Не так давно тут проходила статья про LLD. Мне она показалась скучной т.к. описывает примерно то же, что есть и в документации. Я решил пойти дальше и с помощью LLD мониторить те параметры, которые раньше нельзя было мониторить автоматически, либо это было достаточно сложно. Разберем работу LLD на примере логических процессоров в Windows:
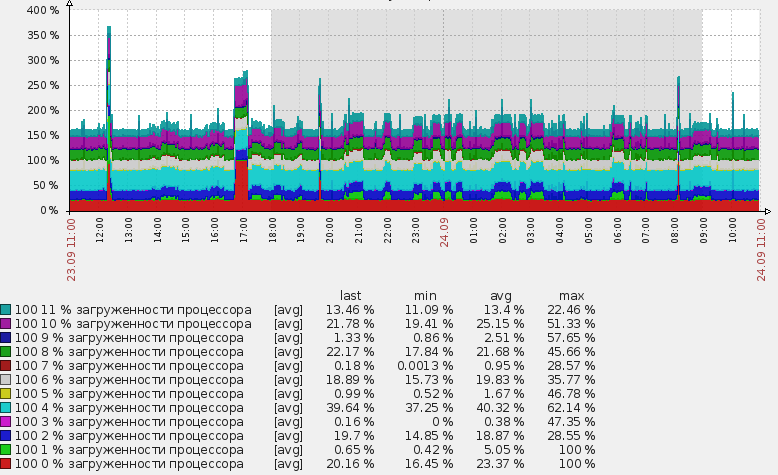
Изначально интересовал расширенный монтиринг помимо ядрер CPU и нагрузка на физические диски. До того как обнаружение было введено, эти задачи частично решались ручным добавлением. Я добавлял условные диски в файл конфигурации zabbix_agent и вообще по-разному извращался. В результате это было очень неудобно, добавлялось много неприятной ручной работы и вообще неправильно в общем как-то было :)
В итоге получается схема, которая автоматически определяет ядра в системе, а также физические диски, установленные в системе и добавляет необходимые элементы сбора данных. Для того, чтобы узнать как это реализовать у себя, добро пожаловать под кат. Я попытаюсь более-менее подробно расписать работу на примере CPU и то как сделать тоже самое, но для физических дисков.
Для начала стоит отослать к документации, где расписывается что такое LLD и с чем его едят. Помимо стандартных шаблонов нас будет интересовать 4-ый раздел с описание JSON формата обнаружения. То есть мы будем создавать свой собственный метод обнаружения. По сути все сводится к вызову скрипта, который формирует в нужном формате нужные данные.
Создаем скрипт.
Для скрипта я выбрал powershell. Его я знаю немного лучше других скриптовых языков, да и учитывая, что все будет крутиться во круг WMI, сделать его можно было бы и на VBS.
Итак, скрипт.
Задача скрипта состоит в том, чтобы определить число логических процессоров с помощью WMI и вывести в консоль эти данные в формате JSON. Передавать мы будем переменную с именем {#PROCNUM}, а также ее значения. Формат вывода будет примерно таким, в зависимости от количества логических процессоров:
Сам скрипт выглядит так:
Сейчас мы получаем, что при запуске скрипта он узнает сколько ядер и формирует пакет для отправки.
Что же мы делаем дальше? Нужно создать Discovery rule.
Для этого заходим в нужный шаблон, который добавлен к интересующим нас хостам, в раздел Discovery и нажимаем кнопку Create discovery rule.
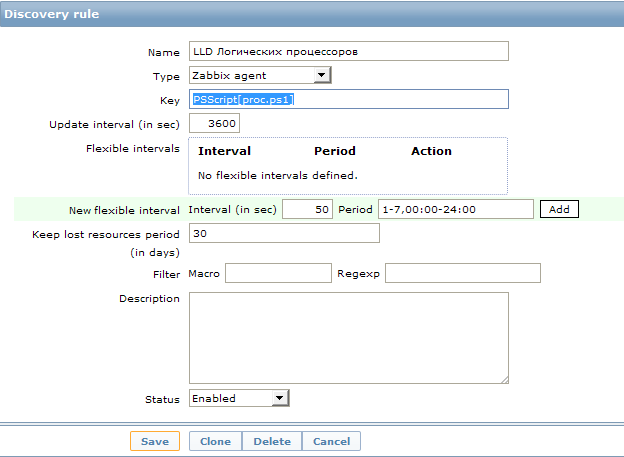
Тут мы видим непонятное значение поля key: PSScript[proc.ps1]. Это UserParameter. Этот пункт создан для удобства, теперь в каждом новом объекте мы можем просто вписывать параметр в виде имени PS скрипта и он будет искать его в заранее оговоренном месте. Сам параметр прописывается в файле конфигурации клиента (обычно называется zabbix_agentd.conf) и выглядит так:
Мы создали новое правило обнаружения с пользовательским сбором данных. Запрос на изменение информации задан как 1 час. Пожалуй, для таких статических данных, как количество процессоров, это слишком часто :), но каждый волен поставить свое значение. Для первоначального сбора данных и отладки лучше это значение уменьшить до совсем небольших значений, чтобы не ждать часами выполнение скрипта.
Хорошо. Данные о количестве процессоров мы начали собирать. Но в результате нам нужны не эти данные, а новый item в мониторинге. Именно item может собирать данные, а не наш скрипт, наш скрипт служит только для обнаружения самих элементов для сбора данных.
А для того что бы создать новый элемент сбора данных, полученный на основании LLD, в том же разделе Discovery мы создаем новый прототип. Для этого заходим в item prototypes и нажимаем create item prototype. Я создал вот такой элемент сбора:
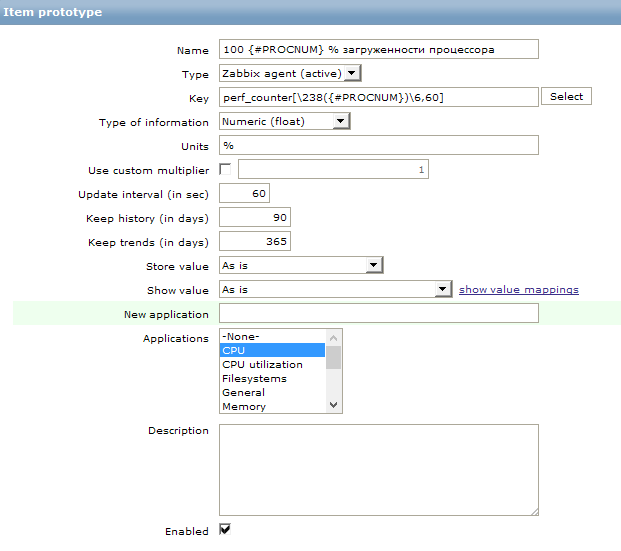
Для сбора данных используется стандартный счетчик производительности. В zabbix для сбора этих данных есть ключ perf_counter. Вместо номера логического ядра мы вставляем полученное значение в виде переменной из раздела Discovery.
Теперь все готово. Или почти все…
С этого момента, когда скрипт discovery обнаружит логические процессоры, для этого хоста будут созданы элементы сбора данных созданных точно для этого количества процессоров.
И теперь если мы зайдем в items для хоста, низкоуровневое обнаружение для которого уже отработало, то мы увидим, что появились новые элементы:
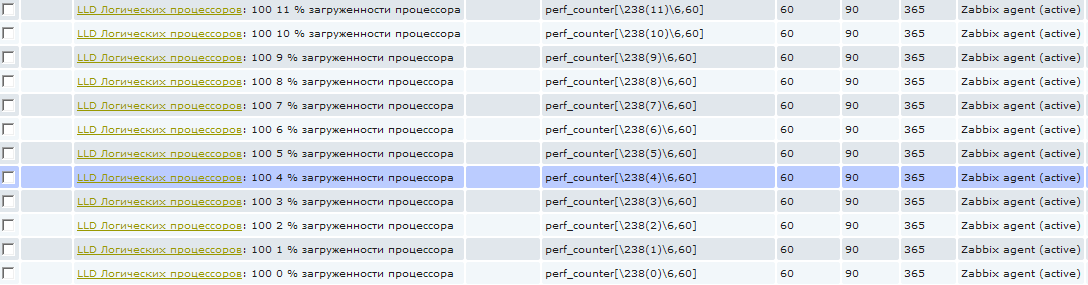
Эти элементы нельзя удалить стандартным способом, т.к. они созданы автоматически, они выделены особенным префиксом с названием правила низкоуровневого обнаружения. На скриншоте кажется, что написана какая-то фигня в имени :), на самом деле все просто, я использую трехзначный код в каждом имени для сортировки. То есть 100 это только лишь сортировочный номер. Следующая цифра от 0 до 11 это номер логического процессора. А дальше уже "% загруженности процессора". А то сначала может показаться, что это 0% загруженности процессора и я пытаюсь это значение собрать :)
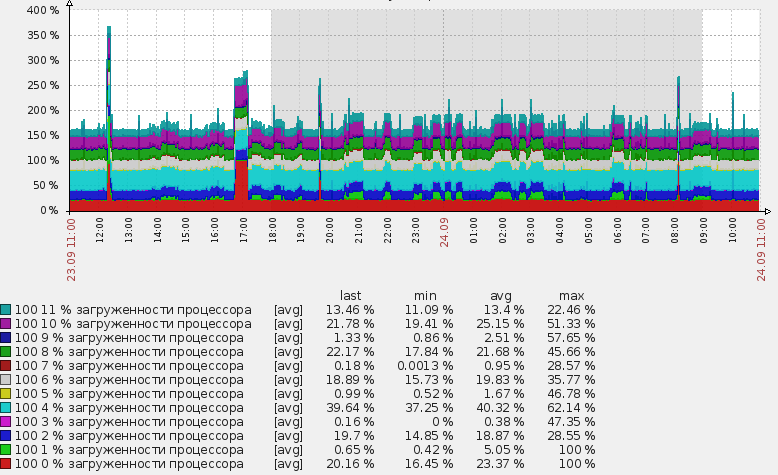
Единственный недостаток всего этого метода в том, что график, такой как в заголовке этого поста, нельзя создать с помощью механизма низкоуровневого обнаружения. То есть мы можем, конечно, создать не только item, но и graph объект для каждого логического процессора, но создать один суммарный график автоматически со всеми обнаруженными логическими процессорами не получится. По крайней мере я не видел как это можно было бы сделать, на форуме zabbix мне также не смогли подсказать. Это, конечно, не особенно серьезный недостаток, но если у вас 200 хостов, это может стать проблемой :). Ведь график для каждого хоста нужно будет создавать вручную.
В вышеприведённом способе лучше разобраться и тогда это открывает достаточно широкие возможности для мониторинга объектов в системе, количество которых либо отличается от хоста к хосту либо их количество во все изменяется во время работы.
Например, часто случается, что нужно определить, не происходил ли недостаток в ресурсах физического диска, установленного в сервере. Чаще всего эти данные сложно уловить в реалтайме и хочется иметь их собранными постфактум. Для этого я ввел аналогичное обнаружение и для физических дисков для сбора обширной статистики по ним. И, в отличии от процессоров, элементов сбора данных я создал их с избытком.
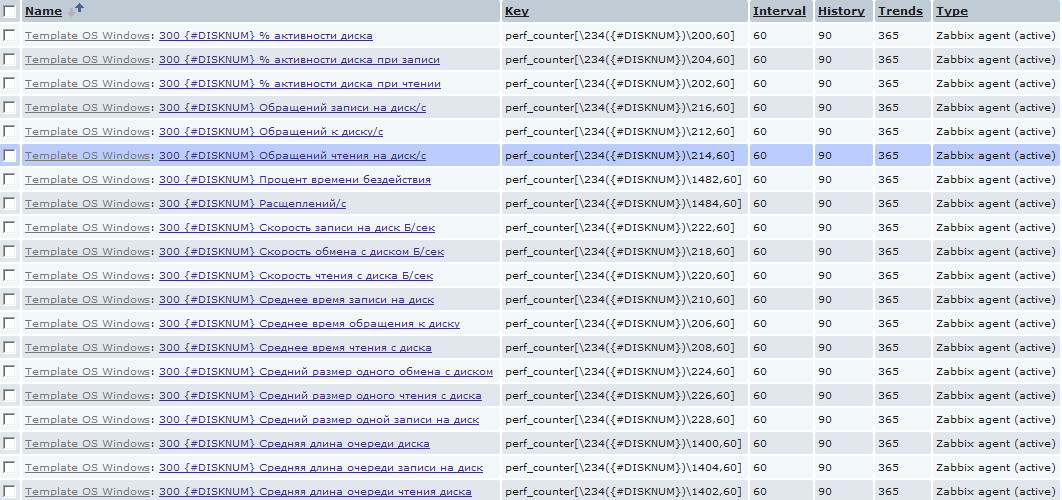
Тут, конечно, надо быть внимательным и если mysql у вас стоит на каком-нибудь стареньком забитом компе, то подобное количество достаточно быстро унесет вашу базу данных в небеса. Т.к. в приведенном примере для каждого хоста создается для каждого физического диска 20 новых элементов, которые будут создавать одного новое значение в минуту. В масштабе пары десятков серверов с кучами разных дисков это выливается в более-менее весомое количество данных. Но тут каждый волен выбирать свой путь самурая :)
Скрипт для LLD физических дисков выглядит так:
Добавляем новое правило обнаружения по аналогии с CPU. Точно также мы создаем нужные элементы в discovery.
Вообще, конечно, этот механизм дает довольно большие возможности по определению различных элементов для мониторинга. Таким же способом можно, например, добавить мониторинг сетевых интерфейсов, процессов в системе, служб и любых других элементов, имя которых и количество заранее неизвестно.
Надеюсь эта статья кому-нибудь поможет разобраться с LLD. С удовольствием отвечу на возникшие вопросы.
Изначально интересовал расширенный монтиринг помимо ядрер CPU и нагрузка на физические диски. До того как обнаружение было введено, эти задачи частично решались ручным добавлением. Я добавлял условные диски в файл конфигурации zabbix_agent и вообще по-разному извращался. В результате это было очень неудобно, добавлялось много неприятной ручной работы и вообще неправильно в общем как-то было :)
В итоге получается схема, которая автоматически определяет ядра в системе, а также физические диски, установленные в системе и добавляет необходимые элементы сбора данных. Для того, чтобы узнать как это реализовать у себя, добро пожаловать под кат. Я попытаюсь более-менее подробно расписать работу на примере CPU и то как сделать тоже самое, но для физических дисков.
Тип отправляемых данных
Для начала стоит отослать к документации, где расписывается что такое LLD и с чем его едят. Помимо стандартных шаблонов нас будет интересовать 4-ый раздел с описание JSON формата обнаружения. То есть мы будем создавать свой собственный метод обнаружения. По сути все сводится к вызову скрипта, который формирует в нужном формате нужные данные.
Создаем скрипт.
Для скрипта я выбрал powershell. Его я знаю немного лучше других скриптовых языков, да и учитывая, что все будет крутиться во круг WMI, сделать его можно было бы и на VBS.
Итак, скрипт.
Задача скрипта состоит в том, чтобы определить число логических процессоров с помощью WMI и вывести в консоль эти данные в формате JSON. Передавать мы будем переменную с именем {#PROCNUM}, а также ее значения. Формат вывода будет примерно таким, в зависимости от количества логических процессоров:
{
"data":[
{ "{#PROCNUM}":"0"},
{ "{#PROCNUM}":"1"},
{ "{#PROCNUM}":"2"},
{ "{#PROCNUM}":"3"},
{ "{#PROCNUM}":"4"},
{ "{#PROCNUM}":"5"},
{ "{#PROCNUM}":"6"},
{ "{#PROCNUM}":"7"},
{ "{#PROCNUM}":"8"},
{ "{#PROCNUM}":"9"},
{ "{#PROCNUM}":"10"},
{ "{#PROCNUM}":"11"}
]
}
Скрипт формирования данных
Сам скрипт выглядит так:
$items = Get-WmiObject Win32_PerfFormattedData_PerfOS_Processor | select name |where-object {$_.name -ne '_Total'}
write-host "{"
write-host " `"data`":["
write-host
foreach ($objItem in $Items) {
$line = " { `"{#PROCNUM}`":`"" + $objItem.Name + "`"},"
write-host $line
}
write-host
write-host " ]"
write-host "}"
write-host
Сейчас мы получаем, что при запуске скрипта он узнает сколько ядер и формирует пакет для отправки.
Что же мы делаем дальше? Нужно создать Discovery rule.
Добавялем низкоуровневое обнаружение в настройках zabbix сервера
Для этого заходим в нужный шаблон, который добавлен к интересующим нас хостам, в раздел Discovery и нажимаем кнопку Create discovery rule.

Тут мы видим непонятное значение поля key: PSScript[proc.ps1]. Это UserParameter. Этот пункт создан для удобства, теперь в каждом новом объекте мы можем просто вписывать параметр в виде имени PS скрипта и он будет искать его в заранее оговоренном месте. Сам параметр прописывается в файле конфигурации клиента (обычно называется zabbix_agentd.conf) и выглядит так:
UserParameter=PSScript[*],powershell -File "C:\Program Files\zabbix agent\script\$1"
Мы создали новое правило обнаружения с пользовательским сбором данных. Запрос на изменение информации задан как 1 час. Пожалуй, для таких статических данных, как количество процессоров, это слишком часто :), но каждый волен поставить свое значение. Для первоначального сбора данных и отладки лучше это значение уменьшить до совсем небольших значений, чтобы не ждать часами выполнение скрипта.
Настройка прототипов данных
Хорошо. Данные о количестве процессоров мы начали собирать. Но в результате нам нужны не эти данные, а новый item в мониторинге. Именно item может собирать данные, а не наш скрипт, наш скрипт служит только для обнаружения самих элементов для сбора данных.
А для того что бы создать новый элемент сбора данных, полученный на основании LLD, в том же разделе Discovery мы создаем новый прототип. Для этого заходим в item prototypes и нажимаем create item prototype. Я создал вот такой элемент сбора:

Для сбора данных используется стандартный счетчик производительности. В zabbix для сбора этих данных есть ключ perf_counter. Вместо номера логического ядра мы вставляем полученное значение в виде переменной из раздела Discovery.
Теперь все готово. Или почти все…
С этого момента, когда скрипт discovery обнаружит логические процессоры, для этого хоста будут созданы элементы сбора данных созданных точно для этого количества процессоров.
И теперь если мы зайдем в items для хоста, низкоуровневое обнаружение для которого уже отработало, то мы увидим, что появились новые элементы:
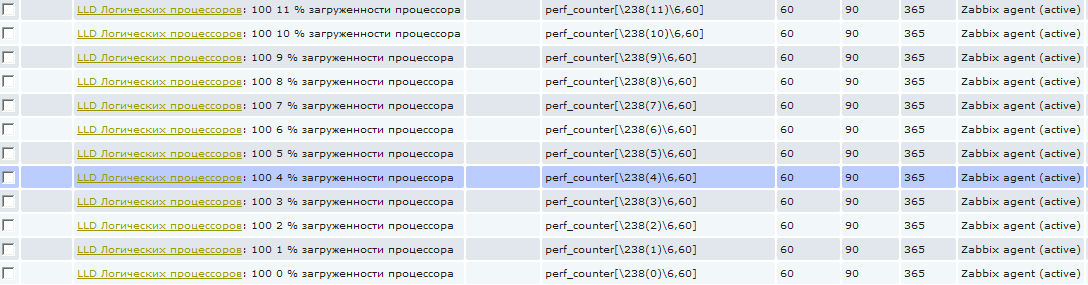
Эти элементы нельзя удалить стандартным способом, т.к. они созданы автоматически, они выделены особенным префиксом с названием правила низкоуровневого обнаружения. На скриншоте кажется, что написана какая-то фигня в имени :), на самом деле все просто, я использую трехзначный код в каждом имени для сортировки. То есть 100 это только лишь сортировочный номер. Следующая цифра от 0 до 11 это номер логического процессора. А дальше уже "% загруженности процессора". А то сначала может показаться, что это 0% загруженности процессора и я пытаюсь это значение собрать :)
Единственный недостаток всего этого метода в том, что график, такой как в заголовке этого поста, нельзя создать с помощью механизма низкоуровневого обнаружения. То есть мы можем, конечно, создать не только item, но и graph объект для каждого логического процессора, но создать один суммарный график автоматически со всеми обнаруженными логическими процессорами не получится. По крайней мере я не видел как это можно было бы сделать, на форуме zabbix мне также не смогли подсказать. Это, конечно, не особенно серьезный недостаток, но если у вас 200 хостов, это может стать проблемой :). Ведь график для каждого хоста нужно будет создавать вручную.
Мониторим производительность каждого физического диска в системе
В вышеприведённом способе лучше разобраться и тогда это открывает достаточно широкие возможности для мониторинга объектов в системе, количество которых либо отличается от хоста к хосту либо их количество во все изменяется во время работы.
Например, часто случается, что нужно определить, не происходил ли недостаток в ресурсах физического диска, установленного в сервере. Чаще всего эти данные сложно уловить в реалтайме и хочется иметь их собранными постфактум. Для этого я ввел аналогичное обнаружение и для физических дисков для сбора обширной статистики по ним. И, в отличии от процессоров, элементов сбора данных я создал их с избытком.
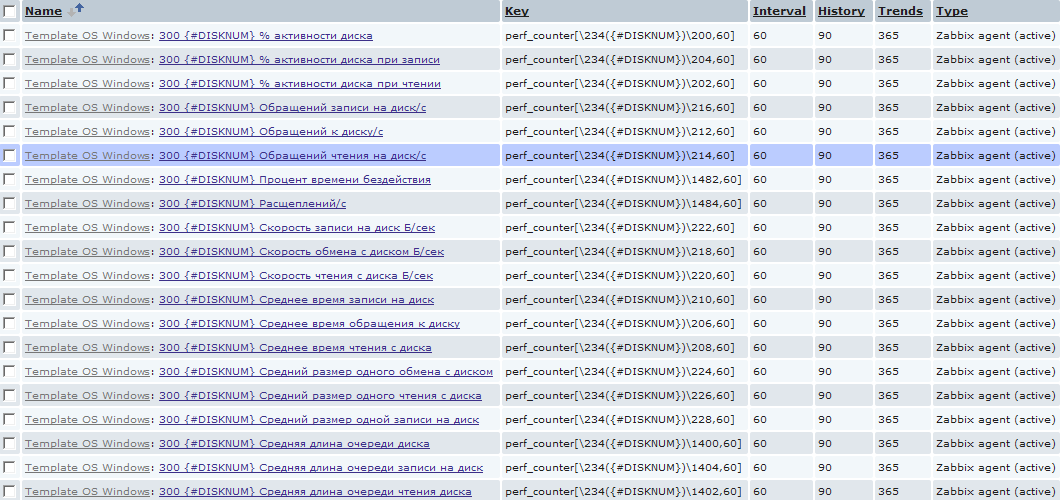
Тут, конечно, надо быть внимательным и если mysql у вас стоит на каком-нибудь стареньком забитом компе, то подобное количество достаточно быстро унесет вашу базу данных в небеса. Т.к. в приведенном примере для каждого хоста создается для каждого физического диска 20 новых элементов, которые будут создавать одного новое значение в минуту. В масштабе пары десятков серверов с кучами разных дисков это выливается в более-менее весомое количество данных. Но тут каждый волен выбирать свой путь самурая :)
Скрипт для LLD физических дисков выглядит так:
$items = Get-WmiObject Win32_PerfRawData_PerfDisk_PhysicalDisk | select name |where-object {$_.name -ne '_Total'}
write-host "{"
write-host " `"data`":["
write-host
foreach ($objItem in $Items) {
$line = " { `"{#DISKNUM}`":`"" + $objItem.Name + "`"},"
write-host $line
}
write-host
write-host " ]"
write-host "}"
write-host
Добавляем новое правило обнаружения по аналогии с CPU. Точно также мы создаем нужные элементы в discovery.
Вообще, конечно, этот механизм дает довольно большие возможности по определению различных элементов для мониторинга. Таким же способом можно, например, добавить мониторинг сетевых интерфейсов, процессов в системе, служб и любых других элементов, имя которых и количество заранее неизвестно.
Надеюсь эта статья кому-нибудь поможет разобраться с LLD. С удовольствием отвечу на возникшие вопросы.
