Технологии семантической паутины (Semantic Web) периодически привлекают внимание благодаря тому, что на их основе создаются новые интересные инструменты. Совсем недавно появился социальный поиск (Graph Search) в Facebook – первый инструмент поиска по графу, доступный действительно широкому кругу пользователей.
Однако, сфера применения семантических технологий не ограничивается социальными сетями и поисковыми сервисами. Идея применить эти технологии для организации обмена данными между информационными системами достаточно очевидна. Если одна система передает другой не только сами данные, но и информацию об их предметной сущности (смысле, семантике), это позволяет лучше абстрагировать обменивающиеся системы друг от друга, чем при использовании выгрузок в XML или веб-сервисов SOA.
Сегодня существует несколько реализаций такого подхода. Большинство из них, конечно, сделано зарубежными компаниями, но есть и российские разработки. В этой статье я расскажу об архитектуре одной таких систем, которую реализовал на практике.
При создании системы я исходил из предположения, что нескольким информационным системам необходимо очень быстро (с интервалом в несколько секунд) сообщать друг другу об изменениях, происходящих в их хранилищах данных. Поэтому архитектура сильно напоминает шину обмена сообщениями (Message Queue), основной особенностью которой является то, что содержание сообщений выражено в синтаксисе RDF, то есть представляет собой триплеты. Со стороны каждой из интегрируемых систем работает клиентский модуль обмена, который интерпретирует получаемые сообщения, и, если необходимо, вносит соответствующие изменения в хранилище данных этой системы. Клиентский модуль является активным, то есть, если в хранилище произошли изменения, о которых нужно сообщить другим системам – он кодирует сведения об этих изменениях в RDF, и отправляет в виде сообщения по шине.
Роль маршрутизатора в шине выполняет центральный сервер-посредник, который обладает информацией о правах доступа информационных систем к разным видам данных, гарантирует доставку, контролирует целостность данных (и, при необходимости, старается ее восстановить), а также выполняет ряд других полезных функций. На рисунке ниже показана схема программных компонентов, участвующих в обмене. В качестве примера двух обменивающихся систем взяты, с одной стороны, некое веб-приложение на PHP/MySQL, и конфигурация 1С — с другой. Сервер-посредник тоже пока реализован на PHP/MySQL, однако будет переписан на более подходящей платформе. Что касается баз данных, то клиентскому компоненту уже сейчас все равно, с какой БД работать — MySQL, PostgreSQL или Oracle.

Разумеется, на практике обменивающихся систем может больше, чем две.
Преимущества этого подхода по сравнению с выгрузкой в XML или веб-сервисом SOAP достаточно очевидны, особенно если исходить из того, что необходимо связать между собой три, четыре или более систем. Они могут оперировать одними и теми же типами объектов (например, во всех информационных системах любой компании почти наверняка присутствует понятие «клиент»), но обладать разными наборами данных о них, и использовать их в разных контекстах. Выгрузки в XML почти всегда будут избыточными, жестко связанными со структурой данных в БД-источнике, и потребуют написания программного кода для экспорта и импорта. Если, например, в CRM-системе хранятся таблицы с клиентами и сделками с ними, XML-выгрузка будет выглядеть примерно так:

Понятно, что одной системе-потребителю этой информации сведения о сделках потребуются с детализацией по товарам, другой — без нее, зато со сведениями о грузополучателе и сроке доставки, и т.д. Использование выгрузок становится крайне проблематичным, если какие-нибудь данные могут измениться «задним числом». А уж если какая-нибудь из систем-получателей имеет право вносить изменения в эти данные (например, из системы отдела логистики могут поступать сведения о фактической отгрузке товара) — продолжать использовать выгрузки можно только из чистого упорства.
Более прогрессивный вариант — использовать SOAP веб-сервис. Тогда схема взаимодействия системы-источника с потребителями информации будет выглядеть так:

Это будет удобно до тех пор, пока число сервисов (растущее пропорционально числу типов информационных объектов, которыми нужно обмениваться) не перевалит через несколько десятков. Тогда проблема мониторинга работоспособности сервисов, их документирования и поддержки начнет становиться по-настоящему критичной. Кроме того, это не решает проблему обратной связи систем: в упомянутом выше примере, когда система отдела логистики не только забирает информацию из CRM, но и может сама помещать в нее какие-либо данные, веб-сервисы придется реализовывать со стороны обеих систем, что совсем неудобно. Также программистам придется самим заботиться о безопасности сервисов, поддержании целостности данных, обработке ошибок и т.п. — проблем не счесть.
В более крупных инфраструктурах применяют MDM-системы (что требует совсем другого порядка вложений и усилий), а также шины обмена сообщениями. Шины хороши тем, что позволяют объединять большое количество информационных систем без возрастания сложности обмена в зависимости от числа систем. Мы, фактически, и реализуем шину, только в отличие от «классической» шины будем передавать по ней сообщения, выглядящие примерно так:

Как я уже говорил, каждая система-отправитель перед отправкой преобразует в такой формат сведения, которыми хочет поделиться, а каждая система-получатель интерпретирует их в соответствии со своими правилами.
Преимущества такого подхода в сравнении с классической шиной обмена сообщениями состоят в том, что информационным системам нет необходимости создавать «протокол обмена», определяющий смысловую нагрузку сообщений. Его роль выполняет онтология, известная всем обменивающимся системам и серверу (сервер обладает наиболее полной версией онтологии, клиентские системы могут использовать ее подмножества). В настройках каждого клиентского модуля производится сопоставление (mapping) элементов онтологии структурным элементам локального хранилища данных (проще говоря, таблицам и полям базы). Разумеется, можно создавать пользовательские программные обработчики для сущностей и связей, которые не имеют однозначного отображения на структуру БД, но в практических внедрениях объем требуемого программного кода измеряется десятками строк. Также, в отличие от классических шин обмена сообщениями, в нашем случае сервер выполняет ряд высокоуровневых полезных функций, вроде уже упомянутого восстановления целостности данных, выявления дублей объектов, разрешения конфликтов. Кстати, заодно сервер может формировать SPARQL базу данных, в которой будут аккумулированы сведения из всех обменивающихся систем, представленные в виде графа. Это обещает обеспечить такие возможности аналитики, какие не сможет предоставить ни одна из интегрируемых систем в отдельности.
Конечно же, использование описанного мной подхода позволяет решить все перечисленные выше проблемы интеграции: обеспечить независимость процедур обмена со стороны различных систем от структуры баз друг друга, отказоустойчивость, безопасность, гибкость настройки, возможность легко использовать одну и ту же информацию в разных контекстах, и т.п.
Разумеется, описанный подход является далеко не единственным вариантом применения семантических технологий для интеграции данных. О возможных альтернативах я расскажу в следующем посте. Также за рамками этого поста остался вопрос о выборе онтологии для кодирования передаваемой информации.
Однако, сфера применения семантических технологий не ограничивается социальными сетями и поисковыми сервисами. Идея применить эти технологии для организации обмена данными между информационными системами достаточно очевидна. Если одна система передает другой не только сами данные, но и информацию об их предметной сущности (смысле, семантике), это позволяет лучше абстрагировать обменивающиеся системы друг от друга, чем при использовании выгрузок в XML или веб-сервисов SOA.

Сегодня существует несколько реализаций такого подхода. Большинство из них, конечно, сделано зарубежными компаниями, но есть и российские разработки. В этой статье я расскажу об архитектуре одной таких систем, которую реализовал на практике.
При создании системы я исходил из предположения, что нескольким информационным системам необходимо очень быстро (с интервалом в несколько секунд) сообщать друг другу об изменениях, происходящих в их хранилищах данных. Поэтому архитектура сильно напоминает шину обмена сообщениями (Message Queue), основной особенностью которой является то, что содержание сообщений выражено в синтаксисе RDF, то есть представляет собой триплеты. Со стороны каждой из интегрируемых систем работает клиентский модуль обмена, который интерпретирует получаемые сообщения, и, если необходимо, вносит соответствующие изменения в хранилище данных этой системы. Клиентский модуль является активным, то есть, если в хранилище произошли изменения, о которых нужно сообщить другим системам – он кодирует сведения об этих изменениях в RDF, и отправляет в виде сообщения по шине.
Роль маршрутизатора в шине выполняет центральный сервер-посредник, который обладает информацией о правах доступа информационных систем к разным видам данных, гарантирует доставку, контролирует целостность данных (и, при необходимости, старается ее восстановить), а также выполняет ряд других полезных функций. На рисунке ниже показана схема программных компонентов, участвующих в обмене. В качестве примера двух обменивающихся систем взяты, с одной стороны, некое веб-приложение на PHP/MySQL, и конфигурация 1С — с другой. Сервер-посредник тоже пока реализован на PHP/MySQL, однако будет переписан на более подходящей платформе. Что касается баз данных, то клиентскому компоненту уже сейчас все равно, с какой БД работать — MySQL, PostgreSQL или Oracle.

Разумеется, на практике обменивающихся систем может больше, чем две.
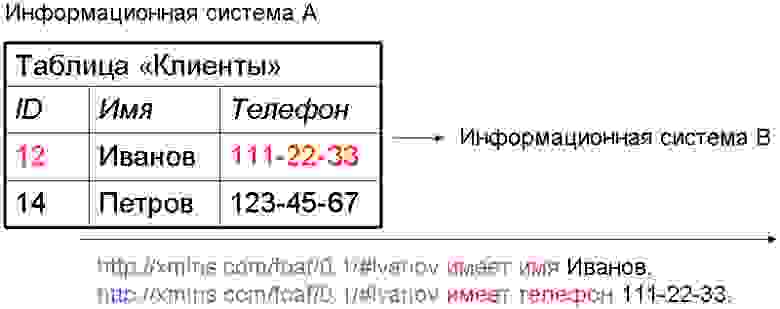
Преимущества этого подхода по сравнению с выгрузкой в XML или веб-сервисом SOAP достаточно очевидны, особенно если исходить из того, что необходимо связать между собой три, четыре или более систем. Они могут оперировать одними и теми же типами объектов (например, во всех информационных системах любой компании почти наверняка присутствует понятие «клиент»), но обладать разными наборами данных о них, и использовать их в разных контекстах. Выгрузки в XML почти всегда будут избыточными, жестко связанными со структурой данных в БД-источнике, и потребуют написания программного кода для экспорта и импорта. Если, например, в CRM-системе хранятся таблицы с клиентами и сделками с ними, XML-выгрузка будет выглядеть примерно так:

Понятно, что одной системе-потребителю этой информации сведения о сделках потребуются с детализацией по товарам, другой — без нее, зато со сведениями о грузополучателе и сроке доставки, и т.д. Использование выгрузок становится крайне проблематичным, если какие-нибудь данные могут измениться «задним числом». А уж если какая-нибудь из систем-получателей имеет право вносить изменения в эти данные (например, из системы отдела логистики могут поступать сведения о фактической отгрузке товара) — продолжать использовать выгрузки можно только из чистого упорства.
Более прогрессивный вариант — использовать SOAP веб-сервис. Тогда схема взаимодействия системы-источника с потребителями информации будет выглядеть так:

Это будет удобно до тех пор, пока число сервисов (растущее пропорционально числу типов информационных объектов, которыми нужно обмениваться) не перевалит через несколько десятков. Тогда проблема мониторинга работоспособности сервисов, их документирования и поддержки начнет становиться по-настоящему критичной. Кроме того, это не решает проблему обратной связи систем: в упомянутом выше примере, когда система отдела логистики не только забирает информацию из CRM, но и может сама помещать в нее какие-либо данные, веб-сервисы придется реализовывать со стороны обеих систем, что совсем неудобно. Также программистам придется самим заботиться о безопасности сервисов, поддержании целостности данных, обработке ошибок и т.п. — проблем не счесть.
В более крупных инфраструктурах применяют MDM-системы (что требует совсем другого порядка вложений и усилий), а также шины обмена сообщениями. Шины хороши тем, что позволяют объединять большое количество информационных систем без возрастания сложности обмена в зависимости от числа систем. Мы, фактически, и реализуем шину, только в отличие от «классической» шины будем передавать по ней сообщения, выглядящие примерно так:

Как я уже говорил, каждая система-отправитель перед отправкой преобразует в такой формат сведения, которыми хочет поделиться, а каждая система-получатель интерпретирует их в соответствии со своими правилами.
Преимущества такого подхода в сравнении с классической шиной обмена сообщениями состоят в том, что информационным системам нет необходимости создавать «протокол обмена», определяющий смысловую нагрузку сообщений. Его роль выполняет онтология, известная всем обменивающимся системам и серверу (сервер обладает наиболее полной версией онтологии, клиентские системы могут использовать ее подмножества). В настройках каждого клиентского модуля производится сопоставление (mapping) элементов онтологии структурным элементам локального хранилища данных (проще говоря, таблицам и полям базы). Разумеется, можно создавать пользовательские программные обработчики для сущностей и связей, которые не имеют однозначного отображения на структуру БД, но в практических внедрениях объем требуемого программного кода измеряется десятками строк. Также, в отличие от классических шин обмена сообщениями, в нашем случае сервер выполняет ряд высокоуровневых полезных функций, вроде уже упомянутого восстановления целостности данных, выявления дублей объектов, разрешения конфликтов. Кстати, заодно сервер может формировать SPARQL базу данных, в которой будут аккумулированы сведения из всех обменивающихся систем, представленные в виде графа. Это обещает обеспечить такие возможности аналитики, какие не сможет предоставить ни одна из интегрируемых систем в отдельности.
Конечно же, использование описанного мной подхода позволяет решить все перечисленные выше проблемы интеграции: обеспечить независимость процедур обмена со стороны различных систем от структуры баз друг друга, отказоустойчивость, безопасность, гибкость настройки, возможность легко использовать одну и ту же информацию в разных контекстах, и т.п.
Разумеется, описанный подход является далеко не единственным вариантом применения семантических технологий для интеграции данных. О возможных альтернативах я расскажу в следующем посте. Также за рамками этого поста остался вопрос о выборе онтологии для кодирования передаваемой информации.
