главных компонент — легко различить день и ночь

Размер видео в байтах на log10 шкале. Видео без животных (голубой) и с животными (оранжевый). Неудивительно — из-за сжатия, видео без животных меньше
3.3 Метрика
![$AggLogLoss = -\frac{1}{MN}\sum_{m=1}^{M}\sum_{n=1}^N[y_{nm}\log(\hat y_{nm})+(1-y_{nm})\log(1-\hat y_{nm})]$](https://habrastorage.org/getpro/habr/formulas/127/dc8/9a6/127dc89a6ba9be2b870a8c8987ab2cfe.svg)
Метрика это просто средний logloss по всем 24 классам. Это хорошо, потому что такая метрика есть почти в каждом DL пакете. С ней довольно легко получить сразу нормальные очки, но при этом она неинтуитивна и ненаглядна. Очень чувствительно к малейшему количеству ложноположительных предсказаний. Ну и простое добавление новых моделей эту метрику улучшает, что не очень хорошо в теории.
4. Как мы решали задачу и наше решение
4.1 Фичеринг
Как мы заметили раньше, я выделил фичи из разных предобученных моделей, вроде resnet152, inception-resnet, inception4 и nasnet. Мы обнаружили, что лучше всего выделять фичи не только из последнего слоя перед полносвязными, но и из skip-connections.
Мы также выделили метаданные вроде ширины, высоты и размера обоих датасетов, микро и оригинального. Что интересно, их комбинация работает намного лучше, чем просто оригинальный датасет. Как правило, метаданные были очень полезны для определения пустых/не пустых видео, потому что пустые видео обычно весили существенно меньше. Это позволяло отделить более 25% пустых видео, что, кстати, самый большой класс по численности:

4.2 Разбиение обучающей и валидационной выборки
Распределение классов было очень несбалансированным. Например, для "льва" было всего два примера из всей ~200k выборки! Мало того, это были видео с несколькими метками животных, так что это нужно было сделать более специфичное разбиение. К счастью, у нас был код с контеста с кеггля Planet: Understanding the Amazon from Space competition. С таким разбиением наша проверочная оценка у себя всегда была чуточку хуже, чем на доске:

def multilabel_stratified_kfold_sampling(Y, n_splits=10, random_state):
train_folds = [[] for _ in range(n_splits)]
valid_folds = [[] for _ in range(n_splits)]
n_classes = Y.shape[1]
inx = np.arange(Y.shape[0])
valid_size = 1.0 / n_splits
for cl in range(0, n_classes):
sss = StratifiedKFold(n_splits=n_splits, shuffle=True, random_state=random_state+cl)
for fold, (train_index, test_index) in enumerate(sss.split(inx, Y[:,cl])):
b_train_inx, b_valid_inx = inx[train_index], inx[test_index]
# to ensure there is no repetetion within each split and between the splits
train_folds[fold] = train_folds[fold] + list(set(list(b_train_inx)) - set(train_folds[fold]) - set(valid_folds[fold]))
valid_folds[fold] = valid_folds[fold] + list(set(list(b_valid_inx)) - set(train_folds[fold]) - set(valid_folds[fold]))
return np.array(train_folds), np.array(valid_folds)4.3. Что мы пробовали делать
После выделения фич у нас была матрица для каждого видео вида (45,3000), где 45 число кадров, а 3000 число фич для каждого кадра.
Что мы попробовали и добавили в конечное решение:
- Мы начали с разных RNN, но они не дали нам лучших очков и требовали много больше времени для обучения (даже для Keras имплементации CuDNN). Но мы использовали несколько обученных RNN в конечной архитектуре.
- Используя RNN мы решили попробовать еще и attention и это дало нам хорошее улучшение. По началу, мы использовали вот эту имплементацию поверх 2xCuDNNGRU с простыми фичами. Но как только мы узнали, что удаление RNN не сильно ухудшает результаты, мы начали тратить больше времени на поиск разных Keras имплементаций attention и нашли вот эту. Attention работал для нас навроде learnable pooling, что позволило нам перейти от матриц размера (45,3000) к вектору видео размера 3000.
- Max-min pooling дал целосообразный прирост очков и это работало намного лучше, чем дефолтный max\avg pooling. Идея состояла в том, чтобы получить лучшее представление как фичи изменяются со временем.
- Объединение фич из разных моделей дало лучше результат, но требовало больше времени и ресурсов для обучения.
- Обучение отдельной модели для распознавания пустых/не пустых видео. Это дало слегка лучший результат для этого конкретного класса, но это было осмысленно, так как класс был самым многочисленным.
- Псевдоразметка (разбиение) всегда давала чуток прироста для наших моделей. Обычно обучение выходило на плато после 12-15 эпох. Похоже что псевдоразметка внесла некоторое разнообразие в обучение и улучшило валидацию.
- Стакание моделей)
Что мы попробовали, но это не сработало для решения задачи:
- Focal loss: в целом, это работает довольно хорошо и добавляет некоторое разнообразие к моделям, но было не очень полезным в соответствии с метрикой соревнования. Но мы точно попробуем это для других проектов.
- Разобраться с несбалансированными классами: не помогает в соответствии с метрикой.
- 1D/3D Convolutions
- Optical Flow
4.4 Описание конечного решения
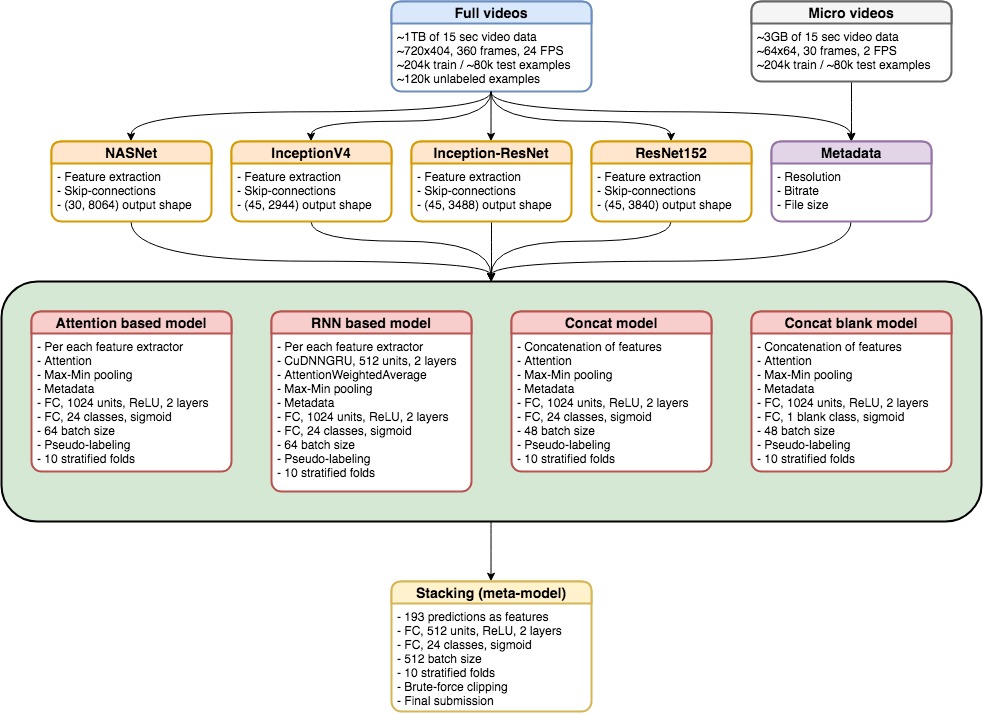
Мы обучили 9 моделей, каждая по 5 фолдов, используя выделенные фичи:
- 3 CuDNNGRU модели с AttentionWeightedAverage и Max-Min polling слоями, основанные на resnet152, inception-resnet and inception4.
- 4 модели с Attention и Max-Min pooling слоями основанными на resnet152, inception-resnet, inception4 and nasnet.
- 1 concat модель с Attention и Max-Min pooling слоями (похоже на предыдущие) но объединенными фичами из resnet152, inception-resnet, inception4.
- 1 concat модель только для пустых\не пустых предсказаний.
Мы обнаружили, что 15 эпох + 5 эпох для псевдоразметки должно быть достаточно, чтобы получить довольно приличный результат. Размер батча был 64(44/20) для single-feature моделей и 48 (32/16) для nasnet и с concat моделей. В целом, больший батч был лучше. Выбор размера зависел от I/O диска и скорости обучения. Для получения конечного результата, предсказания из моделей были сложены вместе через 2 полносвязных слоя метамодели используя 10 фолдов.)
Мы обучили 9 моделей, каждая по 5 фолдов, используя выделенные фичи:
- 3 CuDNNGRU модели с AttentionWeightedAverage и Max-Min polling слоями, основанные на resnet152, inception-resnet и inception4.
- 4 модели с Attention и Max-Min pooling слоями основанными на resnet152, inception-resnet, inception4 и nasnet.
- 1 concat модель с Attention и Max-Min pooling слоями (похоже на предыдущие) но объединенными фичами из resnet152, inception-resnet, inception4.
- 1 concat модель только для пустых/не пустых предсказаний.
Мы обнаружили, что 15 эпох + 5 эпох для псевдоразметки должно быть достаточно, для получения довольно приличного результата. Размер батча был 64(44/20) для single-feature моделей и 48 (32/16) для nasnet и с concat моделей. В целом, больший батч был всегда лучше. Выбор размера зависел от I/O диска и скорости обучения. Для получения конечного результата, предсказания из моделей были сложены вместе через 2 полносвязных слоя метамодели используя 10 фолдов.
5. Альтернативные подходы
Насколько нам известно, можно было сделать еще пару вещей. Например, попробовать сделать обнаружение объектов на видео 64x64, сделать bbox'ы и транслировать их на полноразмерные видео. Сделать из этого двух-трех стадийный пайплайн. Или попробовать построить bbox'ы из дообученных моделей, но это представляется крайне сложным.
Мы сделали более-менее детектирование объектов, но решили не идти этим путем, так как посчитали его ненадежным — не хотелось тратить время на ручную разметку из-за огромного объема данных, плюс мы не верили, что даже на 64x64 детектирование движения будет стабильным.
6. Базовые советы для участников соревнований
- Пробовать простые подходы
- Быть уверенным, что вы понимаете что именно работает и почему это работает
- Прочитать все релевантные пейперы по теме, но не тратить слишком уж много времени на один из подходов, если вы не уверены, что
- это легко и быстро можно реализовать
- вы точно уверены, что это будет работать
- вы можете более менее совместить модели из работ без реализации сложных моделей с нуля
- Не боятся сложности задачи. Современные библиотеки дают вам суперсилу
- 90% того, что написано в пейперах — мусор. У вас нет шести месяцев для тестирования всего, что вы найдете. В этих работах обычно ценят больше форму, а не практику
- Объединение моделей надо делать только в самом конце, и то как самое последнее, что можно придумать
- Общайтесь с людьми, кооперируйтесь. Это что-то типа стакания людей) Вместе вы учитесь не в два раза быстрее, а в десять.
- Делитесь своим кодом и подходами.
7. Базовые советы для исследовательских и продакшн моделей
- В 95% случаях никаких стаканий — обычно это дает не более 5-10%
- Ваша модель и пайплайн должны быть краткими, быстрыми и удобными для инженеров
- Все вышенаписанное применимо и для этих целей, но только с учетом повышенных требований к развертыванию.
8. Наше оборудование
Мы использовали 3 машины — мой слабенький сервер с 1070Ti, но когда мы поставили туда SSD то стали ограниченны размерами дискового пространства. Была еще машина Саввы со слабеньким GPU и сервер моих друзей с двумя 1080Ti.

