
Как научить поисковую машину правильно разбивать текст на предложения? Сделать так, чтобы она могла распознавать точки, которые не являются концами предложений.
Наша статья о машинном обучении объясняет одну из техник, которые применяются в поисковой машине тогда, когда возникает нужда в корректном разбиения текста на предложения. Решение такой задачи имеет принципиальное значение, например, при генерации сниппетов поисковыми системами или при построении базы контекстов словоупотребления. Сейчас эта технология встраивается в индексатор Поиска@Mail.Ru. Точность метода, по нашим наблюдениям — не менее 99%.
О том, как это работает, читайте в нашей статье.
Проблема и существующее решение
При разработке систем автоматической обработки текстов часто возникает задача корректного разбиения текста на предложения. Ее решение имеет принципиальное значение, например, при генерации сниппетов поисковыми системами или при построении базы контекстов словоупотребления.
На практике сначала нужно выяснить, является ли знак концом предложения, потом определить места в тексте, где делитель предложения был пропущен, например, по ошибке. Реализовать (и вычислить) второе намного сложнее, но, к счастью, в этом нет острой необходимости, поскольку подразумеваемые концы предложений встречаются реже, чем явные.
Концы предложений могут обозначаться точками, знаками вопроса и восклицания, символами конца абзаца, многоточиями и, в отдельных случаях, двоеточиями. Основные проблемы создаёт символ точки, поскольку, он также используется в сокращениях и литеральных обозначениях – датах, шифрах, адресах электронной почты, web-адресах и т.п.
Для определения того, является ли точка в данном контексте концом предложения, применяются различные способы, сложность которых зависит от требований к результату. Самыми распространенные – это способы, предполагающие применение регулярных выражений и таблиц стандартных сокращений, которые в достаточно простых случаях дают приемлемый результат.
Основной недостаток таблиц сокращений – то, что их нельзя применить к случаям нестандартных (авторских) сокращений. Кроме того, сокращения могут находиться в конце предложения, а некоторые из них, например, «и т.п.», «и др.» часто обозначают явный конец предложения (кстати, данное предложение является исключением).
Информация о том, является ли знак концом предложения, хранится в контексте и выводится по определенным правилам. Сформулировать их, основываясь только на собственном опыте, оказывается не так уж просто — особенно с учётом того, что их нужно представить в форме алгоритма.
Но вывести правила, позволяющие автоматически различать знаки концов предложений более чем с 99% точностью, все-таки, можно.
Базовые правила делятся на два типа – подстановки и комбинации. Подстановки задаются регулярными выражениями и проверяют конкретные простые признаки контекста такие как, например, «пробелы справа» или «одна прописная буква слева» и т.п.
Комбинации – это алгебраические конструкции, которые строятся из подстановок, например, «прописная буква слева» + «титул справа» (титул – слово, начинающееся с прописной буквы). Каждое из базовых правил, будучи примененным к конкретному контексту, возвращает число начисленных очков, обычно это 0, -1 или +1. Конечный результат вычисляется из вектора очков посредством специального классификатора.
Приятной особенностью этого подхода является тот факт, что для принятия решения нужно вычислять значения не всех правил, а лишь тех, которые потребуются классификатору. Кроме того, основываясь на значимости правил для классификатора, можно их оптимизировать, добиваясь повышения качества и производительности.
Обучение шло последовательно, на документах разных типов – web-страницах, художественных и формальных текстах. Всего было отобрано около 10 тыс. эпизодов с отношением количества знаков-делителей предложений к знакам, не являющимся делителями, как 2 к 3. Для получения итоговой. 99%-процентной точности потребовалось шесть этапов обучения.
Для первого этапа обучения данные готовились вручную: потребовалось рассмотрение порядка 1000 эпизодов. На каждом последующем этапе в список обучения добавлялись эпизоды, где классификатор «ошибался» или «сомневался».
В результате проведенных экспериментов мы выяснили, что к наиболее значимым правилам относятся:
• «Тип разделителя», 3 правила. Определяют соответственно точку, знак вопроса и знак восклицания;
• «Пробелы справа/слева». Определяют наличие пробельных символов справа и слева от разделителя;
• «Символ пунктуации справа/слева»;
• «Цифра справа/слева»;
• «Прописная/строчная буква справа/слева»;
• «Открывающая/закрывающая скобка справа/слева»;
• «Стандартные сокращения»;
• «Неизвестные сокращения общего вида xxx.-xx. xx.» и т.д.
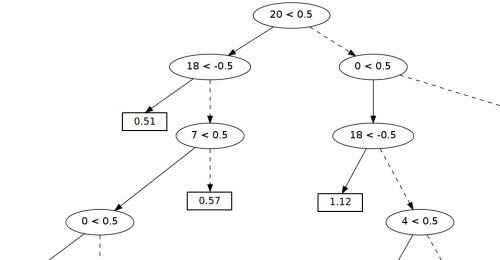
Рисунок 1. Фрагмент дерева принятия решений.
В качестве основы классификатора мы использовали «деревья принятия решений», широко применяемые в машинном обучении. Пример реального «дерева» из нашего классификатора показан на рисунке 1 (мы приводим фрагмент, так как всё «дерево» слишком велико).
В «узлах» дерева находятся условия проверки правил. Запись вида «20 < 0.5» означает, что если правило №20 набрало менее 0.5 очков, то нужно перемещаться в левое поддерево, в противном случае — в правое.
В «листьях дерева» хранятся оценки вероятности того, что делитель является концом предложения (чем больше значение, тем выше вероятность). В данном примере «дерево» принимает решения на основе следующих правил:
• №0 — разделитель является точкой
• №4 — пробелы справа
• №7 — прописная буква слева
• №18 — многоточие(+2 для первой точки, +1 для средних, -1 для последней)
• №20 — титул справа (титул — слово, записанное с прописной буквы).
К сожалению, одно «дерево» не может обеспечить приемлемое качество классификации, поэтому в качестве классификатора мы используем комбинацию нескольких сотен относительно простых деревьев.
Каждое «дерево» строится так, чтобы максимально компенсировать ошибку работы остальных «деревьев» классификатора (такой подход известен в специальной литературе под названием boosting). Дополнительно для улучшения качества работы классификатора в целом мы использовали технику bootstrapping, где для построения каждого «дерева» используется случайное подмножество обучающего множества, меняющееся от «дерева» к «дереву». Полученные таким образом композитный классификатор показывает значительно лучшее качество работы, чем отдельно взятое «дерево».
В таблице приведены оценки, сделанные классификатором. Порог отсечения (равный 0,64) выбирался методом наименьших квадратов для оценок, полученных по обучающей выборке. Смещение порога объясняется несимметричностью обучающей выборки относительно числа случаев, когда знак является разделителем и когда не является.
А что у нас?
В настоящий момент технология машинного обучения по корректной разбивке текстов на предложения встраивается в индексатор нашей поисковой системы. Это внедрение обещает улучшить качество сниппетов в Поиске@Mail.Ru, а также позволит правильнее определять контекст, в котором употребляется слово — что в свою очередь повысит релевантность поисковой выдачи.
С уважением,
Команда Поиска@Mail.Ru
Наша статья о машинном обучении объясняет одну из техник, которые применяются в поисковой машине тогда, когда возникает нужда в корректном разбиения текста на предложения. Решение такой задачи имеет принципиальное значение, например, при генерации сниппетов поисковыми системами или при построении базы контекстов словоупотребления. Сейчас эта технология встраивается в индексатор Поиска@Mail.Ru. Точность метода, по нашим наблюдениям — не менее 99%.
О том, как это работает, читайте в нашей статье.
Проблема и существующее решение
При разработке систем автоматической обработки текстов часто возникает задача корректного разбиения текста на предложения. Ее решение имеет принципиальное значение, например, при генерации сниппетов поисковыми системами или при построении базы контекстов словоупотребления.На практике сначала нужно выяснить, является ли знак концом предложения, потом определить места в тексте, где делитель предложения был пропущен, например, по ошибке. Реализовать (и вычислить) второе намного сложнее, но, к счастью, в этом нет острой необходимости, поскольку подразумеваемые концы предложений встречаются реже, чем явные.
Концы предложений могут обозначаться точками, знаками вопроса и восклицания, символами конца абзаца, многоточиями и, в отдельных случаях, двоеточиями. Основные проблемы создаёт символ точки, поскольку, он также используется в сокращениях и литеральных обозначениях – датах, шифрах, адресах электронной почты, web-адресах и т.п.
Для определения того, является ли точка в данном контексте концом предложения, применяются различные способы, сложность которых зависит от требований к результату. Самыми распространенные – это способы, предполагающие применение регулярных выражений и таблиц стандартных сокращений, которые в достаточно простых случаях дают приемлемый результат.
Основной недостаток таблиц сокращений – то, что их нельзя применить к случаям нестандартных (авторских) сокращений. Кроме того, сокращения могут находиться в конце предложения, а некоторые из них, например, «и т.п.», «и др.» часто обозначают явный конец предложения (кстати, данное предложение является исключением).
Информация о том, является ли знак концом предложения, хранится в контексте и выводится по определенным правилам. Сформулировать их, основываясь только на собственном опыте, оказывается не так уж просто — особенно с учётом того, что их нужно представить в форме алгоритма.
Но вывести правила, позволяющие автоматически различать знаки концов предложений более чем с 99% точностью, все-таки, можно.
Наш метод
Метод, который мы решили использовать для Поиска@Mail.Ru, заключается в создании небольшого набора базовых правил (порядка 40) и последующем автоматическом построении классификатора, опирающегося на результаты применения этих правил.Базовые правила делятся на два типа – подстановки и комбинации. Подстановки задаются регулярными выражениями и проверяют конкретные простые признаки контекста такие как, например, «пробелы справа» или «одна прописная буква слева» и т.п.
Комбинации – это алгебраические конструкции, которые строятся из подстановок, например, «прописная буква слева» + «титул справа» (титул – слово, начинающееся с прописной буквы). Каждое из базовых правил, будучи примененным к конкретному контексту, возвращает число начисленных очков, обычно это 0, -1 или +1. Конечный результат вычисляется из вектора очков посредством специального классификатора.
Приятной особенностью этого подхода является тот факт, что для принятия решения нужно вычислять значения не всех правил, а лишь тех, которые потребуются классификатору. Кроме того, основываясь на значимости правил для классификатора, можно их оптимизировать, добиваясь повышения качества и производительности.
Об обучении: деревья принятия решений
Подбор базовых правил происходил вручную, с помощью специально разработанного декларативного языка. Для построения классификатора мы использовали алгоритм машинного обучения на основе «деревьев принятия решений».Обучение шло последовательно, на документах разных типов – web-страницах, художественных и формальных текстах. Всего было отобрано около 10 тыс. эпизодов с отношением количества знаков-делителей предложений к знакам, не являющимся делителями, как 2 к 3. Для получения итоговой. 99%-процентной точности потребовалось шесть этапов обучения.
Для первого этапа обучения данные готовились вручную: потребовалось рассмотрение порядка 1000 эпизодов. На каждом последующем этапе в список обучения добавлялись эпизоды, где классификатор «ошибался» или «сомневался».
Самые важные правила
Как уже было упомянуто, значимость отдельных правил определяется автоматически, в процессе обучения. Чем выше степень корреляции оценки, получаемой некоторым правилом, с требуемым ответом, тем выше это правило в списке опроса, и тем чаще его выполнение будет проверяться.В результате проведенных экспериментов мы выяснили, что к наиболее значимым правилам относятся:
• «Тип разделителя», 3 правила. Определяют соответственно точку, знак вопроса и знак восклицания;
• «Пробелы справа/слева». Определяют наличие пробельных символов справа и слева от разделителя;
• «Символ пунктуации справа/слева»;
• «Цифра справа/слева»;
• «Прописная/строчная буква справа/слева»;
• «Открывающая/закрывающая скобка справа/слева»;
• «Стандартные сокращения»;
• «Неизвестные сокращения общего вида xxx.-xx. xx.» и т.д.
Алгоритм построения классификатора
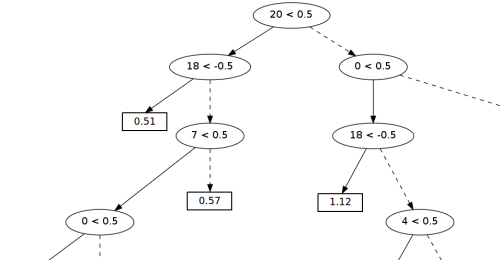
Рисунок 1. Фрагмент дерева принятия решений.
В качестве основы классификатора мы использовали «деревья принятия решений», широко применяемые в машинном обучении. Пример реального «дерева» из нашего классификатора показан на рисунке 1 (мы приводим фрагмент, так как всё «дерево» слишком велико).
В «узлах» дерева находятся условия проверки правил. Запись вида «20 < 0.5» означает, что если правило №20 набрало менее 0.5 очков, то нужно перемещаться в левое поддерево, в противном случае — в правое.
В «листьях дерева» хранятся оценки вероятности того, что делитель является концом предложения (чем больше значение, тем выше вероятность). В данном примере «дерево» принимает решения на основе следующих правил:
• №0 — разделитель является точкой
• №4 — пробелы справа
• №7 — прописная буква слева
• №18 — многоточие(+2 для первой точки, +1 для средних, -1 для последней)
• №20 — титул справа (титул — слово, записанное с прописной буквы).
К сожалению, одно «дерево» не может обеспечить приемлемое качество классификации, поэтому в качестве классификатора мы используем комбинацию нескольких сотен относительно простых деревьев.
Каждое «дерево» строится так, чтобы максимально компенсировать ошибку работы остальных «деревьев» классификатора (такой подход известен в специальной литературе под названием boosting). Дополнительно для улучшения качества работы классификатора в целом мы использовали технику bootstrapping, где для построения каждого «дерева» используется случайное подмножество обучающего множества, меняющееся от «дерева» к «дереву». Полученные таким образом композитный классификатор показывает значительно лучшее качество работы, чем отдельно взятое «дерево».
Пример вывода размечающей программы для случайного набора фраз
Внутри тэгов sn находятся целые предложения:<sn>Погода в тот день была "хорошей".</sn><sn>There is no silver bullet. </sn><sn>А. С. Пушкин - великий русский поэт. </sn><sn>Ф. М. Достоевский жил в не самое простое для России время. </sn><sn>Началом эпохи Unix считается 01. 01. 1970. </sn><sn>Василий Пупкин был назначен и. о. генерального менеджера 11.06.1999. </sn><sn>Его почтовый адрес v.pupkin@nowhere.ru.com, личная страничка здесь - nowhere.ru.com/pupkin.html - теперь все знают, как с ним связаться. </sn>
* This source code was highlighted with Source Code Highlighter.В таблице приведены оценки, сделанные классификатором. Порог отсечения (равный 0,64) выбирался методом наименьших квадратов для оценок, полученных по обучающей выборке. Смещение порога объясняется несимметричностью обучающей выборки относительно числа случаев, когда знак является разделителем и когда не является.
| Решение: | Контекст (разделяющий знак находится в центре): | Оценка: |
| да | `в тот день была "хорошей". There is no silver bulle' | 1,000 |
| да | `There is no silver bullet. А. С. Пушкин — великий р' | 0,734 |
| нет | `re is no silver bullet. А. С. Пушкин — великий русс' | -0,002 |
| нет | `is no silver bullet. А. С. Пушкин — великий русский' | 0,003 |
| да | `ин — великий русский поэт. Ф. М. Достоевский жил в ' | 0,972 |
| нет | `- великий русский поэт. Ф. М. Достоевский жил в не ' | -0,002 |
| нет | `еликий русский поэт. Ф. М. Достоевский жил в не сам' | 0,003 |
| да | ` простое для России время. Началом эпохи Unix счита' | 1,000 |
| нет | `м эпохи Unix считается 01. 01. 1970. Василий Пупкин' | 0,460 |
| нет | `охи Unix считается 01. 01. 1970. Василий Пупкин был' | 0,489 |
| да | `ix считается 01. 01. 1970. Василий Пупкин был назна' | 0,500 |
| нет | `лий Пупкин был назначен и. о. генерального менеджер' | 0,184 |
| нет | ` Пупкин был назначен и. о. генерального менеджера 1' | 0,050 |
| нет | `генерального менеджера 11.06.1999. Его почтовый адр' | -0,001 |
| нет | `ерального менеджера 11.06.1999. Его почтовый адрес ' | -0,001 |
| да | `ного менеджера 11.06.1999. Его почтовый адрес v.pup' | 0,500 |
| нет | `999. Его почтовый адрес v.pupkin@nowhere.ru.com, ли' | -0,055 |
| нет | `ый адрес v.pupkin@nowhere.ru.com, личная страничка ' | 0,000 |
| нет | `адрес v.pupkin@nowhere.ru.com, личная страничка зде' | 0,001 |
| нет | `ка здесь — nowhere.ru.com/pupkin.html — тепе' | 0,000 |
| нет | `здесь — nowhere.ru.com/pupkin.html — теперь ' | -0,001 |
| нет | `p://nowhere.ru.com/pupkin.html — теперь все знают, ' | -0,001 |
| да | `нают, как с ним связаться.' | 0,972 |
А что у нас?
В настоящий момент технология машинного обучения по корректной разбивке текстов на предложения встраивается в индексатор нашей поисковой системы. Это внедрение обещает улучшить качество сниппетов в Поиске@Mail.Ru, а также позволит правильнее определять контекст, в котором употребляется слово — что в свою очередь повысит релевантность поисковой выдачи. Внеклассное чтение
Для более глубокого знакомства с алгоритмами машинного обучения мы рекомендуем вам книгу T.Hastie, R.Tibshirani, J.H.Friedman «The elements of statistical learning», которая доступна on-line.С уважением,
Команда Поиска@Mail.Ru
