В предыдущей статье были рассмотрены критерии выбора между GUID и автоинкрементом в качестве первичного ключа. Основная мысль была в том, что если по каким-то базовым критериям (наличие репликации, требования к уникальности и т.д.) есть необходимость использовать GUID, то нужно учесть нюансы, связанные с его производительностью. Тесты вставки записей показали, что наиболее быстрым вариантом являются последовательные GUID, генерируемые на клиенте, причем вставка в этом случае работает даже быстрее, чем при использовании автоинкремента. Но в статье не был рассмотрен проигрыш в производительности выборки при использовании GUID в качестве ключа. В этой статье я попробую закрыть этот пробел.
Тестировать будем следующие сценарии:
Разделение на сценарий с одной дочерней коллекцией и несколькими нужен для понимания, насколько влияет количество соединений (JOIN) по ключу в одном запросе на конечный результат. И насколько уменьшение производительности зависит от типа ключа.
С помощью этих сценариев сравним три варианта ключей:
Для этого понадобится три набора таблиц, каждый из которых состоит из главной таблицы и 5 таблиц для дочерних записей.
Тестирование будем проводить, как и в предыдущей статье, с использованием Entity Framework 6.1.3. База данных — Microsoft SQL Server 2014 Developer Edition (64 bit). В каждую из главных таблиц добавим по 10000 записей, где у каждой записи будет 5 дочерних коллекций, содержащих по 10 элементов. Таким образом, в таблицах дочерних коллекций будет содержаться по 100000 строк.
Исходный код тестовой программы можно найти здесь.
Ниже приведены диаграммы полученных результатов. Для удобства сравнения на них указаны проценты, где за 100% берется минимальный результат из всех вариантов.
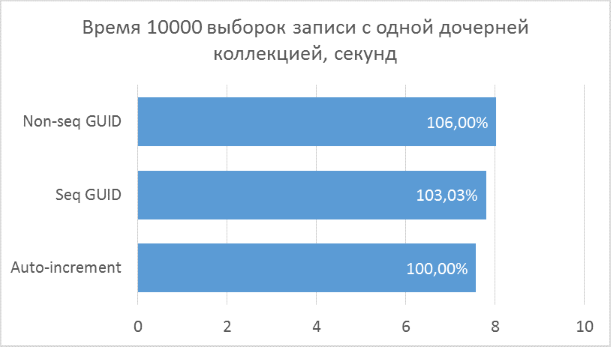
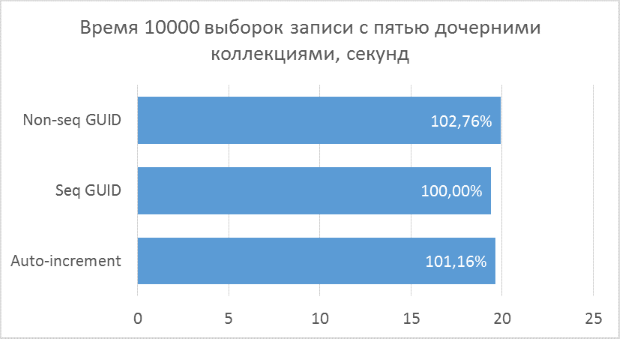
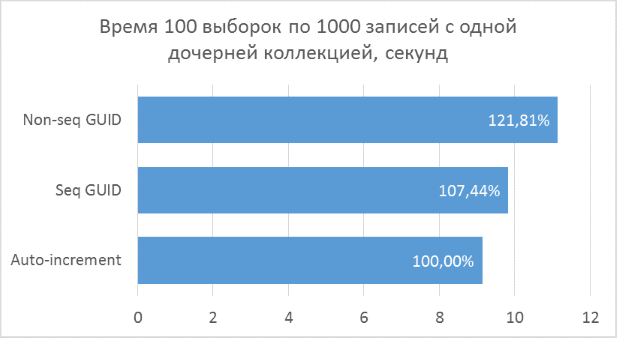
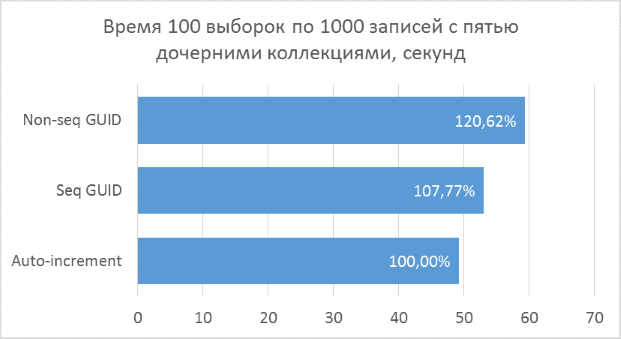
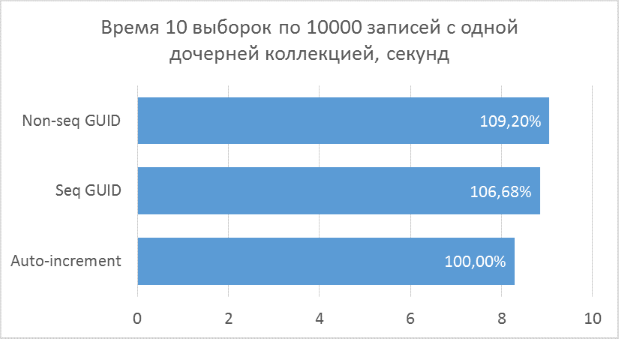
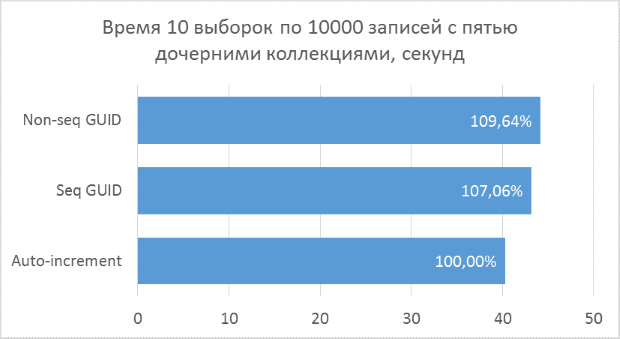
Полученные результаты показывают, что операции выборки, оперирующие целочисленными ключами, конечно же, быстрее, чем в случае с GUID. Но разница в производительности между последовательным GUID и автоинкрементом не настолько велика, чтобы говорить у существенном проигрыше при выборе GUID.
Также следует отметить, что процентная разница времени выполнения сохраняется при увеличении количества соединений в одном запросе. Чего, на самом деле, и стоило ожидать, но убедиться нужно было.
Непоследовательный GUID показал в некоторых случаях заметно худшие результаты, что, опять же, закономерно. На практике разница между ним и остальными двумя вариантами может оказаться еще больше — в тех случаях, когда база данных не может быть полностью закеширована в оперативной памяти и понадобится большой объем чтений с диска для получения всех соседних дочерних записей (подобный тест был описан в предыдущей статье для вставки записей). Соответственно, использовать такой вариант первичного ключа на практике не имеет смысла.
Несмотря на то, что этот тест показал небольшую разницу между автоинкрементом и последовательным GUID, я бы не стал рассматривать последний, как вариант, который можно бездумно использовать во всех ситуациях. GUID занимает больше места, особенно в текстовом представлении. Если в системе есть преобразование объектов в текстовый формат (JSON, XML), и порция объектов, преобразуемая за один раз, содержит большое количество идентификаторов — разница в объеме по сравнению с целочисленными ключами может оказаться существенной. Обратное преобразование (десериализация) для GUID намного медленнее, чем для числа, но, на мой взгляд, этой разницей можно пренебречь. Это время все равно очень мало — на моей машине на парсинг ста тысяч GUID-ов уходит 60 миллисекунд, против 12 миллисекунд для целых чисел. Более ощутимой проблемой при использовании уникальных идентификаторов может оказаться то, что ими гораздо сложнее оперировать при поддержке и отладке, чем целыми числами.
Общий вывод по итогам обеих статей я бы сформулировал так: если по каким-либо причинам, не связанным с производительностью, есть надобность использовать GUID в качестве первичного ключа, то из возможных реализаций следует выбрать последовательный, генерируемый на клиенте. При этом, в большинстве случаев, насчет потери производительности операций чтения можно не переживать. Основная проблема GUID в плане производительности выборки не в том, что процессору нужно больше действий делать для сравнения (это, скорее всего, оптимизировано, да и сравнений при поиске по ключу происходит немного, если это не скан), а в том, что он занимает в 4 раза больше обычного int, соответственно меньшее количество страниц индексов и данных может быть закешировано в том же объеме оперативной памяти. Если в вашей базе индексы первичных и внешних ключей занимают десятки процентов от общего объема базы и объем активно используемых данных не может быть полностью закеширован, причем нет возможности увеличивать объем оперативной памяти — имеет смысл подумать о более «легких» ключах. Но такая ситуация мне кажется достаточно редкой. Также следует обратить внимание на потенциальные проблемы при сериализации/десериализации, упомянутые выше. Однако, соответствующий случай, который я видел на практике, был не столько проблемой самого GUID, сколько проблемой неправильного дизайна API — вычитывалась вся коллекция за один раз без ограничений, пейджинга и т.д.
Тестировать будем следующие сценарии:
- Поиск отдельной записи по первичному ключу с вычиткой одной дочерней коллекции
- Поиск отдельной записи по первичному ключу с вычиткой нескольких дочерних коллекций
- Выборка нескольких записей с вычиткой одной дочерней коллекции для каждой записи
- Выборка нескольких записей с вычиткой нескольких дочерних коллекций для каждой записи
- Выборка всех записей из таблицы с вычиткой одной дочерней коллекции для каждой записи
- Выборки всех записей из таблицы с вычиткой всех дочерних коллекций
Разделение на сценарий с одной дочерней коллекцией и несколькими нужен для понимания, насколько влияет количество соединений (JOIN) по ключу в одном запросе на конечный результат. И насколько уменьшение производительности зависит от типа ключа.
С помощью этих сценариев сравним три варианта ключей:
- Автоинкремент
- Последовательный GUID
- Непоследовательный GUID
Для этого понадобится три набора таблиц, каждый из которых состоит из главной таблицы и 5 таблиц для дочерних записей.
Тестирование будем проводить, как и в предыдущей статье, с использованием Entity Framework 6.1.3. База данных — Microsoft SQL Server 2014 Developer Edition (64 bit). В каждую из главных таблиц добавим по 10000 записей, где у каждой записи будет 5 дочерних коллекций, содержащих по 10 элементов. Таким образом, в таблицах дочерних коллекций будет содержаться по 100000 строк.
Исходный код тестовой программы можно найти здесь.
Ниже приведены диаграммы полученных результатов. Для удобства сравнения на них указаны проценты, где за 100% берется минимальный результат из всех вариантов.
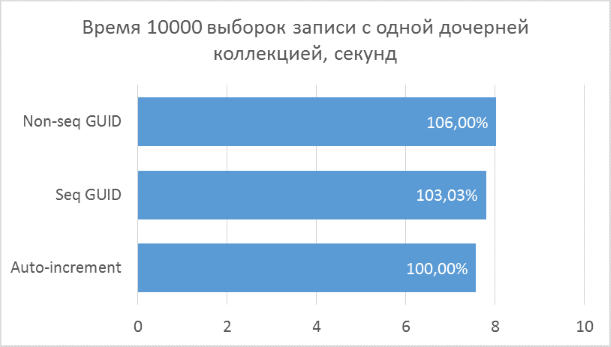

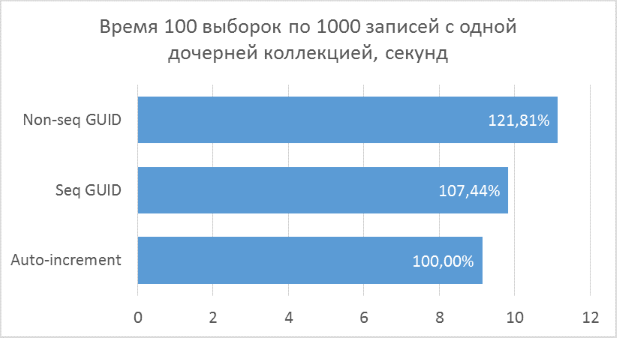
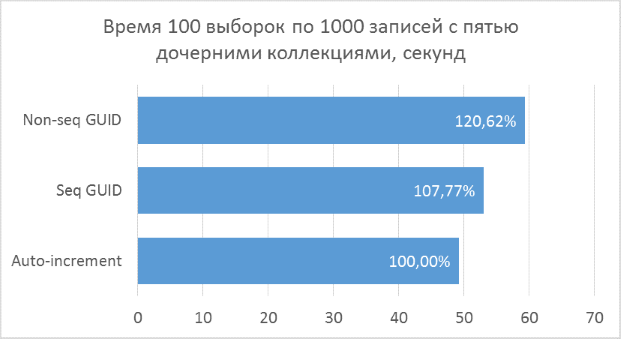
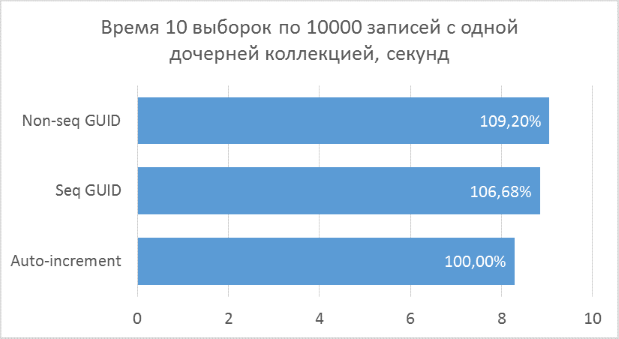
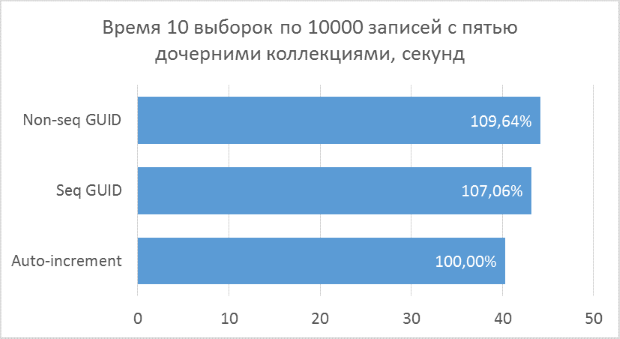
Полученные результаты показывают, что операции выборки, оперирующие целочисленными ключами, конечно же, быстрее, чем в случае с GUID. Но разница в производительности между последовательным GUID и автоинкрементом не настолько велика, чтобы говорить у существенном проигрыше при выборе GUID.
Также следует отметить, что процентная разница времени выполнения сохраняется при увеличении количества соединений в одном запросе. Чего, на самом деле, и стоило ожидать, но убедиться нужно было.
Непоследовательный GUID показал в некоторых случаях заметно худшие результаты, что, опять же, закономерно. На практике разница между ним и остальными двумя вариантами может оказаться еще больше — в тех случаях, когда база данных не может быть полностью закеширована в оперативной памяти и понадобится большой объем чтений с диска для получения всех соседних дочерних записей (подобный тест был описан в предыдущей статье для вставки записей). Соответственно, использовать такой вариант первичного ключа на практике не имеет смысла.
Несмотря на то, что этот тест показал небольшую разницу между автоинкрементом и последовательным GUID, я бы не стал рассматривать последний, как вариант, который можно бездумно использовать во всех ситуациях. GUID занимает больше места, особенно в текстовом представлении. Если в системе есть преобразование объектов в текстовый формат (JSON, XML), и порция объектов, преобразуемая за один раз, содержит большое количество идентификаторов — разница в объеме по сравнению с целочисленными ключами может оказаться существенной. Обратное преобразование (десериализация) для GUID намного медленнее, чем для числа, но, на мой взгляд, этой разницей можно пренебречь. Это время все равно очень мало — на моей машине на парсинг ста тысяч GUID-ов уходит 60 миллисекунд, против 12 миллисекунд для целых чисел. Более ощутимой проблемой при использовании уникальных идентификаторов может оказаться то, что ими гораздо сложнее оперировать при поддержке и отладке, чем целыми числами.
Общий вывод по итогам обеих статей я бы сформулировал так: если по каким-либо причинам, не связанным с производительностью, есть надобность использовать GUID в качестве первичного ключа, то из возможных реализаций следует выбрать последовательный, генерируемый на клиенте. При этом, в большинстве случаев, насчет потери производительности операций чтения можно не переживать. Основная проблема GUID в плане производительности выборки не в том, что процессору нужно больше действий делать для сравнения (это, скорее всего, оптимизировано, да и сравнений при поиске по ключу происходит немного, если это не скан), а в том, что он занимает в 4 раза больше обычного int, соответственно меньшее количество страниц индексов и данных может быть закешировано в том же объеме оперативной памяти. Если в вашей базе индексы первичных и внешних ключей занимают десятки процентов от общего объема базы и объем активно используемых данных не может быть полностью закеширован, причем нет возможности увеличивать объем оперативной памяти — имеет смысл подумать о более «легких» ключах. Но такая ситуация мне кажется достаточно редкой. Также следует обратить внимание на потенциальные проблемы при сериализации/десериализации, упомянутые выше. Однако, соответствующий случай, который я видел на практике, был не столько проблемой самого GUID, сколько проблемой неправильного дизайна API — вычитывалась вся коллекция за один раз без ограничений, пейджинга и т.д.
