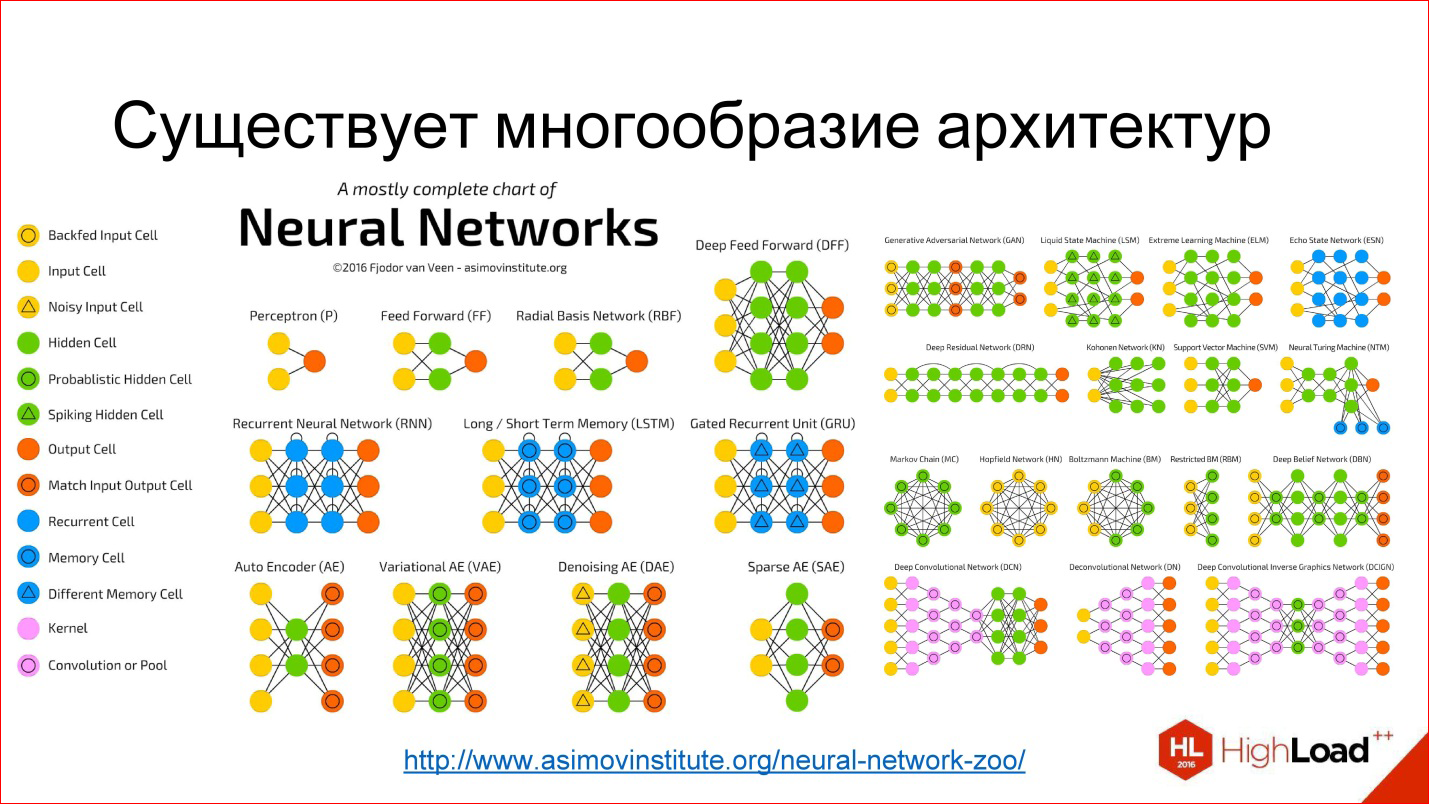
Автор — Алекс Расселл, разработчик Chrome, Blink и веб-платформы в Google
TL;DR: бюджеты производительности — существенная, но недооценённая часть успешного продукта и здоровой команды. Большинство наших партнёров не осведомлены об условиях реального мира — и в результате выбирают не те технологии. Мы установили бюджет по времени пять и менее секунд до интерактивности сайта после первой загрузки, а также две или менее секунд при последующих загрузках. При соблюдении этих нормативов мы ограничены типичным устройством из реального мира и типичной сетевой конфигурацией. Это Android-смартфон за $200 на канале 400 Кбит/с, RTT 400 мс. Это означает бюджет ~130-170 КБ ресурсов критического пути, в зависимости от их состава: чем больше JS — тем меньше объём.
За последние несколько лет мы имели удовольствие работать с десятками команд. Работа оказалась просветляющей, иногда в очень неожиданных местах. Один из самых неожиданных результатов — частые случаи «западни JavaScript».
«Нам нужен новый термин для упущенных деловых возможностей из-за современного фронтенда. Может быть, “западня JavaScript”»?
Управленцы, которые дают добро на создание прогрессивных веб-приложений (PWA), часто основным мотивом называют практически беспроблемный охват новых пользователей. В то же время разработчики осваивают инструменты, которые делают возможной достижение такой цели. Никто не хотел плохого. Тем не менее, результаты «готового» проекта PWA часто требуют недель или месяцев болезненной переделки, чтобы обеспечить минимально приемлемую производительность.
TL;DR: бюджеты производительности — существенная, но недооценённая часть успешного продукта и здоровой команды. Большинство наших партнёров не осведомлены об условиях реального мира — и в результате выбирают не те технологии. Мы установили бюджет по времени пять и менее секунд до интерактивности сайта после первой загрузки, а также две или менее секунд при последующих загрузках. При соблюдении этих нормативов мы ограничены типичным устройством из реального мира и типичной сетевой конфигурацией. Это Android-смартфон за $200 на канале 400 Кбит/с, RTT 400 мс. Это означает бюджет ~130-170 КБ ресурсов критического пути, в зависимости от их состава: чем больше JS — тем меньше объём.
За последние несколько лет мы имели удовольствие работать с десятками команд. Работа оказалась просветляющей, иногда в очень неожиданных местах. Один из самых неожиданных результатов — частые случаи «западни JavaScript».
«Нам нужен новый термин для упущенных деловых возможностей из-за современного фронтенда. Может быть, “западня JavaScript”»?
Управленцы, которые дают добро на создание прогрессивных веб-приложений (PWA), часто основным мотивом называют практически беспроблемный охват новых пользователей. В то же время разработчики осваивают инструменты, которые делают возможной достижение такой цели. Никто не хотел плохого. Тем не менее, результаты «готового» проекта PWA часто требуют недель или месяцев болезненной переделки, чтобы обеспечить минимально приемлемую производительность.