
Прежде чем взяться за разработку мобильного приложения для заучивания лексики, мы в школе Skyeng потратили массу времени на изучение алгоритмов работы памяти и запоминания слов. В результате разработка Aword заняла чуть больше времени, но мы более уверены в результате — использование определенных алгоритмов в показе слов помогает эффективнее пополнять словарный запас.
 На рынке представлено большое количество приложений для заучивания иностранных слов. Всех их объединяет общая черта — использование зубрежки (дриллинга) в качестве основного инструмента обучения. Чем больше времени ученик проводит за повторением слов, тем выше шанс, что он их запомнит. Например, вполне реально за час выучить сто слов. Однако без повторения уже через 6 часов половина из них будет забыта. Еще через шесть часов в памяти останется не больше 15 слов. Чтобы этого не произошло, необходимо регулярно повторять весь набор (зубрить).
На рынке представлено большое количество приложений для заучивания иностранных слов. Всех их объединяет общая черта — использование зубрежки (дриллинга) в качестве основного инструмента обучения. Чем больше времени ученик проводит за повторением слов, тем выше шанс, что он их запомнит. Например, вполне реально за час выучить сто слов. Однако без повторения уже через 6 часов половина из них будет забыта. Еще через шесть часов в памяти останется не больше 15 слов. Чтобы этого не произошло, необходимо регулярно повторять весь набор (зубрить).Если ученик делает в повторении списка паузу (на неделю, на месяц, на отпуск, на рабочий аврал, ...) — высока вероятность, что слова забудутся, и зубрежку придется начать с начала. Если он переключился с одного набора слов на следующий и не повторил первый через некоторое время — он его забудет. Для того, чтобы такое запоминание работало эффективно, необходимо самостоятельно или с помощью преподавателя составить четкий план обучения и неукоснительно ему следовать, иначе зубрежка превратится в бессмысленную потерю огромного количества времени без явного, прогнозируемого результата.
Мы задумались: можно ли сделать приложение, которое будет обеспечивать не только процесс «дриллинга», но также составление и поддержание плана занятий и контроль за полученными знаниями? Как максимизировать эффективность обучения и сэкономить время ученика?
Начать придется издалека: с разговора об устройстве нашей памяти, которая бывает краткосрочной и долгосрочной.
Зубрежка vs запоминание
 Краткосрочная хорошо знакома студентам, сдающим какой-нибудь не очень нужный формальный предмет. Если проштудировать учебник ночью накануне экзамена, есть высокая вероятность, что большая часть информации, пусть и в разрозненном виде, останется в памяти достаточно долго, чтобы сдать экзамен или зачет. Однако уже через пару дней она бесследно выветрится (точнее, как показывают исследования, не выветрится, но так надежно скроется в глубинах сознания, что извлечь ее оттуда будет проблематично).
Краткосрочная хорошо знакома студентам, сдающим какой-нибудь не очень нужный формальный предмет. Если проштудировать учебник ночью накануне экзамена, есть высокая вероятность, что большая часть информации, пусть и в разрозненном виде, останется в памяти достаточно долго, чтобы сдать экзамен или зачет. Однако уже через пару дней она бесследно выветрится (точнее, как показывают исследования, не выветрится, но так надежно скроется в глубинах сознания, что извлечь ее оттуда будет проблематично).Долгосрочная память – это то, что позволяет нам легко вспомнить полученные сведения и через год, и через пять лет. Но для того, чтобы она заработала, необходимы регулярные тренировки, причем наиболее эффективный формат этих тренировок – не перечитывание учебника, а проверка по контрольным вопросам или постоянное применение полученных знаний на практике.
Например, студент, изучающий новый язык программирования, получает эту тренировку в виде ежедневных сессий кодинга. Постигнув тему объектов в C++, он сможет навсегда ее запомнить, если будет регулярно использовать. Поэтому преподаватели требуют объектного программирования даже тривиальных задач, где разумно было бы без него обойтись.
Долгосрочная память требуется не всегда. Химику совершенно не обязательно знать все формулы; юристу не нужно иметь в голове полные версии уголовного, гражданского и процессуального кодекса. Им на помощь всегда могут прийти справочники; для них важнее понимание принципов работы и знание направления поиска данных.
Но есть сферы, где долгосрочная память необходима. Наиболее очевидные – медицина и лингвистика. Врач должен помнить симптомы любых, даже редких, болезней. Человек, претендующий на свободное владение английским языком, должен знать слово serendipity, даже если он никогда в жизни с ним не столкнется. Разумеется, наиболее эффективный способ развить такую долгосрочную память – практика. Выпускник медицинского вуза на несколько лет отправляется в ординатуру или интернатуру. Профессиональный переводчик обязательно едет на стажировку в среду носителей языка.
Но что делать, если такой возможности нет? И как быть, если врач за время ординатуры так и не столкнулся со случаем синдрома Кавасаки?
Необходимо развивать долгосрочную память как-то иначе. Неудивительно, что основные исследования в этой области проводятся как раз медиками и лингвистами.
Польский студент и немецкий психолог
Петр Возняк, автор самого известного алгоритма запоминания SuperMemo, задумался об оптимизации этого процесса в 80-е годы, будучи студентом Познаньского Политеха. Одной из задач, которые он ставил перед собой, было полноценное владение английским языком – его не устраивал тот поверхностно-профессиональный уровень, которым вполне довольствовались его сокурсники.
Возняк оказался достаточно упертым парнем. Он создал базу из карточек по английскому языку и биологии, содержащих вопрос и ответ, и занялся ежедневными тренировками, тщательно записывая результаты в дневник. Под конец эксперимента у него образовалось три тысячи карточек по английскому и более полутора тысяч по биологии.
С помощью несложных вычислений, основанных на полученных данных, Возняк установил, что для запоминания небольшого словаря в 15 тысяч английских слов ему потребуется тратить на тренировки ежедневно по два часа. Потраченное время растет пропорционально количеству слов: для запоминания 30 тысяч потребуется четыре часа повторений ежедневно. Не очень удобно.
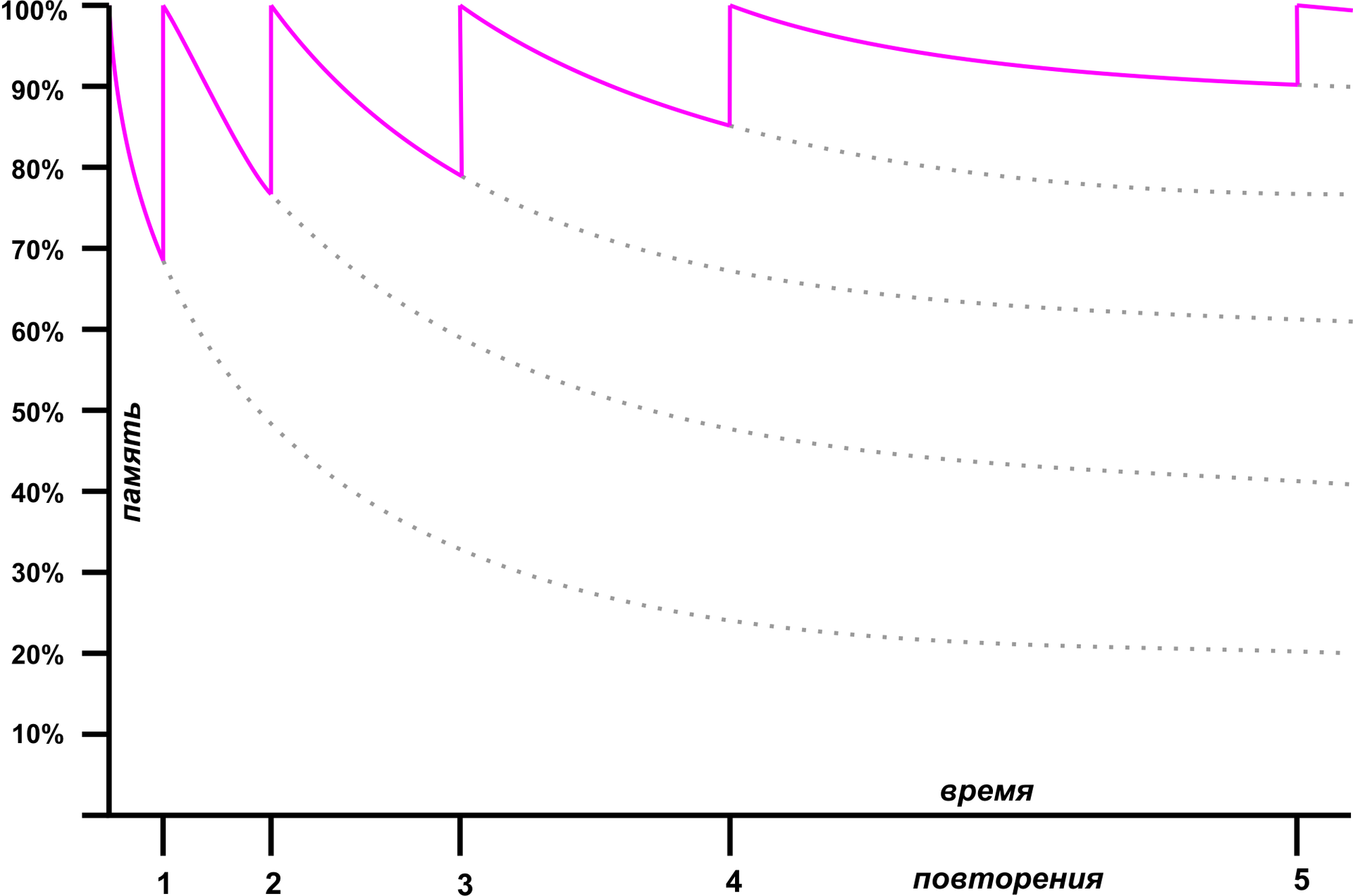
 К счастью, за сто лет до Петра Возняка аналогичной проблемой озаботился немецкий психолог Герман Эббингауз, тоже весьма упертый человек. Эббингауз провел два годичных эксперимента, в ходе которых запоминал бессмысленные наборы слогов. В результате было сделано несколько открытий, самым важным из которых является Кривая забывания.
К счастью, за сто лет до Петра Возняка аналогичной проблемой озаботился немецкий психолог Герман Эббингауз, тоже весьма упертый человек. Эббингауз провел два годичных эксперимента, в ходе которых запоминал бессмысленные наборы слогов. В результате было сделано несколько открытий, самым важным из которых является Кривая забывания.Эббингауз экспериментальным путем установил, что скорость забывания информации падает после каждого повторения. После первого запоминания данных забывание идет очень быстро: уже через час из головы вылетает примерно половина материала, через десять часов – 65%; впрочем, около 20% остается и через месяц после изучения. Однако, если в течение первого часа повторить весь материал, процесс его забывания значительно замедлится, и новое повторение можно делать уже через сутки. Воспользовавшись Кривой забывания, можно расставить повторения таким образом, чтобы произошло максимальное долговременное усвоение материала за минимальное количество тренировок.
Этот метод называется «интервальные повторения» (Spaced Repitition). В 30-е годы был проведен эксперимент, показавший, что такая техника действительно благотворно влияет на процесс обучения. Однако популярности она в то время не обрела из-за своей чрезмерной сложности: необходимо было готовить тысячи карточек с вопросами-ответами, правильно их тасовать, вовремя повторять… Но потом появились компьютеры.
Вернемся к польскому студенту Петру Возняку, мечтавшему выучить английский, но не горевшему желанием тратить на тренировки по четыре часа в день. Он решил алгоритмизировать технику интервальных повторений, что в конце концов вылилось в программу SuperMemo. Разумеется, все оказалось далеко не так просто, и разработка SuperMemo стала, по сути, делом его жизни.
Алгоритмизация метода интервальных повторений – задача достаточно очевидная. Главная проблема этого метода – необходимость точно рассчитать время, когда повторение будет максимально эффективным – т.е. тот самый момент, когда информация забывается. Если написать программу, которая будет не только проводить тренировки, но и своевременно напоминать пользователю об их необходимости, это теоретически позволит добиться более эффективного обучения.
Здесь есть свои особенности. Сама по себе кривая забывания – явление универсальное, однако у разных людей на нее накладываются разные экспоненты. Кому-то третье повторение требуется через 20 минут, кому-то – через час; аналогичным образом изменяется расстояние и между последующими повторами. Поэтому тренировки должны быть гибкими – в их ходе алгоритм старается понять скорость забывания конкретного ученика и подстроиться под нее.
Важной проблемой на пути к успешному обучению становится человеческий фактор. Для того, чтобы эффективно запомнить максимальный объем информации за минимальный срок, нужно точно следовать графику. В реальности это создает неудобства, и ученики решают отложить на потом. В результате, пропустив нужный момент, они откатываются назад – на шаг, на два, а то и к самому началу обучения. Этот откат также надо правильно просчитать, чтобы минимизировать издержки из-за пропусков.
Лицензия на слова
В основе нашего мобильного приложения Aword лежит концепция «лицензий на слова» — по аналогии с ограниченными по времени лицензиями ПО. После первого запоминания «лицензия» действует примерно час; если не повторить слово, оно будет забыто. Если повторить слова в конце этого часа, появится новая «лицензия», уже на шесть часов. Следующая «лицензия» будет на сутки, потом на три дня, на неделю, месяц, полгода, два года. Самый эффективный момент для повтора — пограничный, когда предыдущая «лицензия» истекает, и для того, чтобы вспомнить слово, надо приложить определенные усилия. Все «лицензии» для каждого слова хранятся на нашем сервере в учетной записи ученика, и задача мобильного приложения — вовремя напомнить, что настала пора их обновить.
Базовый алгоритм, лежащий в основе Aword, можно описать таким псевдокодом:
function makeRepetition( user, word, license ){
var timePassed = (new Date()) - license.startTime;
var answer = showWordCard( word );
user.tuneParameters( license, timePassed, answer.quality );
word.tuneComplexity( license, timePassed, answer.quality );
if(answer.quality > 0) {
license.next( timePassed );
} else {
license.rollback( timePassed );
}
}Основной код этого алгоритма определяет, можно ли дать увеличенную «лицензию» на слово, или же его надо учить снова. tuneParameters и tuneComplexity — условные ссылки на настроечные алгоритмы; качество ответа (answer.quality) представляет собой число от 0 до 1. Это число равно единице, если ученик быстро, с первого раза узнал слово; у него хорошо работает память, задача оказалась для него слишком легкой. В этом случае алгоритм увеличит интервалы повторений. Если качество ответа близко меньше 0,5 — ответ был дан с трудом, после подсказок; стандартный интервал повторов для этого ученика слишком велик, необходимо проводить тренировки чаще.
Оригинальная кривая забывания была построена на основе данных синтетического эксперимента. Эббингауз намеренно использовал ничего не значащие слоги, чтобы в итоге получить максимально чистые результаты.
Современные студенты-медики успешно используют кривую забывания в ее начальном виде, например, для запоминания данных по фармакологии (тоже, в общем, состоящей из наборов букв). Вот, например, типичная инструкция по повторению материала:
— первый повтор – сразу после прочтения (проверка по контрольным вопросам);
— второй повтор – через 20 минут;
— третий – через сутки;
— четвертый – через 48 часов после третьего;
— пятый – через 72 часа после четвертого.
Существуют универсальные алгоритмы, позволяющие использовать метод интервальных повторений для эффективного запоминания любой информации. Самая известная (и к тому же бесплатная) такая программа — Anki. Она, разумеется, не учитывает особенностей, связанных с изучением иностранных языков, однако может здорово пригодиться, если необходимо надолго запомнить что-то действительно важное.
 При изучении же иностранного языка мы имеем дело не с хаотичными наборами букв, а с осмысленными словами. Степень осмысленности и понятности слова ученику напрямую влияет на скорость запоминания. Так, инженер значительно быстрее запомнит слово «шестеренка», чем философ. Привычные, легко представляемые слова («дуб») запоминаются легче, чем экзотические («пихта»). Как следствие, необходимо аккуратно подбирать группы с примерно одинаковой скоростью запоминания. Алгоритм SuperMemo использует для такого подбора субъективную оценку пользователя – насколько ему сложно дается слово; это не очень точный показатель. Еще один фактор – уже имеющаяся у ученика словарная база, которую необходимо оценить для составления программы. Все это тоже должно быть алгоритмизировано. Впрочем, это темы для отдельных статей.
При изучении же иностранного языка мы имеем дело не с хаотичными наборами букв, а с осмысленными словами. Степень осмысленности и понятности слова ученику напрямую влияет на скорость запоминания. Так, инженер значительно быстрее запомнит слово «шестеренка», чем философ. Привычные, легко представляемые слова («дуб») запоминаются легче, чем экзотические («пихта»). Как следствие, необходимо аккуратно подбирать группы с примерно одинаковой скоростью запоминания. Алгоритм SuperMemo использует для такого подбора субъективную оценку пользователя – насколько ему сложно дается слово; это не очень точный показатель. Еще один фактор – уже имеющаяся у ученика словарная база, которую необходимо оценить для составления программы. Все это тоже должно быть алгоритмизировано. Впрочем, это темы для отдельных статей.Алгоритмы, используемые в нашем мобильном приложении, в течение полугода тестировались на добровольцах из числа сотрудников и их знакомых. Это позволило нам подобрать некоторые средние параметры (срок «лицензий»), которые в итоге используются для оптимизации процесса долговременного запоминания слов. Сейчас, когда приложение стало доступно всем желающим, мы сможем собрать значительно больше аналитических данных для дальнейшей точной подстройки этих параметров. И все это можно увидеть, скачав мобильное приложение в App Store. В конце октября приложение будет выложено в Google Play, а в ноябре — доступно на Web.
А если вы сами хотите поучаствовать в разработке подобных штук — у нас масса интересных вакансий!
