В системах распознавания речи, содержащих слова, распознавание требует сравнения между входным словом и различными словами в словаре. Эффективное решение проблемы лежит в динамических алгоритмах сравнения, целью которого является введение временных масштабов двух слов в оптимальное соответствие. Алгоритмы такого типа являются динамическими алгоритмами трансформации временной шкалы. В данной статье представлено два варианта реализации алгоритма предназначенные для распознавания отдельных слов.
Исследования в области распознавания речи, так же как и в других областях, следуют по двум направлениям: фундаментальные исследования, целью которых является разработка и тестирование новых методов, алгоритмов и концепций на некоммерческой основе; и прикладных исследований, целью которых является улучшение существующих методов, следуя определенным критериям. В этой статье рассматривается распознавание отдельных слов в тенденции прикладных исследований.
Фундаментальные исследования направлены на получение среднесрочной или долгосрочной выгоды, в то время как прикладные исследования направлены на быстрое улучшение существующих методов или расширения их использования в областях, где такие методы еще практически не используются.
Улучшить скорость распознавания речи можно при учете следующих критериев:
Сегодня системы распознавания звука строятся на основе принципов признания форм распознавания. Методы и алгоритмы, которые использовались до сих пор, могут быть разделены на четыре больших класса:
Методы дискриминатного анализа, основанные на Байесовской дискриминации;
Скрытые модели Маркова;
Динамическое программирование – временные динамические алгоритмы (DTW);
Нейронные сети;
В данной статье приводится пример и альтернатива алгоритму динамического программирования DTW, реализующего распознавание речи.
Алгоритм динамического трансформирования времени (DTW)
Алгоритм динамического трансформирования времени (DTW) вычисляет оптимальную последовательность трансформации (деформации) времени между двумя временными рядами. Алгоритм вычисляет оба значения деформации между двумя рядами и расстоянием между ними.
Предположим, что у нас есть две числовые последовательности (a1, a2, …, an) и (b1, b2, …, bm). Как видим, длина двух последовательностей может быть различной. Алгоритм начинается с расчета локальных отклонений между элементами двух последовательностей, использующих различные типы отклонений. Самый распространенный способ для вычисления отклонений является метод, рассчитывающий абсолютное отклонение между значениями двух элементов (Евклидово расстояние). В результате получаем матрицу отклонений, имеющую n строк и m столбцов общих членов:
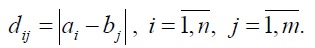
Минимальное расстояние в матрице между последовательностями определяется при помощи алгоритма динамического программирования и следующего критерия оптимизации:

где: aij — минимальное расстояние между последовательностями (a1, a2, …, an) и (b1, b2, …, bm). Путь деформации – это минимальное расстояние в матрице между элементами а11 и anm, состоящими из тех aij элементами, которые выражают расстояние до anm.
Глобальные деформации состоят из двух последовательностей и определяются по следующей формуле:
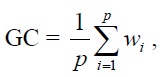
где: wi – элементы, которые принадлежать пути деформации; p – их количество. Расчеты производились для двух коротких последовательностей и указаны в таблице, в которой выделена последовательность деформации.
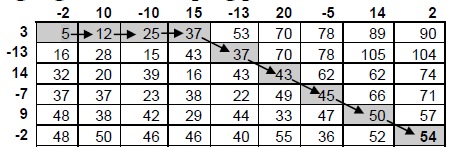
Существует три условия, налагаемых на DTW алгоритм для обеспечения быстрой конвергенции:
1. Монотонность – путь никогда не возвращается, то есть: оба индекса, i и j, которые используются в последовательности, никогда не уменьшаются.
2. Непрерывность – последовательность продвигается постепенно: за один шаг индексы, i и j, увеличиваются не более чем на 1.
3. Предельность – последовательность начинается в левом нижнем углу и заканчивается в правом верхнем.
Пример деформации последовательности с использованием языка программирования Java приведен ниже:
Так как для определения основы последовательности в динамическом программировании оптимальным является использование метод обратного программирования, необходимо использовать определенный динамический тип структуры, который называется «стек». Подобно любому динамическому алгоритму программирования, DWT имеет полиноминальную сложность. Когда мы имеем дело с большими последовательностями, возникают два неудобства:
— Запоминание больших числовых матриц;
— Выполнение большого количества расчетов отклонений.
Существует улучшенная версия алгоритма, FastDWT, которая решает две вышеуказанные проблемы. Решение заключается в разбиении матрицы состояний на 2, 4, 8, 16 и т.д. меньших по размеру матриц, посредством повторяющегося процесса разбиения последовательности ввода на две части. Таким образом, расчеты отклонения производятся только на этих небольших матрицах, и путях деформации, рассчитанных для небольших матриц. С алгоритмической точки зрения, предлагаемое решение основано на методе “Divide et Impera” (прим. пер. от лат. «Разделяй и влавствуй»).
Звук проходит через среду, как продольная волна со скоростью, зависящей от плотности среды. Самый простой способ представления звуков – синусойдный график. Графическое представление вибраций воздуха под давлением на протяжении некоторого времени.
Форма звуковой волны зависит от трех факторов: аплитуды, частоты и фазы.
Амплитуда — перемещение синусоидальных графов выше и ниже временной оси (у = 0), что соответствует энергии загруженной звуковой волны. Измерение амплитуды может быть произведено в единицах давления (децибелах DB), которые измеряют амплитуду обычного звука при помощи логарифмических функций. Измерение амплитуды используя децибелы очень важно на практике, так как это прямое представление о том, как громкость звука воспринимается людьми. Частота – число циклов синусойды за одну секунду. Цикл колебаний начинается со средней линией, потом достигает максимума и минимума, а после возвращается к средней линии. Частота цикла измеряется за одну секунду или в герцах (Гц). Величина обратная частоте называется периодом – время необходимое звуковой волне для завершения цикла.
Последний фактор – фаза. Она измеряет положение относительно начала синусоидальной кривой. Фаза не может быть услышана человеком, однако ее можно определить относительно положения между двумя сигналами. Тем не менее, слуховой аппарат воспринимает положение звука на разных фазах.
Для того чтобы разобрать звуковые волны на синусоидальной кривой воспользуемся теоремой Фурье. Она гласит, что любая комплексная периодическая волна может быть разобрана при помощи синусоидальной кривой с различными частотами, амплитудами и фазами. Этот процесс называется анализ Фурье, и его результатом является набором амплитуд, фаз и частот для каждого синусоидального компонента волны. Складывая эти синусоидальные кривые вместе, получаем оригинальную звуковую волну. Точка частоты или фазы, взятая вместе с амплитудой, называется спектром. Любой периодический сигнал показывает, рекурсивную модель времени, которая соответствует первой частоте колебаний сигнала и называется основной частотой. Она может быть измерена из речевого сигнала, при помощи проверки периода колебаний около 0 оси. Спектр показывает частоту короткой последовательности звуков, и если мы хотим проанализировать ее развитие в течение времени, необходимо найти способ, позволяющий продемонстрировать это. Это можно показать на спектрограмме. Спектрограмма — это диаграмма в двух измерениях: частота и время, — в которой цвет точки (темный – сильный, светлый – слабый) определяет амплитуду интенсивности. Метод играет важную роль в распознавании речи, и профессионал может раскрыть многие подробности, глядя только на звуковую спектрограмму.
Современные методы выявления могут точно определить начальную и конечную точку произнесенного слова в звуковом потоке, на основе обработки сигналов меняющихся в течение времени. Данные методы оценивают энергию и среднюю величину в коротком отрезке времени, а также вычисляют средний уровень пересечения нуля.
Создание начальной и конечной точки – простая задач, если аудиозапись сделана в идеальных условиях. В этом случае отношение сигнал-шум велик, так как определить действительный сигнал в потоке путем анализа образов не представляет труда. В реальных условиях все не так просто: фоновый шум имеет огромную интенсивность и может нарушить процесс отделения слов в потоке речи.
Лучший алгоритм отделения слов — алгоритм Рабинел-Ламель. Если рассматривать стоб-импульсов {s1, s2, …, sn}, где n – число образов строб-импульсов, а si, i=1, n – численное выражение образцов, общая энергия строб-импульсов вычисляется:
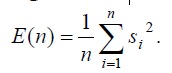
Средний уровень пересечения нулевого уровня:
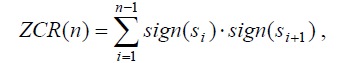
где:
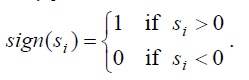
Метод использует три числовых уровня: два для энергии (верхний, нижний) и один для среднего пересечения нулевого уровня. Точка, начиная с которой энергия перекрывает верхний уровень и уровень положительных и отрицательных значений, не отменяет установленный уровень, который считается отправной точкой голосового звучания (не тишины). Поиск первой такой точки производится путем скрещивания импульсов от начала и до конца, и это определит первую область с речью. Обратный переход, из конца в начало, позволяет определить конечную точку последней области с речью. Определение внутри области может быть сделано путем скрещивания импульсов между двумя этими точками. Начало глухой области начинается в точке, в которой энергия становится меньше значения нижнего уровня. Обратите внимание на рисунок ниже, на котором до и после удаления глухой области:
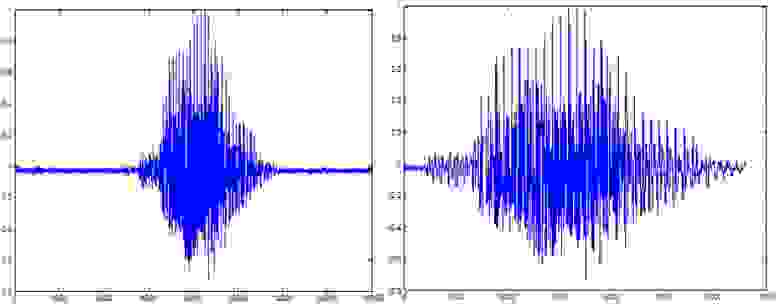
звуковой сигнал слова «nouă»
Определение слов с использованием алгоритма DWT
Определение слова может осуществляться путем сравнения числовых форм сигналов или путем сравнения спектрограммы сигналов. Процесс сравнения в обоих случаях должен компенсировать различные длины последовательности и нелинейный характер звука. DWT алгоритму удается разобрать эти проблемы путем нахождения деформации, соответствующей оптимальному расстоянию между двумя рядами различной длины.
Существуют 2 особенности применения алгоритма:
1. Прямое сравнение числовых форм сигналов. В этом случае, для каждой числовой последовательности создается новая последовательность, размеры которой значительно меньше. Алгоритм имеет дело с этими последовательностями. Числовая последовательность может иметь несколько тысяч числовых значений, в то время как подпоследовательность может иметь несколько сотен значений. Уменьшение количества числовых значений может быть выполнено путем их удаления между угловыми точками. Этот процесс сокращения длины числовой последовательности не должен изменять своего представления. Несомненно, процесс приводит к уменьшению точности распознавания. Однако, принимая во внимание увеличение скорости, точность, по сути, повышается за счет увеличения слов в словаре.
2. Представление сигналов спектрограмм и применение алгоритма DTW для сравнения двух спектрограмм. Метод заключается в разделении цифрового сигнала на некоторое количество интервалов, которые будут перекрываться. Для каждого импульса, интервалы действительных чисел (звуковых частот), будет рассчитывать Быстрым преобразование Фурье, и будет храниться в матрице звуковой спектрограммы. Параметры будут одинаковыми для всех вычислительных операций: длин импульса, длины преобразования Фурье, длины перекрытия для двух последовательных импульсов. Преобразование Фурье является симметрично связанным с центром, а комплексные число с одной стороны связаны с числами с другой стороны. В связи с этим, только значения из первой части симметрии можно сохранить, таким образом, спектрограмма будет представлять матрицу комплексных чисел, количество линий в такой матрице является равной половине длины преобразования Фурье, а количество столбцов будет определяться в зависимости от длины звука. DTW будет применяться на матрице вещественных чисел в результате сопряжения спектрограммы значений, такая матрица называется матрицей энергии.
DTW алгоритмы являются очень полезными для распознавания отдельных слов в ограниченном словаре. Для распознавания беглой речи используются скрытые модели Маркова. Использование динамического программирования обеспечивает полиминальную сложность алгоритма: О (n2v), где n – длина последовательности, а v количество слов в словаре.
DWT имеют несколько слабых сторон. Во-первых, O (n2v) сложность не удовлетворяет большим словарям, которые увеличивают успешность процесса распознавания. Во-вторых, трудно вычислить два элемента в двух разных последовательностях, если принять во внимание, что существует множество каналов с различными характеристиками. Тем не менее, DTW остается простым в реализации алгоритмом, открытым для улучшений и подходящим для приложений, которым требуется простое распознавание слов: телефоны, автомобильные компьютеры, системы безопасности и т.д.
[1] Benoit Legrand, C.S. Chang, S.H. Ong, Soek-Ying Neo, Nallasivam Palanisamy, Chromosome classification using dynamic time warping, ScienceDirect Pattern Recognition Letters 29 (2008) 215–222
[2] Cory Myers, Lawrence R. Rabiner, Aaron E. Rosenberg, Performance Tradeoffs in Dynamic Time Warping Algorithms for Isolated Word Recognition, Ieee Transactions On Acoustics, Speech, And Signal Processing, Vol. Assp-28, No. 6, December 1980
[3] F. Jelinek. «Continuous Speech Recognition by Statisical Methods.» IEEE Proceedings 64:4(1976): 532-556
[4] Rabiner, L. R., A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition, Proc. of IEEE, Feb. 1989
[5] Rabiner, L. R., Schafer, R.W., Digital Processing of Speech Signals, Prentice Hall, 1978.
[6] Stan Salvador, Chan, FastDTW: Toward Accurate Dynamic Time Warping in Linear Time
and Space, IEEE Transactions on Biomedical. Engineering, vol. 43, no. 4
[7] Young, S., A Review of Large-Vocabulary Continuous Speech Recognition, IEEE Signal
Processing Magazine, pp. 45-57, Sep. 1996
[8] Sakoe, H. & S. Chiba. (1978) Dynamic programming algorithm optimization for spoken word recognition. IEEE, Trans. Acoustics, Speech, and Signal Proc., Vol. ASSP-26.
[9] Furtună, F., Dârdală, M., Using Discriminant Analisys in Speech Recognition, The Proceedings Of The Fourth National Conference Humman Computer Interaction Rochi 2007, Universitatea Ovidius Constanţa, 2007, MatrixRom, Bucharest, 2007
[10] * * *, Speech Separation by Humans and Machines, Kluwer Academic Publishers, 2005
перевод статьи: Dynamic Programming Algorithms in Speech Recognition by Titus Felix FURTUNĂ
Введение
Исследования в области распознавания речи, так же как и в других областях, следуют по двум направлениям: фундаментальные исследования, целью которых является разработка и тестирование новых методов, алгоритмов и концепций на некоммерческой основе; и прикладных исследований, целью которых является улучшение существующих методов, следуя определенным критериям. В этой статье рассматривается распознавание отдельных слов в тенденции прикладных исследований.
Фундаментальные исследования направлены на получение среднесрочной или долгосрочной выгоды, в то время как прикладные исследования направлены на быстрое улучшение существующих методов или расширения их использования в областях, где такие методы еще практически не используются.
Улучшить скорость распознавания речи можно при учете следующих критериев:
- Размер узнаваемой лексики;
- Степень спонтанности речи, которую необходимо распознать;
- Зависимость/независимость от диктора;
- Время, необходимое для приведения системы в движение;
- Время приспособления системы для новых пользователей;
- Время выбора и распознавания;
- Степень распознавания (выраженная словом или предложением).
Сегодня системы распознавания звука строятся на основе принципов признания форм распознавания. Методы и алгоритмы, которые использовались до сих пор, могут быть разделены на четыре больших класса:
Методы дискриминатного анализа, основанные на Байесовской дискриминации;
Скрытые модели Маркова;
Динамическое программирование – временные динамические алгоритмы (DTW);
Нейронные сети;
В данной статье приводится пример и альтернатива алгоритму динамического программирования DTW, реализующего распознавание речи.
Алгоритм динамического трансформирования времени (DTW)
Алгоритм динамического трансформирования времени (DTW) вычисляет оптимальную последовательность трансформации (деформации) времени между двумя временными рядами. Алгоритм вычисляет оба значения деформации между двумя рядами и расстоянием между ними.
Предположим, что у нас есть две числовые последовательности (a1, a2, …, an) и (b1, b2, …, bm). Как видим, длина двух последовательностей может быть различной. Алгоритм начинается с расчета локальных отклонений между элементами двух последовательностей, использующих различные типы отклонений. Самый распространенный способ для вычисления отклонений является метод, рассчитывающий абсолютное отклонение между значениями двух элементов (Евклидово расстояние). В результате получаем матрицу отклонений, имеющую n строк и m столбцов общих членов:
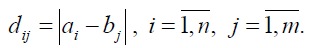
Минимальное расстояние в матрице между последовательностями определяется при помощи алгоритма динамического программирования и следующего критерия оптимизации:
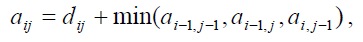
где: aij — минимальное расстояние между последовательностями (a1, a2, …, an) и (b1, b2, …, bm). Путь деформации – это минимальное расстояние в матрице между элементами а11 и anm, состоящими из тех aij элементами, которые выражают расстояние до anm.
Глобальные деформации состоят из двух последовательностей и определяются по следующей формуле:

где: wi – элементы, которые принадлежать пути деформации; p – их количество. Расчеты производились для двух коротких последовательностей и указаны в таблице, в которой выделена последовательность деформации.

Существует три условия, налагаемых на DTW алгоритм для обеспечения быстрой конвергенции:
1. Монотонность – путь никогда не возвращается, то есть: оба индекса, i и j, которые используются в последовательности, никогда не уменьшаются.
2. Непрерывность – последовательность продвигается постепенно: за один шаг индексы, i и j, увеличиваются не более чем на 1.
3. Предельность – последовательность начинается в левом нижнем углу и заканчивается в правом верхнем.
Пример деформации последовательности с использованием языка программирования Java приведен ниже:
public static void dtw(double a[],double b[],double dw[][], Stack<Double> w){
// a,b - the sequences, dw - the minimal distances matrix
// w - the warping path
int n=a.length,m=b.length;
double d[][]=new double[n][m]; // the euclidian distances matrix
for(int i=0;i<n;i++)
for(int j=0;j<m;j++)d[i][j]=Math.abs(a[i]-b[j]);
// determinate of minimal distance
dw[0][0]=d[0][0];
for(int i=1;i<n;i++)dw[i][0]=d[i][0]+dw[i-1][0];
for(int j=1;j<m;j++)dw[0][j]=d[0][j]+dw[0][j-1];
for(int i=1;i<n;i++)
for(int j=1;j<m;j++)
if(dw[i-1][j-1]<=dw[i-1][j])
if(dw[i-1][j-1]<=dw[i][j-1])dw[i][j]=d[i][j]+dw[i-1][j-1];
else dw[i][j]=d[i][j]+dw[i][j-1];
else
if(dw[i-1][j]<=dw[i][j-1])dw[i][j]=d[i][j]+dw[i-1][j];
else dw[i][j]=d[i][j]+dw[i][j-1];
int i=n-1,j=m-1;
double element=dw[i][j];
// determinate of warping path
w.push(new Double(dw[i][j]));
do{
if(i>0&&j>0)
if(dw[i-1][j-1]<=dw[i-1][j])
if(dw[i-1][j-1]<=dw[i][j-1]){i--;j--;} else j--;
else
if(dw[i-1][j]<=dw[i][j-1])i--; else j--;
else if(i==0)j--; else i--;
w.push(new Double(dw[i][j]));
}
while(i!=0||j!=0);
}
Так как для определения основы последовательности в динамическом программировании оптимальным является использование метод обратного программирования, необходимо использовать определенный динамический тип структуры, который называется «стек». Подобно любому динамическому алгоритму программирования, DWT имеет полиноминальную сложность. Когда мы имеем дело с большими последовательностями, возникают два неудобства:
— Запоминание больших числовых матриц;
— Выполнение большого количества расчетов отклонений.
Существует улучшенная версия алгоритма, FastDWT, которая решает две вышеуказанные проблемы. Решение заключается в разбиении матрицы состояний на 2, 4, 8, 16 и т.д. меньших по размеру матриц, посредством повторяющегося процесса разбиения последовательности ввода на две части. Таким образом, расчеты отклонения производятся только на этих небольших матрицах, и путях деформации, рассчитанных для небольших матриц. С алгоритмической точки зрения, предлагаемое решение основано на методе “Divide et Impera” (прим. пер. от лат. «Разделяй и влавствуй»).
Использование DWT алгоритма в распознавании речи
Анализ голосового сигнала
Звук проходит через среду, как продольная волна со скоростью, зависящей от плотности среды. Самый простой способ представления звуков – синусойдный график. Графическое представление вибраций воздуха под давлением на протяжении некоторого времени.
Форма звуковой волны зависит от трех факторов: аплитуды, частоты и фазы.
Амплитуда — перемещение синусоидальных графов выше и ниже временной оси (у = 0), что соответствует энергии загруженной звуковой волны. Измерение амплитуды может быть произведено в единицах давления (децибелах DB), которые измеряют амплитуду обычного звука при помощи логарифмических функций. Измерение амплитуды используя децибелы очень важно на практике, так как это прямое представление о том, как громкость звука воспринимается людьми. Частота – число циклов синусойды за одну секунду. Цикл колебаний начинается со средней линией, потом достигает максимума и минимума, а после возвращается к средней линии. Частота цикла измеряется за одну секунду или в герцах (Гц). Величина обратная частоте называется периодом – время необходимое звуковой волне для завершения цикла.
Последний фактор – фаза. Она измеряет положение относительно начала синусоидальной кривой. Фаза не может быть услышана человеком, однако ее можно определить относительно положения между двумя сигналами. Тем не менее, слуховой аппарат воспринимает положение звука на разных фазах.
Для того чтобы разобрать звуковые волны на синусоидальной кривой воспользуемся теоремой Фурье. Она гласит, что любая комплексная периодическая волна может быть разобрана при помощи синусоидальной кривой с различными частотами, амплитудами и фазами. Этот процесс называется анализ Фурье, и его результатом является набором амплитуд, фаз и частот для каждого синусоидального компонента волны. Складывая эти синусоидальные кривые вместе, получаем оригинальную звуковую волну. Точка частоты или фазы, взятая вместе с амплитудой, называется спектром. Любой периодический сигнал показывает, рекурсивную модель времени, которая соответствует первой частоте колебаний сигнала и называется основной частотой. Она может быть измерена из речевого сигнала, при помощи проверки периода колебаний около 0 оси. Спектр показывает частоту короткой последовательности звуков, и если мы хотим проанализировать ее развитие в течение времени, необходимо найти способ, позволяющий продемонстрировать это. Это можно показать на спектрограмме. Спектрограмма — это диаграмма в двух измерениях: частота и время, — в которой цвет точки (темный – сильный, светлый – слабый) определяет амплитуду интенсивности. Метод играет важную роль в распознавании речи, и профессионал может раскрыть многие подробности, глядя только на звуковую спектрограмму.
Выявление слов
Современные методы выявления могут точно определить начальную и конечную точку произнесенного слова в звуковом потоке, на основе обработки сигналов меняющихся в течение времени. Данные методы оценивают энергию и среднюю величину в коротком отрезке времени, а также вычисляют средний уровень пересечения нуля.
Создание начальной и конечной точки – простая задач, если аудиозапись сделана в идеальных условиях. В этом случае отношение сигнал-шум велик, так как определить действительный сигнал в потоке путем анализа образов не представляет труда. В реальных условиях все не так просто: фоновый шум имеет огромную интенсивность и может нарушить процесс отделения слов в потоке речи.
Лучший алгоритм отделения слов — алгоритм Рабинел-Ламель. Если рассматривать стоб-импульсов {s1, s2, …, sn}, где n – число образов строб-импульсов, а si, i=1, n – численное выражение образцов, общая энергия строб-импульсов вычисляется:
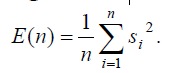
Средний уровень пересечения нулевого уровня:
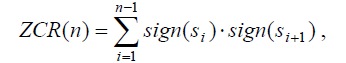
где:
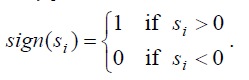
Метод использует три числовых уровня: два для энергии (верхний, нижний) и один для среднего пересечения нулевого уровня. Точка, начиная с которой энергия перекрывает верхний уровень и уровень положительных и отрицательных значений, не отменяет установленный уровень, который считается отправной точкой голосового звучания (не тишины). Поиск первой такой точки производится путем скрещивания импульсов от начала и до конца, и это определит первую область с речью. Обратный переход, из конца в начало, позволяет определить конечную точку последней области с речью. Определение внутри области может быть сделано путем скрещивания импульсов между двумя этими точками. Начало глухой области начинается в точке, в которой энергия становится меньше значения нижнего уровня. Обратите внимание на рисунок ниже, на котором до и после удаления глухой области:
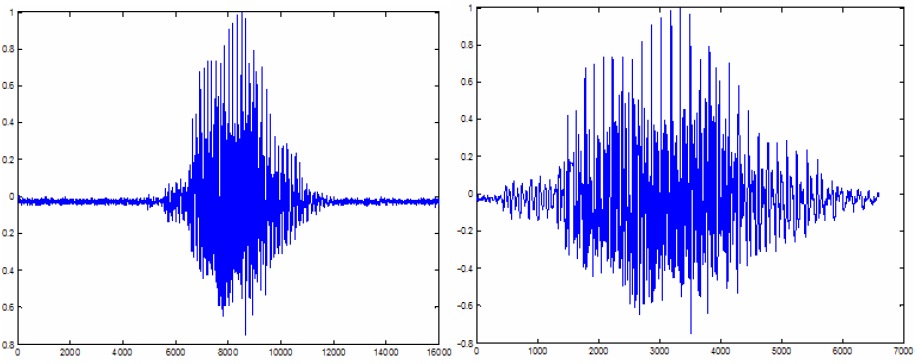
звуковой сигнал слова «nouă»
Определение слов с использованием алгоритма DWT
Определение слова может осуществляться путем сравнения числовых форм сигналов или путем сравнения спектрограммы сигналов. Процесс сравнения в обоих случаях должен компенсировать различные длины последовательности и нелинейный характер звука. DWT алгоритму удается разобрать эти проблемы путем нахождения деформации, соответствующей оптимальному расстоянию между двумя рядами различной длины.
Существуют 2 особенности применения алгоритма:
1. Прямое сравнение числовых форм сигналов. В этом случае, для каждой числовой последовательности создается новая последовательность, размеры которой значительно меньше. Алгоритм имеет дело с этими последовательностями. Числовая последовательность может иметь несколько тысяч числовых значений, в то время как подпоследовательность может иметь несколько сотен значений. Уменьшение количества числовых значений может быть выполнено путем их удаления между угловыми точками. Этот процесс сокращения длины числовой последовательности не должен изменять своего представления. Несомненно, процесс приводит к уменьшению точности распознавания. Однако, принимая во внимание увеличение скорости, точность, по сути, повышается за счет увеличения слов в словаре.
2. Представление сигналов спектрограмм и применение алгоритма DTW для сравнения двух спектрограмм. Метод заключается в разделении цифрового сигнала на некоторое количество интервалов, которые будут перекрываться. Для каждого импульса, интервалы действительных чисел (звуковых частот), будет рассчитывать Быстрым преобразование Фурье, и будет храниться в матрице звуковой спектрограммы. Параметры будут одинаковыми для всех вычислительных операций: длин импульса, длины преобразования Фурье, длины перекрытия для двух последовательных импульсов. Преобразование Фурье является симметрично связанным с центром, а комплексные число с одной стороны связаны с числами с другой стороны. В связи с этим, только значения из первой части симметрии можно сохранить, таким образом, спектрограмма будет представлять матрицу комплексных чисел, количество линий в такой матрице является равной половине длины преобразования Фурье, а количество столбцов будет определяться в зависимости от длины звука. DTW будет применяться на матрице вещественных чисел в результате сопряжения спектрограммы значений, такая матрица называется матрицей энергии.
Заключение
DTW алгоритмы являются очень полезными для распознавания отдельных слов в ограниченном словаре. Для распознавания беглой речи используются скрытые модели Маркова. Использование динамического программирования обеспечивает полиминальную сложность алгоритма: О (n2v), где n – длина последовательности, а v количество слов в словаре.
DWT имеют несколько слабых сторон. Во-первых, O (n2v) сложность не удовлетворяет большим словарям, которые увеличивают успешность процесса распознавания. Во-вторых, трудно вычислить два элемента в двух разных последовательностях, если принять во внимание, что существует множество каналов с различными характеристиками. Тем не менее, DTW остается простым в реализации алгоритмом, открытым для улучшений и подходящим для приложений, которым требуется простое распознавание слов: телефоны, автомобильные компьютеры, системы безопасности и т.д.
Литература
[1] Benoit Legrand, C.S. Chang, S.H. Ong, Soek-Ying Neo, Nallasivam Palanisamy, Chromosome classification using dynamic time warping, ScienceDirect Pattern Recognition Letters 29 (2008) 215–222
[2] Cory Myers, Lawrence R. Rabiner, Aaron E. Rosenberg, Performance Tradeoffs in Dynamic Time Warping Algorithms for Isolated Word Recognition, Ieee Transactions On Acoustics, Speech, And Signal Processing, Vol. Assp-28, No. 6, December 1980
[3] F. Jelinek. «Continuous Speech Recognition by Statisical Methods.» IEEE Proceedings 64:4(1976): 532-556
[4] Rabiner, L. R., A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition, Proc. of IEEE, Feb. 1989
[5] Rabiner, L. R., Schafer, R.W., Digital Processing of Speech Signals, Prentice Hall, 1978.
[6] Stan Salvador, Chan, FastDTW: Toward Accurate Dynamic Time Warping in Linear Time
and Space, IEEE Transactions on Biomedical. Engineering, vol. 43, no. 4
[7] Young, S., A Review of Large-Vocabulary Continuous Speech Recognition, IEEE Signal
Processing Magazine, pp. 45-57, Sep. 1996
[8] Sakoe, H. & S. Chiba. (1978) Dynamic programming algorithm optimization for spoken word recognition. IEEE, Trans. Acoustics, Speech, and Signal Proc., Vol. ASSP-26.
[9] Furtună, F., Dârdală, M., Using Discriminant Analisys in Speech Recognition, The Proceedings Of The Fourth National Conference Humman Computer Interaction Rochi 2007, Universitatea Ovidius Constanţa, 2007, MatrixRom, Bucharest, 2007
[10] * * *, Speech Separation by Humans and Machines, Kluwer Academic Publishers, 2005
перевод статьи: Dynamic Programming Algorithms in Speech Recognition by Titus Felix FURTUNĂ
