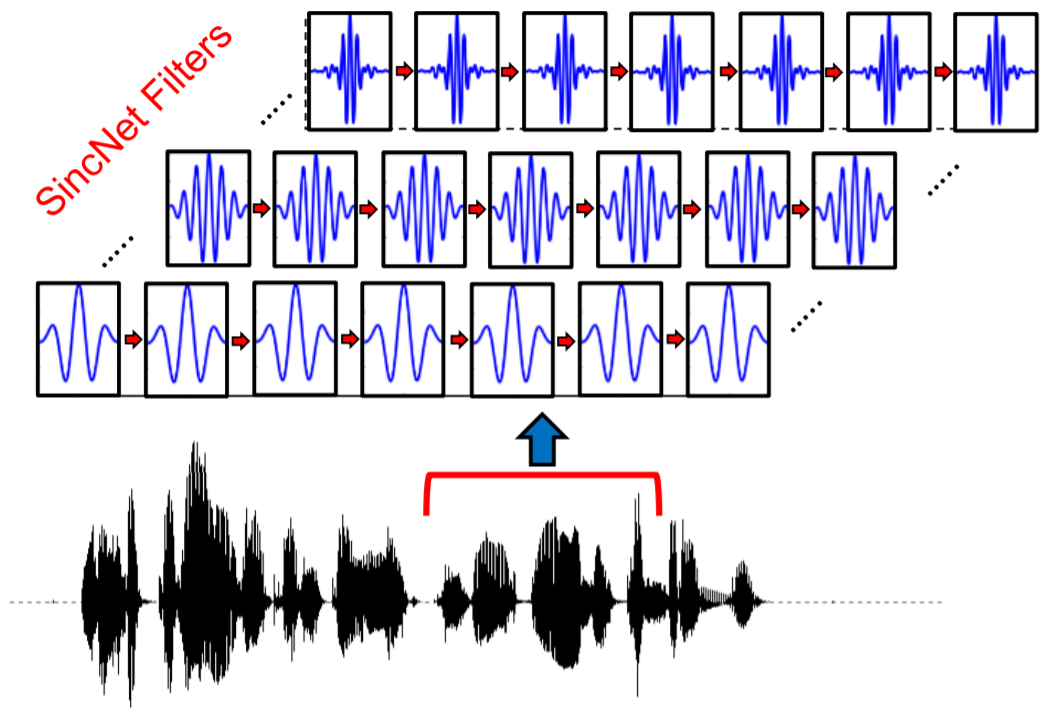
Недавно вышла одна очень интересная статья "Speaker Recognition from raw waveform with SincNet", в которой была описана end-to-end архитектура нейронной сети для распознавания говорящего по голосу. Ключевая особенность этой архитектуры — специальные одномерные сверточные слои, которые имеют всего два параметра с четкой интерпретацией. Интерпретируемость параметров нейронной сети — дело довольно затруднительное, поэтому эта статья привлекла мой интерес.
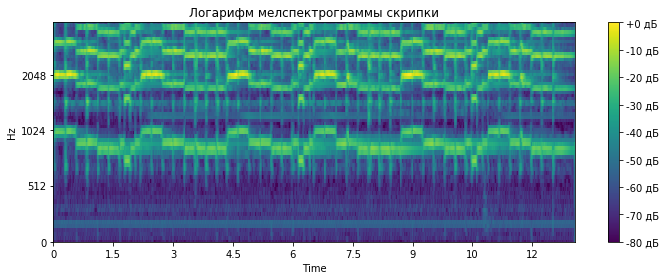
Если заинтересовало описание идеи этой статьи, а также почему эта идея близка по смыслу к построению мел-спектрограмм, то милости прошу под кат.