
Минувшее десятилетие приучило нас к удобствам облачных служб. Облака — это пьянящая возможность в любой момент обзавестись новым сервером. Следующий шаг, дающий новые удобства — платформы, которые предоставляют сервисы более высокого уровня: очереди, API, шлюзы, средства аутентификации. На очереди — всеобщее бессерверное счастье?

Фотография с выставки «Искусство LEGO»
У многих бессерверные вычисления ассоциируются с существующими платформами, представляющими услуги в формате «функция как сервис» (function-as-a-servise, FaaS), что вполне понятно. Многих эти платформы разочаровывают, заставляют с подозрением смотреть на всё «бессерверное». Однако, это — слишком узкий взгляд на вещи.
Сегодня я расскажу о том, как развитие бессерверных платформ уже совсем скоро изменит наше отношение к ним. Я покажу три волны универсальных бессерверных технологий и продемонстрирую их взаимодействие, которое направлено на предоставление гораздо более широких возможностей, нежели FaaS-продукты.
Бессерверные технологии — это всегда абстракция уровня сервиса, иллюзия, созданная ради удобств конечного пользователя. Аппаратное обеспечение при этом, естественно, никуда не девается. По сути, можно выделить две определяющие характеристики бессерверных технологий: невидимая инфраструктура вместо настраиваемых образов виртуальных машин? и схема оплаты, основанная на фактически потребляемых ресурсах вместо фиксированной почасовой ставки.
Всё это не так уж и таинственно, как может показаться на первый взгляд — большинство облачных сервисов уже работают по бессерверному принципу. При использовании базовых служб вроде AWS S3 или Azure Storage, вы оплачиваете объём хранимых данных (то есть, стоимость используемого дискового пространства), число операций ввода-вывода (стоимость вычислительных ресурсов, необходимых для организации доступа к данным), и объём переданных данных (стоимость использования сетевых каналов). Всё это держится на аппаратных серверах, но их мощности разделены между сотнями или тысячами потребителей, которые попросту не задумываются об этом аспекте работы подобных систем.
Многих разработчиков смущает идея выполнения их кода в бессерверной среде, другими словами, им непривычна мысль об универсальных бессерверных вычислениях.
Как я узнаю, что мой код начнёт работать? Как отлаживать и мониторить окружение? Как поддерживать ПО сервера в актуальном состоянии?
Это вполне понятные реакции и вопросы. Все эти проблемы, не имеющие отношения к функционалу, нужно решить, прежде чем заводить разговор о том, что такое хорошая бессерверная архитектура. Посмотрим теперь, что уже в этой сфере сделано.
Первыми вышедшими на рынок системами для организации бессерверных вычислений стали FaaS-платформы. Среди примеров — AWS Lambda и Azure Functions. И там и там можно размещать фрагменты кода, которые вызывают по требованию. Приложений, как таковых, тут нет. Разработчик пишет функции, фрагменты приложения, и задаёт правила, основанные на событиях, которые вызывают код в нужные моменты. Например: «Запусти X, когда придёт HTTP-запрос по адресу /foo», «Вызови Y, когда в этой очереди окажется сообщение». И так далее.
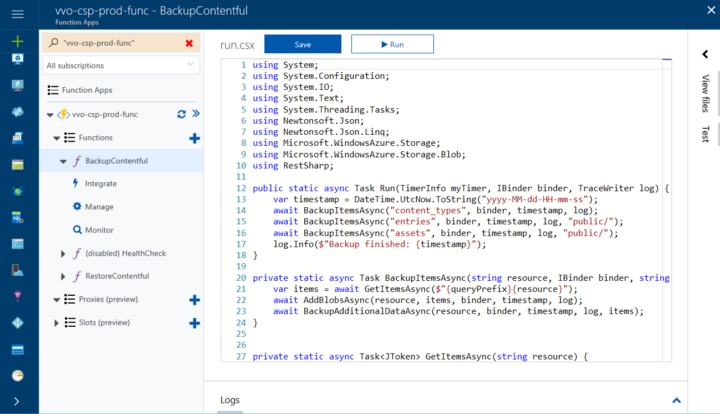
Функции могут быть довольно простыми. Например, состоящими из вызовов нескольких методов для выполнения простой задачи
Разработчик ничего не знает о сервере, не заботится о нём. Код просто работает. При этом оплачивать приходится лишь те доли секунды, которыми исчисляется использование функциями ресурсов систем провайдера. То, как часто будет вызываться функция — раз в день, или миллион раз в час — значения не имеет, так как вопросы масштабирования решаются без участия разработчика.
Итак, FaaS — это, определённо, бессерверные технологии, но сами по себе они погоды не сделают. Это так по нескольким причинам
Всё это — проблемы архитектурного характера.
Кроме того, существуют и чисто инструментальные сложности, которые делают использование FaaS в некоторых сценариях очень неудобным. Я не особенно беспокоюсь о сложностях такого характера, так как инструменты постоянно улучшаются. Не так быстро как хотелось бы, но если именно это не даёт вам приступить к работе с FaaS, уверен, эти проблемы скоро решат. Главный вопрос тут в том, когда это произойдёт.
Если ваши отношения с FaaS-системами не сложились из-за того, что ваш рабочий процесс просто не влезает в модель маленьких фрагментов кода, исполняемых по событиям, это означает одно из двух. Либо ваш проект требует более сложной организации, либо вам нужно, чтобы программа выполнялась непрерывно — или в течение некоего значительного периода времени, что, в сущности, одно и то же.
Проекты, имеющие сложную организацию, впервые охватили такие продукты, как Azure Logic Apps и AWS Step Functions. Они позволяют разработчику, с использованием графического интерфейса, создавать блок-схемы, которые описывают длительные процессы. С помощью схем можно задавать порядок вызова функций, встраивать собственный функционал во фреймворк, организующий управление процессом.

Создание приложения в Azure Logic APP, которое, при появлении обновлений в CRM-системе отправляет их для дальнейшей обработки. Управление сложным асинхронным процессом, объединяющим различные системы, сведено к описанию необходимых шагов.
Платформы для организации схем взаимодействия сложных систем упрощают разработку. Например, если некий код, скажем, имеющий отношение к отзывам об электронном магазине, нужно запускать через 24 часа после покупки товара, достаточно добавить в схему соответствующую задачу. Нужно произвести некое действие, если кто-то упомянул ваш продукт в Твиттере? Чтобы это организовать, достаточно пары щелчков мышью. Ни о запросах к API Твиттера, ни о том, как реагировать на ответы, думать не нужно. Готовые к использованию блоки не только облегчают проблемы организации программ, но и устраняют необходимость писать клиентский код для большинства распространённых сервисов.
В то время как подход с использованием схем отлично подходит для моделирования бизнес-процессов, он не позволяет перенести все нагрузки на бессерверные платформы. Это — не панацея. Например, по-настоящему сложное дерево решений, представленное в виде блок-схемы, выглядит весьма неуклюжим, работать с ним не удобно. Обычный программный код в подобной ситуации отличается большей выразительностью. Кроме того, модель оплаты подобных сервисов, основанная на подсчёте шагов в схемах, делает частые запросы и разбиение задач на слишком мелкие части дорогим удовольствием.
Короче говоря, ни подход с использованием функций, ни применение схем, не дают достойного решения задачи организации работы непрерывно выполняющихся сложно устроенных приложений. На первый взгляд, перед нами не слишком серьёзная проблема, касающаяся лишь достаточно узкой сферы применения бессерверных вычислений. Однако, всё меняет один простой факт: приложения, созданные за последние несколько десятилетий, спроектированы, по крайней мере отчасти, как непрерывно выполняющиеся задачи. Поэтому — пришло время третьей волны бессерверных технологий.
Технологии контейнеризации приложений пришли в массы несколько лет назад, преимущественно, благодаря популярности Docker. Приход этих технологий оказался весьма заметным. Контейнеры можно рассматривать как следующее поколение виртуальных машин. Поначалу в центре внимания разработчиков систем контейнеризации была экосистема Linux, однако, теперь можно говорить и о поддержке Windows. Кроме того, становятся всё более распространёнными платформы для управления контейнерами, такие, как Mesosphere и Cubernetes.
Самое важное, что надо учитывать, говоря о контейнерах, заключается в том, что их нельзя считать обычной заменой виртуальных машин более легковесной абстракцией. Контейнеры — это ещё и универсальный механизм упаковки приложений. Если приложению на Node.js нужна особая конфигурация Nginx, её достаточно настроить в контейнере. Если веб-сайт на ASP.NET задействует фоновый Windows Service, соответствующий слой можно встроить в образ контейнера.
Тут может возникнуть вопрос: «Итак, использование контейнеров, очевидно, рассматривается как средство для упаковки приложений, но при чём тут бессерверные технологии? Контейнеры — это, в сущности, просто упакованные мини-серверы, которые исполняются на хосте контейнеров. Это ведь, в сущности, просто разновидность серверов! Так ведь получается, что контейнеры — это чуть ли не враги бессерверных технологий!».
Хороший вопрос, на самом деле. Я уверен, что в контейнерных архитектурах есть два элемента, правильная организация которых позволит контейнерам внести вклад в бессерверные платформы. Это — бессерверный хостинг контейнеров и автоматическое обслуживание контейнеров.
Кластеры контейнеров — это эффективная массовая хостинговая платформа. Контейнеры, в сравнении с виртуальными машинами, могут реально повысить плотность размещения рабочей нагрузки.
Однако, для перехода к бессерверным технологиям, нужно забыть о модели постоянно работающей, ожидающей заданий виртуальной машины. Нам нужен биллинг, основанный на вызовах, на детальном измерении потребляемых ресурсов.
Первое массовое предложение, реализующее подобное — это Azure Container Instances, предварительная версия этого сервиса увидела свет в июле 2017-го. Это решение позволяет вызывать контейнеры по требованию, без необходимости думать об инфраструктуре, на которой они будут выполняться. Хотите развернуть экземпляр контейнера на одном виртуальном процессоре с двумя гигабайтами памяти?
Дело сделано. В оплату включат $0.0025 за вызов контейнера, плюс — $0.0000125 в секунду за гигабайт и процессорное ядро. Таким образом, если запустить это на 10 секунд, с вас возьмут $0.002875. Если делать это ежечасно в течение месяца, стоимость услуги составит $2.07.
Перед нами — микробиллинг в действии, и такая модель оплаты может быть, на самом деле, очень эффективной. Вам не нужно иметь виртуальную машину для пакетных задач, а если срочно понадобится большой объём ресурсов, бессерверный контейнер обеспечит их за считанные секунды, вместо значительно более длительного времени, которое нужно на запуск кластера виртуальных машин.
Но даже учитывая возможность удобного хостинга бессерверных контейнеров, у нас всё ещё остаётся дилемма о контейнерах, содержащих сервера, то есть, вопрос: «Как обновить ОС в базовом образе?».
Одна из догм бессерверных технологий заключается в том, чтобы позволить разработчику сосредоточиться на функционале, а не на обслуживании инфраструктуры. Контейнеры — отличный инструмент, однако по определению, они идут с некоторой дополнительной нагрузкой в виде поддержки контейнеризованного окружения.
Вы создаёте приложение, выбирая базовый образ операционной системы, добавляя к этому образу слои с различными необходимыми сервисами, и, наконец, внедряя в образ ваше приложение. Выпуская новую версию, вы просто пересобираете образ контейнера. Однако, тут остаётся вопрос. Учитывая то, что ОС и зависимости встроены в образ, как они будут обновляться? Как свежий патч Windows или новое исправление безопасности ядра Linux попадёт в работающее приложение?
Размышления о вопросах вроде этого идут вразрез с природой бессерверных вычислений. Обслуживание зависимостей среды — это не то, чем должен заниматься бессерверный разработчик, поэтому данную задачу следует автоматизировать.
Однако, граница между обслуживанием окружения и принятием критически важных решений размыта. Например, типичному веб-сайту пойдёт на пользу обновление операционной системы, ничего опасного в этом действии вроде бы не найти. Но где провести границу между автоматикой и решениями, которые принимает человек? Должен ли веб-сервер обновляться без вашего ведома? Надо ли, например, автоматически ставить новую версию Node.js?
Это каверзная проблема, одна из тех, которые нельзя обойти вниманием. В продолжение этого обсуждения рекомендую послушать несколько минут интервью со Стивом Ласкером из Microsoft (.NET Rocks #1459, примерно 37-я минута).
Тут можно очень долго рассуждать, это выходит за рамки данного материала, однако, попробуйте представить себе будущее, которое выглядит так:
При таком подходе неожиданно оказывается, что контейнеризованные серверы становятся прямо таки образцом бессерверных вычислений. Мы пока ещё не доросли до сервиса такого уровня, но это — путь развития индустрии.
Контейнеры позволяют организовывать гораздо более сложные рабочие нагрузки, чем простые FaaS-фреймворки, оперирующие небольшими фрагментами кода. Контейнеры смягчают побочные эффекты работы с зависимостями. Они оказываются гораздо более сильно, нежели другие технологии, нацеленными на решение задач разработчика.
В заголовке этого материала есть вопрос: «Когда...». Думаю, вполне очевидный ответ: «не сейчас». В существующих платформах бессерверных вычислений пока достаточно недочётов.
Например, выполнение контейнерной нагрузки в режиме 24/7 на Azure Container Instances оказывается слишком дорогим удовольствием. Для такой задачи лучше подойдёт виртуальная машина. Полная автоматизация обновления ОС в виртуальной машине — ещё одна сложная задача. И автоматизации обслуживания контейнеров тоже пока не видно. Далее, логирование и мониторинг в FaaS-продуктах — постоянная головная боль разработчиков, которые пользуются AWS или Azure. А как насчёт достойной поддержки контейнеров Windows? «Мы над этим работаем», — пока ничего другого в ответ не услышать.
Однако, инструменты улучшаются очень быстро. И бессерверные вычисления, основанные на функциях, и системы, основанные на блок-схемах, серьёзно продвинулись за последний год. Контейнерные технологии всё ещё в стадии активной разработки, но их востребованность делает своё дело.
Далее, понятие разделения нагрузки на небольшие части, понятие микросервисов, тесно связано с идеей бессерверных технологий. Для того, чтобы извлечь максимальную пользу из возможностей бессерверных фреймворков по управлению рабочими нагрузками, неплохо было бы сначала найти эти рабочие нагрузки. Это ещё одна область, в которой ведётся интенсивная разработка. Службы вроде Azure Event Grid позволяют создавать связи между различными бессерверными платформами.
Например, можно связать AWS Lambda и Azure Logic Apps, а, при возникновении неких событий, запускать контейнер. Всё это, в общем-то, из той же оперы: маленькие, основанные на событиях, направленные на решение конкретной проблемы рабочие нагрузки действуют совместно для решения большой задачи.
Когда наступит то будущее, о котором мы тут рассуждаем, на новых платформах можно будет размещать даже приложения предыдущих поколений, которые теперь будут гораздо меньше зависеть от инфраструктуры. Кроме того, стоит отметить, что переход к бессерверным вычислениям потребует нового подхода к проектированию приложений, даже довольно современных, рассчитанных на работу в облаке.
В целом можно сказать, что индустрия бессерверных технологий динамично развивается и в будущем нас ожидает много нового и интересного.
Уважаемые читатели! Используете ли вы бессерверные вычисления?

Фотография с выставки «Искусство LEGO»
У многих бессерверные вычисления ассоциируются с существующими платформами, представляющими услуги в формате «функция как сервис» (function-as-a-servise, FaaS), что вполне понятно. Многих эти платформы разочаровывают, заставляют с подозрением смотреть на всё «бессерверное». Однако, это — слишком узкий взгляд на вещи.
Сегодня я расскажу о том, как развитие бессерверных платформ уже совсем скоро изменит наше отношение к ним. Я покажу три волны универсальных бессерверных технологий и продемонстрирую их взаимодействие, которое направлено на предоставление гораздо более широких возможностей, нежели FaaS-продукты.
О понятии «бессерверные технологии»
Бессерверные технологии — это всегда абстракция уровня сервиса, иллюзия, созданная ради удобств конечного пользователя. Аппаратное обеспечение при этом, естественно, никуда не девается. По сути, можно выделить две определяющие характеристики бессерверных технологий: невидимая инфраструктура вместо настраиваемых образов виртуальных машин? и схема оплаты, основанная на фактически потребляемых ресурсах вместо фиксированной почасовой ставки.
Всё это не так уж и таинственно, как может показаться на первый взгляд — большинство облачных сервисов уже работают по бессерверному принципу. При использовании базовых служб вроде AWS S3 или Azure Storage, вы оплачиваете объём хранимых данных (то есть, стоимость используемого дискового пространства), число операций ввода-вывода (стоимость вычислительных ресурсов, необходимых для организации доступа к данным), и объём переданных данных (стоимость использования сетевых каналов). Всё это держится на аппаратных серверах, но их мощности разделены между сотнями или тысячами потребителей, которые попросту не задумываются об этом аспекте работы подобных систем.
Многих разработчиков смущает идея выполнения их кода в бессерверной среде, другими словами, им непривычна мысль об универсальных бессерверных вычислениях.
Как я узнаю, что мой код начнёт работать? Как отлаживать и мониторить окружение? Как поддерживать ПО сервера в актуальном состоянии?
Это вполне понятные реакции и вопросы. Все эти проблемы, не имеющие отношения к функционалу, нужно решить, прежде чем заводить разговор о том, что такое хорошая бессерверная архитектура. Посмотрим теперь, что уже в этой сфере сделано.
Первая волна: событийно-зависимые вычисления
Первыми вышедшими на рынок системами для организации бессерверных вычислений стали FaaS-платформы. Среди примеров — AWS Lambda и Azure Functions. И там и там можно размещать фрагменты кода, которые вызывают по требованию. Приложений, как таковых, тут нет. Разработчик пишет функции, фрагменты приложения, и задаёт правила, основанные на событиях, которые вызывают код в нужные моменты. Например: «Запусти X, когда придёт HTTP-запрос по адресу /foo», «Вызови Y, когда в этой очереди окажется сообщение». И так далее.

Функции могут быть довольно простыми. Например, состоящими из вызовов нескольких методов для выполнения простой задачи
Разработчик ничего не знает о сервере, не заботится о нём. Код просто работает. При этом оплачивать приходится лишь те доли секунды, которыми исчисляется использование функциями ресурсов систем провайдера. То, как часто будет вызываться функция — раз в день, или миллион раз в час — значения не имеет, так как вопросы масштабирования решаются без участия разработчика.
Итак, FaaS — это, определённо, бессерверные технологии, но сами по себе они погоды не сделают. Это так по нескольким причинам
- Не все рабочие нагрузки сводятся к модели, где выполнение отдельных операций вызывают некие события.
- Далеко не всегда можно чисто отделить код от его зависимостей. Некоторые зависимости могут потребовать серьёзных ресурсов на установку и настройку.
- Язык, на котором вы ведёте разработку и (или) парадигма программирования могут не поддерживаться FaaS-платформой.
- Перевод существующего приложения на модель FaaS обычно настолько сложен, что оказывается финансово нецелесообразным.
Всё это — проблемы архитектурного характера.
Кроме того, существуют и чисто инструментальные сложности, которые делают использование FaaS в некоторых сценариях очень неудобным. Я не особенно беспокоюсь о сложностях такого характера, так как инструменты постоянно улучшаются. Не так быстро как хотелось бы, но если именно это не даёт вам приступить к работе с FaaS, уверен, эти проблемы скоро решат. Главный вопрос тут в том, когда это произойдёт.
Вторая волна: схемы рабочих потоков
Если ваши отношения с FaaS-системами не сложились из-за того, что ваш рабочий процесс просто не влезает в модель маленьких фрагментов кода, исполняемых по событиям, это означает одно из двух. Либо ваш проект требует более сложной организации, либо вам нужно, чтобы программа выполнялась непрерывно — или в течение некоего значительного периода времени, что, в сущности, одно и то же.
Проекты, имеющие сложную организацию, впервые охватили такие продукты, как Azure Logic Apps и AWS Step Functions. Они позволяют разработчику, с использованием графического интерфейса, создавать блок-схемы, которые описывают длительные процессы. С помощью схем можно задавать порядок вызова функций, встраивать собственный функционал во фреймворк, организующий управление процессом.
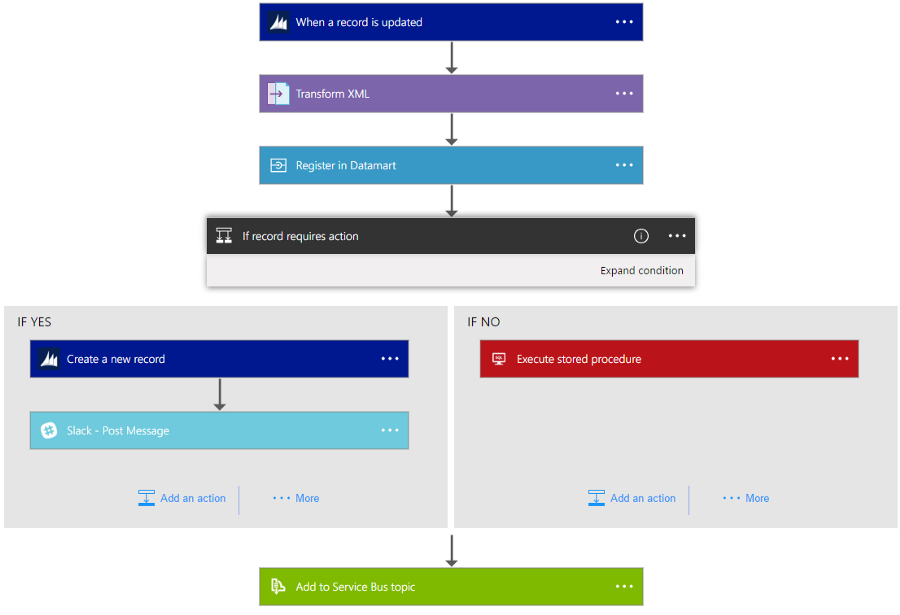
Создание приложения в Azure Logic APP, которое, при появлении обновлений в CRM-системе отправляет их для дальнейшей обработки. Управление сложным асинхронным процессом, объединяющим различные системы, сведено к описанию необходимых шагов.
Платформы для организации схем взаимодействия сложных систем упрощают разработку. Например, если некий код, скажем, имеющий отношение к отзывам об электронном магазине, нужно запускать через 24 часа после покупки товара, достаточно добавить в схему соответствующую задачу. Нужно произвести некое действие, если кто-то упомянул ваш продукт в Твиттере? Чтобы это организовать, достаточно пары щелчков мышью. Ни о запросах к API Твиттера, ни о том, как реагировать на ответы, думать не нужно. Готовые к использованию блоки не только облегчают проблемы организации программ, но и устраняют необходимость писать клиентский код для большинства распространённых сервисов.
В то время как подход с использованием схем отлично подходит для моделирования бизнес-процессов, он не позволяет перенести все нагрузки на бессерверные платформы. Это — не панацея. Например, по-настоящему сложное дерево решений, представленное в виде блок-схемы, выглядит весьма неуклюжим, работать с ним не удобно. Обычный программный код в подобной ситуации отличается большей выразительностью. Кроме того, модель оплаты подобных сервисов, основанная на подсчёте шагов в схемах, делает частые запросы и разбиение задач на слишком мелкие части дорогим удовольствием.
Короче говоря, ни подход с использованием функций, ни применение схем, не дают достойного решения задачи организации работы непрерывно выполняющихся сложно устроенных приложений. На первый взгляд, перед нами не слишком серьёзная проблема, касающаяся лишь достаточно узкой сферы применения бессерверных вычислений. Однако, всё меняет один простой факт: приложения, созданные за последние несколько десятилетий, спроектированы, по крайней мере отчасти, как непрерывно выполняющиеся задачи. Поэтому — пришло время третьей волны бессерверных технологий.
Третья волна: технологии контейнеризации
Технологии контейнеризации приложений пришли в массы несколько лет назад, преимущественно, благодаря популярности Docker. Приход этих технологий оказался весьма заметным. Контейнеры можно рассматривать как следующее поколение виртуальных машин. Поначалу в центре внимания разработчиков систем контейнеризации была экосистема Linux, однако, теперь можно говорить и о поддержке Windows. Кроме того, становятся всё более распространёнными платформы для управления контейнерами, такие, как Mesosphere и Cubernetes.
Самое важное, что надо учитывать, говоря о контейнерах, заключается в том, что их нельзя считать обычной заменой виртуальных машин более легковесной абстракцией. Контейнеры — это ещё и универсальный механизм упаковки приложений. Если приложению на Node.js нужна особая конфигурация Nginx, её достаточно настроить в контейнере. Если веб-сайт на ASP.NET задействует фоновый Windows Service, соответствующий слой можно встроить в образ контейнера.
Тут может возникнуть вопрос: «Итак, использование контейнеров, очевидно, рассматривается как средство для упаковки приложений, но при чём тут бессерверные технологии? Контейнеры — это, в сущности, просто упакованные мини-серверы, которые исполняются на хосте контейнеров. Это ведь, в сущности, просто разновидность серверов! Так ведь получается, что контейнеры — это чуть ли не враги бессерверных технологий!».
Хороший вопрос, на самом деле. Я уверен, что в контейнерных архитектурах есть два элемента, правильная организация которых позволит контейнерам внести вклад в бессерверные платформы. Это — бессерверный хостинг контейнеров и автоматическое обслуживание контейнеров.
Бессерверный хостинг контейнеров
Кластеры контейнеров — это эффективная массовая хостинговая платформа. Контейнеры, в сравнении с виртуальными машинами, могут реально повысить плотность размещения рабочей нагрузки.
Однако, для перехода к бессерверным технологиям, нужно забыть о модели постоянно работающей, ожидающей заданий виртуальной машины. Нам нужен биллинг, основанный на вызовах, на детальном измерении потребляемых ресурсов.
Первое массовое предложение, реализующее подобное — это Azure Container Instances, предварительная версия этого сервиса увидела свет в июле 2017-го. Это решение позволяет вызывать контейнеры по требованию, без необходимости думать об инфраструктуре, на которой они будут выполняться. Хотите развернуть экземпляр контейнера на одном виртуальном процессоре с двумя гигабайтами памяти?
az container create --name JouniDemo --image myregistry/nginx-based-demo:v2 --cpu 1 --memory 2 --registryДело сделано. В оплату включат $0.0025 за вызов контейнера, плюс — $0.0000125 в секунду за гигабайт и процессорное ядро. Таким образом, если запустить это на 10 секунд, с вас возьмут $0.002875. Если делать это ежечасно в течение месяца, стоимость услуги составит $2.07.
Перед нами — микробиллинг в действии, и такая модель оплаты может быть, на самом деле, очень эффективной. Вам не нужно иметь виртуальную машину для пакетных задач, а если срочно понадобится большой объём ресурсов, бессерверный контейнер обеспечит их за считанные секунды, вместо значительно более длительного времени, которое нужно на запуск кластера виртуальных машин.
Но даже учитывая возможность удобного хостинга бессерверных контейнеров, у нас всё ещё остаётся дилемма о контейнерах, содержащих сервера, то есть, вопрос: «Как обновить ОС в базовом образе?».
Обслуживание контейнеров и автоматизация
Одна из догм бессерверных технологий заключается в том, чтобы позволить разработчику сосредоточиться на функционале, а не на обслуживании инфраструктуры. Контейнеры — отличный инструмент, однако по определению, они идут с некоторой дополнительной нагрузкой в виде поддержки контейнеризованного окружения.
Вы создаёте приложение, выбирая базовый образ операционной системы, добавляя к этому образу слои с различными необходимыми сервисами, и, наконец, внедряя в образ ваше приложение. Выпуская новую версию, вы просто пересобираете образ контейнера. Однако, тут остаётся вопрос. Учитывая то, что ОС и зависимости встроены в образ, как они будут обновляться? Как свежий патч Windows или новое исправление безопасности ядра Linux попадёт в работающее приложение?
Размышления о вопросах вроде этого идут вразрез с природой бессерверных вычислений. Обслуживание зависимостей среды — это не то, чем должен заниматься бессерверный разработчик, поэтому данную задачу следует автоматизировать.
Однако, граница между обслуживанием окружения и принятием критически важных решений размыта. Например, типичному веб-сайту пойдёт на пользу обновление операционной системы, ничего опасного в этом действии вроде бы не найти. Но где провести границу между автоматикой и решениями, которые принимает человек? Должен ли веб-сервер обновляться без вашего ведома? Надо ли, например, автоматически ставить новую версию Node.js?
Это каверзная проблема, одна из тех, которые нельзя обойти вниманием. В продолжение этого обсуждения рекомендую послушать несколько минут интервью со Стивом Ласкером из Microsoft (.NET Rocks #1459, примерно 37-я минута).
Тут можно очень долго рассуждать, это выходит за рамки данного материала, однако, попробуйте представить себе будущее, которое выглядит так:
- Ваши контейнеры оснащены автоматизированной системой тестирования, которая проверяет ключевой функционал рабочей нагрузки.
- Платформа, на которой исполняется контейнер, знает подробности об обновлении базовой операционной системы (например, что-то вроде: «У Alpine Linux 14.1.5 имеется критическое обновление безопасности»).
- Платформа может самостоятельно проверить работоспособность контейнера после установки новых патчей. Когда происходит обновление базового образа, она может попытаться заблаговременно пересобрать контейнер приложения, запустить набор тестов и отправить вам отчёт о результатах.
- Вам доступно даже автоматическое обновление, основанное на правилах. Например: «Когда выйдет критическое обновление ОС, автоматически обновить образ работающего приложения в том случае, если ни один из тестов не будет провален».
При таком подходе неожиданно оказывается, что контейнеризованные серверы становятся прямо таки образцом бессерверных вычислений. Мы пока ещё не доросли до сервиса такого уровня, но это — путь развития индустрии.
Контейнеры позволяют организовывать гораздо более сложные рабочие нагрузки, чем простые FaaS-фреймворки, оперирующие небольшими фрагментами кода. Контейнеры смягчают побочные эффекты работы с зависимостями. Они оказываются гораздо более сильно, нежели другие технологии, нацеленными на решение задач разработчика.
Итоги
В заголовке этого материала есть вопрос: «Когда...». Думаю, вполне очевидный ответ: «не сейчас». В существующих платформах бессерверных вычислений пока достаточно недочётов.
Например, выполнение контейнерной нагрузки в режиме 24/7 на Azure Container Instances оказывается слишком дорогим удовольствием. Для такой задачи лучше подойдёт виртуальная машина. Полная автоматизация обновления ОС в виртуальной машине — ещё одна сложная задача. И автоматизации обслуживания контейнеров тоже пока не видно. Далее, логирование и мониторинг в FaaS-продуктах — постоянная головная боль разработчиков, которые пользуются AWS или Azure. А как насчёт достойной поддержки контейнеров Windows? «Мы над этим работаем», — пока ничего другого в ответ не услышать.
Однако, инструменты улучшаются очень быстро. И бессерверные вычисления, основанные на функциях, и системы, основанные на блок-схемах, серьёзно продвинулись за последний год. Контейнерные технологии всё ещё в стадии активной разработки, но их востребованность делает своё дело.
Далее, понятие разделения нагрузки на небольшие части, понятие микросервисов, тесно связано с идеей бессерверных технологий. Для того, чтобы извлечь максимальную пользу из возможностей бессерверных фреймворков по управлению рабочими нагрузками, неплохо было бы сначала найти эти рабочие нагрузки. Это ещё одна область, в которой ведётся интенсивная разработка. Службы вроде Azure Event Grid позволяют создавать связи между различными бессерверными платформами.
Например, можно связать AWS Lambda и Azure Logic Apps, а, при возникновении неких событий, запускать контейнер. Всё это, в общем-то, из той же оперы: маленькие, основанные на событиях, направленные на решение конкретной проблемы рабочие нагрузки действуют совместно для решения большой задачи.
Когда наступит то будущее, о котором мы тут рассуждаем, на новых платформах можно будет размещать даже приложения предыдущих поколений, которые теперь будут гораздо меньше зависеть от инфраструктуры. Кроме того, стоит отметить, что переход к бессерверным вычислениям потребует нового подхода к проектированию приложений, даже довольно современных, рассчитанных на работу в облаке.
В целом можно сказать, что индустрия бессерверных технологий динамично развивается и в будущем нас ожидает много нового и интересного.
Уважаемые читатели! Используете ли вы бессерверные вычисления?
