В мире, где Kubernetes доминирует в управлении контейнеризированными приложениями, один вопрос часто встаёт перед теми, кто стремится понять его внутренние механизмы: 'Как на самом деле работает k8s scheduler?' Эта статья предназначена для развенчания мифов и предоставления чёткого объяснения работы Kubernetes планировщика. Мы исследуем ключевые моменты этого процесса, начиная от того, назначает ли планировщик модули узлам один за другим в очереди или выполняет эту задачу параллельно, и заканчивая более сложными аспектами его работы. Погрузитесь в детали этой сложной, но увлекательной темы вместе с нами, чтобы лучше понять, как Kubernetes оптимизирует размещение подов в вашем кластере
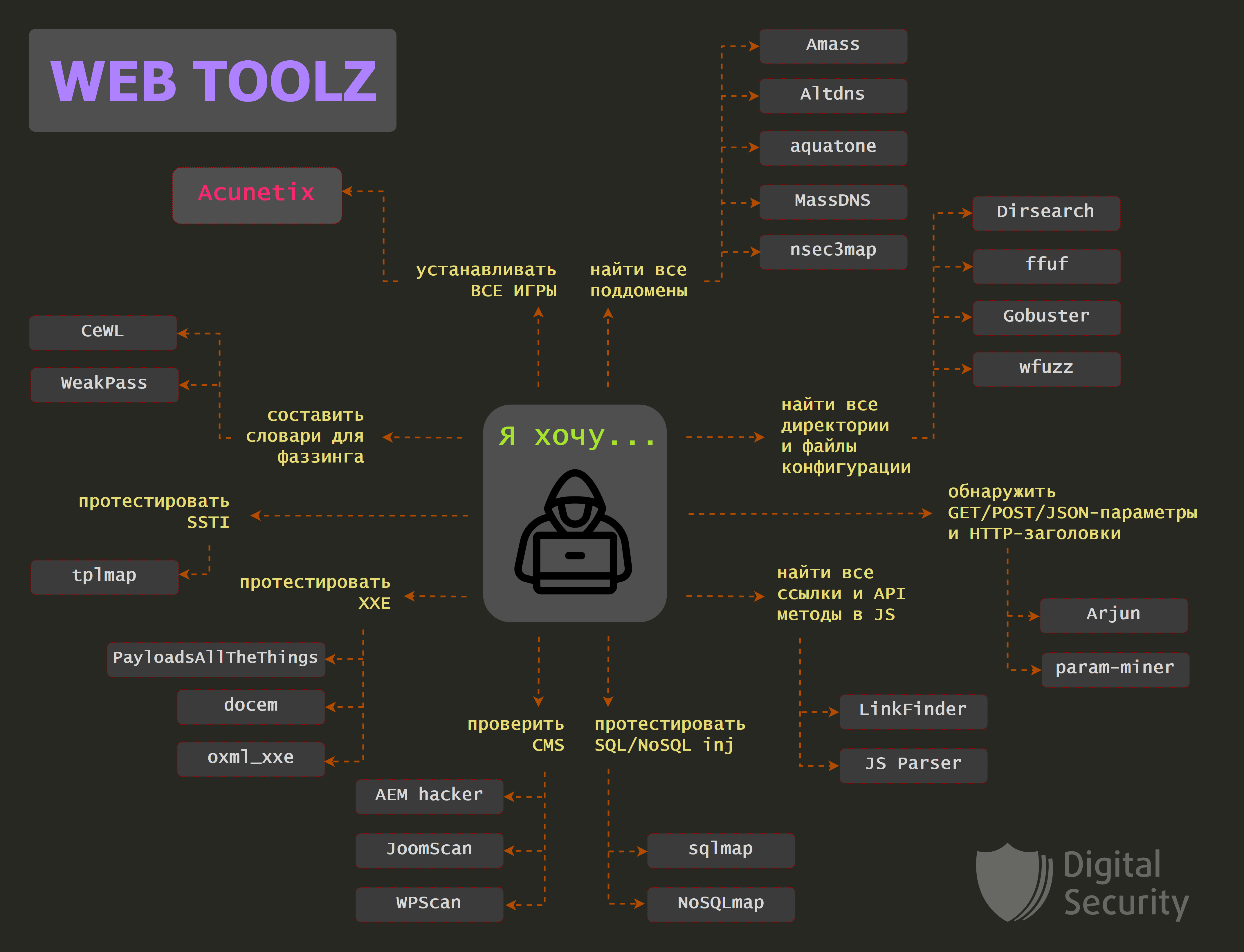






 Эта статья описывает использование контейнеров docker как отдельные ноды для системы непрерывной интеграции, в данном случае jenkins. Кому лень читать
Эта статья описывает использование контейнеров docker как отдельные ноды для системы непрерывной интеграции, в данном случае jenkins. Кому лень читать 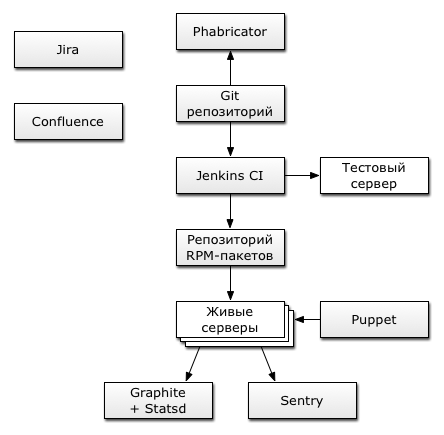

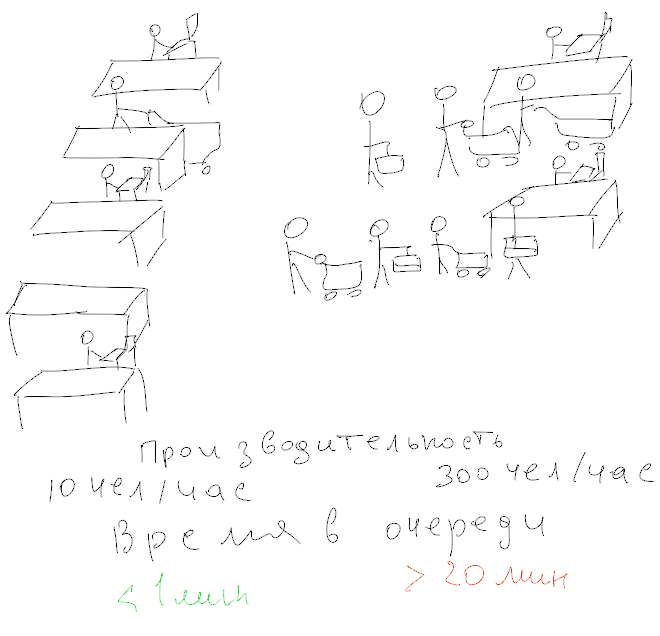
 Некоторое время назад зам.главы московского офиса разработки Badoo Алексей Рыбак и ведущие IT-Компот записали выпуск подкаста «Архитектура высоконагруженных приложений. Масштабирование распределенных систем".
Некоторое время назад зам.главы московского офиса разработки Badoo Алексей Рыбак и ведущие IT-Компот записали выпуск подкаста «Архитектура высоконагруженных приложений. Масштабирование распределенных систем".