Для своих ETL (Extract, Transform, Loading) процессов, на этапах E и T, то есть извлечение и преобразование данных мы используем Apache Storm, и, так как большинство ошибок, связанных с инвалидацией сырых данных, происходит именно на этом этапе, — появилось желание централизованно логировать всё это, используя ELK стэк (Elasticsearch, Logstash, Kibana).
Каким же было моё удивление, что нигде не то, что на русском языке, но даже в оригинальных туториалах не было описана работа с логами в формате log4j2, который является дефолтом в мире Java-приложений.
Исправляя это упущение — под катом туториал по настройке централизованного сбора любых log4j2 логов на основе:

Здесь уже писалось про установку ELK внутри Docker-контейнера, однако автор этой статьи использовал filebeat, а мне, по ряду причин, не хотелось тащить на application-хосты какой-то дополнительный софт, к тому же log4j2 умеет слать данные напрямуюбез смс и регистрации в TCP сокет.
После недолгих поисков, я обнаружил, что с последний версией ELK (на момент написания статьи это ELK 6.0.0) более менее из коробки работает только Docker-образ sebp/elk — его мы и используем, но исправим образ для работы без filebeat и будем использовать для этого TCP Source.
Просто создаем два файла — один для приёма логов по TCP, а другой для записи в Elasticsearch
Обратите внимание на kv filter (key value) — именно он позволит нам корректно обрабатывать логи в формате log4j2, так как мы разобьем необходимые нам параметры на пары «ключ-значение».
Параметр же recursive необходим, чтобы фильтр не пытался искать вложенные пары «ключ-значение» в поле value.
Так же на этом этапе мы можем добавить в Dockerfile установку необходимых плагинов для Elasticsearch или Kibana (для Logstash тоже, но на сколько я понял в составе образа уже установлены все официальные плагины, так что если вам понадобится что-то очень кастомное) как описано здесь.
Для чего немного изменим Dockerfile (я приведу только diff):
То есть мы уберем из образа стандартные input, предназначенные для работы с filebeats, syslog и nginx и добавим туда свои файлы конфигурации
Дальше осталось только собрать новый образ:
В данном случае я его еще и опубликовал в локальном docker-registry (или можно опубликовать на docker hub)
Запуск происходит стандартно, но сначала создадим директорию на host-машине, где мы будем хранить данные Elasticseach, чтобы они не пропали после остановки контейнера
И запускаем ELK:
Обратите внимание на
Примерно через 40 секунд контейнер запустится и вы сможете зайти в Kibana по адресу host01.lan:5601/app/kibana# и увидите что-то вроде этого:
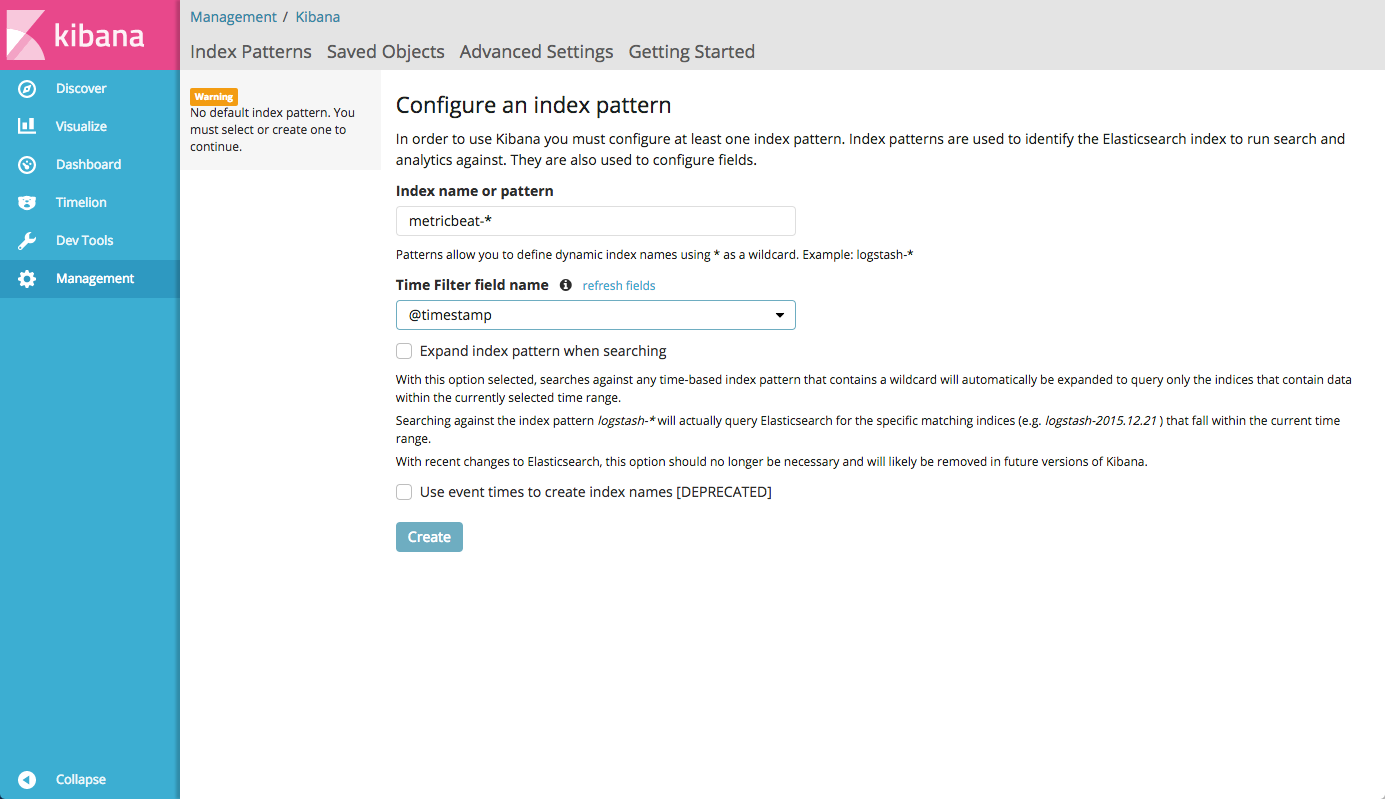
Так как в файле конфигурации индексов Elasticsearch мы указали формат
По части установки Storm написано множество руководств, да и официальная документация достаточно подробная. Эта часть факультативная и если Вам не интересна настройка Storm, вы можете смело перейти к следующей части
Мы используем ветку Storm 1.0 (по историческим причинам и потому что всем лень портировать код на 1.1.х, так как он просто работает), поэтому я буду устанавливать последнюю версию из этой ветки — 1.0.5 (на момент написания статьи)
Установка довольно проста:
Так же для работы кворума нам будут необходимы Zookeeper-сервера. Их настройка — тема для отдельной статьи, так что здесь я их описывать не буду, просто предположу, что они у нас настроены на серверах с именами
Создаем конфигурационный файл storm.yaml
Здесь помимо Zookeeper-кластера нужно указать Nimbus сервера, которые выступают своеобразными координаторами топологий в Storm
По умолчанию Apache Storm не демонизируется самостоятельно, а официальное руководство ничего не говорит по поводу автоматического запуска в режиме демона. Поэтому мы используем Python supervisord, хотя конечно же вы можете использовать любой оркестратор процессов (RunIT, daemonize etc)
У меня на CentOS 7.3 supervisord ставится через pip, но зависимость meld3 придется поставить из пакета. На вашей системе установка может (и будет) отличаться, но только в незначительных деталях:
Дальше нам необходимо создать конфигурационные файлы для запуска Apache Storm и тут надо остановиться на том, что Storm имеет в своём составе несколько компонентов:
Для каждого из них нам нужно будет создать файл конфигурации в
Например у нас будет 5 серверов Storm:
А так же на каждом сервере мы запустим процесс logviewer (хотя он нам не так уж и нужен, потому что мы сможем смотреть логи из Kibana, но чтобы ссылки в Storm UI не вели в пустоту — пусть будет).
Соответственно на всех пяти серверах создаем вот такие два файла:
Дальше на серверах storm01.lan и storm02.lan создадим аналогичные файлы для запуска Nimbus:
Ну и на первом сервере, где мы решили установить UI создадим еще один файл, который будет его запускать:
Как вы могли заметить, файлы конфигурации практически аналогичны, так как Storm использует общую для всех компонентов конфигурацию и мы меняем только роль, которую мы хотим запустить.
На этом настройка Apache Storm под управлением supervisord завершена, осталось только настроить сбор логов.
Для Apache Storm в нашей инсталляции логированием будут управлять два файла:
Однако, так как формат Log4J2 универсальный, вы с легкостью можете адаптировать эту конфигурацию к любому Java-приложению
Файл worker.xml:
И файл cluster.xml:
Как вы можете заметить, конфигурация аналогичная, за исключением дополнительного логгера METRICS, который используется для worker'ов (если вы используете метрики в вашей Storm-топологии).
Рассмотрим ключевые моменты в файлах конфигурации:
На этом, собственно настройка закончена, можно запускать Storm и смотреть логи
На каждом сервере выполняем такие команды:
Дальше supervisord запустит все компоненты Apache Storm
Теперь мы можем зайти в Kibana и полюбоваться на графики вроде такого:

Здесь мы видим распределение сообщений с уровнем INFO по серверам
В моём случае, как основная система мониторинга, которая рисует красивые графики и дашборды используется Grafana, и у неё есть прекрасная особенность — она умеет строить графики из Elasticsearch (а еще они на мой взгляд более красивые, чем в Kibana)
Просто зайдем в источники данных в Grafana и добавим наш Elasticsearch, указав адрес host-машины, где у нас запущен ELK:

После чего мы сможем добавить график, где будем смотреть, например количество WARNING по каждому серверу:

Диски, как известно не резиновые, а Elasticsearch по умолчанию никакой ротации не делает. На моей инсталляции это может стать проблемой, так как за день у меня набирается порядка 60 Гб данных в индексах
Для того, чтобы автоматически очищать старые логи, существует python-пакет elasticsearch-curator
Установим его на хост-машине, где у нас запущен elk-контейнер, используя pip:
И создадим два конфигурационных файла, один описывает подключение к Elasticsearch, а другой задает action, т.е. действия непосредственно для очистки устаревших индексов:
Здесь мы указываем наш index-pattern, в данном случае
Дальше мы можем просто добавить команду в cron, для запуска curator раз в день:
Этот туториал не претендует на 100% полноту и опускает некоторые вещи, потому как предполагается больше как шпаргалка для самого себя, а также предполагает средний и выше уровень владения Linux и понимание как это всё работает.
Для меня было действительно сложно найти развернутое описание как сделать связку из Storm, Log4J2 и ELK в виде конкретного руководства. Конечно, можно потратить несколько часов на чтение документации, но надеюсь тем, кто столкнётся с похожей задачей будет проще и быстрее воспользоваться моим кратким руководством.
Буду очень рад любым замечаниям, дополнениям, а также вашим кейсам централизованного сбора логов, равно как и сложностям или особенностям, с которыми вам пришлось столкнуться в вашей практике. Добро пожаловать в комментарии!
Каким же было моё удивление, что нигде не то, что на русском языке, но даже в оригинальных туториалах не было описана работа с логами в формате log4j2, который является дефолтом в мире Java-приложений.
Исправляя это упущение — под катом туториал по настройке централизованного сбора любых log4j2 логов на основе:
- ELK внутри Docker
- Настройка log4j для работы с Logstash
- Настройка Logstash для правильной индексации логов
- Немного бонусов, в виде краткой настройки Storm и интеграции Elasticsearch с Grafana
ELK на Docker и настройка Logstash
Здесь уже писалось про установку ELK внутри Docker-контейнера, однако автор этой статьи использовал filebeat, а мне, по ряду причин, не хотелось тащить на application-хосты какой-то дополнительный софт, к тому же log4j2 умеет слать данные напрямую
Скачаем образ
После недолгих поисков, я обнаружил, что с последний версией ELK (на момент написания статьи это ELK 6.0.0) более менее из коробки работает только Docker-образ sebp/elk — его мы и используем, но исправим образ для работы без filebeat и будем использовать для этого TCP Source.
cd /usr/local/src
git clone https://github.com/spujadas/elk-docker
cd elk-docker
Создадим свою собственную конфигурацию Logstash
Просто создаем два файла — один для приёма логов по TCP, а другой для записи в Elasticsearch
[root@host01 elk-docker]# cat 02-tcp-input.conf
input {
tcp {
port => 5044
codec => line
}
}
filter {
kv {
source => "message"
recursive => "false"
add_tag => "%{loggerclass}"
}
}
[root@host01 elk-docker]# cat 30-output.conf
output {
elasticsearch {
hosts => ["localhost"]
index => "storm-%{+YYYY.MM.dd}"
}
}Обратите внимание на kv filter (key value) — именно он позволит нам корректно обрабатывать логи в формате log4j2, так как мы разобьем необходимые нам параметры на пары «ключ-значение».
Параметр же recursive необходим, чтобы фильтр не пытался искать вложенные пары «ключ-значение» в поле value.
add_tag => "%{loggerclass}" — добавит к каждой записи Java-класс процесса, который породил эту запись — очень удобно, когда нужно посмотреть работу (ошибки) конкретного компонента, например на этапе отладки.Так же на этом этапе мы можем добавить в Dockerfile установку необходимых плагинов для Elasticsearch или Kibana (для Logstash тоже, но на сколько я понял в составе образа уже установлены все официальные плагины, так что если вам понадобится что-то очень кастомное) как описано здесь.
Соберём контейнер
Для чего немного изменим Dockerfile (я приведу только diff):
diff --git a/Dockerfile b/Dockerfile
index ab01788..723120e 100644
--- a/Dockerfile
+++ b/Dockerfile
@@ -128,9 +128,7 @@ ADD ./logstash-beats.crt /etc/pki/tls/certs/logstash-beats.crt
ADD ./logstash-beats.key /etc/pki/tls/private/logstash-beats.key
# filters
-ADD ./02-beats-input.conf /etc/logstash/conf.d/02-beats-input.conf
-ADD ./10-syslog.conf /etc/logstash/conf.d/10-syslog.conf
-ADD ./11-nginx.conf /etc/logstash/conf.d/11-nginx.conf
+ADD ./02-tcp-input.conf /etc/logstash/conf.d/02-tcp-input.conf
ADD ./30-output.conf /etc/logstash/conf.d/30-output.conf
# patternsТо есть мы уберем из образа стандартные input, предназначенные для работы с filebeats, syslog и nginx и добавим туда свои файлы конфигурации
Дальше осталось только собрать новый образ:
docker build -t https://docker-registry-host.lan:5000/elk .В данном случае я его еще и опубликовал в локальном docker-registry (или можно опубликовать на docker hub)
Запускаем ELK
Запуск происходит стандартно, но сначала создадим директорию на host-машине, где мы будем хранить данные Elasticseach, чтобы они не пропали после остановки контейнера
mkdir -p /mnt/data1/elk/dataИ запускаем ELK:
sysctl vm.max_map_count=524288 #Необходимо для корректной работы индексов Elasticseach
docker run -v /mnt/data1/elk/data:/var/lib/elasticsearch --network=host -p 5601:5601 -p 9200:9200 -p 5044:5044 -e ES_HEAP_SIZE="4g" -e LS_HEAP_SIZE="1g" -it -d --name elk docker-registry-host.lan:5000/elkОбратите внимание на
-e ES_HEAP_SIZE="4g" -e LS_HEAP_SIZE="1g", — размер памяти, который Вам необходим зависит от количества логов, которые вы собираетесь агрегировать. В моём случае 256 Мб, установленных по умолчанию мне не хватило, поэтому я выделил 4 Гб для Elasticsearch и 1 Гб для Logstash соответственно. Эти параметры придётся подбирать интуитивно исходя из нагрузки, так как внятного описания соответствия объема данных в секунду и количества используемой памяти я не нашёлПримерно через 40 секунд контейнер запустится и вы сможете зайти в Kibana по адресу host01.lan:5601/app/kibana# и увидите что-то вроде этого:
Так как в файле конфигурации индексов Elasticsearch мы указали формат
storm-%{+YYYY.MM.dd}, то при старте Kibana мы зададим index pattern как storm-*Установка и настройка Apache Storm (факультативно)
По части установки Storm написано множество руководств, да и официальная документация достаточно подробная. Эта часть факультативная и если Вам не интересна настройка Storm, вы можете смело перейти к следующей части
Мы используем ветку Storm 1.0 (по историческим причинам и потому что всем лень портировать код на 1.1.х, так как он просто работает), поэтому я буду устанавливать последнюю версию из этой ветки — 1.0.5 (на момент написания статьи)
Установка довольно проста:
mkdir /opt/storm
cd /opt/storm
wget http://ftp.byfly.by/pub/apache.org/storm/apache-storm-1.0.5/apache-storm-1.0.5.tar.gz
tar xzf apache-storm-1.0.5.tar.gz
ln -s apache-storm-1.0.5 currentТак же для работы кворума нам будут необходимы Zookeeper-сервера. Их настройка — тема для отдельной статьи, так что здесь я их описывать не буду, просто предположу, что они у нас настроены на серверах с именами
zookeeper-{01..03}.lanСоздаем конфигурационный файл storm.yaml
--- /opt/storm/current/conf/storm.yaml
storm.zookeeper.servers:
- "zookeeper-01.lan"
- "zookeeper-01.lan"
- "zookeeper-01.lan"
storm.local.dir: "/opt/storm"
nimbus.seeds: ["storm01.lan", "storm02.lan"]
Здесь помимо Zookeeper-кластера нужно указать Nimbus сервера, которые выступают своеобразными координаторами топологий в Storm
Управление запуском Apache Storm через Supervisord
По умолчанию Apache Storm не демонизируется самостоятельно, а официальное руководство ничего не говорит по поводу автоматического запуска в режиме демона. Поэтому мы используем Python supervisord, хотя конечно же вы можете использовать любой оркестратор процессов (RunIT, daemonize etc)
У меня на CentOS 7.3 supervisord ставится через pip, но зависимость meld3 придется поставить из пакета. На вашей системе установка может (и будет) отличаться, но только в незначительных деталях:
yum install python-pip -y #устанавливаем pip
yum install python-meld3 -y #так же поставим зависимость, необходимую для работы supervisord (pip не может поставить её автоматически на CentOS 7.3)
pip install --upgrade pip #обновим pip до последней версии
pip install supervisor #установим supervisordДальше нам необходимо создать конфигурационные файлы для запуска Apache Storm и тут надо остановиться на том, что Storm имеет в своём составе несколько компонентов:
- Nimbus — оркестратор, который предоставляет API, а так же управляет балансировкой задач (топологий, экзекуторов) между узлами кластера
- UI — тут всё просто — это web-интерфейс, который позволяет посмотреть всякое о текущем статусе
- Supervisor — не тот, что мы только что поставили, а свой, внутренний — который получает задания от Nimbus сервера и запускает внутри себя worker'ы, которые и делают работу,
описанную в топологиях - Logviewer — позволяет через web-интерфейс посмотреть логи на каждой машине кластера
Для каждого из них нам нужно будет создать файл конфигурации в
/etc/supervisord/conf.d/ в зависимости от роли сервераНапример у нас будет 5 серверов Storm:
storm01.lan— Nimbus (см. выше, где мы настраивали storm.yaml), UI, Supervisorstorm02.lan— Nimbus, Supervisorstorm03.lan— Supervisorstorm04.lan— Supervisorstorm05.lan— Supervisor
А так же на каждом сервере мы запустим процесс logviewer (хотя он нам не так уж и нужен, потому что мы сможем смотреть логи из Kibana, но чтобы ссылки в Storm UI не вели в пустоту — пусть будет).
Соответственно на всех пяти серверах создаем вот такие два файла:
[root@storm01 ~]# cat /etc/supervisord/conf.d/storm.supervisor.conf
[program:storm.supervisor]
command=/opt/storm/current/bin/storm supervisor
user=storm
autostart=true
autorestart=true
startsecs=10
startretries=999
log_stdout=true
log_stderr=true
logfile=/opt/storm/supervisor.log
logfile_maxbytes=20MB
logfile_backups=10
environment=JAVA_HOME=/usr/java/current,PATH=%(ENV_PATH)s:/opt/storm/current/bin,STORM_HOME=/opt/storm/current
[root@storm01 ~]# cat /etc/supervisord/conf.d/storm.logviewer.conf
[program:storm.logviewer]
command=/opt/storm/current/bin/storm logviewer
user=storm
autostart=true
autorestart=true
startsecs=10
startretries=999
log_stdout=true
log_stderr=true
logfile=/opt/storm/logviewer.log
logfile_maxbytes=20MB
logfile_backups=10
environment=JAVA_HOME=/usr/java/current,PATH=%(ENV_PATH)s:/opt/storm/current/bin,STORM_HOME=/opt/storm/currentДальше на серверах storm01.lan и storm02.lan создадим аналогичные файлы для запуска Nimbus:
[root@storm01 ~]# cat /etc/supervisord/conf.d/storm.nimbus.conf
[program:storm.nimbus]
command=/opt/storm/current/bin/storm nimbus
user=storm
autostart=true
autorestart=true
startsecs=10
startretries=999
log_stdout=true
log_stderr=true
logfile=/opt/storm/nimbus.log
logfile_maxbytes=20MB
logfile_backups=10
environment=JAVA_HOME=/usr/java/current,PATH=%(ENV_PATH)s:/opt/storm/current/bin,STORM_HOME=/opt/storm/currentНу и на первом сервере, где мы решили установить UI создадим еще один файл, который будет его запускать:
[root@storm01 ~]# cat /etc/supervisord/conf.d/storm.ui.conf
[program:storm.ui]
command=/opt/storm/current/bin/storm ui
user=storm
autostart=true
autorestart=true
startsecs=10
startretries=999
log_stdout=true
log_stderr=true
logfile=/opt/storm/ui.log
logfile_maxbytes=20MB
logfile_backups=10
environment=JAVA_HOME=/usr/java/current,PATH=%(ENV_PATH)s:/opt/storm/current/bin,STORM_HOME=/opt/storm/currentКак вы могли заметить, файлы конфигурации практически аналогичны, так как Storm использует общую для всех компонентов конфигурацию и мы меняем только роль, которую мы хотим запустить.
На этом настройка Apache Storm под управлением supervisord завершена, осталось только настроить сбор логов.
Настройка Log4J2 для отправки логов в ELK
Для Apache Storm в нашей инсталляции логированием будут управлять два файла:
/opt/storm/current/log4j2/cluster.xml— управляет конфигурацией для логов сервисов Apache Storm (Nimbus, Supervisor, UI)/opt/storm/current/log4j2/worker.xml— управляет конфигурацией для логирования worker'ов, то есть непосредственно топологии (приложения), запущенной внутри Storm
Однако, так как формат Log4J2 универсальный, вы с легкостью можете адаптировать эту конфигурацию к любому Java-приложению
Файл worker.xml:
<?xml version="1.0" encoding="UTF-8"?>
<configuration monitorInterval="60">
<properties>
<property name="defaultpattern">logdate=(%d{ISO8601}) thread=(%thread)) level=(%level) loggerclass=(%logger{36}) message=(%msg)%n</property>
</properties>
<appenders>
<RollingFile name="A1"
fileName="${sys:storm.log.dir}/${sys:logfile.name}"
filePattern="${sys:storm.log.dir}/${sys:logfile.name}.%i.gz">
<PatternLayout>
<pattern>${defaultpattern}</pattern>
</PatternLayout>
<Policies>
<SizeBasedTriggeringPolicy size="100 MB"/> <!-- Or every 100 MB -->
</Policies>
<DefaultRolloverStrategy max="9"/>
</RollingFile>
<RollingFile name="METRICS"
fileName="${sys:storm.log.dir}/${sys:logfile.name}.metrics"
filePattern="${sys:storm.log.dir}/${sys:logfile.name}.metrics.%i.gz">
<PatternLayout>
<pattern>${defaultpattern}</pattern>
</PatternLayout>
<Policies>
<SizeBasedTriggeringPolicy size="2 MB"/>
</Policies>
<DefaultRolloverStrategy max="9"/>
</RollingFile>
<Socket name="logstash" host="host01.lan" port="5044">
<PatternLayout pattern="${defaultpattern}" charset="UTF-8" />
</Socket>
<Async name="LogstashAsync" bufferSize="204800">
<AppenderRef ref="logstash" />
</Async>
</appenders>
<loggers>
<root level="INFO">
<appender-ref ref="A1"/>
<appender-ref ref="LogstashAsync"/>
</root>
<Logger name="METRICS_LOG" level="info" additivity="false">
<appender-ref ref="METRICS"/>
<appender-ref ref="LogstashAsync"/>
</Logger>
</loggers>
</configuration>И файл cluster.xml:
<?xml version="1.0" encoding="UTF-8"?>
<configuration monitorInterval="60">
<properties>
<property name="defaultpattern">logdate=(%d{ISO8601}) thread=(%thread)) level=(%level) loggerclass=(%logger{36}) message=(%msg)%n</property>
</properties>
<appenders>
<RollingFile name="A1"
fileName="${sys:storm.log.dir}/${sys:logfile.name}"
filePattern="${sys:storm.log.dir}/${sys:logfile.name}.%i">
<PatternLayout>
<pattern>${defaultpattern}</pattern>
</PatternLayout>
<Policies>
<SizeBasedTriggeringPolicy size="100 MB"/> <!-- Or every 100 MB -->
</Policies>
<DefaultRolloverStrategy max="9"/>
</RollingFile>
<Socket name="logstash" host="host01.lan" port="5044">
<PatternLayout pattern="${defaultpattern}" charset="UTF-8" />
</Socket>
<Async name="LogstashAsync" bufferSize="204800">
<AppenderRef ref="logstash" />
</Async>
</appenders>
<loggers>
<root level="INFO">
<appender-ref ref="A1"/>
<appender-ref ref="LogstashAsync"/>
</root>
</loggers>
</configuration>Как вы можете заметить, конфигурация аналогичная, за исключением дополнительного логгера METRICS, который используется для worker'ов (если вы используете метрики в вашей Storm-топологии).
Рассмотрим ключевые моменты в файлах конфигурации:
- Паттерн, который мы используем для логирования, где мы пишем в формате key-value (помните, мы использовали фильтр kv в Logstash) необходимые нам сущности, а именно — дату, тред, уровень логирования, класс (который также станет tag'ом в Elasticsearch) и собственно сообщение, которое было отправлено этим классом:
<property name="defaultpattern">logdate=(%d{ISO8601}) thread=(%thread)) level=(%level) loggerclass=(%logger{36}) message=(%msg)%n</property>
- Помимо логирования на диск (которое необходимо, чтобы смотреть логи через встроенный в Apache Storm logviewer), за которое отвечает дефолтный appender A1 мы используем SocketAppender, который позволит отправлять сообщения непосредственно в Logstash по TCP:
<Socket name="logstash" host="host01.lan" port="5044"> <PatternLayout pattern="${defaultpattern}" charset="UTF-8" /> </Socket>
Здесь в после host, мы указываем сервер (хост-машину), на котором у нас запущен docker-контейнер с ELK и порт, который мы указали в конфигурации - Так же мы обязательно делаем запись логов асинхронной, иначе наша Storm-топология
будет вставать коломбудет заблокирована, в случае, если Logstash перестанет отвечать или будут проблемы со связностью с этой машиной:
<Async name="LogstashAsync" bufferSize="204800"> <AppenderRef ref="logstash" /> </Async>
Размер буфера здесь взят наугад, но для моего throughput его более чем достаточно
Запуск Apache Storm и проверка логирования
На этом, собственно настройка закончена, можно запускать Storm и смотреть логи
На каждом сервере выполняем такие команды:
systemctl enable supervisord
systemctl start supervisordДальше supervisord запустит все компоненты Apache Storm
Проверка работы и небольшой бонус!
Теперь мы можем зайти в Kibana и полюбоваться на графики вроде такого:
Здесь мы видим распределение сообщений с уровнем INFO по серверам
Интеграция с Grafana
В моём случае, как основная система мониторинга, которая рисует красивые графики и дашборды используется Grafana, и у неё есть прекрасная особенность — она умеет строить графики из Elasticsearch (а еще они на мой взгляд более красивые, чем в Kibana)
Просто зайдем в источники данных в Grafana и добавим наш Elasticsearch, указав адрес host-машины, где у нас запущен ELK:
После чего мы сможем добавить график, где будем смотреть, например количество WARNING по каждому серверу:
Очистка старых логов
Диски, как известно не резиновые, а Elasticsearch по умолчанию никакой ротации не делает. На моей инсталляции это может стать проблемой, так как за день у меня набирается порядка 60 Гб данных в индексах
Для того, чтобы автоматически очищать старые логи, существует python-пакет elasticsearch-curator
Установим его на хост-машине, где у нас запущен elk-контейнер, используя pip:
[root@host01 ~]# pip install elasticsearch-curatorИ создадим два конфигурационных файла, один описывает подключение к Elasticsearch, а другой задает action, т.е. действия непосредственно для очистки устаревших индексов:
[root@host01 ~]# cat /mnt/elk/conf/curator/curator.yml
---
client:
hosts:
- 127.0.0.1
port: 9200
url_prefix:
use_ssl: False
certificate:
client_cert:
client_key:
ssl_no_validate: False
http_auth:
timeout: 30
master_only: False
logging:
loglevel: INFO
logfile:
logformat: default
blacklist: ['elasticsearch', 'urllib3']
[root@host01 ~]# cat /mnt/elk/conf/curator/rotate.yml
---
actions:
1:
action: delete_indices
description: >-
Delete indices older than 20 days (based on index name), for storm-
prefixed indices.
options:
ignore_empty_list: True
disable_action: False
filters:
- filtertype: pattern
kind: prefix
value: storm-
- filtertype: age
source: name
direction: older
timestring: '%Y.%m.%d'
unit: days
unit_count: 60Здесь мы указываем наш index-pattern, в данном случае
storm-, формат суффикса (год, месяц, день) и количество дней, которые мы будем хранить логи.Дальше мы можем просто добавить команду в cron, для запуска curator раз в день:
/bin/curator --config /mnt/elk/conf/curator/curator.yml /mnt/elk/conf/curator/rotate.ymlЗаключение и disclaimer
Этот туториал не претендует на 100% полноту и опускает некоторые вещи, потому как предполагается больше как шпаргалка для самого себя, а также предполагает средний и выше уровень владения Linux и понимание как это всё работает.
Для меня было действительно сложно найти развернутое описание как сделать связку из Storm, Log4J2 и ELK в виде конкретного руководства. Конечно, можно потратить несколько часов на чтение документации, но надеюсь тем, кто столкнётся с похожей задачей будет проще и быстрее воспользоваться моим кратким руководством.
Буду очень рад любым замечаниям, дополнениям, а также вашим кейсам централизованного сбора логов, равно как и сложностям или особенностям, с которыми вам пришлось столкнуться в вашей практике. Добро пожаловать в комментарии!
