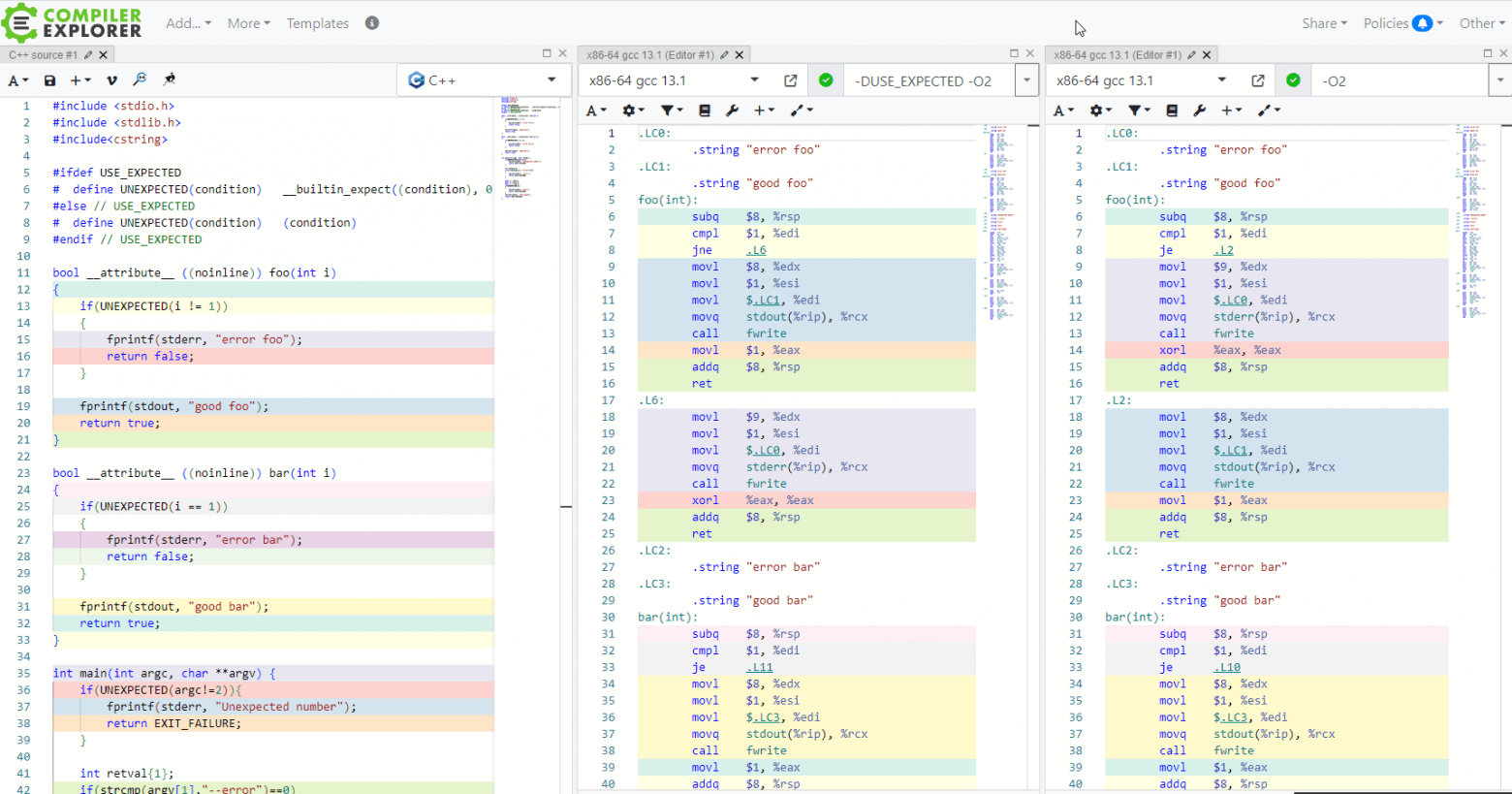
Поводом к написанию данной статьи и к разработке соответствующей мини-библиотеки ffh стало одно из практических заданий по дисциплине ‘Языки программирования’, которую я веду. В этом задании необходимо прочитать все строки из текстового файла для последующей обработки. Так вот, у студентов, выбравших для выполнения этого задания язык C++ [язык программирования выбирается студентом для каждого задания, но чаще всего выбирают C++ или Python], почему-то иногда читалась из файла лишняя пустая строка. В прошлые годы я не придавал этому большого значения, но в последний раз решил таки разобраться в чём проблема.
Файловый ввод, сделанный по-человечески
21 min
Поводом к написанию данной статьи и к разработке соответствующей мини-библиотеки ffh стало одно из практических заданий по дисциплине ‘Языки программирования’, которую я веду. В этом задании необходимо прочитать все строки из текстового файла для последующей обработки. Так вот, у студентов, выбравших для выполнения этого задания язык C++ [язык программирования выбирается студентом для каждого задания, но чаще всего выбирают C++ или Python], почему-то иногда читалась из файла лишняя пустая строка. В прошлые годы я не придавал этому большого значения, но в последний раз решил таки разобраться в чём проблема.