С 19 по 25 июля проходил хакатон Deephack, где участники улучшали алгоритм обучения с подкреплением на базе Google Deepmind. Цель хакатона — научиться лучше играть в классические игры Atari (Space Invaders, Breakout и др.). Мы хотим рассказать, почему это важно и как это было.
Авторы статьи: Иван Лобов IvanLobov, Константин Киселев mrKonstantin, Георгий Овчинников ovchinnikoff.
Фотографии мероприятия: Мария Молокова, Политехнический музей.
Почему хакатон по обучению с подкреплением это круто:

Начнем с того, в каком состоянии находится сейчас машинное обучение и что с помощью него можно решать. Есть 3 основных направления (намеренно упрощаем):
Так вот задачи обучения с учителем решены уже практически для всех областей. Однако следующий большой шаг — это области машинного обучения, где нет очевидного и мгновенного результата взаимодействия. Именно в этом направлении движется сейчас область машинного обучения.
Есть агент и окружающая среда — игра. Для агента игра выглядит как черный ящик — он не знает ее правил и не догадывается, что это вообще игра. На старте обучения игра выдает агенту набор действий (actions), который он может в ней выполнять, при этом все действия для агента выглядят идентично. Далее на каждом шаге агент выполняет одно из действий и получает в ответ состояние игры (state) и очки (reward). Состояние игры — это картинка с экрана. Очки (reward) — это награда за совершенные действия, может быть положительной, отрицательной или 0. Во время обучения агент выбирает действия и пробует их в игре, получая очки. Задача агента — выработать стратегию, которая максимизируют финальное количество очков.
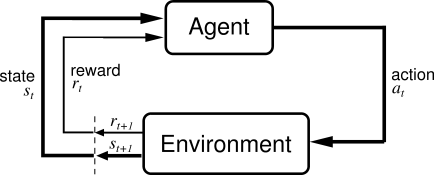
Фактически мы имитируем обучение человека игре (очень грубо, так как на самом деле мы не знаем, как именно мы с вами обучаемся). С некоторыми отличиями, например: у взрослого человека уже есть большой опыт и сформирован широкий класс ассоциативных понятий, что позволяет ему с первого взгляда понять правила игры и быстро обучиться. В нашем случае модель обучения агента скорее напоминает обучение 2-х летнего ребенка: сначала он произвольным образом нажимает кнопки управления и постепенно, улавливая закономерности и принципы игры, начинает играть лучше и лучше.
Для обучения необходима модель, с помощью которой наш алгоритм аппроксимирует правила взаимодействия агента со средой. Одной из распространенных техник, которую успешно применила команда DeepMind в играх Atari, является Q-learning. В данной технике моделируется функция награды Q. Далее при тестировании агент выбирает действия по правилу: действие должно максимизировать функцию награды.
В качестве модели могут быть деревья решений, многомерная линейная функция, нейронные сети и т.д. Когда мы имеем дело с сложными многомерными данными, такими как картинки, хорошо себя зарекомендовали сверточные нейронные сети (convolutional neural networks). Инновация Deepmind — совместить сверточные сети и Q-learning.
Сейчас удается научить компьютер играть в простейшие игры лучше человека, что на большинство людей не производит большого впечатления. Следующий шаг — научить компьютер играть, скажем в Doom, т.е. заставить его обучаться в 3-х мерной среде. Далее постепенно усложнять игры. Основная задача — выработать определенные принципы поиска оптимальных решений на поставленные задачи в сложных средах и употребить эти принципы в виде алгоритмов в реальном мире. Таким образом, машины, играя в игры, могут получить эффективное представление (representation) об окружающей их среде и использовать его для обобщения прошлого опыта в новых ситуациях.

Если удастся заставить компьютер самостоятельно обучаться играть, например в Need For Speed, и научиться играть хорошо, то созданные алгоритмы с небольшими модификациями возможно будет применить в обучении роботов водить реальные автомобили. И не только автомобиля… Это позволит придти к массовому использованию роботов, начиная от персональных помощников, заканчивая умными самообслуживаемыми системами, умной городской средой, в которой машины под надзором человека самостоятельно обслуживает всю сложную городскую инфраструктуру.
Теперь понятно, зачем Google приобрел Deepmind за более чем $400 млн.
Организаторы подготовились к хакатону серьёзно: 7 полных дней с проживанием, конкурс на участие — 5 человек на место, лекторы из топ-10 исследователей в области машинного обучения, 15 gpu-кластеров, 24/7 поддержка участников по любым вопросам. Место проведения — кампус МФТИ в Долгопрудном.
Порядок проведения конкурса:
Stella (эмулятор Atari) -> ALE (Arcade Learning Environment) -> фреймворк машинного обучения на выбор.
За основу всех решений был взят открытый код Google Deepmind и статья 2015 г. в Nature. Команды решали задачу в одном из трёх фреймворков ML: Lua+Torch (оригинальный код на нём), Python+Theano или C++/Caffe. Мы выбрали Python+Theano, так как у нас в нем было больше опыта. Не можем однозначно выделить лучший фреймворк, у каждого были свои минусы. В целом, есть ощущение, что область ещё свежая, поэтому проверенного и хорошо работающего кода мало. Многое приходится переписывать, перепроверять и дебажить. Значимых преимуществ одного из фреймворков не нашли: ни в скорости расчётов (всё равно узкое горлышко — свёртки в cuDNN), ни в удобстве прототипирования.
Для вычислений каждой команде был выделен кластер с 4 GRID K520 на AWS (g2.8xlarge), поэтому можно было запускать до 4 расчётов одновременно. Этого было достаточно, чтобы в течение недели прогнать некоторое количество тестов (полноценный тест обучается на одном GPU ~5 полных дней, однако мы гоняли короткие десятичасовые тесты), которые помогали проверить первые гипотезы. Но недостаточно, чтобы провести полноценное исследование, поэтому некоторые команды продолжают развивать свои наработки после окончания хакатона. Хотя тут вопрос не столько в железе, сколько в реальном времени.
Space Invaders
Kung Fu Master
Все ещё свежие, обсуждают идеи:

Первая (?) ночь прямо в коворкинге:

Несмотря на усталость все слушают лекции:

Последние дни перед финалами. Несколько дней почти без сна. Всё ещё работают только самые стойкие:

Финал на ВДНХ. Всё уже решено, осталось болеть за обученные модели:

Участники хакатона:

У нас у всех очень разный бэкграунд — реклама, IT, наука. Однако нас объединяет одно — мы видим будущее за развитием машинного обучения и понимаем, что у нас в России очень мало этим занимаются:
При этом все знания, ПО и даже железо для глубокого обучения доступны любому студенту. Уровень вхождения в область с точки зрения трудозатрат тоже не зашкаливает.
Куда хотелось бы двигаться:
Если у вас есть идеи или предложения, как это можно делать, пишите в комментариях.
P.S. Спасибо большое всем организаторам, а особенно Евгению Ботвиновскому, Сергею Плису, Михаилу Бурцеву, Андрею Пакошу, Елизавете Чернягиной, Виталию Львовичу Дунину-Барковскому, Валерии Цвелой и др.
Авторы статьи: Иван Лобов IvanLobov, Константин Киселев mrKonstantin, Георгий Овчинников ovchinnikoff.
Фотографии мероприятия: Мария Молокова, Политехнический музей.
Почему хакатон по обучению с подкреплением это круто:
- Это первый в России хакатон с использованием глубокого обучения и обучения с подкреплением;
- Алгоритм Google Deepmind — одно из последних достижений в области обучения с подкреплением;
- Если вас интересует искусственный интеллект, то эта тема — очень близка к этому понятию (хотя мы сами и не хотели бы называть это ИИ).

Откуда интерес к исследованию обучения с подкреплением?
Начнем с того, в каком состоянии находится сейчас машинное обучение и что с помощью него можно решать. Есть 3 основных направления (намеренно упрощаем):
- Обучение с учителем — это любые задачи, где алгоритм обучается с помощью примеров: дал ответ — получил результат. Сюда попадают регрессии и классификации. Задачи из реального мира: оценить стоимость недвижимости, прогнозировать продажи, предсказывать землетрясения;
- Обучение без учителя — это задачи без “ответов”, где нужно найти закономерности в данных, найти “похожесть” или “непохожесть”. Задачи из реального мира: кластеризация потребителей, поиск правил ассоциации;
- Обучение с подкреплением — это промежуточный тип задач, когда обучение происходит при взаимодействии с некой средой. Алгоритм (агент) осуществляет действия в среде и иногда получает обратную связь. Под этот класс задач попадают многие “интересные” человеческие активности: спортивные соревнования (в каждую секунду времени у вас нет “правильного” действия, есть только результат — забит гол или нет), переговоры, процесс научного исследования и т.д.
Так вот задачи обучения с учителем решены уже практически для всех областей. Однако следующий большой шаг — это области машинного обучения, где нет очевидного и мгновенного результата взаимодействия. Именно в этом направлении движется сейчас область машинного обучения.
Как работают алгоритмы обучения в подкреплением на примере игр Atari (интуиция)
Есть агент и окружающая среда — игра. Для агента игра выглядит как черный ящик — он не знает ее правил и не догадывается, что это вообще игра. На старте обучения игра выдает агенту набор действий (actions), который он может в ней выполнять, при этом все действия для агента выглядят идентично. Далее на каждом шаге агент выполняет одно из действий и получает в ответ состояние игры (state) и очки (reward). Состояние игры — это картинка с экрана. Очки (reward) — это награда за совершенные действия, может быть положительной, отрицательной или 0. Во время обучения агент выбирает действия и пробует их в игре, получая очки. Задача агента — выработать стратегию, которая максимизируют финальное количество очков.

Фактически мы имитируем обучение человека игре (очень грубо, так как на самом деле мы не знаем, как именно мы с вами обучаемся). С некоторыми отличиями, например: у взрослого человека уже есть большой опыт и сформирован широкий класс ассоциативных понятий, что позволяет ему с первого взгляда понять правила игры и быстро обучиться. В нашем случае модель обучения агента скорее напоминает обучение 2-х летнего ребенка: сначала он произвольным образом нажимает кнопки управления и постепенно, улавливая закономерности и принципы игры, начинает играть лучше и лучше.
Для обучения необходима модель, с помощью которой наш алгоритм аппроксимирует правила взаимодействия агента со средой. Одной из распространенных техник, которую успешно применила команда DeepMind в играх Atari, является Q-learning. В данной технике моделируется функция награды Q. Далее при тестировании агент выбирает действия по правилу: действие должно максимизировать функцию награды.
В качестве модели могут быть деревья решений, многомерная линейная функция, нейронные сети и т.д. Когда мы имеем дело с сложными многомерными данными, такими как картинки, хорошо себя зарекомендовали сверточные нейронные сети (convolutional neural networks). Инновация Deepmind — совместить сверточные сети и Q-learning.
К чему приведет развитие машинного обучения?
Сейчас удается научить компьютер играть в простейшие игры лучше человека, что на большинство людей не производит большого впечатления. Следующий шаг — научить компьютер играть, скажем в Doom, т.е. заставить его обучаться в 3-х мерной среде. Далее постепенно усложнять игры. Основная задача — выработать определенные принципы поиска оптимальных решений на поставленные задачи в сложных средах и употребить эти принципы в виде алгоритмов в реальном мире. Таким образом, машины, играя в игры, могут получить эффективное представление (representation) об окружающей их среде и использовать его для обобщения прошлого опыта в новых ситуациях.

Если удастся заставить компьютер самостоятельно обучаться играть, например в Need For Speed, и научиться играть хорошо, то созданные алгоритмы с небольшими модификациями возможно будет применить в обучении роботов водить реальные автомобили. И не только автомобиля… Это позволит придти к массовому использованию роботов, начиная от персональных помощников, заканчивая умными самообслуживаемыми системами, умной городской средой, в которой машины под надзором человека самостоятельно обслуживает всю сложную городскую инфраструктуру.
Теперь понятно, зачем Google приобрел Deepmind за более чем $400 млн.
Как проходил хакатон
Организаторы подготовились к хакатону серьёзно: 7 полных дней с проживанием, конкурс на участие — 5 человек на место, лекторы из топ-10 исследователей в области машинного обучения, 15 gpu-кластеров, 24/7 поддержка участников по любым вопросам. Место проведения — кампус МФТИ в Долгопрудном.
Порядок проведения конкурса:
- Отборочный тур (первые 6 дней) — кто лучше научится играть в Gopher, Seaquest и Tutakham. Наша команда, Rockband, заняла 3-е место;
- Финалы — олимпийская система из 8 команд на 3-х заранее неизвестных играх (Space Invaders, Hero, Kung-Fu Master).
На чём всё это работало? (Софт)
Stella (эмулятор Atari) -> ALE (Arcade Learning Environment) -> фреймворк машинного обучения на выбор.
За основу всех решений был взят открытый код Google Deepmind и статья 2015 г. в Nature. Команды решали задачу в одном из трёх фреймворков ML: Lua+Torch (оригинальный код на нём), Python+Theano или C++/Caffe. Мы выбрали Python+Theano, так как у нас в нем было больше опыта. Не можем однозначно выделить лучший фреймворк, у каждого были свои минусы. В целом, есть ощущение, что область ещё свежая, поэтому проверенного и хорошо работающего кода мало. Многое приходится переписывать, перепроверять и дебажить. Значимых преимуществ одного из фреймворков не нашли: ни в скорости расчётов (всё равно узкое горлышко — свёртки в cuDNN), ни в удобстве прототипирования.
На чём всё это работало? (Железо)
Для вычислений каждой команде был выделен кластер с 4 GRID K520 на AWS (g2.8xlarge), поэтому можно было запускать до 4 расчётов одновременно. Этого было достаточно, чтобы в течение недели прогнать некоторое количество тестов (полноценный тест обучается на одном GPU ~5 полных дней, однако мы гоняли короткие десятичасовые тесты), которые помогали проверить первые гипотезы. Но недостаточно, чтобы провести полноценное исследование, поэтому некоторые команды продолжают развивать свои наработки после окончания хакатона. Хотя тут вопрос не столько в железе, сколько в реальном времени.
Примеры того, как играет обученная за 24 часа модель:
Space Invaders
Kung Fu Master
Как это было (фото)
Все ещё свежие, обсуждают идеи:

Первая (?) ночь прямо в коворкинге:

Несмотря на усталость все слушают лекции:

Последние дни перед финалами. Несколько дней почти без сна. Всё ещё работают только самые стойкие:

Финал на ВДНХ. Всё уже решено, осталось болеть за обученные модели:

Участники хакатона:

Вместо заключения
У нас у всех очень разный бэкграунд — реклама, IT, наука. Однако нас объединяет одно — мы видим будущее за развитием машинного обучения и понимаем, что у нас в России очень мало этим занимаются:
- Учебных заведений — единицы с профессорами, которые что-то публикуют;
- Компаний, где реально что-то применяют, — хватит двух рук, чтобы пересчитать. И 3-х пальцев, чтобы пересчитать тех, кто использует глубокое обучение в масштабе;
- Специалистов — сотни, может 1000 (?) человек, которые могут собрать сверточную сеть.
При этом все знания, ПО и даже железо для глубокого обучения доступны любому студенту. Уровень вхождения в область с точки зрения трудозатрат тоже не зашкаливает.
Куда хотелось бы двигаться:
- Популяризация возможностей ML у обычных людей;
- Популяризация ML и глубокого обучения у студентов;
- Популяризация применения ML и глубокого обучения в бизнесе;
Если у вас есть идеи или предложения, как это можно делать, пишите в комментариях.
P.S. Спасибо большое всем организаторам, а особенно Евгению Ботвиновскому, Сергею Плису, Михаилу Бурцеву, Андрею Пакошу, Елизавете Чернягиной, Виталию Львовичу Дунину-Барковскому, Валерии Цвелой и др.
