Одна из практических проблем, с которыми сталкивается теория информации — вопрос об идентификации текстов и определении авторства. Изучим один из возможных способов решения этой проблемы, основанный на измерении и сравнении энтропийных показателей данного и эталонного текстов для проблемы определения принадлежности фрагмента текста.
Обычно для сравнения текстов и определения авторства используется энтропия марковского процесса, показывающая среднее количество информации в битах, которое сообщает один символ, если известно k–1 предыдущих. Ознакомившись с некоторыми из таких работ, в которых не учитывалось, что сравниваемые произведения имеют различный объём, я решила изучить зависимость энтропии текста от его объёма.
Из шести текстов трёх авторов были сделаны выборки различных объёмов и вычислены средние значения энтропий от 1 до 6 порядка включительно. Результаты работы можно увидеть на графиках (верхние линии соответствуют энтропии 1 порядка, нижние — 6):
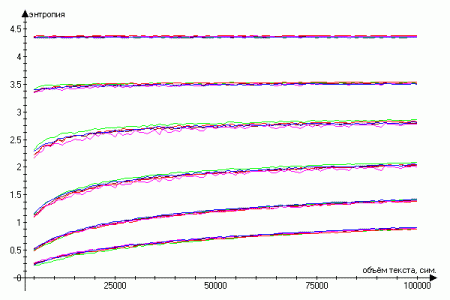
Таким образом, чем выше порядок, тем сильнее прослеживается логарифмическая зависимость энтропии от объёма текста. Причём уже для второго порядка при заданных выборках логарифмический тренд объясняет в среднем 85% дисперсии, при рассмотрении объёмов менее 50 тыс. сиволов — более 90%. Это означает, что наиболее устойчивой и независимой от объёма текста является энтропия первого порядка, то есть распределенеие частот отдельных символов без учёта их последовательностей.
При более подробном рассмотрении энтропии первого порядка можно увидеть, что для объёма менее 30 тысяч символов средняя энтропия меньше энтропии целого текста, однако общие соотношения сохраняются (пунктиром показана энтропия целого текста)

Можно заметить, что графики пересекаются, что уже свидетельствует о том, что в точках пересечения однозначно определить принадлежность текста нельзя.
Однако для ответа на вопрос о решаемости нашей задачи необходимо оценить разброс значений внутри одного текста. На следующем графике все промежуточные выборки показаны точками. Полученное колебание энтропии в пределах одного текста превосходит разницу между средними значениями, что свидетельствует о невозможности точного решения задачи о принадлежности фрагмента текста в данных условиях.

Таким образом, метод, основанный на прямом сравнении энтропий текста-фрагмента и эталонного текста, является крайне неточным и не подходит для идентификации текстов из-за большого разброса значений внутри текста. В отличие от характеристик, основанных на количестве N-грамм и прямом сравнении относительных частот их распределения, энтропия является обезличенным параметром и её использование в точных задачах может привести к ошибкам.
Обычно для сравнения текстов и определения авторства используется энтропия марковского процесса, показывающая среднее количество информации в битах, которое сообщает один символ, если известно k–1 предыдущих. Ознакомившись с некоторыми из таких работ, в которых не учитывалось, что сравниваемые произведения имеют различный объём, я решила изучить зависимость энтропии текста от его объёма.
Из шести текстов трёх авторов были сделаны выборки различных объёмов и вычислены средние значения энтропий от 1 до 6 порядка включительно. Результаты работы можно увидеть на графиках (верхние линии соответствуют энтропии 1 порядка, нижние — 6):
Таким образом, чем выше порядок, тем сильнее прослеживается логарифмическая зависимость энтропии от объёма текста. Причём уже для второго порядка при заданных выборках логарифмический тренд объясняет в среднем 85% дисперсии, при рассмотрении объёмов менее 50 тыс. сиволов — более 90%. Это означает, что наиболее устойчивой и независимой от объёма текста является энтропия первого порядка, то есть распределенеие частот отдельных символов без учёта их последовательностей.
При более подробном рассмотрении энтропии первого порядка можно увидеть, что для объёма менее 30 тысяч символов средняя энтропия меньше энтропии целого текста, однако общие соотношения сохраняются (пунктиром показана энтропия целого текста)
Можно заметить, что графики пересекаются, что уже свидетельствует о том, что в точках пересечения однозначно определить принадлежность текста нельзя.
Однако для ответа на вопрос о решаемости нашей задачи необходимо оценить разброс значений внутри одного текста. На следующем графике все промежуточные выборки показаны точками. Полученное колебание энтропии в пределах одного текста превосходит разницу между средними значениями, что свидетельствует о невозможности точного решения задачи о принадлежности фрагмента текста в данных условиях.
Таким образом, метод, основанный на прямом сравнении энтропий текста-фрагмента и эталонного текста, является крайне неточным и не подходит для идентификации текстов из-за большого разброса значений внутри текста. В отличие от характеристик, основанных на количестве N-грамм и прямом сравнении относительных частот их распределения, энтропия является обезличенным параметром и её использование в точных задачах может привести к ошибкам.
