Что такое физический дизайн структур хранения
 Основная цель, преследуемая в ходе разработки физической модели данных, — создание таких объектов для конкретной платформы/СУБД, которые позволят достигнуть максимальной производительности запросов/приложений, создающих основную нагрузку, сведя при этом дополнительные затраты, такие как необходимость поддерживать дополнительные индексы, выполнять материализацию производных данных и т. п., к минимуму.
Основная цель, преследуемая в ходе разработки физической модели данных, — создание таких объектов для конкретной платформы/СУБД, которые позволят достигнуть максимальной производительности запросов/приложений, создающих основную нагрузку, сведя при этом дополнительные затраты, такие как необходимость поддерживать дополнительные индексы, выполнять материализацию производных данных и т. п., к минимуму.Все реляционные СУБД построены на одних принципах, но каждой платформе присущи уникальные черты в виде наличия различных типов объектов и особенностей их реализации. По этой причине процесс физического моделирования является платформенно-зависимым, в отличие от логического моделирования, основная цель которого — достоверно описать данные и бизнес-процессы.
Хранение данных в СУБД Teradata
Говоря о физическом дизайне баз данных на платформе Teradata, помимо прочего, необходимо упомянуть, что это MPP (Massive Parallel Processing) платформа, в которой все данные распределяются по компонентам системы (AMP’ам) и обрабатываются ими при выполнении пользовательских запросов параллельно (см. нашу первую статью). Такая архитектура, а также равномерное распределение данных делают их обработку эффективной и в отсутствие дополнительных элементов обеспечения производительности. Эта возможность позволяет Teradata прекрасно справляться с Ad-Hoc запросами, не предусмотренными разработчиками физической модели.
Но для смешанной нагрузки, когда в системе одновременно выполняются и тактические (OLTP-подобные), и стратегические (OLAP, DSS, Data Mining) запросы, этого явно недостаточно. Особенно это относится к тактическим запросам, которые имеют достаточно высокие требования к времени отклика и пропускной способности. Основная техника физического дизайна для повышения производительности тактических запросов — создание индексов — путей доступа к данным, которые могут быть использованы запросами для быстрого поиска нужных строк таблицы без необходимости ее полного просмотра. Использование индексов позволяет радикально сократить количество операций ввода-вывода при выполнении запроса, что сокращает время отклика и, как следствие, повышает пропускную способность системы. Давайте посмотрим, как устроены индексы в Teradata, с учетом параллельной архитектуры.
Способы доступа к данным
СУБД Teradata поддерживает различные способы доступа к строкам таблиц:
Доступ по первичному индексу (о том, что такое первичный индекс, речь шла в нашей первой статье)
Это самый быстрый и наименее затратный способ доступа к данным в Teradata.
Напомним, что данные в СУБД Teradata распределяются с использованием результата хеширования значения колонки первичного индекса. Строки с одинаковыми значениями колонки первичного индекса ВСЕГДА попадают на один и тот же AMP.
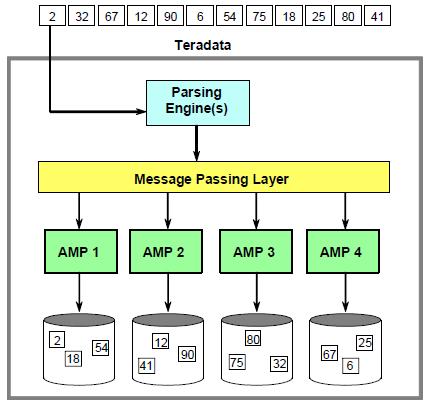
Алгоритм, применяемый для определения AMP’а, на котором должна быть размещена строка при ее вставке в таблицу, с тем же успехом используется и для поиска строки с известным значением колонки первичного индекса.
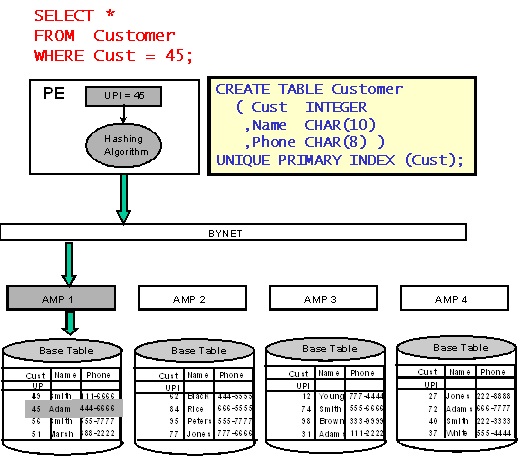
Когда AMP, на котором находится искомая строка, определен, Teradata использует индексные структуры для поиска требуемого блока данных. Последовательно просматриваются:
- Master Index (всегда загружен в память AMP’а) для поиска цилиндра, содержащего нужный блок данных;
- Cylinder Index (почти всегда загружен в память AMP’а) для поиска нужного блока данных.
После того как требуемый блок данных найден, производится его чтение и далее — поиск строки с использованием массива указателей строк (Row Reference Array).
Данный алгоритм одинаково работает как для уникальных (Unique Primary Index — UPI), так и неуникальных (Non-unique Primary Index — NUPI) первичных индексов — с той лишь разницей, что при доступе по UPI всегда читается только один блок данных и возвращается не более одной строки, в то время как при доступе по NUPI эти значения зависят от степени неуникальности индекса.
Формат строки базовой таблицы
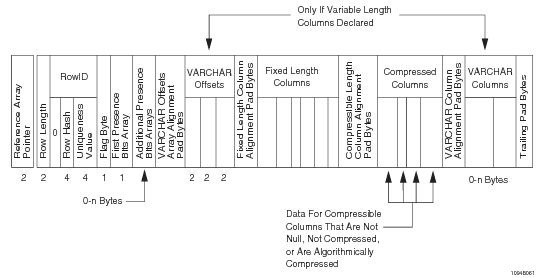
Особенность хранения данных в Teradata состоит в том, что на каждом AMP’е строки таблиц хранятся не в произвольном порядке, а отсортированы по хеш-значениям первичного индекса. Такой подход требует дополнительных усилий при вставке данных, поскольку новые строки нужно вставлять не в «конец таблицы», а так, чтобы сохранять сортировку по хешам. При этом мы получаем два преимущества:
- При соединении по колонке первичного индекса — возможность сразу применять эффективное соединение MERGE JOIN, поскольку строки уже упорядочены.
- Автоматическое индексирование колонки первичного индекса. Внутренние индексы файловой системы (мастер-индекс и цилиндр-индекс), указанные выше, содержат внутри себя диапазоны хеш-значений для тех данных, которые хранятся в блоках данных. За счет того, что строки упорядочены, эти диапазоны не пересекаются. Как следствие — создавая разметку дискового пространства на блоки данных, мы фактически получаем не только саму эту разметку, но и индексирование колонки первичного индекса — классический B-tree-индекс по хеш-значениям первичного индекса. Мы даже иногда говорим, что первичный индекс не занимает дискового пространства и не требует сопровождения, — имея в виду, что он является частью структуры «мастер-индекс» и «цилиндр-индекс» для хранения данных на дисковой системе AMP’ов.
Особенности данного алгоритма также определяют и присущие ему ограничения, а именно — доступ по первичному индексу возможен только при следующих условиях:
- использование в запросе условия «равно» для фильтрации по колонке первичного индекса;
- включение в условия поиска ВСЕХ колонок, составляющих первичный индекс.
Доступ по вторичному индексу
Вторичные индексы — альтернативные пути доступа к данным. Реализованы в виде индексных подтаблиц, позволяющих по значению колонки индексирования определить соответствующие ему идентификаторы строк базовой таблицы.
Реализация индексных подтаблиц уникального (Unique Secondary Index — USI) и неуникального (Non-unique Secondary Index — NUSI) вторичных индексов отличаются.
Формат строки индексной подтаблицы USI

Строки индексной подтаблицы USI распределяются по AMP’ам с использованием результата хеширования колонки индексирования. С высокой вероятностью строка индексной таблицы будет находиться на другом по отношению к соответствующей строке базовой таблицы AMP’е. Каждой строке базовой таблицы соответствует строка индексной подтаблицы. Доступ к данным с использованием USI требует вовлечения двух AMP’ов (первый — для поиска строки в индексе, второй — для чтения строки базовой таблицы по ее идентификатору). Доступ к данным с использованием USI можно считать таким же эффективным, как и с использованием первичного индекса. Основное назначение USI — доступ к данным по значению индексной колонки. Точно так же, как и для первичного индекса, в выражении «WHERE» должны быть указаны ВСЕ колонки, составляющие индекс с условием «РАВНО».

Формат строки индексной подтаблицы NUSI

Строки индексной подтаблицы NUSI расположены локально (на тех же AMP’ах) по отношению к строкам базовой таблицы и по умолчанию логически отсортированы по hash-значению колонки вторичного индекса. Такое хранение означает, что строки с одним и тем же значением индексной колонки могут встречаться на любом из AMP’ов системы, а следовательно, в поиск требуемых строк в индексной подтаблице будут вовлечены все AMP’ы. Далее, для выбора строк из базовой таблицы будут задействованы только те AMP’ы, на которых отобраны строки индексной подтаблицы. Будет ли оптимизатор использовать NUSI для доступа к данным, зависит от селективности индекса. В качестве значения, при превышении которого оптимизатор выберет полный просмотр таблицы, можно ориентироваться на 1 % (если при выполнении запроса будет отобрано менее 1 % строк таблицы, индекс будет использован). Из этого следует правило: собирайте статистики по NUSI, без них оптимизатор выберет FTS.
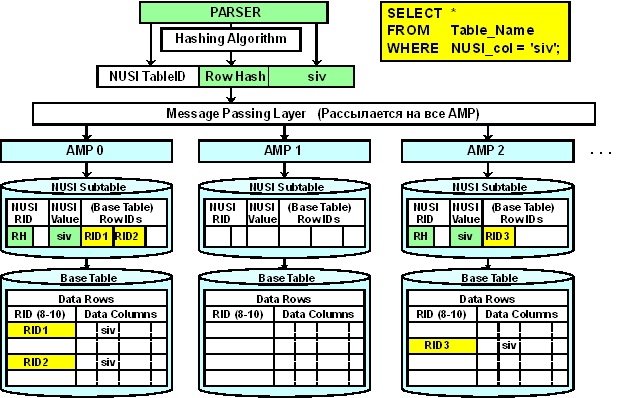
Как и в случае с PI и USI, по умолчанию NUSI используется для доступа к строкам по значению (условие «РАВНО» на все колонки NUSI в выражении «WHERE»). Но помимо этого, NUSI может быть использован и для запросов с диапазонным доступом к строкам таблицы, для чего существует опция «ORDER BY VALUES», которая логически сортирует строки индексной подтаблицы по значению индексной колонки. Созданный таким образом индекс позволяет повысить производительность с условиями на индексную колонку, отличными от «РАВНО»: <, >, >=, <=, BETWEEN.
Также, как вы видите из формата строки индексной подтаблицы, на одно значение индексной колонки может приходиться более одного RowID базовой таблицы. Это делает индексную подтаблицу NUSI автоматически сжимаемой, что минимизирует используемое дисковое пространство.
Полный просмотр таблицы (Full Table Scan, или FTS)
О данном методе доступа сказать особенно нечего. Teradata использует его в тех случаях, когда другие пути доступа к данным, с точки зрения оптимизатора, являются неэффективными. Хочется только отметить, что поиск строк путем полного просмотра в Teradata является очень эффективным благодаря MPP-архитектуре, поскольку множество AMP’ов одновременно выполняют сканирование распределенных по ним фрагментов таблицы. Зачастую полное чтение таблиц, содержащих миллионы строк, требует выполнения каждым AMP’ом всего нескольких операций ввода-вывода.
В завершение этого обзора доступа к данным таблиц первичных/вторичных индексов хотелось бы отметить, что Teradata при наличии альтернатив всегда предпочтет первичный индекс вторичному и уникальный — неуникальному.
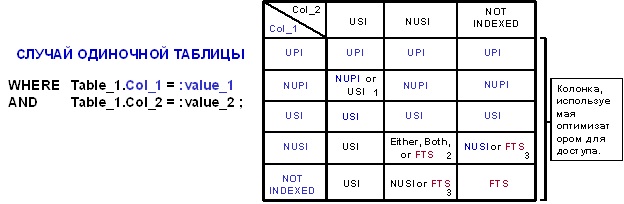
1. Оптимизатор предпочитает первичный индекс вторичному, а уникальные индексы — неуникальным. Предпочтение будет отдано NUPI, только если запрашивается один блок данных (1 I/O).
2. В зависимости от селективности оптимизатор может использовать NUSI, NUSI Bit Mapping или FTS.
3. Все зависит от селективности индекса.
Доступ с соединением таблиц
Еще одним путем доступа к данным является соединение двух или нескольких таблиц. Этот процесс имеет одну очень важную особенность, специфичную для MPP-платформ. Заключается она в том, что соединение таблиц выполняется AMP’ами, и данные, участвующие в соединении, должны находиться на соответствующих AMP’ах.
Как вы помните, от первичного индекса зависит распределение строк таблицы по AMP’ам, и не всегда строки соединяемых таблиц с одинаковыми значениями колонки соединения изначально расположены на одних и тех же AMP’ах. Следовательно, не всегда, но часто соединению таблиц предшествует подготовительная операция. Исключение представляет соединение двух таблиц по колонке первичного индекса, так как в этом случае строки с одинаковыми значениями колонок первичных индексов уже находятся на одном AMP’е. Соединение таблиц по колонкам PI является самым быстрым.
Для выполнения соединения таблиц во всех других случаях Teradata может обеспечить наличие на одном AMP’е строк с одинаковым значением колонки соединения следующими способами (важно: все производные наборы данных материализуются в SPOOL — временной области хранения промежуточных результатов запросов):
- дублирование строк маленькой таблицы на все AMP’ы;
- перераспределение строк одной/обеих таблиц шага соединения по колонке соединения (изменение PI). При этом сама таблица остается на месте, и создается временная копия тех строк, которые участвуют в запросе (необязательно вся таблица), с другим первичным индексом.
Какой из указанных выше способов будет выбран оптимизатором, зависит от демографии данных, наличия собранных статистик и индексов (Teradata может использовать некоторые типы индексов, например, NUSI, для повышения производительности соединений).
Когда наличие необходимых данных на AMP’ах обеспечено, Teradata может использовать традиционные стратегии соединения таблиц, такие как:
- MERGE JOIN:
- Row Hash;
- Inclusion;
- Exclusion;
- PRODUCT JOIN;
- NESTED JOIN;
- HASH JOIN.
Что нужно иметь для выполнения качественного физического дизайна
Логическая модель
Непосредственно физическому моделированию традиционно предшествует создание логической модели, которая в дальнейшем служит шаблоном для создания объектов базы данных. Структура хорошей логической модели может быть реализована в базе данных «один к одному».
Применительно к корпоративным хранилищам данных логическая модель — описание всех бизнес-процессов организации. Она должна быть реализована так, чтобы не только решить существующие проблемы бизнеса, но и поддержать его дальнейшее развитие. Создание подобной модели «с нуля» — очень нетривиальная и трудоемкая задача, требующая отличного знания предметной области и техник моделирования. В данной статье мы не будем обсуждать вопросы логического моделирования, отметим лишь, что в своих проектах мы стараемся использовать проверенные временем и многочисленными внедрениями отраслевые логические модели Teradata. Тем же, кто считает западные модели непригодными для использования на российском рынке, возразим, что на практике объем работ по локализации (а лучше сказать, адаптации модели под процессы заказчика, поскольку организации с одинаковыми процессами встречаются нечасто) невелик и зачастую сводится к расширению атрибутного состава уже имеющихся в модели сущностей.
Данные
Нет, можно, конечно, моделировать «в вакууме», но для физической модели крайне важно иметь перед глазами данные, которые позже будут загружены в модель. Это позволяет принимать решения о способах перехода от логической модели к физической. Некоторые полагают, что физическая модель один в один соответствует логической, но это далеко не всегда так. Например, в результате анализа данных может быть принято решение реализовать несколько сущностей логической модели данных в виде одной таблицы в физической таблицы. И это лишь один из примеров.
Демографии
Сколь бы хороша ни была логическая модель, одного лишь набора сущностей и связей недостаточно для выполнения качественного физического дизайна — необходимо понимание специфики данных и характера их использования. Обычно мы анализируем несколько демографий:
- демография данных — объемы данных, частотные диаграммы и т. п.;
- демография изменчивости — как часто изменяются данные в той или иной колонке таблицы;
- демография использования — используются ли колонки для доступа к данным по значению (единичному или по диапазону значений) или по соединению.
Знание перечисленных выше демографий позволяет создателю физической модели делать выбор осознанно.
Очевидно, что не все из этих демографий известны до начала использования модели. В частности, способы доступа к данным и частоту обращения к тем или иным колонкам модели на 100 % 99 % можно узнать только после долго периода эксплуатации хранилища. Но довольно большой ряд способов доступа можно продумать заранее, исходя из логики реализации самой модели.
Терпение и внимательность
Физическое моделирование — это увлекательный процесс, но не всегда четко алгоритмизируемый. Перефразируя персонажа известного советского мультфильма: «Физическое моделирование – наука не точная». С одной стороны, это дает возможности для творчества, с другой — требует времени, внимательности и, зачастую, итерационного подхода, поэтому внимание к деталям и терпение при работе с большими моделями данных играют ключевую роль в физическом моделировании.
Выбор индексов
Индексы часто используются как один из основных способов оптимизации физической модели для определенных шаблонов использования. Иногда выбор индексов может казаться очевидным. Давайте рассмотрим пример, когда очевидное не всегда является верным.
Представим себе следующую таблицу: ACCOUNT (1 000 000 строк)
| Acct_id | Acct_num | Acct_open_dt | Acct_close_dt | Acct_pty_id |
| PK | NOT NULL, UNIQUE | NOT NULL | NOT NULL, FK | |
| UPI | USI | NUSI | NUSI? | NUSI |
Третья строка содержит предполагаемый выбор индексов.
Легенда:
- UPI (Unique Primary Index)
- NUPI (Non-Unique Primary Index)
- USI (Unique Secondary Index)
- NUSI (Non-Unique Secondary Index)
Можете ли вы с уверенностью сказать, что данный выбор правильный? Думаю, что опыт создания физических моделей для той или иной СУБД может подсказать правильный выбор, но в общем случае сказать, что сделанный выбор верен, нельзя. Говоря о представленном выше примере, можно, например, задаться вопросом, осуществляется ли поиск в данной таблице по идентификатору счета? Если ответ — нет, можно исключить колонку Acct_id из кандидатов на первичный индекс.
Простой пример показывает, что даже самой хорошей логической модели недостаточно для создания модели физической. Необходимо понимание демографий данных (см. выше). Дополним приведенный выше пример демографиями и посмотрим, облегчит ли это задачу.
Та же таблица ACCOUNT (1 000 000 строк)
| Acct_id | Acct_num | Acct_open_dt | Acct_close_dt | Acct_pty_id | |
| PK | NOT NULL, UNIQUE | NOT NULL | NOT NULL, FK | ||
| Частота доступа по значению | 800 | 10K | 1K | 500 | 1K |
| Частота доступа по соединению | 3K | 0 | 0 | 0 | 5K |
| Кол-во уникальных строк | 1000K | 1000K | 731 | 256 | 400K |
| Макс. кол-во строк на одно значение (не NULL) | 1 | 1 | 2056 | 1K | 7 |
| Типичное кол-во строк на одно значение | 1 | 1 | 1235 | 400 | 2 |
| Кол-во строк с NULL | 0 | 0 | 0 | 900K | 0 |
| Предполагаемый выбор | USI | NUSI | NUSI | ||
| Выбор на основе демографий | NUSI | USI | NUSI | NUSI? | NUPI |
Как вы можете заметить, первоначальный выбор индексов был изменен. Для этого есть вполне объективные причины:
- Для колонки Acct_pty_id
Доступ по первичному индексу — самый эффективный метод доступа к данным в Teradata. Как мы видим из примера, доступ по значению этой колонки происходит часто. Кроме того, эта же колонка наиболее часто используется для соединения с другой таблицей. Соединение двух таблиц по колонкам первичных индексов также наиболее предпочтительно для Teradata. - Для колонки Acct_id
Эта колонка также используется для доступа достаточно часто. Поскольку выбор первичного индекса уже сделан, мы можем создать неуникальный вторичный индекс для максимально эффективного чтения строк таблицы по значению и повышения производительности соединений. - Для колонки Acct_close_dt
Выбор индекса поставлен под вопрос из-за того, что при определенных значениях (NULL) Teradata не будет его использовать ввиду недостаточной селективности.
Партиционирование таблиц в Teradata
Если таблица большая по объему, то естественное желание — разбить ее на части (партиции) и сканировать только эти партиции вместо полного просмотра таблицы.
В Teradata следующие два механизма — распределение по AMP’ам и партиционирование — эффективно дополняют друг друга. Партиционированные таблицы распределяются по AMP’ам точно так же, как и непартиционированные таблицы. Далее, на каждом AMP’е строки упорядочиваются сначала по партициям, и номера партиций записываются в мастер-индекс и цилиндр-индекс для адресации блоков данных. И затем, внутри партиций, строки уже сортируются по хеш-значениям первичного индекса, так же, как и для непартиционированных таблиц.
Таким образом, если мы запускаем запрос вида «колонка_партиционирования BETWEEN значение1 AND значение2», то все AMP’ы работают параллельно и сканируют каждый свой фрагмент таблицы, но не полностью, а только нужные партиции.
Есть и многоуровневое партиционирование, когда колонок несколько — при этом внутри партиций создаются подпартиции.
Все большие таблицы, как правило, партиционируются. Эта техника физического дизайна позволяет повысить производительность определенных запросов, имеющих фильтрацию по полям партиционирования.
Заключение
В этой статье мы решили ограничиться описанием базовых принципов и элементов, используемых при выполнении физического дизайна баз данных для СУБД Teradata. Использование в работе уже только этих практик позволит не наступать на «грабли» в самом начале пути тем, кто только начинает работать с массивно-параллельными СУБД.
В следующей статье «Дополнительные техники физического моделирования в Teradata» мы планируем рассказать вам о дополнительных возможностях индексирования и сжатия данных в Teradata.
Ждем ваших вопросов.
