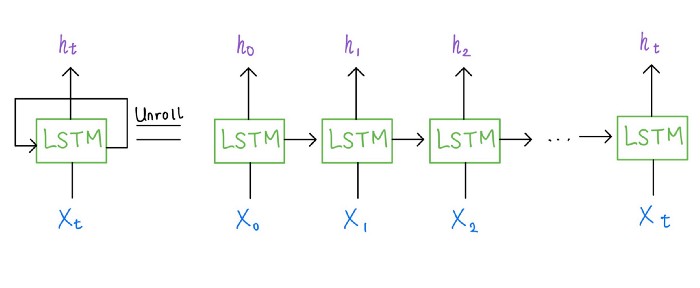
Удаление определенной информации в процессе обучения помогает моделям машинного обучения быстрее и лучше осваивать новые языки.
Группа ученых в области компьютерных наук придумала более гибкую модель машинного обучения. В чем особенность: модель должна периодически забывать кое-что из того, что знает. Новый подход не заменит огромные модели, но зато, возможно, подскажет нам, как именно они понимают естественный язык.