
Неоднократно доводилось слышать мнение, что из всех заметающих кривых. именно кривая Гильберта наиболее перспективна для пространственной индексации. Мотивируется это тем, что она не содержит разрывов и потому в некотором смысле “хорошо устроена”. Так ли это на самом деле и при чем здесь пространственная индексация, разберёмся под катом.
Завершающая статья из цикла:
- Почему не работает прямолинейный подход при
пространственной индексации заметающими кривыми - Презентация алгоритма
- 3D и очевидные оптимизации
- 8D и перспективы в OLAP
- 3D на сфере, как это выглядит
- 3D на сфере, benchmarks
- Как насчет индексации неточечных объектов?
Кривая Гильберта обладает замечательным свойством — расстояние между двумя последовательными точками на ней всегда равно единице (шагу текущей детализации, если точнее). Поэтому данные с не сильно отличающимися значениями кривой Гильберта находятся недалеко друг от друга (обратное, кстати, неверно — расположенные рядом точки могет очень сильно отличаться по значению). Ради этого свойства её используют, например, для
- понижения размерности (управление цветовой палитрой)
- повышения локальности доступа в многомерном индексировании (здесь)
- в конструировании антенн (здесь)
- кластеризации таблиц (DB2)
Что касается пространственных данных, свойства кривой Гильберта позволяют увеличить локальность ссылок и повысить эффективность кэша СУБД, как здесь, где перед использованием таблицы рекомендуют дополнить её колонкой с вычисленным значением и отсортировать по этой колонке.
В пространственном поиске кривая Гильберта присутствует в Гильбертовых R-деревьях, где основная идея (очень грубо) — когда приходит время расщепить страницу на двух потомков — сортируем все элементы на странице по значениям центроидов и делим пополам.
Но нас больше интересует другое свойство кривой Гильберта — это самоподобная заметающая кривая. Что позволяет использовать ее в индексе на основе B-дерева. Речь идёт о способе нумерации дискретного пространства.
- Пусть задано дискретное пространство размерности N.
- Допустим также, что у нас есть некоторый способ нумерации всех точек этого пространства.
- Тогда, для индексации точечных объектов достаточно поместить в индекс на основе B-дерева номера точек в которые попали эти объекты.
- Поиск в таком пространственном индексе зависит от способа нумерации и в конечном счете сводится к выборке по индексу из интервалов значений.
- Заметающие кривые хороши своим самоподобием, которое позволяет порождать относительно небольшое количество таких подинтервалов, тогда как прочие способы (например, подобие строчной развёртки) требует огромного числа подзапросов, что делает такую пространственную индексацию малоэффективной.

Итак, откуда берётся это интуитивное ощущение, что кривая Гильберта хороша для пространственной индексации? Да в ней нет разрывов, расстояние между любыми последовательными точками равно шагу дискретизации. Ну и что? Какова связь между этим фактом и потенциально высокой производительностью?
В самом начале мы сформулировали правило — «хороший» метод нумерации минимизирует суммарный периметр страниц индекса. Речь идёт о страницах B-дерева, на которых в конце концов окажутся данные. Другими словами — производительность индекса определяется числом страниц, которые придётся прочитать. Чем меньше страниц приходится в среднем на запрос эталонного размера, тем выше (потенциальная) производительность индекса.
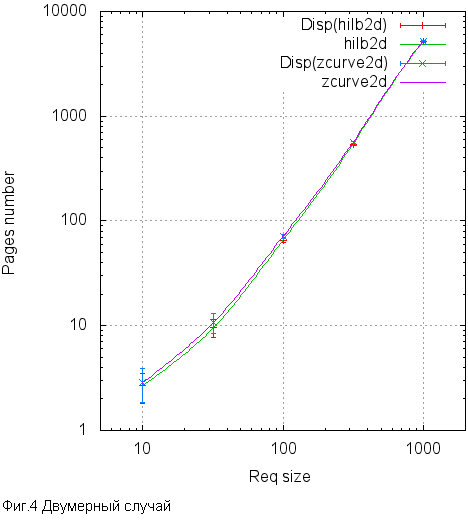
С этой точки зрения кривая Гильберта выглядит очень перспективно. Но это интуитивное ощущение на хлеб не намажешь, поэтому проведём численный эксперимент.
- рассмотрим 2 и 3 -мерные пространства
- возьмём квадратные/кубические запросы разных размеров
- для серии случайных запросов одного типа и размера подсчитаем среднее/дисперсию числа заметённых страниц, в серии 1000 запросов
- будем исходить из того, что в каждом узле пространства лежит точка. Можно набросать случайных данных и проверить на них, но тогда возникли бы вопросы к качеству этих случайных данных. А так мы имеем вполне объективный показатель “пригодности”, пусть и далёкий от любого реального набора данных
- на странице помещается 200 элементов, важно чтобы это была бы не степень двойки, что привело бы к вырожденному случаю
- сравним между собой кривую Гильберта и Z-curve

Вот так это выглядит в виде графиков.

Теперь стоит хотя бы из любопытства посмотреть как при фиксированном размере запроса (2D 100X100) ведет себя число прочитанных страниц в зависимости от размера страницы.


Хорошо заметны “ямы” в Z-order, соответствующие размерам 128, 256 и 512. И “ямки” в 192, 384, 768. Не такие уж и большие.
Как мы видим, разница может достигать 10%, но почти везде это в пределах статистической погрешности. Тем не менее везде кривая Гильберта ведёт себя лучше чем Z-кривая. Не сильно, но лучше. По-видимому, эти 10% и есть оценка сверху потенциального эффекта, которого можно достичь, перейдя на кривую Гильберта. Стоит ли овчинка выделки? Попробуем узнать.
Реализация.
Использование кривой Гильберта в пространственном поиске сталкивается с рядом трудностей. Например, само вычисление ключа из 3 координат занимает (у автора) около 1000 тактов, примерно в 20 раз больше, чем то же для zcurve. Возможно, существует какой то более эффективный метод, кроме того есть мнение, что уменьшение числа прочитанных страниц окупает любое усложнение работы. Т.е. диск — более дорогой ресурс чем процессор. Поэтому мы будем в первую очередь ориентироваться именно на чтения буферов, а времена просто примем к сведению.
Что касается алгоритма поиска. Вкратце, он базируется на двух идеях —
- Индекс представляет собой B-дерево с его страничной организацией. Если мы хотим логарифмического доступа к первому элементу выдачи, то должны подобно бинарному поиску использовать стратегию “разделяй и властвуй”. Т.е. необходимо на каждой итерации в среднем поровну делить запрос на подзапросы.
Но в отличие от бинарного поиска в нашем случае разбиение не делит пополам число располагаемых элементов, а происходит по геометрическому принципу.
Из самоподобия заметающих кривых следует, что если взять квадратную (кубическую) решетку, выходящую из начала координат с шагом в степень двойки, то любой элементарный куб в этой решетке содержит один интервал значений. Следовательно, рассекая поисковый запрос по узлам этой решетки можно разбить исходный произвольный подзапрос на непрерывные интервалы. После чего каждый из этих интервалов вычитывается из дерева. - Если этот процесс не остановить, он порежет исходный запрос вплоть до интервалов из одного элемента, это не то, чего бы нам хотелось. Критерий остановки таков — запрос режется на подзапросы до тех пор, пока целиком не умещается на одной странице B-дерева. Как только уместился — проще прочитать страницу целиком и отфильтровать ненужное. Как узнать что уместились? У нас есть минимальная и максимальная точки подзапроса, равно как и текущая и последняя точки страницы.
Ведь в начале обработки подзапроса мы делаем поиск в B-дереве минимальной точки подзапроса и получаем листовую страницу, на которой остановился поиск и текущее положение в ней.
Всё это одинаково справедливо и для кривой Гильберта и для Z-order. Однако:
- для кривой Гильберта нарушен порядок — левая нижняя точка запроса вовсе не обязательно меньше правой верхней (для двумерного случая)
- мало того, совершенно не обязательно максимум и/или минимум подзапроса находится в одном из его углов, он необязательно вообще лежит в пределах запроса
- следовательно, настоящий диапазон значений может быть гораздо шире поискового запроса, в худшем случае, это весь экстент слоя, если вам удалось попасть в область вокруг центра
Это приводит к тому, что необходимо модифицировать исходный алгоритм.
Для начала изменился интерфейс работы с ключом.
- bitKey_limits_from_extent — этот метод вызывается один раз в начале поиска для определения настоящих границ поиска. На вход принимает координаты поискового экстента, отдаёт минимальное и максимальное значения диапазона поиска.
- bitKey_getAttr — на вход принимает интервал значений подзапроса и также исходные координаты поискового запроса. Возвращает маску из следующих значений
- baSolid — этот подзапрос целиком лежит внутри поискового экстента, его не надо расщеплять, а можно значения из интервала целиком помещать в выдачу
- baReadReady — минимальный ключ интервала подзапроса лежит внутри поискового экстента, можно делать поиск в B-дереве. В случае zcurve этот бит взводится всегда.
- baHasSmth — если этот бит не взведён, данный подзапрос целиком расположен вне поискового запроса и должен быть проигнорирован. В случае Z-order этот бит взводится всегда.
Модифицированный алгоритм поиска выглядит так:
- Заводим очередь подзапросов, изначально в этой очереди один единственный элемент — экстент (а также минимальный и максимальный ключи диапазона), найденный с помощью вызова bitKey_limits_from_extent
- Пока очередь не пуста:
- Достаем элемент с вершины очереди
- Получаем информацию о нём с помощью bitKey_getAttr
- Если не взведен baHasSmth, игнорируем этот подзапрос
- Если взведен baSolid, вычитываем весь диапазон значений прямо в resultset и переходим к следующему подзапросу
- Если взведен baReadReady, выполняем поиск в B-дереве по минимальному значению в подзапросе
- Если не взведен baReadReady или для этого запроса не срабатывает критерий остановки (он не помещается на одной странице)
- Вычисляем минимальное и максимальное значения диапазона подзапроса
- Находим разряд ключа, по которому будем резать
- Получаем два подзапроса
- Помещаем их в очередь, сначала тот, что с бОльшими значениями, затем второй
Рассмотрим на примере запроса в экстенте [524000,0,484000 …525000,1000,485000].

Вот так выглядит исполнение запроса для Z-order — ничего лишнего.
Subqueries — все порождённые подзапросы, results — найденные точки,
lookups — запросы к B-дереву.

Поскольку диапазон пересекает 0x80000, стартовый экстент получается размером в весь экстент слоя. Всё самое интересное слилось в центре, рассмотрим поподробнее.

Обращают на себя внимание «скопления» подзапросов на границах. Механизм их возникновения примерно таков — допустим, очередной разрез отсёк от границы поискового экстента узкую полоску, например, шириной 3. Причем, в этой полоске даже нет точек, но мы то этого не знаем. А проверить сможем только в тот момент, когда минимальное значение диапазона подзапроса попадёт в пределы поискового экстента. В результате алгоритм станет резать полоску вплоть до подзапросов размером в 2 и 1 и только тогда сможет сделать запрос к индексу чтобы убедиться, что там ничего нет. Или есть.
На число прочитанных страниц это не влияет, все такие проходы по В-дереву приходятся на кэш, но объем проделанной работы впечатляет.
Ну что же, осталось выяснить сколько в действительности было прочитано страниц и сколько времени всё это заняло. Следующие значения получены на тех же данных и тем же способом, что и ранее. Т.е. 100 000 000 случайных точек в [0...1 000 000, 0...0, 0...1 000 000].
Замеры проводились на скромной виртуальной машине с двумя ядрами и 4 Гб ОЗУ, поэтому времена не имеют абсолютной ценности, а вот числам прочитанных страниц по прежнему можно доверять.
Времена показаны на вторых прогонах, на разогретом сервере и виртуальной машине. Количества прочитанных буферов — на свеже-поднятом сервере.
| NPoints | Nreq | Type | Time(ms) | Reads | Hits |
|---|---|---|---|---|---|
| 1 | 100 000 | zcurve rtree hilbert |
.36 .38 .63 |
1.13307 1.83092 1.16946 |
3.89143 3.84164 88.9128 |
| 10 | 100 000 | zcurve rtree hilbert |
.38 .46 .80 |
1.57692 2.73515 1.61474 |
7.96261 4.35017 209.52 |
| 100 | 100 000 | zcurve rtree hilbert |
.48 .50 … 7.1 * 1.4 |
3.30305 6.2594 3.24432 |
31.0239 4.9118 465.706 |
| 1 000 | 100 000 | zcurve rtree hilbert |
1.2 1.1 … 16 * 3.8 |
13.0646 24.38 11.761 |
165.853 7.89025 1357.53 |
| 10 000 | 10 000 | zcurve rtree hilbert |
5.5 4.2 … 135 * 14 |
65.1069 150.579 59.229 |
651.405 27.2181 4108.42 |
| 100 000 | 10 000 | zcurve rtree hilbert |
53.3 35...1200 * 89 |
442.628 1243.64 424.51 |
2198.11 186.457 12807.4 |
| 1 000 000 | 1 000 | zcurve rtree hilbert |
390 300…10000* 545 |
3629.49 11394 3491.37 |
6792.26 3175.36 36245.5 |
Npoints — среднее число точек в выдаче
Nreq — число запросов в серии
Type — ‘zcurve’ — исправленный алгоритм с гиперкубами и разбором numeric, используя его внутреннюю структуру,;’rtree’- gist only 2D rtree; ‘hilbert’ — тот же алгоритм что и для zcurve, но для кривой Гильберта, (*) — для того, чтобы сравнить время поиска приходилось уменьшать серию в 10 раз для того, чтобы страницы умещались в кэш
Time(ms) — среднее время выполнения запроса
Reads — среднее число чтений на запрос. Самая важная колонка.
Shared hits — число обращений к буферам
* — разброс значений вызван высокой нестабильностью результатов, если нужные буфера успешно находились в кэше, то наблюдалось первое число, в случае массовых промахов — второе. Фактически, второе число характерно для заявленного Nreq, первое — в 5-10 раз меньшего.
Выводы
Немного удивляет, что “наколеночная” оценка преимуществ кривой Гильберта дала довольно точную оценку реального положения дел.
Видно, что на запросах, где размер выдачи соизмерим или более размера страницы, кривая Гильберта начинает вести себя лучше по числу промахов мимо кэша. Выигрыш, впрочем, составляет единицы процентов.
С другой стороны, интегральное время работы для кривой Гильберта примерно вдвое хуже оного у Z-кривой. Допустим, автор выбрал не самый эффективный способ вычисления кривой, допустим, что-то можно было сделать поаккуратнее. Но ведь вычисление кривой Гильберта объективно тяжелее Z-кривой, для работы с ней действительно надо предпринимать существенно больше действий. Ощущение такое, что отыграть это замедление с помощью нескольких процентов выигрыша в чтении страниц не удастся.
Да, можно сказать, что в высококонкурентной среде каждое чтение страницы обходится дороже десятков тысяч вычислений ключа. Но ведь число успешных попаданий в кэш у кривой Гильберта заметно больше, а они проходят через сериализацию и в конкурентной среде тоже чего-то стоят.
Итого
Вот и подошло к концу эпическое повествование о возможности и особенностях пространственных и/или многомерных индексов на основе самоподобных заметающих кривых, построенных на B-деревьях.
За это время (кроме того, что такой индекс реализуем) мы выяснили что по сравнению с традиционно применяемым в данной области R-деревом
- он компактнее (объективно — за счет лучшей средней заполняемости страниц)
- быстрее строится
- не использует эвристик (т.е. это именно алгоритм)
- не боится динамических изменений
- на малых и средних запросах работает быстрее.
Проигрывает на больших запросах (только при избытке памяти под кэш страниц) — там, где выдаче участвуют сотни страниц.
При этом R-дерево работает быстрее т.к. фильтрация происходит только на периметре, обработка которого заметающими кривыми заметно тяжелее.
В обычных условиях конкуренции за память и на таких запросах наш индекс заметно быстрее R-дерева. - Без изменения алгоритма работает с ключами любой (разумной) размерности
- При этом возможно применение разнородных данных в одном ключе, например, времени, класса объекта и координат. При этом не надо настраивать никаких эвристик, в худшем случае, если диапазоны данных сильно различается, просядет производительность.
- Пространственные объекты ((многомерные) интервалы) трактуются как точки, пространственная семантика обрабатывается в границах поисковых экстентов.
- Допускается смешение интервальных и точных данных в одном ключе, опять же вся семантика выносится наружу, алгоритм не меняется
- Всё это не требует вмешательства в синтаксис SQL, введения новых типов, …
Если хочется, можно написать обёртывающее расширение PostgreSQL. - И да, выложено под лицензией BSD, допускающей почти полную свободу действий.
