
Разработанная инженерами Uber система хранения данных Schemaless используется в нескольких самых важных и крупных сервисах нашей компании (например, Mezzanine). Schemaless — это масштабируемое и отказоустойчивое хранилище данных, работающее поверх кластеров MySQL¹. Когда этих кластеров было 16, управление ими было несложным делом. Но в настоящий момент у нас их более 1 000, и в них развернуто не менее 4 000 серверов баз данных. Управление такой системой требует инструментов совсем другого класса.
Из множества компонентов, входящих в Schemadock, сравнительно небольшой, но очень важной частью является Docker. Переход на более масштабируемое решение стал для нас знаковым событием, и в данной статье мы рассказали о том, как Docker помог нам этого добиться.
Изначально для управления всеми кластерами мы использовали Puppet, разнообразные скрипты, а также делали многие вещи вручную. Но чем быстрее рос Uber и чем больше он становился, тем сложнее было продолжать использовать этот подход. Поэтому мы начали искать более удобные инструменты для управления кластерами MySQL. Основные требования свелись к следующим:
- Работа нескольких серверов БД на одном хосте.
- Полная автоматизация.
- Единая точка входа для организации управления и мониторинга всех кластеров во всех датацентрах.
В итоге родилось решение под названием Schemadock. Теперь наши MySQL-серверы работают в Docker-контейнерах, которые управляются целевыми состояниями, определяющими топологию кластера с помощью файлов конфигурации. В них может быть указано, что, например, в кластере «A» должно быть 3 сервера, и который из них должен стать мастером. Применение соответствующих ролей к индивидуальным серверам выполняется специальными программами-агентами. Единый сервис осуществляет мониторинг целевых состояний всех серверов и в случае отклонений от нормы выполняет необходимые действия для исправления ситуации.
Почему Docker?
Контейнеры упрощают задачу запуска на одном хосте множества процессов MySQL, имеющих разные версии и конфигурации. Это также позволяет расположить на одной машине несколько небольших кластеров, что в итоге дает возможность использовать меньшее количество хостов при том же количестве кластеров. Наконец, мы больше не зависим от Puppet и имеем одинаковые настройки хостов.
Что касается самого Докера: в настоящее время наши инженеры создают все stateless-сервисы на его основе, поэтому мы хорошо знаем эту систему. Она, конечно, не идеальна, но на данный момент является для нас лучшей альтернативой.
Что есть помимо Docker?
Альтернативы Docker следующие: полная виртуализация, LXC-контейнеры, а также управление процессами MySQL напрямую с помощью, например, Puppet. Мы не очень долго выбирали, поскольку Docker лучше всего подходил к существовавшей на тот момент инфраструктуре. Однако, если бы до этого мы не использовали Docker, его внедрение только для MySQL могло бы стать довольно большим проектом, для которого необходимо было бы освоить создание и распространение образов, мониторинг и обновление самого Докера, сбор логов, особенности работы с сетью и многое другое.
Это значит, что внедрение Docker требует ресурсов и времени. Более того, Docker необходимо рассматривать в качестве технологии и не ожидать от него решения всех проблем. Мы в Uber очень тщательно подошли к проектированию системы управления базами данных MySQL, где Docker является лишь одной из составных частей. Но не все компании достигли масштабов Uber, поэтому им может лучше подойти вариант с использованием Puppet, Ansible или аналогичного ПО.
Образ для Schemaless
В основном наш образ лишь загружает и устанавливает Percona Server, а также запускает mysqld — практически то же самое, что делает стандартный образ Docker с MySQL на борту. Однако между загрузкой и установкой выполняется еще несколько операций.
- Если на подключенном томе нет данных, значит, необходима начальная загрузка. Для мастера запускаем mysql_install_db, а также создаем несколько стандартных пользователей и таблиц. Для реплики (minion в терминологии Uber — Прим. перев.) запускаем загрузку данных из резервной копии или другой ноды в кластере.
- Mysqld будет запущен сразу после завершения загрузки данных.
- Если копирование данных по тем или иным причинам не закончится, контейнер будет остановлен.
Роль контейнера задается с помощью переменных окружения. Стоит обратить внимание на механизм получения данных — сам образ не содержит какой-либо логики настройки топологий репликации, проверки статусов и т. д. Поскольку эта логика меняется чаще, чем сам MySQL, весьма разумным будет их разделить.
Директория с данными MySQL монтируется из файловой системы хоста, что означает отсутствие обусловленных Docker накладных расходов на запись. Мы все же записываем в образ конфигурацию MySQL, что делает его немутабельным. Несмотря на то что саму конфигурацию можно отредактировать, эти изменения никогда не вступят в силу, так как мы не используем контейнеры повторно. Если контейнер по какой-либо причине останавливается, он не будет использован еще раз. Мы удаляем контейнер, создаем новый из самого свежего образа, используя такие же параметры (либо новые, если целевое состояние с тех пор изменилось), и запускаем его.
Такой подход дает нам следующие преимущества:
- Становится гораздо проще контролировать дрейф конфигурации. Проблема сводится к номерам версий Docker-образов, которые мы тщательно мониторим.
- Значительно упрощается обновление MySQL. Мы создаем новый образ, а затем по порядку останавливаем контейнеры.
- Если что-то сломалось, оно просто перезапускается. Мы удаляем проблемный контейнер и стартуем новый, не пытаясь ничего чинить.
Для создания образов используется та же самая инфраструктура, что обеспечивает работу stateless-сервисов. Она же реплицирует образы между датацентрами, чтобы сделать их доступными в локальных реестрах.
В работе нескольких контейнеров на одном хосте есть и недостатки. Поскольку между контейнерами нет нормальной I/O-изоляции, любой из них может использовать всю пропускную способность системы ввода-вывода, что крайне негативно скажется на работе остальных контейнеров. В Docker 1.10 появились I/O-квоты, но мы еще не успели с ними поэкспериментировать. Пока мы боремся с этой проблемой путем контроля количества контейнеров на хосте и постоянно мониторим производительность каждой базы данных.
Настройка контейнеров и топологий
Теперь, когда у нас есть образ Docker, который может быть сконфигурирован в роли мастера или реплики, что-то должно запускать контейнеры и настраивать на них требуемую топологию репликации. Для этого на каждом хосте запущен специальный агент, который получает информацию о конечном состоянии для всех баз данных. Типичное описание конечного состояния выглядит следующим образом:
“schemadock01-mezzanine-mezzanine-us1-cluster8-db4”: {
“app_id”: “mezzanine-mezzanine-us1-cluster8-db4”,
“state”: “started”,
“data”: {
“semi_sync_repl_enabled”: false,
“name”: “mezzanine-us1-cluster8-db4”,
“master_host”: “schemadock30”,
“master_port”: 7335,
“disabled”: false,
“role”: “minion”,
“port”: 7335,
“size”: “all”
}
}Здесь говорится, что на хосте schemadock01 должна быть запущена одна реплика базы данных Mezzanine (порт 7335), мастером для нее должна стать база на schemadock30:7335. Параметр size имеет значение all. Это означает, что данная база является единственной на schemadock01, и она должна использовать всю доступную память.
Процедура создания такого описания целевого состояния является темой для отдельной публикации, поэтому мы перейдем к дальнейшим шагам: агент, выполняющийся на хосте, получает и локально сохраняет описание целевого состояния, а затем начинает его обработку.
Обработка — это бесконечный цикл, выполняющийся каждые 30 секунд (что-то похожее на запуск Puppet раз в полминуты). В цикле проверяется соответствие текущего и целевого состояний. Для этого выполняются следующие действия:
- Проверить, запущен ли контейнер. Если нет, создать и запустить.
- Проверить топологию репликации контейнера. Если с ней что-то не так, попытаться починить.
- Если это реплика, а должен быть мастер, убедиться, что изменение роли будет безопасным. Для этого проверить, установлен ли статус read-only текущего мастера, а также все ли GTIDs получены и применены. Если все условия соблюдены, можно удалить связь с предыдущим мастером и включить возможность записи.
- Если это мастер, который должен быть выведен из строя, включить режим read-only.
- Если это реплика, но репликация не выполняется, настроить репликацию.
- Проверить различные параметры MySQL (read_only и super_read_only, sync_binlog и т. д.) согласно роли базы. На мастерах должна быть разрешена запись, реплики должны быть read_only и т. д. Более того, мы снижаем нагрузку на реплики путем отключения binlog fsync и аналогичных параметров².
- Запустить или остановить все вспомогательные контейнеры, такие как pt-heartbeat и pt-deadlock-logger.
Важно отметить, что мы являемся убежденными сторонниками идеи «один процесс — одна цель — один контейнер». В этом случае нам не приходится перенастраивать работающие контейнеры, к тому же значительно упрощается обновление.
В случае возникновения любой ошибки процесс генерирует соответствующее сообщение и завершается, а вся процедура во время следующей попытки повторяется заново. Мы стараемся настроить систему таким образом, чтобы свести необходимость координации между агентами к минимуму. Это значит, что нас не заботит очередность при инициализации нового кластера, например. Если делать эту операцию вручную, то надо выполнить примерно следующие шаги:
- создать MySQL-мастер и подождать, пока он не будет готов к работе,
- создать первую реплику и подключить ее к мастеру,
- повторить предыдущий пункт для оставшихся реплик.
В итоге что-то подобное все же происходит. Но при этом нас совершенно не заботит очередность выполнения шагов. Мы лишь создаем целевые состояния, описывающие необходимую нам конфигурацию:
“schemadock01-mezzanine-cluster1-db1”: {
“data”: {
“disabled”: false,
“role”: “master”,
“port”: 7335,
“size”: “all”
}
},
“schemadock02-mezzanine-cluster1-db2”: {
“data”: {
“master_host”: “schemadock01”,
“master_port”: 7335,
“disabled”: false,
“role”: “minion”,
“port”: 7335,
“size”: “all”
}
},
“schemadock03-mezzanine-cluster1-db3”: {
“data”: {
“master_host”: “schemadock01”,
“master_port”: 7335,
“disabled”: false,
“role”: “minion”,
“port”: 7335,
“size”: “all”
}
}Эта информация отправляется соответствующим агентам в произвольном порядке, и они начинают выполнять задание. Для достижения целевого состояния в зависимости от очередности может потребоваться несколько попыток. Обычно их немного, но некоторые операции перезапускаются сотни раз. Например, если сначала запускаются реплики, они не смогут подключиться к мастеру и должны будут пытаться сделать это снова и снова, пока он не войдет в строй (что может занять длительное время):
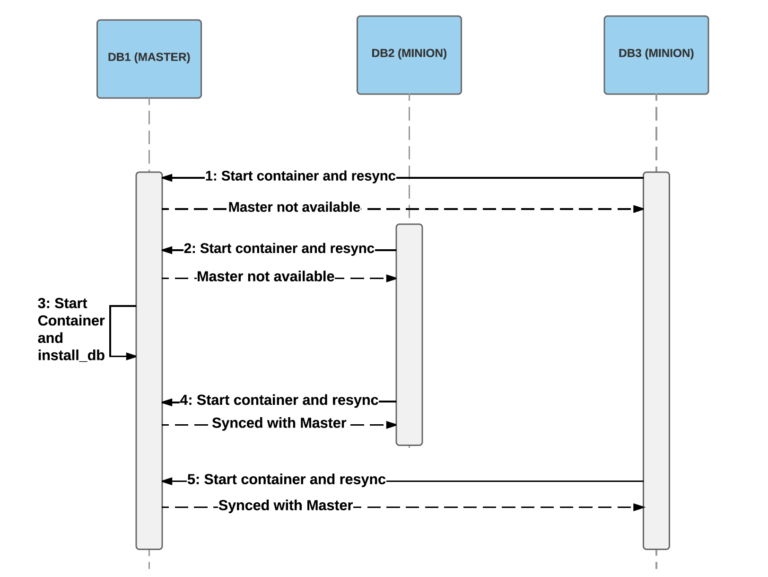
Пример, в котором две реплики стартовали раньше мастера. На шагах 1 и 2 они не смогут получить снимок с мастера, поэтому процесс запуска завершится неудачей. Когда мастер наконец запустится (на шаге 3), реплики смогут подключиться и синхронизировать данные (шаги 4 и 5).
Работа в среде Docker
На большинстве наших хостов установлен Docker 1.9.1 с devicemapper на LVM. Использование LVM для devicemapper оказалось более производительным решением по сравнению с loopback. У devicemapper много проблем, связанных с производительностью и надежностью, но альтернативы, такие как AuFS и OverlayFS, также далеки от идеала³. Сообщество долго не могло определиться, какой вариант организации хранилища лучше. Но в последнее время все больше голосов звучит в пользу OverlayFS, которая к тому же, кажется, стабилизировалась, поэтому мы собираемся перейти на эту файловую систему и одновременно обновиться до Docker 1.12.1.
Одним из неудобств Docker является требование по перезапуску контейнеров при перезагрузке сервиса. Это означает, что мы должны контролировать процесс обновления, так как у нас не будет работающих мастеров во время обновления хоста. К счастью, в Docker 1.12 добавлена опция перезагрузки и обновления демона без перезапуска контейнеров, поэтому мы надеемся, что с этой проблемой нам предстоит столкнуться в последний раз.
В каждой следующей версии Docker появляется много улучшений и новых возможностей, а также приличное количество ошибок. 1.12.1 кажется лучше предыдущих, но мы все еще сталкиваемся с определенными проблемами:
- Иногда docker inspect виснет после того, как Docker проработал без остановки несколько дней.
- Использование bridge networking с userland proxy приводит к странному поведению при завершении TCP-соединений. Клиентские соединения иногда не получают сигнал RST и остаются открытыми независимо от установленного таймаута.
- Процессы контейнеров иногда переподчиняются pid 1 (init), и Docker их теряет.
- Регулярно происходят случаи, когда Docker-демон очень долго создает новые контейнеры.
Заключение
Мы начали с того, что определили список требований к системе управления кластером хранения данных в Uber:
1) несколько контейнеров на одном хосте,
2) автоматизация,
3) единая точка входа.
Теперь мы можем выполнять ежедневное обслуживание с помощью единого пользовательского интерфейса и простых инструментов, ни один из которых не требует прямого доступа к хостам:

Скриншот нашей консоли управления. Здесь можно увидеть процесс достижения целевого состояния: в данном случае мы разбиваем кластер на две части, сначала добавив второй кластер, а затем разорвав репликационную связь.
За счет запуска нескольких контейнеров на одном хосте мы более полно используем вычислительные ресурсы. Стало возможным выполнение контролируемого обновления всего парка машин. С помощью Docker нам достаточно быстро удалось этого добиться. Docker также позволяет запустить установку всего кластера целиком в тестовом окружении, что может быть использовано для испытания различных эксплуатационных процедур.
Мы начали миграцию на Docker в начале 2016, и сейчас у нас запущено около 1500 production-серверов Docker (только для MySQL), на которых развернуто около 2300 баз данных MySQL.
В Schemadock есть много других компонентов, но именно Docker нам очень помог. С ним мы получили возможность быстрого продвижения вперед, много экспериментируя в тесной связи с существующей инфраструктурой Uber. Хранилище поездок, в которое добавляется по несколько миллионов записей в день, теперь основано на докеризированных базах данных MySQL (совместно с хранилищами другой информации). Другими словами, теперь без Docker пользователи Uber в буквальном смысле слова далеко не уедут.
Joakim Recht является штатным специалистом (инженером) по программному обеспечению в офисе Uber Engineering’s Aarhus, а также техлидом по автоматизации инфраструктуры Schemaless.
¹ Если быть точным, Percona Server 5.6
² sync_binlog = 0 и innodb_flush_log_at_trx_commit = 2
³ Небольшая коллекция проблем: https://github.com/docker/docker/issues/16653, https://github.com/docker/docker/issues/15629, https://developerblog.redhat.com/2014/09/30/overview-storage-scalability-docker/, https://github.com/docker/docker/issues/12738
