Данная статья подготовлена Алексеем Струченко, начальником отдела оптимизации СУБД и приложений компании «Инфосистемы Джет»
Вышедшая в июле 2014 года опция Database In-Memory является самой ожидаемой и самой обсуждаемой инновацией Oracle в семействе продуктов Oracle Database. За последние несколько месяцев сотрудники компании Oracle регулярно знакомили российское оракловое сообщество с особенностями новой опции.
На Oracle Day 2014 в Москве мне выпала честь дополнить теоретическую презентацию Игоря Мельникова (Oracle) по Database In-Memory практической демонстрацией. Эту демонстрацию в полном объеме показать не удалось – оказалось не так-то просто подключить проектор к ноутбуку, соединенному с демонстрационной базой. Поэтому я решил воспользоваться трибуной Habrahabr и все-таки донести суть демонстрации Database In-Memory до сообщества.
Итак, есть две таблицы – PERSONS и CREDITS, – в которых существенно разное число полей. Структуру таблицы PERSONS приведем целиком, т.к. в ней всего четыре поля (COUNTRY_ID – ссылка на страну, SALARY – поле для аналитики):
В таблице CREDITS двадцать три поля, поэтому приведем только существенную часть ее структуры (COUNTRY – ссылка на страну, CREDIT_LIMIT – поле для аналитики):
Справочник стран взят из интернета, таблицы PERSONS и CREDITS заполнены случайным образом так, чтобы их записи ссылались только на страны Европы – всего в таблицах PERSONS и CREDITS получилось по 21248349 записей.
Роль аналитических запросов в демонстрации будут играть запросы вида:
Конкретно этот запрос считает сумму SALARY по всем записям таблицы PERSONS, которые связаны со странами на букву R – в Европе это Россия и Румыния. Причем оба участвующие в запросе поля сложены в In-Memory для обеих таблиц PERSONS и CREDITS:
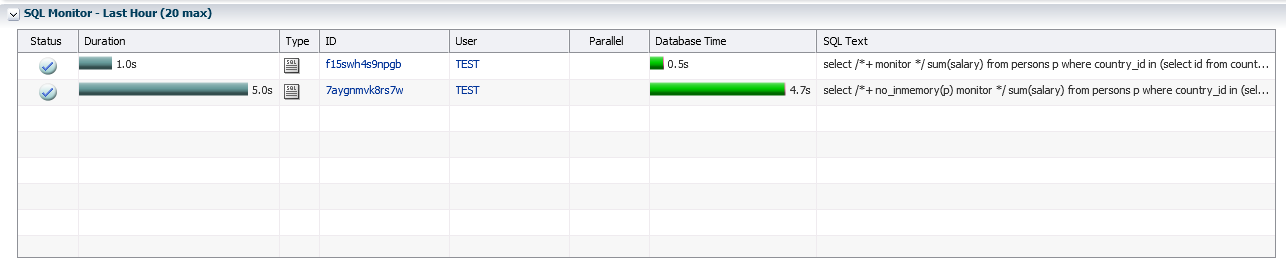
Результат выполнения аналитического запроса из таблицы PERSONS при использовании Database In-Memory оказывается в ПЯТЬ раз быстрее (ниже приведены тайминги из SQL*Plus и SQL Monitor из Enterprise Manager):

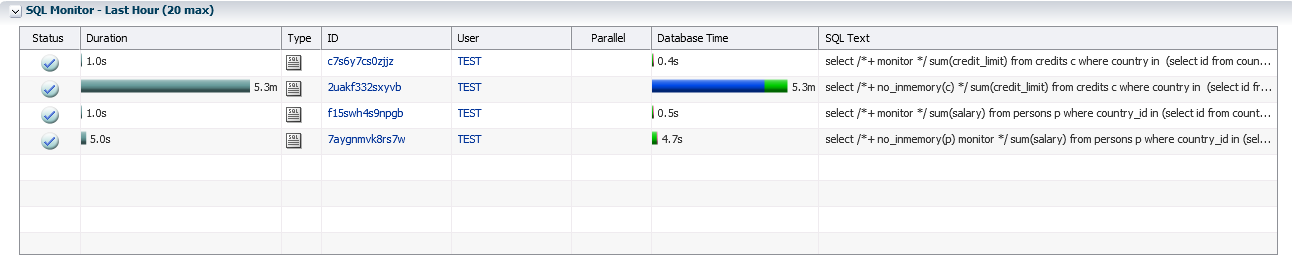
Результат выполнения подобного аналитического запроса из таблицы CREDITS при использовании Database In-Memory оказывается быстрее более чем в СЕМЬСОТ раз:

В таблице PERSONS мало полей, и она заведомо помещается в память и без использования Database In-Memory. В первом опыте мы сравниваем производительность Oracle Database при строковом (традиционный буферный кэш) и колоночном (In-Memory) хранении данных в памяти. Колоночный способ хранения в этом опыте дает выигрыш в пять раз за счет ряда реализованных в In-Memory механизмов.
В таблице CREDITS полей много, и она либо в память не помещается, либо Oracle сам отказывается класть ее в память, опасаясь «вымывания» кеша. Во втором опыте мы сравниваем чтение из памяти и чтение с диска, что хорошо видно на SQL Monitor (синим цветом обозначается ввод–вывод). Чтение из памяти действительно быстрее в сотни раз, и полученный в этом опыте выигрыш в 700 раз вполне ожидаем.
Какой из этого следует вывод? В Database In-Memory действительно реализована красивая наука, способная показывать ускорения запросов в сотни и тысячи раз. Но это должны быть особенные запросы – например, на таких больших таблицах, что в память помещается только несколько нужных для аналитики полей.
А если при тестировании In-Memory будут использоваться запросы из таблиц типа PERSONS, то результат может быть другим, что, возможно, приведет к обманутым ожиданиям. В некотором роде можно считать этот пост инструкцией “Как нужно и как не нужно демонстрировать работу опции Database In-Memory”.
Мы будем рады вашим конструктивным комментариям.
Вышедшая в июле 2014 года опция Database In-Memory является самой ожидаемой и самой обсуждаемой инновацией Oracle в семействе продуктов Oracle Database. За последние несколько месяцев сотрудники компании Oracle регулярно знакомили российское оракловое сообщество с особенностями новой опции.
На Oracle Day 2014 в Москве мне выпала честь дополнить теоретическую презентацию Игоря Мельникова (Oracle) по Database In-Memory практической демонстрацией. Эту демонстрацию в полном объеме показать не удалось – оказалось не так-то просто подключить проектор к ноутбуку, соединенному с демонстрационной базой. Поэтому я решил воспользоваться трибуной Habrahabr и все-таки донести суть демонстрации Database In-Memory до сообщества.
Итак, есть две таблицы – PERSONS и CREDITS, – в которых существенно разное число полей. Структуру таблицы PERSONS приведем целиком, т.к. в ней всего четыре поля (COUNTRY_ID – ссылка на страну, SALARY – поле для аналитики):
| ID | NOT NULL | NUMBER |
| COUNTRY_ID | NUMBER | |
| NAME | VARCHAR2(50) | |
| SALARY | NUMBER |
В таблице CREDITS двадцать три поля, поэтому приведем только существенную часть ее структуры (COUNTRY – ссылка на страну, CREDIT_LIMIT – поле для аналитики):
| ID | NOT NULL | NUMBER |
| NAME | VARCHAR2(50) | |
| COUNTRY | NUMBER | |
| CREDIT_LIMIT | NUMBER |
Справочник стран взят из интернета, таблицы PERSONS и CREDITS заполнены случайным образом так, чтобы их записи ссылались только на страны Европы – всего в таблицах PERSONS и CREDITS получилось по 21248349 записей.
Роль аналитических запросов в демонстрации будут играть запросы вида:
SQL> select sum(salary) from persons where country_id in (select id from countries where name like 'R%');
Конкретно этот запрос считает сумму SALARY по всем записям таблицы PERSONS, которые связаны со странами на букву R – в Европе это Россия и Румыния. Причем оба участвующие в запросе поля сложены в In-Memory для обеих таблиц PERSONS и CREDITS:
SQL> select table_name,COLUMN_NAME,INMEMORY_COMPRESSION from v$im_column_level where table_name in ('PERSONS','CREDITS');
| PERSONS | COUNTRY_ID | FOR QUERY HIGH |
| PERSONS | SALARY | FOR QUERY HIGH |
| CREDITS | COUNTRY | FOR QUERY HIGH |
| CREDITS | CREDIT_LIMIT | FOR QUERY HIGH |
Результат выполнения аналитического запроса из таблицы PERSONS при использовании Database In-Memory оказывается в ПЯТЬ раз быстрее (ниже приведены тайминги из SQL*Plus и SQL Monitor из Enterprise Manager):
SQL> select /*+ no_inmemory(p) monitor */ sum(salary) from persons p where country_id in (select id from countries where name like 'R%');
Elapsed: 00:00:04.68
SQL> select /*+ monitor */ sum(salary) from persons p where country_id in (select id from countries where name like 'R%');
Elapsed: 00:00:00.48
Результат выполнения подобного аналитического запроса из таблицы CREDITS при использовании Database In-Memory оказывается быстрее более чем в СЕМЬСОТ раз:
SQL> select /*+ no_inmemory(c) */ sum(credit_limit) from credits c where country in (select id from countries where name like 'R%');
Elapsed: 00:05:16.35
SQL> select /*+ monitor */ sum(credit_limit) from credits c where country in (select id from countries where name like 'R%');
Elapsed: 00:00:00.43
В таблице PERSONS мало полей, и она заведомо помещается в память и без использования Database In-Memory. В первом опыте мы сравниваем производительность Oracle Database при строковом (традиционный буферный кэш) и колоночном (In-Memory) хранении данных в памяти. Колоночный способ хранения в этом опыте дает выигрыш в пять раз за счет ряда реализованных в In-Memory механизмов.
В таблице CREDITS полей много, и она либо в память не помещается, либо Oracle сам отказывается класть ее в память, опасаясь «вымывания» кеша. Во втором опыте мы сравниваем чтение из памяти и чтение с диска, что хорошо видно на SQL Monitor (синим цветом обозначается ввод–вывод). Чтение из памяти действительно быстрее в сотни раз, и полученный в этом опыте выигрыш в 700 раз вполне ожидаем.
Какой из этого следует вывод? В Database In-Memory действительно реализована красивая наука, способная показывать ускорения запросов в сотни и тысячи раз. Но это должны быть особенные запросы – например, на таких больших таблицах, что в память помещается только несколько нужных для аналитики полей.
А если при тестировании In-Memory будут использоваться запросы из таблиц типа PERSONS, то результат может быть другим, что, возможно, приведет к обманутым ожиданиям. В некотором роде можно считать этот пост инструкцией “Как нужно и как не нужно демонстрировать работу опции Database In-Memory”.
Мы будем рады вашим конструктивным комментариям.
