
Прим. Переводчика. Статья может быть интересна архитекторам и разработчикам, планирующим построение решения на основе микросервисов, либо ищущим способы оптимизации текущего решения, особенно если работа идет с большими объемами данных. Перевод сделан на основе части 1 и части 2 цикла статей о микросервисах на Apache Ignite. Предполагается общее знакомство с экосистемой Java (Apache Ignite работает также с .NET, C++, а через REST и с другими языками, но примеры в статье будут апеллировать к Java), рекомендуется наличие базового знания Spring.
Сегодня микросервисная архитектура — это один из наиболее популярных подходов, на основе которого многие компании строят свои решения. Одно из ключевых преимуществ этого подхода — то, что он предполагает разделение решения на набор слабо связанных компонентов — микросервисов, — каждый из которых может иметь собственный жизненный и релизный циклы, команду разработки и т.д. У этих компонентов всегда есть хотя бы один механизм обмена данными, посредством которого микросервисы взаимодействуют друг с другом. Более того они могут создаваться с использованием разных языков и технологий, наиболее подходящих конкретному модулю системы.
Если вы используете решения на основе микросервисной архитектуры там, где есть высокая нагрузка и необходимо работать с активно растущими массивами данных, скорее всего, вы сталкивались или столкнетесь с проблемами классических подходов:
- дисковые базы данных не справляются с нарастающими объемами информации, которую необходимо хранить и обрабатывать; базы данных становятся узким местом, в которое «упирается» ваше решение;
- требования к высокой доступности, которые когда-то были «вишенкой на торте», теперь являются необходимым минимумом для продукта, который хочет успешно конкурировать на рынке.
Цель этой статьи — рассказать, как вы можете решить эти проблемы в своем продукте, используя Apache Ignite (или GridGain In-Memory Data Fabric), чтобы построить отказоустойчивое и масштабируемое решение в микросервисной парадигме.
Разбор решения на базе Apache Ignite
Давайте рассмотрим типичную архитектуру микросервисного решения, которое использует Apache Ignite, приведенную на рисунке ниже.
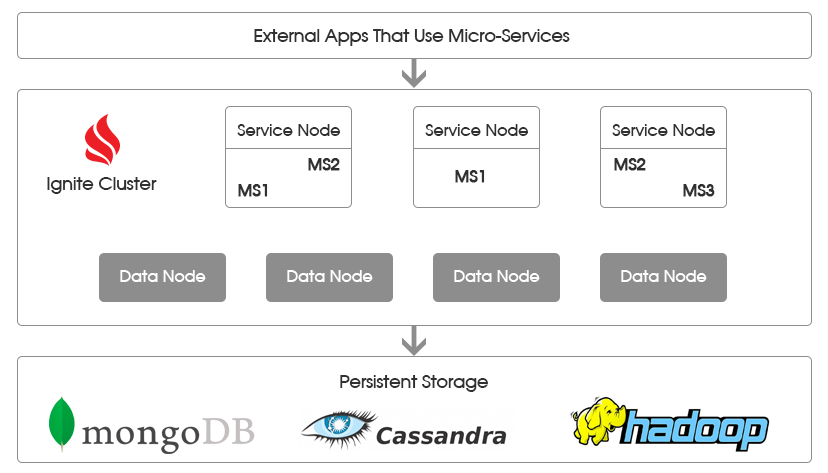
Слой кластера Apache Ignite
Кластер Apache Ignite используется для достижения 2 целей.
Во-первых, это основное хранилище данных, в котором они содержатся в оперативной памяти. Поскольку данные находятся в памяти, микросервису не нужно опосредованно через СУБД выполнять множество дорогостоящих обращений к диску, что значительно повышает общую производительность системы.
«Узлы данных» (data nodes) — особая группа в кластере, которая отвечает за хранение данных. Это «серверные» узлы Apache Ignite, которые хранят участки данных и позволяют исполнение на этих участках запросов получения данных и вычислений. При этом не требуется разворачивать классы данных и вычислений: Apache Ignite полагается на собственный кросс-платформенный бинарный формат, а также имеет механизмы обмена классами с логикой между узлами кластера (peer class loading).
Бинарный формат Apache Ignite используется для сериализации объектов и поддержки динамического обмена классами между узлами. Возможность подобного обмена логикой внутри кластера позволяет гибко управлять вычислениями, загружая необходимый код по требованию с отдельного слоя узлов сервисов, содержащего бизнес-логику.
Во-вторых, кластер управляет жизненным циклом микросервисов и предоставляет все необходимые для взаимодействия между ними и узлами данных API.
Для этого решения на основе кластера Apache Ignite используют Узлы сервисов (service nodes, сервисные узлы). Это узлы, где развернут код микросервисов, содержащий необходимую бизнес-логику. Отдельный узел может содержать один и более микросервис, в зависимости от особенностей конкретного решения.
Каждый микросервис реализует интерфейс Service, а также регистрируется в узле Apache Ignite, после чего внутренние механизмы кластера позволяют обеспечить отказоустойчивость и дают удобный механизм для вызова микросервиса из других частей кластера. Apache Ignite берет на себя заботу по развертыванию одной и более копий микросервиса на сервисных узлах. Внутренняя механика кластера также обеспечивает балансировку нагрузки и отказоустойчивость.
На вышеприведенном рисунке микросервисы помечены как MS<N> (MS1, MS2 и т.д.). За счет разнесения логики между сервисными узлами и узлами данных исчезает необходимость перезапускать весь кластер, если микросервис MS1 необходимо обновить. Все, что необходимо сделать — обновить классы MS1 на сервисных узлах, где он развернут. Далее необходимо будет перезапустить только некоторое подмножество узлов, минимизируя потенциальное влияние на систему.
Все узлы (сервисов и данных) связаны между собой в единый кластер, что позволяет MS1, развернутому на одном узле взаимодействовать с любым другим микросервисом, развернутым на другом (или том же самом) узле, а также получать или отправлять данные и вычисления на любые узлы данных.
Слой постоянного хранения данных
Этот слой не обязателен и может быть использован в сценариях, где:
- нет смысла либо невозможно держать все данные в памяти;
- необходимо иметь возможность восстановить данные с копии на диске в случае, если кластер упадет целиком, либо потребуется его перезапустить.
Чтобы использовать слой постоянного хранения данных, необходимо указать для Apache Ignite реализацию интерфейса CacheStore. Среди реализаций по-умолчанию можно найти различные реляционные СУБД, а также MongoDB, Cassandra и т.д.
Слой взаимодействия с внешними приложениями
Это слой «клиентов» ваших микросервисов, с этого слоя инициируются различные ветки исполнения путем вызова одного или более микросервисов.
Этот слой может общаться с вашими микросервисами с использованием протоколов, специфичных для конкретного микросервиса. При этом в рамках данного архитектурного решения микросервисы будут общаться между собой с использованием механизмов Apache Ignite.
Данная архитектура обеспечивает возможность горизонтального масштабирования, позволяет хранить данные в памяти и гарантирует высокую доступность (high availability) микросервисов.
Пример реализации
Далее рассмотрена возможная реализация первого слоя кластера Apache Ignite. Код, с которым будет происходить работа, можно посмотреть на: https://github.com/dmagda/MicroServicesExample.
В частности, будет показано, как можно:
- настраивать и запускать узлы данных;
- реализовывать сервисы с использованием Apache Ignite Service Grid API;
- настраивать и запускать сервисные узлы;
- создать приложение (в простейшей форме), которое подключается к кластеру и инициирует исполнение сервиса.
Узлы данных
Как было написано выше, узел данных — это серверный узел Apache Ignite, который содержит часть данных и позволяет выполнять запросы и вычисления, инициируемые со стороны бизнес-логики приложения. Узлы данных отвязаны от бизнес-логики и инкапсулируют в себе только механизмы хранения и обработки данных, принимая конкретные запросы по ним извне.
Давайте рассмотрим создание таких узлов на примере. Для этого вам потребуется скачать GitHub-проект, который упоминался ранее.
Найдите в проекте файл data-node-config.xml. Этот файл используется для запуска новых узлов данных. В нем можно увидеть определение кешей, которые должны быть развернуты на кластере, а также иные настройки, специфичные для узлов данных. Рассмотрим основные из них.
Прим. переводчика. XML-конфигурация Apache Ignite использует Spring для построения дерева объектов. Если читатель не знаком с конфигурацией Spring, необходимую информацию можно получить, например, из официальной документации (англ.) либо из каких-либо обучающих материалов. Естественно, возможно создание IgniteConfiguration напрямую, а также, поскольку используются механизмы Spring, построение конфигурации на основе аннотаций или диалекта Groovy.
Во-первых, в данной конфигурации для каждого кеша, к устанавливается фильтр, который определяет, какие узлы Apache Ignite будут содержать информацию. Данный фильтр будет накладываться при каждом изменении топологии, когда узлы присоединяются к кластеру либо покидают его. Реализация фильтра должна быть развернута на classpath всех узлов кластера, включая узлы, не являющиеся узлами данных, и быть доступна на classpath.
<bean class="org.apache.ignite.configuration.CacheConfiguration">
...
<property name="nodeFilter">
<bean class="common.filters.DataNodeFilter"/>
</property>
</bean>Во-вторых, реализуется класс фильтра, который мы определили выше. В данном примере применяется один из наиболее простых подходов, когда критерием того, будет ли узел отвечать за хранение данных, является атрибут узла “data.node”. Если этот атрибут установлен и равен true, узел будет считаться узлом данных и содержать на сете кеши. В ином случае, узел будет игнорироваться при распределении данных по кластеру.
public boolean apply(ClusterNode node) {
Boolean dataNode = node.attribute("data.node");
return dataNode != null && dataNode;
}В третьих, в конфигурации определяется значение параметра “data.node” для каждого узла, который будет использовать эту конфигурацию при запуске.
<property name="userAttributes">
<map key-type="java.lang.String" value-type="java.lang.Boolean">
<entry key="data.node" value="true"/>
</map>
</property>Попробуйте использовать класс DataNodeStartup, чтобы запустить узел данных, либо используйте ignite.sh или ignite.bat-скрипты, передав им как аргумент конфигурацию, определенную в data-node-config.xml. В последнем случае, не забудьте предварительно собрать JAR-файл, который будет содержать классы из java/app/common, и положить этот JAR-файл на classpath каждого узла данных.
Сервисные узлы
С точки зрения конфигурации сервисные узлы не сильно отличаются от узлов данных из предыдущего раздела. Аналогично необходимо определить критерий, согласно которому будет выделяться подмножество узлов Apache Ignite, но это подмножество будет отвечать уже не за хранение данных, но за работу микросервисов.
Для начала необходимо определить микросервис, используя Apache Ignite Service Grid API. В рамках статьи будет рассмотрен пример MaintenanceService, приложенный в репозитории на GitHub.
Интерфейс сервиса выглядит следующим образом:
public interface MaintenanceService extends Service {
public Date scheduleVehicleMaintenance(int vehicleId);
public List<Maintenance> getMaintenanceRecords(int vehicleId);
}Сервис позволяет планировать техническое обслуживание машины, а также получать список назначенных обслуживаний. Реализация, помимо бизнес-логики, содержит определение специфических для Service Grid методов, таких как init(…), execute(…) и cancel(…).
Есть несколько способов опубликовать данный микросервис на подмножестве кластера. Один из них, который будет использоваться в примере, — определить конфигурационный файл maintenance-service-node-config.xml, и запускать сервисные узлы с этим конфигурационным файлом и необходимыми классами на classpath. В таком случае конфигурация будет выглядеть следующим образом.
Для начала, определяется фильтр, который позволит отличать сервисные узлы от остальных.
<bean class="org.apache.ignite.services.ServiceConfiguration">
<property name="nodeFilter">
<bean class="common.filters.MaintenanceServiceFilter"/>
</property>
</bean>Реализация фильтра выглядит следующим образом:
public boolean apply(ClusterNode node) {
Boolean dataNode = node.attribute("maintenance.service.node");
return dataNode != null && dataNode;
}В данной реализации критерием служит наличие у узла атрибута “maintenance.service.node”, установленного в значение true.
Наконец, узлы будут получать этот атрибут за счет следующего участка конфигурации maintenance-service-node-config.xml:
<property name="userAttributes">
<map key-type="java.lang.String" value-type="java.lang.Boolean">
<entry key="maintenance.service.node" value="true"/>
</map>
</property>Прим. переводчика. Сам факт размещения сервиса задается нижеприведенным кодом из конфигурации. В serviceConfiguration перечисляются сервисы, которые могут теоретически быть развернуты на данном узле.
Свойство name сервиса отвечает за уникальное в рамках кластера наименование, по которому, например, к сервису можно будет обращаться через сервис-прокси, свойство service ссылается на класс, реализующий логику сервиса, а свойства totalCount и maxPerNodeCount обозначают общее количество экземпляров, которые необходимо поддерживать и максимально допустимое количество экземпляров на конкретном узле соответственно. В данном случае, сконфигурирован кластер-синглтон: в рамках несегментированного кластера всегда будет только 1 экземпляр сервиса.
<property name="serviceConfiguration">
<list>
<!--
Конфигурация MaintenanceService. Сервис будет автоматически
Развернут в соответствии с данной конфигурацией
-->
<bean class="org.apache.ignite.services.ServiceConfiguration">
<!-- Уникальное в рамках кластера имя сервиса -->
<property name="name" value="MaintenanceService"/>
<!-- Класс, реализующий сервис -->
<property name="service">
<bean class="services.maintenance.MaintenanceServiceImpl"/>
</property>
<!-- Количество экземпляров сервиса в рамках кластера -->
<property name="totalCount" value="1"/>
<!-- Количество экземпляров сервиса, которое можно размещать на узле -->
<property name="maxPerNodeCount" value="1"/>
…
</bean>
</list>
</property>Попробуйте запустить несколько экземпляров сервисных узлов используя MaintenanceServiceNodeStartup либо передавая maintenance-service-node-config.xml в ignite.sh или ignite.bat, предварительно положим все необходимые классы из java/app/common и java/services/maintenance на classpath каждого из узлов.
В репозитории на GitHub также можно найти пример сервиса VehicleService. Запустить экземпляры этого сервиса можно используя класс VehicleServiceNodeStartup, либо передав файл vehicle-service-node-config.xml в ignite.sh или ignite.bat, предварительно поместив все необходимые классы на classpath.
Пример приложения
Как только у нас настроены и готовы к запуску узлы данных, а также сервисные узлы с сервисами MaintenanceService и VehicleService, можно запустить наше первое приложение, которое будет использовать инфраструктуру распределенных микросервисов.
Для этого запустите файл TestAppStartup из репозитория GitHub. Приложение присоединится к кластеру, заполнит кеши данными и выполнит операции на развернутых микросервисах.
Код для выполнения операций на сервисе выглядит следующим образом:
MaintenanceService maintenanceService =
ignite.services().serviceProxy(
MaintenanceService.SERVICE_NAME,
MaintenanceService.class, false);
int vehicleId = rand.nextInt(maxVehicles);
Date date = maintenanceService.scheduleVehicleMaintenance(vehicleId);Как можно заметить, приложение работает с сервисами используя сервис-прокси. Прелесть данного подхода в том, что узел, играющий роль клиента, не обязан иметь классы реализации сервиса, развернутые локально на classpath — достаточно только интерфейсных классов, — а также не обязан иметь запущенным локально сам сервис: прокси обеспечит прозрачное взаимодействие с удаленной реализацией.
Заключение
В данной статье была рассмотрена архитектура, предполагающая использование микросервисов поверх Apache Ignite, а также был рассмотрен пример приложения, реализующего данную архитектуру. В следующих статьях будет рассмотрено, как связать кластер со слоем постоянного хранения данных, а также как выделить слой взаимодействия с внешними приложениями.
