Много пик сломано в мире на тему того, можно ли и как создавать многопоточность в PHP. Чаще всего все сводится к тому, что так делать нельзя или дискуссия материализуется в какие-то ужасные костыли (ох, сколько я их уже повидал). Я хочу изложить свою точку зрения на этот вопрос. Легко догадаться, что если бы моя позиция была “так нельзя” или “это зло”, то я бы не писал эту статью. Вот только погодите, не спешите доставать тухлые яйца и вооружаться мелкими бытовыми предметами для рукопашной схватки. Я постараюсь дипломатично изложить тему и максимально объективно раскрыть ситуацию. Так что самые смелые из моих читателей могут прочитать молитву от ереси и открыть статью.

Существует много разных терминов: multithreading, multiprocess, asynchronous execution. Они все означают разные вещи. Однако, часто бывает так, что на практике нам, как потребителям, не так уж и важно, в разных процессах, потоках или еще как параллельно исполняется наша программа. Лишь бы она работала быстрее и не теряла отзывчивость в процессе своего выполнения. Поэтому в этой статье я рассмотрю все возможные варианты параллелизации PHP вне зависимости от внутренней кухни этой самой параллелизации. То есть, я попытаюсь ответить на вопрос: как можно сделать так, чтобы какое-то долгое действие в моем PHP коде выполнялось в фоне, пока мой код занят чем-то другим полезным.
Вообще-то, я считаю, что в 99% случаев оно не надо (и заметьте, это пишет автор статьи на тему параллелизации). Я проработал 8 лет с PHP и до прошлой недели всегда считал большой глупостью пытаться вкрутить многопоточность в PHP. Дело в том, что задача PHP – это принять входящий HTTP запрос и сгенерировать на него ответ. Один запрос – один ответ. Схема весьма простая, и очень удобно вести обработку линейно в одном потоке. Мне кажется, что в связке клиент-сервер на сервере делать что-то многопоточным не надо, за исключением каких-то особенных обстоятельств, которые вас вынуждают к этому и на которых можно сыграть для уменьшения потребляемых ресурсов и времени ответа. Почему я так считаю? Ведь кто-то может сказать, что если распараллелить какой-то процесс, то он может выполняться на 2х ядрах сразу и таким образом выполнится быстрее. Это правда. Но на сервере всегда есть один нюанс: вы должны быть готовы обрабатывать сразу N клиентов одновременно. И если ваш серверный код “расползется” на все 8 доступных ядер, и в этот момент придет новый входящий запрос, то ему придется ютиться в очереди, ожидая, пока какое-то ядро будет готово начать его обработку. И у вас начнется бесполезная конкуренция за циклы 8-ми CPUs между 16 потоками/процессами. Именно поэтому я считаю, что даже если на сервере есть ресурсы, которые можно привлечь в обработку входящего запроса за счет параллелизации, лучше так не делать. Можно сказать, что параллелизация уже присутствует и так, т.к. сервер может одновременно обрабатывать несколько входящих запросов. Ну и получается, что вкручивать параллелизацию в параллелизацию – это уже как бы перебор.
Я к этому моменту уже мельком упомянул, зачем нужна многопоточность. Она позволяет “разрывать” единую нить исполнения кода. Из этого следует сразу несколько “полезных” следствий. Во-первых, можно в фоне выполнять какое-то медленное действие, сохраняя отзывчивость основного потока программы (асинхронное исполнение). К примеру: нам по бизнес логике нужно обменяться информацией с каким-нибудь периферийным устройством. Это устройство очень медленное, и операция занимает около 5 секунд. Если все это делать в одном потоке, то блок-схема нашего алгоритма выглядит вот так:
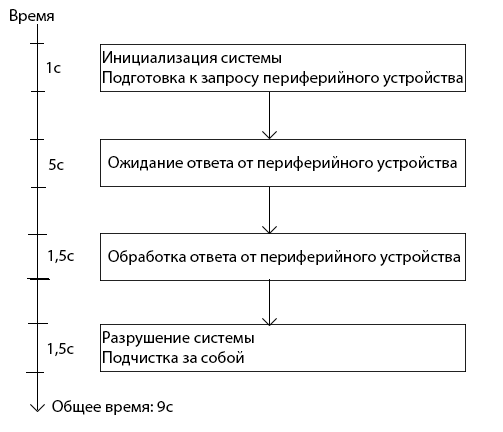
Очень вероятно, что хоть какую-то часть из “разрушение системы и подчистка за собой” можно выполнять не зная ответа от периферийного устройства. Тогда можно вызвать периферийное устройство в отдельном потоке, и пока устройство отвечает, никто нам не запретит в основном потоке выполнить что-то из пункта “разрушение системы и подчистка”. Тогда блок-схема выглядит вот так:
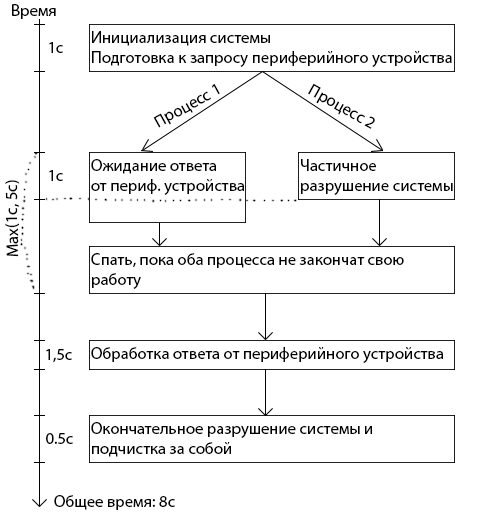
Ну а второе большое следствие из разрыва этой единой нити исполнения это то, что можно использовать больше ресурсов компьютера, на котором исполняется код. Если это какое-то трудоемкое математическое вычисление, то его можно запустить на несколько потоков (при условии, что алгоритм вычислений это позволяет), и тогда над результатом будут сразу работать несколько ядер процессора. То бишь, в абстрактной формулировке: если в несколько потоков конкурировать за какой-то ресурс, то его можно получить больше за тот же промежуток времени. Хотя, я уже говорил, что этот пункт весьма сомнителен для меня в случае серверного кода (а мы именно такой и рассматриваем).
Самый большой, да и единственный значимый, мне кажется – это дополнительные расходы на поддержание многоточности, как при run time (потокам нужно как-то обмениваться между собой информацией, чтобы они могли работать на общее благо), так и в development time (многопоточные/асинхронные программы сложнее писать и поддерживать, т.к. человеческому мозгу куда проще воспринимать линейную логику исполнения). Ведь мы всегда воспринимаем мир “здесь и сейчас”, а осознать, что где-то еще происходит что-то еще, всегда получается не так ярко как текущую сцену “здесь и сейчас”. Получается, что многопоточная программа будет потреблять больше ресурсов, выполняя ту же самую задачу, что и однопоточная программа. Также, очень вероятно, она будет требовать больше времени на разработку и поддержание/расширение. Что же получается? Многопоточность может дать прирост в скорости работы за счет параллельного исполнения, и многоточность будет потреблять больше ресурсов из-за необходимости синхронизации и обмена данными между потоками. В общем-то, как всегда: параллелизация – это всего лишь инструмент. При правильном использовании он может оказаться полезным, в противном случае он будет лишним грузом.
Я работаю над вебсайтом, который оценивает себестоимость отправки посылки из пункта А в пункт Б. По сути, это агрегатор API грузоперевозчиков. Ну, вы уже догадались? При холодном кеше в худших случаях могло получиться так, что из 1 входящего запроса на мой вебсайт “вырастают” под 200 запросов на API разных грузоперевозчиков. Естественно, делать 200 синхронных HTTP запросов – это грех куда страшнее, чем вкручивание многопоточности в PHP. Поэтому из 2-х зол я выбрал меньшее. У меня действительно был случай один на миллион в этой ситуации. Дополнительные потоки не потребляют много циклов CPU, ни сети, ни жесткого диска, очень условно говоря, мне нужны были потоки, в которых всего лишь нужно было поспать 1-2 секунды (пока генерируется ответ на стороне API перевозчика). Disclaimer: 10 раз подумайте, прежде реализовывать это у себя где-то в проекте. Я за 8 лет работы первый раз встретил случай, где это имеет смысл. Одевайте этот хомут на шею только если он вам действительно нужен.
Прежде чем я перейду к конкретным способам реализации, которые я пробовал, позвольте представить некоторые теоретические размышления на эту тему. Самое крупное деление алгоритмов разбивается по линии fork/thread текущего PHP процесса или запуск нового дочернего процесса. Во-первых, я нашел только 1 возможную реализацию на forking текущего PHP процесса (которая оказалась нерабочей ко всему прочему). Во-вторых, fork'аться в PHP – это явно пример плохой параллелизации. Почему? Да потому, что в параллельный поток нужно стараться вынести исключительно то действие, которое выполняется медленно (связь с периферийным устройством, а не интерпретацию его ответа; выполнение HTTP запроса, а не его интерпретация опять же). Смотрите пункт про параллелизацию серверного кода вверху, чтобы понять почему нужно делать именно так. В-третьих, fork'ая полноценную программу, вы обязуете себя на синхронизацию данных между ними, а это очень непросто. С другой стороны, если вы создаете дочерний процесс с буквально парочкой строк кода, которые выполняют какую-то муторную и долго-спящую операцию, вам ничего не надо синхронизировать и вы не “расползаетесь” на остальные ядра вашего сервера. Ну и как бонус, этот подход в разы гибче – вы можете запустить не PHP дочерний процесс, а bash скрипт какой-нибудь или программу на C, или вообще что попало, тут вас ограничивает только ваша фантазия (и знания Линукса, конечно).
Остановимся подробнее на дочерних процессах. Как можно организовать коммуникацию между родительским и дочерним процессами? Конечно, можно организовать их коммуникацию на файлах, можно на БД или еще на каком-то хранилище данных. Но поддерживать “зоопарк” файлов в 200 штук на каждый входящий запрос в моем конкретном случае выглядело очень гемморно. Работать с БД я не хотел, чтобы не исчерпать коннекты к MySQL (ведь это будет 200 коннектов на 1 входящий запрос – при такой арифметике я не смогу сильно масштабировать свой код и весьма быстро упрусь в количество коннектов к БД). К счастью, старый добрый Linux и так имеет инструментарий для общения между процессами (уже лет 20 как имеет и похоже, что всем его достаточно, значит и мне, и вам тоже должно быть достаточно). Таким образом моя цель была найти такую идеальную реализацию создания дочерних процессов, чтобы:
Как по мне, самое бредовое из того, что я видел про параллелизацию PHP – это запускать
Другое дело, если запросы отправляются на другой сервер, как в моем случае. Здесь использование
Пример (сразу скажу, я его на деле сильно не пробовал, т.к. негибкость этого подхода меня сильно отпугивала): php.net/manual/en/function.curl-multi-exec.php
Если скомпилировать PHP c флагом
Якобы,
Самый скорый на реализацию метод, который позволяет запускать любую команду в ОС (читайте “очень гибкий”). До столкновения с моей текущей задачей я всего лишь раз прибегал к этой функции. Но у меня там случай был другой, мне просто нужно было запустить команду, дать ей входные аргументы и забыть о ней. Никаких ответов мне от нее не нужно было. В процессе выполнения команда сама куда надо запишет результат. Тогда я это реализовал вот так:
Без амперсанда в конце команды, она бы выполнялась синхронно, т.е. PHP процесс бы спал до окончания работы команды. Говоря по правде, я на этом способе тоже сильно долго не задерживался, но по идее, все необходимые входные аргументы можно передать через аргументы команды. STDERR и STDOUT команды можно перенаправить в файлы или named pipes. Если очень надо, то можно предварительно записать STDIN в файл или named pipe. В самом худшем случае получится где-то вот такой франкенштейн:
Самый большой недостаток, заключается в том, что нет хорошего способа определить закончила ли свою работу команда. Но если изначально заложить определенный интерфейс содержимого STDOUT, то можно жить весьма неплохо и на этом способе. Вам тогда нужно периодически считывать содержимое STDOUT, и дальше, основываясь на вашем протоколе содержимого STDOUT, можно интерпретировать в каком состоянии находится команда. Под передачу мета информации о текущем статусе можно завести отдельный файл дескриптор (4й, допустим).
Итак, наш следующий кандидат выглядит немного выигрышнее, чем
Якобы,
Из недостатков: невозможно узнать текущий статус дочерней команды. Иногда это может быть важным. Представьте, что мы запустили 10 асинхронных команд. Они все выполняются где-то 2 секунды, ± 10%. И в основном процессе PHP мы по окончанию каждой из команды хотим проинтерпретировать результаты. Каждая такая интерпретация у нас займет 0.5 секунды. Если бы у нас была возможность узнать закончила ли работу такая-то дочерняя команда, то мы бы могли читать STDOUT тех дочерних команд, которые уже закончили свою работу. И пока мы занимаемся интерпретацией текущей дочерней команды, остальные выполняющиеся дочерние команды весьма вероятно успеют завершиться к моменту, когда мы будем готовы интерпретировать их результат. Увы, мы так делать не можем. Максимум, что мы можем делать в этом способе – это читать STDOUT, и если STDOUT дочерней команды еще открыт, то наш основной PHP процесс будет спать до тех пор, пока дочерняя команда его не закроет либо не закончит свою работу (что неявным образом тоже закроет pipe). Мы немного теряем асинхронность, т.к. в определенных ситуациях можем “напороться” на долгий “сон” основного PHP процесса.
Второй недостаток: односторонность коммуникации. Хорошо бы иметь сразу 3 дескриптора… на все случаи жизни, так сказать. И если без STDIN можно обойтись (можно все входные данные запихнуть во входные аргументы дочерней команды), то вот без STDERR все-таки сложнее. Умельцы могут придумать такое решение:
Но тогда вам придется самостоятельно разбирать кашу в STDOUT, т.к. там в любой момент может оказаться содержимое STDERR. Если вам нужен STDERR, то вам придется самостоятельно на уровне ОС создавать named pipes или временные файлы и редиректить в них STDERR поток. Забегая наперед, скажу, что если вам действительно нужен STDERR, то лучше не морочиться с
Итого имеем победителя! Он нам подходит по всем критериям и запускается довольно небольшим количеством кода в PHP. Я на практике уже около недели использую этот способ и не имею нареканий. Вебсайт и сервер не видели еще настоящей нагрузки, т.к. вебсайт еще не вышел на финальную стадию, но тьфу-тьфу-тьфу у меня нет причин нарекать, и кажется, я написал код, в возможность существования которого я сам не верил дней 10 назад.
Я рассказал про сухие реализации асинхронности в PHP. Но ведь на практике все так просто и красиво никогда не бывает, не правда ли? Асинхронность здесь не исключение. В заключение хочу привести некоторые уловки, которые помогут вам на прикладном уровне в момент применения этих техник.
Если вы хотите обмениваться информацией между 2 PHP процессами, вероятно, что в какой-то момент вы захотите “толкать” между STDIN/STDOUT какие-то сложные структуры данных, присущие вашему проекту (читайте “не скаляры”). Первое, что приходит в голову – это запихнуть их в
Умелое использование асинхронного вызова – это большая наука. Нетрудно догадаться, что нужно максимально агрессивно (eager) запускать дочернюю асинхронную команду и максимально лениво (lazy) читать результаты ее работы. Ведь таким образом у вашей команды будет максимум времени на исполнение и ваш основной поток не будет заблокирован в спячке, ожидая окончание ее работы. Не все архитектуры программ удобно ложатся под этот принцип. Вы должны понимать, что запускать дочернюю команду и следующей же строчкой читать ее результат – это делать себе только хуже. Если вы планируете использовать асинхронность, постарайтесь продумать свою архитектуру как можно раньше и всегда держите это в уме. На своем конкретном примере скажу, что когда я дошел до понимания, что мне нужно параллелить свой PHP процесс, мне пришлось переписать основной движок вебсайта, развернув его более удобной стороной к асинхронности.
Асинхронность – это лишние расходы. На синхронизацию данных (если она у вас будет), на создание и убивание дочернего процесса, на открытие и закрытие файл дескрипторов и т.п. На моем ноутбуке асинхронный вызов простого
Во-вторых, якобы, вы что-то делаете асинхронно потому, что оно выполняется медленно. Так почему бы не убить 2х зайцев одним выстрелом? Кешируйте результаты асинхронной команды в каком-нибудь перманентном хранилище, будь-то БД, файловая система или memcache. Естественно, этот пункт имеет смысл только если ваши результаты не теряют своей актуальности слишком быстро. Более того, поставьте этот кеш перед всей асинхронностью, чтобы избежать тех 3 мс. На всякий случай приведу блок-схему моей мысли:

Знать теорию – это хорошо. Но обычно ленивые и практичные ребята хотят скачать какую-нибудь библиотеку, подключить ее, подергать за пару методов и решить свою проблему. На базе последнего решения (через

Объект дискуссии – что я подразумеваю под многозадачностью/многопоточностью?
Существует много разных терминов: multithreading, multiprocess, asynchronous execution. Они все означают разные вещи. Однако, часто бывает так, что на практике нам, как потребителям, не так уж и важно, в разных процессах, потоках или еще как параллельно исполняется наша программа. Лишь бы она работала быстрее и не теряла отзывчивость в процессе своего выполнения. Поэтому в этой статье я рассмотрю все возможные варианты параллелизации PHP вне зависимости от внутренней кухни этой самой параллелизации. То есть, я попытаюсь ответить на вопрос: как можно сделать так, чтобы какое-то долгое действие в моем PHP коде выполнялось в фоне, пока мой код занят чем-то другим полезным.
А зачем оно вообще надо?
Вообще-то, я считаю, что в 99% случаев оно не надо (и заметьте, это пишет автор статьи на тему параллелизации). Я проработал 8 лет с PHP и до прошлой недели всегда считал большой глупостью пытаться вкрутить многопоточность в PHP. Дело в том, что задача PHP – это принять входящий HTTP запрос и сгенерировать на него ответ. Один запрос – один ответ. Схема весьма простая, и очень удобно вести обработку линейно в одном потоке. Мне кажется, что в связке клиент-сервер на сервере делать что-то многопоточным не надо, за исключением каких-то особенных обстоятельств, которые вас вынуждают к этому и на которых можно сыграть для уменьшения потребляемых ресурсов и времени ответа. Почему я так считаю? Ведь кто-то может сказать, что если распараллелить какой-то процесс, то он может выполняться на 2х ядрах сразу и таким образом выполнится быстрее. Это правда. Но на сервере всегда есть один нюанс: вы должны быть готовы обрабатывать сразу N клиентов одновременно. И если ваш серверный код “расползется” на все 8 доступных ядер, и в этот момент придет новый входящий запрос, то ему придется ютиться в очереди, ожидая, пока какое-то ядро будет готово начать его обработку. И у вас начнется бесполезная конкуренция за циклы 8-ми CPUs между 16 потоками/процессами. Именно поэтому я считаю, что даже если на сервере есть ресурсы, которые можно привлечь в обработку входящего запроса за счет параллелизации, лучше так не делать. Можно сказать, что параллелизация уже присутствует и так, т.к. сервер может одновременно обрабатывать несколько входящих запросов. Ну и получается, что вкручивать параллелизацию в параллелизацию – это уже как бы перебор.
Я к этому моменту уже мельком упомянул, зачем нужна многопоточность. Она позволяет “разрывать” единую нить исполнения кода. Из этого следует сразу несколько “полезных” следствий. Во-первых, можно в фоне выполнять какое-то медленное действие, сохраняя отзывчивость основного потока программы (асинхронное исполнение). К примеру: нам по бизнес логике нужно обменяться информацией с каким-нибудь периферийным устройством. Это устройство очень медленное, и операция занимает около 5 секунд. Если все это делать в одном потоке, то блок-схема нашего алгоритма выглядит вот так:

Очень вероятно, что хоть какую-то часть из “разрушение системы и подчистка за собой” можно выполнять не зная ответа от периферийного устройства. Тогда можно вызвать периферийное устройство в отдельном потоке, и пока устройство отвечает, никто нам не запретит в основном потоке выполнить что-то из пункта “разрушение системы и подчистка”. Тогда блок-схема выглядит вот так:
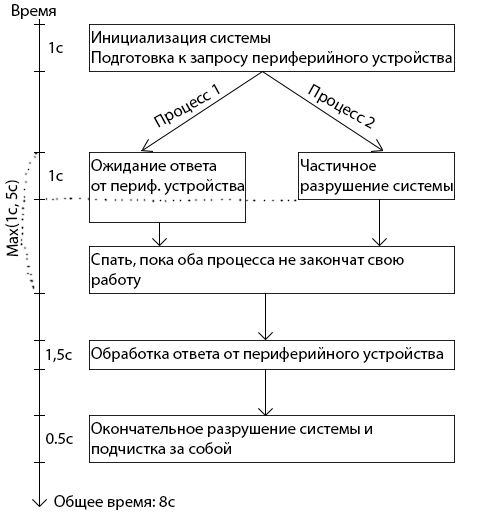
Ну а второе большое следствие из разрыва этой единой нити исполнения это то, что можно использовать больше ресурсов компьютера, на котором исполняется код. Если это какое-то трудоемкое математическое вычисление, то его можно запустить на несколько потоков (при условии, что алгоритм вычислений это позволяет), и тогда над результатом будут сразу работать несколько ядер процессора. То бишь, в абстрактной формулировке: если в несколько потоков конкурировать за какой-то ресурс, то его можно получить больше за тот же промежуток времени. Хотя, я уже говорил, что этот пункт весьма сомнителен для меня в случае серверного кода (а мы именно такой и рассматриваем).
Недостатки и трудности параллелизации
Самый большой, да и единственный значимый, мне кажется – это дополнительные расходы на поддержание многоточности, как при run time (потокам нужно как-то обмениваться между собой информацией, чтобы они могли работать на общее благо), так и в development time (многопоточные/асинхронные программы сложнее писать и поддерживать, т.к. человеческому мозгу куда проще воспринимать линейную логику исполнения). Ведь мы всегда воспринимаем мир “здесь и сейчас”, а осознать, что где-то еще происходит что-то еще, всегда получается не так ярко как текущую сцену “здесь и сейчас”. Получается, что многопоточная программа будет потреблять больше ресурсов, выполняя ту же самую задачу, что и однопоточная программа. Также, очень вероятно, она будет требовать больше времени на разработку и поддержание/расширение. Что же получается? Многопоточность может дать прирост в скорости работы за счет параллельного исполнения, и многоточность будет потреблять больше ресурсов из-за необходимости синхронизации и обмена данными между потоками. В общем-то, как всегда: параллелизация – это всего лишь инструмент. При правильном использовании он может оказаться полезным, в противном случае он будет лишним грузом.
Что меня заставило реализовать многопоточность в PHP
Я работаю над вебсайтом, который оценивает себестоимость отправки посылки из пункта А в пункт Б. По сути, это агрегатор API грузоперевозчиков. Ну, вы уже догадались? При холодном кеше в худших случаях могло получиться так, что из 1 входящего запроса на мой вебсайт “вырастают” под 200 запросов на API разных грузоперевозчиков. Естественно, делать 200 синхронных HTTP запросов – это грех куда страшнее, чем вкручивание многопоточности в PHP. Поэтому из 2-х зол я выбрал меньшее. У меня действительно был случай один на миллион в этой ситуации. Дополнительные потоки не потребляют много циклов CPU, ни сети, ни жесткого диска, очень условно говоря, мне нужны были потоки, в которых всего лишь нужно было поспать 1-2 секунды (пока генерируется ответ на стороне API перевозчика). Disclaimer: 10 раз подумайте, прежде реализовывать это у себя где-то в проекте. Я за 8 лет работы первый раз встретил случай, где это имеет смысл. Одевайте этот хомут на шею только если он вам действительно нужен.
Эволюция моей мысли (моего алгоритма)
Прежде чем я перейду к конкретным способам реализации, которые я пробовал, позвольте представить некоторые теоретические размышления на эту тему. Самое крупное деление алгоритмов разбивается по линии fork/thread текущего PHP процесса или запуск нового дочернего процесса. Во-первых, я нашел только 1 возможную реализацию на forking текущего PHP процесса (которая оказалась нерабочей ко всему прочему). Во-вторых, fork'аться в PHP – это явно пример плохой параллелизации. Почему? Да потому, что в параллельный поток нужно стараться вынести исключительно то действие, которое выполняется медленно (связь с периферийным устройством, а не интерпретацию его ответа; выполнение HTTP запроса, а не его интерпретация опять же). Смотрите пункт про параллелизацию серверного кода вверху, чтобы понять почему нужно делать именно так. В-третьих, fork'ая полноценную программу, вы обязуете себя на синхронизацию данных между ними, а это очень непросто. С другой стороны, если вы создаете дочерний процесс с буквально парочкой строк кода, которые выполняют какую-то муторную и долго-спящую операцию, вам ничего не надо синхронизировать и вы не “расползаетесь” на остальные ядра вашего сервера. Ну и как бонус, этот подход в разы гибче – вы можете запустить не PHP дочерний процесс, а bash скрипт какой-нибудь или программу на C, или вообще что попало, тут вас ограничивает только ваша фантазия (и знания Линукса, конечно).
Остановимся подробнее на дочерних процессах. Как можно организовать коммуникацию между родительским и дочерним процессами? Конечно, можно организовать их коммуникацию на файлах, можно на БД или еще на каком-то хранилище данных. Но поддерживать “зоопарк” файлов в 200 штук на каждый входящий запрос в моем конкретном случае выглядело очень гемморно. Работать с БД я не хотел, чтобы не исчерпать коннекты к MySQL (ведь это будет 200 коннектов на 1 входящий запрос – при такой арифметике я не смогу сильно масштабировать свой код и весьма быстро упрусь в количество коннектов к БД). К счастью, старый добрый Linux и так имеет инструментарий для общения между процессами (уже лет 20 как имеет и похоже, что всем его достаточно, значит и мне, и вам тоже должно быть достаточно). Таким образом моя цель была найти такую идеальную реализацию создания дочерних процессов, чтобы:
- Родительский процесс мог писать в STDIN дочернего процесса;
- Родительский процесс знал PID дочернего процесса (полезно, если нужно отправить какой-то сигнал дочернему процессу или проверить, закончил ли он свою работу);
- Родительский процесс мог читать из STDERR и STDOUT дочернего процесса;
- Родительский процесс знал exit code дочернего процесса по его завершению;
- Дочерний процесс знал PPID (PID своего родителя). Опять же, это может быть удобным для общения через сигналы. Как мы оговорились выше, мы в основном будем рассматривать параллелизацию через запуск дочернего процесса. Дочерний процесс отнюдь не должен быть PHP интерпретатором, поэтому этот пункт не относится напрямую к родителю и параллелизации PHP вообще. Это скорее проблема дочернего процесса сориентироваться в ситуации и узнать свой PPID.
Через curl_multi_exec()
Как по мне, самое бредовое из того, что я видел про параллелизацию PHP – это запускать
curl_multi_exec() на свой же вебсайт. Если вы хотите что-то исполнять асинхронно на локальной ОС, зачем вам вообще нужно подключать под это дело HTTP стек? Только потому, что cURL умеет делать асинхронные запросы? Аргумент слабоват. Реализовывать таким способом асинхронность относительно удобно, но у вас будет лишняя нагрузка на ваш вебсервер, и вам его будет сложнее настроить оптимально в плане max child worker processes (в Apache prefork MPM это “MaxClients”, в PHP FPM это “pm.max_children”), т.к. очень вероятно, что существует огромная разница между валидными входящими запросами и вашими внутренними запросами, вырожденными из асинхронности. Ну и о вопросах синхронизации данных между подпроцессами можно забыть. Ваш максимум коммуникации – это HTTP запрос и HTTP ответ. Можно общаться еще через БД, но я боюсь представить, что вам придется делать, если вы используете транзакции и вам нужно одну и ту же транзакцию видеть из обоих обработчиков.Другое дело, если запросы отправляются на другой сервер, как в моем случае. Здесь использование
curl_multi_exec() я считаю оправданным. Ваш главный плюс: можно завестись с полпинка, работы много делать не надо. Ваши минусы: не каждую логику программы можно так “вывернуть”, чтобы можно было запустить несколько cURL запросов из одного места и в том же самом месте обработать их результаты. К примеру, запросы могут идти на 2 разных хоста, и каждый из хостов может отвечать в своем собственном формате. Таким образом ваш код запросто может стать неудобным в поддержке вокруг этого curl_multi_exec() вызова. Второй минус заключается в том, что у вас мало гибкости. В этом подходе вы ничего кроме HTTP запросов асинхронно сделать никогда не сможете.Пример (сразу скажу, я его на деле сильно не пробовал, т.к. негибкость этого подхода меня сильно отпугивала): php.net/manual/en/function.curl-multi-exec.php
Через pcntl_fork()
Если скомпилировать PHP c флагом
--enable-pcntl, то в PHP появятся функции pcntl_*(). Эти функции предоставляют инфраструктуру для fork'ания текущего PHP процесса. Самая интересная из них – это pcntl_fork(). Именно она делает fork PHP процесса и в родительском процессе возвращает PID дочернего, в дочернем она возвращает ноль. Пока я набирал этот код просто примерчика, у меня в голове возник вопрос. А если PHP работает как модуль Apache из-под worker процесса Apache, то как здесь произойдет fork? Ведь по идее fork'нется целый Apache worker process. И как потом на это дело вообще отреагирует Apache master process? В воздухе веяло какое-то ощущение деления на ноль… К моменту, когда я закончил набирать примерчик с pcntl_fork(), ответ стал очевиден. Еще не догадываетесь? Все очень просто! Когда PHP работает из-под модуля Apache, функция pcntl_fork() не объявлена, даже если ваш PHP скомпилирован с нужным флагом.Якобы,
pcntl_fork() можно использовать, когда PHP работает из CLI. По поводу CGI и FastCGI интерфейсов я не уверен. Т.к. я был ограничен во времени и не занимался исследованием вакуумного пространства в полнолуние високосного года, а решал конкретную задачу, то я больше не уделил внимания этому варианту. Как я понимаю, если pcntl_fork() можно запускать из FastCGI интерфейса, то этот вариант должен работать при связке Nginx + PHP-FPM (Apache тоже можно вместо Nginx в этой формуле, просто кто использует Apache с PHP-FPM?). Может быть у кого-то из читателей есть больше опыта в этом вопросе? Пишите комментарии, и я расширю этот раздел согласно вашим дополнениям. Могу предположить, что вас ожидает достаточно проблем связанных с file descriptors и коннектами к БД, если вы пойдете путем fork'ания.Через exec()
Самый скорый на реализацию метод, который позволяет запускать любую команду в ОС (читайте “очень гибкий”). До столкновения с моей текущей задачей я всего лишь раз прибегал к этой функции. Но у меня там случай был другой, мне просто нужно было запустить команду, дать ей входные аргументы и забыть о ней. Никаких ответов мне от нее не нужно было. В процессе выполнения команда сама куда надо запишет результат. Тогда я это реализовал вот так:
exec("my-command --input1 a --input2 b &")
Без амперсанда в конце команды, она бы выполнялась синхронно, т.е. PHP процесс бы спал до окончания работы команды. Говоря по правде, я на этом способе тоже сильно долго не задерживался, но по идее, все необходимые входные аргументы можно передать через аргументы команды. STDERR и STDOUT команды можно перенаправить в файлы или named pipes. Если очень надо, то можно предварительно записать STDIN в файл или named pipe. В самом худшем случае получится где-то вот такой франкенштейн:
exec("my-command --inputargument1 a --inputargument2 b < my-stdin.txt > my-stdout.txt 2> my-stderr.txt &")
Самый большой недостаток, заключается в том, что нет хорошего способа определить закончила ли свою работу команда. Но если изначально заложить определенный интерфейс содержимого STDOUT, то можно жить весьма неплохо и на этом способе. Вам тогда нужно периодически считывать содержимое STDOUT, и дальше, основываясь на вашем протоколе содержимого STDOUT, можно интерпретировать в каком состоянии находится команда. Под передачу мета информации о текущем статусе можно завести отдельный файл дескриптор (4й, допустим).
Через popen()
Итак, наш следующий кандидат выглядит немного выигрышнее, чем
exec("my-command &") вариант. Вы уже заметили, что я пытаюсь их строить по возрастанию? Этот способ позволяет запускать команду и возвращает file descriptor на pipe. В зависимости от 2го аргумента функции popen() это будет либо STDIN дочерней команды, либо STDOUT дочерней команды. Получается как-то однобоко… Либо глухой, либо немой, зато удобно в 1 строку и с минимальной низкоуровневой морокой. Мне больше всего понравился вот такой вариант: $stdout = popen('my-command --inputargument1 a', 'r');
// Мы уже запустили команду и у нас есть дескриптор на ее STDOUT.
// Пока она занимается своей задачей, мы можем в нашем PHP процессе
// тоже делать какие-то свои полезные вещи.
do_something_while_asynchronous_command_works();
// В момент, когда нам уже пора бы знать результат работы дочерней
// команды, можно воспользоваться вот такими строками. Мы читаем
// STDOUT дочерней команды построчно и сохраняем каждую строку
// в массив (или куда вам будет угодно). Когда STDOUT pipe закроют на
// конце дочерней команды, мы выскочим из цикла, благодаря проверке
// на окончание файла.
$output = array();
while (!feof($stdout)) {
$output[] = fgets($stdout);
}
pclose($stdout);
// Мы теперь готовы интерпретировать результаты дочерней команды и
// делать любое полезное дело с ними.
do_something_with_asynchronous_command_results($output);
Якобы,
pclose() функция вернет exit code дочерней команды. Однако, php.net предупреждает, что особо доверять этому значению не нужно. Я дополнительных практических заметок по этому поводу не могу сказать, т.к. этот метод практически не тестировал.Из недостатков: невозможно узнать текущий статус дочерней команды. Иногда это может быть важным. Представьте, что мы запустили 10 асинхронных команд. Они все выполняются где-то 2 секунды, ± 10%. И в основном процессе PHP мы по окончанию каждой из команды хотим проинтерпретировать результаты. Каждая такая интерпретация у нас займет 0.5 секунды. Если бы у нас была возможность узнать закончила ли работу такая-то дочерняя команда, то мы бы могли читать STDOUT тех дочерних команд, которые уже закончили свою работу. И пока мы занимаемся интерпретацией текущей дочерней команды, остальные выполняющиеся дочерние команды весьма вероятно успеют завершиться к моменту, когда мы будем готовы интерпретировать их результат. Увы, мы так делать не можем. Максимум, что мы можем делать в этом способе – это читать STDOUT, и если STDOUT дочерней команды еще открыт, то наш основной PHP процесс будет спать до тех пор, пока дочерняя команда его не закроет либо не закончит свою работу (что неявным образом тоже закроет pipe). Мы немного теряем асинхронность, т.к. в определенных ситуациях можем “напороться” на долгий “сон” основного PHP процесса.
Второй недостаток: односторонность коммуникации. Хорошо бы иметь сразу 3 дескриптора… на все случаи жизни, так сказать. И если без STDIN можно обойтись (можно все входные данные запихнуть во входные аргументы дочерней команды), то вот без STDERR все-таки сложнее. Умельцы могут придумать такое решение:
$stdout = popen('my-command --inputargument1 a 2>&1', 'r')
Но тогда вам придется самостоятельно разбирать кашу в STDOUT, т.к. там в любой момент может оказаться содержимое STDERR. Если вам нужен STDERR, то вам придется самостоятельно на уровне ОС создавать named pipes или временные файлы и редиректить в них STDERR поток. Забегая наперед, скажу, что если вам действительно нужен STDERR, то лучше не морочиться с
popen(), а перейти к следующему пункту статьи.Через proc_open()
proc_open() — это что-то вроде старшего брата popen(). Он делает тоже самое, но умеет поддерживать больше, чем 1 pipe. Вот пример:$descriptorspec = array(
0 => array('pipe', 'r'),
1 => array('pipe', 'w'),
2 => array('pipe', 'w'),
// И можно тыкать даже больше дескрипторов. Лишь бы ваша
// дочерняя команда знала, как правильно ими пользоваться!
);
$pipes = array();
$process = proc_open('my-command –inputargument1 a', $descriptorspec, $pipes);
// Теперь $process – это дескриптор на процесс дочерней команды.
// $pipes – массив файл дескрипторов согласно $desciptorspec
// спецификации. Отсюда мы можем читать или писать в
// зависимости от направления pipe, таким образом общаясь
// между основным PHP процессом и нашей дочерней командой.
$meta_info = proc_get_status($process);
// Теперь $meta_info содержит кучу полезной информации о
// дочернем процессе, среди прочего текущий статус (исполняется
// ли) и PID дочернего процесса). Детали смотрите здесь
// http://php.net/manual/en/function.proc-get-status.php
// Сообщим то, что мы хотели сообщить дочерней команде в ее STDIN.
fwrite($pipes[0], $stdin);
fclose($pipes[0]);
do_something_while_asynchronous_command_works();
// Предположим, мы уже хотим знать результаты работы дочерней
// команды.
$stdout = stream_get_contents($pipes[1]);
$stderr = stream_get_contents($pipes[2]);
// Таким же самым образом можно считать и другие файл
// дескрипторы, если они были открыты на чтение.
// $fdX = stream_get_contents($pipes[$x]);
foreach ($pipes as $pipe) {
if (is_resource($pipe)) {
fclose($pipe);
}
}
$exit_code = proc_close($process);
$exit_code = $meta_info['running'] ? $exit_code : $meta_info['exitcode'];
Итого имеем победителя! Он нам подходит по всем критериям и запускается довольно небольшим количеством кода в PHP. Я на практике уже около недели использую этот способ и не имею нареканий. Вебсайт и сервер не видели еще настоящей нагрузки, т.к. вебсайт еще не вышел на финальную стадию, но тьфу-тьфу-тьфу у меня нет причин нарекать, и кажется, я написал код, в возможность существования которого я сам не верил дней 10 назад.
Конкретные трюки и уловки
Я рассказал про сухие реализации асинхронности в PHP. Но ведь на практике все так просто и красиво никогда не бывает, не правда ли? Асинхронность здесь не исключение. В заключение хочу привести некоторые уловки, которые помогут вам на прикладном уровне в момент применения этих техник.
base64_encode(serialize())
Если вы хотите обмениваться информацией между 2 PHP процессами, вероятно, что в какой-то момент вы захотите “толкать” между STDIN/STDOUT какие-то сложные структуры данных, присущие вашему проекту (читайте “не скаляры”). Первое, что приходит в голову – это запихнуть их в
serialize() PHP функцию (и unserialize(), соответственно, по другую сторону канала). Все бы ничего, но serialize() может вставить null byte или еще чего-то лишнее, и это сломает ваш поток. У меня были проблемы с non-ASCII символами типа á, í, ú. В итоге я на практике просто оборачиваю результат сериализации в base64, чтобы убедиться что никакой ереси в потоки ввода/вывода не попадет.Запускайте как можно раньше, потребляйте результаты как можно позже
Умелое использование асинхронного вызова – это большая наука. Нетрудно догадаться, что нужно максимально агрессивно (eager) запускать дочернюю асинхронную команду и максимально лениво (lazy) читать результаты ее работы. Ведь таким образом у вашей команды будет максимум времени на исполнение и ваш основной поток не будет заблокирован в спячке, ожидая окончание ее работы. Не все архитектуры программ удобно ложатся под этот принцип. Вы должны понимать, что запускать дочернюю команду и следующей же строчкой читать ее результат – это делать себе только хуже. Если вы планируете использовать асинхронность, постарайтесь продумать свою архитектуру как можно раньше и всегда держите это в уме. На своем конкретном примере скажу, что когда я дошел до понимания, что мне нужно параллелить свой PHP процесс, мне пришлось переписать основной движок вебсайта, развернув его более удобной стороной к асинхронности.
Прикройте асинхронный вызов синхронным кешем
Асинхронность – это лишние расходы. На синхронизацию данных (если она у вас будет), на создание и убивание дочернего процесса, на открытие и закрытие файл дескрипторов и т.п. На моем ноутбуке асинхронный вызов простого
echo "a" занимает около 3 мс. Вроде бы не много, но я вам говорил, что у меня вплоть до 200 асинхронных вызовов может быть. 200 х 3 = 600 мс. Вот я и потерял уже 600 мс в никуда.Во-вторых, якобы, вы что-то делаете асинхронно потому, что оно выполняется медленно. Так почему бы не убить 2х зайцев одним выстрелом? Кешируйте результаты асинхронной команды в каком-нибудь перманентном хранилище, будь-то БД, файловая система или memcache. Естественно, этот пункт имеет смысл только если ваши результаты не теряют своей актуальности слишком быстро. Более того, поставьте этот кеш перед всей асинхронностью, чтобы избежать тех 3 мс. На всякий случай приведу блок-схему моей мысли:

Небольшой framework для ленивых и практичных ребят
Знать теорию – это хорошо. Но обычно ленивые и практичные ребята хотят скачать какую-нибудь библиотеку, подключить ее, подергать за пару методов и решить свою проблему. На базе последнего решения (через
proc_open()) я создал очень маленькую библиотеку. Ее также удобно использовать для синхронного кеша, как я описал его в предыдущем разделе. Ссылка: github.com/bucefal91/php-async