Вместо предисловия
Отказоустойчивость понимается — в рамках одного дата-центра – то есть защита от выхода из строя 1-2 физических серверов.
Реализация у нас будет недорогая с точки зрения «железа», а именно то, что дает в аренду один известный немецкий хостер.
С точки зрения стоимости программного обеспечения оно либо бесплатное, либо уже имеется. Партнерская программа Microsoft, так сказать, в действии.
С появлением на рынке Windows Server 2012 было много рекламы «От сервера до облака», «Ваши приложения работают всегда». Именно это мы и попробуем реализовать.
Конечно, есть тема для «холиваров»: что лучше VMWare или Hyper-V – но это тема не этого поста. Спорить не буду. На вкус и цвет — все фломастеры разные.
Наверное, некоторые скажут, что это дело можно отправить в Azure – возможно окажется, что это даже дешевле, но мы параноики и хотим
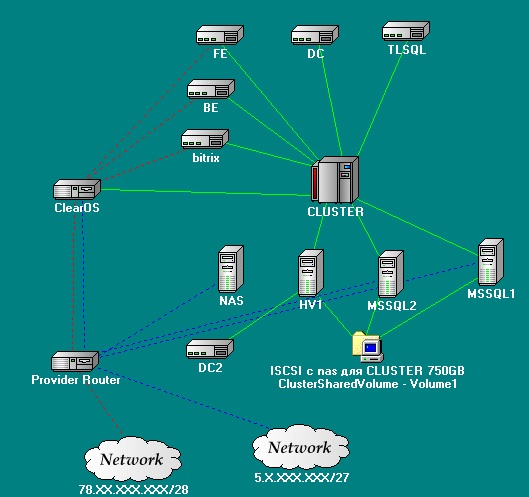
Требования к решению
Есть некий проект который использует:
- База данных – MSSQL
- backend – IIS
- frontend – некое приложение на PHP
Необходимо реализовать:
- Данная связка работала «всегда».
- Выход из строя «железного» сервера не вызывал простоев в работе.
- Данные не терялись.
- Была некая балансировка нагрузки.
- Масштабируемость.
- Для осуществления вышеперечисленного не приходилось городить огород программными средствами (например Identity для MSSQL).
Все это хозяйство будет размещаться на одном известном немецком хостинге.
Реализация
Разобьем реализацию на логические части:
- Требования к аппаратной части.
- Подготовительные действия
- Отказоустойчивость MSSQL (с элементами балансировки).
- Отказоустойчивость backend и frontend
- Настройка сети
- Отказоустойчивость: еще один рубеж.
Требования к аппаратной части
Для задуманного нам потребуется минимум 4 сервера. Крайне желательно, что бы они находились в одном дата центре, а лучше в одном свитче. В нашем случае у нас будет отдельная стойка. А раз стойка одна, то как нам объяснили, свитч у нее тоже выделенный.
Сервера
2 сервера – процессор с поддержкой виртуализации, 32ГБ ОЗУ, 2HDD X 3TB (RAID 1)
2 оставшихся – пойдут под SQL, поэтому в них будем использовать маленькое изменение (в конфигурации один жесткий диск заменим на RAID контроллер и 3 SAS диска по 300ГБ (они пойдут в RAID 5 – быстрое хранилище для MSSQL)).
В принципе это делать не обязательно. Отказоустойчивость, конечно, снижается, но скорость важнее.
Так же понадобится флэшка (но об этом ниже.)
Опционально: отдельный свитч для организации локальной сети, но это можно сделать и позже по мере роста проекта.
Подготовительные действия
Так как мы поднимаем Failover Cluster нам будет необходим домен Active Directory.
Он же потом упростит нам задачу авторизации нашего backend на SQL сервере.
Поднимаем контроллер домена в виртуальной машине.
Так же необходимо определится с адресацией локальной сети.
Наш DC (Domain Controller), понятное дело, не будет иметь белого ip адреса и будет выходить «наружу» через NAT.
В настройках всех машин виртуальных и не очень Primary DNS: наш контроллер домена.
Вторыми ip адресами, помимо белых выданных, необходимо прописать адреса нашей локальной сети.
Идеальный вариант описан в части масштабируемость ниже.
Отказоустойчивость MSSQL.
Будем использовать кластеризацию MSSQL, но не в классическом понимании, то есть будем кластеризовывать не все службу, а только Listener. Кластеризация всего MSSQL требует общего хранилища, которое будет являться точкой отказа. Мы же идем по пути минимизации точек отказа. Для этого мы воспользуемся новой возможностью MSSQL Server 2012 — Always On.
Ода этой фишке неплохо описана SQL Server 2012 – Always On by Andrew Fryer. Там же подробно расписано как настроить.
Если вкратце объединение двух технологий репликации и мирроринга. Оба экземпляра базы данных содержат идентичную информацию, но при этом используют каждый свое хранилище.
Так же имеется возможность использовать балансировку нагрузки, применением read-only реплик. Предварительно настроив маршруты для чтения, подробнее — Read-Only Routing with SQL Server 2012 Always On Database Availability Groups
Вообще Best Practice по этому вопросу подробно освещены в Microsoft SQL Server AlwaysOn Solutions Guide for High Availability and Disaster Recovery by LeRoy Tuttle
Заострю внимание только на том, что конфигурация путей в установках MSSQL должна быть идентичной.
Отказоустойчивость backend и frontend.
Данный функционал мы будем реализовывать кластеризацией виртуальных машин.
Что бы кластеризовать виртуальные машины, нам понадобится Cluster Shared Volume (CSV).
А что бы создать CSV нам понадобиться SAN, причем он должен проходить валидацию кластером и быть бесплатным. Оказывается, не такая простая задача. Было перебрано десяток решений (Open Source и не очень). В итоге искомый продукт был обнаружен. Зовется он NexentaStor
18 TB raw space бесплатно, куча протоколов и фишечек.
Единственное что, при развёртывании, необходимо учитывать опыт и рекомендации ULP Опыт эксплуатации Nexenta, или 2 месяца спустя
Мы к сожалению, по этим граблям прошлись самостоятельно.
Так же у Nexenta переодически бывает «болезнь» — перестает отвечать Web-интерфейс, при этом все остальные сервисы функционируют нормально. Решение имеется http://www.nexentastor.org/boards/2/topics/2598#message-2979
Итак. Подробнее об установке.
Пытаемся поставить Nexenta, установка проходит успешно. Заходим в систему и удивляемся – все свободное место ушло под системный пул и данные нам размещать негде. Казалось бы решение очевидно — дозаказываем жесткие диски в сервер и создаем пул для хранения данных, но есть другое решение. Для этого то, мы и воспользуемся флэшкой.
Ставим систему на флэшку (данный процесс занимает около 3 часов).
После установки создаем системный пул и пул для данных. К системному пулу прицепляем флэшку и синхронизируем. После этого флэшку из пула можно убрать. Подробно описано на http://www.nexentastor.org/boards/1/topics/356#message-391.
И получаем такую картинку.
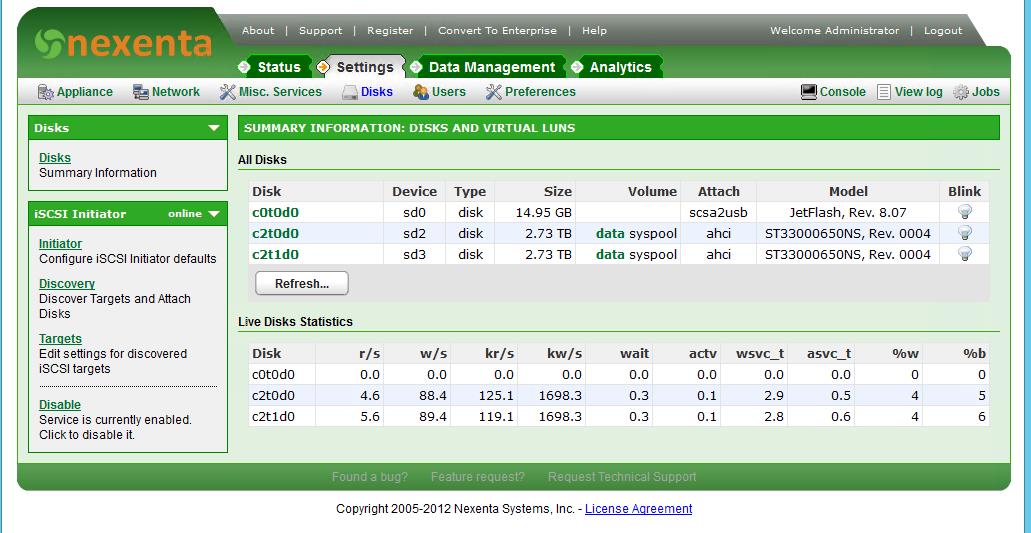
Создаем zvol. После создания привязываем его к target и публикуем через ISCSI.
Подключаем его к каждой ноде нашего кластера. И добавляем его в Cluster Shared Volume.
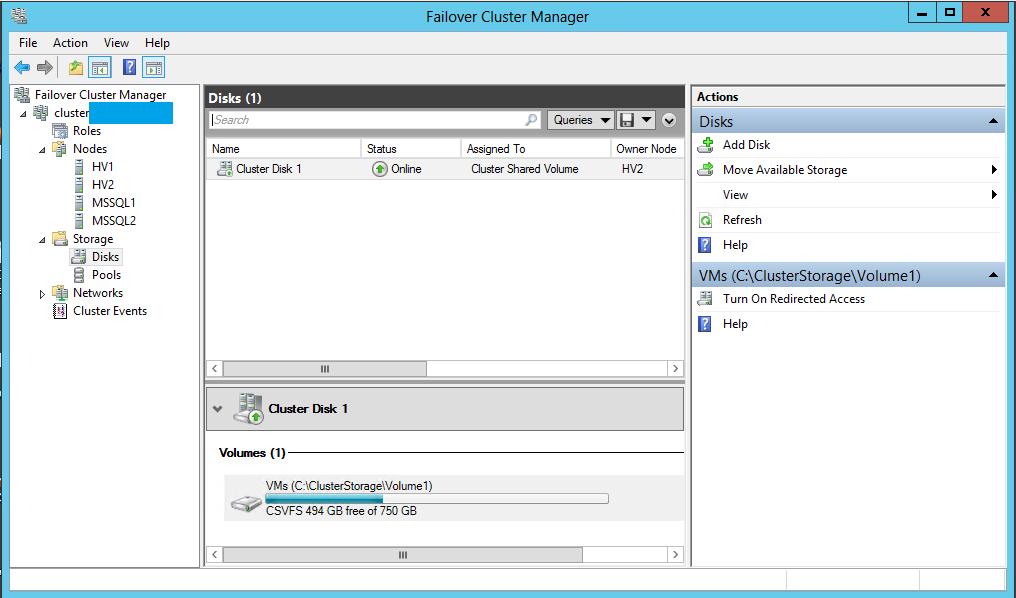
Соответственно, в настройках Hyper-V на каждой ноде кластера указываем расположение конфигураций виртуальных машин и файлов жестких дисков именно на нем.
Так же не маловажно – имена виртуальных свитчей на каждой ноде тоже должно быть одинаковым.
После этого можно создавать виртуальные машины и настраивать для них фэйловер.
Выбор ОС, конечно, ограничивается MS Windows и Linux, для которых есть службы интеграции, но так сложилось, что именно их мы и используем.
Так же не забываем добавить наш контроллер домена в Hyper-V кластер.
Настройка сети
У нас уже есть отказоустойчивый SQL, у нас есть отказоустойчивые frontend и backend.
Осталось сделать так, что бы они были доступны из внешнего мира.
У нашего хостинг провайдера есть 2 услуги для реализации данного функционала:
- Есть возможность запросить дополнительный IP адрес для нашего сервера и привязать его к MAC адресу.
- Так же есть возможность запросить целую подсеть /29 или /28 и попросить смаршрутизировать ее на адрес из 1 пункта.
Создаем в нашем Hyper-v кластере еще одну виртуальную машину. Для этой цели мы будем использовать ClearOS. Выбор на нее пал, сходу, потому, что она построена на базе CentOS и поэтому на нее можно поставить службы интеграции.
Не забываем после установки их поставить, а то могут быть проблемы с пропаданием сетевых интерфейсов.
У нее будут 3 интерфейса:
- Локальная сеть
- DMZ
- Внешняя сеть
Внешеняя сеть – это тот дополнительный адрес который мы попросили у провайдера
DMZ – подсеть которую нам выдал провайдер.
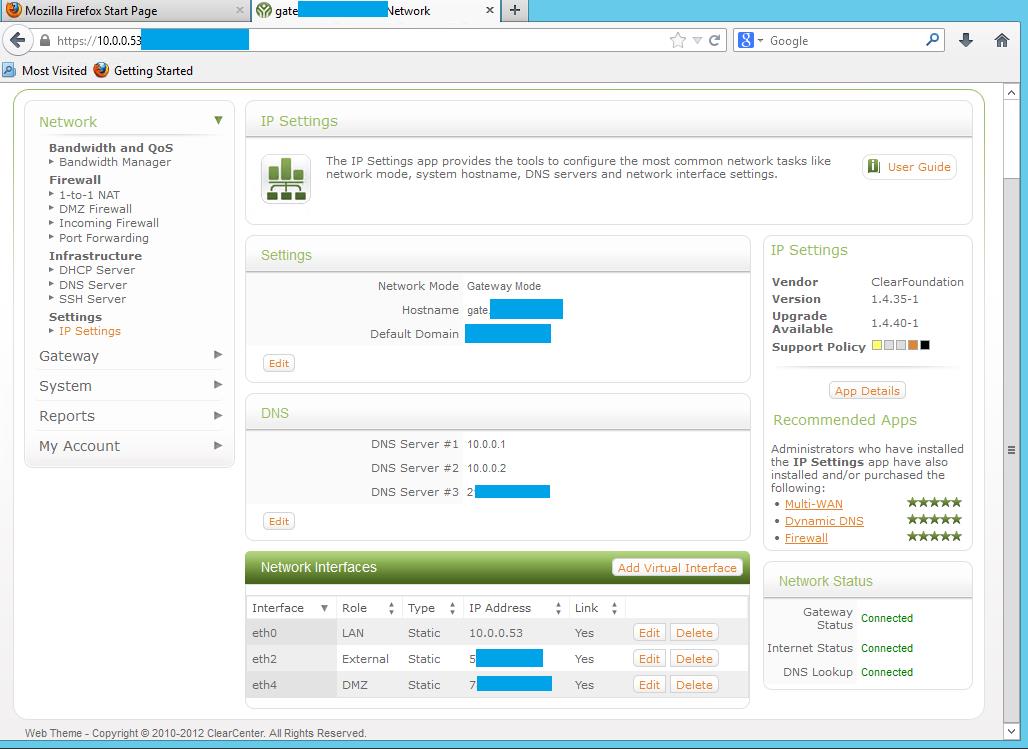
Так же данная машина будет выпускать наши виртуальные машины (не имеющий белого ip адреса) наружу через NAT.
Таким образом мы сделали нашу маршрутизацию так же отказоустойчивой. Маршрутизатор кластеризован и тоже может перемещаться с ноды на ноду.
На самих же нодах не забываем настроить файервол (блокируем на опасных портах доступ со всех ip, кроме доверенных и локальных). А лучше, отключить белые ip адреса.
Конечно, если нет необходимости больше чем в одном белом адресе, то целую подсеть выделять смысла нет и доступ снаружи можно реализовать через Port Forwarding и Reverse Proxy.
Отказоустойчивость: еще один рубеж
Как уже говорилось раньше, мы идем по пути уменьшения точек отказа. Но одна точка отказа у нас все-таки осталась – это наш SAN. Так как все кластеризованные виртуальные машины лежат на нем, в том числе и наш контроллер домена, исчезновение данного ресурса не только приведет к пропаданию backend и frontend, но и приведет к разваливанию кластера.
У нас остался еще один сервер. Его мы будем использовать как последний рубеж.
Мы создадим на нашем резервном сервере виртуальную машину со вторым контроллером домена и настроим на нем репликацию AD.
Не забываем вторичным DNS сервером на всех наших машинах прописать именно его. В таком случае, когда пропадет CSV, те службы, которые от CSV не зависят, а именно наш кластеризованный SQL-listener, продолжат функционировать.
Для того что бы backend и frontend, после падения CSV, могли вернуться в строй, мы воспользуемся новой функцией Windows Server 2012 – репликацией Hyper-V. Критичные для проекта машины мы будем реплицировать на наш 4 сервер. Минимальный период репликации 5 минут, но это не настолько важно, т.к. frontend и backend содержат статические данные, которые обновляются очень редко.
Для того, что бы это осуществить, необходимо добавить кластерную роль «Hyper-V Replica Broker». И в его свойствах настроить свойства репликации. Подробнее о репликации:
Обзор реплики Hyper-V
Windows Server 2012 Hyper-V. Hyper-V Replica
И, конечно же, не забываем про бэкап.
Немного про масштабируемость
Это решение в перспективе можно масштабировать, добавлением серверов-нод.
MSSQL сервер масштабируется добавлением нод-реплик, доступных для чтения и балансировкой маршрутов чтения.
Виртуальные машины можно «раздувать» до размеров ноды по ресурсам, без привязки к «железу».
В целях оптимизации трафика, можно добавить дополнительные интерфейсы к серверам-нодам и подключения виртуальных свитчей Hyper-V к этим интерфейсам. Это позволит отделить внешний трафик от внутреннего.
Можно реплицировать виртуальные машины в Azure.
Можно добавить SCVMM и Orchestrator и получить «частное облако».
Примерно так можно построить свой кластер который будет отказоустойчивым, до определенной степени. Как в принципе и вся отказоустойчивость.
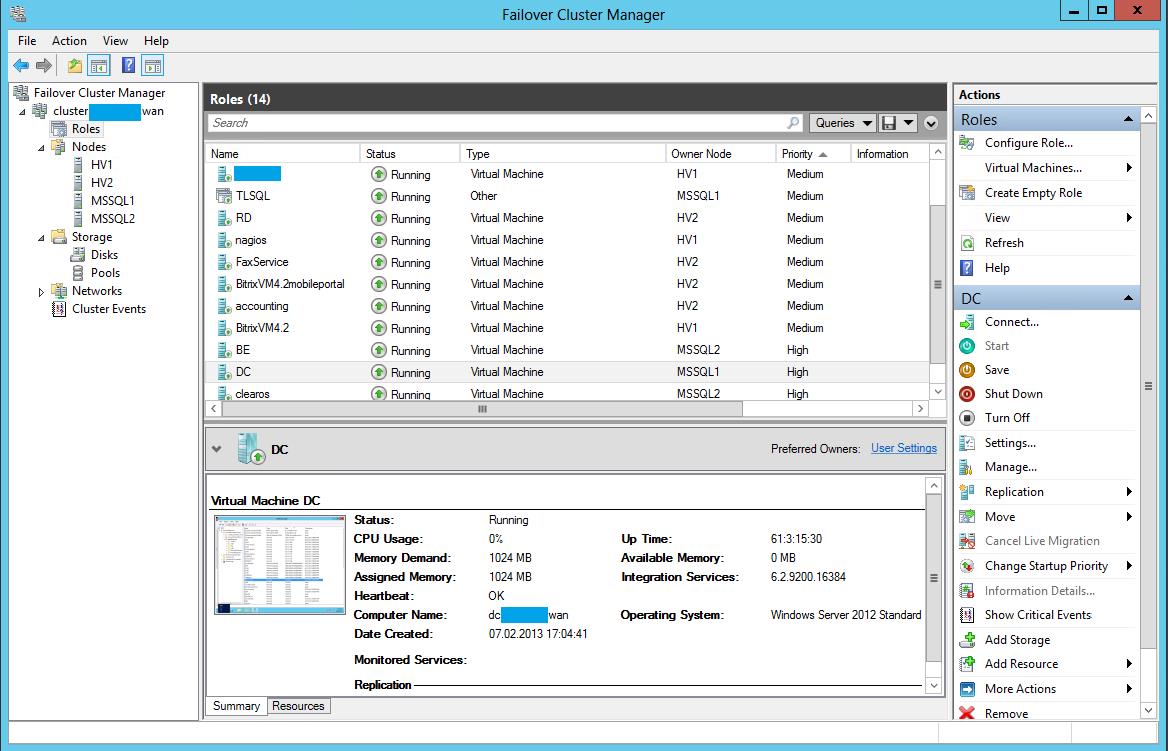
P.S. Три месяца — полет нормальный. Количество кластерных нод и виртуальных машин растет. На скриншоте видно, что система уже несколько больше описываемой.
Пост, наверное, не раскрывает всех деталей настройки, да такой задачи и не было. Я думаю, все детали будет читать утомительно. Если вдруг, кому будут интересны подробности – милости прошу. Критика приветствуется.
